1. Introduction
Artificial intelligence is already proving to be a huge success in various sectors and disciplines. Despite the fact that this concept has been there since the 1960s, it has only lately acquired popularity as a result of expanding data quantities, advanced algorithms, and improvements in computing capacity [
1].
In the energy field, artificial intelligence can be used as a forecasting tool for grid quality and stability, planning, dispatching of power, and efficient management [
2]. Renewable energy sources encounter several critical challenges regarding their integration in the energy mix due to their unpredictability and improbability. In the case of photovoltaic solar energy, these inaccuracies are mainly controlled by the Earth’s motion around the sun [
3].
The relevance of this problem has led to advanced research in order to accurately predict photovoltaic power production. One of the best solutions used to tackle and address this issue is the machine learning approach since it does not require any knowledge about PV systems. In the literature, several machine learning-based prediction techniques are used, including multiple linear regression (MLR) [
4], support vector regression (SVR) [
5], random forest (RF) [
6], quantile random forest (QRF) [
7], long short-term memory (LSTM) neural networks (NNs) [
8], K nearest neighbors (KNN), extreme learning machine (ELM), generalized regression neural network (GRNN) [
9], elastic net, ridge regression, gradient boosting (GB) [
10] etc.
This study can give important information regarding forecasting methodologies to academics and engineers working in solar PV plants, since it presents comparative research on different machine learning techniques for hourly PV power prediction. Moreover, since several factors, namely climatic variables, can affect solar PV output power and add complexity to the prediction process, a principal component analysis (PCA) was conducted to decrease the number of interconnected variables into a smaller number of dominating factors. The prevailing factors were then used as inputs for the predictive models. Finally, the accuracy of the proposed models was assessed using performance metrics, residual analysis, and a diagnostic approach, mainly the regression error characteristic (REC) curve. The main contributions of this study are the following:
This study enhances the ability of short-term PV power predictions thanks to the robust and competitive results obtained in terms of R2 and RMSE
Our approach requires only open data freely available on the web, and anyone with technological skills may create their own customized version.
The most relevant variables to PV power prediction are identified using PCA.
Finally, investments in new PV installations will be encouraged thanks to the results of our comparison.
2. Materials and Methods
2.1. Data Source and Description
In this work, we used the hourly PV output power data (PAC) derived from a PV power platform with a total capacity of 6 kW in Rabat, Morocco. For the input data, we used SoDa, a free data source offering solar energy and weather services. The inputs utilized in our forecasting models are presented in
Table 1,
Table 2 and
Table 3 as follows.
2.2. Principal Component Analysis
Principal component analysis (PCA) is an extremely powerful tool for synthesizing information. It is used especially when there is a large amount of quantitative data to process and interpret. The core of this statistical technique is to use fewer independent factors to reflect the majority of the original variables and to eliminate their duplication [
11]. The principal components are obtained from the covariance matrix’s eigenvalues and eigenvectors [
12]. In this study, 17 variables were studied as inputs for our predictive models.
2.3. Machine Learning Algortihms
In this paper, four machine learning algorithms were tested and fitted in R (R Core Team, 2018) [
13]. The dataset was partitioned into two parts—training and testing sets—according to the Pareto rule of 80% and 20% using the function createDataPartition in the CARET Package in R. We defined the training and tuning settings using the trainControl function. To minimize over-fitting of the training set, we used cross-validation with 10 folds.
2.3.1. Elastic Net Regression
The first algorithm tested in our work was elastic net regression. It adds two penalty terms from both the lasso and ridge methods to regularize regression models (with non-zero coefficients
) as presented in Equation (1) [
14].
where lambda
(
≥ 0) is the penalty coefficient.
2.3.2. Support Vector Regression
The second method used in our study was support vector regression. It is one of the most popular algorithms in machine learning. Its main principle is to find an ideal hyperplane in the training data space that represents all of the observations in the dataset. The hyperplane is the line used to forecast the target. The support vectors or data points nearest to the boundary lines might be either within or outside the boundary lines [
6]. The hyperplane is then established by any equation, i.e., non-linear or polynomial. In this study, a radial-based kernel function was used [
15].
2.3.3. Random Forest Regression
Random forest (RF) is an ensemble-based regression method. In the form of a tree structure, RF displays relationships between features and the target, which allows for easy-to-understand and interpretable results [
16]. This method is a decision tree adaptation, in which a model produces predictions based on a succession of base models as stated as in Equation (2) [
17].
where each base model is a decision tree and
k denote the number of decision trees.
2.3.4. Bayesian Regularized Neural Networks
In this work, we investigated the ability of a neural network trained using the Bayesian regularization technique to forecast PV power, since this method has not seen many applications in the field of solar energy prediction. The Bayesian technique has a variety of practical benefits, including the ability to solve the over-fitting problem which occurs in conventional neural networks [
18].
