
Multiscale Content-Independent Feature Fusion Network for Source Camera Identification


Abstract
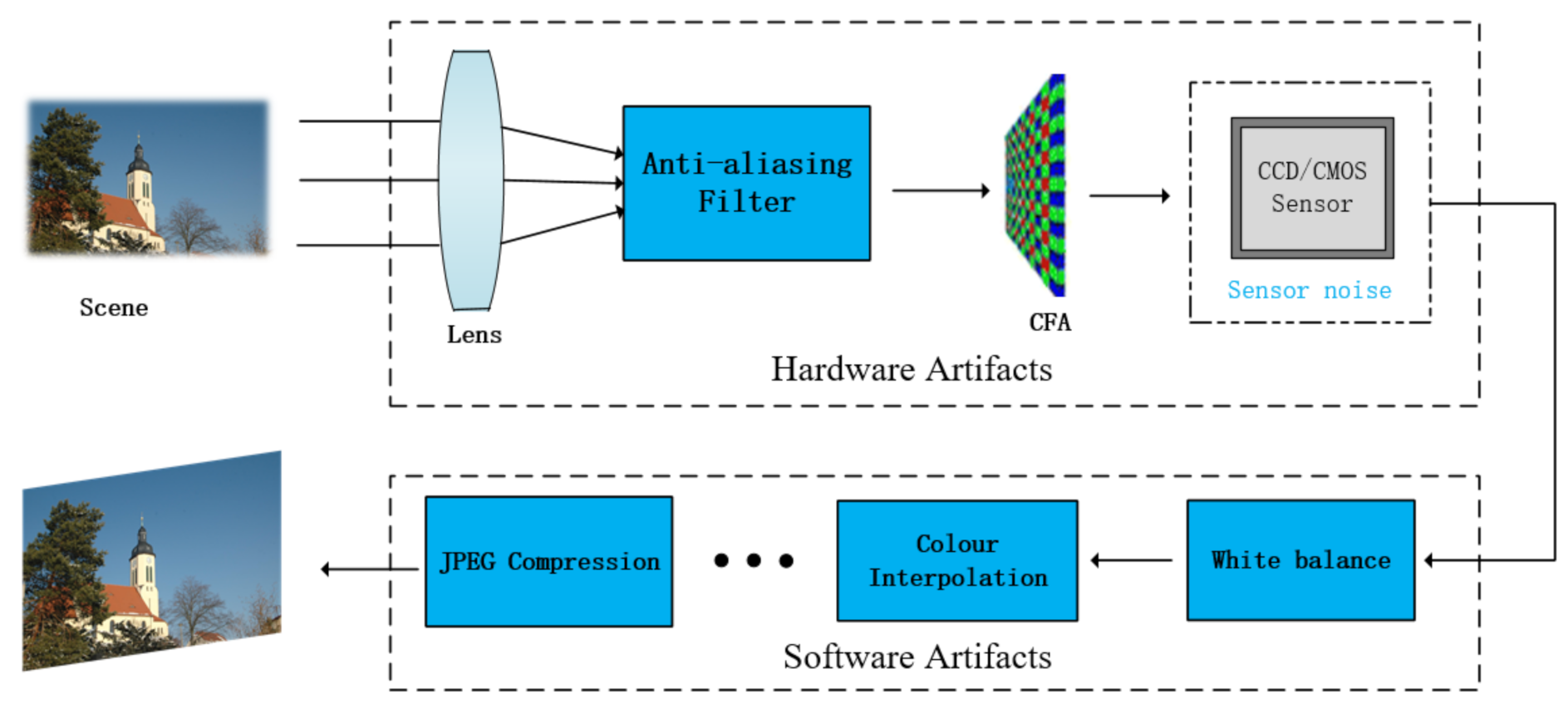
:1. Introduction
- 1.
- 2.
- 3.
