
Automatic Surgical Instrument Recognition—A Case of Comparison Study between the Faster R-CNN, Mask R-CNN, and Single-Shot Multi-Box Detectors

Abstract
:Feature Application
Abstract
1. Introduction
2. Methods
2.1. Dataset
2.2. The Faster R-CNN Network
2.3. The Mask R-CNN Network
2.4. The Single-Show Multi-Box Detector (SSD) Network
2.5. Comparison of the Networks
3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
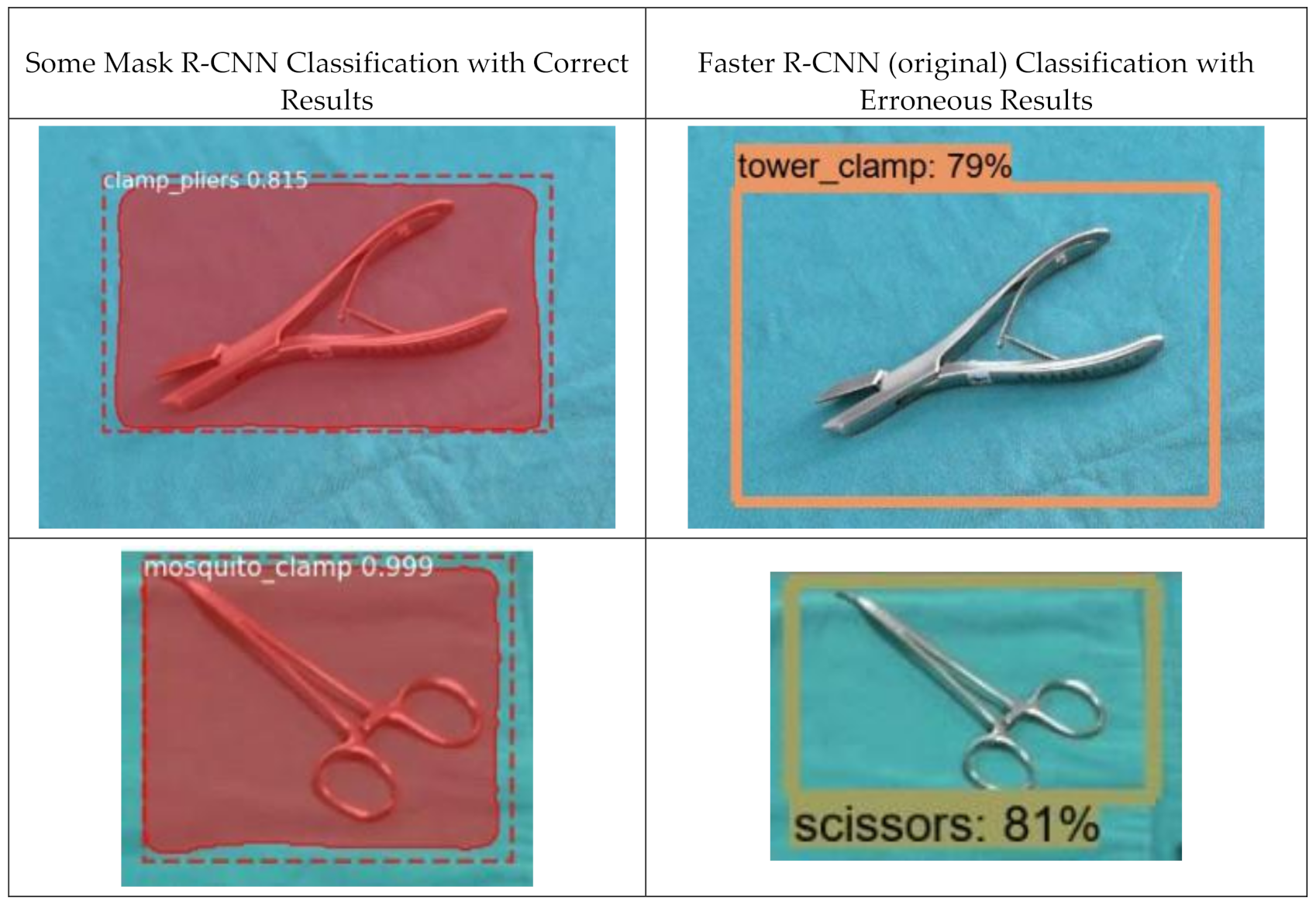{kind=link}
| Multi-box SSD | clamp pliers | diagonal pliers | forceps | gunshaped forceps | gunshaped forceps+ | long scalpel | medium scalpel | mosquito clamp | mosquito scissors | scissors | short scalpel | spring needle holder | steel push | towel clamp |
| clamp _pliers | 271 | 4 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| diagonal _pliers | 0 | 229 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| forceps | 0 | 0 | 253 | 1 | 2 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| gunshaped _forceps | 0 | 0 | 0 | 230 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| gunshaped _forceps+ | 0 | 0 | 0 | 4 | 172 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| long_ scalpel | 0 | 0 | 0 | 1 | 0 | 234 | 0 | 3 | 0 | 0 | 1 | 0 | 0 | 0 |
| medium_ scalpel | 0 | 0 | 1 | 1 | 0 | 17 | 120 | 0 | 0 | 0 | 1 | 3 | 0 | 0 |
| mosquito_ clamp | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 232 | 0 | 4 | 0 | 0 | 0 | 21 |
| mosquito_ scissors | 0 | 0 | 1 | 0 | 0 | 2 | 0 | 19 | 149 | 11 | 0 | 0 | 0 | 0 |
| scissors | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 216 | 0 | 0 | 0 | 4 |
| short _scalpel | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 2 | 0 | 0 | 248 | 0 | 0 | 0 |
| spring needle holder | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 269 | 0 | 5 |
| steel_ push | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 147 | 0 |
| towel_ clamp | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 47 | 0 | 6 | 0 | 127 |
| no_label (undetected) | 2 | 18 | 32 | 11 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 3 | 25 |
| Faster RCNN (COCO) | clamp pliers | diagonal pliers | forceps | gunshaped forceps | gunshaped forceps+ | long scalpel | medium scalpel | mosquito clamp | mosquito scissors | scissors | short scalpel | spring needle holder | steel push | towel clamp |
| clamp _pliers | 272 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| diagonal _pliers | 1 | 251 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| forceps | 0 | 0 | 252 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0 |
| gunshaped _forceps | 0 | 0 | 13 | 207 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| gunshaped _forceps+ | 0 | 0 | 1 | 36 | 174 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 |
| long_ scalpel | 0 | 0 | 0 | 1 | 0 | 250 | 1 | 0 | 0 | 0 | 5 | 0 | 0 | 0 |
| medium_ scalpel | 0 | 0 | 8 | 1 | 0 | 4 | 118 | 0 | 0 | 0 | 10 | 2 | 0 | 0 |
| mosquito_ clamp | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 237 | 0 | 27 | 0 | 0 | 0 | 5 |
| mosquito_ scissors | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 147 | 19 | 0 | 0 | 0 | 0 |
| scissors | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 182 | 0 | 0 | 0 | 13 |