2.4. Performance Metrics
The accuracy of PV power (PAC) forecasting models was evaluated considering the following metrics [
19,
20]:
3. Results
3.1. Principal Component Analysis: Factor Extraction Results
The principal component analysis (PCA) was performed on the datasets to identify the most important data features for use in training the machine learning models.
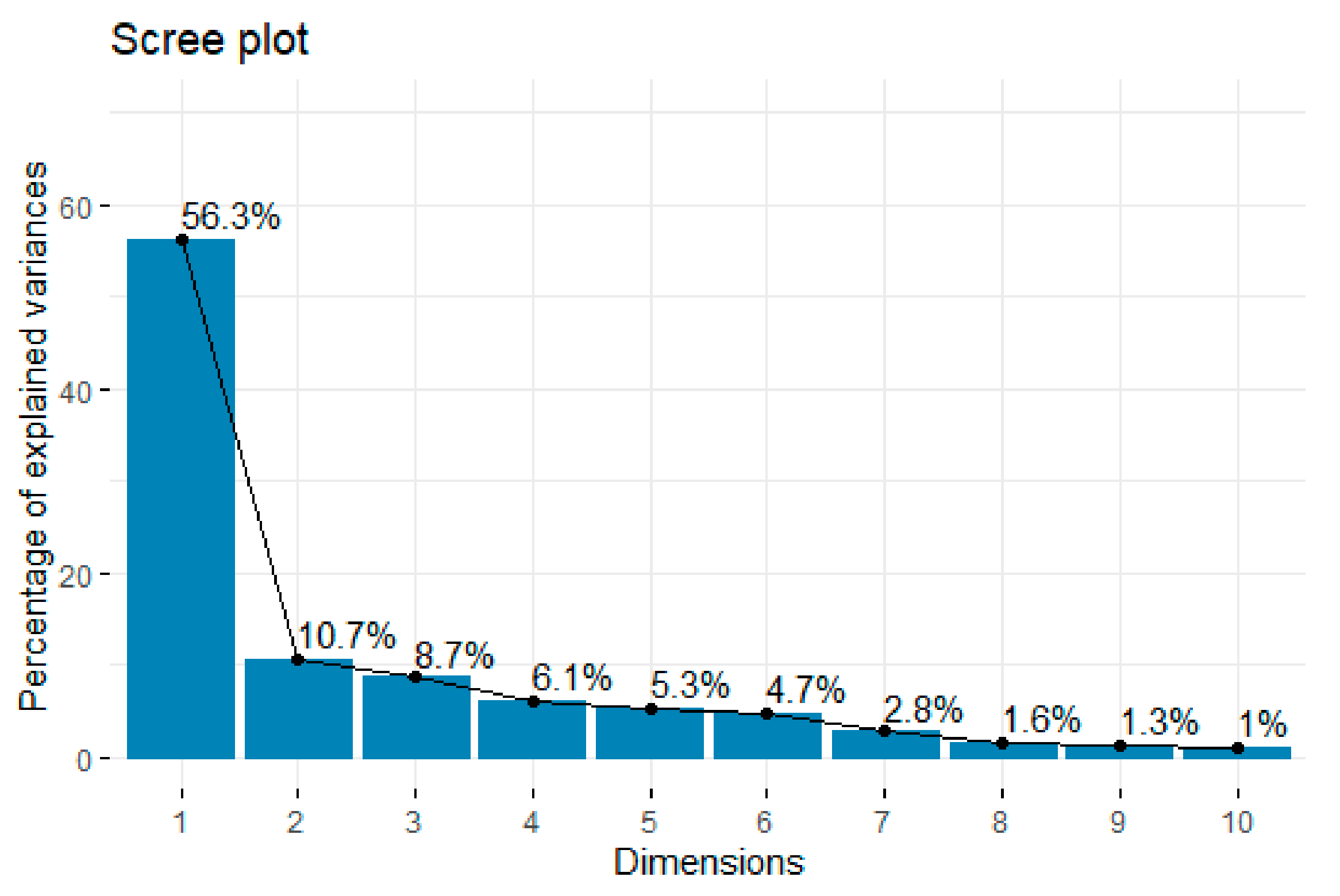
Table 4 shows the variance distribution of the principal components (PCs) (PC1–PC17). According to the eigenvalues, it appears that the cumulative variance of PC1 to PC6 is 91.95%Therefore, the first six principal components were identified as the main model inputs and were sufficient to develop our predictive models. Moreover,
Figure 1 presents the scree plot, which is a line plot of the correlation matrix’s eigenvalues, arranged from greatest to smallest.