2. Methodology
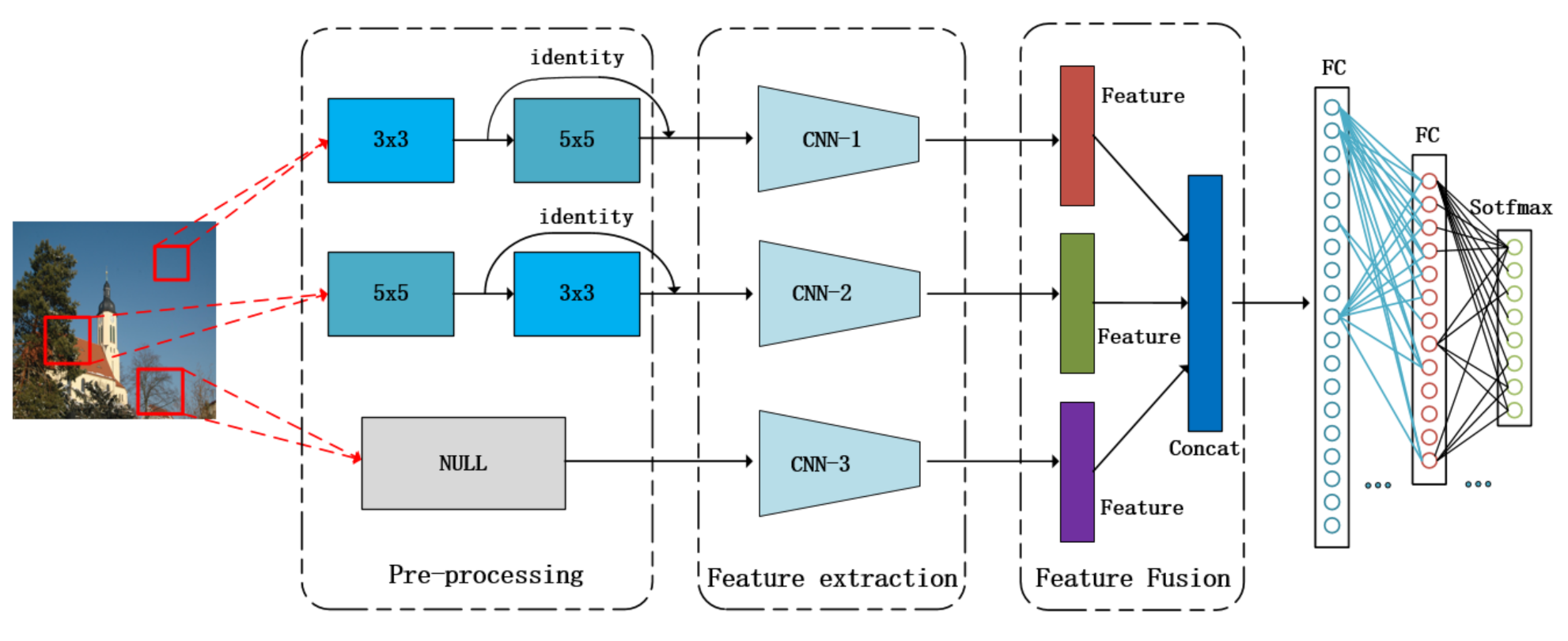
2.1. MCIFFN Structure
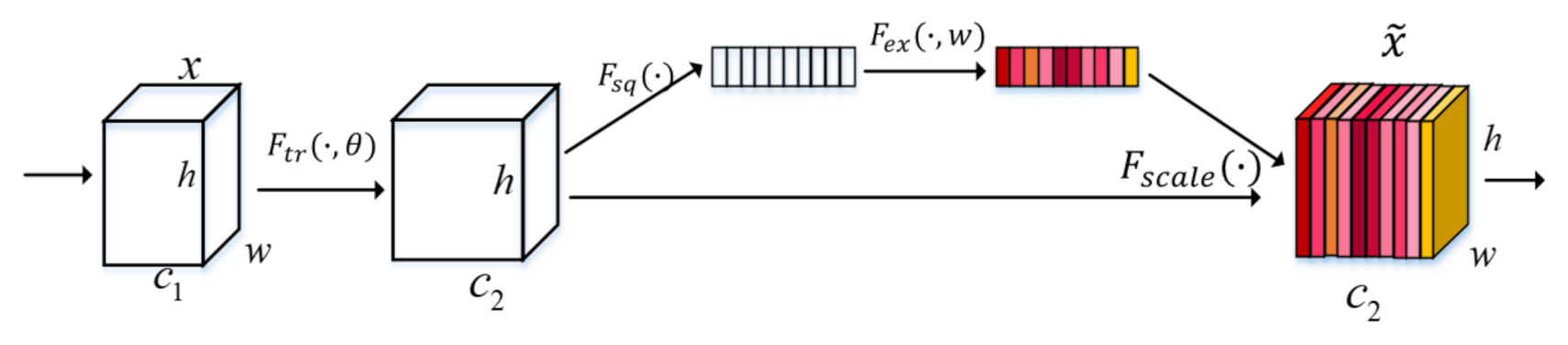
2.1.1. Squeeze and Excitation (SE)
- The first is the squeeze operation, which compresses the features along the spatial dimension, turning each two-dimensional feature channel into a real number that has a global receptive field to some extent. The output dimension matches the input feature channel number. It represents the global distribution of the response on the feature channel and makes the layer close to the input while also obtaining the global receptive field, which is very useful in many tasks.
- The second is the exception operation, which is similar to the gate mechanism in recurrent neural networks. A parameter W is used to generate weights for each feature channel, where the parameter W is learned to explicitly model the correlation between feature channels.
- The last is a reweight operation, which regards the weight of the output of exception as the importance of each feature channel after feature selection and then weighs the previous feature channel by channel through multiplication to complete the recalibration of the original feature on the channel dimension.
