
A Multiple-Choice Machine Reading Comprehension Model with Multi-Granularity Semantic Reasoning

Abstract
:1. Introduction
- 1.
- We design a multi-granularity semantic information extractor and apply it to our proposed MRC model to enhance the comprehension of local sematic meanings, which have been proved beneficial to the model performance in our experiments.
- 2.
- We investigate the semantic interactional reasoning aspect and leverage attention mechanism to extract semantic perceptual information between articles, questions and candidates. By fusing multiple semantic interaction information, we have further improved the performance of our multiple-choice MRC model.
- 3.
- We model the learning process of global semantic information and local semantic information, respectively, and jointly construct a deep global and local semantic multiple-choice MRC model to achieve better deep semantic learning and reasoning for articles, questions and answers in multiple-choice MRC tasks.
2. Related Work
2.1. Rule-Based MRC
2.2. Machine-Learning-Based MRC
2.3. Deep-Learning-Based MRC
3. Method
3.1. Task Definition
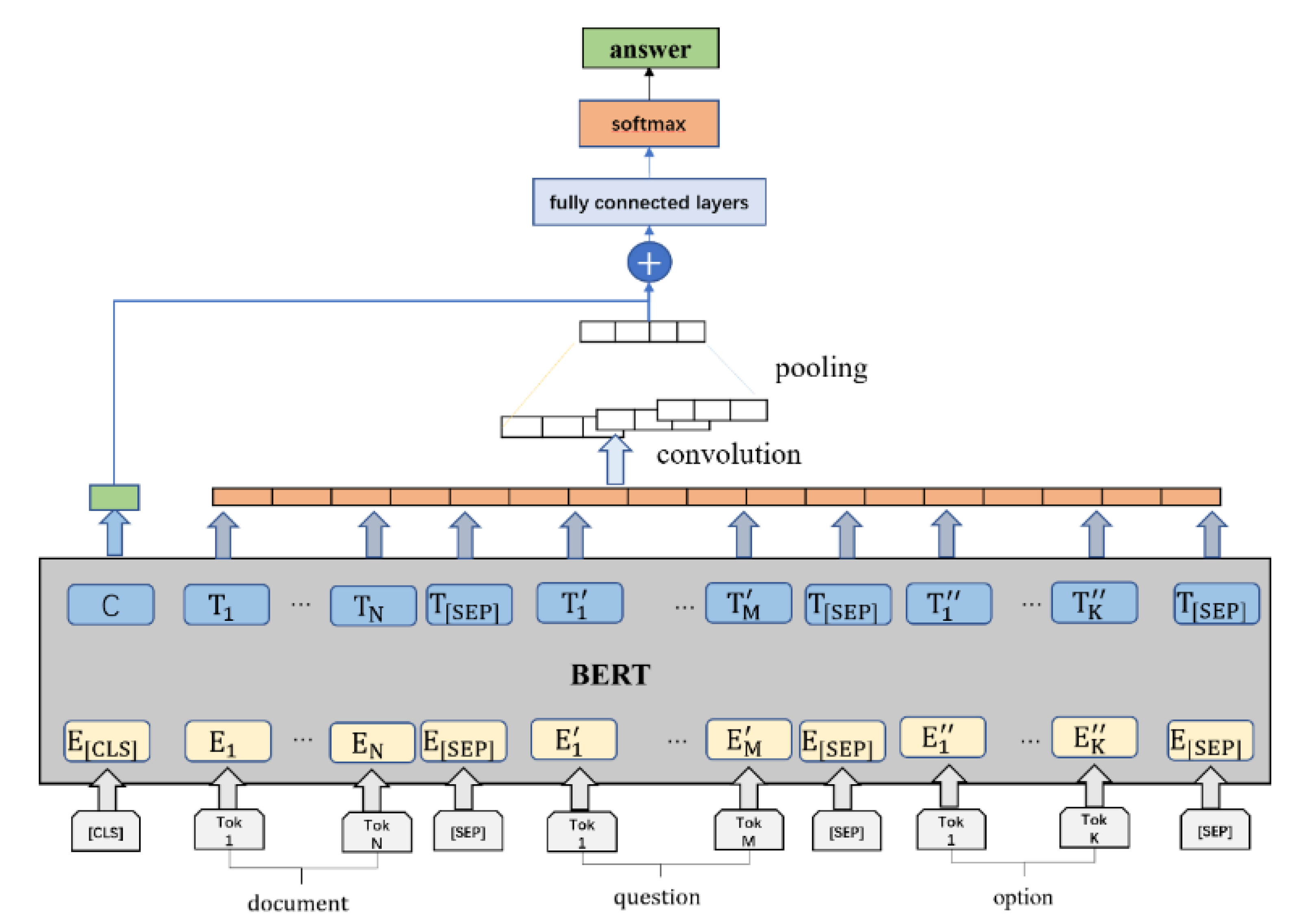
3.2. Model
3.2.1. Input Layer
3.2.2. Embedding Layer
3.2.3. Encoding Layer
3.2.4. Multi Granularity Semantic Reasoning Layer
3.2.5. Information Fusion Layer
3.2.6. Answer Prediction Layer
3.3. Optimization
4. Experiment
4.1. Dataset
4.2. Metrics
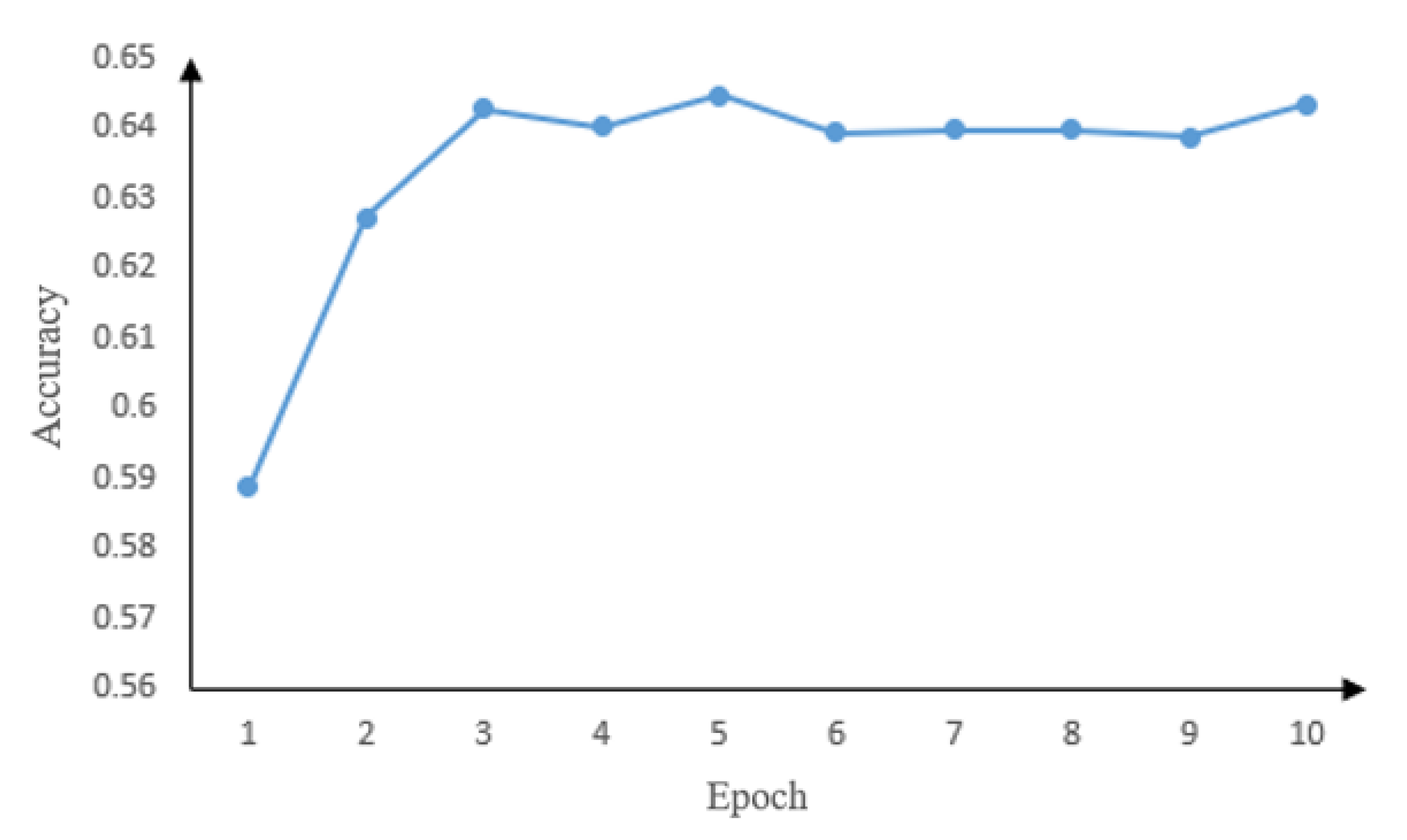
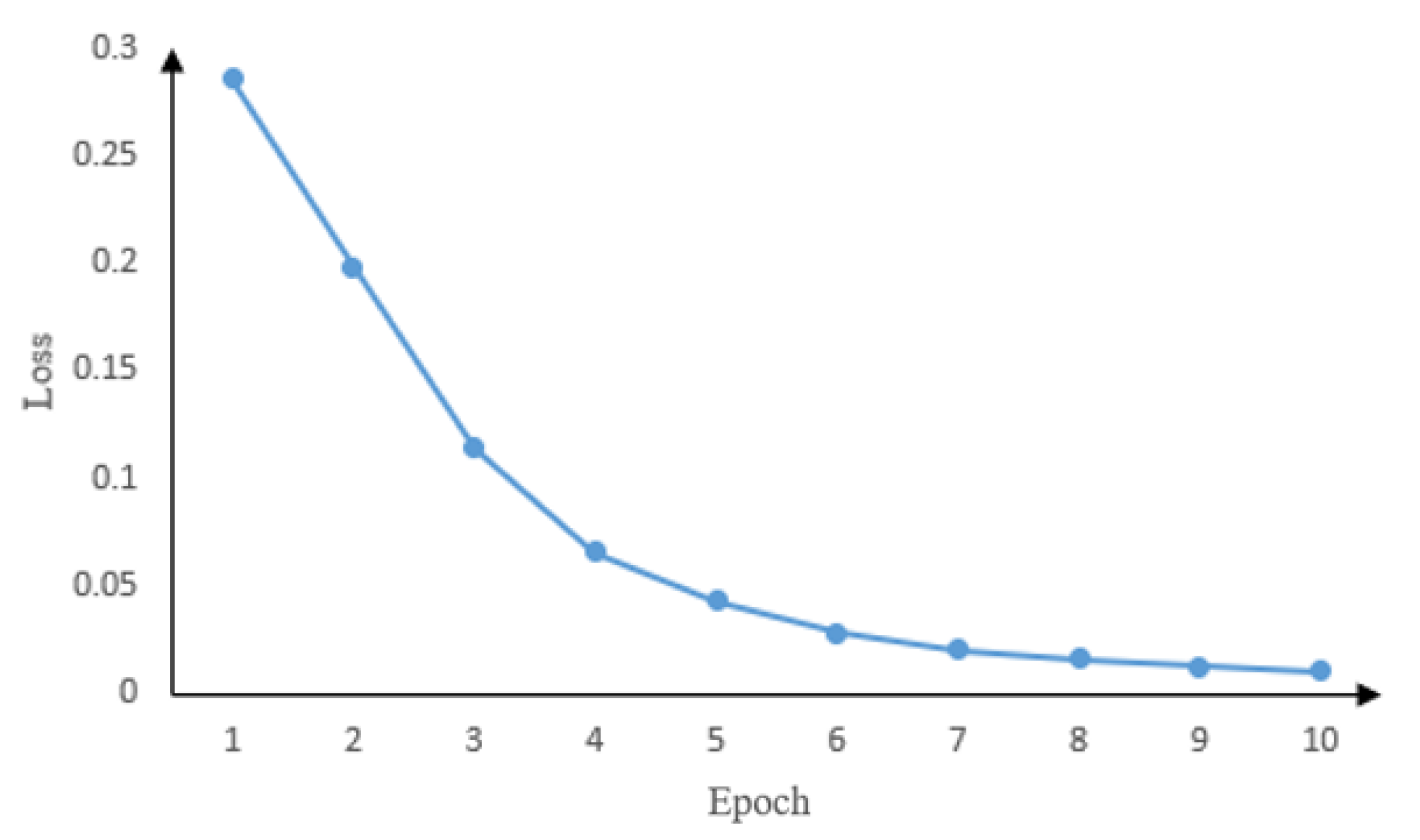
4.3. Experimental Settings
