
Impact Sound Generation for Audiovisual Interaction with Real-World Movable Objects in Building-Scale Virtual Reality


Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- Automatic generation of indoor 3D maps—technology for creating a 3D map that faithfully reproduces the actual 3D shapes in a building.
- (2)
- Enlargement of human tracking area by deep learning—technology for tracking the pose (position and orientation) of users moving around the indoor area of a building.
- (3)
- Tracking of user’s hands by visual-inertial odometry—technology for manipulating objects with both hands in virtual space.
- (4)
- Modification of building-scale indoor scene—technology for modifying VR space in accordance with its intended usage by segmenting or replacing 3D point clouds.
- (5)
- Representation of people in the area—technology in which people are displayed in a virtual space and all of them share the same information as in real life.
- (6)
- Simulation of behaviors and phenomena—technology to simulate human behaviors and physical phenomena in virtual space.
2. Related Work
2.1. Augmented Reality and Real Walking with VR
2.2. Sound Manipulation in VR
2.3. Sound Generation in VR
2.4. Content Generation by Deep Learning Techniques
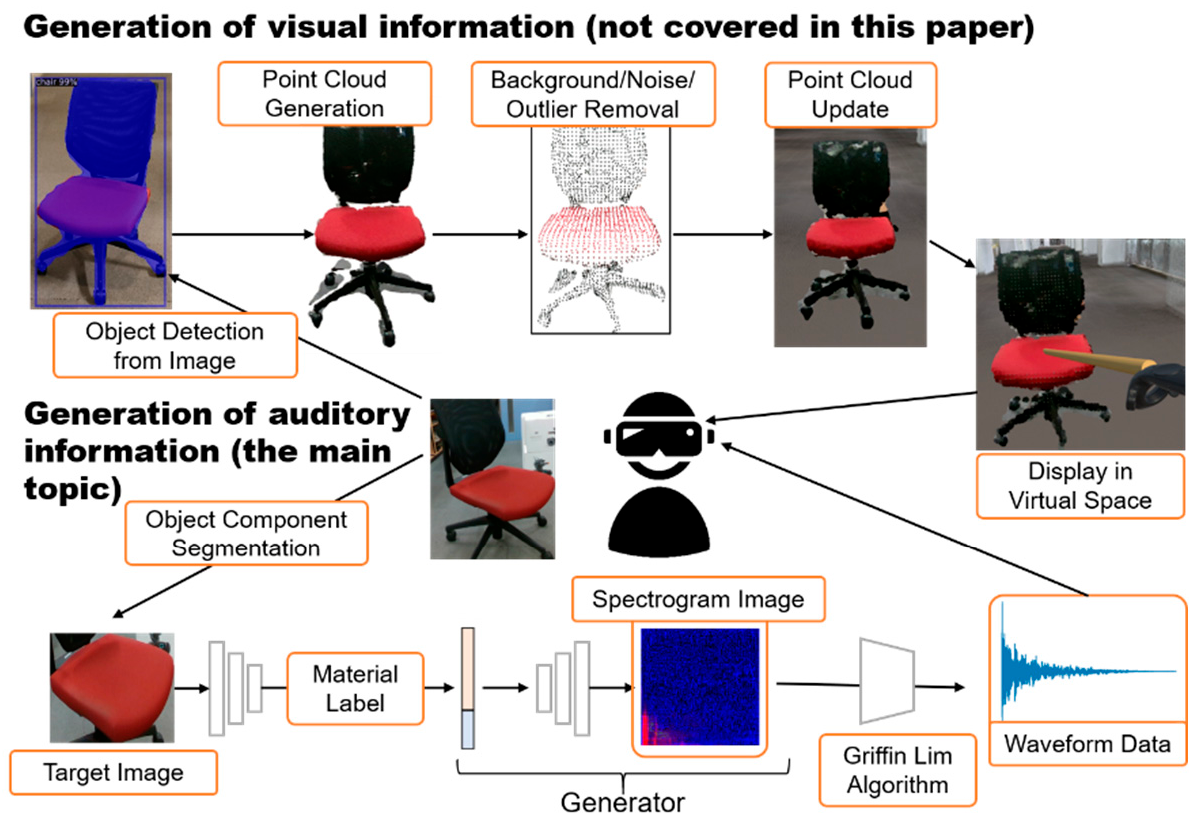
3. Audiovisual Interaction with Real-World Movable Objects
3.1. Devices
3.2. System Configuration
4. Object Segmentation into Components and Their Material Estimation
4.1. Dataset
4.2. Material Estimation
4.3. Object Component Segmentation
- (1)
- Reduce color information by grouping pixels that differ in distance and color.