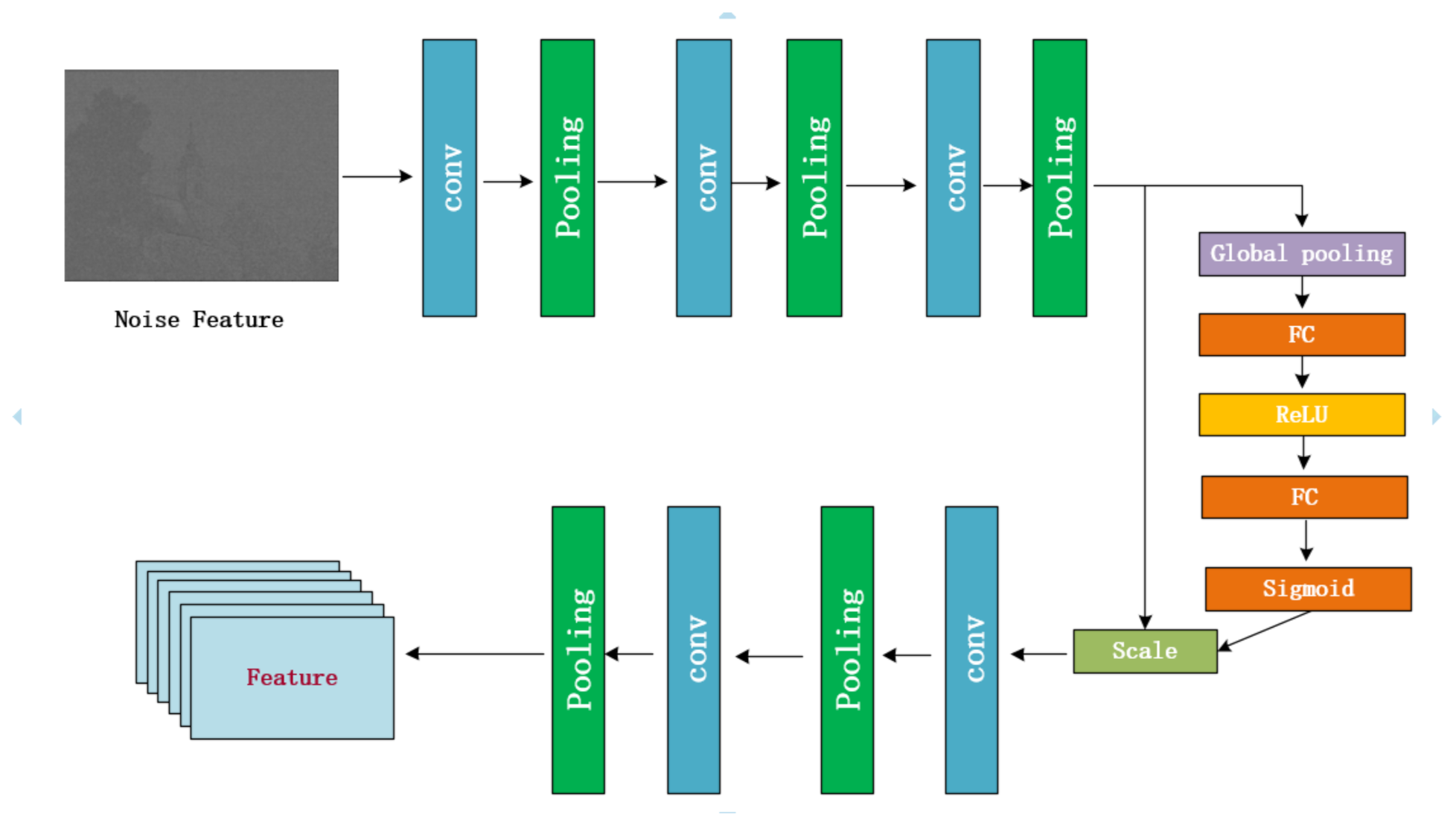
2.1.2. SE-SCINet in MCIFFN Structure
2.1.3. Multiscale Fusion Analysis
3. Experiment and Evaluation
3.1. Dataset
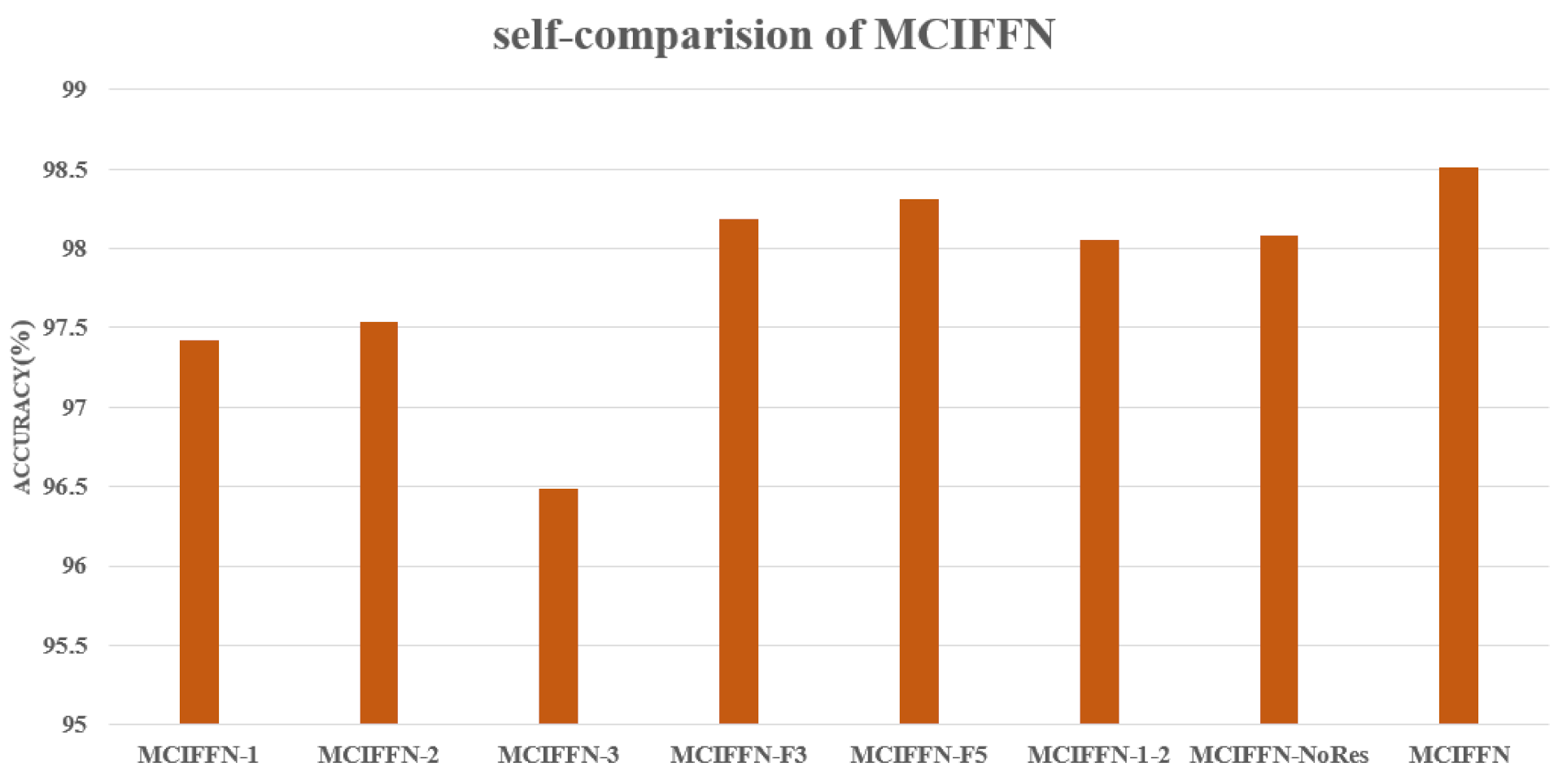
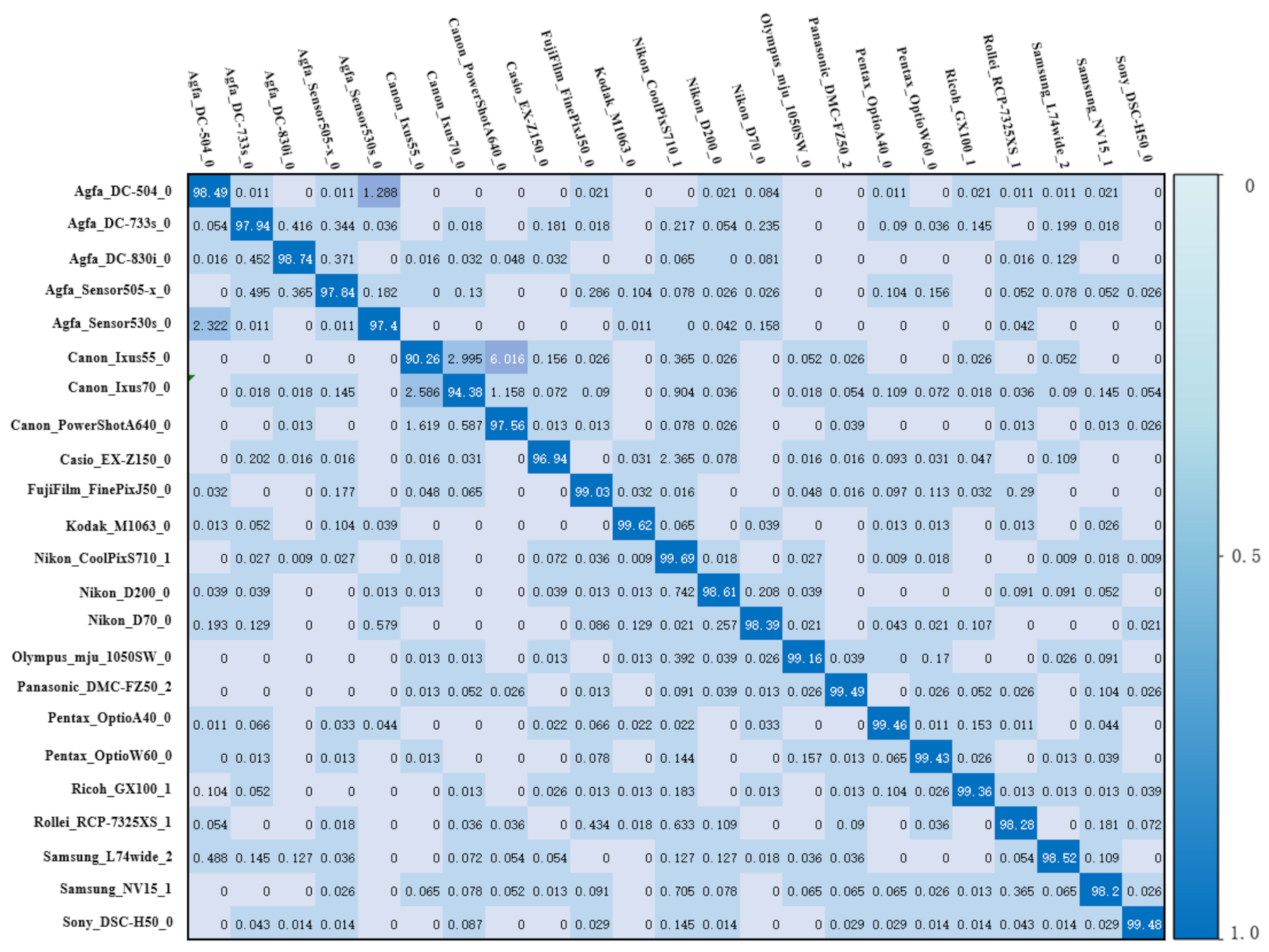
3.2. Performance of MCIFFN
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, B.B.; Swanson, M.D. When seeing isn’t believing [multimedia authentication technologies]. IEEE Signal Process. Mag. 2004, 21, 40–49. [Google Scholar] [CrossRef]
- Farid, H. Digital doctoring: How to tell the real from the fake. Significance 2006, 3, 162–166. [Google Scholar] [CrossRef]
- Choi, K.S.; Lam, E.Y.; Wong, K.K. Source camera identification using footprints from lens aberration. In Proceedings of the SPIE, San Jose, CA, USA, 9 October 2006. [Google Scholar]
- San Choi, K.; Lam, E.Y.; Wong, K.K. Feature selection in source camera identification. In Proceedings of the EEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; pp. 3176–3180. [Google Scholar]
- San Choi, K.; Lam, E.Y.; Wong, K.K. Automatic source camera identification using the intrinsic lens radial distortion. Opt. Express 2006, 14, 11551–11565. [Google Scholar] [CrossRef] [PubMed]