| short _scalpel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 226 | 0 | 0 | 0 |
| spring needle holder | 0 | 0 | 3 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 262 | 0 | 5 |
| steel_ push | 0 | 0 | 8 | 0 | 0 | 0 | 1 | 6 | 0 | 0 | 8 | 0 | 150 | 0 |
| towel_ clamp | 0 | 5 | 0 | 4 | 0 | 0 | 0 | 4 | 0 | 51 | 0 | 4 | 0 | 157 |
| no_label (undetected) | 0 | 2 | 5 | 5 | 1 | 3 | 0 | 2 | 0 | 0 | 2 | 6 | 0 | 2 |
| Faster RCNN | clamp pliers | diagonal pliers | forceps | gunshaped forceps | gunshaped forceps+ | long scalpel | medium scalpel | mosquito clamp | mosquito scissors | scissors | short scalpel | spring needle holder | steel push | towel clamp |
| clamp _pliers | 271 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| diagonal _pliers | 2 | 256 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| forceps | 0 | 0 | 287 | 10 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0 |
| gunshaped _forceps | 0 | 0 | 0 | 241 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| gunshaped _forceps+ | 0 | 0 | 0 | 4 | 172 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| long_ scalpel | 0 | 0 | 0 | 0 | 0 | 254 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| medium_ scalpel | 0 | 0 | 3 | 0 | 0 | 0 | 120 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| mosquito_ clamp | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 243 | 0 | 0 | 0 | 0 | 0 | 6 |
| mosquito_ scissors | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 150 | 2 | 0 | 0 | 0 | 0 |
| scissors | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 274 | 0 | 0 | 0 | 13 |
| short _scalpel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 250 | 0 | 0 | 0 |
| spring needle holder | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 271 | 0 | 5 |
| steel_ push | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 150 | 0 |
| towel_ clamp | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 1 | 1 | 0 | 0 | 157 |
| no_label (undetected) | 0 | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 1 |
| Masked RCNN | clamp pliers | diagonal pliers | forceps | gunshaped forceps | gunshaped forceps+ | long scalpel | medium scalpel | mosquito clamp | mosquito scissors | scissors | short scalpel | spring needle holder | steel push | towel clamp |
| clamp _pliers | 273 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| diagonal _pliers | 0 | 258 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| forceps | 0 | 0 | 289 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| gunshaped _forceps | 0 | 0 | 0 | 256 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| gunshaped _forceps+ | 0 | 0 | 0 | 2 | 176 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| long_ scalpel | 0 | 0 | 0 | 0 | 0 | 257 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| medium_ scalpel | 0 | 0 | 0 | 0 | 0 | 0 | 120 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| mosquito_ clamp | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 258 | 0 | 3 | 0 | 0 | 0 | 0 |
| mosquito_ scissors | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 150 | 0 | 0 | 0 | 0 | 0 |
| scissors | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 273 | 0 | 0 | 0 | 2 |
| short _scalpel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 250 | 0 | 0 | 0 |