5. Results and Analysis
5.1. Experimental Results
5.2. Ablation Studies
5.3. Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gu, Y.; Gui, X.; Li, D.; Shen, Y.; Liao, D. A Review of Neural Network-based Machine Reading Comprehension. J. Softw. 2020, 20, 2095–2126. [Google Scholar]
- Sheng, Y.; Lan, M. A Multiple-Choice Machine Reading Comprehension Model using External Knowledge Assistance and Multi-Step Reasoning. Comput. Syst. Appl. 2020, 29, 5–13. [Google Scholar]
- Li, C. A Study of Machine Reading Comprehension Based on Semantic Reasoning and Representation. Ph.D. Thesis, East China Normal University, Shanghai, China, 2018. [Google Scholar]
- Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; Hovy, E. RACE: Large-scale ReAding Comprehension Dataset From Examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Ostermann, S.; Modi, A.; Roth, M.; Thater, S.; Pinkal, M. MCScript: A Novel Dataset for Assessing Machine Comprehension Using Script Knowledge. arXiv 2018, arXiv:1803.05223. [Google Scholar]
- Sun, K.; Yu, D.; Yu, D.; Cardie, C. Investigating Prior Knowledge for Challenging Chinese Machine Reading Comprehension. Trans. Assoc. Comput. Linguist. 2020, 8, 141–155. [Google Scholar] [CrossRef]
- Hirschman, L.; Light, M.B.E. Deep read: A reading comprehension system. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 325–332. [Google Scholar]
