1. Introduction
Radar sensing has been classically used in an extensive range of applications, due to its ability to operate under all-weather and scene illumination geometry independence acquisition conditions. This would be a critical advantage, under specific circumstances, when compared, for instance, to optical sensing. Advances in radar hardware and software technology have made it possible to reliably detect and track objects, under competitive classification accuracy conditions, in underwater, air, and ground environments [
1,
2]. However, this framework seems to have been applied only to relatively big objects in specific scenarios, i.e., airplanes, ships, or submarines [
3,
4].
Radar technology has also found an important field of application in remote sensing data classification and health monitoring for environmental preservation purposes, usually combined in a common optical remote sensing framework [
5,
6].
Apart from these research fields, radar sensors are also being applied nowadays in other areas, as in action and gesture recognition or in autonomous driving, to cite a few cases. In particular, there is an increasing interest in the use of radar technology in human gesture and action recognition because it is aimed at solving the problem of low recognition accuracy that vision based systems may have. Not only gestures [
7] but also more complex actions are aimed at by the new radar acquisition technology and classification strategies [
8]. Even daily or ordinary activities (e.g., cooking, eating, and resting) may be classified using this type of acquisition technology [
9]. Usually, human action recognition is made using sensors whose location is fixed, but new approaches using unmanned aerial vehicles (UAVs) are starting to appear [
10].
Another area where radar technology is being applied is related to object and people classification for systems aimed at helping create a safer driving environment, or even in autonomous driving [
11,
12].
Some of the newest radar sensing applications do not try to obtain information from objects over long, mid, or short distances (in the range of meters), but just within a few centimeters. A sensor developed by Google, called Soli, was announced in 2015 and obtained great media interest. It is a millimeter-wave radar, and it has found several research applications. In [
13], this sensor is used to identify up to 26 types of materials and 10 body parts from several participants. In [
14], it is used to classify and distinguish five common types of materials, namely aluminum, ceramic, plastic, wood, and water, regardless of their different sizes and thicknesses. A hand gesture recognition system, which successfully distinguishes 10 gestures, is proposed in [
15]. This type of radar sensor has even been used for face verification [
16] or to differentiate between blood samples of disparate glucose concentrations in the range of 0.5 to 3.5 mg/mL [
17]. However, the number of research studies focused on the application of this technology for daily object material classification and other interactions seems to still be scarce [
18]. A Tangible User Interface (TUI) allows the user to interact with digital information through real actions. This type of user interfaces is known to be more usable and easier to understand, especially for elderly people [
19], since, although not everyone knows how to operate a keyboard or mouse, everyone is familiar with grasping or moving common objects. The idea behind TUIs is that there is a direct link between the digital system and the way the physical objects are manipulated.
Miniature milimeter-wave radar sensing has been proposed to enhance the interactions by identifying materials or estimating the orientation or distance at which the physical elements are located [
18]. Millimeter-wave radar technology could be considered a cost effective option for material identification, counting objects/items, or estimating their position, even when they might be partially covered or occluded. This property is a great advantage when compared to other sensors such as cameras.
The aim of this paper is to apply a diverse group of classification strategies and feature extraction techniques on a series of datasets of different nature, acquired by a portable radar sensor, aiming at validating this technology as a good candidate to be used in TUI sensing problems. The classification strategies include Random Forests [
20] and Support Vector Machines [
21]. Moreover, different classifiers are combined in ensembles, using Stacked Generalization [
22].
The feature extraction techniques applied in this paper are the basic aggregation features (e.g., averages and root mean squares) previously used by Yeo et al. [
18] and two techniques originally introduced for time series classification: ROCKET [
23] and TSFRESH [
24]. The datasets used in this study, obtained using a radar system, are not time series. Nevertheless, as in time series, the features are arranged and therefore their order is important. For instance, functions on the values in an interval (e.g., the first half of the series or channel) can be used. Hence, methods proposed for times series classification can also be used for this kind of data. It is common practice to use time series classification methods (including multivariate time series) for datasets where the feature order is important even though the features do not represent different times [
25,
26], for instance, from spectroscopy [
27,
28]. Image contours or outlines, such as arrowheads [
29], leaves [
30], or fish species [
31], can be represented as time series.
The rest of the paper is organized as follows.
Section 2 describes the group of datasets, as well as the corresponding feature extraction and classification algorithms used.
Section 3 discusses the results. These results are validated and analyzed using average rankings and post hoc tests such as the Nemenyi test, as well as by using Bayesian Signed-Rank Test, all of them in order to determine which combination of feature vector and classification method is best, and whether this improvement (i.e., difference in accuracy performance) is statistically significant or not.
Section 4 presents the conclusions and discusses potential future lines of research.
2. Datasets, Feature Extraction, and Classification Methods
Radar sensing uses an electromagnetic signal that hits an object. This signal might be directly reflected or scattered/absorbed by it, therefore giving an overview of the properties of the material the object is made of or of the distance or position the object is at. The type of radar whose data form the repository we used is a Frequency-Modulated Continuous-Wave (FMCW) radar, and this type of radar system has shown its potential to be used for detection/recognition purposes.
Soli [
18] is a mono-static, multi-channel (8 channels = 2 transmitters × 4 receivers) radar device, operating in the 57–64 GHz range (center frequency of 60 GHz), using an FMCW principle, where the radar transmits and receives information on a continuous basis. When an object is placed on the top or nearby the Soli sensor, the energy transmitted from the sensor is absorbed and scattered by the object, which varies depending on its distance, thickness, shape, density, internal composition, and surface properties, commonly described as the Radar Cross Section (RCS). As a result, the signals that are reflected back represent rich information about the contributions from a range of surface and internal properties.
Nevertheless, the complex mixing nature of the signals obtained by the radar sensor (due to these above-mentioned multiple factors that are contributing to the final, detected, and signal) make them have non-smooth and complex shapes, which contribute with an additional complexity degree to a potential signal classification strategy.
The aim of
Section 2 is to present a coherent explanation of the different feature extraction techniques and classification strategies applied on a series of datasets obtained by Yeo et al. [
18], using the Soli radar sensor. It is composed of the following subsections:
Section 2.1 gives a detailed overview about the different types of datasets used in our classification performance analysis framework.
Section 2.2 explains the feature extraction methods that are applied. Feature selection methods are considered taking into account their number in relation to the number of instances of each dataset (the so-called curse of dimensionality).
Section 2.3 describes the different classification strategies applied.
2.1. Radar Datasets
A previous study [
18] showed that Soli could be used to identify materials, estimate number of objects, their orientation, or the the distance to the sensor. Yeo et al. [
18] created a series of supervised classification datasets, formed by on the one hand the signal acquired by this sensor, and the class of the material on the other hand. The type of material, distance, and other features were also included. The following is a brief schematic description about the different types of categories these datasets are formed by:
- ⋄
Material identification (of the material an object is made of), from a limited list of materials.
- ⋄
Object identification, from a series of objects in the same category (i.e., a credit card of a specific bank from the rest of the credit cards).
- ⋄
Counting the number of elements that might be piled up on the surface of the sensor.
- ⋄
Distance estimation, from an object to the sensor.
- ⋄
Order identification, of the items in a battery of objects.
- ⋄
Flipping identification, where the orientation of an object may be inferred.
- ⋄
Movement, where the angular position of the object or changes in the movement of one of them in relation to other(s) are obtained.
The complete group of datasets can be found at:
https://github.com/tcboy88/solinteractiondata (accessed on 18 January 2021). As stated above, the radar chip has eight channels that acquire a series of raw signals. Each of these channels has 64 data points. This information is converted into a 512 (=
) feature vector and collectively saved in a CSV file. Therefore, the original dataset dimensionality value is always constant and equal to 512. As recommended by Yeo et al. [
18], the easiest way to use the data was considering the Weka Graphical User Interface (GUI), converting them to Attribute-Relation File Format (i.e., .arff) files. This final group of datasets is formed by 34 files.