The top three variables with a value greater than 0.60 in
Table 5 were chosen as the main variables of each of the PCs to choose prominent predictor variables for further regression analysis [
21]. For PC1, the global horizontal irradiation (GHI), beam horizontal irradiation (BHI), and beam normal irradiation (BNI) were used. For PC2, the pressure (P) was identified. For PC3, top of atmosphere radiation (TOA), clear sky diffuse horizontal irradiation (CSDHI), and diffuse horizontal irradiation (DHI) were chosen. For PC4, the wind speed parameter was selected. For PC5, cell temperature (Tcell), PV efficiency (Eff), and ambient temperature (Tamb) were used. Finally, only wind direction was identified for PC6. All 12 variables were considered to be PV power driving factors, allowing them to be used as inputs in the proposed predictive models.
3.2. Final Models
3.2.1. Elastic Net Regression
The final values used for the model were
and
. The regression coefficients of the final model are presented below in
Table 6.
3.2.2. Support Vector Regression
We used a radial-based kernel function to conduct an epsilon regression. The final model’s parameters achieving the best fit were , , , and
3.2.3. Random Forest
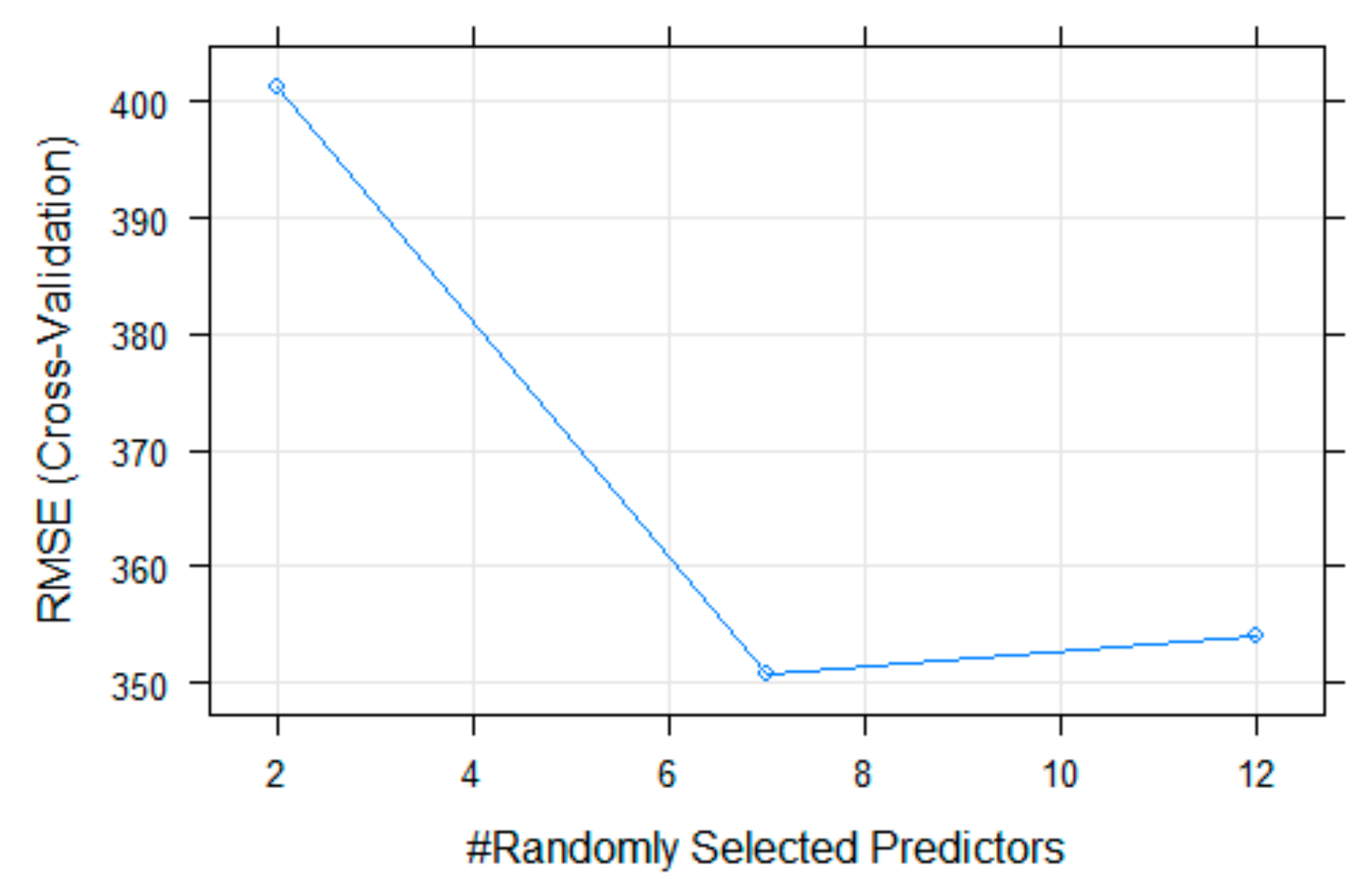
In the final model, the number of variables randomly test at each split was
, as seen in
Figure 2.