- (2)
- Obtain the HSV value using a superpixel technique [28] and perform clustering using the k-means method.
- (3)
- After determining the range from the hue (H) value, based on the segmentation results, perform trimming.
4.4. Transfer Learning
5. Impact Sound Generation for Object Materials
5.1. Generative Adversarial Networks
5.2. Generation of Time-Series Data
5.3. Proposed GAN Architecture
- Introduction of residual block, from the SRResNet structure used for super-resolution image generation in Generator
- Introduction of residual block to Discriminator
- Introduction of projection to Discriminator, to improve accuracy for multi-category tasks.
5.4. Converting Sound into Spectrogram
5.5. Results of Learning
5.6. Sound Generation from Spectrogram Images
6. Experiments and Discussion
6.1. Preliminary Experiment
6.1.1. Purpose and Hypothesis
6.1.2. Subjects
6.1.3. Experimental Conditions and Processes
6.1.4. Experimental Results
6.1.5. Discussion and Suggestions for Next Experiment
6.2. Evaluation Experiment of Generated Sound
6.2.1. Difference from Preliminary Experiment
6.2.2. Subjects, Conditions, and Processes
6.2.3. Experimental Results
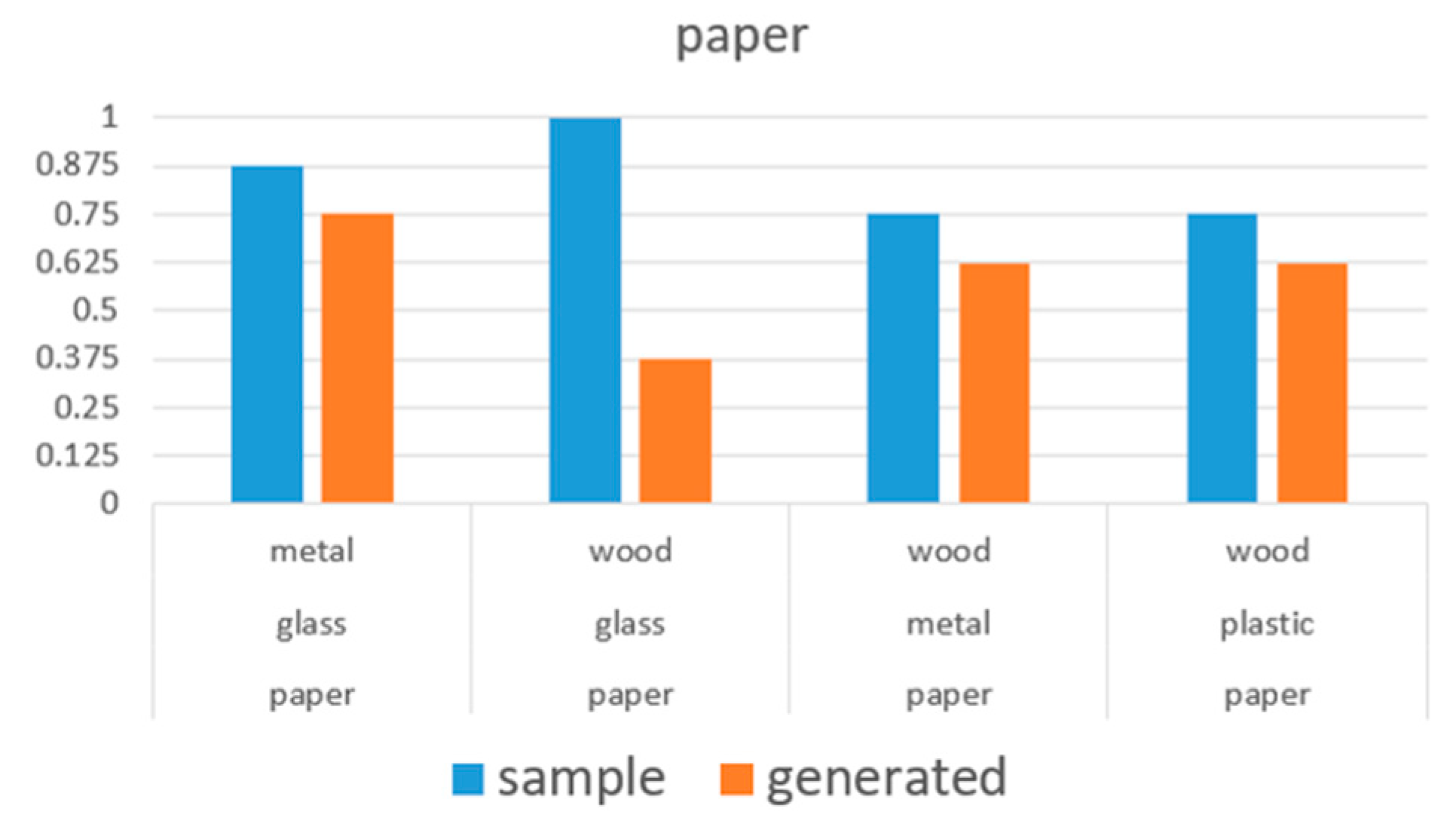
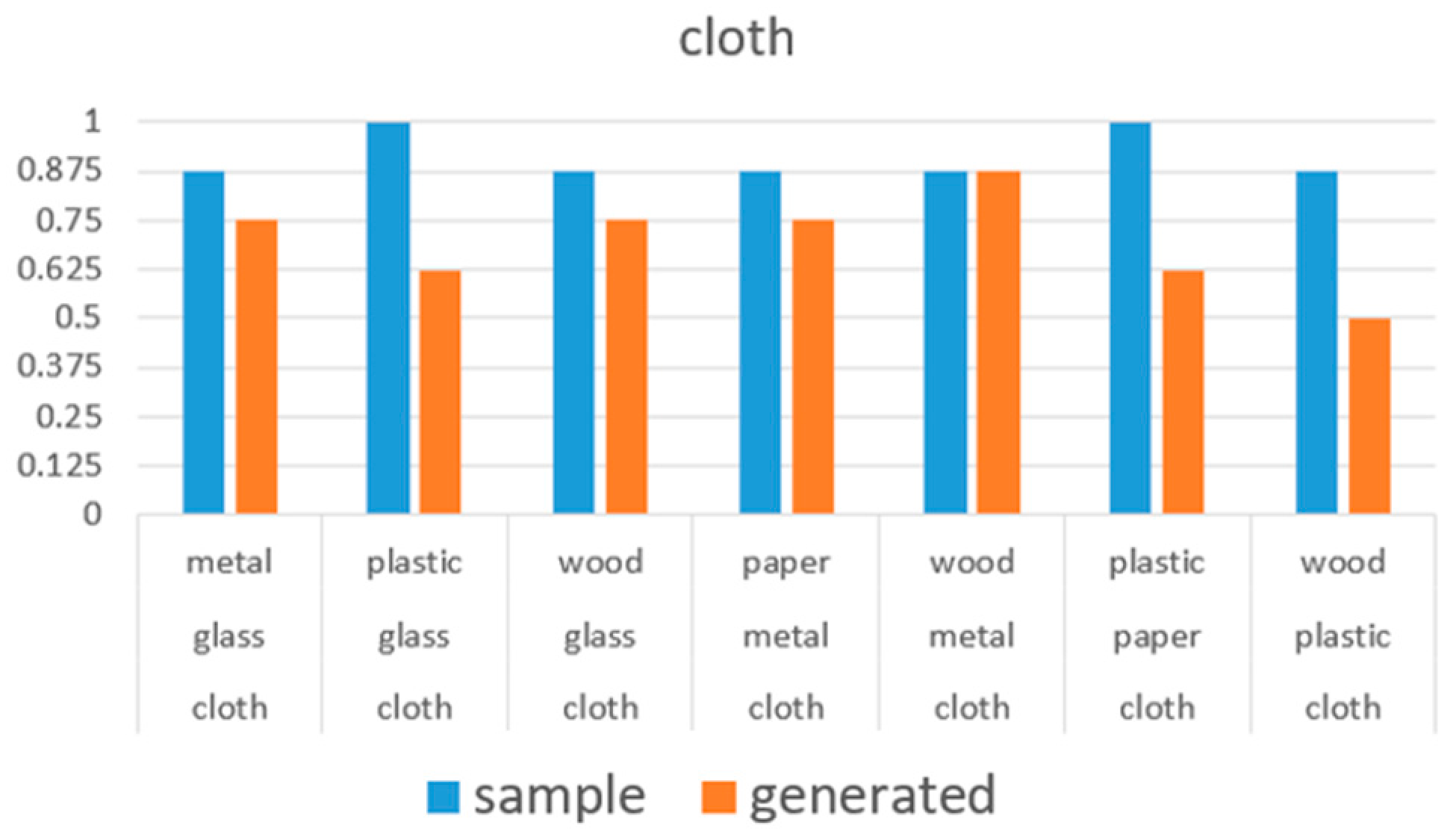
6.3. Additional Experiment on Psychoacoustic Evaluation
6.3.1. Purpose
6.3.2. Conditions and Processes
6.3.3. Results
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nagao, K.; Yang, M.; Miyakawa, Y. Building-Scale Virtual Reality: Reconstruction and Modification of Building Interior Extends Real World. Int. J. Multimed. Data Eng. Manag. 2019, 10, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Griffin, D.W.; Lim, J.S. Signal Estimation from Modified Short-Time Fourier Transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Carmigniani, J.; Furht, B.; Anisetti, M.; Ceravolo, P.; Damiani, E.; Ivkovic, M. Augmented Reality Technologies, Systems and Applications. Multimed. Tools Appl. 2011, 51, 341–377. [Google Scholar] [CrossRef]
