
Deep Learning Model for the Inspection of Coffee Bean Defects


Abstract
:1. Introduction
1.1. Coffee Bean Defects Detection
1.2. CNN
1.3. CNN in Agricultural Applications
1.4. AlexNet
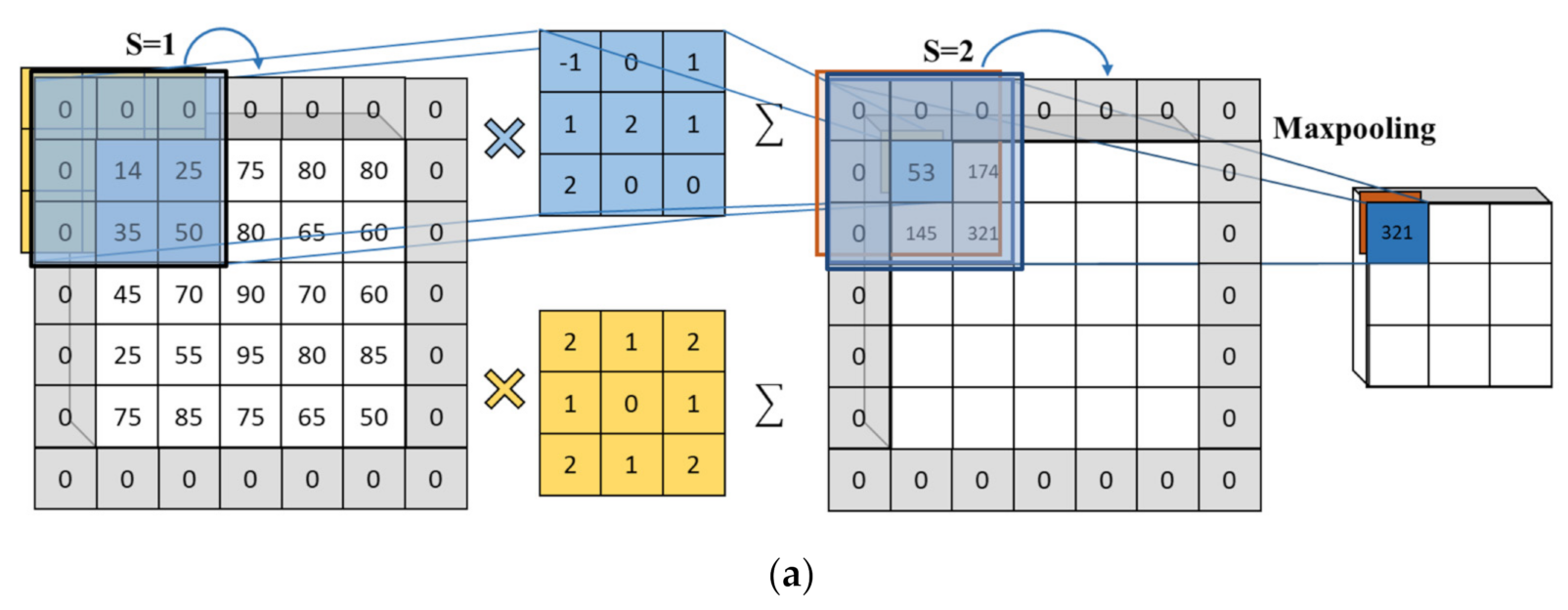
2. Materials and Methods
2.1. Image Preprocessing
2.2. Initial Model Construction
2.3. Visual Evaluation
2.4. Model Modification
2.4.1. Feature Extraction and Dimensionality Reduction
2.4.2. Padding
2.4.3. Activation Function
3. Results
3.1. Dataset
- Each coffee bean is only photographed once to avoid over augmentation.
- To avoid including the same bean sample in the training set and test set. The original sample is divided into a training set and a test set before augmentation.
- Since the coffee beans are elliptical, the sample only undergoes a 90-degree rotation augmentation.
3.2. Experiment Settings
- Feature extraction and dimensionality reduction
- Padding
- Activation Function
3.3. Experimental Results
3.4. Testing in Other Networks
3.5. Comparison with Other Networks
4. Discussion
- In the proposed improved convolution architecture, each neuron uses different training weights to reduce dimensionality. It is different from the other network that performs the same dimensionality reduction on all neurons in the pooling layer. Therefore, more features can be retained after image dimensionality reduction.