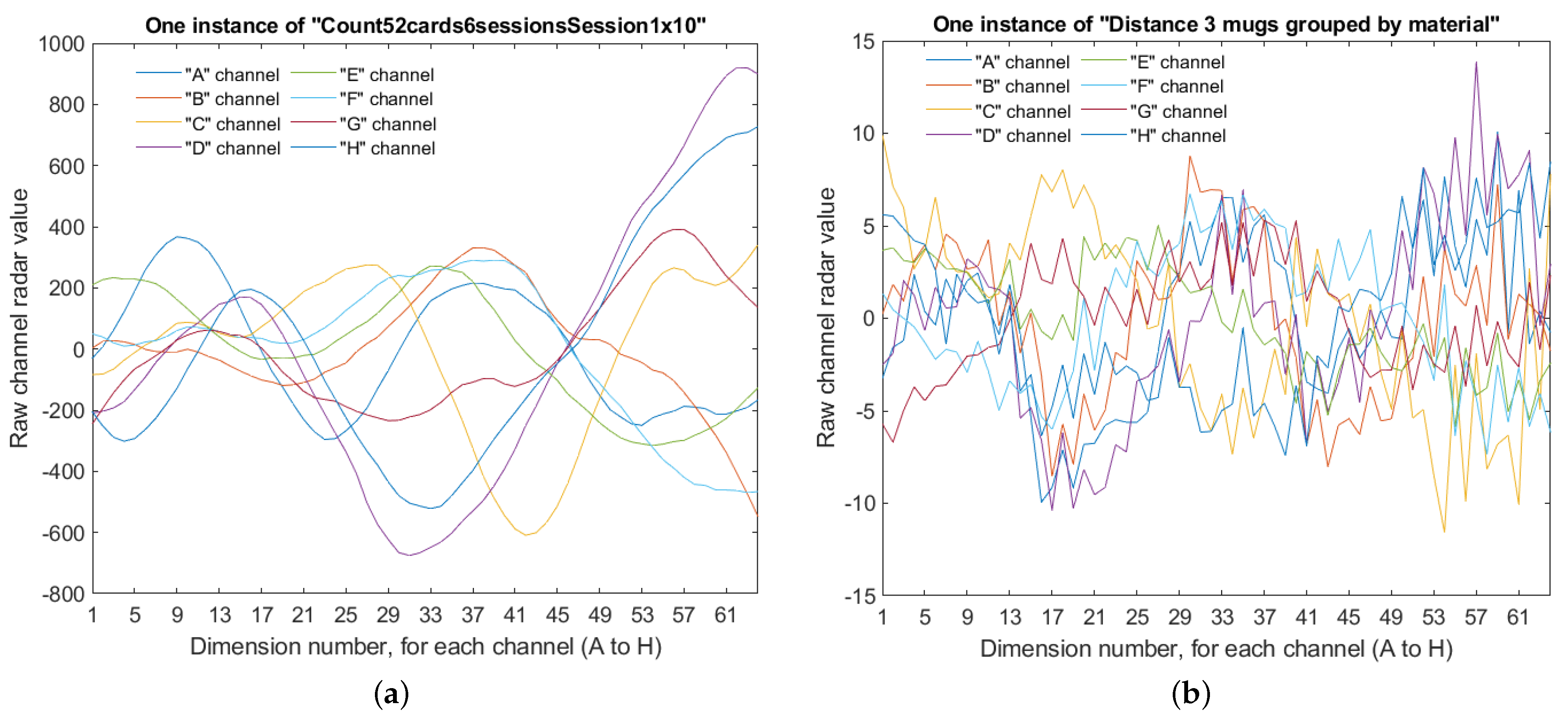
Figure 1a,b shows the eight 64D signals obtained by the radar sensor for two instances, each from a different dataset. We can see the complex and irregular shape of the signals detected by the sensor.
Table 1 shows the total number of samples and classes for each one of the files. These datasets show different acquisition conditions over a series of distinct objects, including playing cards, poker chips, and Lego blocks. For particular details and a deeper description about the acquisition conditions for the creation of these sets, the reader is referred to Section 6 in [
18].
2.2. Feature Extraction
The most straightforward way to apply a classification strategy on this dataset would be to use the complete 512-dimensional vector (raw data) as the feature vector. However, raw data often contain noise, redundancies, or irrelevant information; thus, there are different feature selection/extraction techniques that could be applied on such a feature space and subsequently be used instead or added to this feature vector. The following additional feature extraction techniques are considered in our case:
In this framework, each feature vector is individually analyzed in relation to its significance for predicting the target class label. As a result, a vector of
p-values is obtained. This vector is assessed against the Benjamini–Yekutieli procedure [
33], which allows the method to decide which features to keep. This selection strategy considers the application of a threshold, whose default value is 0.05. However, this selection is so restrictive in some cases that most of the features are discarded. An iterative method is applied that considers the threshold values
and selects the first one that keeps at least a 10% of the total number of attributes.
2.3. Classification Methods
Two main blocks of classification strategies were considered to be applied on the datasets, summarized as the use of: (a) a Support Vector Machine and a Random Forest classifier, being these two classifiers those that were used in [
18] (presented in
Section 2.3.1); (b) a Stacked Generalization approach (a particular type of ensemble machine learning algorithm) (
Section 2.3.2), where we try to take advantage of the diversity that different classification methods may give, in order to help improve classification accuracy, when using them in a coordinated/simultaneous way.
2.3.1. Single Type Classifiers
Two classification methodologies were applied: (1) Support Vector Machines (SVM); (2) Random Forests (RFs). SVM is a widely used classification method, in different and varied areas of research, partly because of its capability and good behavior when dealing with problems with a small number of samples in (relation to) high-dimensional feature spaces. Originally developed and applied in linearly separable problems, it is aimed at obtaining the hyperplane whose distance to the two groups of data points (called margin), representing the two classes, was maximal. SVM was generalized later to deal with nonlinearly separable problems using the so-called (transformational) Kernel trick [
21]. A mathematical transformation function is applied to map the nonlinear separable dataset into a higher dimensional space where the samples can be linearly separated using an hyperplane.
Under this mathematical framework, two parameters emerge
. The optimal value of these parameters is problem dependent. A Grid Search strategy was applied to assess their optimal values. The parameter
C search interval and step size was
,
,…,
, and the corresponding
interval and step size was
,
,…,
. Whenever the best best pair of parameters was obtained in the interval limits, the Grid Search was automatically extended by a factor of two. This procedure follows the guidelines given in [
34].
Ensemble learning methods are based on the idea of using multiple learning algorithms to obtain better predictive performance than one could obtain from any of them, separately. The idea behind ensemble learning is the way an expert committee works in real life, i.e., it is usually easier to properly predict something when the prediction is made by more than one expert, and a consensus is obtained from them. Ensembles are combinations of several classifiers, which are often called base classifiers. There are several types of ensembles, which may be divided into two large groups: (a) homogeneous ensembles, where all the base classifiers are built using the same algorithm (but with different versions of the dataset or different training parameters); (b) heterogeneous ensembles, where the base classifiers are built using different algorithms.
Diversity is a key property in the search for an optimal ensemble strategy performance, since there is no benefit when combining base classifiers that always obtain the same predictions. There are several techniques to induce diversity in homogeneous ensembles. In Bagging [
35], for instance, each classifier is trained with a variant of the training dataset, which uses different random samples of the training set. Random Forests [
20] are ensembles of Decision Trees [
36]. In this method, the diversity during the training process is enforced by combining the sampling of the training set, as Bagging does, with the random selection of subsets of attributes in each node of the tree. This way, in each node, the splits only consider the selected subset of attributes. Later, on the prediction stage, each base classifier predicts a class, and the class selected the most (the mode) is the final prediction of the ensemble. RFs are used to correct the tendency of the decision trees to overfit. The main parameter of an RF is its size (i.e., the number of trees that are generated into the ensemble). In our study, 100 decision trees were used because it is a usual and sufficient number [
37].
2.3.2. Stacked Generalization
Stacked Generalization is an ensemble method where a new model learns how to best combine the predictions from multiple existing models. In this approach, any learning algorithm could be used to combine them.