- Charniak, E.; Altun, Y.B.R.S. Reading Comprehension Programs in a Statistical-Language-Processing Class. In Proceedings of the 2000 ANLP/NAACL Workshop on Reading Comprehension Tests as Evaluation for Computer-Based Language Understanding Sytems, Stroudsburg, PA, USA, 4 May 2000; Volume 6, pp. 1–5. [Google Scholar]
- Richardson, M.; Burges, C.; Renshaw, E. MCTest: A Challenge Dataset for the Open-Domain Machine Comprehension of Text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Narasimhan, K.; Barzilay, R. Machine Comprehension with Discourse Relations. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015. [Google Scholar]
- Sachan, M.; Dubey, K.; Xing, E.; Richardson, M. Learning Answer-Entailing Structures for Machine Comprehension. In Proceedings of the Meeting of the Association for Computational Linguistics & the International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015. [Google Scholar]
- Hai, W.; Bansal, M.; Gimpel, K.; Mcallester, D. Machine Comprehension with Syntax, Frames, and Semantics. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015. [Google Scholar]
- Hermann, K.M.; Kovcisk, T.; Grefenstette, E.; Espeholt, L.; Blunsom, P. Teaching Machines to Read and Comprehend. Adv. Neural Inf. Process. Syst. 2015, 28, 1693–1701. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Wang, S.; Jiang, J. Machine Comprehension Using Match-LSTM and Answer Pointer. arXiv 2016, arXiv:1608.07905. [Google Scholar]