- Kharrazi, M.; Sencar, H.T.; Memon, N. Blind source camera identification. In Proceedings of the IEEE International Conference on Image Processing, Singapore, 24–27 October 2004; pp. 709–712. [Google Scholar]
- Xu, B.; Wang, X.; Zhou, X.; Xi, J.; Wang, S. Source camera identification from image texture features—ScienceDirect. Neurocomputing 2016, 207, 131–140. [Google Scholar] [CrossRef]
- Zhao, Y.; Zheng, N.; Qiao, T.; Xu, M. Source camera identification via low dimensional PRNU features. Multimed. Tools Appl. 2018, 78, 8247–8269. [Google Scholar] [CrossRef]
- Hwang, M.G.; Park, H.J.; Har, D.H. Determining digital image origin using sensor imperfections. Aust. J. Forensic Sci. 2014, 46, 98–110. [Google Scholar] [CrossRef]
- Lukas, J.; Fridrich, J.; Goljan, M. Source camera identification based on interpolation via lens distortion correction. Image Video Commun. Process. 2005, 2005, 249–260. [Google Scholar]
- Lukas, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Swaminathan, A.; Wu, M.; Liu, K.J.R. Nonintrusive component forensics of visual sensors using output images. IEEE Trans. Inf. Forensics Secur. 2007, 2, 91–106. [Google Scholar] [CrossRef] [Green Version]
