
Factors Behind the Effectiveness of an Unsupervised Neural Machine Translation System between Korean and Japanese



Abstract
:1. Introduction
- We propose a new method to analyze cross-attentions of an encoder–decoder architecture considering the difference in properties between a source and target sequence.
- We apply the analysis method to an unsupervised NMT task between Korean and Japanese, which are known to be very similar each other.
- We demonstrate how similar Korean and Japanese are in terms of machine translation by examining cross-attentions of an encoder–decoder on which the unsupervised NMT between both languages is implemented.
2. Related Studies
2.1. MASS
2.2. Unsupervised NMT
3. Pre-Trained Models and Unsupervised NMTs
3.1. Datasets and Pre-Training Setup
3.1.1. Monolingual Corpora
- (K)
- The Korean corpus is collected from the Korean Contemporary Corpus of Written Sentences (http://nlp.kookmin.ac.kr/kcc/, accessed on 19 August 2021). To not only maximize lexical overlap with the English corpus but also minimize lexical overlap with Japanese corpus, we collect sentences including as many alphabets and digits as possible, but not Chinese characters. They are tokenized using the ETRI parser (https://aiopen.etri.re.kr/service_api.php, accessed on 19 August 2021).
- (J)
- The Japanese corpus is collected from WMT2019 (https://www.statmt.org/wmt19/translation-task.html, accessed on 19 August 2021) and JParaCrawl [14]. To minimize lexical overlap with the Korean corpus, we only collect sentences with neither alphabets nor digits. They are tokenized using the Mecab tokenizer (https://taku910.github.io/mecab/, accessed on 19 August 2021).
- (E)
- The English corpus is collected from WMT 2017-2019 datasets (https://www.statmt.org/wmt17/translation-task.html; https://www.statmt.org/wmt18/translation-task.html; https://www.statmt.org/wmt19/translation-task.html, accessed on 19 August 2021), and those sentences are tokenized by the Moses tokenizer (https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl, accessed on 19 August 2021) for pre-processing.
3.1.2. Parallel Corpora
3.2. Pre-Trained Models and Unsupervised NMTs
4. Analysis and Discussion
4.1. Analysis Objectives
- Are word embeddings of fine-tuned NMT models located appropriately in a vector space according to their meanings?
