
Classification of Electricity Consumption Behavior Based on Improved K-Means and LSTM


Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- A framework for intelligent classification of electricity consumption behavior based on improved k-means and LSTM is proposed, which can judge users’ electricity consumption behavior accurately.
- (2)
- An improved k-means clustering method is introduced to set labels for scattered and irregular original data, and the initial k value and initial clustering centers of the k-means algorithm are optimized intelligently.
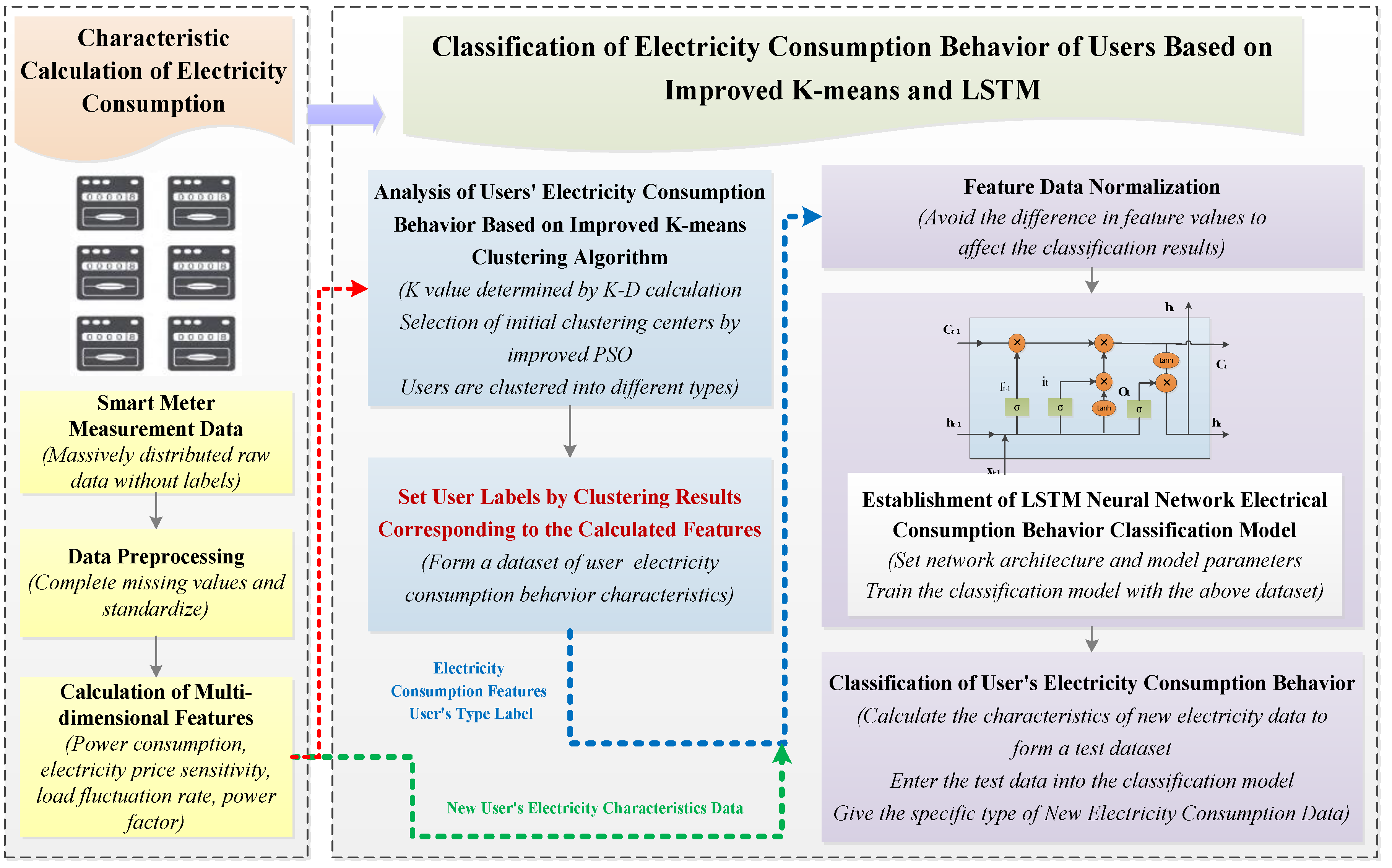
2. The Framework of Electricity Consumption Behavior Classification Based on Improved K-Means and LSTM
- Data acquisition: The electricity consumption data of a certain period were acquired by smart meters. Then, the incomplete data in the original data were replaced with values (average or median) close to the center of the sample attribute. In order to avoid the impact of data differentiation, the above preprocessed data were normalized.