- Choi, C.-H.; Choi, J.-H.; Lee, H.-K. CFA Pattern Identification of Digital Cameras Using Intermediate Value Counting. In Proceedings of the Thirteenth ACM Multimedia Workshop on Multimedia and Security, Buffalo, NY, USA, 13 September 2011. [Google Scholar]
- Swaminathan, A.; Wu, M.; Liu, K.J. Digital Image Forensics via Intrinsic Fingerprints. IEEE Trans. Inf. Forensics Secur. 2008, 3, 101–117. [Google Scholar] [CrossRef] [Green Version]
- Bondi, L.; Baroffio, L.; Güera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. First Steps Toward Camera Model Identification With Convolutional Neural Networks. IEEE Signal Process. Lett. 2017, 24, 259–263. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Ni, R.; Zhao, Y.; Zhao, W. Source Camera Identification Based On Content-Adaptive Fusion Network. Pattern Recognit. Lett. 2017, 119, 195–204. [Google Scholar] [CrossRef]
- Tuama, A.; Frédéric, C.; Chaumont, M. Camera Model Identification With The Use of Deep Convolutional Neural Networks. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Abu Dhabi, United Arab Emirates, 4–7 December 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. IEEE Comput. Soc. 2016, arXiv:1608.06993. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. IEEE Comput. Soc. 2013, arXiv:1311.2524. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Kai, Z.; Zuo, W.; Chen, Y. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2016, 26, 3142–3155. [Google Scholar]
- Xie, J.; Xu, L.; Chen, E. Image Denoising and Inpainting with Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NA, USA, 3–6 December 2012. [Google Scholar]
- Chowdhary, C.L.; Patel, P.V.; Kathrotia, K.J.; Attique, M.; Perumal, K.; Ijaz, M.F. Analytical Study of Hybrid Techniques for Image Encryption and Decryption. Sensors 2020, 18, 5162. [Google Scholar] [CrossRef]
- Bondi, L.; Baroffio, L.; Güera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. Camera identification with deep convolutional networks. arXiv 2016, arXiv:1603.01068. [Google Scholar]
- Freire-Obregón, D.; Narducci, F.; Barra, S.; Castrillón-Santana, M. Deep learning for source camera identification on mobile devices. Pattern Recognit. Lett. 2019, 126, 86–91. [Google Scholar] [CrossRef] [Green Version]
- Huang, N.; He, J.; Zhu, N.; Xuan, X.; Liu, G.; Chang, C. Identification of the source camera of images based on convolutional neural network. Digit. Investig. 2018, 26, 72–80. [Google Scholar] [CrossRef]
- Yao, H.; Qiao, T.; Xu, M.; Zheng, N. Robust multi-classifier for camera model identification based on convolution neural network. IEEE Access 2018, 6, 24973–24982. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Verdoliva, L. On the vulnerability of deep learning to adversarial attacks for camera model identification. Signal Process. Image Commun. 2018, 65, 240–248. [Google Scholar] [CrossRef]
- Kamal, U.; Rafi, A.M.; Hoque, R.; Das, S.; Abrar, A. Application of DenseNet in Camera Model Identification and Post-processing Detection. arXiv 2018, arXiv:1809.00576. [Google Scholar]
- Bayar, B.; Stamm, M.C. Augmented convolutional feature maps for robust cnn-based camera model identification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4098–4102. [Google Scholar]
- Zuo, Z. Camera Model Identification with Convolutional Neural Networks and Image Noise Pattern. 2018. Available online: http://hdl.handle.net/2142/100123 (accessed on 2 July 2018).