3.2.4. Bayesian Regularized Neural Networks
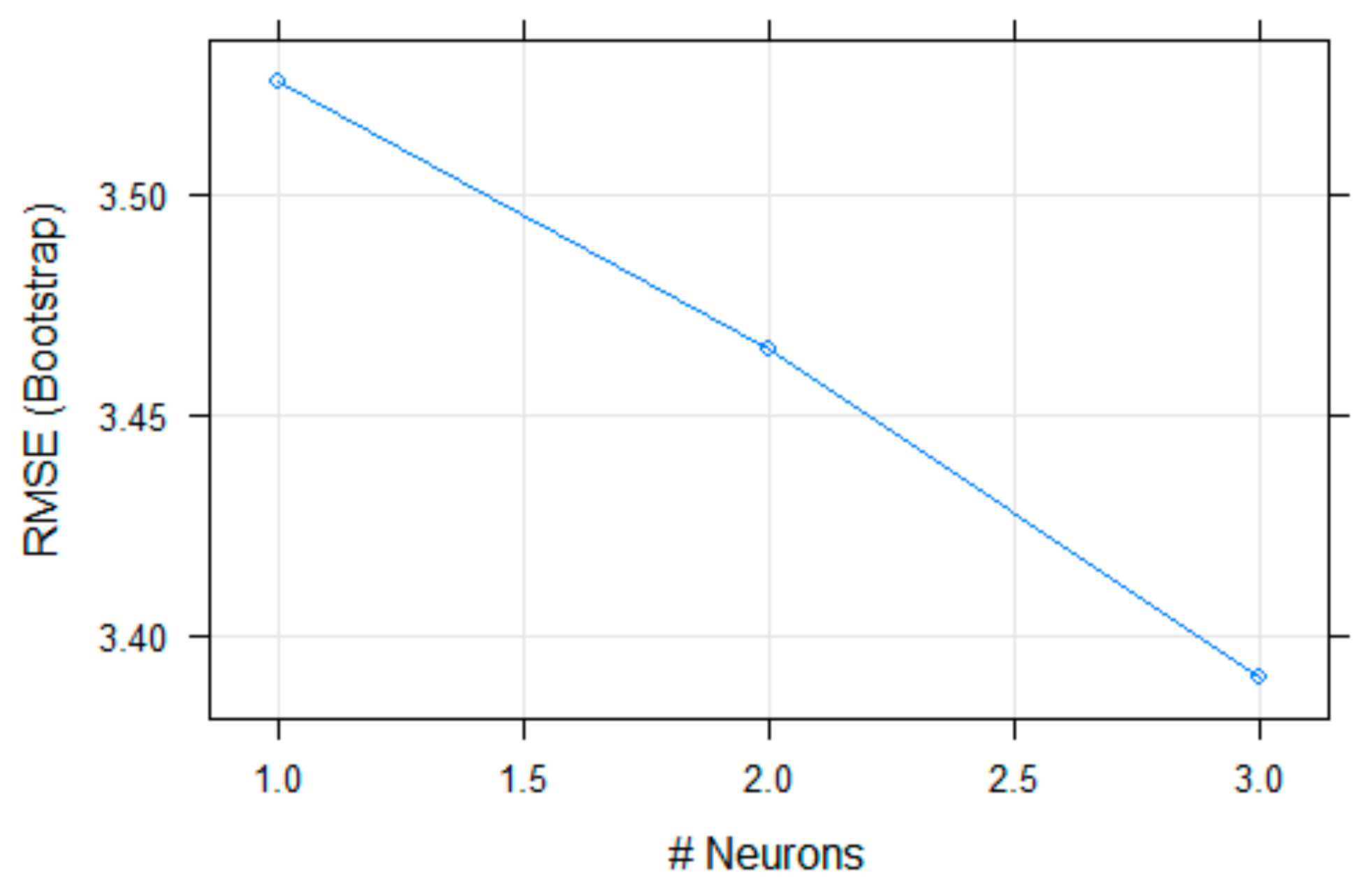
As shown in
Figure 3, the final value of neurons reducing the RMSE error in the final model was
.
3.3. Performance Measures for Predictive Models
The accuracy of the investigated models was measured for the training phase and the testing phase using the most common metrics in regression as presented in
Table 7 and
Table 8.
