
Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation

 ,
, 
 and
and
Abstract
:1. Introduction
- We perform a comprehensive evaluation of thirty-six combinations of three selected architectures and loss functions, as well as four image types, to assess which of these elements affects wildfire segmentation performance the most, exploring as well the use of attention modules for the particular task of fire segmentation.
- We benchmark the best combination against traditional fire segmentation methods to assess if it provides a significant advantage over them.
2. Related Work
- Convolutional layers: In these layers, a filter (also referred to as kernel) is convolved with the input to perform feature extraction, constructing a 2D activation map of such filter. The CNN learns the weights of its filters, which activate when a particular type of feature is observed [56].
- Non-linear layers: These layers apply an activation function (e.g., sigmoid, Tanh, ReLU, amongst others [57]) on the obtained feature maps to allow the network to successfully learn non-linear functions.
- Pooling layers: These layers reduce the spatial resolution of a feature map by replacing neighborhoods with given statistical information of said neighborhood, such as its mean, maximum, among other strategies [55]. The latter reduces the number of parameters and calculations in the model, thus improving the training and inference times as well as addressing the issue of overfitting [56].
2.1. Deep Learning-Based Semantic Segmentation
2.2. Deep Learning-Based Wildfire Segmentation
3. Materials and Methods
3.1. Data
3.2. Image Fusion Methods
3.2.1. Infrared and Visible Image Fusion Using a Deep Learning Framework
3.2.2. Fire-GAN: A Novel Deep Learning-Based Infrared-Visible Fusion Method for Wildfire Imagery
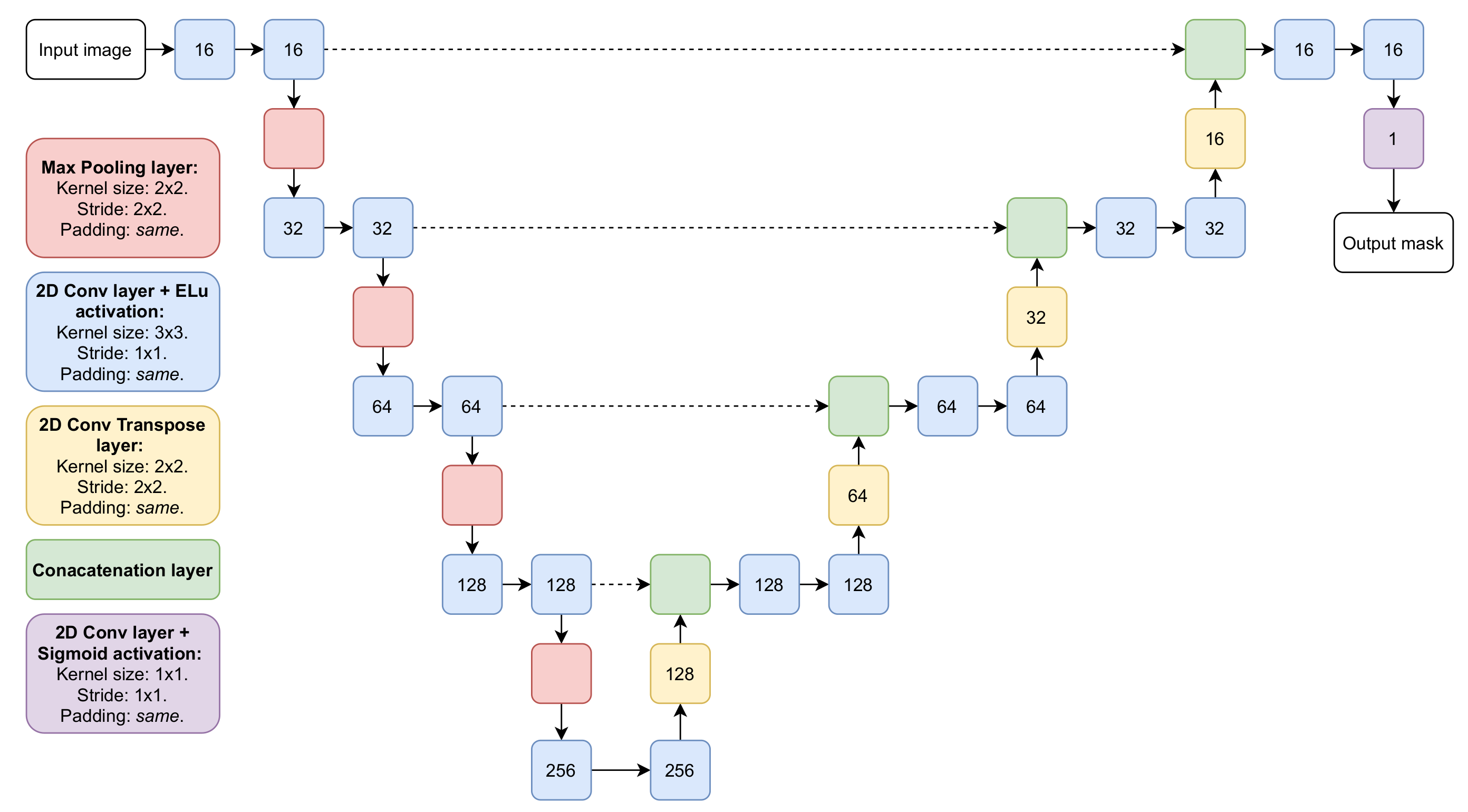
3.3. Architectures
3.3.1. Wildland Fires Detection and Segmentation using Deep Learning
3.3.2. Semantic Fire Segmentation Model Based on Convolutional Neural Network for Outdoor Image
3.3.3. Convolutional Neural Network for Smoke and Fire Semantic Segmentation
3.4. Attention Modules
3.4.1. Attention Gate
3.4.2. Spatial Attention Module
3.4.3. Channel Attention Module
3.5. Loss Functions
3.5.1. Dice Loss
3.5.2. Focal Tversky Loss
3.5.3. Unified Focal Loss
3.6. Metrics
3.6.1. Matthews Correlation Coefficient
3.6.2. F1 Score
3.6.3. Hafiane Quality Index
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep Learning |
| ML | Machine Learning |
| AG | Attention gate |
| SP | Spatial Attention |
| UAV | Unmanned aerial vehicle |
| NIR | Near-infrared |
| MCC | Matthews Correlation Coefficient |
| HAF | Hafiane quality index |
| GAN | Generative Adversarial Network |
| CNN | Convolutional neural network |
| RMI | Region Mutual Information |
| SOTA | State-of-the-art |
| DCNN | Deep convolutional neural network |
| LWIR | Long-wave infrared |
| MECA | Modified Efficient Channel Attention |
References
- Insurance Information Institute. Facts + Statistics: Wildfires. 2021. Available online: https://www.iii.org/fact-statistic/facts-statistics-wildfires (accessed on 3 June 2021).