- Feature selection: Multi-dimensional features were calculated based on the preprocessed data, which included electricity consumption, electricity price sensitivity, load fluctuation rate, and power factor.
- Cluster analysis: Referring to the calculated features, we performed a preliminary clustering of users. In order to improve the performance of clustering, the traditional k-means algorithm was improved.
- Training classification model: We initialized the LSTM network structure and selected model parameters. Based on the results of clustering, the users’ labels were set. Together with the calculated features, the electricity consumption behavior dataset was formed, which was used as an input to train the LSTM classification model, and then the trained model parameters were saved.
- Evaluation of classification results: We obtained new electricity consumption data from smart meters and calculated features through the same steps as above. Then, we input the new features into the trained LSTM, and output the classification results to judge the users’ electricity consumption behavior. Finally, the performance of the model was evaluated, and the classification results of other models were compared.
3. Analysis Method of Users’ Electricity Consumption Behavior
3.1. Multi-Dimensional Feature Extraction
- Electricity consumption characteristics.
- Sensitivity of electricity price.
- Load fluctuation rate.
- Power factor.
3.2. Optimization of K Value
3.3. Optimization of Initial Clustering Centers
3.4. LSTM Classification Model
4. Case Analysis Results
4.1. Analysis of Electricity Consumption Behavior
4.2. Classification of Electricity Consumption Feature
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Wang, B.; Li, F. Prospect and thinking of flexible and interactive intelligent power consumption. Autom. Electr. Power Syst. 2015, 39, 2–9. [Google Scholar] [CrossRef]
- Zhu, W.; Wang, Y.; Luo, M.; Lin, G.; Cheng, J.; Kang, C. Distributed clustering algorithm for mass user power characteristics perception. Power Syst. Autom. 2016, 40, 21–27. [Google Scholar] [CrossRef]
- Liu, K.; Sheng, W.; Zhang, D.; Jia, D.; Hu, L.; He, K. Research on application requirements and scenario analysis of smart distribution network big data. Chin. J. Electr. Eng. 2015, 35, 287–293. [Google Scholar] [CrossRef]
- Lu, J.; Zhu, Y.; Peng, W.; Sun, Y. Feature optimization strategy for intelligent power user behavior analysis. Power Syst. Autom. 2017, 41, 58–63, 83. [Google Scholar] [CrossRef]
- Zhou, B.; Liu, B.; Wang, D.; Lan, Y.; Ma, X.; Sun, D.; Huo, Q. Cluster analysis of user interaction electricity consumption behavior based on self-organizing center K-means algorithm. Electr. Power Constr. 2019, 40, 68–76. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, Y.; Yang, L. Analysis of electricity consumption behavior based on PCA and fuzzy clustering. Data Commun. 2020, 2, 36–40. [Google Scholar] [CrossRef]
- Li, C.; Cai, W.; Zhao, R.; Yu, Q.; Zhang, Q. Analysis of AP cluster user electricity consumption behavior based on optimized SAX and weighted load characteristic index. J. Electr. Eng. 2019, 34, 368–377. [Google Scholar] [CrossRef]
- Li, Y.; Tao, S.; Zhao, L.; Guo, A. Load forecasting based on short time scale correlation clustering. Electr. Meas. Instrum. 2019, 56, 32–38. [Google Scholar] [CrossRef]