In particular, the generation of classifiers that are accurate and diverse is only the first part in an ensemble classifier generation process. The second part (as important as the former one) is the method used to obtain the ensemble outputs by combining the outputs of the base classifiers. Two of the approaches used to combine the outputs of the base classifiers are: (a) majority voting; (b) average of probabilities. Alternatively, there are methods that may be able to learn the so-called combination rules. These methods (called meta-classifiers) are particularly useful when the base classifiers do not have the same success rate (among them) when classifying instances. This may happen when the base classifiers are generated using different training sets or different training algorithms.
Stacked Generalization (also called Stacking) [
22] builds a classifier that takes as inputs values, the output values of the base classifiers, and learns to map these values of the base classifiers into the correct final output value. In other words, no voting strategy is applied in order to combine the predictions of the base classifiers. In this case, a meta-classifier is used. The base classifiers are trained with the training set and the meta-classifier is trained with the predictions of the base classifiers.
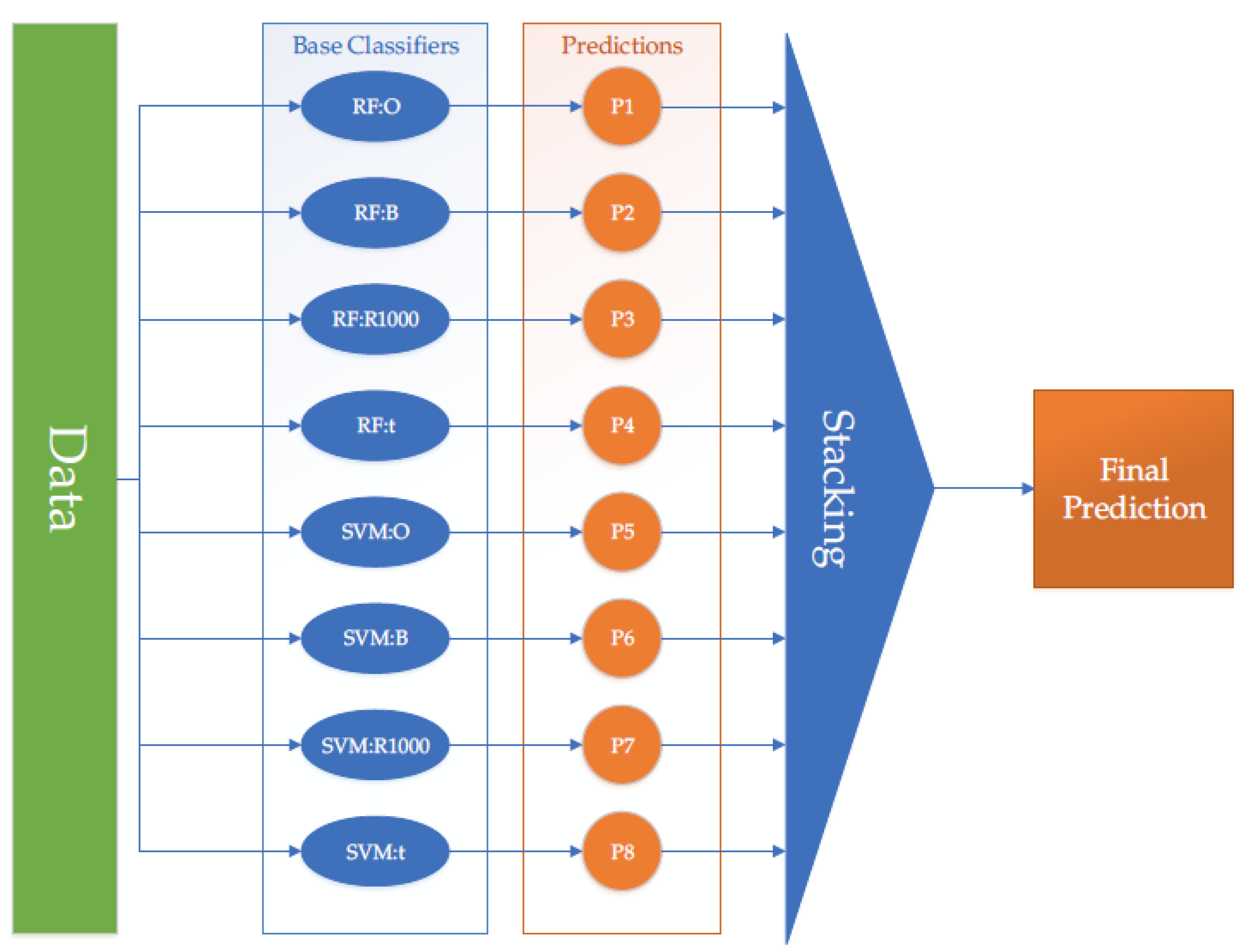
Figure 2 shows a scheme of one of the stacking approaches used.
The predictions of the classifiers are obtained from a different partition set than the one used for training. This is achieved by dividing the training set into several partitions. Therefore, Stacking can also be seen as a sophisticated form of attribute extraction. Stacking base classifiers are usually trained using different algorithms. Another strategy would be to use different views, i.e., subsets of attributes obtained by each feature extraction method. This type of Stacking strategy is often called multi-view stacking and has been successfully used when applied to other (but somehow similar) problems [
38,
39,
40].
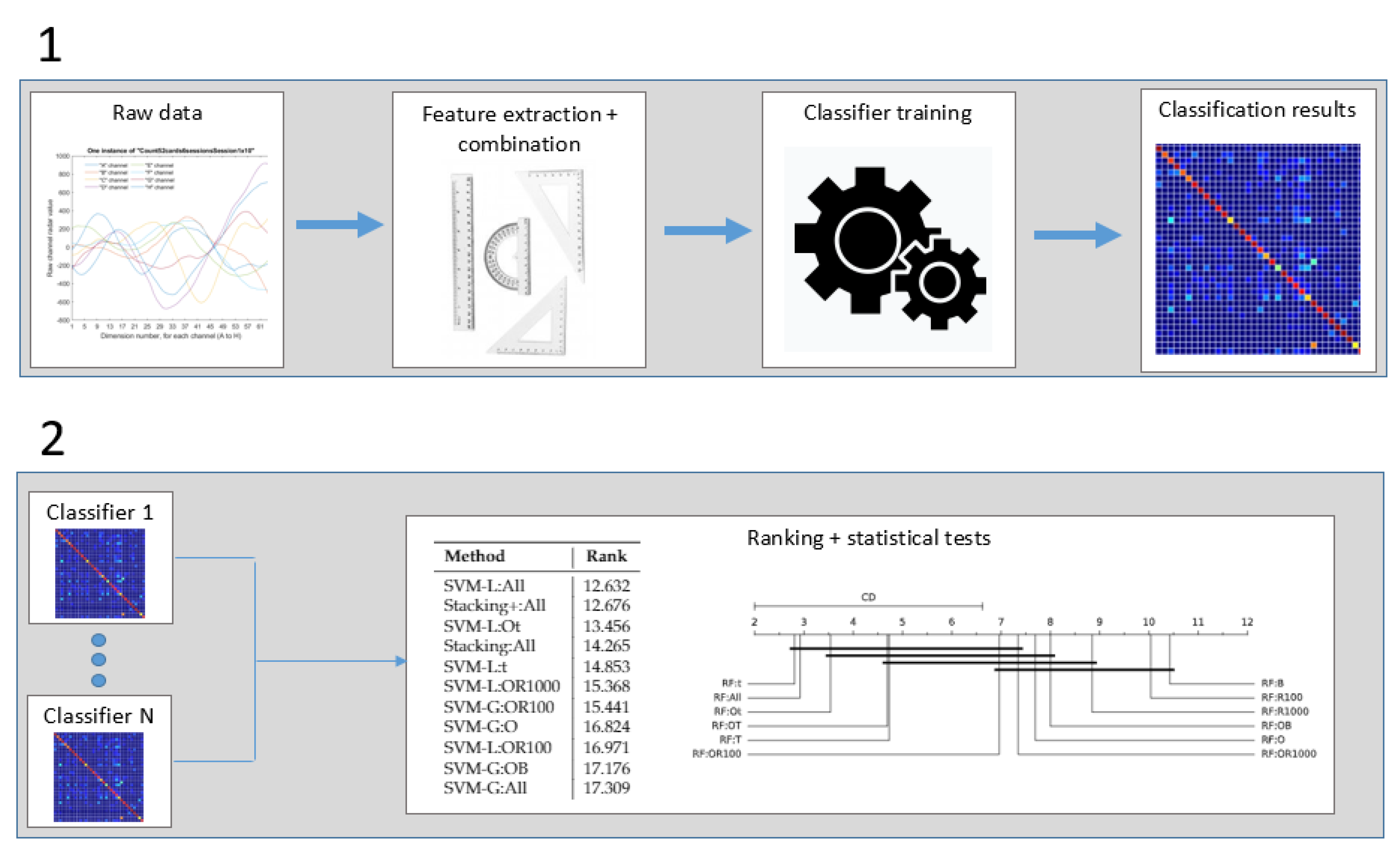
Figure 3 shows a flow diagram of the general data processing strategy followed in the paper. The figure shows the processing chain divided into two parts. The first of them shows that different types of features and feature combination strategies are obtained from the raw data values, and different classifiers are trained and used to obtain the classification accuracy results for the different datasets. In the second part, these classification accuracy results, for each dataset, are ranked, and the statistical significance of their differences are obtained in order to assess which method is better, and whether the differences among classification strategies are statistically significant or not.