- Yu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Basafa, H.; Movahedi, S.; Ebrahimi, A.; Shakery, A.; Faili, H. NLP-IIS@UT at SemEval-2021 Task 4: Machine Reading Comprehension using the Long Document Transformer. arXiv 2021, arXiv:2105.03775. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Wang, B.; Yao, T.; Zhang, Q.; Xu, J.; Wang, X. ReCO: A Large Scale Chinese Reading Comprehension Dataset on Opinion. arXiv 2020, arXiv:2006.12146. [Google Scholar]
- Zheng, C.; Huang, M.; Sun, A. ChID: A Large-scale Chinese IDiom Dataset for Cloze Test. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 778–787. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, T.; Che, W.; Xiao, L.; Chen, Z.; Ma, W.; Wang, S.; Hu, G. A Span-Extraction Dataset for Chinese Machine Reading Comprehension. arXiv 2018, arXiv:1810.07366. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.; et al. ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Wang, X.; Gao, T.; Zhu, Z.; Liu, Z.; Li, J.; Tang, J. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. arXiv 2019, arXiv:1911.06136. [Google Scholar]
- Cui, Y.; Liu, T.; Wang, S.; Hu, G. Unsupervised Explanation Generation for Machine Reading Comprehension. arXiv 2020, arXiv:2011.06737. [Google Scholar]
- Sun, K.; Yu, D.; Yu, D.; Cardie, C. Probing Prior Knowledge Needed in Challenging Chinese Machine Reading Comprehension. arXiv 2019, arXiv:1904.09679. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parm Type | Parm Value |
|---|---|
| Batch size | 32 |
| Learning rate | 2 × 10 |
| Epoch | 10 |
| Max Length | 512 |
| Dropout | 0.1 |
| Gradient Accumulation Steps | 4 |
| Optimization functions | Adam |
| Model | -Test | -Test | -Test |
|---|---|---|---|
