
KGGCN: Knowledge-Guided Graph Convolutional Networks for Distantly Supervised Relation Extraction

Abstract
:1. Introduction
Contributions
2. Related Work
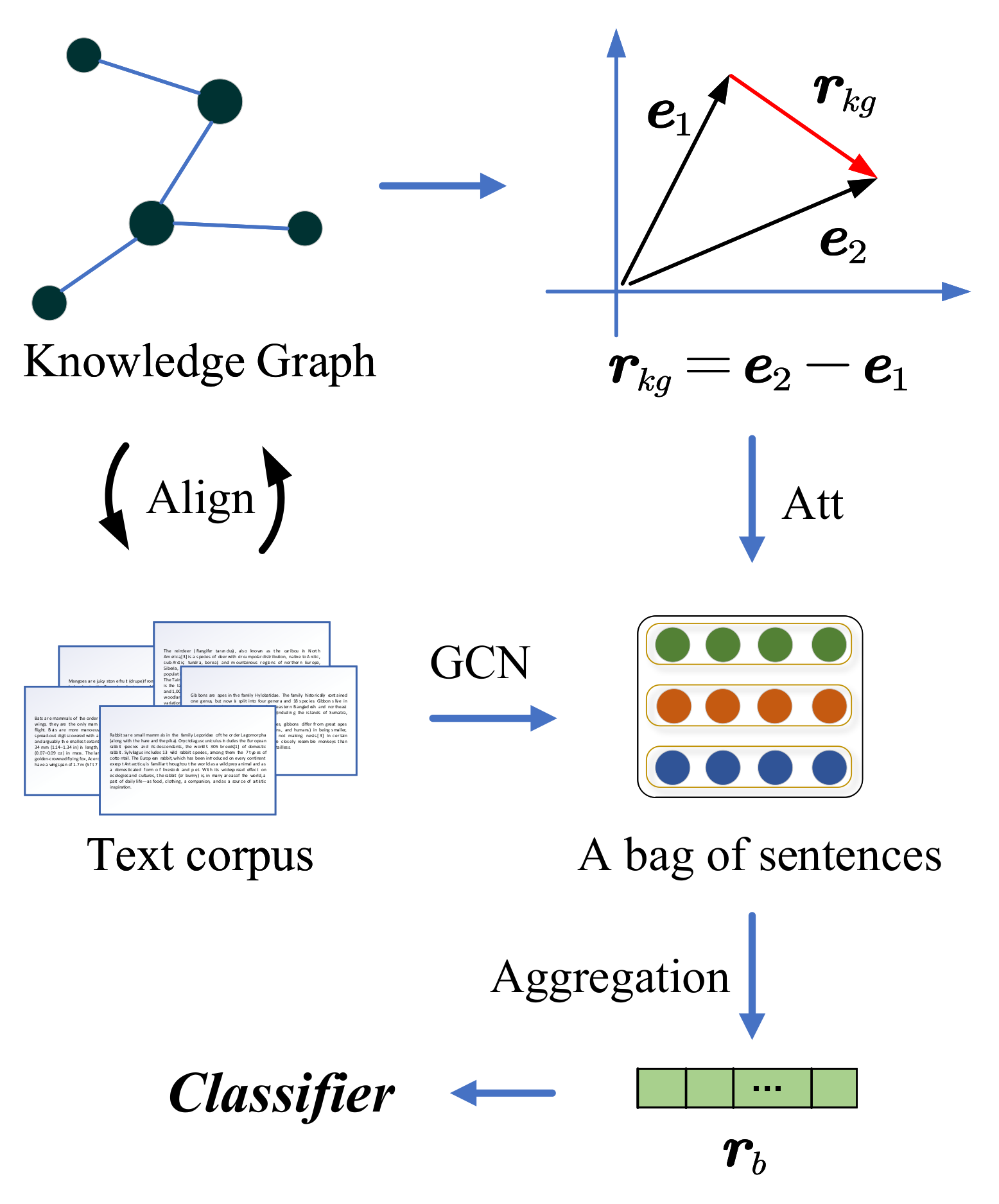
3. Methodology
3.1. Sentence Representation
3.1.1. Generation of Relation Indicator
3.1.2. Knowledge Attention over Words
3.1.3. Knowledge Attention Based GCN
3.2. Knowledge Supervised Sentences Selection
3.2.1. Knowledge Graph Embedding
3.2.2. Knowledge Attention over Sentences
3.3. Complexity Analysis
4. Implementation for Relation Classification
5. Experimental Setup
5.1. Dataset and Evaluation Metrics
5.2. Baselines
5.2.1. Feature-Based
5.2.2. Neural-Based
5.3. Parameter Settings
5.4. Comparison with Baselines
5.5. Ablation Study
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RE | Relation extraction |
| NLP | Natural language processing |
| KG | Knowledge graph |
| CNN | Convolutional neural network |
| RNN | Recurrent neural network |
| GCN | Graph convolutional network |
| KGGCN | Knowledge-guided graph convolutional network |
| LUs | Lexical units |
| SGD | Stochastic gradient descent |
| NYT-FB | New York Times with freebase facts |
| GDS | Google distant supervision |
| PR | Precision-recall |
| P@N | Top-N precision |
References
- Cui, W.; Xiao, Y.; Wang, H.; Song, Y.; Hwang, S.W.; Wang, W. KBQA: Learning Question Answering over QA Corpora and Knowledge Bases. Proc. VLDB Endow. 2017, 10. [Google Scholar] [CrossRef] [Green Version]
- Quirk, C.; Poon, H. Distant Supervision for Relation Extraction beyond the Sentence Boundary. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; pp. 1171–1182. [Google Scholar]
- Young, T.; Cambria, E.; Chaturvedi, I.; Huang, M.; Zhou, H.; Biswas, S. Augmenting end-to-end dialog systems with commonsense knowledge. arXiv 2017, arXiv:1709.05453. [Google Scholar]
- Zhang, Z. Weakly-supervised relation classification for information extraction. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; pp. 581–588. [Google Scholar]
- Qian, L.; Zhou, G.; Kong, F.; Zhu, Q. Semi-supervised learning for semantic relation classification using stratified sampling strategy. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 1437–1445. [Google Scholar]
- Rink, B.; Harabagiu, S. Utd: Classifying semantic relations by combining lexical and semantic resources. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 256–259. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation Classification via Convolutional Deep Neural Network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Zhang, D.; Wang, D. Relation classification via recurrent neural network. arXiv 2015, arXiv:1508.01006. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009; Volume 2, pp. 1003–1011. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Li, P.; Mao, K.; Yang, X.; Li, Q. Improving Relation Extraction with Knowledge-attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 229–239. [Google Scholar]
- Ruppenhofer, J.; Ellsworth, M.; Schwarzer-Petruck, M.; Johnson, C.R.; Scheffczyk, J. FrameNet II: Extended Theory and Practice. Available online: http://framenet.icsi.berkeley.edu/fndrupal (accessed on 2 May 2021).