- Qian, C.; Chen, M.; Gao, C.; Li, H.; Shen, T. Research on the analysis of user’s electricity behavior and the application of demand response based on global energy interconnection. In Proceedings of the 2016 China International Conference on Electricity Distribution (CICED), Xi’an, China, 10–13 August 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Cong, X.; Su, H.; Li, H.; Wang, B. Research on personalized smart electricity package based on data mining and demand response. Power Demand Side Manag. 2019, 21, 21–25. [Google Scholar]
- Zhu, T.; Ai, Q.; Li, Z.; He, X. Research on a data-driven analysis model of electricity consumption behavior. Electr. Appl. Energy Effic. Manag. Technol. 2019, 19, 91–100. [Google Scholar] [CrossRef]
- Ou, J.; Cao, X.; Zhang, J.; Ding, C. Research on electric power customer segmentation based on hybrid neural network. Comput. Digit. Eng. 2019, 47, 689–695. [Google Scholar]
- Xin, M.; Zhang, Y.; Xie, D. A review of research on consumer electricity behavior analysis based on power big data. Electr. Autom. 2019, 41, 1–4. [Google Scholar]
- Zhang, S.; Liu, J.; Zhao, B.; Cao, J. Research on analysis model of residential electricity consumption based on cloud computing. Power Grid Technol. 2013, 37, 1542–1546. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, P.; Gao, Y.; Xu, J.; Sun, H. Research on user index system and algorithm of power market users from a regulatory perspective. China Electr. Power 2018, 12, 139–148. [Google Scholar]
- Bai, M.; Tang, W.; Wu, B. User-side comprehensive energy system evaluation index system and its application. Distrib. Energy 2018, 3, 41–46. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, W.; Su, Y. Power user classification based on functional data analysis and k-means algorithm. Power Grid Technol. 2015, 39, 3153–3162. [Google Scholar] [CrossRef]
- Nuchprayoon, S. Electricity load classification using K-means clustering algorithm. In Proceedings of the 5th Brunei International Conference on Engineering & Technology, Bandar Seri Begawan, Brunei, 1–3 November 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Li, L.; Wang, J.; He, Y.; Zhan, P.; Liu, F.; Tang, Y. Multi-point PV-DG day-to-day distribution plan based on K-means clustering particle swarm optimization algorithm. High Volt. Technol. 2017, 43, 1263–1270. [Google Scholar] [CrossRef]
- Xie, X.; Li, T. A K-means optimization clustering algorithm based on improved PSO. Comput. Technol. Dev. 2014, 24, 34–38. [Google Scholar]
- Fu, T.; Sun, Y. PSO-based k-means algorithm and its application in network intrusion detection. Comput. Sci. 2011, 38, 54–55, 73. [Google Scholar]
- Sun, Y.; Zhang, L.; Zhao, H.; Liu, Y.; Li, B.; Li, D.; Cui, G. Non-intrusive household load decomposition method based on dynamic adaptive particle swarm optimization. Power Grid Technol. 2018, 42, 1819–1826. [Google Scholar] [CrossRef]
- Huang, Q.; Yang, S.; Deng, X.; Chen, H.; Wang, S. Classification and analysis method of user power consumption behavior based on under-complete self-encoder. Electr. Power Eng. Technol. 2019, 38, 24–30. [Google Scholar]
- Xu, W. Research and analysis of customer demand response based on artificial intelligence. Power Demand Side Manag. 2019, 21, 17–20, 31. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J. Recurrent nets that time and count. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27 July 2000; pp. 189–194. [Google Scholar] [CrossRef]
- Liu, Y.; Hua, J.; Li, X.; Fu, T.; Wu, X. Chinese syllable-to-character conversion with recurrent neural network based supervised sequence labelling. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 350–353. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Electricity Consumption | Peak | Valley | Flat |
|---|---|---|---|