- Can word embeddings shift in a vector space appropriately when they are recalculated through self-attention layers of an encoder?
- We assume that cross-attention layers between an encoder and a decoder reflect syntactical differences between the two languages in a certain way. Can we measure the language differences by analyzing cross-attentions between an encoder and a decoder?
4.2. Analysis of Cross-Word Embeddings
4.2.1. Word Translation: Cross-Lingual Alignment of Word Embeddings
4.2.2. Sentence-Translation Retrieval
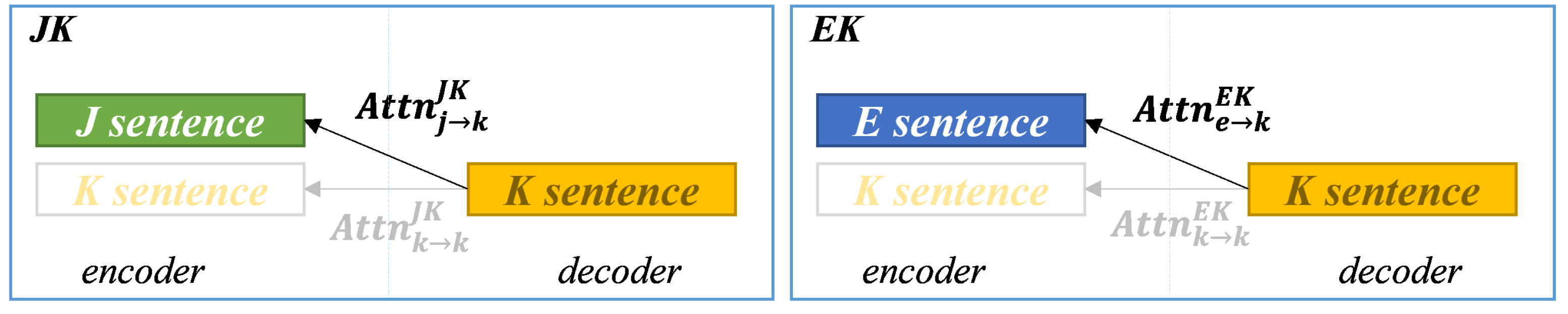
4.3. Analysis of Cross-Attentions
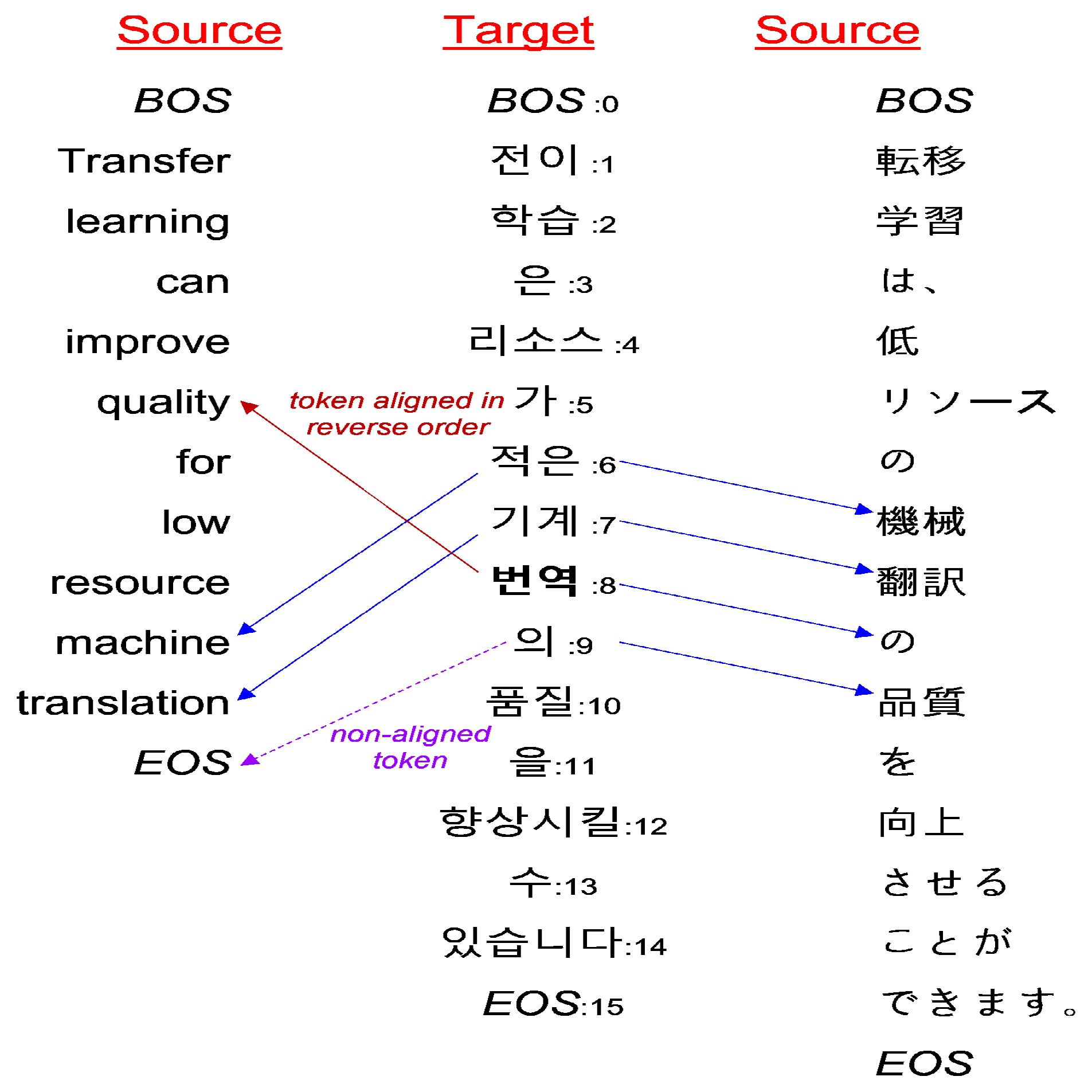
4.3.1. Cross-Attention between the Same Sentences
4.3.2. Cross-Attention between the Different Languages
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| BOS | Begin of Sentence |
| BPE | Byte Pair Encoding |
| EOS | End of Sentence |
| GPT | Generative Pre-trained Transformer |
| MASS | Masked Sequence-to-Sequence |
| MUSE | Multilingual Unsupervised and Supervised Embeddings |
| NMT | Neural Machine Translation |
References
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. MASS: Masked Sequence to Sequence Pre-training for Language Generation. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5926–5936. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Han, J.Y.; Oh, T.H.; Jin, L.; Kim, H. Annotation Issues in Universal Dependencies for Korean and Japanese. In Proceedings of the Fourth Workshop on Universal Dependencies (UDW 2020); Association for Computational Linguistics: Barcelona, Spain, 2020; pp. 99–108. [Google Scholar]
- Brown, L.; Yeon, J. The Handbook of Korean Linguistics; Wiley-Blackwell: Hoboken, NJ, USA, 2015. [Google Scholar]
- Murphy, E. The Oscillatory Nature of Language; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Radford, A.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Zhang, W.; Li, X.; Yang, Y.; Dong, R. Pre-Training on Mixed Data for Low-Resource Neural Machine Translation. Information 2021, 12, 133. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Yang, Y.; Dong, R.; Luo, G. Keeping Models Consistent between Pretraining and Translation for Low-Resource Neural Machine Translation. Future Internet 2020, 12, 215. [Google Scholar] [CrossRef]
