1. Introduction
Obtaining a sustainable competitive advantage largely depends on the organization’s analytical skills, including the ability to analyze customers’ needs and demands [
1,
2]. Research has shown that organizations which rely on advanced data analysis perform much better than others, both financially and operationally [
3]. For several years, organizations have been gaining a new source of data for analysis, known as big data. Mikalef et al. [
4] show in a detailed manner how various resources and contextual factors lead to performance gains from big data analytics (BDA). However, organizations are still facing the problem of efficient analysis and understanding of this data. This is due to the features of big data, which are the most often described as the so-called 7V, i.e., Volume, Velocity, Variety, Veracity, Variability, Visualization, Value [
5]. In a modern fast-changing economy, the Velocity and Variability dimensions become particularly important—the features that cause the most problems in the analysis process are the speed of data inflow and their variability and thus the temporal dimension of big data. This dimension is interconnected with the fundamental assumption that time is an inseparable element influencing the phenomenon of big data and the process of analyzing this data. The temporal dimension manifests itself in three ways: as the fourth dimension of space-time, as the logical sequence of events (which are described by big data), and as a direct determinant of these events (cf. [
6]). The time dimension concerns both the phenomenon of data inflow and the reality reflected in these data, because the organization’s environment is changeable. The formal description of time and temporality is given, e.g., in [
7].
One of the most important volatile elements influencing the reality of an organization is the image of its customers. This image comes in the form of customer insights, defined as the profound “knowledge about customers” [
8] that is knowledge about their needs, expectations, and opinions which drives organizations’ innovative efforts and business processes [
9] (cf.
Section 2.1). Extracting value from customer insights is identified as a pronounced challenge for organizations which becomes even greater when these insights are searched for in the vast area of big data [
10,
11]. To effectively analyze big data about customers, organizations must therefore adapt to their dynamics. Only in this way will they obtain current and valuable knowledge about trends and market expectations [
11]. Such advanced analysis of clients is the way to acquire, maintain, engage, and satisfy them in an effective manner [
11,
12]. Customer analytics is strictly related to time and dynamics as it brings behavioral insights about customers by finding hidden patterns in (big) data. Hence, big data consumer analytics may be defined as “the extraction of hidden insights about consumer behavior from big data and the exploitation of that insight through advantageous interpretation” [
13]. The dynamic characteristics of customers’ opinions, expectations and behavior are already subject of research [
12,
14], but the temporal dimension of customer data is not addressed directly. As Jukić et al. [
15] point out, big data needs to be analyzed in a time-sensitive manner. This applies also to customer big data. If customer behavior and opinions were tracked as they change in time, the company would be more customer-oriented, which is the vital step on the road to market success. Our previous research [
16] also revealed the need for explicit incorporation of time aspect into big data analytics.
Processing and analyzing big customer data are possible thanks to the use of big data analytics tools. BDA, which has transformed the world of business management, has been dubbed a “game-changer” [
17]. BDA is defined in the literature as “methodologies used to interpret and obtain information from big data-helps”. To drive future decisions, big data analytics leverages various databases from a heterogeneous range of related media and metadata [
18]. Organizations, including enterprises, to function properly and in the long term, should advance and implement goals (under constant and dynamic establishment), both short-term and long-term. BDA is seen as the “enabler of dynamic capabilities” [
19]. Grasping the processes taking place in the organization, of which the evolution of big data analytics is a part, is therefore the foundation for effective counteracting failures in achieving the goals of the organization for its further growth. The organization, being in constant and effective development, can better use BDA and thus more efficiently understand and research the needs of consumers.
The main purpose of this article is to provide a theoretically grounded discussion on big data analytics for customer insights and to identify and describe a research gap due to the lack of temporal big data mining methods and tools. The main contributions of this paper are:
To organize knowledge on the role of advanced big data analytics in understanding client behavior;
To indicate the importance of the temporal dimension of customer behavior;
To identify an interesting research gap: mining of temporal big data for a complete picture of clients.
These contributions are due to analyzing the existing research achievements promulgated in the domains of big data analytics and of customer analytics. Based on this analysis, we identify the current state of big data analytics for customer insights, and the challenges to address the time dimension of customer behavior while mining big data.
The literature search has employed various bibliographic databases: Scopus, Thomson Reuters Web of Science, ProQuest, and EBSCOhost, as well as open access papers. The research has been conducted in four steps: search, selection, analysis, and synthesis as proposed in [
20]. The results presented in the paper have been verified against the Scopus database. The results obtained in this paper may be further utilized by scholars and researchers looking for an engrossing new possible area of investigation and by business practitioners searching for new approaches to customer analytics.
The rest of the paper is organized as follows:
Section 2 provides a profound theoretical outline for the notions of customer insights and big data. In
Section 3 the types of customer insights from big data are discussed in the context of their role in organizations.
Section 4 is devoted to the identified challenges in big data mining which leads to the identification of a research gap. In
Section 5, the identified research gap is verified against the Scopus database. In
Section 6, the discussion of results against existing literature is provided.
Section 7 summarizes and concludes the research findings.
3. Types of Customer Insights from Big Data and Their Role in Organizations
Big data-enabled societies—particularly based on the foundations of the digital economy—are capable of opening new perspectives for organizations striving to get to know their customers better [
86]. The enormous volumes of data deriving from a variety of sources allow to analyze greater number of dimensions depicting customers, than before. This is mostly due to the new sources of data origin, as e.g., social media. Thanks to the characteristics of big data, it offers gargantuan possibilities for gaining new insights [
87,
88]. These new insights are not narrowed to customer-centric decision-making processes but affect the whole operating space of an organization. In simplification, the insights from big data—if properly used—may contribute to value generation, as well as to innovations, and to the competitive advantage [
89,
90]. Specifically, big data analytics is considered together with data mining issues [
91]. For example, Xindong Wu et al. [
92] propose a big data processing model from the data mining perspective. They point out that mining big data is data-driven and demand-driven. This context of data mining is present in many big data analytics definitions. In the paper by Mohsenian-Rad et al. [
93], this type of analytics is described as the process of uncovering hidden patterns, unknown correlations, irregularities, and other data-driven intelligence. Data mining related to big data analytics’ tasks also encompasses text mining (for sentiment analysis) and social media analytics (for community detection or social influence analysis) [
60]. Especially the latter may be of paramount importance in modern dynamic operational environments, due to empowerment of organizations to perform the so-called situational data analytics instead of—or at least together with—classic static data analytics of transactional or enterprise data [
94].
In the context of customer insights, there are several application areas of big data analytics which can be found in the literature. These include inter alia:
Market basket analysis [
76,
98];
Customer intelligence [
76];
Public transportation management [
102];
Telecommunications [
78,
104];
Policymaking, public governance, and administration performance [
106];
Customer relationships management [
75,
107,
108].
In these application areas of big data analytics, several types of customer insights seem to dominate:
Customer needs;
Customer satisfaction and experience, sentiment analysis and opinion mining;
Customer profiles;
Customer churn, retention, and loyalty;
Customer behavior.
The use of big data analytics in acquiring customer insights is evidenced in many scientific studies confirmed by the successes of enterprises in the field of customer relationship management. Foremost, it should be noted that currently the largest corporations, such as Facebook, Amazon, Netflix, or Google, successfully use algorithms based on big data analysis in their business models in order to obtain “digital advantage” [
109]. The case study conducted by Wang and Hajli [
110] showed that the use of BDA (along with the “V” axes of big data: volume, variety, velocity [
111,
112]) in health sector organizations can obtain insightful business value, which led to their entrepreneurial triumph. The use of big data analytics is also used in the US Immigration and Customs Office to ensure the safety of citizens, immigrants, and travelers, as well as to counter terrorism [
113]. The commercial successes include, first of all [
113]:
A successful revolution in big data analysis in social networks such as Facebook and Twitter, translating into greater data personalization and understanding of customers, which strengthened the position of these companies on the market;
The use of customer insights and their transformation by BDA tools (using mobile network data) enabled a greater degree of profiling in the Sprint mobile network;
Personalization with big data (which is the result of “listening” to customers) has also found successful application at the Bank of Scotland and Netflix;
Big data for customer insights is also used for family and entertainment industries such as theme parks (Walt Disney Parks and Resorts), mobile gaming (Zynga), and casinos (Caesars).