- The proposed single-stride pooling layer performs feature contrast enhancement without reducing the dimensionality. In the new network-final model, an improved pooling layer is added after the four convolutional layers, which greatly improves the training accuracy.
- The leaky ReLU alleviates the rigidity of the ReLU and retains the extremely small slope of each negative feature value. The results indicated that the leaky ReLU did not reduce the model learning performance and retained the features that were lost by the dead neurons generated by the ReLU; thus, higher model accuracy was obtained with the leaky ReLU than with the regular ReLU.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xie, Q.; Li, D.; Xu, J.; Yu, Z.; Wang, J. Automatic detection and classification of sewer defects via hierarchical deep learning. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1836–1847. [Google Scholar] [CrossRef]
- Tello, G.; Al-Jarrah, O.Y.; Yoo, P.D.; Al-Hammadi, Y.; Muhaidat, S.; Lee, U. Deep-structured machine learning model for the recognition of mixed-defect patterns in semiconductor fabrication processes. IEEE Trans. Semicond. Manuf. 2018, 31, 315–322. [Google Scholar] [CrossRef]
- Nasiri, A.; Taheri-Garavand, A.; Zhang, Y.D. Image-based deep learning automated sorting of date fruit. Postharvest Biol. Technol. 2019, 153, 133–141. [Google Scholar] [CrossRef]
- da Costa, A.Z.; Figueroa, H.E.; Fracarolli, J.A. Computer vision based detection of external defects on tomatoes using deep learning. Biosyst. Eng. 2020, 190, 131–144. [Google Scholar] [CrossRef]
- Casaño, C.D.L.C.; Sánchez, M.C.; Chavez, F.R.; Ramos, W.V. Defect detection on andean potatoes using deep learning and adaptive learning. In Proceedings of the IEEE Engineering International Research Conference (EIRCON), Lima, Peru, 21–23 October 2020. [Google Scholar]
- Chouhan, S.S.; Kaul, A.; Singh, U.P. A deep learning approach for the classification of diseased plant leaf images. In Proceedings of the International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 17–19 July 2019. [Google Scholar]
- Marzougui, F.; Elleuch, M.; Kherallah, M. A Deep CNN Approach for plant disease detection. In Proceedings of the 2020 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, 28–30 November 2020. [Google Scholar]
- Oliveri, P.; Malegori, C.; Casale, M.; Tartacca, E.; Salvatori, G. An innovative multivariate strategy for HSI-NIR images to automatically detect defects in green coffee. Talanta 2019, 199, 270–276. [Google Scholar] [CrossRef]
- Birhanu, H.; Tesfa, T. Ethiopian roasted coffee classification using imaging techniques. In Proceedings of the 3rd International Conference on the Advancement of Science and Technology, Bahirdar, Ethiopia, 8–9 May 2015. [Google Scholar]
- Faridah, F.; Parikesit, G.O.F.; Ferdiansjah., F. Coffee bean grade determination based on image parameter. Telkomnika 2011, 9, 547–554. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhou, H.; Zhuang, Z.; Liu, Y.; Liu, Y.; Zhang, X. Defect classification of green plums based on deep learning. Sensor 2020, 20, 6993. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Song, J. An intelligent classification model for surface defects on cement concrete bridges. Appl. Sci. 2020, 10, 972. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Stursa, D.; Dolezel, P. Comparison of ReLU and linear saturated activation functions in neural network for universal approximation. In Proceedings of the 22nd International Conference on Process Control (PC19), Štrbské Pleso, Slovakia, 11–14 June 2019. [Google Scholar]
