
Soft Sensor Transferability: A Survey




Abstract
:1. Introduction
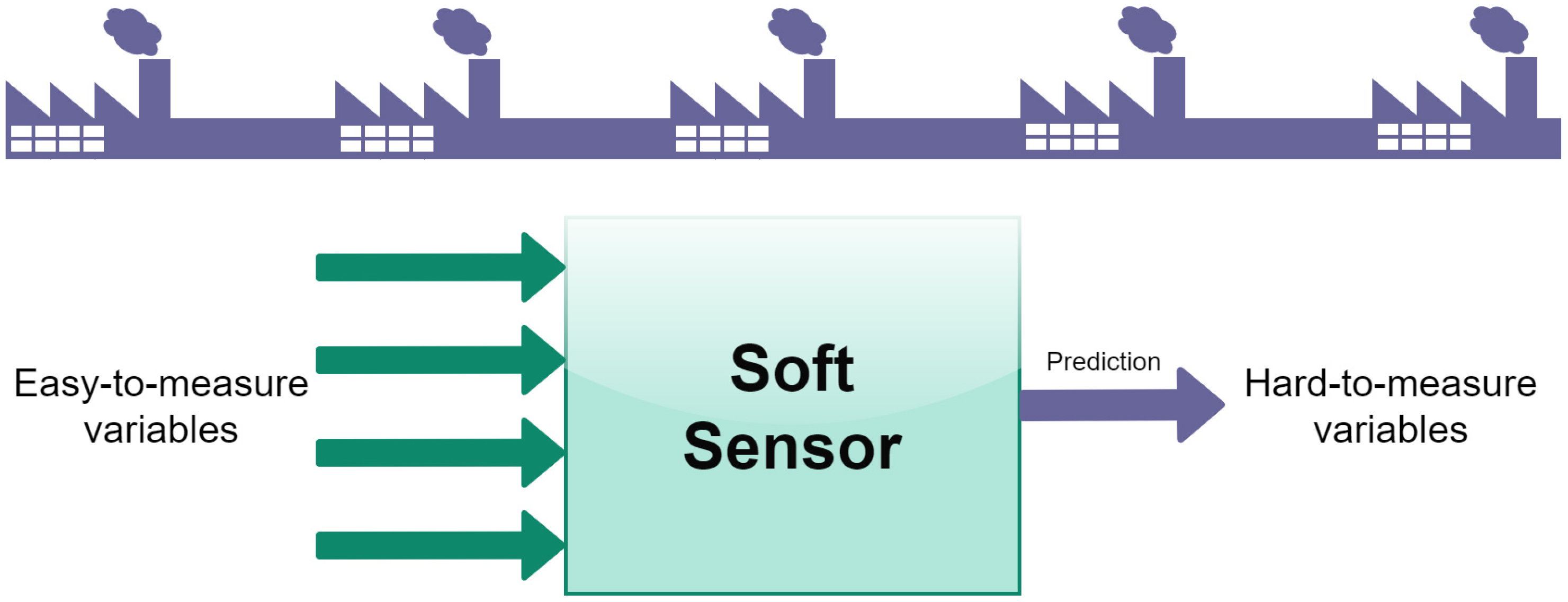
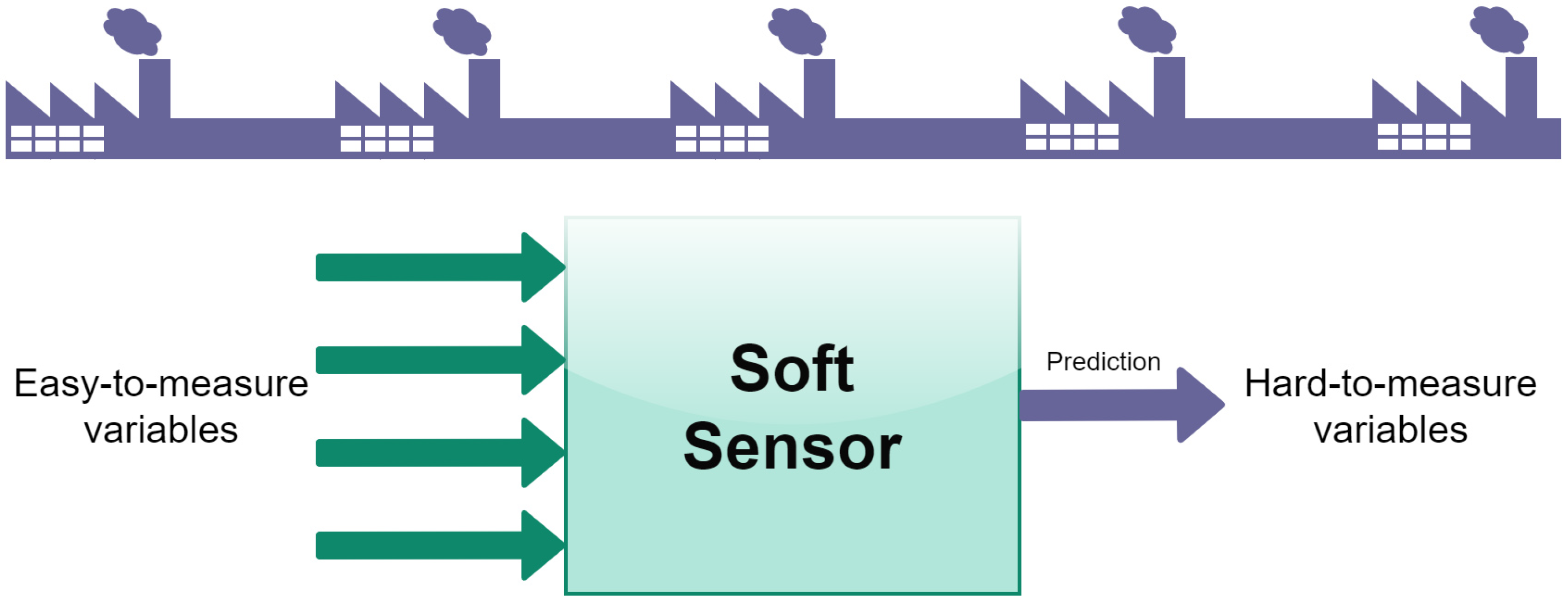
2. Soft Sensors
- Data collection and filtering;
- Input variables selection;
- Model choice;
- Model identification;
- Model validation.
- FIR, characterized by the following regression vector:with d and m being the delay of the samples;
- ARX, characterized by the following regression vector:where l is the maximum delay needed for the output variables;
- ARMAX, characterized by the following regression vector:where is the model residual and k is the associated maximum time delay.