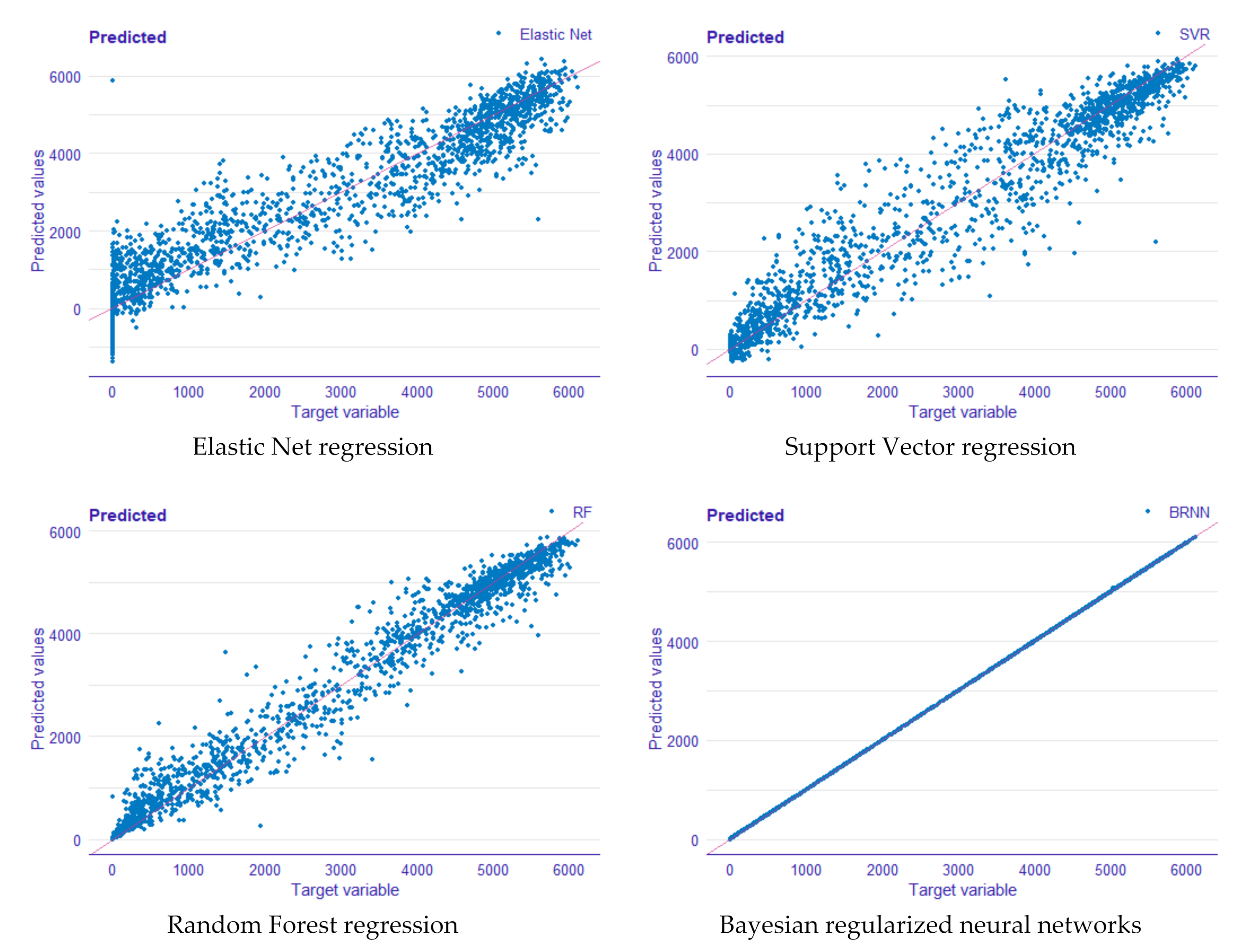
Scatterplots (see
Figure 4) revealed more information about the model’s effectiveness.
Figure 4 shows the scatterplots of predicted values vs. actual ones. For a suitable model, all points should be near to the diagonal line and show no practical dependencies.