| spring needle holder | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 | 0 | 5 |
| steel_ push | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 150 | 0 |
| towel_ clamp | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 1 | 1 | 0 | 0 | 157 |
| no_label (undetected) | 0 | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 1 |
References
- Wubben, I.; van Manen, J.G.; van den Akker, B.J.; Vaartjes, S.R.; van Harten, W.H. Equipment-related incidents in the operating room: An analysis of occurrence, underlying causes and consequences for the clinical process. J. Qual. Saf. Health Care 2010, 6, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guédon, A.C.P.; Wauben, L.S.G.L.; Van Der Eijk, A.C.; Vernooij, A.S.N.; Meeuwsen, F.C.; Van Der Elst, M.; Hoeijmans, V.; Dankelman, J.; Dobbelsteen, J.J.V.D. Where are my instruments? Hazards in delivery of surgical instruments. Surg. Endosc. 2016, 30, 2728–2735. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hosaka, R.; Noji, R. Automatic identification for surgical instruments using UHF band passive RFID. In Proceedings of the VI Latin American Congress on Biomedical Engineering CLAIB 2014, Paraná, Argentina, 29–31 October 2014; Springer Science and Business Media LLC.: Singapore, 2017; Volume 65, pp. 1061–1064. [Google Scholar]
- Lin, Q.; Cai, K.; Yang, R.; Chen, H.; Wang, Z.; Zhou, J. Development and Validation of a Near-Infrared Optical System for Tracking Surgical Instruments. J. Med. Syst. 2016, 40, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Wachs, J.P. Needle in a haystack: Interactive surgical instrument recognition through perception and manipulation. Robot. Auton. Syst. 2017, 97, 182–192. [Google Scholar] [CrossRef]
- Cai, T.; Zhao, Z. Convolutional neural network-based surgical instrument detection. Technol. Health Care 2020, 28, 81–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- EndoVis Grand Challenge. Available online: https://endovis.grand-challenge.org/ (accessed on 30 May 2021).
- Zhao, Z.; Cai, T.; Chang, F.; Cheng, X. Real-time Surgical Instrument Detection in Robot-Assisted Surgery using a Convolutional Neural Network Cascade. Healthc. Technol. Lett. 2019, 6, 275. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, L.; Wang, P.; Yan, Y.; Xia, Y.; Cao, W. MASSD: Multi-scale attention single shot detector for surgical instruments. Comput. Biol. Med. 2020, 123, 103867. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE, Manhattan, NY, USA. pp. 2980–2988. [Google Scholar]
- Sanchez, S.A.; Romero, H.J.; Morales, A.D. A review: Comparison of performance metrics of pretrained models for object detection using the TensorFlow framework. IOP Conf. Series: Mater. Sci. Eng. 2020, 844, 15. [Google Scholar] [CrossRef]
- Hui, J. Object Detection: Speed and Accuracy Comparison. Available online: https://jonathan-hui.medium.com/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo-5425656ae359 (accessed on 15 September 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Lect. Notes Comput. Sci. 2016, 9905, 21–37. [Google Scholar]
- Chang Gung Memorial Hospital at Linkou, Taiwan. Available online: https://www1.cgmh.org.tw/branch/lnk/2016/en/ (accessed on 8 March 2020).