- Hongyo, R.; Egashira, Y.; Yamaguchi, K. Deep neural network based predistorter with relu activation for Doherty power amplifiers. In Proceedings of the Asia-Pacific Microwave Conference (APMC), Kyoto, Japan, 6–9 November 2018. [Google Scholar]
- Lee, K.; Sung, S.H.; Kim, D.H.; Park, S.H. Verification of normalization effects through comparison of CNN models. In Proceedings of the International Conference on Multimedia Analysis and Pattern Recognition (MAPR), Ho Chi Minh City, Vietnam, 9–10 May 2019. [Google Scholar]
- Tian, Y.; Chen, F.; Wang, H.; Zhang, S. Real-time semantic segmentation network based on lite reduced atrous spatial pyramid pooling module group. In Proceedings of the 5th International Conference on Control, Robotics and Cybernetics (CRC), Wuhan, China, 16–18 October 2020. [Google Scholar]
- Hyun, J.; Seong, H.; Kim, E. Universal pooling—A new pooling method for convolutional neural networks. Expert Syst. Appl. 2021, 180, 115084. [Google Scholar] [CrossRef]
- de Buy Wenniger, G.M.; Schomaker, L.; Way, A. No padding please: Efficient neural handwriting recognition. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Douglas, S.C.; Yu, J. Why RELU units sometimes die: Analysis of single-unit error backpropagation in neural networks. In Proceedings of the 52nd Asilomar Conference on Signals, Systems, and Computers (ACSSC), Pacific Grove, CA, USA, 28–31 October 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, Cambridge, MA, USA, 20–23 June 1995. [Google Scholar]
- Wang, Y.J.; Hsu, C.W.; Sue, C.Y. Design and calibration of a dual-frame force and torque sensor. IEEE Sens. J. 2020, 20, 12134–12145. [Google Scholar] [CrossRef]
- Parhi, R.; Nowak, R.D. The role of neural network activation functions. IEEE Signal Process. Lett. 2020, 27, 1779–1783. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Strength | Weakness |
|---|---|---|
| Principal component analysis | extract vector features from images the number of features is adjustable | small components may be ignored |
| Geometrical feature extraction | extract appearance features identify the appearance differences of different varieties | features associated with color and brightness cannot be extracted |
| Textural feature extraction | extract features associated with the overall image evenness and color concentration | image background will affect the uniformity of the image |
| Color feature extraction | extract features associated with color differences identify stains caused by lesions. | less sensitive toward changes in shapes than are other methods |
| Deep learning | high learning ability suitable for image recognition in various fields | large amount of calculation |
| AlexNet | AlexNet-1/2neurons | AlexNet-Adjust | |
|---|---|---|---|
| Layer | Patch Size | ||
| Input layer | 224 × 224 × 3 | 112 × 112 × 3 | 112 × 112 × 3 |
| Conv. 1 | 11 × 11 × 96 | 11 × 11 × 48 | 11 × 11 × 32 |
| Pool. 1 | 3 × 3 × 96 | 3 × 3 × 48 | 3 × 3 × 32 |
| Conv. 2 | 5 × 5 × 256 | 5 × 5 × 128 | 5 × 5 × 72 |
| Pool. 2 | 3 × 3 × 256 | 3 × 3 × 128 | 3 × 3 × 72 |
| Conv. 3 | 3 × 3 × 384 | 3 × 3 × 192 | 3 × 3 × 96 |
| Conv. 4 | 3 × 3 × 384 | 3 × 3 × 192 | 3 × 3 × 96 |
| Conv. 5 | 3 × 3 × 256 | 3 × 3 × 128 | 3 × 3 × 64 |