- Congressional Research Service. Wildfire Statistics; Technical Report; Congressional Research Service: Washington, DC, USA, 2021. [Google Scholar]
- Yuan, C.; Zhang, Y.; Liu, Z. A Survey on Technologies for Automatic Forest Fire Monitoring, Detection and Fighting Using UAVs and Remote Sensing Techniques. Can. J. For. Res. 2015, 45, 150312143318009. [Google Scholar] [CrossRef]
- Nemalidinne, S.M.; Gupta, D. Nonsubsampled contourlet domain visible and infrared image fusion framework for fire detection using pulse coupled neural network and spatial fuzzy clustering. Fire Saf. J. 2018, 101, 84–101. [Google Scholar] [CrossRef]
- Choi, H.S.; Jeon, M.; Song, K.; Kang, M. Semantic Fire Segmentation Model Based on Convolutional Neural Network for Outdoor Image. Fire Technol. 2021. [Google Scholar] [CrossRef]
- Namozov, A.; Cho, Y.I. An Efficient Deep Learning Algorithm for Fire and Smoke Detection with Limited Data. Adv. Electr. Comput. Eng. 2018, 18, 121–128. [Google Scholar] [CrossRef]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 877–882. [Google Scholar] [CrossRef]
- Valente de Almeida, R.; Crivellaro, F.; Narciso, M.; Sousa, A.; Vieira, P. Bee2Fire: A Deep Learning Powered Forest Fire Detection System. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence, Valletta, Malta, 22–24 February 2020; ICAART: Setúbal, Portugal, 2020. [Google Scholar] [CrossRef]
- Zhang, Q.; Xu, J.; Xu, L.; Guo, H. Deep Convolutional Neural Networks for Forest Fire Detection. In Proceedings of the 2016 International Forum on Management, Education and Information Technology Application, Guangzhou, China, 30–31 January 2016; Atlantis Press: Dordrecht, The Netherland, 2016; pp. 568–575. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42, Learning System in Real-time Machine Vision. [Google Scholar] [CrossRef]
- Toulouse, T.; Rossi, L.; Akhloufi, M.; Celik, T.; Maldague, X. Benchmarking of wildland fire colour segmentation algorithms. IET Image Process. 2015, 9, 1064–1072. [Google Scholar] [CrossRef] [Green Version]
- Ciullo, V.; Rossi, L.; Pieri, A. Experimental Fire Measurement with UAV Multimodal Stereovision. Remote Sens. 2020, 12, 3546. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Çetin, A.E.; Dimitropoulos, K.; Gouverneur, B.; Grammalidis, N.; Günay, O.; Habiboǧlu, Y.H.; Töreyin, B.U.; Verstockt, S. Video fire detection—Review. Digit. Signal Process. 2013, 23, 1827–1843. [Google Scholar] [CrossRef] [Green Version]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving Deep Convolutional Neural Networks for Image Classification. IEEE Trans. Evol. Comput. 2020, 24, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Liang, Y.; Zhang, Y. Deep convolutional neural networks for diabetic retinopathy detection by image classification. Comput. Electr. Eng. 2018, 72, 274–282. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Li, H.; Yang, S.; Wang, Z.; Loy, C.C.; et al. DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Farfade, S.S.; Saberian, M.J.; Li, L.J. Multi-View Face Detection Using Deep Convolutional Neural Networks. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; Association for Computing Machinery: New York, NY, USA ICMR ’15. , 2015; pp. 643–650. [Google Scholar] [CrossRef] [Green Version]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey. Knowl. Based Syst. 2020, 201–202, 106062. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhang, S.; Ma, Z.; Zhang, G.; Lei, T.; Zhang, R.; Cui, Y. Semantic Image Segmentation with Deep Convolutional Neural Networks and Quick Shift. Symmetry 2020, 12, 427. [Google Scholar] [CrossRef] [Green Version]
- Döllner, J. Geospatial Artificial Intelligence: Potentials of Machine Learning for 3D Point Clouds and Geospatial Digital Twins. PFG—J. Photogramm. Remote Sens. Geoinf. Sci. 2020, 88, 15–24. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Ma, J. Segmentation Loss Odyssey. arXiv 2020, arXiv:2005.13449. [Google Scholar]
- Luo, X.; Zhang, Z.; Zhang, B.; Wu, X. Image Fusion With Contextual Statistical Similarity and Nonsubsampled Shearlet Transform. IEEE Sens. J. 2017, 17, 1760–1771. [Google Scholar] [CrossRef]