3.4. Residual Analysis Result
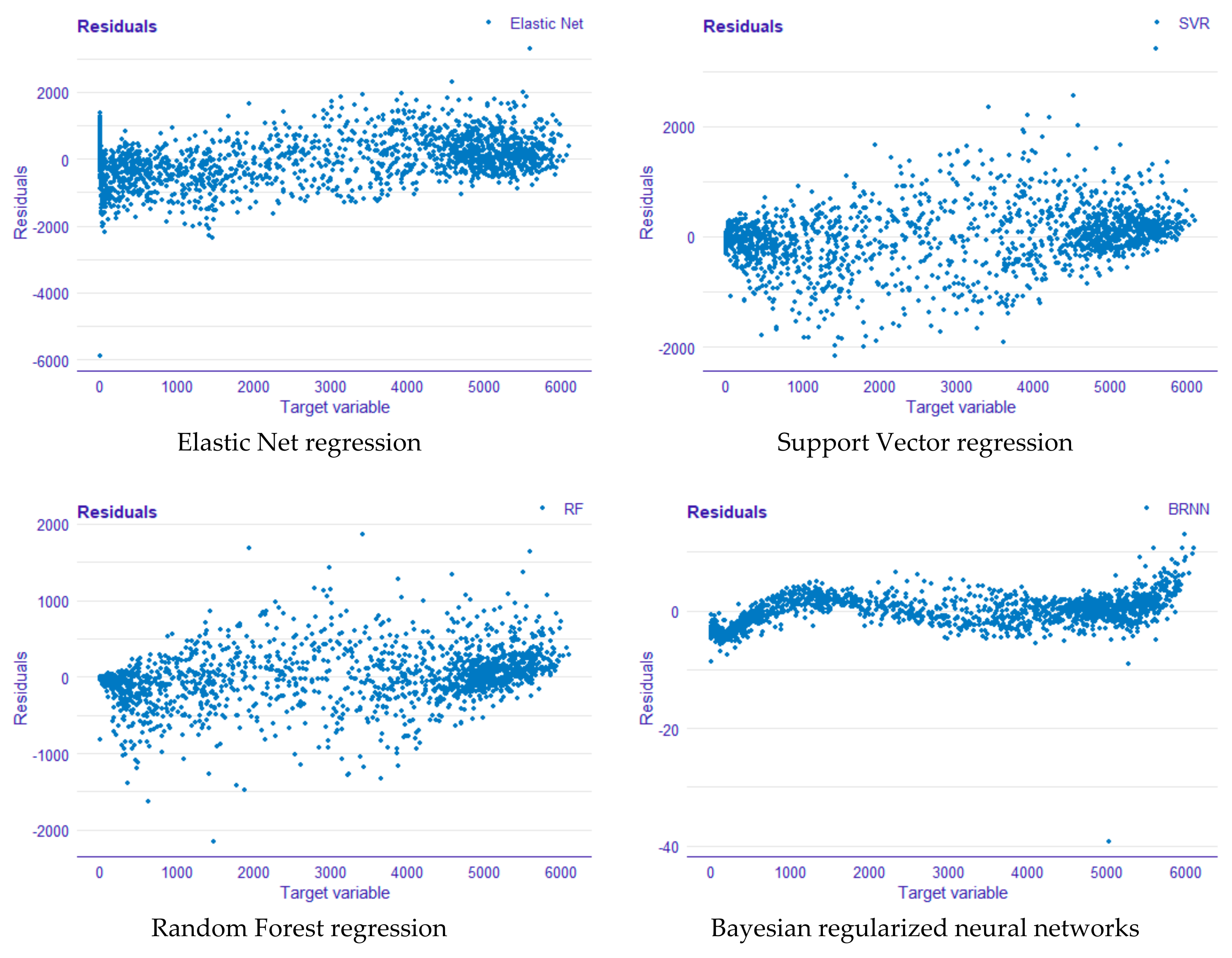
The investigation of residuals is widely acknowledged as a critical step in any regression study. The first plot (see
Figure 5) displays the residuals versus the observed values.