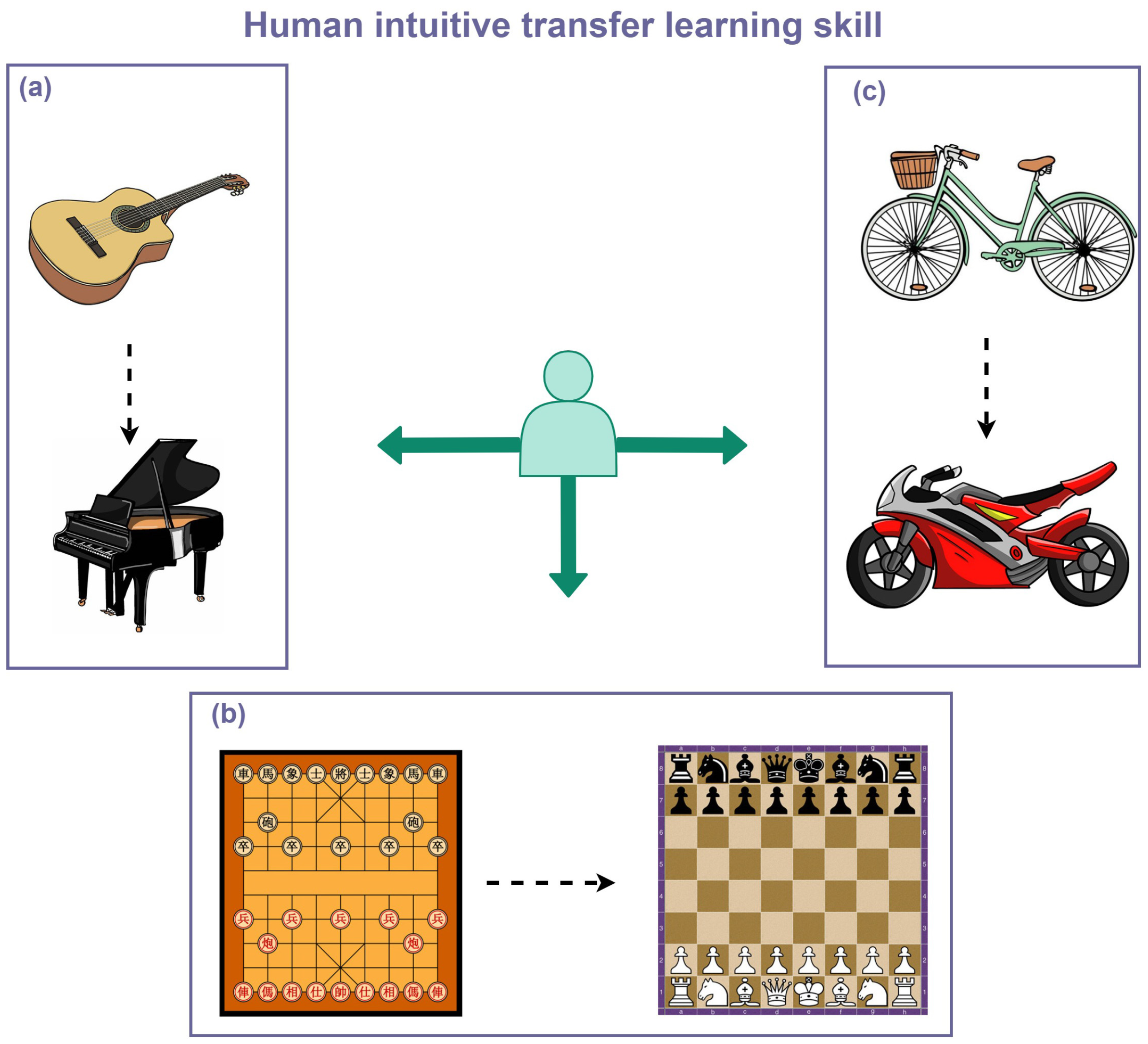
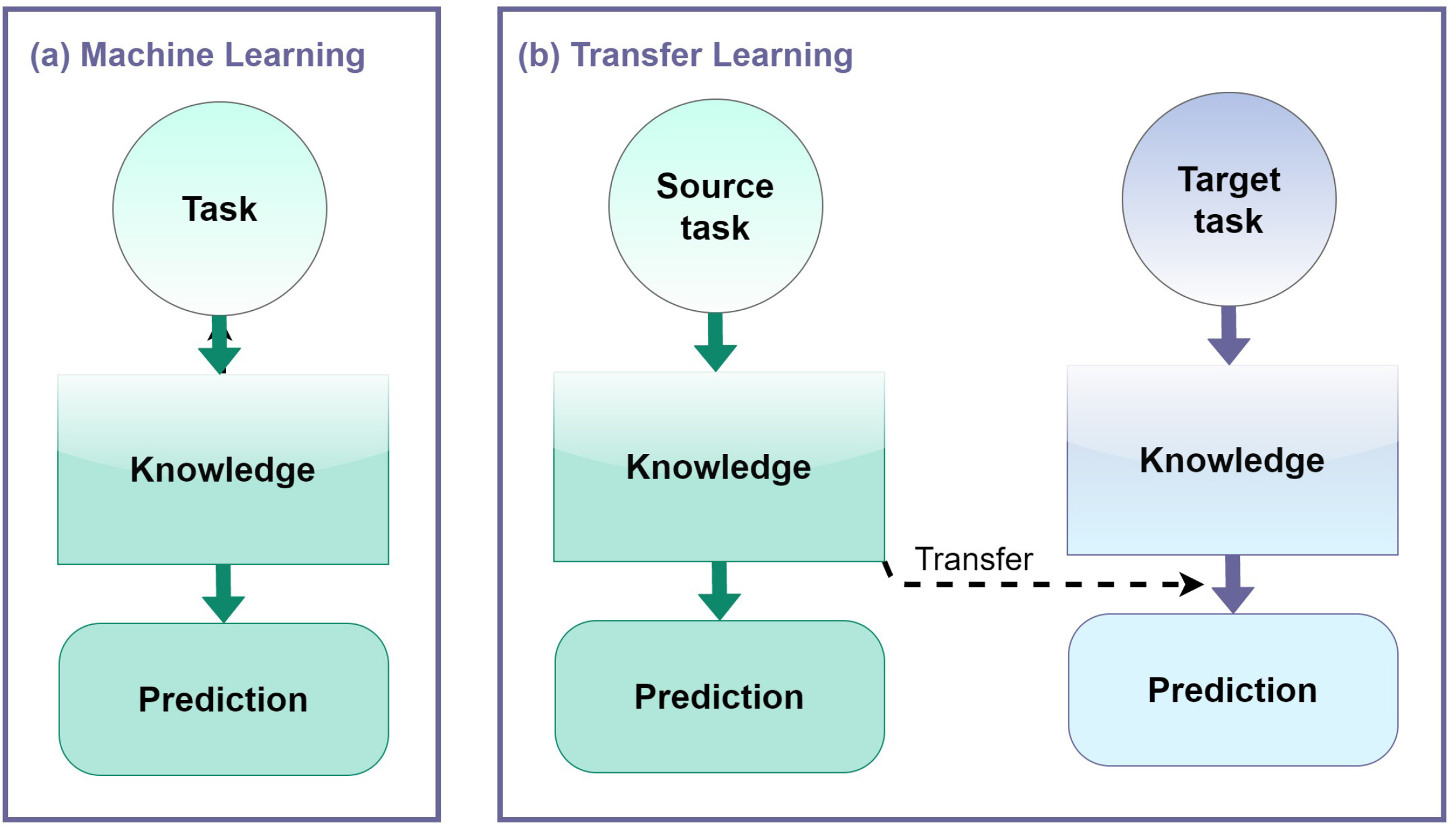
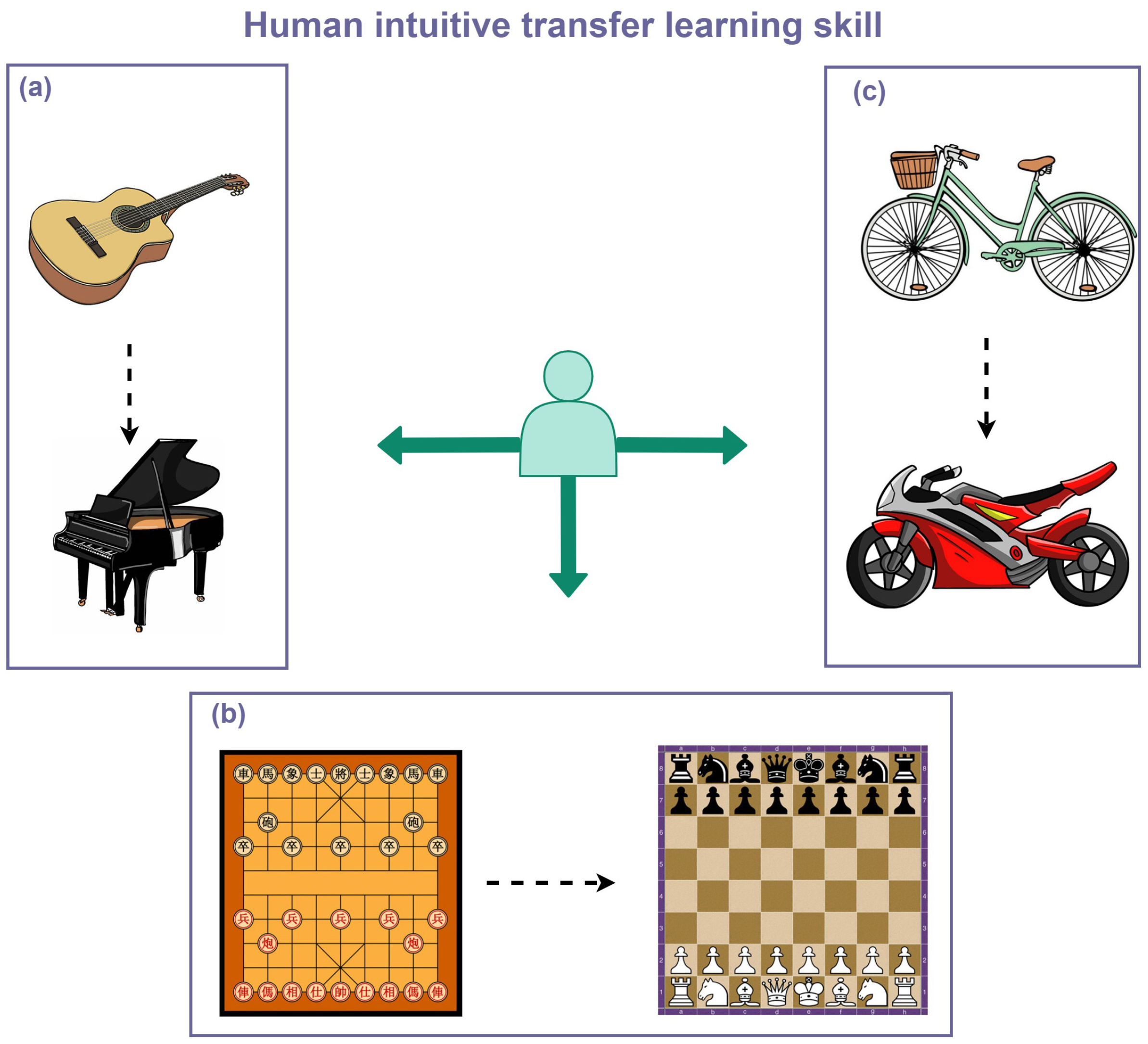
3. Transfer Learning
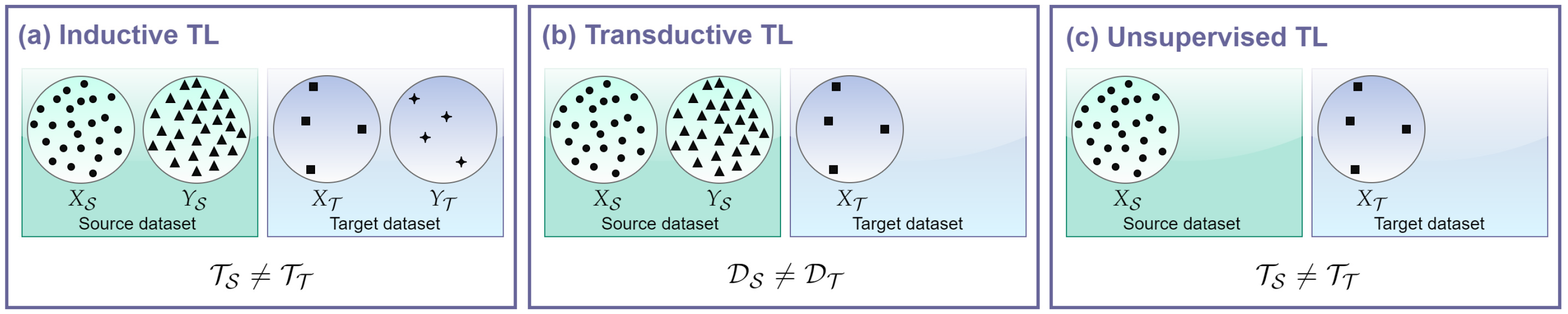
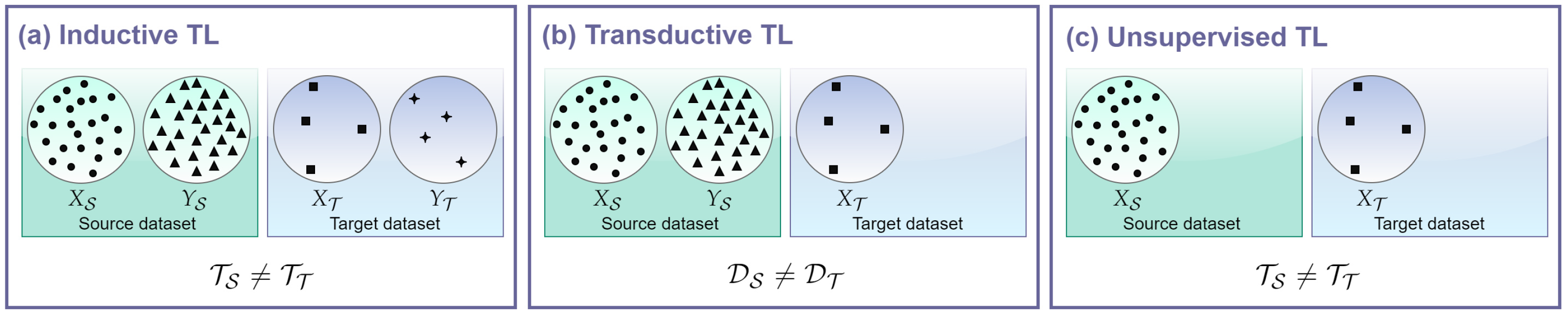
- Inductive TL: target and source tasks are different, regardless of the domains, and the label information of the target domain instances is available. Target-labeled data induce the learning of the target predictive model, hence the name;
- Transductive TL: target and source domains differ and the label information only comes from the source domain. In this case, if the domains differ because the feature spaces are the same , but the marginal probability distributions of the inputs differ , such TL setting is referred to as domain adaptation [39];
- Unsupervised TL: target and source tasks are different and the label information is unknown for both the source and the target domains. This means that by definition such setting regards clustering and dimensionality reduction tasks, and not classification or regression as in the previous cases. For this reason, given the application of SSs, unsupervised solutions are not considered.