- Chen, J.; Wu, K.; Cheng, Z.; Luo, L. A saliency-based multiscale approach for infrared and visible image fusion. Signal Process. 2021, 182, 107936. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.; Kittler, J. Infrared and Visible Image Fusion using a Deep Learning Framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2705–2710. [Google Scholar]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Zhao, Y.; Fu, G.; Wang, H.; Zhang, S. The Fusion of Unmatched Infrared and Visible Images Based on Generative Adversarial Networks. Math. Probl. Eng. 2020, 2020, 3739040. [Google Scholar] [CrossRef]
- Toulouse, T. Estimation par Stéréovision Multimodale de Caractéristiques Géométriques d’un feu de Végétation en Propagation. Ph.D. Thesis, Université De Corse—Pasquale Paoli, Corte, France, 2015. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef] [Green Version]
- Ciprián-Sánchez, J.F.; Ochoa-Ruiz, G.; Gonzalez-Mendoza, M.; Rossi, L. FIRe-GAN: A Novel Deep Learning-Based Infrared-Visible Fusion Method for Wildfire Imagery. arXiv 2021, arXiv:2101.11745. [Google Scholar]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency Detection and Deep Learning-Based Wildfire Identification in UAV Imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [Green Version]
- Frizzi, S.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Sayadi, M. Convolutional neural network for smoke and fire semantic segmentation. IET Image Process. 2021, 15, 634–647. [Google Scholar] [CrossRef]
- Harkat, H.; Nascimento, J.; Bernardino, A. Fire segmentation using a DeepLabv3+ architecture. In Image and Signal Processing for Remote Sensing XXVI; Bruzzone, L., Bovolo, F., Santi, E., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, MA, USA, 2020; Volume 11533, pp. 134–145. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Tokime, R.B.; Elassady, H. Wildland fires detection and segmentation using deep learning. In Pattern Recognition and Tracking XXIX; Alam, M.S., Ed.; International Society for Optics and Photonics, SPIE: Bellingham, MA, USA, 2018; Volume 10649, pp. 86–97. [Google Scholar] [CrossRef]
- Toan, N.T.; Thanh Cong, P.; Viet Hung, N.Q.; Jo, J. A deep learning approach for early wildfire detection from hyperspectral satellite images. In Proceedings of the 2019 7th International Conference on Robot Intelligence Technology and Applications (RiTA), KAIST, Daejeon, Korea, 1–3 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 38–45. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Fully Virtual, Online, 27–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Abraham, N.; Khan, N.M. A Novel Focal Tversky Loss Function With Improved Attention U-Net for Lesion Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 683–687. [Google Scholar] [CrossRef] [Green Version]
- Yeung, M.; Sala, E.; Schönlieb, C.B.; Rundo, L. Unified Focal Loss: Generalising Dice and Cross Entropy-Based Losses to Handle Class Imbalanced Medical Image Segmentation. arXiv 2021, arXiv:2102.04525. [Google Scholar]
- Matthews, B. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta (BBA) Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Collumeau, J.F.; Laurent, H.; Hafiane, A.; Chetehouna, K. Fire scene segmentations for forest fire characterization: A comparative study. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2973–2976. [Google Scholar] [CrossRef]
- Hafiane, A.; Chabrier, S.; Rosenberger, C.; Laurent, H.A.; Chabrier, S.; Rosenberger, C.; Laurent, H. A New Supervised Evaluation Criterion for Region Based Segmentation Methods. In Advanced Concepts for Intelligent Vision Systems; Blanc-Talon, J., Philips, W., Popescu, D., Scheunders, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 439–448. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Guo, C.; Szemenyei, M.; Pei, Y.; Yi, Y.; Zhou, W. SD-Unet: A Structured Dropout U-Net for Retinal Vessel Segmentation. In Proceedings of the 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, 28–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 439–444. [Google Scholar]