3. Results and Discussion
Accuracy (for the Random Forest, SVM Linear with default parameters (rhe same configuration as the one used in [
18]), and the optimized Gaussian SVM classifiers) was assessed using different combinations of the attributes explained in
Section 2.2.
Table 2 shows these combination strategies: The symbol `&’ means that the referred attributes are concatenated. Stacking was applied using two different configurations, called as follows:
- ⋄
Stacking:All: Eight base classifiers were assembled (four RF classifiers and four SVM linear classifiers), one for each one of the four extracted feature sets (raw features (O), basic aggregation features (B), ROCKET with 1000 kernels (R1000), and TSFRESH with feature selection (t)).
- ⋄
Stacking+:All: Ten base classifiers were assembled: the eight base classifiers described in the previous case, a linear SVM, and an RF, trained in both cases with the concatenation of all the attributes.
In all the results that follow, we use SVM-L (SVM with Linear Kernel) to refer to SVM with default parameters and SVM-G to refer to Grid search-optimized SVM with RBF Kernel. We simply use RF for the Random Forest classifier. Features used for training the classifiers use the same abbreviation as that shown in
Table 2.
In order to compare the performance of the different classification methods, we might use the average accuracy of each one of the pairs (Classifier:Feature Set) evaluated throughout the 34 datasets shown in
Table 1. Nevertheless, when comparing multiple methods on multiple datasets, an alternative to (and sometimes more appropriate way than) comparing average accuracies is to use average ranks [
41]. Average ranks are computed in the following way: For a given dataset, the methods (in this case, a method is a pair formed by Classifier and Feature set) are sorted from best to worst. The best method receives rank = 1, the second best receives rank = 2, etc. In the case of a tie, average ranks are assigned. For instance, if two methods tie for the top rank, they both receive rank = 1.5. The average ranks across all the datasets are then computed for each method.
Post hoc tests were applied in order to identify statistically significant differences among the performance results. Some of these tests are strict in the conclusions that might be obtained from them. We found that the classification accuracy results from some of the 34 datasets are substantially high, for a considerable number of methods. Therefore, aiming at inferring the classifiers and attributes that work best with the hardest datasets (i.e., those that are more interesting), the statistical comparison of the methods was carried out twice: first using all the datasets and then using the subset formed by the difficult ones (the division between easy and difficult datasets was determined based on the performance of a baseline classifier).
Post hoc tests based on mean-ranks are commonly used, but their application has been questioned recently [
42]. Hence, the results are also compared with the Bayesian Signed-Rank Test [
43].
3.1. Results Corresponding to All the Datasets
Table 3 shows a selection of the results, for a subset of the pairs (Classifier:Feature Set). Given the large number of pairs, it is not possible to include all the methods in a single table (
Table A1,
Table A2,
Table A3 and
Table A4 (in the
Appendix A) show the complete set of results for the RF, SVM-L, and SVM-G classifiers and the Stacking strategy, respectively, considering all the datasets). The pairs in the subset were selected so that for all data sets there was some method with the highest accuracy. In some datasets, many methods share the best accuracy, so it is not possible to include all of them in the subset. Therefore, the subset of pairs was further reduced according to the average accuracy across all the datasets. Moreover, the pairs with the feature set OB were also included because it was used by Yeo et al. [
18].
Table 4 presents the average accuracy of each one of the pairs (Classifier:Feature Set) assessed throughout the 34 datasets. It also shows the average ranks computed using all the methods in the experimental setup. In terms of average accuracies, the best results obtained by Shyong Yeo et al. [
18] appear in the lower third of the table; SVM-L:OB (Linear SVM trained using the concatenation of Raw and Basic features) achieves an average accuracy of 91.36%. The same classifier, when trained using all features or TSFRESH with feature selection, obtains an accuracy higher than 94.5%. In terms of average ranks, the two pairs with top ranks are SVM-L:All and Stacking+:All, with average ranks below 12.7. The average rank for SVM-L:OB is 18.13.
The best five pairs according to the average accuracy and rank (in
Table 4) use the feature sets (t), (All), and (Ot).
Table 5 summarizes the results in
Table 4 averaging for each feature set the corresponding values of RF, SVM-L and SVM-G. According to both the average accuracies and ranks, the three best feature sets are (t), (All), and (Ot).
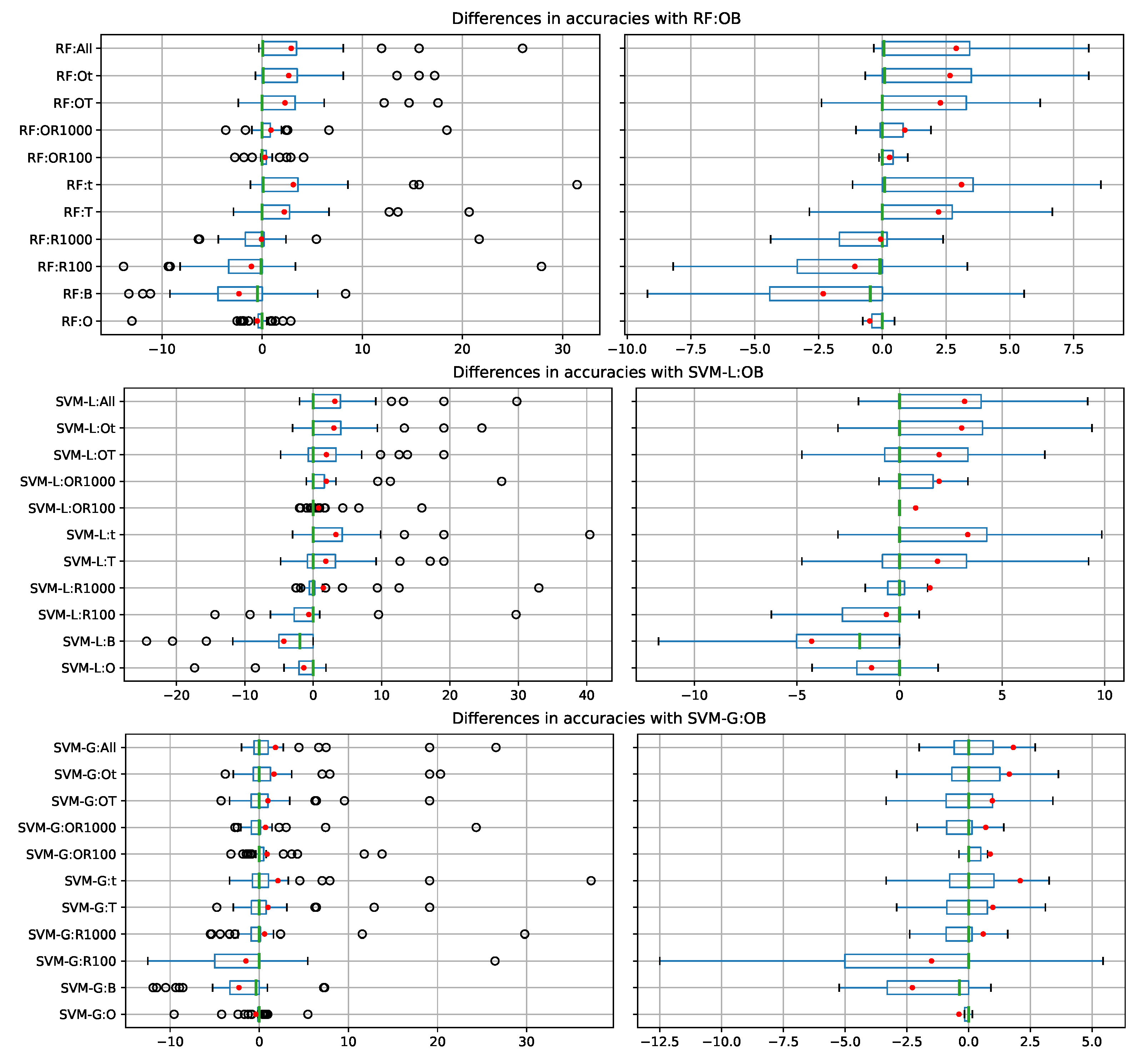
Figure 4 shows, for each one of the three classification methods, the differences in terms of accuracy between each feature set and the feature set (OB) used by Yeo et al. [
18]. Each boxplot is from the corresponding differences from the 34 datasets. The average differences are clearly favorable for several of the alternative feature sets. Medians of the differences are close to 0 or negative. As shown in
Table A1,
Table A2,
Table A3 and
Table A4, there are several datasets with 100% accuracy for all or many of the feature sets. For several feature sets, the boxplot are mostly in the positive region, positive differences are greater than negative differences. For SVM-G the boxplots are less favorable to the alternative feature sets, but, as shown in
Table 4, SVM-L has better results than SVM-G.