- Akçayır, M.; Akçayır, G. Advantages and Challenges Associated with Augmented Reality for Education: A Systematic Review of the Literature. Educ. Res. Rev. 2017, 20, 1–11. [Google Scholar] [CrossRef]
- Azuma, R.; Baillot, Y.; Behringer, R.; Feiner, S.; Julier, S.; MacIntyre, B. Recent Advances in Augmented Reality. IEEE Comput. Graph. Appl. 2001, 21, 34–47. [Google Scholar] [CrossRef] [Green Version]
- Scavarelli, A.; Teather, R.J. VR collide! Comparing Collision-Avoidance Methods between Co-located Virtual Reality Users. In Proceedings of the 2017 ACM Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2915–2921. [Google Scholar]
- Sra, M.; Garrido-Jurado, S.; Maes, P. Oasis: Procedurally Generated Social Virtual Spaces from 3D Scanned Real Spaces. IEEE Trans. Vis. Comput. Graph. 2018, 24, 3174–3187. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keller, M.; Exposito, F. Game Room Map Integration in Virtual Environments for Free Walking. In Proceedings of the 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Reutlingen, Germany, 18–22 March 2018; pp. 763–764. [Google Scholar]
- Yang, J.; Holz, C.; Ofek, E.; Wilson, A.D. DreamWalker: Substituting Real-World Walking Experiences with a Virtual Reality. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New York, NY, USA, 20–23 October 2019; pp. 1093–1107. [Google Scholar]
- Fujisaki, W.; Goda, N.; Motoyoshi, I.; Komatsu, H.; Nishida, S. Audiovisual Integration in the Human Perception of Materials. J. Vis. 2014, 14, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Kern, A.C.; Ellermeier, W. Audio in VR: Effects of a Soundscape and Movement-Triggered Step Sounds on Presence. Front. Robot. AI 2020, 7, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Lahav, O.; Mioduser, D. Multisensory Virtual Environment for Supporting Blind Persons’ Acquisition of Spatial Cognitive Mapping–A Case Study. In Proceedings of the EdMedia+ Innovate Learning 2001, Association for the Advancement of Computing in Education (AACE), Tampere, Finland, 25–30 June 2001; pp. 1046–1051. [Google Scholar]