- Homogeneous TL: if and/or ;
- Heterogeneous TL: if and/or .
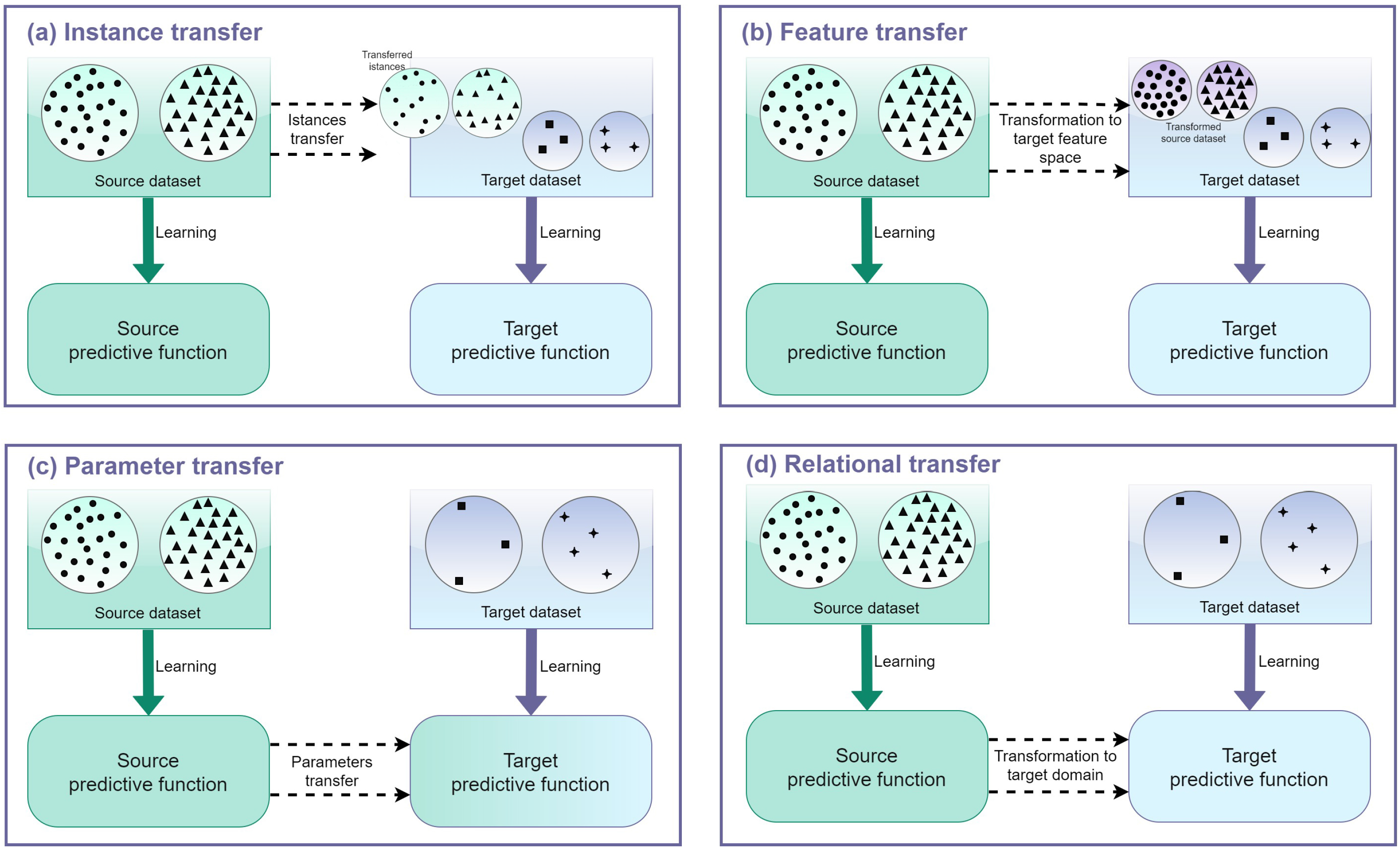
- Instance-based transfer: these approaches assume that due to the difference in distributions between the source and the target domains, certain parts of the data in the source domain can be reused, by reweighting them so as to reduce the effect of the “harmful” source data, while encouraging the “good” data;
- Feature-based transfer: the idea behind this approach is to learn a “good” feature representation for the target domain, to minimize the marginal and the conditional distribution differences, preserving the properties or the potential structures of the data, and classification or regression model error. For instance, a solution is to find the common latent features through feature transformation and use them as a bridge to transfer knowledge: this case is referred to as a symmetric feature-based transfer since both the source and the target features are transformed into a new feature representation; in contrast, in the asymmetric case, the source features are transformed to match the target ones. When performing feature transformation to reduce the distribution difference, one issue is how to measure such differences or similarities. This is done through specific ad-hoc metrics, which are described in Section 3.1;
- Parameter-based transfer: this approach performs the transfer at the model/parameter level by assuming that models for related tasks should share some parameters or prior distributions of hyperparameters. So, by discovering them, knowledge is transferred across tasks themselves;
- Relational-based transfer: these approaches deal with transfer learning for relational domains, where the data are non-independent and identically distributed (i.i.d.) and can be represented by multiple relations. The assumption is that some relationship among the data in the source and target domains is similar and that is the knowledge to be transferred, transferring the logical relationship or rules learned in the source domain to the target domain.
3.1. Distribution Distance Metrics
- Maximum Mean Discrepancy (MMD) [41]Given two distributions P and Q, MMD is defined as the distance between the means of them mapped into a Reproducing Kernel Hilbert Space (RKHS):where represents the mean value of the distribution.The MMD is one of the most used measures in TL. One known feature representation method for TL called Transfer Component Analysis (TCA) [42] learns some transfer components across domains in an RKHS using MMD. Another unsupervised feature transformation technique called Joint Distribution Adaptation (JDA) jointly adapts both the marginal and conditional distributions of the domains in a dimensionality reduction procedure based on Principal Component Analysis (PCA) and the MMD measure [43].