Given the large number of (Classifier:Feature Set) tested methods, it is preferable to obtain the average ranks by considering smaller pair groups. Therefore, methods were divided depending on the type of classifier used: RF, SVM-L, and SVM-G. These average ranks are shown in
Table 6.
The use of the Nemenyi test [
44] was also proposed by Demšar [
41] to compare methods in a pairwise way. For a certain level of confidence (
), the test determines a critical difference (CD) value. If the difference between the average rankings of two methods is greater than CD, the null hypothesis,
, that both methods have equal performance, is rejected.
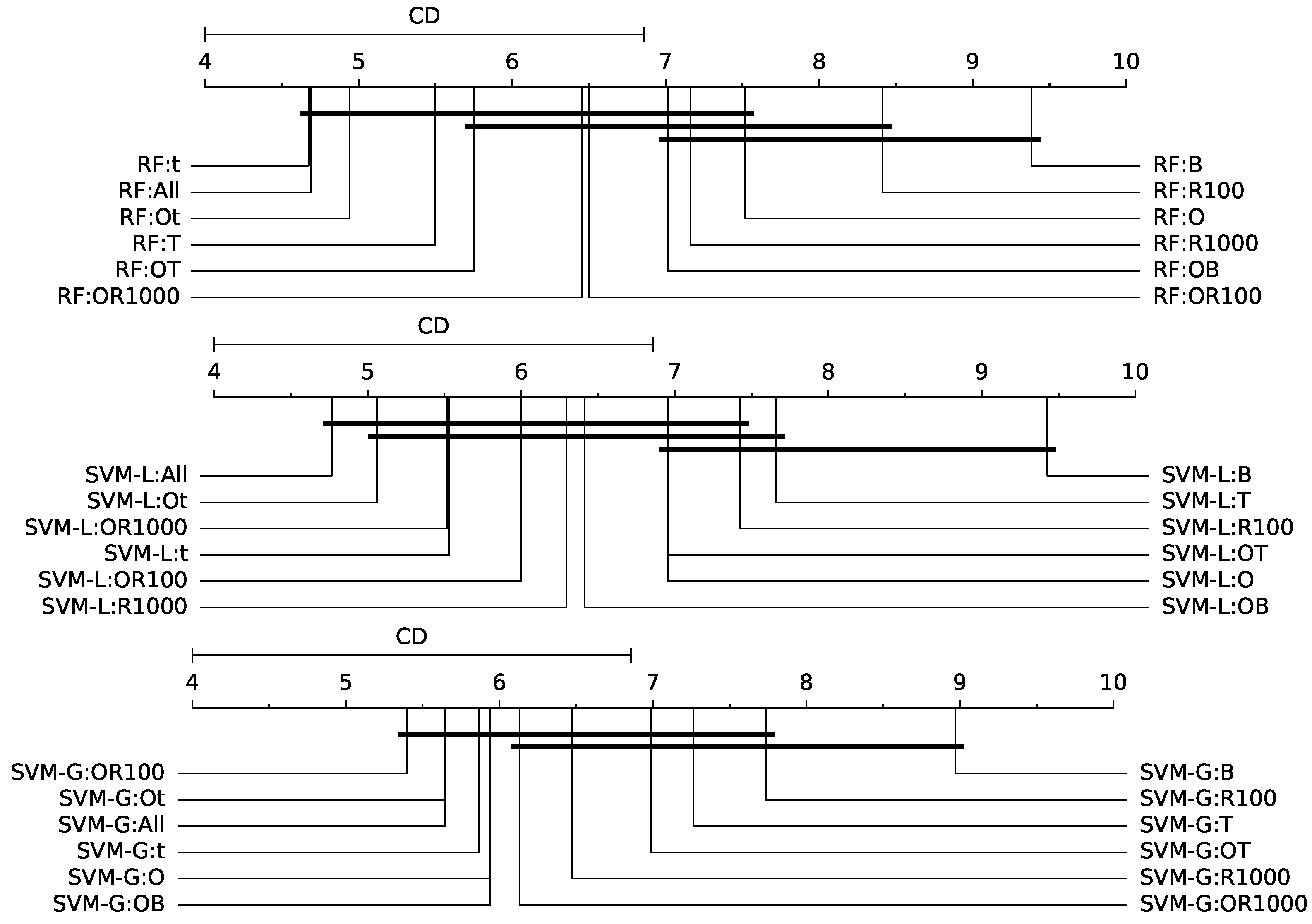
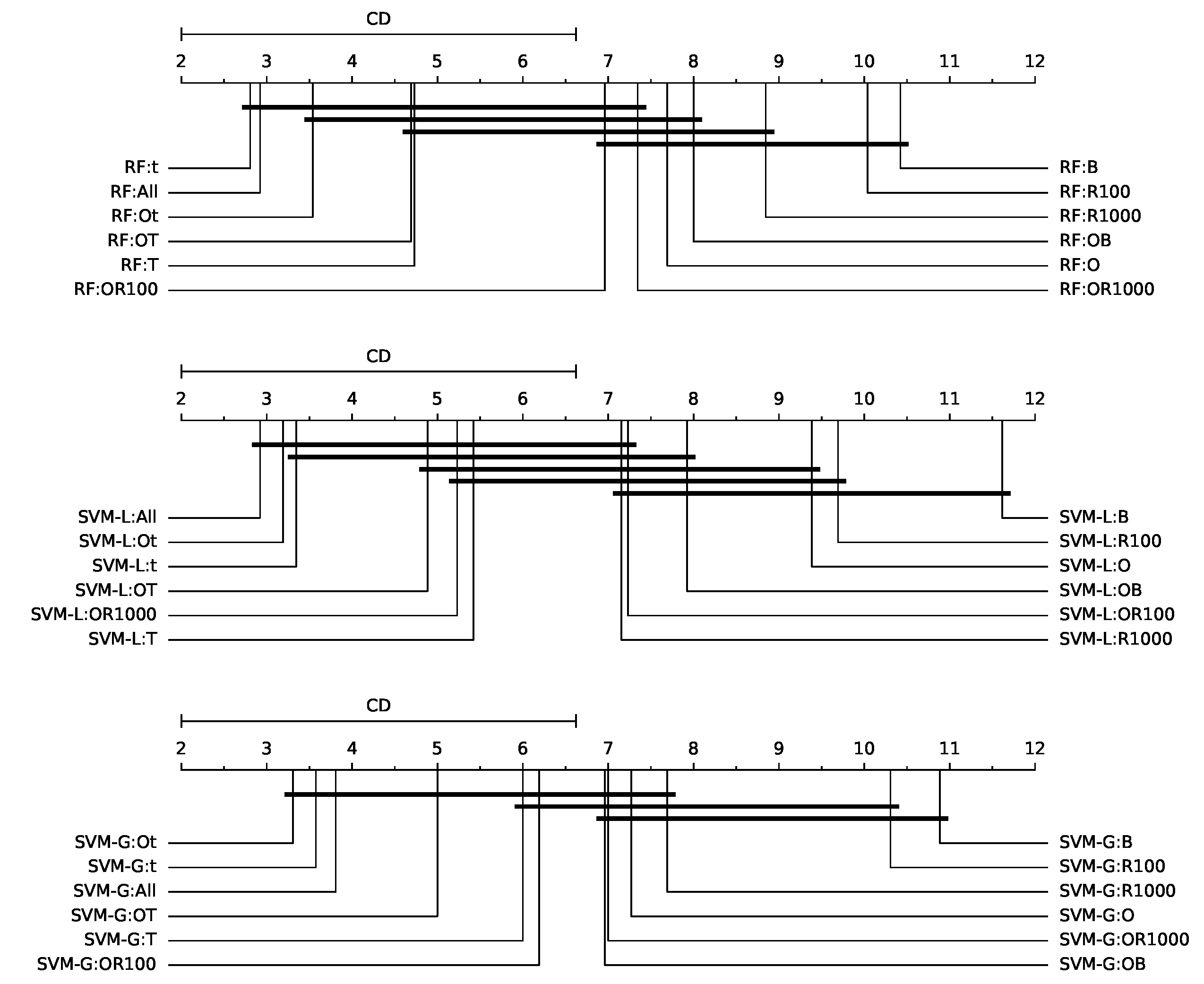
Figure 5 shows the Nemenyi’s CD diagrams. In these diagrams, thick horizontal lines are used to connect methods whose difference in average ranks is smaller than CD.
The methods were also compared using the Bayesian Signed-Rank Test [