| Time | 8:00–12:00 17:00–21:00 | 5:00–8:00 12:00–17:00 21:00–22:00 | 22:00–05:00 |
| Price | 1.2 | 0.8 | 0.4 |
| Type | A | SS | ST1 | ST2 | ST3 | DPN | MSE | RMP | MINFP |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 148,724.90 | 691.05 | 887.60 | 3028.27 | 2028.09 | 500.17 | 151.60 | 1,736,617.25 | 0.69 |
| 2 | 2.73 | 0.00 | 0.03 | 0.05 | 0.03 | 0.02 | 0.00 | 0.00 | 0.48 |
| 3 | 150.48 | 0.25 | 1.01 | 3.16 | 1.70 | 1.14 | 0.29 | 26.64 | 0.61 |
| 4 | 1438.09 | 10.28 | 8.55 | 28.23 | 20.87 | 6.98 | 1.94 | 630.46 | 0.56 |
| 5 | 22,811.29 | 112.37 | 178.13 | 471.28 | 243.09 | 84.79 | 24.88 | 220,706.65 | 0.48 |
| Type | A | SS | ST1 | ST2 | ST3 | DPN | MSE | RMP | MINFP |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 139,238.99 | 726.53 | 795.37 | 2907.16 | 1929.18 | 476.91 | 144.38 | 1,457,026.12 | 0.75 |
| 2 | 103,531.74 | 436.17 | 827.64 | 2107.28 | 1116.34 | 357.39 | 106.10 | 1,314,510.43 | 0.68 |
| 3 | 131.84 | 0.33 | 0.95 | 2.61 | 1.62 | 0.92 | 0.24 | 7.77 | 0.67 |
| 4 | 1401.43 | 9.92 | 20.16 | 22.43 | 10.43 | 17.08 | 4.03 | 9224.87 | 0.67 |
| 5 | 1491.33 | 10.61 | 8.88 | 29.32 | 21.60 | 7.05 | 1.98 | 548.61 | 0.90 |
| Type | A | SS | ST1 | ST2 | ST3 | DPN | MSE | RMP | MINFP |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 160,102.23 | 688.09 | 894.54 | 3094.59 | 2035.40 | 501.63 | 152.03 | 1,732,439.39 | 0.68 |
| 2 | 2.95 | 0.00 | 0.03 | 0.05 | 0.03 | 0.02 | 0.00 | 0.00 | 0.82 |
| 3 | 160.85 | 0.24 | 1.02 | 3.15 | 1.70 | 1.13 | 0.29 | 24.17 | 0.68 |
| 4 | 1541.06 | 10.28 | 8.52 | 28.26 | 20.88 | 6.99 | 1.94 | 640.59 | 1.00 |
| 5 | 23,964.09 | 111.05 | 174.16 | 462.87 | 238.34 | 83.37 | 24.49 | 217,997.52 | 0.81 |
| Type | A | SS | ST1 | ST2 | ST3 | DPN | MSE | RMP | MINFP |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 147,504.50 | 725.86 | 784.20 | 2874.68 | 1910.23 | 472.74 | 143.19 | 1,440,424.00 | 0.62 |
| 2 | 113,077.80 | 436.06 | 842.00 | 2149.86 | 1139.75 | 362.00 | 107.54 | 1,330,185.00 | 0.67 |
| 3 | 140.18 | 0.32 | 0.94 | 2.59 | 1.61 | 0.92 | 0.24 | 7.79 | 0.70 |
| 4 | 1582.28 | 10.55 | 8.82 | 28.95 | 21.43 | 7.01 | 1.96 | 539.64 | 0.62 |
| 5 | 1516.08 | 10.02 | 20.24 | 22.75 | 10.56 | 17.08 | 4.03 | 9265.71 | 0.62 |
| Evaluation | K-Means | PSO-K | PSO-KD |
|---|---|---|---|
| Silhouette Index (SI) | 0.5644 | 0.6434 | 0.6345 |
| Time (T/s) | 17,263.3 | 39,736.62 | 10,274.02 |
| User Type | Label | Quarter | Label |
|---|---|---|---|
| 1 | 001 | 1 | 001 |
| 2 | 010 | 2 | 010 |
| 3 | 100 | 3 | 100 |
| 4 | 101 | 4 | 101 |
| 5 | 111 |
| Classifier | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| LSTM | 96.71% | 95.15% | 98% | 96.65% |
| SVM | 90.85% | 90.15% | 95% | 90.81% |
| KNN | 83.53% | 80.32% | 88.82% | 84.36% |
| ELM | 86.47% | 86.74% | 90.83% | 88.74% |
| BP | 73.53% | 67.07% | 98.24% | 79.71% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Hu, B.; Liu, Y.; Yang, B.; Liu, X.; Li, G.; Wang, Z.; Zhou, B. Classification of Electricity Consumption Behavior Based on Improved K-Means and LSTM. Appl. Sci. 2021, 11, 7625. https://doi.org/10.3390/app11167625
Li H, Hu B, Liu Y, Yang B, Liu X, Li G, Wang Z, Zhou B. Classification of Electricity Consumption Behavior Based on Improved K-Means and LSTM. Applied Sciences. 2021; 11(16):7625. https://doi.org/10.3390/app11167625
Chicago/Turabian StyleLi, Hua, Bo Hu, Yubo Liu, Bo Yang, Xuefang Liu, Guangdi Li, Zhenyu Wang, and Bowen Zhou. 2021. "Classification of Electricity Consumption Behavior Based on Improved K-Means and LSTM" Applied Sciences 11, no. 16: 7625. https://doi.org/10.3390/app11167625