- Inman, D.P.; Loge, K.; Cram, A. Teaching Orientation and Mobility Skills to Blind Children Using Computer Generated 3D Sound Environments. In Proceedings of the 6th International Conference on Auditory Display (ICAD2000), Atlanta, GA, USA, 2–5 April 2000. [Google Scholar]
- Siu, A.F.; Sinclair, M.; Kovacs, R.; Ofek, E.; Holz, C.; Cutrell, E. Virtual Reality Without Vision: A Haptic and Auditory White Cane to Navigate Complex Virtual Worlds. In Proceedings of the 2020 ACM Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Rausch, D. Modal Sound Synthesis for Interactive Virtual Environments. Ph.D. Thesis, RWTH Aachen University, Aachen, Germany, 2017. [Google Scholar]
- Cirio, G.; Li, D.; Grinspun, E.; Otaduy, M.A.; Zheng, C. Crumpling Sound Synthesis. ACM Trans. Graph. 2016, 35, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Ban, Y.; Ujitoko, Y. TactGAN: Vibrotactile Designing Driven by GAN-based Automatic Generation. In Proceedings of the SIGGRAPH Asia 2018 Emerging Technologies, Tokyo, Japan, 4 December 2018; pp. 1–2. [Google Scholar]
- Chris, D.; McAuley, J.; Puckette, M. Adversarial Audio Synthesis. arXiv 2018, arXiv:1802.04208. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Adv. Neural Inf. Process. Syst. 2017, 30, 5099–5108. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Owens, A.; Isola, P.; McDermott, J.; Torralba, A.; Adelson, E.H.; Freeman, W.T. Visually Indicated Sounds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2405–2413. [Google Scholar]
- Farnebäck, G. Two-Frame Motion Estimation Based on Polynomials. In Proceedings of the Scandinavian Conference on Image Analysis, Halmstad, Sweden, 29 June–3 July 2003; Springer: Berlin/Heidelberg, Germany; pp. 363–370. [Google Scholar]
- Xue, J.; Zhang, H.; Dana, K. Deep Texture Manifold for Ground Terrain Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 558–567. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Tenenbaum, J.B.; Freeman, W.T. Separating Style and Content with Bilinear Models. Neural Comput. 2000, 12, 1247–1283. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2281. [Google Scholar] [CrossRef] [Green Version]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. Adv. Neural Inf. Process. Syst. 2017, 30, 5767–5777. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A Learned Representation for Artistic Style. arXiv 2016, arXiv:1610.07629. [Google Scholar]