43], the Bayesian framework equivalent version of the Wilcoxon Signed-Rank Test. In this test, the value of the Region of Practical Equivalence (ROPE) was set to 1% for accuracy. Two methods were considered equivalent when the difference in their performance was smaller than this ROPE value. The test determines three probability values, corresponding to the following cases: (1) one method is better than the other; (2) vice versa; (3) they are in the ROPE.
Figure 6,
Figure 7 and
Figure 8 show the Bayesian Signed-Rank Tests posteriors, for the RF, SVM-L, and SVM-G classifiers, respectively. In these figures, the (OB) feature set is compared against each one of the other feature sets, for the corresponding classifier. For each feature set, there is a triangle. In these triangles [
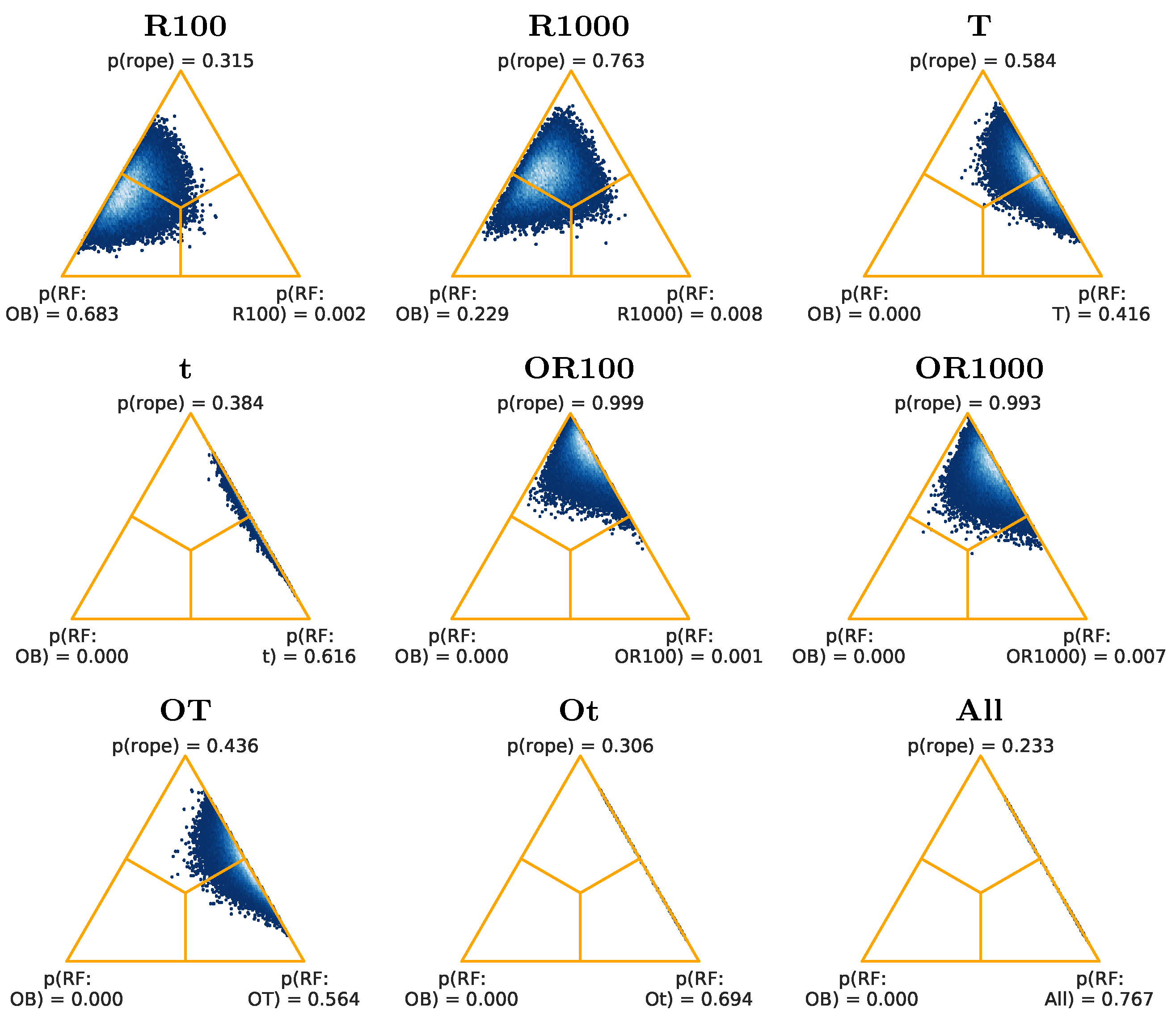
43], the bottom-left and bottom-right regions correspond to the case where one method is better than the other or vice versa. The top region represents the case where the ROPE is more probable. The corner triangles show the probability of each region. The left region in the triangle is for OB and the right region for the other feature set.