Customer needs, as pointed out by Olszak and Zurada [
90], play crucial role in acquiring competitive advantage by an organization. If properly captured and understood, they allow for new business opportunities. The big data analytics is one of the ways to achieve these goals and to create business value [
114,
115]. Customer needs may be examined by analyzing customer complaints, opinions, and sentiments [
95] or by experimenting with customer data. In fact, there are five dimensions distinguished for creating business value from big data, and experimentations are one of them. Other dimensions are creation of transparency, segmentation of populations, replacement, or support of decision-making with algorithms and innovations concerning business models, products, and services [
20,
116]. Customer needs in the form of patterns excavated from big data are also indispensable for product customization which is becoming a dominant trend in today manufacturing [
117]. Deepened knowledge on customer needs may be transfigured into product or services innovations, which may result in increased customer satisfaction. To stay informed on the satisfaction level of consumers, an organization needs to perform sentiment analysis and opinion mining on a daily basis. These adhibitions, along with trend discovery, are described as the most applied in big data analytics [
99]. Big data sources—such as, e.g., opinion portals, organizations’ Facebook professional pages, forums, blogs, etc.—provide an immense amount of data and information on consumers’ reviews, opinions, wishes, complaints, and other satisfaction-related issues. With the utilization of big data, organizations may assess customer satisfaction levels in (almost) real time to adjust operations as needed [
95]. As research has proven, big data analytics can explain 62.4% of the variance of customer satisfaction [
118]. Measuring satisfaction levels, together with marketing reports, sales data, customer opinions and other allows to monitor organization’s performance on the market [
119]. Customers’ sentiments may be explored in a continuous way using time-varying data and dedicated ICT tools [
120], thus enabling organizations to capture market trends [
121]. Hence, sentiment analysis and opinion mining are closely related to the issues of streaming analytics which is discussed below.
Customers’ opinions, sentiments, interests and needs when accompanied with socio-demographic, financial, and other types of data empower organizations to create customer profiles. These are used for brand management [
122], marketing operations [
123,
124,
125], churn prediction [
126,
127], and many others. In e-commerce, and more generally in the retail area, customer profiles are discovered from transactional data [
95,
116,
128], from the CRM data [
107], or from Internet data, especially the social networks [
20,
129]. The social media analytics constitutes a remarkable kind of big data analytics for customer insights and will be considered in more detail below. Big data analysis of customer experiences (CX) based on various sources of data origin during the customer journey on the website may allow for the interpretation of obtained analyzes that were conducted as customer insights [
130]. The use of big data analytical tools in the field of social media contributes to the enhancement of the organization’s marketing by creating instruments for personalizing recommendations [
100]. This can be done through the pattern detections (which is one of the main aspects of data mining [
131]) and may turn to be useful when generating positive insights. There are also broader attempts to analyze big data for customer intelligence [
76].
The customer churn and customer retention and loyalty are amongst the most used big data analytics applications, together with market basket analysis, customer intelligence, retention modeling, and social media analytics [
76]. As claimed in [
132], analytics directed towards new data sources—e.g., social networks, clickstreams, CRM, emotions, opinions, audio and video conversations, images etc.—allows not only churn prediction but also insights on prevention manners and what incentives to use. It has also been proven that using big data analytical tools, such as Hadoop (with Datameer extension), with prior collection of consumer data (i.e., archive, network, mobile), can not only significantly contribute to creating a customer churn prediction model but also understanding the client retirement path [
133]. More generally, contemporary big data analytics is successfully used to conduct research on customer loyalty and customer retention. Chiefly in industries under constant and dynamic development, as e.g., telecommunications, big data analytics is not only aimed at attracting new customers. It primarily focuses on retaining the “old” (current) ones through analyzing the behaviors characterized by the way telecommunications services are used [
134]. In particular, big data techniques enable profound analysis of socio-demographic, psychographic, and behavioral features [
107]. Insights on customer behaviors are nowadays strictly related with streaming analytics, social media analytics, and pattern mining.
The aims of customer behaviors’ analytics can be generally divided into detection of behavioral patterns and prediction of behaviors [
135]. The former allows for a better understanding (description) of customers, while the latter, for an adjustment of enterprise’s actions towards actual and potential customers. Obviously both aims are interrelated.
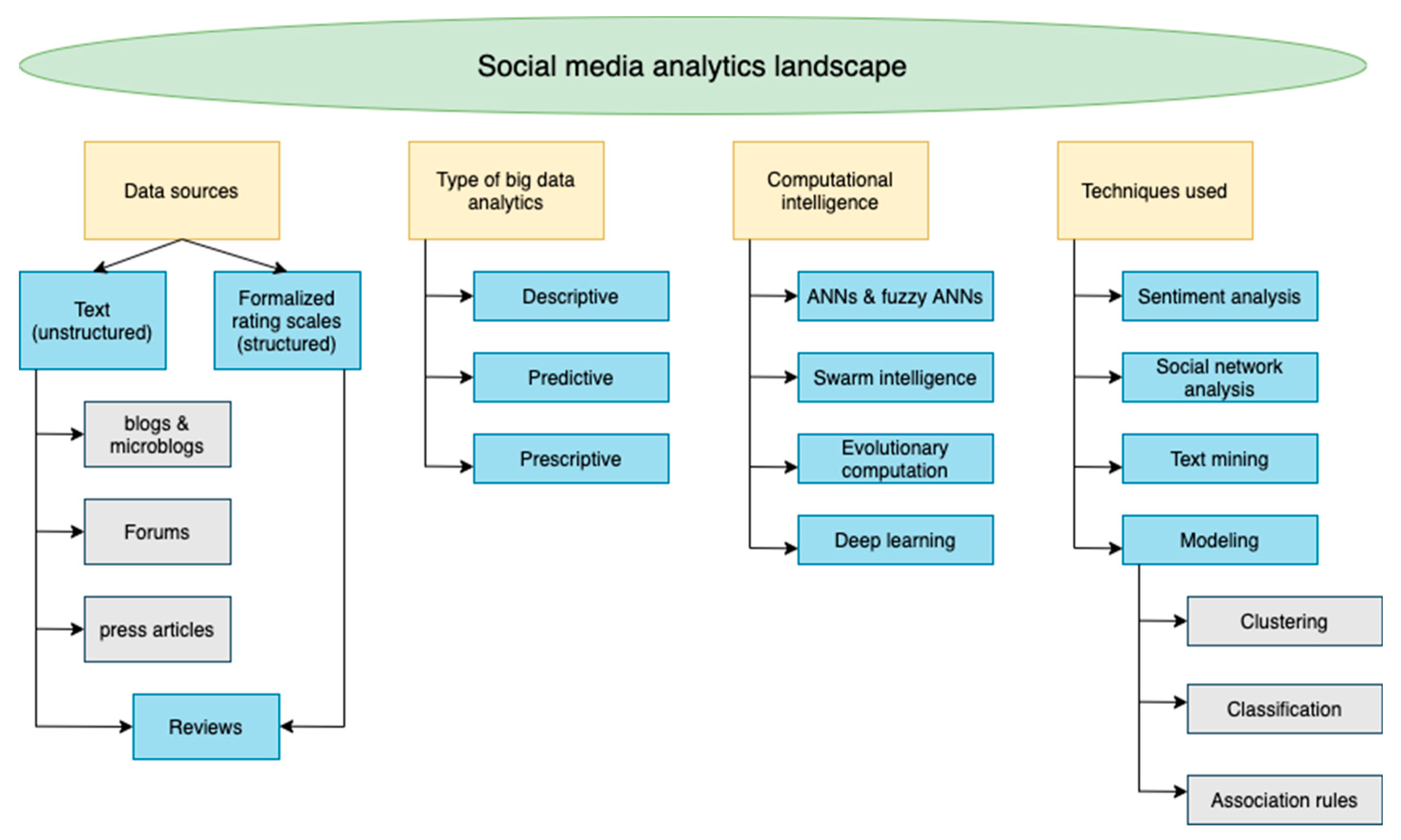
Social media analytics arises as an important part of marketing insights because of an increasing role of sentiment and recommendations [
95]. When used in various fields of marketing, business, or politics, it allows to constantly collect, monitor, and naturally analyze user’s behavior or his/her sentiments while continuously inspecting user-generated content [
136]. Sentiments show consumers’ reactions to enterprises’ offers and marketing activities. Moreover, social media analytics may reveal how information streams between consumers and how the network is formatted [
120,
137]. Big data approach to social media may reveal consumers’ communities and directions of social influence [
60]. Insights on customers’ social media activities, connections, interactions with the firm, and emotions are used to explore retention models [
93,
132]. To prevent churn, firms may propose diversified offers to customers as well as diversified marketing content in various social media channels [
108]. The summary of social media analytics to understand customers is presented in
Figure 1, with various big data analytical activities on SM.
Customer behavior may be observed and analyzed not only on social media, but also by tracing information from customer touchpoints with the firm. Broadly, data may come from service providers (e.g., business transaction, human resource, and financial data) or customers (e.g., demographic, behavioral, and purchase history data) [
108]. Data may also originate from location services and interconnected technologies, like GPS [
138]. With the use of big data analytics accompanied by these sources it is possible to detect customers’ patterns. These patterns may concern buying habits, searching activities, site usage, movement behaviors, and may others which allow for almost real-time monitoring of consumers [
128,
139]. If they are extracted with intelligent algorithms, they are called smart data [
140], which come in handy to proper data interpretation and data provenance provision [
141]. Regardless of the name, the predominant issue in such analyzes is to explicitly link patterns and behaviors to the dimension of time. This is because social networks, behaviors, patterns are all dynamic constructs. For example, in virtue of big data analytical tools, it is possible to measure the flow of information in a social network (SN) at scale and over time [
137] to monitor consumers’ reactions and responses. As Lazer et al. [
87] point out, big data offers mountainous possibilities for analyzing temporal dynamics of various phenomena. Some research is whence devoted to streaming analytics directed towards click-stream data with the aid of dedicated tools as SAP Hana, Storm, and S4 [
142]. Click-stream data together with web server log files and user information enable to reveal consumer’s behavior as a sequence of events [
143]. An example is given in
Figure 2.