- Kullback–Leibler Divergence () [44]is an asymmetric measure of how one probability distribution differs from another. Given two discrete probability distributions, P and Q on the same probability space , , or the relative entropy, from Q to P is defined as:In Zhuang et al. [45] a supervised representation learning method based on deep autoencoders for TL is introduced so that the distance in distributions of the instances between the source and the target domains is minimized in terms of . Feature-based TL realized through autoencoders is proposed in Guo et al. [46], where is adopted to measure the similarity of new samples concerning historical data samples.
- JSD is a symmetric and smooth version of , defined as:with M being .
- Bregman Distance () [50]is a difference measure between two points defined in terms of a strictly convex function called Bregman function F. The points can be interpreted as probability distributions. Given a continuously-differentiable, strictly convex function defined on a closed convex set , the Bregman distance associated with F for points is defined as the difference between the value of F at point p and the value of the first-order Taylor expansion of F around point q evaluated at point p:A TL method for hyperspectral image classification proposed in Shi et al. [51] employs a regularization based on to find common feature representation for both the source domain and target domain. A domain adaptation approach introduced in Sun et al. [52] reduces the discrepancy between the source domain and the target domain in a latent discriminative subspace by minimizing a matrix divergence function.
- Hilbert–Schmidt Independence Criterion (HSIC) [53]Given separable RKHSs , and a joint measure over , HSIC is defined as the squared HS-norm of the associated cross-covariance operator :A domain adaptation method called Maximum Independence Domain Adaptation (MIDA) finds a latent feature space in which the samples and their domain features are maximally independent in the sense of HSIC [54]. Another method to find the structural similarity between two source and target domains is proposed in Wang and Yang [55]. The algorithm extracts the structural features within each domain and then maps them into the RKHS. The dependencies estimations across domains are performed using the HSIC.
- Wasserstein Distance (W) [56]Given two distributions P and Q, the pth Wasserstein distance metric W is defined as:where and are the corresponding cumulative distribution functions and and the respective quantile functions.W is employed in Shen et al. [57] for an algorithm that aims to learn domain invariant feature representation. It utilizes an ANN to estimate the empirical W distance between the source and target samples and optimizes a feature extractor network to minimize the estimated W in an adversarial manner. A W-based asymmetric adversarial domain adaptation is proposed also in Ying et al. [58] for unsupervised domain adaptation for fault diagnosis.
- Central Moment Discrepancy (CMD) [59]CMD is a distance function on probability distributions on compact intervals. Given two bounded random vectors and i.i.d. and two probability distributions P and Q on the compact interval , CMD is defined aswhere is the expectation of X and is the central moment vector of order k defined in Zellinger et al. [59].In a domain adaptation method for fault detection presented in Li et al. [60], a CNN is applied to extract features from two differently distributed domains and the distribution discrepancy is reduced using the CMD criterion. Another CNN- and CMD-based for fault detection is proposed in Xiong et al. [61].
4. Transfer Learning in SS Design
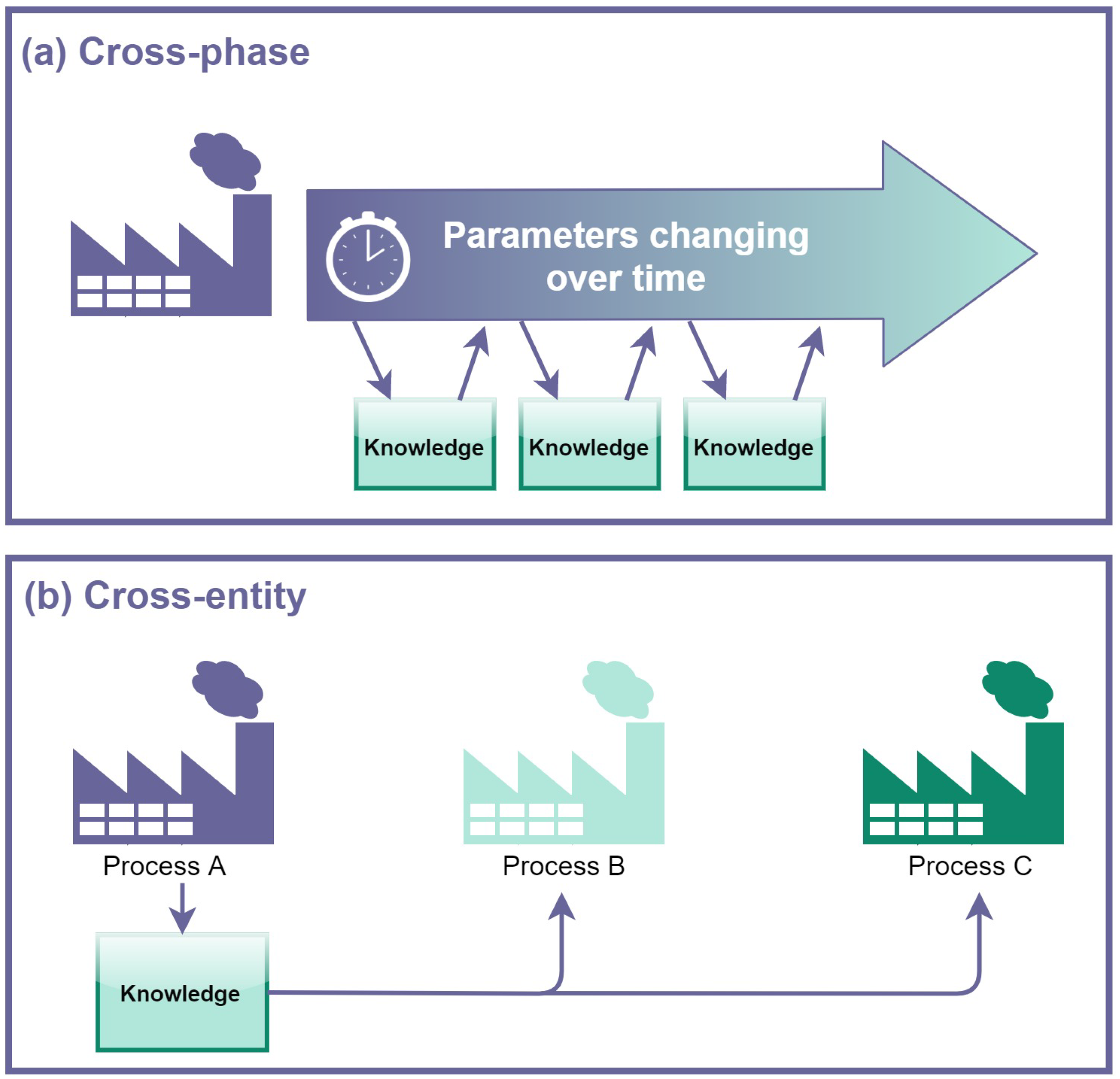
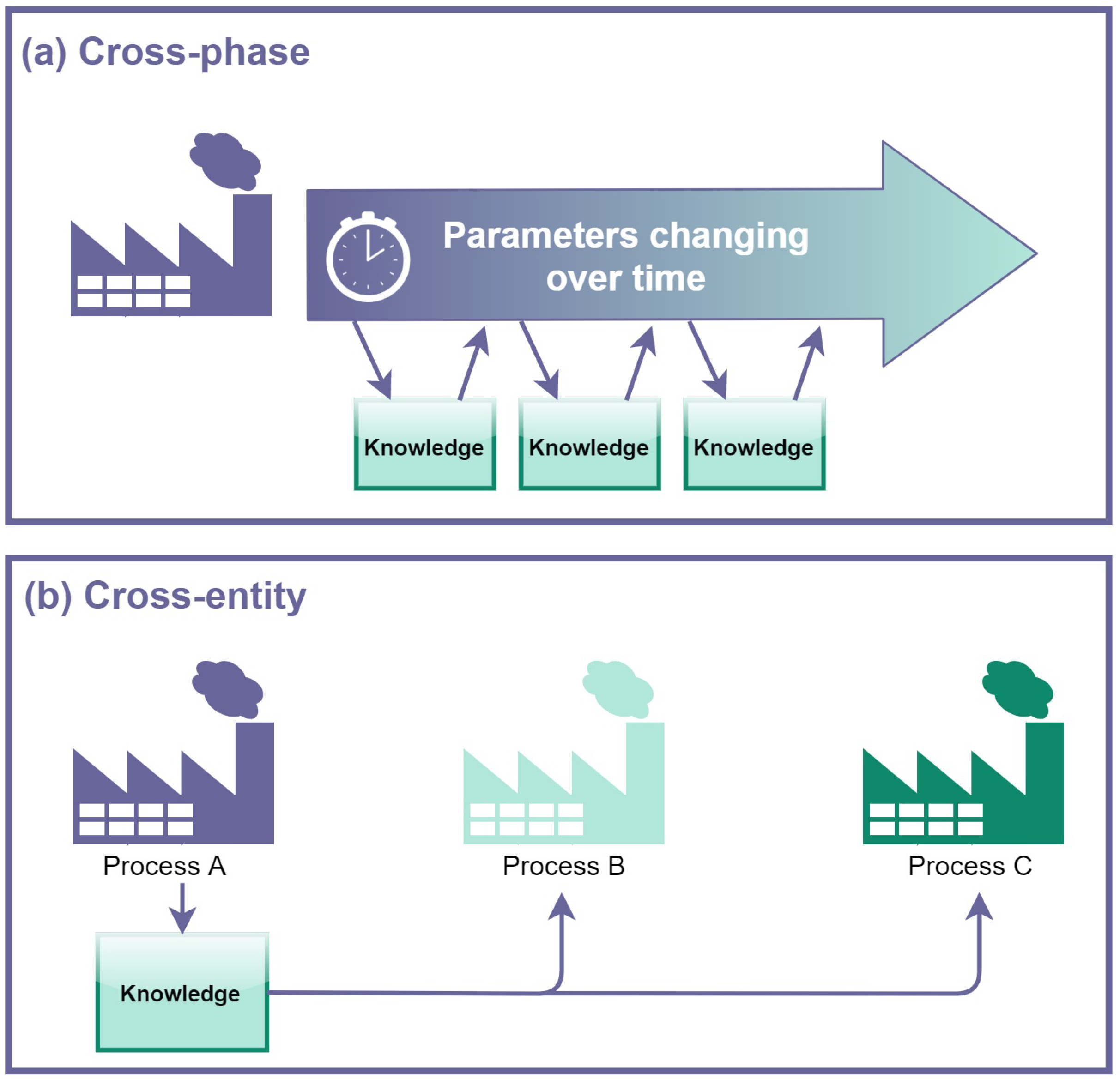
- Cross-phase, which is the case in which plants meet new working conditions and models lose accuracy: this can happen because of signal drift or different operative stages in multi-grade processes or, in the case of production processes, because of changes in products, tools, machines or materials;
- Cross-entity, which is the case in which TL is adopted to transfer knowledge between similar but physically different processes.
4.1. Batch Processes
4.2. Production Processes
4.3. Multi-Grade Chemical Processes
4.4. Industrial Process Systems
5. Conclusions and Future Trends
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shardt, Y.A.; Yang, X.; Brooks, K.; Torgashov, A. Data Quality Assessment for System Identification in the Age of Big Data and Industry 4.0. IFAC-PapersOnLine 2020, 53, 104–113. [Google Scholar] [CrossRef]
- Fortuna, L.; Graziani, S.; Rizzo, A.; Xibilia, M.G. Soft Sensors for Monitoring and Control of Industrial Processes; Springer: London, UK, 2007; Volume 22. [Google Scholar]
- Kadlec, P.; Gabrys, B.; Strandt, S. Data-driven soft sensors in the process industry. Comput. Chem. Eng. 2009, 33, 795–814. [Google Scholar] [CrossRef] [Green Version]