| Random | 27.8 | 26.6 | 27.2 |
| Distance-Based Sliding Window | 45.8 | 40.4 | 43.1 |
| Co-Matching | 48.2 | 51.4 | 49.8 |
| ERNIE | 63.7 | 64.6 | 64.1 |
| BERT | 64.6 | 64.4 | 64.5 |
| Our model | 65.234 | 65.238 | 65.236 |
| Model | -Test | -Test | -Test |
|---|---|---|---|
| BERT | 64.6 | 64.4 | 64.5 |
| Local Multi-Granularity Model | 63.08 | 63.439 | 63.25 |
| Local + Global-Granularity Model | 65.234 | 65.238 | 65.236 |
| Model | BERT | Our Model | ||
|---|---|---|---|---|
| Dataset | -Test | -Test | -Test | -Test |
| Semantic Reasoning | 81.5 | 81.8 | 88.9 | 90.91 |
| Implicative Reasoning | 62.5 | 0 | 75.0 | 0 |
| Causal Reasoning | 55.6 | 57.1 | 66.7 | 57.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y.; Fu, Y.; Yang, L. A Multiple-Choice Machine Reading Comprehension Model with Multi-Granularity Semantic Reasoning. Appl. Sci. 2021, 11, 7945. https://doi.org/10.3390/app11177945
Dai Y, Fu Y, Yang L. A Multiple-Choice Machine Reading Comprehension Model with Multi-Granularity Semantic Reasoning. Applied Sciences. 2021; 11(17):7945. https://doi.org/10.3390/app11177945
Chicago/Turabian StyleDai, Yu, Yufan Fu, and Lei Yang. 2021. "A Multiple-Choice Machine Reading Comprehension Model with Multi-Granularity Semantic Reasoning" Applied Sciences 11, no. 17: 7945. https://doi.org/10.3390/app11177945
APA StyleDai, Y., Fu, Y., & Yang, L. (2021). A Multiple-Choice Machine Reading Comprehension Model with Multi-Granularity Semantic Reasoning. Applied Sciences, 11(17), 7945. https://doi.org/10.3390/app11177945