The user behavior, as depicted in
Figure 2, can be understood as a sequence of events, each of which may have a different duration. For example, event 3 is longer than events 1, 2, and 4. The time dimension then allows to order and analyze events. Not surprisingly then, some authors started using temporal formalisms to give form and to reason about consumer behavior. In such formal frames time is the dimension brought to the forefront. A thought-provoking research domain has been presented in [
144] named stream reasoning. This notion is defined as a combination of stream processing and reasoning. Stream reasoning requires a real-time processing of events. This kind of research has been presented in [
77]. The so-called complex event processing (CEP) is directed at combining big data analytics with real-time processing. The events are processed as triggers or as situation delimiters (i.e., detection of situations via sequences of events). The natural consequence of the need to temporally process events is to use some temporal logics. The most used is event calculus introduced by Kowalski and Sergot [
145,
146]. Other logics are also in use, such as linear temporal logic (LTL) [
96], and thus, the situation calculus may also be considered [
147]. This list of temporal formalisms helpful in event/stream processing is of course much wider, but this question is beyond the scope of this paper. Summing up, properly selected temporal logics are very useful in capturing users’ behaviors and behavioral patterns.
A summary of customer insights with big data analytics may be seen in
Figure 3.
Although
Figure 3 is directed towards the framework of marketing mix, it shows what sources of customer insights can be considered, which methods, and for which applications. The methods are narrowed to data mining ones (cf.
Section 4), and no temporal methods are shown. This is because temporal reasoning and temporal big data mining are still an unexplored field of research.
There is a multitude of challenges ahead of extracting value from customer insights. They also find their source in the challenges faced by big data in general, such as security and privacy issues, potential waste of resources, or regulatory and compliance problems [
148]. Analytical approaches in big data, such as big data mining (BDM), prove to be helpful, due to the speed of operation and automation of the mining process, but to achieve the success of the enterprise, it is crucial to collate threats, opportunities, and challenges to choose the best development strategy. Chapter 4 outlines the challenges of gaining value from customer insights using BDM, which may be useful from a managerial point of view of the company but also constitute horizons for development for academia.
4. Challenges in Big Data Mining for Customer Insights
Generating insights from big data is a process consisting of two main activities—data management and data analytics. The former encompasses data acquisition, extraction, cleaning, integration, and representation. The latter consists of data modeling, analysis, and interpretation [
60]. Data mining techniques are among the most used ones in big data analytics. Hence, it can be assumed that challenges in BDA concern also big data mining, even if not expressed explicitly. In a very general way, the first and foremost challenge of big data analytics is to generate business value [
95]. It is also one of the ultimate goals of BDA and big data mining. The other ones are also provision of competitive advantage [
5,
11], and generation of new business ideas from big data insights [
89]. Obviously, the quality of insights results from a proper orchestration of big data-related resources, that is, data, technology, processes, and people within the framework of organization [
4]. Human skills and organizational culture are as important as the technological dimensions of BDA in providing valuable results for the success of organization [
89,
149]. The overall success of big data analytics is therefore dependent on such factors as top management support, organizational change, technical infrastructure, the data science skillset, data availability and quality, data security, and privacy [
150]. Conceptually, the overall big data challenges can be summarized as presented in
Figure 4.
In the big data lifecycle, the first group of challenges concerns the characteristics of big data itself (the “Vs”) which in turn affect the issues of big data preprocessing, e.g., integration, cleansing, and transformation. At the data processing stage, the typical tasks of analysis, modeling, mining, etc. must be adjusted to properly address the challenges of the first stage. Moreover, at the stage of presenting the results, the graphical methods must be able to cope with visualizing a huge amount of big data analysis results. The big data management stage extends over all other stages and is associated with challenges such as privacy, security, data ownership, and other ethical issues [
76,
152,
153,
154,
155]. Among the features determining data, information, and insights quality the completeness, accuracy, and currency are mentioned to be the most significant [
156]. Especially, the last feature is a challenge when applied to big data analysis and mining. Not only the data comes as a stream or flow (the velocity dimension of big data), but also, it must be analyzed/mined in real-time manner to provide value to organizations. We will cover this temporal challenge later.
With data mining as one of the most important elements of big data analytics, it is not surprising that the DM software is one of the most appreciated tools among various analytical tools used for BDA [
157]. However, even the best software will not produce valuable results from garbage data. Hence, among big data mining challenges, the first group includes data inconsistence and incompleteness, scalability, timeliness, and data security. Challenges also concern data capture, storage, searching, sharing, analysis, and visualization [
158]. There is a common agreement that before mining the data it is mandatory to consider such issues as validity and reliability of data. The bigger the data quantity is, the bigger the challenge. With the amount of data, discovering dependencies and valuable patterns becomes extremely difficult [
87,
118]. The next group of challenges is associated with the mining process itself. The algorithms and techniques used for “classic” data mining in, e.g., data warehouses sometimes are not suited to be used with huge amounts of constantly incoming big data. This is so because traditional data mining approaches start with a centralized data repository, able to store and process data. With the prodigious size and variety characterizing big data, such centralized approach may not be used. There is a strong need of more distributed approaches capable of mining huge amounts of unstructured data [
159]. Some other challenges include, e.g., lack of large-scale data representation (for mining purposes), lack of effective and efficient online large-scale machine learning techniques, and lack of data confidentiality mechanism [
77]. Challenges concern mining algorithms which must deal with sparse, uncertain, incomplete, complex, and dynamic data [
92]. Moreover, the constant inflow of data to be mined can be recognized a momentous challenge, as many mining algorithms do not provide proper sequences or patterns [
143]. Some of the proposals to overcome this obstacle include, e.g., incremental pattern mining and cluster analysis, when the discovered patterns and clusters are incrementally augmented with updated information [
160], post-processing enhancements of mined patterns [
138], and special spatio-temporal representations of data for further mining [
77]. Therefore, these stages, such as data cleaning, integration, ranking, and querying, are often considered as the sources of “algorithmic bias” [
161,
162]. Reasoning about them as well as attenuating inequity upstream from the final data analysis phase is potentially more impactful [
162].
However, it becomes obvious that for valuable insights from big data mining it is essential to consider temporal-related issues. As Xindong Wu et al. [
92] point out, in a dynamic world, data and information representing interesting features from the environment of an enterprise enlargement. Hence, while mining useful patterns from big data, it is indispensable to consider these evolving changes. However, it seems symptomatic that a miniature number of big data analytics definitions even mention the question of dynamics. For example, Mikalef et al. [
5] while presenting sample definitions of BDA consider only two ones addressing the dynamic dimension of BDA. A challenge in big data mining hence arises—how to deal with dynamic/temporal aspects of the realm described by big data. One of the ways to do it is to implement agile big data analytics. BDA is seen as a ‘bridging’ instrument in development of software applications using agile methods [
79]. Agility is achieved by creating a data infrastructure enabling identification and evaluation of various big data sources [
11]. Afterwards, there are approaches focused on big data stream processing enabling a flexible mining solution [
159]. However, these solutions are insufficient when it comes to real-time data processing [
117]. The real-time big data analytics presents another challenge related to big data mining which must be considered [
76]. Many of the phenomena of interest to the organization are represented as time series [
163], this applies to, e.g., sentiment analysis or user’s website activities. However, many other phenomena are too intricate to be represented this way. Knowledge coming from organization’s environment evolves very quickly because of a constant inflow of data and information. The big data mining in real time may ameliorate decision-making processes in organizations because it would enable dealing with real-time uncertainties [
88,
120]. The time dimension of big data is reflected in the speed of their inflow. This causes big data to be transient which implies the need to mine them as and when they are generated [
139]. The timeliness of data analysis and mining is the succeeding challenge, tightly linked with the challenge of dealing with temporal dimension of big data. This timeliness challenge is discussed in [
158] in more detail.
The most intuitive way to deal with temporal aspects of big data mining is to treat the data inflow as a set of events. This is quite natural because events are the building blocks of surroundings of organizations; hence, they need to be represented and mined during big data analytics. The big data mining process should be therefore focused on events implied from the massive volume of data. It is thus clear that big data mining is closely related to events [
164]. The consecutive big data mining challenges may be formulated as the challenge of event capturing and representation for further analytics, the challenge of constructing temporal big data mining algorithms, and the challenge of representing temporal features of the mined knowledge. The events and temporal information in big data should be identified; the temporal relations among events should be found and represented; event-based information retrieval and analytics should be done. Zhang et al. [
77] proposed a big data temporal analytics solution but only for texts, while leaving apart many other forms of data leading to the big data variety feature.