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, X.; Tu, D. Face Detection Using Improved Faster RCNN. arXiv 2018, arXiv:1802.02142. [Google Scholar]
- Ren, Y.; Zhu, C.; Xiao, S. Object Detection Based on Fast/Faster RCNN Employing Fully Convolutional Architectures. Math. Probl. Eng. 2018, 2018, 3598316. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, A.Q.; Nguyen, H.T.; Tran, V.C.; Pham, H.X.; Pestana, J. A Visual Real-time Fire Detection using Single Shot MultiBox Detector for UAV-based Fire Surveillance. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), Phu Quoc Island, Vietnam, 13–15 January 2021; pp. 338–343. [Google Scholar]
- Kanimozhi, S.; Gayathri, G.; Mala, T. Multiple Real-time object identification using Single shot Multi-Box detection. In Proceedings of the 2019 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 21–23 February 2019; pp. 1–5. [Google Scholar]
- Ge, W.; Yu, Y. Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-Tuning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Hawaii, HI, USA, 21–26 July 2017; pp. 10–19. [Google Scholar]
- Common Objects in Context (COCO). Available online: https://cocodataset.org/ (accessed on 15 April 2021).
- Python. Available online: https://www.python.org/ (accessed on 8 February 2021).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, CA, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Hawaii, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]

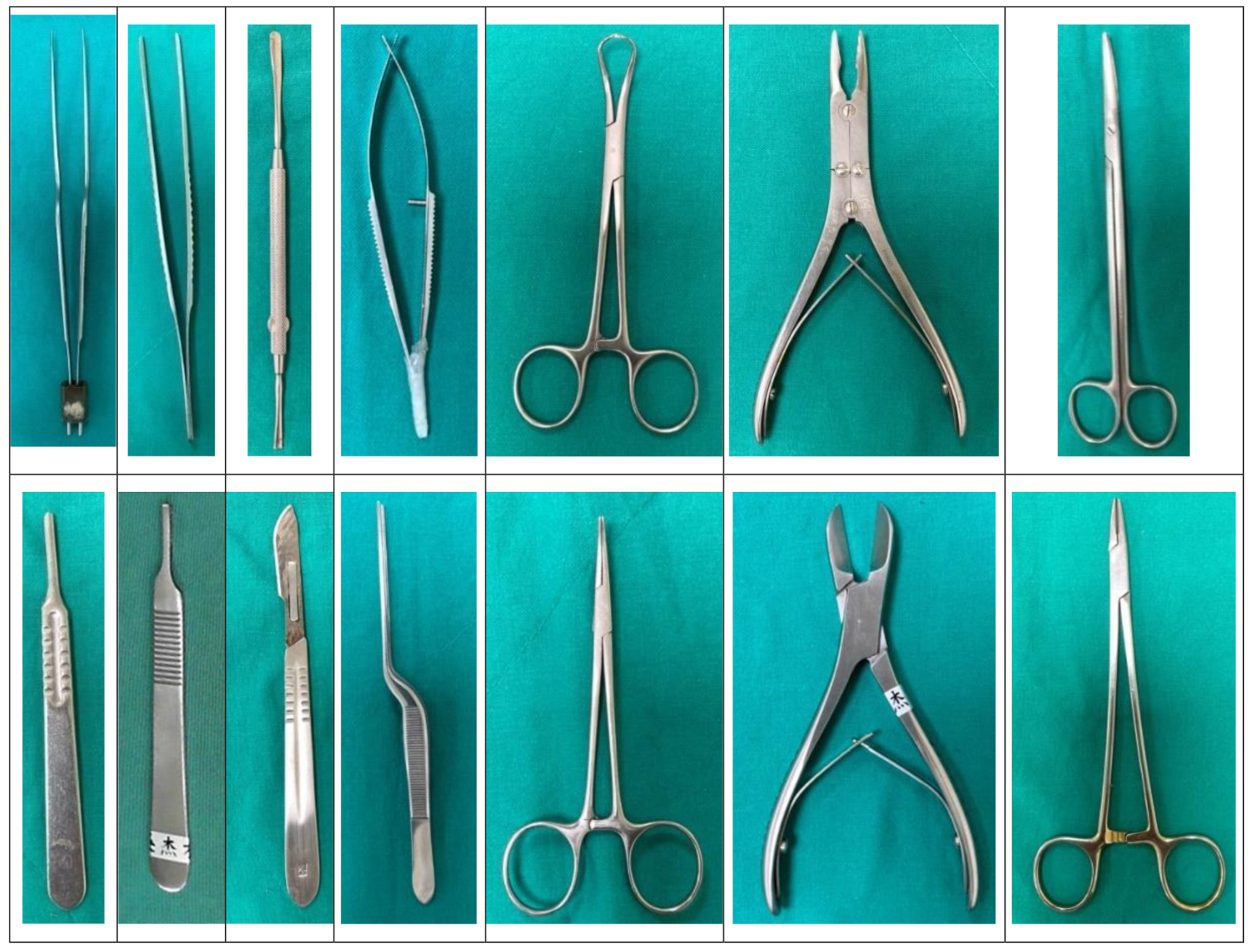








| Surgical Instrument | Number of Test Sample |
|---|---|
| Clamp Pliers | 273 |
| Diagonal Pliers | 258 |
| Forceps (General) | 289 |
| Gunshaped Forceps | 259 |
| Gunshaped Forceps+ (Modifed) | 176 |
| Long Scapel | 259 |
| Medium Scapel | 120 |
| Short Scapel | 251 |
| Mosquito Clamp | 259 |
| Mosquito Scissors | 150 |
| Scissors (General) | 279 |
| Needle Holder | 280 |
| Steel Push | 150 |
| Towel Clamp | 182 |
| Surgical Instrument | Faster R-CNN, MAP | Faster R-CNN (COCO), MAP | Mask R-CNN, MAP | Multi-Box SSD, MAP |