- Guo, C.; Szemenyei, M.; Hu, Y.; Wang, W.; Zhou, W.; Yi, Y. Channel Attention Residual U-Net for Retinal Vessel Segmentation. arXiv 2020, arXiv:2004.03702. [Google Scholar]
- Jung, S.; Lee, U.; Jung, J.; Shim, D.H. Real-time Traffic Sign Recognition system with deep convolutional neural network. In Proceedings of the 2016 13th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Xi’an, China, 19–22 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 31–34. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive Medical Image Segmentation Using Deep Learning With Image-Specific Fine Tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Nassar, A.; Amer, K.; ElHakim, R.; ElHelw, M. A Deep CNN-Based Framework for Enhanced Aerial Imagery Registration With Applications to UAV Geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Lateef, F.; Ruichek, Y. Survey on semantic segmentation using deep learning techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Visual Pattern Recognition. In Competition and Cooperation in Neural Nets; Amari, S.I., Arbib, M.A., Eds.; Springe: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. Early Access. [Google Scholar] [CrossRef] [PubMed]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Aloysius, N.; Geetha, M. A review on deep convolutional neural networks. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, Tamilnadu, India, 6–8 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 0588–0592. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1520–1528. [Google Scholar] [CrossRef] [Green Version]
- Quan, T.M.; Hildebrand, D.G.C.; Jeong, W.K. FusionNet: A Deep Fully Residual Convolutional Neural Network for Image Segmentation in Connectomics. Front. Comput. Sci. 2021, 3. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Rota Bulò, S.; Porzi, L.; Kontschieder, P. In-Place Activated BatchNorm for Memory-Optimized Training of DNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: London, UK, 2018. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Khanh, T.L.B.; Dao, D.P.; Ho, N.H.; Yang, H.J.; Baek, E.T.; Lee, G.; Kim, S.H.; Yoo, S.B. Enhancing U-Net with Spatial-Channel Attention Gate for Abnormal Tissue Segmentation in Medical Imaging. Appl. Sci. 2020, 10, 5729. [Google Scholar] [CrossRef]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhloufi, M.A. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef] [Green Version]
- Cazzolato, M.; Avalhais, L.; Chino, D.; Ramos, J.; Souza, J.; Rodrigues, J., Jr.; Taina, A. FiSmo: A Compilation of Datasets from Emergency Situations for Fire and Smoke Analysis. In Proceedings of the Brazilian Symposium on Databases-SBBD, Minas Gerais, Brazil, 2–5 October 2017; pp. 213–223. [Google Scholar]
- IMAGENET. Available online: http://www.image-net.org/ (accessed on 20 November 2020).
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Veit, A.; Wilber, M.; Belongie, S. Residual Networks Behave Like Ensembles of Relatively Shallow Networks. arXiv 2016, arXiv:1605.06431. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: London, UK, 2018; pp. 3–19. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar] [CrossRef] [Green Version]
- Fidon, L.; Li, W.; Garcia-Peraza-Herrera, L.C.; Ekanayake, J.; Kitchen, N.; Ourselin, S.; Vercauteren, T. Generalised Wasserstein Dice Score for Imbalanced Multi-class Segmentation Using Holistic Convolutional Networks. In International MICCAI Brainlesion Workshop; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 64–76. [Google Scholar] [CrossRef] [Green Version]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky Loss Function for Image Segmentation Using 3D Fully Convolutional Deep Networks. In Machine Learning in Medical Imaging; Wang, Q., Shi, Y., Suk, H.I., Suzuki, K., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 379–387. [Google Scholar]
- Li, Z.; Kamnitsas, K.; Glocker, B. Analyzing Overfitting Under Class Imbalance in Neural Networks for Image Segmentation. IEEE Trans. Med. Imaging 2021, 40, 1065–1077. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 13. [Google Scholar] [CrossRef]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef] [Green Version]