Another approach to temporal big data has been proposed in the work of Singh et al. [
160] where the frequent patterns mining and cluster analysis model are used on constantly incoming data. The model encompasses a progressive and incremental update of mined patterns and clusters with new information, and newly discovered patterns and clusters are incrementally added to the existing ones. However, events are not addressed in this approach, and there is lack of temporal representation. In fact, the model is concentrated on time series instead of event sequences. An answer to the challenge of temporal BD mining has been proposed in [
77,
144]. Both approaches consider Complex Event Processing (CEP) systems as a solution. CEP systems are particularly useful for real-time analytics and stream reasoning. These solutions differ in time representation. Some of them are based on point structures, while others are based on intervals (cf. [
6]). The CEP systems also differ in their complexity and in orientation: computation-oriented vs. detection-oriented ones [
77]. A variation of event processing systems has been proposed in [
159], namely, Semantic Complex Event Processing augmented with an agent that dynamically builds an ontology which can then be queried temporally. However, even the mining systems based on event processing are yet not capable of mining causality relations [
143] which would contain a lot of useful information on complex phenomena in organization’s environment.
Another group of approaches to analyzing streaming and/or temporal big data is built upon the so-called ontology-based data access (OBDA). OBDA origins from the Semantic Web analytics, and its core feature lies in separating conceptual and database levels of data [
94]. Unfortunately, OBDA itself does not adapt to changes in data sources. The W3C standardized an ontology and a query language for the ODBA: OWL2QL and SPARQL [
165], but these solutions do not handle essentially temporal big data. Incorporating complex temporal information into OBDA together with the ability to process heterogeneous data poses a serious challenge [
166]. A temporal OBDA is then requisite. There are various ways to the development of such a temporal version of OBDA:
Extending OWL2QL with various temporal operators [
167];
Extending both OWL2QL and SPARQL with the LTL (linear temporal logic) temporal operators [
168,
169];
Extending OWL2QL and SPARQL with the MTL (metric temporal logic) temporal operators [
165];
Extending OWL2QL and SPARQL with the interval logic by Halpern and Shoham [
170];
Developing fully temporal OBDA [
170].
The advantage of all the above solutions lies in the direct incorporation of time dimension into analytics. On the other hand, the main disadvantage and weakness in the context of big data mining concern the nature of data and analytics. All the above solutions are directed towards relational/structured data and queries and do not deal with any data mining tasks. Hence, they cannot be considered satisfactory for temporal big data mining. The challenge which then is seen concerns augmenting the existing big data mining models, methods, and algorithms with explicit temporal expressions and with ways to handle them to mine temporal big data.
Summing up, our study identifies several challenges for big data mining, especially in the context of customer insights. These are:
Completeness, accuracy, and currency of discovered insights/patterns,
Quality of data to be mined,
Issues concerning big data storing/processing,
Modification of mining algorithms and techniques to deal with abundant, heterogeneous, and streaming data,
Dealing with evolving changes,
Dealing with dynamics/velocity of big data,
Flexibility of mining algorithms and techniques,
Representing and processing big data as events and event sequences.
All these challenges constitute important and promising research areas, but as shown, the most important and challenging issue concerns incorporating explicit time notion into representation and mining procedures of big data. There is a strong need to express temporal dimension of big data and in big data itself, using more complex temporal representations than event calculus. There is a need to represent causality of phenomena, of discovering changes in phenomena depicted by big data, and of mining useful temporal patterns to get deep and profound insights on the way the world around organizations evolves.
We have focused on the challenges associated with big data mining which is a specific subarea of BDA. Obviously, the broader BDA field also faces several challenges. These are primarily challenges with big data’s volume characteristics. The large sample size may result in several biases as, e.g., sampling error, measurement error, aggregation error, etc. [
171]. Especially the sampling error may result in highly biased data. Researchers have shown examples of such biased data collected from social networks. While gathering this data, it may be erroneously assumed that social media users are representative of the population [
172] while there are many social groups excluded from using the SM, e.g., people digitally excluded—due to age, education, low socioeconomic status may not be represented in the retrieved big data sample [
172,
173,
174]. A noticeable bias in big data may also result from gender and race issues [
175,
176,
177]. All these challenges should be kept in mind while addressing the question of big data analytics; however, they are beyond the scope of this paper.
5. Verification of Research Findings
To verify the identified challenges and gaps concerning big data mining for customers insights, the Scopus database has been consulted. Three key phrases resulting from the challenges identified in
Section 5 have been searched: (1) “big data mining”, (2) “temporal big data”, and (3) “temporal big data mining”. In all the three cases, Scopus has been queried within article titles, abstracts, and keywords. The searches have not been restricted in any way. The search activities took place on 10th May 2021. Moreover, in order toto extend the scope of the study, the broader term “big data analytics” (parent to the aforementioned challenges) has been also analyzed. The analysis took place on 16–17 July 2021. In conjunction with the fact that the “big data analysis” notion overrides “big data mining”, the Scopus inspection of “big data analysis” term in this paper is presented prior to the remaining phrases. The summary data that was generated by the Scopus database and used for further analysis can be found in the
Supplementary File, which is described in the
Appendix A.
5.1. “Big Data Analytics” Phrase in Literature
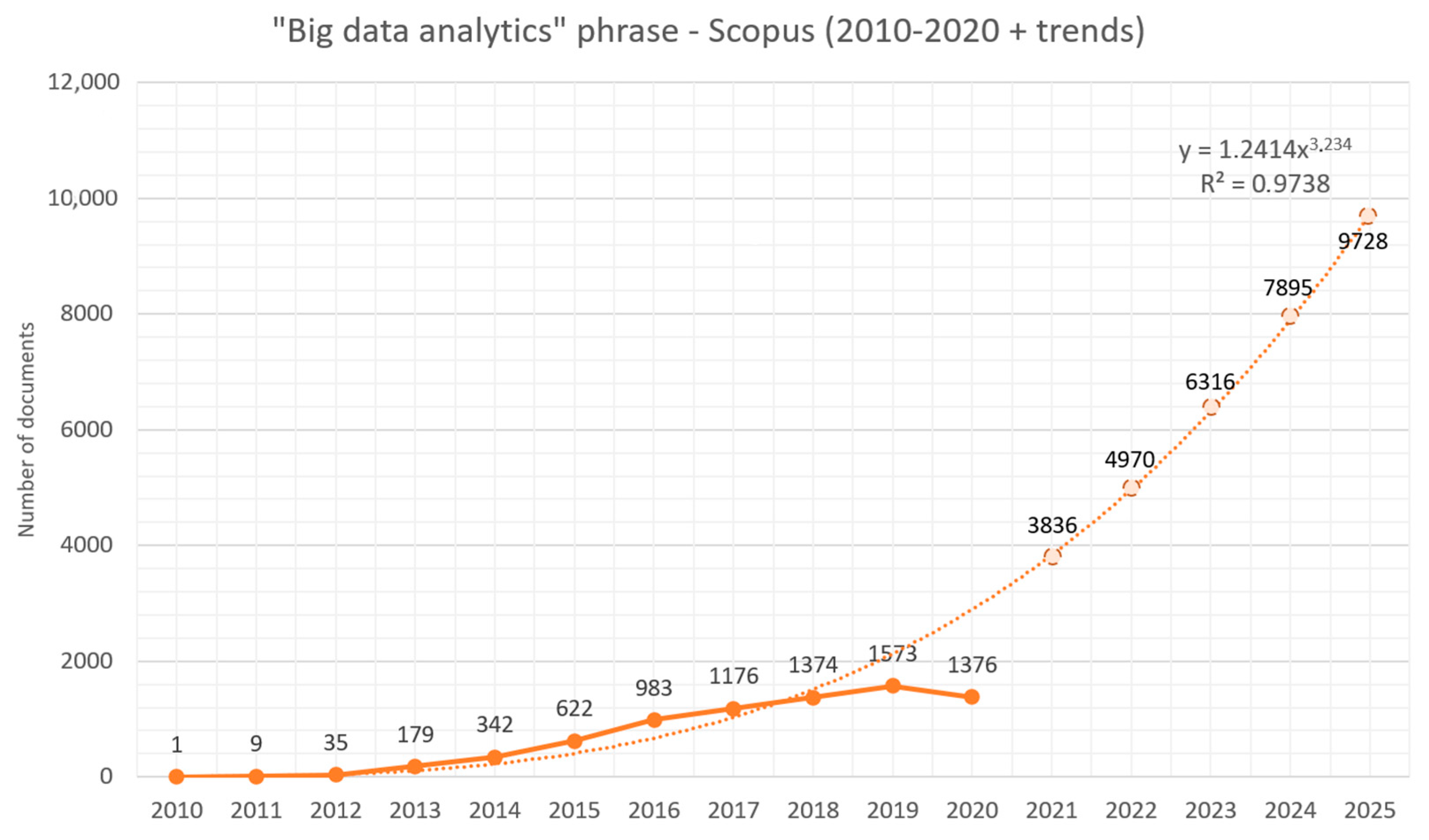
Since the phrase “big data analytics” is the broadest concept (and includes derivative scientific areas such as “big data mining”, etc.), its analysis in Scopus databases is the first. The very first scientific paper concerning this term appeared in this indexing portal in 2010. Then, in simplification, every year the number of articles dealing with the “big data analytics” topic rocketed. The query returned 8373 documents, of which 2232 are open access. The visualized results of the study are presented in
Figure 5,
Figure 6 and
Figure 7, respectively.