- Artetxe, M.; Labaka, G.; Agirre, E.; Cho, K. Unsupervised Neural Machine Translation. arXiv 2017, arXiv:1710.11041. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. arXiv 2015, arXiv:1511.06709. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Morishita, M.; Suzuki, J.; Nagata, M. JParaCrawl: A Large Scale Web-Based English-Japanese Parallel Corpus. arXiv 2019, arXiv:1911.10668. [Google Scholar]
- Lee, K.J.; Lee, S.; Kim, J.E. A Bidirectional Korean–Japanese Statistical Machine Translation System by Using MOSES. J. Adv. Mar. Eng. Technol. 2012, 36, 683–693. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Conneau, A.; Lample, G.; Ranzato, M.; Denoyer, L.; Jégou, H. Word Translation Without Parallel Data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Liu, L.; Utiyama, M.; Finch, A.M.; Sumita, E. Neural Machine Translation with Supervised Attention. arXiv 2016, arXiv:1609.04186. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language Pair for Pre-Training | The Number of Voc. in Monolingual Lexicon | The Number of Shared Voc./The Number of Voc. in Joint Lexicon (the Ration) |
|---|---|---|
| Korean–Japanese | Korean: 37,670 | 33/75,147 |
| Japanese: 37,510 | (0.089%) | |
| Korean–English | Korean: 47,805 | 20,174/65,176 |
| English: 38,085 | (30.9%) |
| Hyperparameters | Values |
|---|---|
| architecture | Transformer |
| (encoder 6 layers, decoder 6 layers) | |
| embedding dim. | 1024 |
| hidden layer dim. | 1024 |
| feed-forward dim. | 4096 |
| attention head | 8 |
| activation function | Gelu |
| optimizer | Adam |
| scheduler | inverse sqrt |
| initial learning rate | |
| beta1, beta2 | 0.9, 0.98 |
| dropout | 0.1 |
| mini-batch size | 3000 tokens (pre-trained model) |
| 2000 tokens (supervised/unsupervised NMT) |
| Language Pairs | Models | BLEU Scores | ||
|---|---|---|---|---|
| Based on Pre-Trained Models | Supervised NMT | |||
| Unsupervised NMT | Supervised NMT | |||
| Korean–Japanese (KO-JA) | JA → KO | 32.76 | 51.69 | 48.12 |
| KO → JA | 29.07 | 41.96 | 41.02 | |
| Korean–English (KO-EN) | EN → KO | 3.62 | 30.14 | 21.83 |
| KO → EN | 1.10 | 27.13 | 19.49 | |
| MASS Encoder | ||||
|---|---|---|---|---|
| Models | JA → KO | KO → JA | EN → KO | KO → EN |
| Unsupervised NMT | 13.49 | 7.31 | 4.92 | 1.27 |
| Supervised NMT | 8.37 | 4.83 | 3.61 | 0.73 |
| Models | Embeddings | MASS Encoder | |