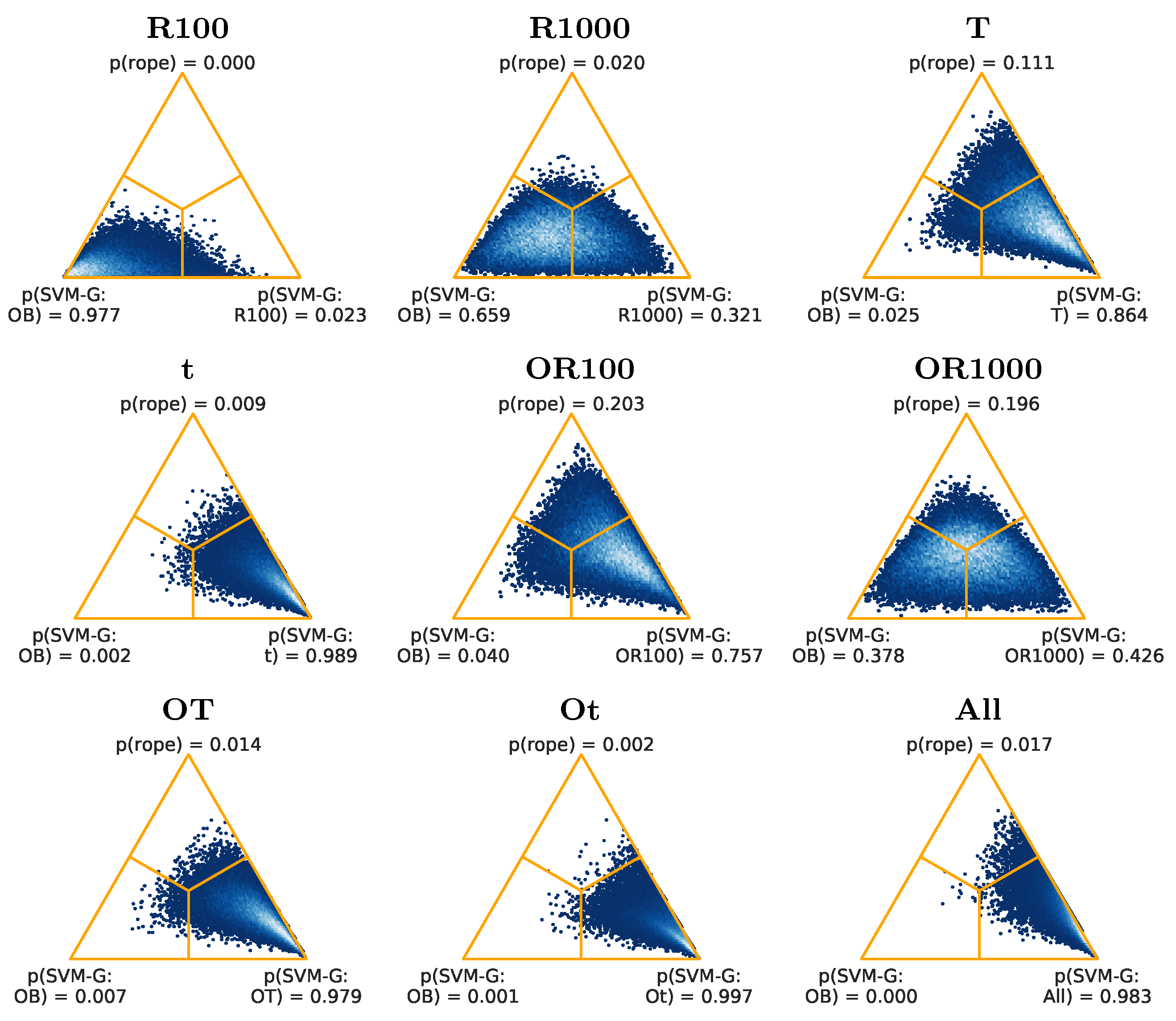
Figure 6 shows that, for RF, the feature set with more favorable results when compared to (OB) is (All), with a probability of 0.767, while it is 0.000 for (OB).
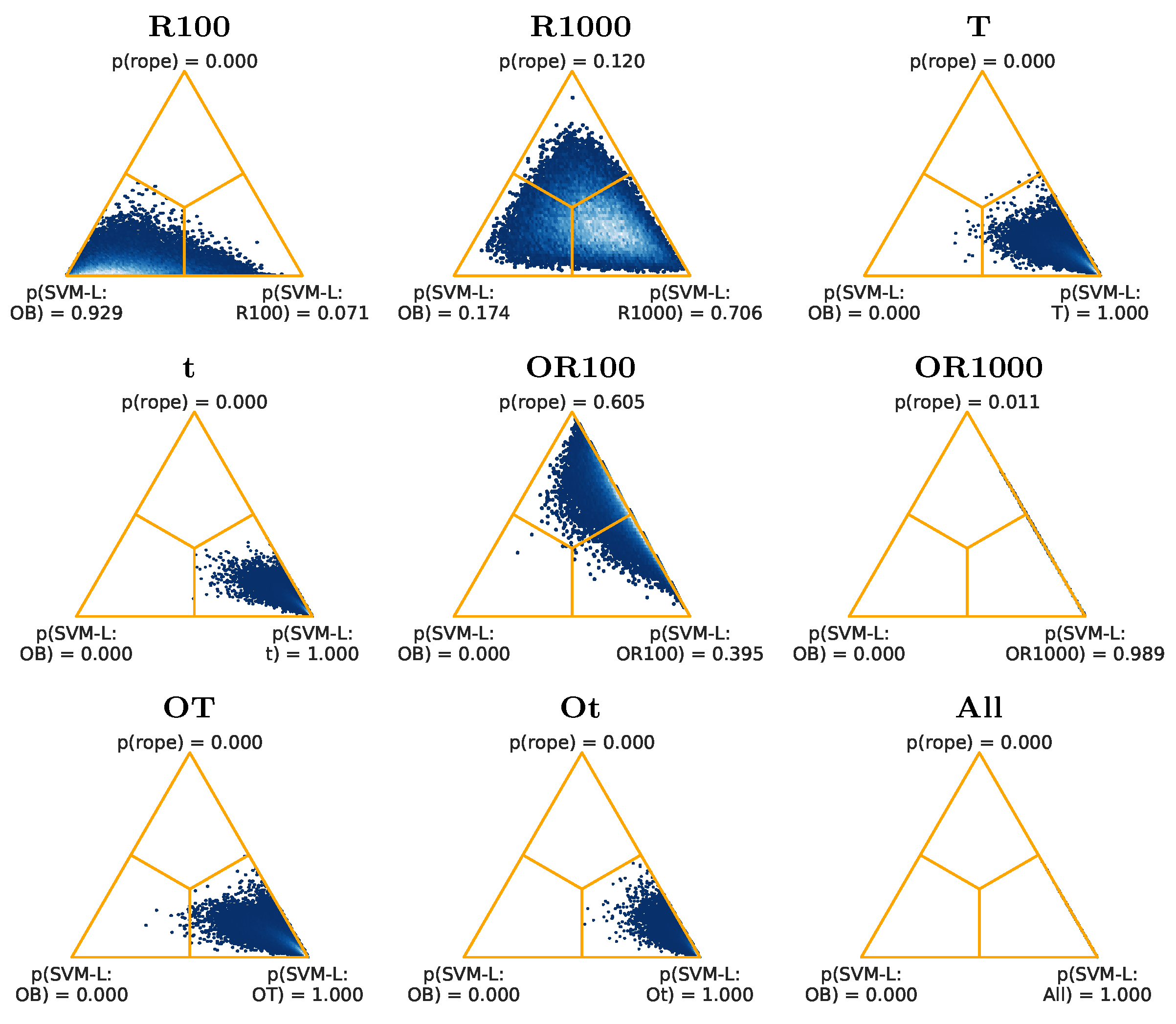
Figure 7 shows that, for SVM-L, the best feature set is (Ot): its probability is 0.821, while it is 0.000 for (OB). In
Figure 8, for SVM-G, the results are less favorable for the alternative cases to (OB). The best feature set is (Ot), with a probability of 0.244, being 0.001 the probability for (OB). The classification results for the three different classifiers therefore show an improvement that can be considered as significant, when using the different types of proposed feature sets, versus the features proposed in [
18].