- Graziani, S.; Xibilia, M.G. Deep learning for soft sensor design. In Development and Analysis of Deep Learning Architectures; Springer: Cham, Switzerland, 2020; pp. 31–59. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Kadlec, P.; Grbić, R.; Gabrys, B. Review of adaptation mechanisms for data-driven soft sensors. Comput. Chem. Eng. 2011, 35, 1–24. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Curreri, F.; Patanè, L.; Xibilia, M.G. RNN- and LSTM-Based Soft Sensors Transferability for an Industrial Process. Sensors 2021, 21, 823. [Google Scholar] [CrossRef] [PubMed]
- Farahani, H.S.; Fatehi, A.; Nadali, A.; Shoorehdeli, M.A. A Novel Method For Designing Transferable Soft Sensors And Its Application. arXiv 2020, arXiv:2008.02186. [Google Scholar]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. arXiv 2019, arXiv:1902.07208. [Google Scholar]
- Alibadi, Z.; Vidal, J.M. To Read or To Do? That’s The Task: Using Transfer Learning to Detect the Intent of an Email. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 1105–1110. [Google Scholar]
- Wang, D.; Zheng, T.F. Transfer learning for speech and language processing. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 1225–1237. [Google Scholar]
- Maschler, B.; Weyrich, M. Deep transfer learning for industrial automation. IEEE Ind. Electron. Mag. 2021, 15, 65–75. [Google Scholar] [CrossRef]
- Fortuna, L.; Graziani, S.; Xibilia, M.G. Virtual instruments in refineries. IEEE Instrum. Meas. Mag. 2005, 8, 26–34. [Google Scholar] [CrossRef]
- Curreri, F.; Graziani, S.; Xibilia, M.G. Input selection methods for data-driven Soft sensors design: Application to an industrial process. Inf. Sci. 2020, 537, 1–17. [Google Scholar] [CrossRef]
- Patanè, L.; Xibilia, M.G. Echo-state networks for soft sensor design in an SRU process. Inf. Sci. 2021, 566, 195–214. [Google Scholar] [CrossRef]
- Graziani, S.; Xibilia, M.G. Deep structures for a reformer unit soft sensor. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; pp. 927–932. [Google Scholar]
- Stanišić, D.; Jorgovanović, N.; Popov, N.; Čongradac, V. Soft sensor for real-time cement fineness estimation. ISA Trans. 2015, 55, 250–259. [Google Scholar] [CrossRef]
- Sujatha, K.; Bhavani, N.P.; Cao, S.Q.; Kumar, K.R. Soft Sensor for Flame Temperature Measurement and IoT based Monitoring in Power Plants. Mater. Today Proc. 2018, 5, 10755–10762. [Google Scholar] [CrossRef]
- Galicia, H.J.; He, Q.P.; Wang, J. A reduced order soft sensor approach and its application to a continuous digester. J. Process Control 2011, 21, 489–500. [Google Scholar] [CrossRef]
- Zhu, X.; Rehman, K.U.; Wang, B.; Shahzad, M. Modern soft-sensing modeling methods for fermentation processes. Sensors 2020, 20, 1771. [Google Scholar] [CrossRef] [Green Version]
- Zhu, C.H.; Zhang, J. Developing soft sensors for polymer melt index in an industrial polymerization process using deep belief networks. Int. J. Autom. Comput. 2020, 17, 44–54. [Google Scholar] [CrossRef] [Green Version]
- Pisa, I.; Santín, I.; Vicario, J.L.; Morell, A.; Vilanova, R. ANN-based soft sensor to predict effluent violations in wastewater treatment plants. Sensors 2019, 19, 1280. [Google Scholar] [CrossRef] [Green Version]
- Souza, F.A.; Araújo, R.; Mendes, J. Review of soft sensor methods for regression applications. Chemom. Intell. Lab. Syst. 2016, 152, 69–79. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning. Mach. Learn. 2006, 128, 738. [Google Scholar]
- Ljung, L. System identification. In Signal Analysis and Prediction; Birkhäuser: Boston, MA, USA, 1998; pp. 163–173. [Google Scholar]
- Curreri, F.; Fiumara, G.; Xibilia, M.G. Input selection methods for soft sensor design: A survey. Future Internet 2020, 12, 97. [Google Scholar] [CrossRef]
- Pani, A.K.; Amin, K.G.; Mohanta, H.K. Soft sensing of product quality in the debutanizer column with principal component analysis and feed-forward artificial neural network. Alex. Eng. J. 2016, 55, 1667–1674. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Shang, C.; Liu, L.; Jiang, Y.; Huang, D.; Yang, F. Dynamic soft sensor development based on convolutional neural networks. Ind. Eng. Chem. Res. 2019, 58, 11521–11531. [Google Scholar] [CrossRef]
- Wang, X. Data Preprocessing for Soft Sensor Using Generative Adversarial Networks. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 1355–1360. [Google Scholar]
- Liu, R.; Rong, Z.; Jiang, B.; Pang, Z.; Tang, C. Soft Sensor of 4-CBA Concentration Using Deep Belief Networks with Continuous Restricted Boltzmann Machine. In Proceedings of the 2018 5th IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), Nanjing, China, 23–25 November 2018; pp. 421–424. [Google Scholar]
- Chitralekha, S.B.; Shah, S.L. Support Vector Regression for soft sensor design of nonlinear processes. In Proceedings of the 18th Mediterranean Conference on Control and Automation (MED’10), Marrakech, Morocco, 23–25 June 2010; pp. 569–574. [Google Scholar]