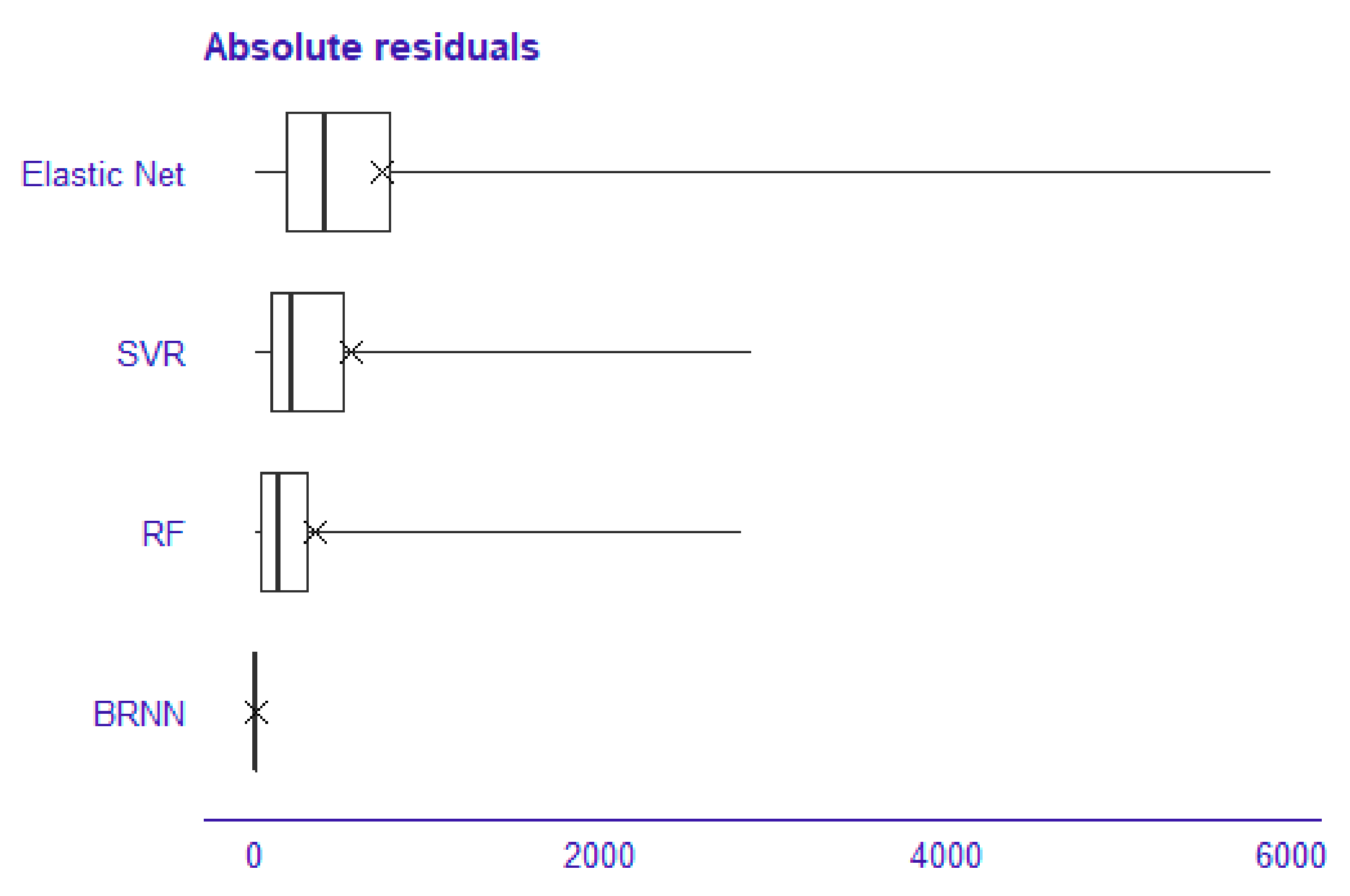
The second plot represents the residual boxplot. It depicts the distribution of absolute residual values as illustrated in
Figure 6.
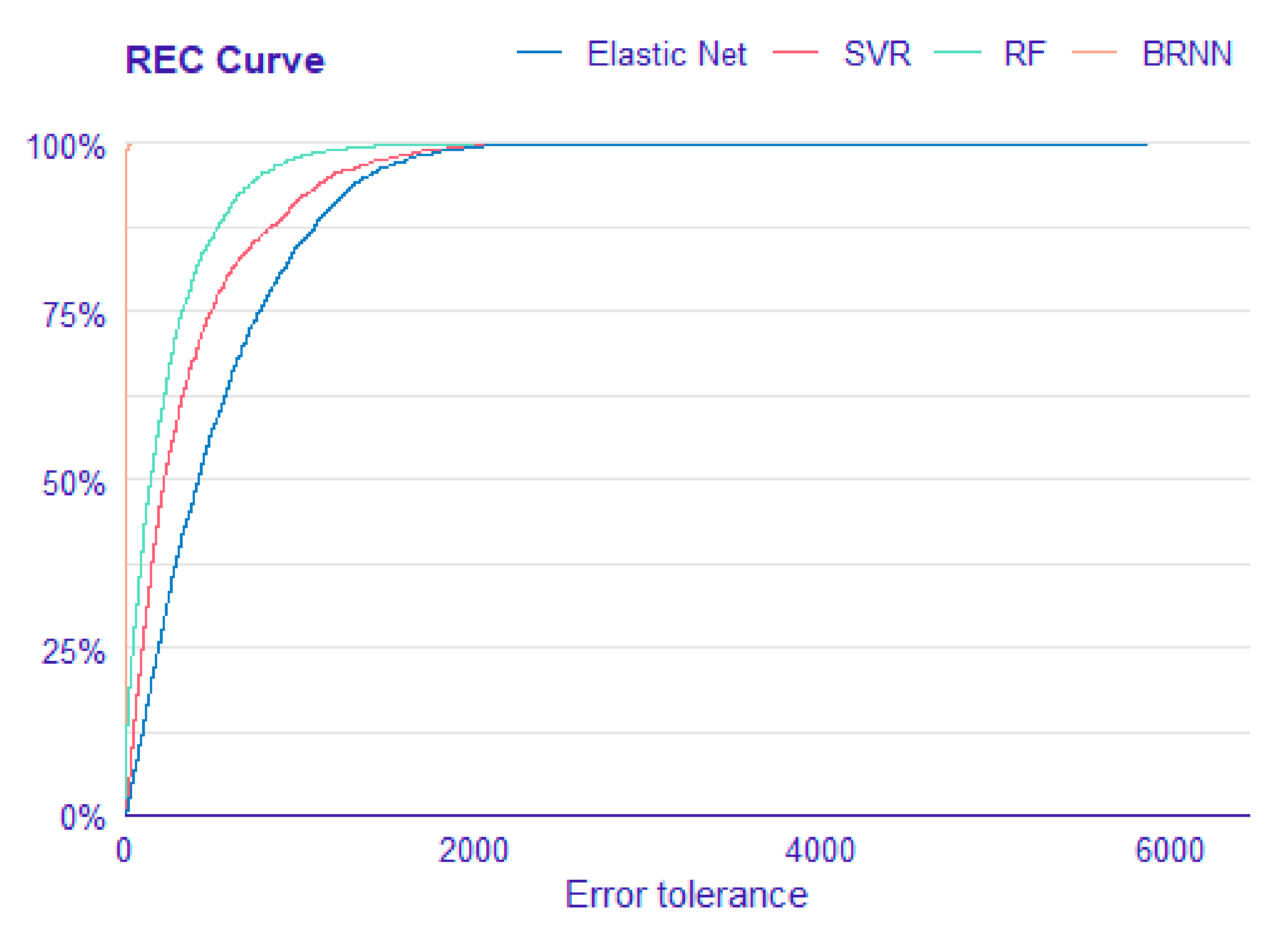
The last plot represents regression error characteristic (REC) curve. This is a regression form of the ROC curve in classification. The error tolerance is plotted on the x-axis, and the percentage of points forecasted inside the tolerance is plotted on the y-axis [
22].
4. Discussion
The principal component analysis (PCA) conducted above revealed six major factor components affecting PV power and explaining up to 90% of the total variable variance. The most significant variables identified using the PCA technique were subsequently used in the proposed models.
Moreover, based on the findings of the performance metrics acquired in
Table 7 and
Table 8, it can be seen that non-linear models, particularly Bayesian regularized neural networks and random forest, obtained the best compromise between the predicted and observed values, with R
2 = 99.99% and R
2 = 99.53%, respectively, in the training phase and R
2 = 99.99% and R
2 = 97.33%, respectively, in the testing phase, while the lowest performance was achieved by linear models such as the elastic net algorithm with R
2 = 89.3% and RMSE = 0.69 kW. This is mainly because non-linear methods are better at including data dynamics and capturing non-linear correlations between variables.
Finally, several plots have been presented above to enable a more accurate study of the models in terms of residuals. For instance, using residual versus observed values plots in
Figure 5 showed that Bayesian regularized neural networks offer better prediction accuracy when compared with the other predictive models investigated in this study, since the residuals are symmetrically distributed around the x-axis (near to zero). In the same way, when examining the residual boxplots (see