3.2. Results for the So-Called Difficult Datasets
An important part of the datasets reached a classification accuracy near or equal
(
Table A1,
Table A2,
Table A3 and
Table A4, in
Appendix A) , while others did not even reach
. This was the reason we considered splitting up the dataset into two groups, one being formed only by what we may call the difficult datasets, for which the classification accuracy using SVM-L (best classifier in the previous work) was ≤90% using the original set of raw features. The list of difficult datasets (in
Table A2) is the following: (1)
Count 20 chips NO case x30 sorted; (2)
Count 20 chips WITH case x30 sorted; (3)
Count 20 papers x10; (4)
Distance 3 mugs 10 distances; (5)
Distance 3 mugs grouped by material; (6)
Flip 10 creditcards NO case; (7)
Identify 10 creditcards NO case; (8)
Identify 5 colors x 20 chips; (9)
Identify 6 users by palm; (10)
Identify 6 users by touch behavior sorted; (11)
Order 3 coasters NO case; (12) Order 3 creditcards NO case sorted; (13)
Order 4 creditcards NO case sorted.
For the other datasets, simple methods may have good accuracy results, with little room for improvement. The entire experimental framework was repeated considering only this (difficult) subgroup of datasets, and the results are as follows.
Table 7 shows the average accuracies and average ranks, obtained using only the difficult datasets. The average accuracy for SVM-L:OB is 78.199 and for SVM-L:t is 87.173. The average rank of SVM-L:OB is 23.115 and 6.654 for SVM-L:All.
Table 8 summarizes the results in
Table 7 for each feature set, averaging the results of RF, SVM-L and SVM-G. The best feature set is (t), with an average accuracy of 85.58% and an average rank of 10.987. The average accuracy is 77.922 and the rank is 23.090 for (OB).
Given again the large number of methods (Classifier:Feature Set) tested, they were divided depending on the type of classifier used: RF, SVM-L, and SVM-G. These average ranks (for the difficult datasets) are shown in
Table 9.
Figure 9 shows the critical difference diagrams for the Nemenyi test, for the three classifiers. The difference of the average ranks between RF:OB and the best feature sets with RF is greater than the critical difference. The distance of SVM-L:OB to the best feature sets with SVM-L is also greater. Nevertheless, the differences for SVM-G:OB and other feature sets with SVM-G are smaller than the critical difference.
Figure 10,
Figure 11 and
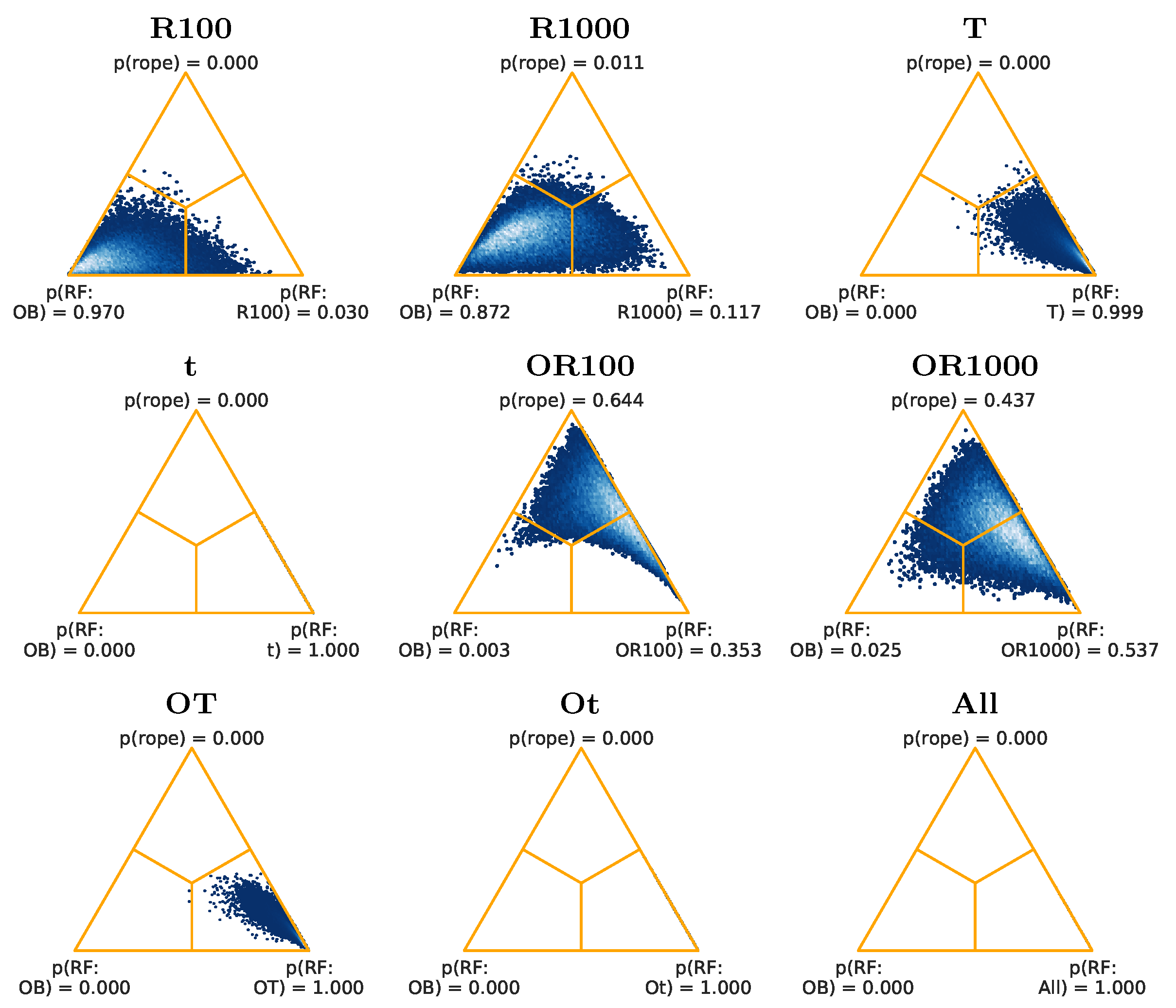
Figure 12 show the Bayesian Signed-Rank Tests posteriors, for the RF, SVM-L, and SVM-G classifiers, respectively, for the difficult datasets. In
Figure 10, for RF, the feature sets with more favorable results when compared to (OB) are (t), (OT), (Ot), and (All), with a probability of 1.000 for the corresponding feature set, and 0.000 for (OB). For SVM-L (
Figure 11), the best feature sets are, again, (t), (OT), (Ot), and (All), with a probability of 1.000 for the corresponding feature set, and 0.000 for (OB). In
Figure 12, for SVM-G, the results are best for (Ot), with a probability of 0.997, and a probability of 0.001 for (OB), followed by (All), with a probability of 0.983, and a probability of 0.000 for (OB), and by (t), with a probability of 0.989, and a probability of 0.002 for (OB).
4. Conclusions
This paper presents a comparative analysis of different types of classification methodologies, applied on a series of datasets of raw signals acquired by a portable radar sensor, for different types of materials. In particular, twelve different types of feature vectors obtained from the original raw dataset were obtained, applying different types of feature extraction strategies. These feature vectors were subsequently combined with two classification methods (Random forests and SVM with linear and radial kernel types). A stacked generalization (Stacking) approach was also considered which involved base classifiers created using Random Forest and SVM trained using a subset of the different sets of features. The classification results shown outperformed the corresponding ones obtained by Shyong Yeo et al. [
18], when considering the complete collection of datasets, as well as in a wider margin when using the partial so-called difficult datasets. In particular, the difference between the use of the TSFRESH with feature selection (t) features and the original and basic (OB) features (used in [
18]), for the complete group of datasets, is almost
in accuracy. Moreover, this difference increases to almost
, for (t) vs. (OB) as well, for the so-called difficult subgroup.
From a classifier performance point-of-view, SVM with linear kernel (with default options) has the best global results (the methods with best average accuracy and rank in
Table 4 and
Table 7 use SVM-L), being much less costly than SVM with Gaussian kernel (with parameter adjustment) and Stacking. This suggest that it is not necessary to use expensive methods when using adequate feature extraction methods.
Potential future lines of research include the creation of our own datasets to explore the use of the radar sensor in problems that may have an industrial interest, for instance, in non-destructive testing or in the signal analysis of trash composites, to discern or classify them.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