- Phillips III, W.; Shah, M.; da Vitoria Lobo, N. Flame recognition in video. Pattern Recognit. Lett. 2002, 23, 319–327. [Google Scholar] [CrossRef]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The Lovász-Softmax Loss: A Tractable Surrogate for the Optimization of the Intersection-Over-Union Measure in Neural Networks. arXiv 2018, arXiv:1705.08790. [Google Scholar]
- Zhao, S.; Wang, Y.; Yang, Z.; Cai, D. Region Mutual Information Loss for Semantic Segmentation. arXiv 2019, arXiv:1910.12037. [Google Scholar]
- Ke, T.W.; Hwang, J.J.; Liu, Z.; Yu, S.X. Adaptive Affinity Fields for Semantic Segmentation. arXiv 2018, arXiv:1803.10335. [Google Scholar]
- Wang, W.; Zhou, T.; Yu, F.; Dai, J.; Konukoglu, E.; Gool, L.V. Exploring Cross-Image Pixel Contrast for Semantic Segmentation. arXiv 2021, arXiv:2101.11939. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Advantages | Disadvantages |
|---|---|---|
| VGG-based | Simple, straightforward architectures. | Large number of parameters; high computational power required. |
| Residual block-based | Address the vanishing gradient problem: allows for deeper networks. | Large-scale usage of skip connections can lead to memory problems. |
| DeepLab family | Atrous convolutions to generate high-resolution feature maps. | ASPP-based methods display a significant computational cost. |
| U-Net-based models | Designed for good performance on smaller datasets. Relatively low number of parameters. | Skip connections tend to use redundant information in low-level encoder features. |
| Metric | Value | Architecture | Loss | Image Type |
|---|---|---|---|---|
| MCC | 0.9252 | Akhloufi | Dice | Visible |
| 0.9248 | Choi | Focal Tversky | Visible | |
| 0.9231 | Akhloufi | Focal Tversky | Visible | |
| 0.9151 | Choi | Focal Tversky | FIRe-GAN | |
| 0.9140 | Akhloufi | Focal Tversky | NIR | |
| F1 | 0.9323 | Akhloufi | Dice | Visible |
| 0.9274 | Akhloufi | Focal Tversky | Visible | |
| 0.9265 | Choi | Focal Tversky | Visible | |
| 0.9176 | Choi | Focal Tversky | FIRe-GAN | |
| 0.9165 | Akhloufi | Focal Tversky | NIR | |
| HAF | 0.9098 | Akhloufi | Dice | Visible |
| 0.9068 | Choi | Focal Tversky | Visible | |
| 0.8957 | Akhloufi | Focal Tversky | Visible | |
| 0.8904 | Akhloufi | Dice | NIR | |
| 0.8892 | Akhloufi | Focal Tversky | NIR |
| Metric | Method | Value |
|---|---|---|
| MCC | Akhloufi + Focal Tversky + visible | 0.92 |
| Phillips et al. [84] | 0.81 | |
| F1 | Akhloufi + Focal Tversky + visible | 0.92 |
| Phillips et al. [84] | 0.82 | |
| HAF | Akhloufi + Focal Tversky + visible | 0.89 |
| Phillips et al. [84] | 0.75 |
| Metric | Method | Value |
|---|---|---|
| MCC | Akhloufi + Focal Tversky + visible | 0.9225 |
| AG Akhloufi + Focal Tversky + visible | 0.9241 | |
| SP Akhloufi + Focal Tversky + visible | 0.9240 | |
| MECA Akhloufi + Focal Tversky + visible | 0.9244 | |
| F1 | Akhloufi + Focal Tversky + visible | 0.9244 |
| AG Akhloufi + Focal Tversky + visible | 0.9260 | |
| SP Akhloufi + Focal Tversky + visible | 0.9258 | |
| MECA Akhloufi + Focal Tversky + visible | 0.9263 | |
| HAF | Akhloufi + Focal Tversky + visible | 0.9004 |
| AG Akhloufi + Focal Tversky + visible | 0.9016 | |
| SP Akhloufi + Focal Tversky + visible | 0.9019 | |
| MECA Akhloufi + Focal Tversky + visible | 0.9032 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ciprián-Sánchez, J.F.; Ochoa-Ruiz, G.; Rossi, L.; Morandini, F. Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation. Appl. Sci. 2021, 11, 7046. https://doi.org/10.3390/app11157046
Ciprián-Sánchez JF, Ochoa-Ruiz G, Rossi L, Morandini F. Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation. Applied Sciences. 2021; 11(15):7046. https://doi.org/10.3390/app11157046
Chicago/Turabian StyleCiprián-Sánchez, Jorge Francisco, Gilberto Ochoa-Ruiz, Lucile Rossi, and Frédéric Morandini. 2021. "Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation" Applied Sciences 11, no. 15: 7046. https://doi.org/10.3390/app11157046
APA StyleCiprián-Sánchez, J. F., Ochoa-Ruiz, G., Rossi, L., & Morandini, F. (2021). Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation. Applied Sciences, 11(15), 7046. https://doi.org/10.3390/app11157046