Due to the huge number of articles dealing with this scientific sphere, it can be concluded that scientists and researchers are very interested in conducting research on or with the use of big data analytics. It should be noted that the decrease in the number of articles in 2021 results from the period of the study (the authors do not have complete data for 2021), while the slight reduction in the number of papers in 2020 may be the result of the prevailing COVID-19 pandemic, where science accessibility in many regions of the world was lower than ever before.
There is no doubt that computer science (25.6%) is, without surprise, the domain in which the field of big data analytics is most often used and explored. Together with engineering (17.9%), it accounts for more than half (53.5%) of all BDA-related scientific works. It should be noted, however, that mathematics (7.5%), decision sciences (7.3%), and business and management (7.0%) are equally important subject areas in investigating and the use of BDA. It can therefore be concluded that the concept of “big data analytics” is multidisciplinary, and hence, it states as foremost implications for academia and business.
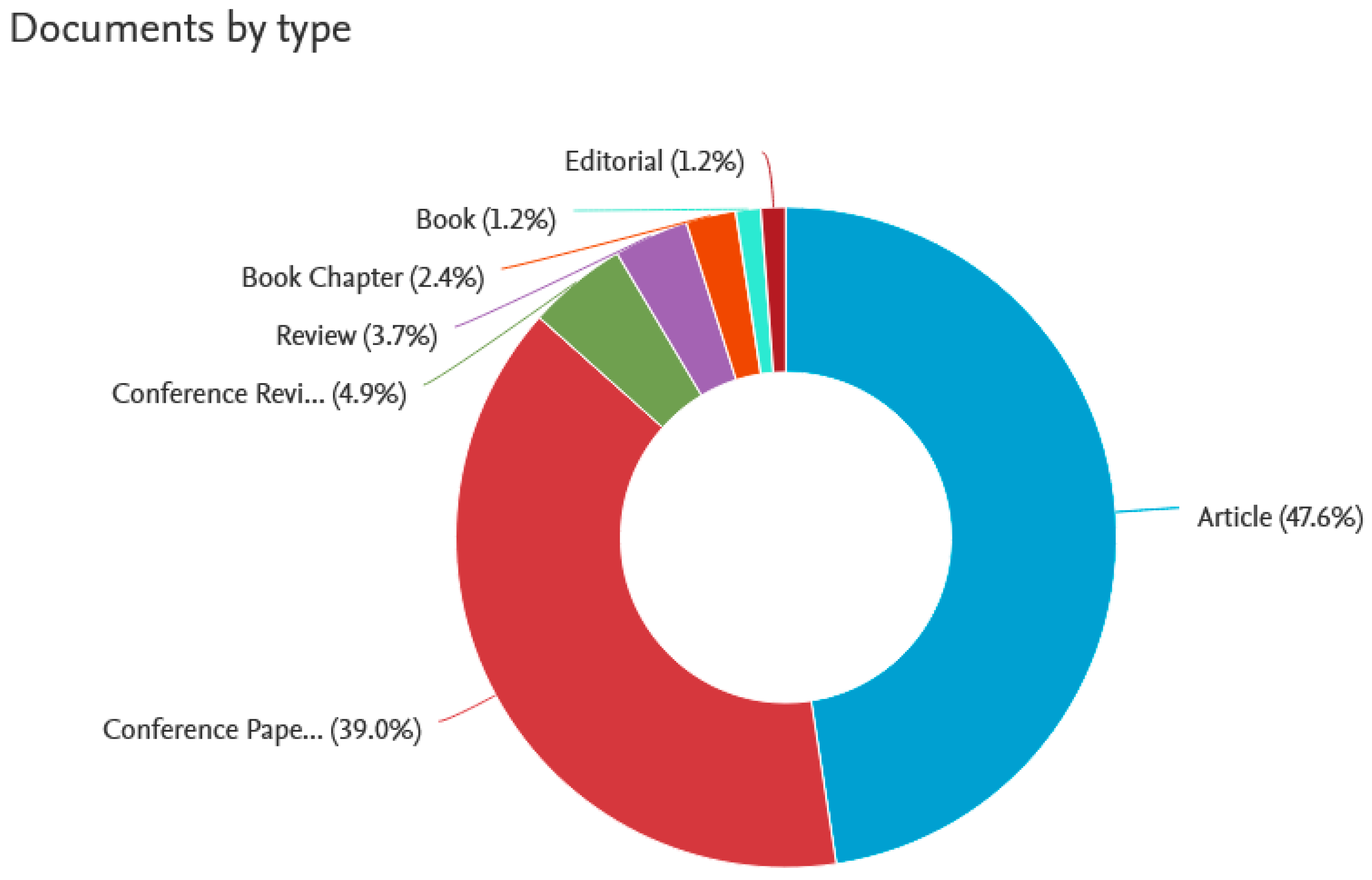
The overwhelming majority of publications including the notation “big data analytics” (82.2%) are conference publications and scientific articles. Chapters in scientific monographs, reviews, and other types of scientific documents are of a much less importance.
5.2. “Big Data Mining” Phrase in Literature
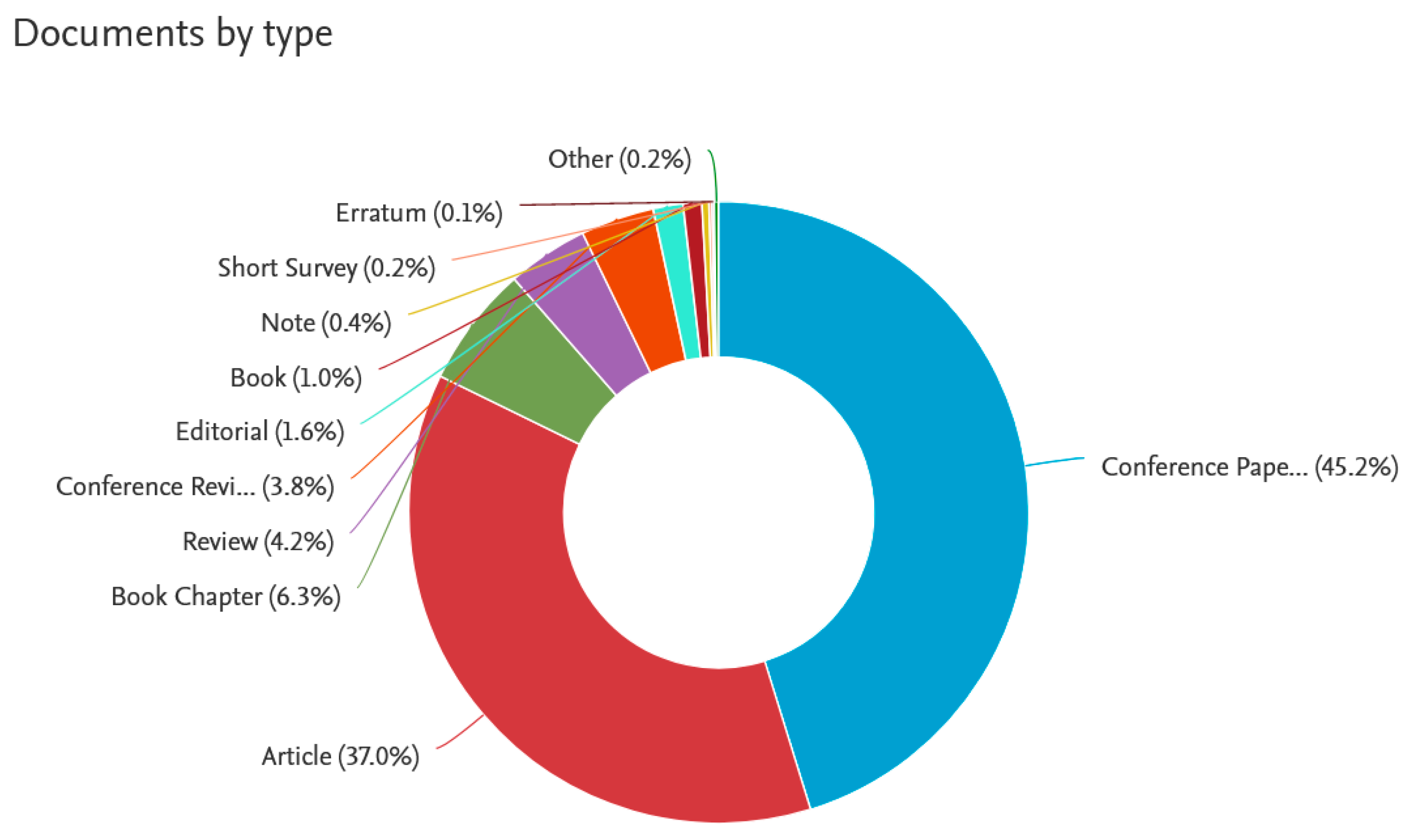
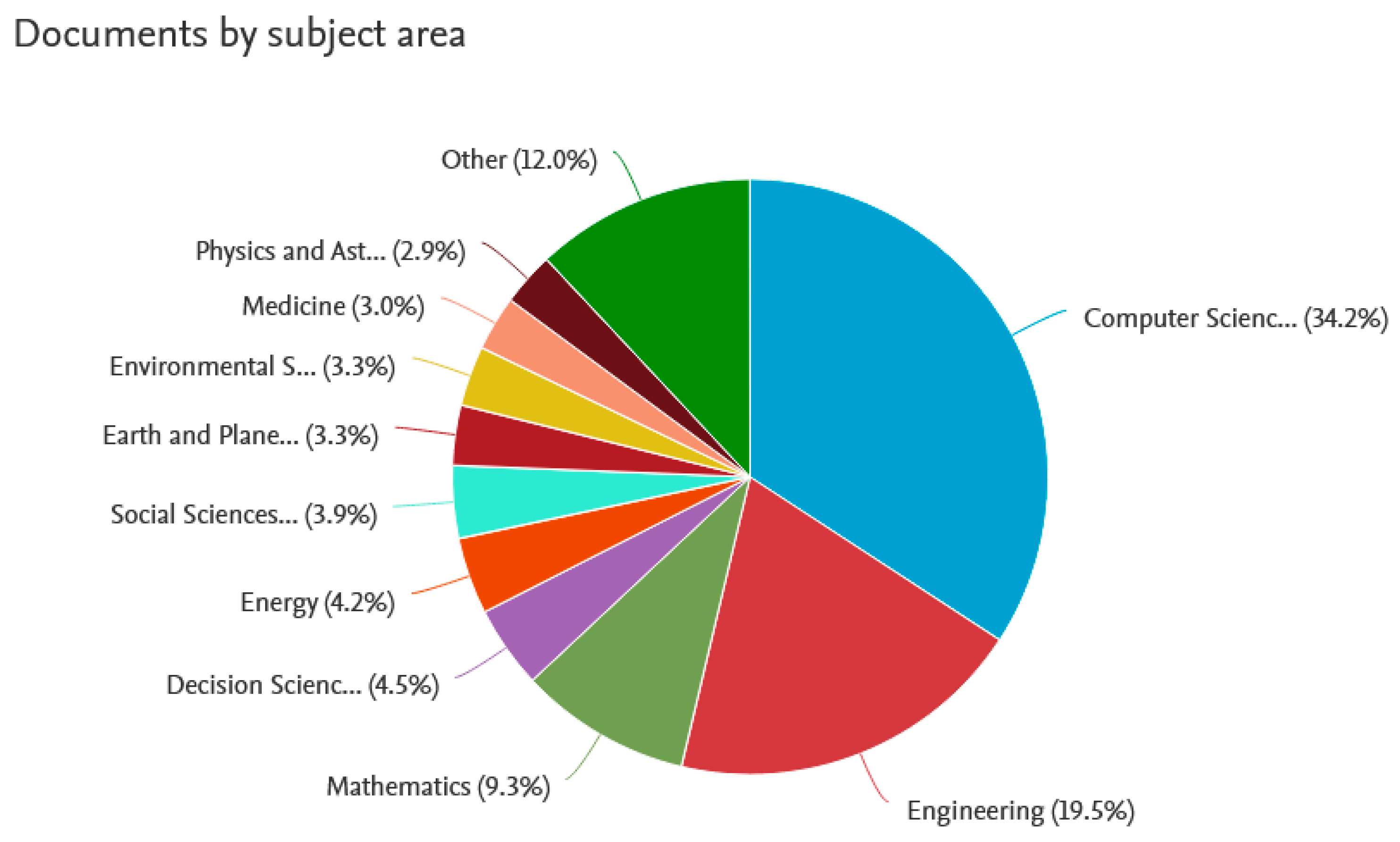
Moving on to the more specific sphere, the query “big data mining” throughout the Scopus database returned 943 documents, among which 230 open-access ones (i.e., gold, hybrid gold, bronze, and green open-access options), while 713—other types of access. The year range detected was 2012–2021. Hence, the research question of big data mining may be already treated as mature one, attracting a widely spread attention of scholars. The returned documents have been then analyzed using three criteria: year of publication, subject area, and document type. The visualizations of findings are presented in
Figure 8,
Figure 9 and
Figure 10, respectively.
Obviously, the issue of big data mining is gaining more and more interest among scholars. The research area of data mining is generally well explored, but when it comes to mine big data, there are still many questions to ask and to answer. The surge in the number of documents in 2021 (concerning the issue of “big data mining”) occurs due to the survey being conducted in the middle of the year. This means that standardization must be done to be able to refer to the whole year. For this purpose, the trend analysis presented in the
Section 5.5 is used.
Not surprisingly, big data mining issue is explored mainly within the areas of computer science and engineering. At the same time, it seems underestimated within business and management (2.6%—not visible on the chart), as well as social sciences (3.9%). This may suggest that there may be a possibility of new research concerning big data mining for the use in business, in management, etc.—e.g., for customer insights. The more to do, the more data is available. Although certain research disciplines prevail, big data mining can be considered an interdisciplinary field (or at least one that can be applied in many different industries).
Finally, as a relatively new research topic, big data mining is mostly addressed in journal articles and conference papers.
5.3. “Temporal Big Data” Phrase in Literature
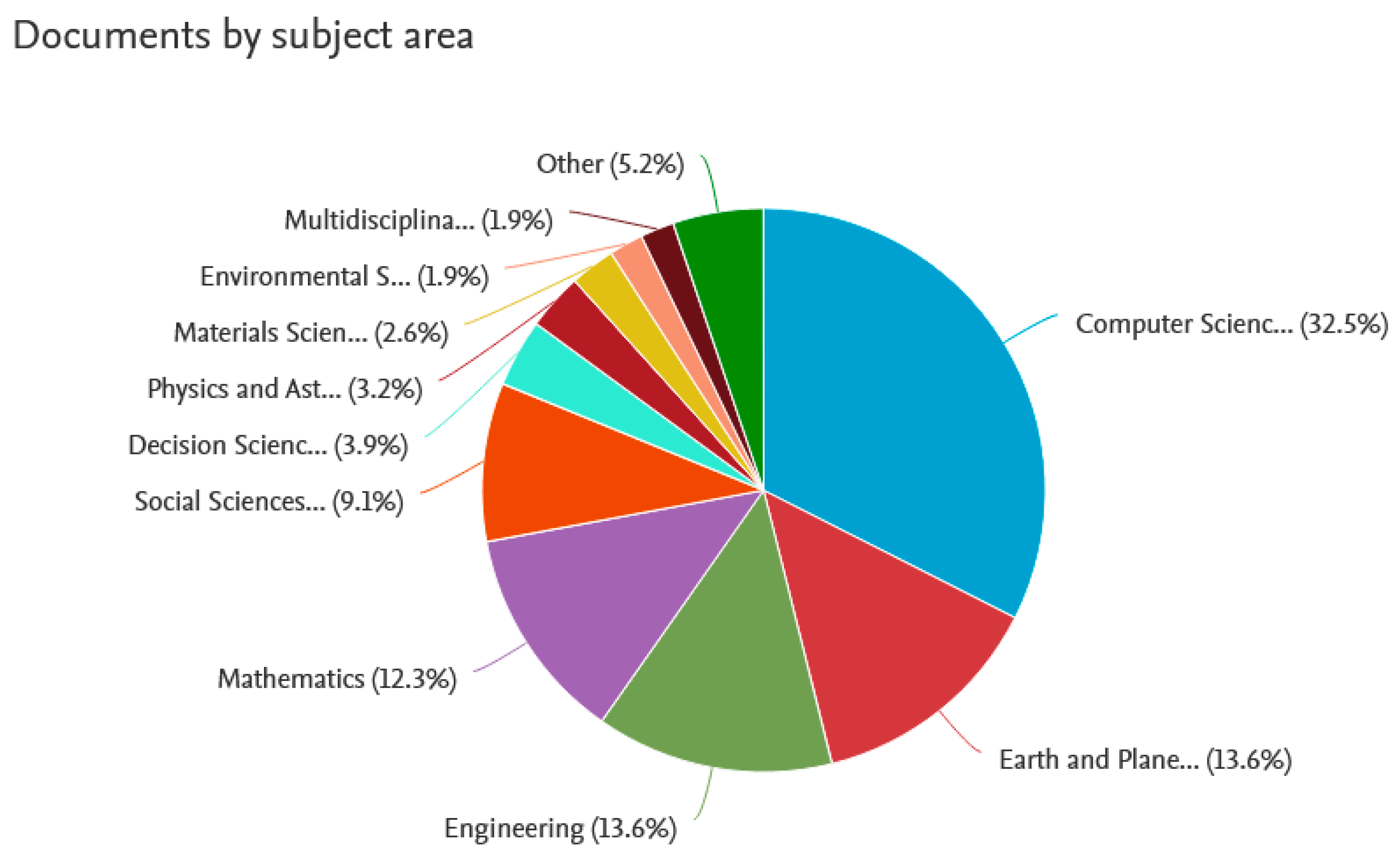
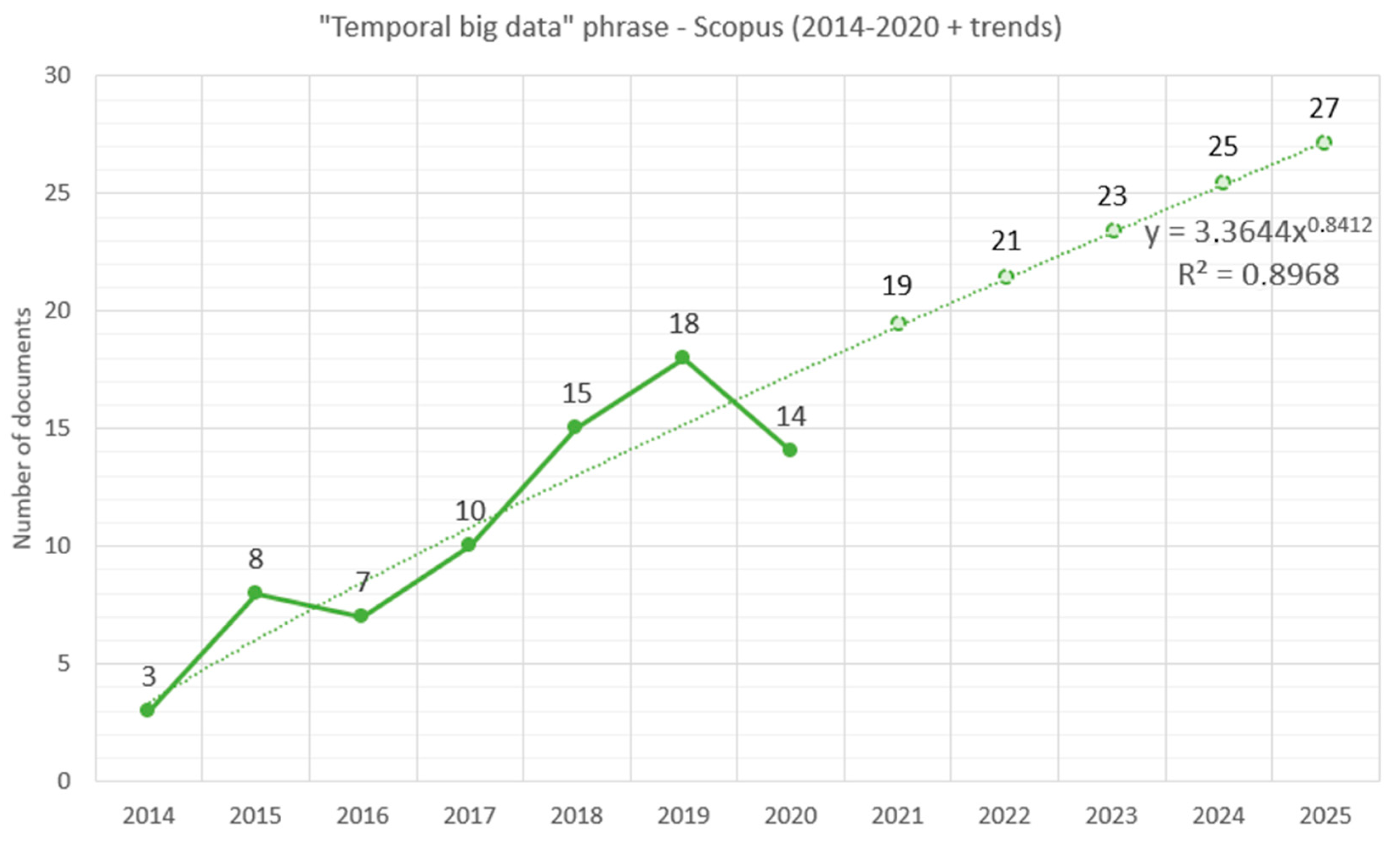