- Khan, A.W.; Khan, M.U.; Khan, J.A.; Ahmad, A.; Khan, K.; Zamir, M.; Kim, W.; Ijaz, M.F. Analyzing and Evaluating critical challenges and practices for software vendor organizations to secure Big Data on Cloud Computing: An AHP-based Systematic Approach. IEEE Access 2021, 9, 2617–2633. [Google Scholar] [CrossRef]
- Kaur, J.; Ahmed, S.; Kumar, Y.; Alaboudi, A.; Jhanjhi, N.; Ijaz, M.F. Packet Optimization of Software Defined Network Using Lion Optimization. CMC-COMPUTERS MATERIALS & CONTINUA 2021, 69, 2617–2633. [Google Scholar]
- Kambhatla, N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions, Barcelona, Spain, 21–26 July 2004; p. 22. [Google Scholar]
- Suchanek, F.M.; Ifrim, G.; Weikum, G. Combining linguistic and statistical analysis to extract relations from web documents. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 712–717. [Google Scholar]
- Alicante, A.; Corazza, A. Barrier features for classification of semantic relations. In Proceedings of the International Conference Recent Advances in Natural Language Processing 2011, Hissar, Bulgaria, 12–14 September 2011; pp. 509–514. [Google Scholar]
- Bunescu, R.C.; Mooney, R.J. A shortest path dependency kernel for relation extraction. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731. [Google Scholar]
- Zhang, M.; Zhang, J.; Su, J.; Zhou, G. A composite kernel to extract relations between entities with both flat and structured features. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006; pp. 825–832. [Google Scholar]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 1201–1211. [Google Scholar]
- Liu, C.; Sun, W.; Chao, W.; Che, W. Convolution neural network for relation extraction. In Proceedings of the International Conference on Advanced Data Mining and Applications, Hangzhou, China, 14–16 December 2013; pp. 231–242. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Portland, OR, USA, 19–24 June 2011; pp. 541–550. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 4–8 September 2010; pp. 148–163. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 241–251. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Liu, T.; Zhang, X.; Zhou, W.; Jia, W. Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2195–2204. [Google Scholar]
- Du, J.; Han, J.; Way, A.; Wan, D. Multi-Level Structured Self-Attentions for Distantly Supervised Relation Extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2216–2225. [Google Scholar]
- Ren, F.; Zhou, D.; Liu, Z.; Li, Y.; Zhao, R.; Liu, Y.; Liang, X. Neural relation classification with text descriptions. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1167–1177. [Google Scholar]
- Vashishth, S.; Joshi, R.; Prayaga, S.S.; Bhattacharyya, C.; Talukdar, P. Reside: Improving distantly-supervised neural relation extraction using side information. arXiv 2018, arXiv:1812.04361. [Google Scholar]
- Han, X.; Liu, Z.; Sun, M. Neural Knowledge Acquisition via Mutual Attention Between Knowledge Graph and Text. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018; pp. 4832–4839. [Google Scholar]
- Zeng, W.; Lin, Y.; Liu, Z.; Sun, M. Incorporating relation paths in neural relation extraction. arXiv 2016, arXiv:1609.07479. [Google Scholar]