- Miyato, T.; Koyama, M. cGANs with Projection Discriminator. arXiv 2018, arXiv:1802.05637. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On Convergence and Stability of GANs. arXiv 2017, arXiv:1705.07215. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6626–6637. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Paolis, D.; Tommaso, L.; Bourdot, P.; Mongelli, A. Audio-Visual Perception—The Perception of Object Material in a Virtual Environment. In Proceedings of the International Conference on Augmented Reality, Virtual Reality, and Computer Graphics, Ugento, Italy, 12–15 July 2017; pp. 12–15. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Hatano, S.; Hashimoto, T. Booming Index as a Measure for Evaluating Booming Sensation. In Proceedings of the 29th International Congress and Exhibition on Noise Control Engineering, Nice, France, 27–30 August 2000. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Material | Number |
|---|---|
| plastic | 2029 |
| drywall | 912 |
| metal | 3926 |
| wood | 4485 |
| carpet | 913 |
| plastic-bag | 901 |
| cloth | 1986 |
| paper | 1712 |
| rock | 2736 |
| leaf | 2515 |
| gravel | 905 |
| glass | 874 |
| tile | 914 |
| ceramic | 910 |
| dirt | 3277 |
| grass | 980 |
| water | 982 |
| Material | Object 1 | Object 2 | Object 3 |
|---|---|---|---|
| cloth | 0.15 | ||
| glass | 0.85 | 0.48 | |
| metal | 0.05 | 0.05 | |
| paper | 0.10 | ||
| plastic | 0.15 | 0.36 | 0.48 |
| wood | 0.31 |
| Material | Cloth | Glass | Metal | Paper | Plastic | Wood |
|---|---|---|---|---|---|---|
| Example Images |  |  |  |  |  |  |
 |  |  |  |  |  | |
| Number | 3970 | 1090 | 1680 | 1290 | 1940 | 1470 |
| Material | Original | Transfer Learning |
|---|---|---|
| cloth | 0.85 | 0.99 |
| glass | 0.0 | 0.96 |
| metal | 0.11 | 0.93 |