The next query “temporal big data” returned merely 82 documents among which 22 open-access ones and 60 paid-access ones. This query returned the year range of 2014–2021; hence, the notion and research question of temporal big data may be considered slightly “younger” than big data mining and of much smaller popularity among researchers. Moreover, for this query, the returned set of documents has been analyzed by year, by subject area, and by type, and the results are given in
Figure 11,
Figure 12 and
Figure 13, respectively.
In the case of the phrase “temporal big data”, the surge of documents in 2021 results from the same reason as in the case of the “big data mining” analysis, i.e., partial information for the current year in the case of a survey conducted in the middle of 2021. What can be in our opinion inferred from the above chart is that the temporal big data area is just gaining popularity and is attracting attention as a research topic. The year 2020 admittedly saw a slight decrease in the number of articles (like in the previous queries), but it could have been caused by the COVID-19 pandemic situation, which forcefully hindered conducting scientific research.
As it has been observed for the “big data mining” key phrase, also the “temporal big data” is mostly explored within the areas of computer science, engineering, as well as earth and planet sciences, but it is also present in mathematics. Social sciences are also notably represented. For earth and society, temporal data are natural because they reflect the dynamism of the domain. However, in business and management the temporal aspects of phenomena also should be considered. The business environment is perceived as dynamic, and changes should be analyzed. Even though the sphere of business and management is not included in the chart (it is hidden under the “other” layer), it does not mean that there is no interest in the temporal aspects of big data in this sphere. This can only testify to the dynamics of this environment and its significant unexplored area, which may be a starting point for researchers willing to define the research gap.
As “big data mining”, also “temporal big data” reveals to be a new and unexplored research area. This is reflected not only in the relatively small number of publications addressing this topic but also in the structure of the documents retrieved from Scopus—these are mostly journal articles and conference papers (86.6% together). This result, together with our investigations presented in this study, shows the future potential of solutions aimed at capturing and processing temporal big data.
5.4. “Temporal Big Data Mining” in Literature
The last query concerned the “temporal big data mining” key phrase as a sum of the two previous key phrases. This query returned merely two documents (specifically: scientific articles) from the Scopus database. The first of them is dated 2016, with subject area named “multidisciplinary” and, more precisely, geological sciences. The latter comes from 2021, and on the day the analysis was conducted, it was in the press. This article can also be described as “multidisciplinary”, because according to Scopus, it combines three subject areas: engineering, computer science, and mathematics. The issue of temporal big data mining is a new research topic, and within the area of business, it seems completely unexplored. This result is in line with the findings presented in this study. The research topic of temporal big data mining is challenging, and within business, management, and decision sciences, there is a vast area for future investigations.
5.5. Trends Analysis