- Palmer, M.; Gildea, D.; Kingsbury, P. The proposition bank: An annotated corpus of semantic roles. Comput. Linguist. 2005, 31, 71–106. [Google Scholar] [CrossRef]
- Schuler, K.K. VerbNet: A Broad-Coverage, Comprehensive verb Lexicon; University of Pennsylvania: Philadelphia, PA, USA, 2005. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Xiao, Y.; Jina, Y.; Cheng, R.; Hao, K. Hybrid Attention-Based Transformer Block Model for Distant Supervision Relation Extraction. arXiv 2020, arXiv:2003.11518. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2787–2795. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Dos Santos, C.; Xiang, B.; Zhou, B. Classifying Relations by Ranking with Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–3 July 1 2015; pp. 626–634. [Google Scholar]
- Jat, S.; Khandelwal, S.; Talukdar, P. Improving distantly supervised relation extraction using word and entity based attention. arXiv 2018, arXiv:1804.06987. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Sentences | Entity Pairs | Relations | |
|---|---|---|---|---|
| Train | 455,771 | 233,064 | ||
| NYT-FB | Valid | 114,317 | 58,635 | 53 |
| Test | 172,448 | 96,678 | ||
| Train | 11,297 | 6498 | ||
| GDS | Valid | 1864 | 1082 | 5 |
| Test | 5663 | 3247 |
| Para | Description | Value |
|---|---|---|
| Word∖entity∖relation Embedding | 50 | |
| Position Embedding | 5 | |
| Regularization Factor | 0.001 | |
| Learning Rate | 0.5 | |
| p | Dropout probability | 0.5 |
| L | GCN Layers | 2 |
| Models | One | Two | All | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P@100 | P@200 | P@300 | Mean | P@100 | P@200 | P@300 | Mean | P@100 | P@200 | P@300 | Mean | |
| PCNN | 73.3 | 64.8 | 56.8 | 65.0 | 70.3 | 67.2 | 63.1 | 66.9 | 72.3 | 69.7 | 64.1 | 68.7 |
| PCNN+ATT | 73.3 | 69.2 | 60.8 | 67.8 | 77.2 | 71.6 | 66.1 | 71.6 | 76.2 | 73.1 | 67.4 | 72.2 |
| BGWA | 78.0 | 71.0 | 63.3 | 70.8 | 81.0 | 73.0 | 64.0 | 72.7 | 82.0 | 75.0 | 72.0 | 76.3 |
| RESIDE | 80.0 | 75.5 | 69.3 | 74.9 | 83.0 | 73.5 | 70.6 | 75.7 | 84.0 | 78.5 | 75.6 | 79.4 |
| KGGCN (ours) | 87.6 | 78.3 | 72.8 | 79.6 | 85.1 | 76.2 | 73.8 | 78.4 | 86.7 | 81.4 | 76.3 | 81.5 |
| Models | p@100 | p@200 | p@300 | Mean |
|---|---|---|---|---|
| KGGCN(ours) | 86.7 | 81.4 | 76.3 | 81.5 |
| KGGCN w TransE | 85.1 | 80.2 | 74.9 | 80.1 |
| KGGCN w/o LU | 84.5 | 78.7 | 73.7 | 79.0 |
| KGGCN w/o KG | 78.2 | 75.4 | 69.3 | 74.3 |
| KGGCN w/o ALL | 73.2 | 69.5 | 62.9 | 68.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, N.; Huang, W.; Zhong, H. KGGCN: Knowledge-Guided Graph Convolutional Networks for Distantly Supervised Relation Extraction. Appl. Sci. 2021, 11, 7734. https://doi.org/10.3390/app11167734
Mao N, Huang W, Zhong H. KGGCN: Knowledge-Guided Graph Convolutional Networks for Distantly Supervised Relation Extraction. Applied Sciences. 2021; 11(16):7734. https://doi.org/10.3390/app11167734
Chicago/Turabian StyleMao, Ningyi, Wenti Huang, and Hai Zhong. 2021. "KGGCN: Knowledge-Guided Graph Convolutional Networks for Distantly Supervised Relation Extraction" Applied Sciences 11, no. 16: 7734. https://doi.org/10.3390/app11167734