- Grbić, R.; Slišković, D.; Kadlec, P. Adaptive soft sensor for online prediction and process monitoring based on a mixture of Gaussian process models. Comput. Chem. Eng. 2013, 58, 84–97. [Google Scholar] [CrossRef]
- Tercan, H.; Guajardo, A.; Meisen, T. Industrial Transfer Learning: Boosting Machine Learning in Production. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki, Finland, 22–25 July 2019; Volume 1, pp. 274–279. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 24–29 June 2007; pp. 440–447. [Google Scholar]
- Wang, Z.; Dai, Z.; Póczos, B.; Carbonell, J. Characterizing and avoiding negative transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11293–11302. [Google Scholar]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Huang, J.; Gretton, A.; Borgwardt, K.; Schölkopf, B.; Smola, A. Correcting sample selection bias by unlabeled data. Adv. Neural Inf. Process. Syst. 2006, 19, 601–608. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning: Transfer learning with deep autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Guo, F.; Wei, B.; Huang, B. A just-in-time modeling approach for multimode soft sensor based on Gaussian mixture variational autoencoder. Comput. Chem. Eng. 2021, 146, 107230. [Google Scholar] [CrossRef]
- Endres, D.M.; Schindelin, J.E. A new metric for probability distributions. IEEE Trans. Inf. Theory 2003, 49, 1858–1860. [Google Scholar] [CrossRef] [Green Version]
- Dey, S.; Madikeri, S.; Motlicek, P. Information theoretic clustering for unsupervised domain-adaptation. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5580–5584. [Google Scholar]
- Chen, W.H.; Cho, P.C.; Jiang, Y.L. Activity recognition using transfer learning. Sens. Mater 2017, 29, 897–904. [Google Scholar]
- Bregman, L.M. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, Y.; Liu, X.; Zhao, K. Regularised transfer learning for hyperspectral image classification. IET Comput. Vis. 2019, 13, 188–193. [Google Scholar] [CrossRef]
- Sun, H.; Liu, S.; Zhou, S. Discriminative subspace alignment for unsupervised visual domain adaptation. Neural Process. Lett. 2016, 44, 779–793. [Google Scholar] [CrossRef]
- Gretton, A.; Fukumizu, K.; Teo, C.H.; Song, L.; Schölkopf, B.; Smola, A.J. A kernel statistical test of independence. In Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Volume 20, pp. 585–592. [Google Scholar]
- Yan, K.; Kou, L.; Zhang, D. Learning domain-invariant subspace using domain features and independence maximization. IEEE Trans. Cybern. 2017, 48, 288–299. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Yang, Q. Transfer learning by structural analogy. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011. [Google Scholar]
- Vaserstein, L.N. Markov processes over denumerable products of spaces, describing large systems of automata. Probl. Peredachi Informatsii 1969, 5, 64–72. [Google Scholar]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein distance guided representation learning for domain adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ying, Y.; Jun, Z.; Tang, T.; Jingwei, W.; Ming, C.; Jie, W.; Liang, W. Wasserstein distance based Asymmetric Adversarial Domain Adaptation in intelligent bearing fault diagnosis. Meas. Sci. Technol. 2021, 32, 115019. [Google Scholar]
- Zellinger, W.; Grubinger, T.; Lughofer, E.; Natschläger, T.; Saminger-Platz, S. Central moment discrepancy (cmd) for domain-invariant representation learning. arXiv 2017, arXiv:1702.08811. [Google Scholar]
- Li, X.; Hu, Y.; Zheng, J.; Li, M.; Ma, W. Central moment discrepancy based domain adaptation for intelligent bearing fault diagnosis. Neurocomputing 2021, 429, 12–24. [Google Scholar] [CrossRef]
- Xiong, P.; Tang, B.; Deng, L.; Zhao, M.; Yu, X. Multi-block domain adaptation with central moment discrepancy for fault diagnosis. Measurement 2021, 169, 108516. [Google Scholar] [CrossRef]
- Pan, J. Review of metric learning with transfer learning. AIP Conf. Proc. 2017, 1864, 020040. [Google Scholar]
- Wang, J.; Zhao, C. Mode-cloud data analytics based transfer learning for soft sensor of manufacturing industry with incremental learning ability. Control Eng. Pract. 2020, 98, 104392. [Google Scholar] [CrossRef]
- Chu, F.; Shen, J.; Dai, W.; Jia, R.; Ma, X.; Wang, F. A dual modifier adaptation optimization strategy based on process transfer model for new batch process. IFAC-PapersOnLine 2018, 51, 791–796. [Google Scholar] [CrossRef]
- Chu, F.; Zhao, X.; Yao, Y.; Chen, T.; Wang, F. Transfer learning for batch process optimal control using LV-PTM and adaptive control strategy. J. Process Control 2019, 81, 197–208. [Google Scholar] [CrossRef]
- Chu, F.; Wang, J.; Zhao, X.; Zhang, S.; Chen, T.; Jia, R.; Xiong, G. Transfer learning for nonlinear batch process operation optimization. J. Process Control 2021, 101, 11–23. [Google Scholar] [CrossRef]
- Chu, F.; Cheng, X.; Peng, C.; Jia, R.; Chen, T.; Wei, Q. A process transfer model-based optimal compensation control strategy for batch process using just-in-time learning and trust region method. J. Frankl. Inst. 2021, 358, 606–632. [Google Scholar] [CrossRef]