Considering the time series regarding the number of scientific documents in given years, for all three phrases: “big data analytics”, “big data mining”, and “temporal big data”, a clear upward trend is noticeable, which proves that researchers are becoming increasingly interested in these topics over time. Performing a trend analysis in the case of the phrase “temporal big data mining” is not possible, due to the presence of only 2 articles in the Scopus database corresponding to this phrase (for the abstract, keywords and title). With the help of only two references (i.e., a time series consisting of two observations), it is pointless and impossible to create a trendline and thus analyze it.
It was decided that the trend analysis methodologies (predictions) will be used to analyze these time series, with prior examination of the fit of the data in the model using the coefficient of determination
R2. This coefficient takes the values
the larger its value, the higher the match of the dataset. It is expressed by the following formula, as presented in [
178]:
where
is th observation of variable;
is theoretical value of the dependent variable (based on the model);
is arithmetic mean of empirical values of the dependent variable.
For comparison purposes, the following trends were chosen: linear, second-order polynomial, logarithmic, exponential, and power. The formula for polynomial models (i.e., linear and second-order polynomial) is generalized as follows:
where
goes for linear and
goes for second-order polynomial trend.
The exponential trend formula is as follows:
The power trend formula is as follows:
The logarithmic trend formula is as follows:
For further and deepened discussion for linear/polynomial trends, see [
179,
180], and for logarithmic, exponential, and power trends, see [
181,
182]. The study compares the models estimated using the ordinary least squares (OLS) methodology [
183,
184], which is broadly used in scientific research [
185,
186,
187,
188].
For each dataset, individual regressions (characterized by exponential, linear, logarithmic, second-order polynomial, and power trendlines) were compared with respect to the matching (fitting) degree of the dataset, using the R2 coefficient. The trendlines with the highest R2 coefficient were selected for further processing.
The trendlines in various regression models were expressed by trend function equations, in tabular comparison with the values of the determination coefficients. To calculate the values of R2 coefficients, as well as the function of the particular trendlines, and to visualize the results in the form of charts, Microsoft Excel 2019 software was used.
Using regression and trend analysis to predict future values for a given phenomenon can bring enormous value, among others for determining the directions and forms of development of accompanying phenomena. It may turn out to be useful in the scientific or business spheres, depending on the subject of research. Thanks to researching trends, it is simpler to gather knowledge about threats and challenges but also about opportunities faced, for example, by a company, industry, country, region, etc.
The usefulness of the trend analysis is confirmed in scientific research from various fields. For example, there is a study that used trend analysis to analyze the phenomena of road accidents and to eliminate them [
189]. Prediction of future values with the use of trend analyzes also turns out to be useful in temperature and climatological studies [
190,
191,
192]. Furthermore, trend analysis approach is widely used to investigate and prevent the COVID-19 spread [
193,
194,
195].
5.5.1. Trends for “Big Data Analytics” Phrase
The occurrence of an upward trend is confirmed in analyzes of time series trends. The trendlines for the phrase “big data analytics” (for each line type) was always accompanied by
R2 values exceeding 0.75, which proves that the data was highly matched. This shows a clearly defined trend that is plainly visible and statistically significant.