|---|---|---|---|
| JA → KO | EN → KO | ||
| Unsupervised NMT | Initial embeddings | 6.10 | 1.05 |
| Final embeddings | 20.90 | 2.95 | |
| Supervised NMT | Initial embeddings | 1.15 | 0.90 |
| Final embeddings | 76.85 | 40.20 | |
| Cross Attentions | Models | ||
|---|---|---|---|
| Aligned in the reverse order | Pre-trained Model | 0.204% | 3.715% |
| Unsupervised NMT | 0.109% | 0.527% | |
| Supervised NMT | 0.514% | 3.825% | |
| Non-aligned | Pre-trained Model | 0.157% | 4.808% |
| Unsupervised NMT | 8.599% | 6.789% | |
| Supervised NMT | 10.346% | 18.366% | |
| Aligned in the reverse order + Non-aligned | Pre-trained Model | 0.691% | 8.523% |
| Unsupervised NMT | 9.447% | 8.353% | |
| Supervised NMT | 11.955% | 30.874% |
| Cross Attentions | Models | ||
|---|---|---|---|
| Aligned in the reverse order | Pre-trained Model | 0.992% | 3.284% |
| Unsupervised NMT | 0.703% | 2.069% | |
| Supervised NMT | 0.992% | 7.256% | |
| Non-aligned | Pre-trained Model | 2.112% | 8.126% |
| Unsupervised NMT | 10.078% | 18.917% | |
| Supervised NMT | 12.099% | 16.095% | |
| Aligned in the reverse order + Non-aligned | Pre-trained Model | 4.446% | 14.202% |
| Unsupervised NMT | 12.055% | 25.027% | |
| Supervised NMT | 14.651% | 41.279% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, Y.-S.; Park, Y.-H.; Yun, S.; Kim, S.-H.; Lee, K.-J. Factors Behind the Effectiveness of an Unsupervised Neural Machine Translation System between Korean and Japanese. Appl. Sci. 2021, 11, 7662. https://doi.org/10.3390/app11167662
Choi Y-S, Park Y-H, Yun S, Kim S-H, Lee K-J. Factors Behind the Effectiveness of an Unsupervised Neural Machine Translation System between Korean and Japanese. Applied Sciences. 2021; 11(16):7662. https://doi.org/10.3390/app11167662
Chicago/Turabian StyleChoi, Yong-Seok, Yo-Han Park, Seung Yun, Sang-Hun Kim, and Kong-Joo Lee. 2021. "Factors Behind the Effectiveness of an Unsupervised Neural Machine Translation System between Korean and Japanese" Applied Sciences 11, no. 16: 7662. https://doi.org/10.3390/app11167662
APA StyleChoi, Y.-S., Park, Y.-H., Yun, S., Kim, S.-H., & Lee, K.-J. (2021). Factors Behind the Effectiveness of an Unsupervised Neural Machine Translation System between Korean and Japanese. Applied Sciences, 11(16), 7662. https://doi.org/10.3390/app11167662