| paper | 0.65 | 0.95 |
| plastic | 0.29 | 0.88 |
| wood | 0.38 | 0.99 |
| Model | FID |
|---|---|
| Proposed Method (Residual Block + SE Block) | 17.6590 |
| Residual Block | 20.1736 |
| TactGAN | 63.2101 |
| DCGAN | 37.8643 |
| WaveGAN | 22.3209 |
| Actual Class | Accuracy |
|---|---|
| cloth | 0.80 |
| glass | 0.61 |
| metal | 0.73 |
| paper | 0.67 |
| plastic | 0.51 |
| wood | 0.63 |
| Actual Class | Patterns |
|---|---|
| cloth | glass-metal, glass-plastic, glass-wood, metal-paper, metal-wood, paper-plastic, plastic-wood |
| glass | cloth-metal, cloth-paper, metal-paper, metal-wood |
| metal | cloth-paper, cloth-plastic, cloth-wood, glass-paper, paper-plastic, paper-wood |
| paper | glass-metal, glass-wood, metal-wood, paper-wood |
| plastic | cloth-glass, cloth-paper, cloth-wood, glass-paper |
| wood | cloth-metal, glass-plastic, metal-paper, metal-plastic |
| Subject | Accuracy of All Materials |
|---|---|
| A | 0.828 |
| B | 0.828 |
| C | 0.828 |
| D | 0.862 |
| E | 0.724 |
| F | 0.859 |
| G | 0.931 |
| H | 0.682 |
| I | 0.931 |
| J | 0.897 |
| Material | Accuracy | Difference from Preliminary Experiment |
|---|---|---|
| cloth | 0.696 | −0.161 |
| glass | 0.719 | −0.219 |
| metal | 0.667 | −0.208 |
| paper | 0.594 | −0.25 |
| plastic | 0.656 | −0.156 |
| wood | 0.689 | −0.156 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagao, K.; Kumon, K.; Hattori, K. Impact Sound Generation for Audiovisual Interaction with Real-World Movable Objects in Building-Scale Virtual Reality. Appl. Sci. 2021, 11, 7546. https://doi.org/10.3390/app11167546
Nagao K, Kumon K, Hattori K. Impact Sound Generation for Audiovisual Interaction with Real-World Movable Objects in Building-Scale Virtual Reality. Applied Sciences. 2021; 11(16):7546. https://doi.org/10.3390/app11167546
Chicago/Turabian StyleNagao, Katashi, Kaho Kumon, and Kodai Hattori. 2021. "Impact Sound Generation for Audiovisual Interaction with Real-World Movable Objects in Building-Scale Virtual Reality" Applied Sciences 11, no. 16: 7546. https://doi.org/10.3390/app11167546