Table 1 juxtaposes the coefficients of determination
R2 along with the equations of the trend function for the “big data analytics” phrase.
The trend function, which is a power function, finds the highest fit because its coefficient of determination R2 is the highest among the other types of functions. It is close to 1 (exactly 0.9738), which proves an extremely high data fit. From the definition of the power function (more precisely from the value of the exponent that is higher than 1 and a high positive scalar value), it follows that the growth dynamics increases with each period. This translates into the fact that the trend of choosing “big data analytics” as a topic of scientific work is constantly getting more popular. Moreover, it proves that the number of papers is growing at an increasing pace every year.
With the available data set from Scopus database, it is possible to predict the number of documents for subsequent years (periods) using the trend function. In this case, the function with the greatest fit (i.e., having the highest
R2) was used to estimate the values for subsequent periods. All periods were included in the predictions, but the year 2021 was excluded, due to its incompleteness. Standardization for this period is carried out by predicting the value from the used trend function.
Table 2 shows the prediction values for five consecutive periods after 2020, i.e., from 2021 to 2025.
Figure 14 shows the power trend function plotted on a time series of scientific documents for the phrase “big data analytics” from the Scopus database with respect to the year, along with the plotted prediction values for subsequent periods. As the document cannot have decimals, it is assumed that the prediction values are the absolute value of the calculated trend values for the successive periods.
5.5.2. Trends for “Big Data Mining” Phrase
For the phrase “big data mining”, the coefficient of determination
R2 is always greater than 0.8 (regardless of the type of trend function), which proves a very good fit of the data, similar to trends for the broader concept of “big data analytics”. The coefficients of determination
R2 along with the equations of the trend function for the “big data mining” phrase are presented in
Table 3.
As in the case of “big data analytics”, also here, the trend line with the highest coefficient of determination is the one expressed by the power function (
R2 = 0.9806). It should be noted, however, that since “big data mining” is a narrower concept than the BDA, the number of observations (scientific articles dealing with this topic) is noticeably smaller. Nevertheless, this does not change the fact that BDM seems to be a topic desired by scientists and researchers, and the interest grows over time. Moreover, here, the value for 5 consecutive periods was predicted based on the trend with the highest coefficient of determination, analogous to the phrase “big data analytics”, as seen in the
Table 4. It also depicts the number of scientific documents for the 2012–2020 period (value for 2021 was also standardized). The forecasted values are treated as the absolute value from the value of the trend function, to maintain the integer value. The power trendline plotted on a time series of scientific documents from the Scopus database is depicted in
Figure 15, respectively. It conjuncts with the expression “temporal big data” with regard to the year, as well as the with projected forecast values for subsequent periods.
5.5.3. Trends for “Temporal Big Data” Phrase
In the case of the time series, for the number of documents in the Scopus database corresponding to the phrase “temporal big data”, the same trend analysis methodology was used. Moreover, in this case, there are high levels of data fit, which are manifested in high values of the coefficient of determination
R2. Note, however, that this phrase has a slightly less dynamic trend, but this may be the result of less data (in this case, the number of documents) that was used to create the trend. It does not change the fact that the trend is strongly growing and clearly outlined (due to the high value of the
R2 coefficient). The highest fit level is also visible in the power trend, although this lower dynamics (in comparison to “big data mining” query) is manifested by a lower scalar value and a lower exponent value (which is less than 1—which indicates a slight stabilization over a long period of time). The coefficients of determination
R2 along with the equations of the trend function for the “temporal big data” phrase are presented in
Table 5.
For this query, values for future periods can also be predicted. This estimate is visible in
Table 6, also excluding the year 2021 and treating it as the period for standardization. The table shows the values for the next 5 periods after 2020 (i.e., from 2021 to 2025 inclusive) and the prediction values are treated as the absolute value from the value of the trend function, to maintain the integer value.
Figure 16, respectively, depicts the power trend function plotted on a time series of science documents from the Scopus database for the expression “temporal big data” regarding the year, as well as the projected forecast values for subsequent periods.
5.5.4. Trends for “Temporal Big Data Mining” Phrase
The last query concerned the “temporal big data mining” key phrase as a sum of the two previous key phrases. This query returned only one document from the Scopus database, dated 2016 (and one in press, dated 2021), with subject area named as “multidisciplinary” and, more precisely, geological sciences. The issue of temporal big data mining is a new research topic, and within the area of business, it seems completely unexplored. This result is in line with our findings presented in this paper. The research topic of temporal big data mining is challenging, and within business, management, and decision sciences, there is a vast area for future investigations.
5.5.5. Usefulness of Trend Analysis in the Context of Bibliographic Research
The usefulness of the trend analysis is confirmed in scientific research from various fields. Hence, in this paper, based primarily on the bibliographic research, we have decided to use the trend analysis to check whether our findings are confirmed. Naturally, the raising trend indicates the augmenting interest in the temporal issues regarding big data mining issues. It may seem apparent and undisputable; however, it is not. As noted in the Introduction, we understand “temporality” in its very deep context that is as the time dimension of phenomena being examined. Time is being understood not only as a simple (calendar) linear construct. It may be perceived and analyzed as a branching structure (branching to the future or to the past), as a structure composed of parallel timelines, or even as a cyclic structure [
7]. The timeline may be composed of intervals, of points, or both [
196,
197]. So far, such a rich approach to the problem of time, both from the philosophical and logical side, has so far been typical for the area of artificial intelligence [
6,
198,
199]. It enables, e.g., reasoning about change, analyzing causality, or introducing the notion of possibility. Time is philosophically treated as the fourth dimension [
200,
201,
202], but it provides the basis for extending reasoning not only in everyday life, but also in the understanding and aspects of artificial intelligence (AI) [
203]. This was a point for further considerations in the context of big data analysis. As such, “AI approach” to big data analytics and big data mining is not obvious; the trend analysis performed in this paper has proven that our observation about such a temporal research gap in BDM is confirmed.
6. Discussion
Consumer insights have been analyzed also before the big data era—by applying the data mining techniques to huge customer databases. Obviously, this concerned the structured data. These databases have been mined for various purposes and with various machine learning (ML) techniques. Liao et al. [
204] mined customer data for new product development and for customer relationship management in the tourism industry. Rajagopal [
205] applied database clustering to identify the high-value, and low-risk customers. Clustering has been also exploited, together with market basket analysis, in [
206] with the ultimate goal to discover customer groups defined by lifestyle. As these examples show, the temporal aspect of analysis has been rarely addressed. It is touched in [
207] where classification and clustering of time-stamped banking transaction data is performed for customer profiling. In [
208] historical electricity consumption, data are mined to automatically estimate the absence probability of a customer. The input data are temporally ordered as time series. Hence, the temporal dimension is present only in the simple form of timestamping.
The advent of big data, with its heterogeneity, velocity, volume, and other features, offered quite new possibilities of mining customer insights. However, the big data mining approaches found in the literature seldom address the temporality. e.g., [
209,
210,
211,
212] propose various social media mining approaches, to analyze and visualize Twitter clusters, to extract customers’ opinions on product features, to analyze customer requirements. All these approaches do not touch any time aspects of data nor analytics. Similarly, in the e-commerce area, Ref. [
213] combine machine learning methods: association rule mining, clustering, and classification to enhance precision marketing and personal referral services; Ref. [
214] mine customer data to predict remanufactured product demand. These two approaches do not address the temporal dimension of data as well. Textual data of consumer complaints is mined with the Outcome-Driven Innovation method in [
215] where the problem of time-dependent opinion changeability is omitted by introducing the concept of a job. The job is assumed to be stable in a certain period of time. Hassani et al. [
216,
217] offer two exhaustive literature reviews on big data mining in banking, and on textual big data mining, respectively. As for the banking area, no research with explicit time aspect is detected, only some publications on real-time analytics are pointed out. For textual big data analytics, the problem of changes over time, typical to social media data, has been noticed. Hence, Ref. [
217] point out the research gap linked to temporal big data analytics, but it is limited to textual social media content analysis.
Temporal big data mining for consumer insights has been addressed in a limited number of research works. Ref. [
218] propose the sentiment intelligence tool to analyze consumer complaints expressed via social media. Although the analysis is performed in real time, it is not fully temporal. It does not offer analysis of changes over time, of time structure, of causal relationships and other temporal characteristics. Only timestamping of complaints is used. Timestamping of events depicted by big data is used by several other researchers too. Ref. [
219] use clustering of time series of smart meter data to discover time and intensity of water use by end customers. Refs. [
220,
221] mine processes in event logs and location data, respectively. In both cases, data is simply time-stamped which means that the simplest approach to time is used, namely linear calendar time. A more complete view of time is presented by [
222], who address the problem of temporal clustering of sentiments in emails. Sentiment features are represented as a trajectory which enables the discovery of sentiment flow in emails with regard to topic and time.
Obviously then, some research on temporal big data mining for customer insights has already emerged, however, these attempts are few, and time is captured in a simplified way. As the analysis in
Section 4 and
Section 5 has shown, the temporal big data mining for customer insights area offers many more research possibilities and is generally unexplored.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}