|---|---|---|---|---|
| clamp_pliers | 99.63% ± 0.2% | 96.34% ± 2.6% | 100% ± 0% | 93% ± 2.7% |
| diagonal_pliers | 99.74% ± 0.2% | 88.76% ± 6.9% | 99.26% ± 0.2% | 94.52% ± 4.2% |
| forceps | 99.65% ± 0.2% | 86.85% ± 0.3% | 99.51% ± 0.2% | 88.15% ± 1.3% |
| gunshaped_forceps | 89.19% ± 3% | 73.36% ± 5.4% | 99.21% ± 0.3% | 93.82% ± 3.9% |
| gunshaped_forceps+ | 100.00% ± 0% | 98.86% ± 0.5% | 99.5% ± 0.3% | 92.87% ± 4.2% |
| long_scalpel | 99.23% ± 0.3% | 81.08% ± 12.6% | 99.21% ± 0.3% | 94.94% ± 3.7% |
| medium_scalpel | 100.00% ± 0% | 98.33% ± 0.7% | 99.49% ± 0.3% | 100.00% ± 0% |
| mosquito_clamp | 93.82% ± 0.2% | 79.54% ± 10% | 99.21% ± 0.7% | 89.91% ± 0.3% |
| mosquito_scissors | 99.78% ± 0.2% | 98% ± 0.3% | 99.07% ± 0.2% | 96.33% ± 1.1% |
| scissors | 97.85% ± 0.6% | 63.80% ± 5.3% | 100% ± 0% | 87.66% ± 11.3% |
| short_scalpel | 99.60% ± 0.2% | 87.25% ± 2.1% | 99.14% ± 0..3% | 99.20% ± 0.5% |
| spring_needle_holders | 93.57% ± 0.2% | 96.97% ± 3% | 98.01% ± 0.5% | 87.09% ± 7.1% |
| steel_push | 99.78% ± 0.3% | 100% ± 0% | 100% ± 0% | 94.79% ± 2.8% |
| towel_clamp | 86.26% ± 3.9% | 78.02% ± 6.8% | 93.18% ± 2.1% | 85.24% ± 10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-D.; Chien, J.-C.; Hsu, Y.-T.; Wu, C.-T. Automatic Surgical Instrument Recognition—A Case of Comparison Study between the Faster R-CNN, Mask R-CNN, and Single-Shot Multi-Box Detectors. Appl. Sci. 2021, 11, 8097. https://doi.org/10.3390/app11178097
Lee J-D, Chien J-C, Hsu Y-T, Wu C-T. Automatic Surgical Instrument Recognition—A Case of Comparison Study between the Faster R-CNN, Mask R-CNN, and Single-Shot Multi-Box Detectors. Applied Sciences. 2021; 11(17):8097. https://doi.org/10.3390/app11178097
Chicago/Turabian StyleLee, Jiann-Der, Jong-Chih Chien, Yu-Tsung Hsu, and Chieh-Tsai Wu. 2021. "Automatic Surgical Instrument Recognition—A Case of Comparison Study between the Faster R-CNN, Mask R-CNN, and Single-Shot Multi-Box Detectors" Applied Sciences 11, no. 17: 8097. https://doi.org/10.3390/app11178097