Figure 6), we can observe that Bayesian regularized neural networks have the fewest residuals, followed by random forest and support vector regression, unlike elastic net, which has considerably more widely distributed residuals.
Another important tool for comparing and analyzing the accuracy of regression models for different tolerance levels is the REC curve graphic (see
Figure 7). The ideal model is located in the upper left corner, similar to the ROC curve. The better the model, the faster the curve approaches this point, which is the case for the Bayesian regularized neural networks model, followed by random forest.
This study presented deep insight into comparing the performance of four statistical and machine learning techniques for hourly PV power forecasts, which will be useful to researchers and engineers working in the field of solar photovoltaic energy such as PV-integrated smart buildings, efficient energy management system, electric vehicle charging, and smart grids.
5. Conclusions
Two key contributions are made by this study. To begin, the most significant variables affecting PV power were identified using principal component analysis (PCA). In addition, a comparison research was conducted to explore which algorithms forecasted solar PV output power the best.
PV power prediction will not only aid in assuring cost-effective solar power dispatch, but it will also enable solar electricity suppliers to make better financial and funding decisions. Finally, the presented findings show that machine learning algorithms can accurately forecast the output power generated by PV panels in a shorter amount of time. This specificity is determined by the precision of the data utilized, the time horizon, meteorological conditions, and the geographic area.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}