- Wang, B.; Yin, J.; Tan, S.; Li, Y.; Li, M. Source camera model identification based on convolutional neural networks with local binary patterns coding. Signal Process. Image Commun. 2018, 68, 162–168. [Google Scholar] [CrossRef]
- Bondi, L.; Güera, D.; Baroffio, L.; Bestagini, P.; Delp, E.J.; Tubaro, S. A Preliminary Study on Convolutional Neural Networks for Camera Model Identification. Electron. Imaging 2017, 7, 67–76. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Baracchi, D.; Ni, R.; Zhao, Y.; Argenti, F.; Piva, A. A Survey of Deep Learning-Based Source Image Forensics. J. Imaging 2020, 6, 9. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Bayar, B.; Stamm, M.C. Constrained Convolutional Neural Networks: A New Approach Towards General Purpose Image Manipulation Detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning Rich Features for Image Manipulation Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, P.; Ni, R.; Zhao, Y. Recapture image forensics based on Laplacian convolutional neural networks. In International Workshop on Digital Watermarking; Springer: Berlin, Germany, 2016; pp. 119–128. [Google Scholar]
- Gloe, T.; BóHme, R. The Dresden Image Database for Benchmarking Digital Image Forensics. J. Digit. Forensic Pract. 2010, 3, 150–159. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Number | Layer Type | Kernel Size | Filters | Stride | Pad |
|---|---|---|---|---|---|
| 1 | Convolution | 64 | 1 | 1 | |
| 2 | Max pooling | - | 1 | 0 | |
| 3 | Convolution | 32 | 1 | 1 | |
| 4 | Max pooling | - | 2 | 0 | |
| 5 | Convolution | 32 | 1 | 1 | |
| 6 | Max pooling | - | 2 | 0 | |
| 7 | Convolution | 64 | 1 | 1 | |
| 8 | Max pooling | - | 2 | 0 | |
| 9 | Convolution | 128 | 1 | 1 | |
| 10 | Max pooling | - | 2 | 0 | |
| 11 | fc | - | 128 | - | - |
| 12 | ReLu | - | - | - | - |
| 13 | fc | - | 23 | - | - |
| Method | AlexNet | MCIFFN-AlexNet | ResNet18 | MCIFFN-ResNet18 |
|---|---|---|---|---|
| accuracy (ACC) | 92.16 | 98.32 | 96.06 | 97.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, C.; Zheng, H.; Guo, Z.; Wang, T.; Wu, X. Multiscale Content-Independent Feature Fusion Network for Source Camera Identification. Appl. Sci. 2021, 11, 6752. https://doi.org/10.3390/app11156752
You C, Zheng H, Guo Z, Wang T, Wu X. Multiscale Content-Independent Feature Fusion Network for Source Camera Identification. Applied Sciences. 2021; 11(15):6752. https://doi.org/10.3390/app11156752
Chicago/Turabian StyleYou, Changhui, Hong Zheng, Zhongyuan Guo, Tianyu Wang, and Xiongbin Wu. 2021. "Multiscale Content-Independent Feature Fusion Network for Source Camera Identification" Applied Sciences 11, no. 15: 6752. https://doi.org/10.3390/app11156752
APA StyleYou, C., Zheng, H., Guo, Z., Wang, T., & Wu, X. (2021). Multiscale Content-Independent Feature Fusion Network for Source Camera Identification. Applied Sciences, 11(15), 6752. https://doi.org/10.3390/app11156752