- Jia, R.; Zhang, S.; You, F. Transfer learning for end-product quality prediction of batch processes using domain-adaption joint-Y PLS. Comput. Chem. Eng. 2020, 140, 106943. [Google Scholar] [CrossRef]
- Yao, L.; Jiang, X.; Huang, G.; Qian, J.; Shen, B.; Xu, L.; Ge, Z. Virtual Sensing f-CaO Content of Cement Clinker Based on Incremental Deep Dynamic Features Extracting and Transferring Model. IEEE Trans. Instrum. Meas. 2020, 70, 1–10. [Google Scholar]
- Yang, C.; Chen, B.; Wang, Z.; Yao, Y.; Liu, Y. Transfer learning soft sensor for product quality prediction in multi-grade processes. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 1148–1153. [Google Scholar]
- Liu, Y.; Yang, C.; Liu, K.; Chen, B.; Yao, Y. Domain adaptation transfer learning soft sensor for product quality prediction. Chemom. Intell. Lab. Syst. 2019, 192, 103813. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Zhang, M.; Dai, Y.; Yao, Y. Development of adversarial transfer learning soft sensor for multigrade processes. Ind. Eng. Chem. Res. 2020, 59, 16330–16345. [Google Scholar] [CrossRef]
- Hsiao, Y.D.; Kang, J.L.; Wong, D.S.H. Development of Robust and Physically Interpretable Soft Sensor for Industrial Distillation Column Using Transfer Learning with Small Datasets. Processes 2021, 9, 667. [Google Scholar] [CrossRef]
- Alakent, B. Soft sensor design using transductive moving window learner. Comput. Chem. Eng. 2020, 140, 106941. [Google Scholar] [CrossRef]
- Alakent, B. Soft-sensor design via task transferred just-in-time-learning coupled transductive moving window learner. J. Process Control 2021, 101, 52–67. [Google Scholar]
- Farahani, H.S.; Fatehi, A.; Nadali, A.; Shoorehdeli, M.A. Domain Adversarial Neural Network Regression to design transferable soft sensor in a power plant. Comput. Ind. 2021, 132, 103489. [Google Scholar] [CrossRef]
- Graziani, S.; Xibilia, M.G. Improving Soft Sensors performance in the presence of small datasets by data selection. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Jaeckle, C.M.; MacGregor, J.F. Product transfer between plants using historical process data. AIChE J. 2000, 46, 1989–1997. [Google Scholar] [CrossRef]
- Muñoz, S.G.; MacGregor, J.F.; Kourti, T. Product transfer between sites using Joint-Y PLS. Chemom. Intell. Lab. Syst. 2005, 79, 101–114. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TL Categories | ||
|---|---|---|
| Categorization Criterion | Types | |
| Problem categorization | Label setting | Inductive Transductive Unsupervised |
| Space setting | Homogeneous Heterogeneous | |
| Approach categorization | “What” is transferred | Instance-based Feature-based Parameter-based Relational-based |
| Distribution Difference Measure | Algorithm | Applications |
|---|---|---|
| Maximum Mean Discrepancy (MMD) | [41] | [42,43] |
| Kullback–Leibler Divergence () | [44] | [45,46] |
| Jensen–Shannon Divergence (JSD) | [47] | [48,49] |
| Bregman Distance () | [50] | [51,52] |
| Hilbert–Schmidt Independence Criterion (HSIC) | [53] | [54,55] |
| Wasserstein Distance (W) | [56] | [57,58] |
| Central Moment Discrepancy (CMD) | [59] | [60,61] |
| Problem Categorization | Approach Categorization | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Use Case | Label Avail. | Feature Space | TL Approach | ML Technique | |||||||
| Cross-Phase | Cross-Entity | Inductive | Transductive | Homogeneous | Heterogeneous | Instance | Feature | Parameter | Relational | ||
| Batch processes | |||||||||||
| [63] | • | • | • | • | PLS | ||||||
| [64,65,66,67] | • | • | • | • | • | • | PLS | ||||
| [68] | • | • | • | • | PLS | ||||||
| Production processes | |||||||||||
| [36] | • | • | • | • | • | ANN | |||||
| [69] | • | • | • | • | • | LSTM, XGBoost | |||||
| Multi-grade chemical processes | |||||||||||
| [70,71] | • | • | • | • | ELM | ||||||
| [72] | • | • | • | • | • | GAN, ELM | |||||
| Industrial process systems | |||||||||||
| [73] | • | • | • | • | ANN | ||||||
| [10] | • | • | • | • | LSTM, RNN | ||||||
| [74,75] | • | • | • | • | MW, JITL | ||||||
| [46] | • | • | • | • | • | GMVAE, JITL | |||||
| [11,76] | • | • | • | • | • | DANN | |||||
| [77] | • | • | • | • | • | PCA, ANN | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Curreri, F.; Patanè, L.; Xibilia, M.G. Soft Sensor Transferability: A Survey. Appl. Sci. 2021, 11, 7710. https://doi.org/10.3390/app11167710
Curreri F, Patanè L, Xibilia MG. Soft Sensor Transferability: A Survey. Applied Sciences. 2021; 11(16):7710. https://doi.org/10.3390/app11167710
Chicago/Turabian StyleCurreri, Francesco, Luca Patanè, and Maria Gabriella Xibilia. 2021. "Soft Sensor Transferability: A Survey" Applied Sciences 11, no. 16: 7710. https://doi.org/10.3390/app11167710
APA StyleCurreri, F., Patanè, L., & Xibilia, M. G. (2021). Soft Sensor Transferability: A Survey. Applied Sciences, 11(16), 7710. https://doi.org/10.3390/app11167710