| Pool. 5 | 3 × 3 × 256 | 3 × 3 × 128 | 3 × 3 × 64 |
| Flatten 6 | |||
| Full connect7 | 4096 | 2048 | 1024 |
| Full connect8 | 4096 | 2048 | 1024 |
| Output layer | 1000 | 8 | 8 |
| Cut | Good-f 1 | Good-b 1 | Immature |
|---|---|---|---|
 367 original samples |  451 original samples |  760 original samples |  441 original samples |
| Partial sour | Slight insect damage-f 1 | Slight insect damage-b 1 | withered |
 250 original samples |  564 original samples |  370 original samples |  418 original samples |
| Layer | Patch Size | Strides | Padding | Remark |
|---|---|---|---|---|
| Input layer | 112 × 112 × 3 | |||
| Conv. 1 | 7 × 7 × 32 | 2 | Vaild | LRN, Leaky ReLU |
| Pool. 1 | 3 × 3 × 32 | 1 | Same | |
| Conv. 2 | 5 × 5 × 72 | 2 | Vaild | LRN, Leaky ReLU |
| Pool. 2 | 3 × 3 × 72 | 1 | Same | |
| Conv. 3 | 3 × 3 × 96 | 2 | Vaild | LRN, Leaky ReLU |
| Pool. 3 | 3 × 3 × 96 | 1 | Same | |
| Conv. 4 | 3 × 3 × 72 | 1 | Vaild | LRN, Leaky ReLU |
| Pool. 4 | 3 × 3 × 72 | 1 | Same | |
| Flatten 6 | 7200 | |||
| Full connect7 | 512 | Dropout | ||
| Full connect8 | 512 | Dropout | ||
| Output layer | 8 | Dropout |
| Alexnet-aj | New Network-dr | New Network-dr-pv | New Network-Final | |
|---|---|---|---|---|
| Acc-train | 95.7% | 98.0% | 98.6% | 98.6% |
| Acc-test | 90.2% | 94.4% | 94.8% | 95.1% |
| kappa | 0.891 | 0.928 | 0.937 | 0.935 |
| Alexnet-aj | New Network-dr | New Network-dr-pv | New Network-Final | |
|---|---|---|---|---|
| Params | 1.91 M 1 | 6.95 M 1 | 4.26 M 1 | 4.26 M 1 |
| FLOPs | 100.41 M 1mac | 185.13 M 1mac | 123.53 M 1mac | 123.53 M 1mac |
| Training time | 359 s | 519 s | 414 s | 433 s |
| T\P 1 | Cut | Good-f 2 | Good-b 2 | Immature | Sour | Insect-f 2 | Insect-b 2 | Withered | Acc |
|---|---|---|---|---|---|---|---|---|---|
| Cut | 114 | 0 | 0 | 0 | 4 | 7 | 2 | 9 | 86.1% |
| Good-f 2 | 0 | 182 | 3 | 0 | 0 | 0 | 0 | 0 | 95.1% |
| Good-b 2 | 0 | 7 | 280 | 0 | 0 | 0 | 0 | 0 | 98.3% |
| Immature | 0 | 0 | 0 | 165 | 0 | 0 | 0 | 0 | 98.8% |
| Sour | 0 | 0 | 0 | 0 | 113 | 0 | 1 | 0 | 93.0% |
| Insect-f 2 | 2 | 1 | 0 | 0 | 2 | 194 | 6 | 2 | 94.2% |
| Insect-b 2 | 0 | 0 | 0 | 5 | 10 | 0 | 147 | 2 | 90.3% |
| Withered | 11 | 1 | 4 | 14 | 16 | 1 | 24 | 110 | 69.4% |
| T\P 1 | Cut | Good-f 2 | Good-b 2 | Immature | Sour | Insect-f 2 | Insect-b 2 | Withered | Acc |
|---|---|---|---|---|---|---|---|---|---|
| Cut | 123 | 0 | 0 | 0 | 2 | 2 | 1 | 9 | 89.8% |
| Good-f 2 | 0 | 182 | 3 | 0 | 0 | 0 | 0 | 0 | 98.4% |
| Good-b 2 | 0 | 3 | 284 | 0 | 0 | 0 | 0 | 0 | 99.0% |
| Immature | 0 | 0 | 0 | 163 | 0 | 0 | 1 | 1 | 98.8% |
| Sour | 0 | 0 | 0 | 0 | 112 | 0 | 2 | 0 | 99.1% |
| Insect-f 2 | 4 | 0 | 0 | 0 | 0 | 194 | 5 | 5 | 93.7% |
| Insect-b 2 | 0 | 0 | 0 | 0 | 3 | 0 | 155 | 6 | 93.9% |
| Withered | 16 | 0 | 0 | 2 | 4 | 0 | 20 | 139 | 77.2% |
| T\P 1 | Cut | Good-f 2 | Good-b 2 | Immature | Sour | Insect-f 2 | Insect-b 2 | Withered | Acc |
|---|---|---|---|---|---|---|---|---|---|
| Cut | 127 | 0 | 0 | 0 | 0 | 3 | 1 | 7 | 94.2% |
| Good-f 2 | 0 | 181 | 4 | 0 | 0 | 0 | 0 | 0 | 97.8% |
| Good-b 2 | 0 | 4 | 283 | 0 | 0 | 0 | 0 | 0 | 98.6% |
| Immature | 0 | 0 | 0 | 163 | 0 | 0 | 1 | 3 | 97.6% |
| Sour | 3 | 0 | 0 | 0 | 107 | 0 | 3 | 0 | 93.9% |
| Insect-f 2 | 4 | 0 | 0 | 0 | 0 | 200 | 1 | 3 | 96.6% |
| Insect-b 2 | 0 | 0 | 0 | 1 | 2 | 1 | 152 | 9 | 92.7% |
| Withered | 15 | 0 | 0 | 3 | 2 | 2 | 8 | 150 | 83.9% |
| T\P 1 | Cut | Good-f 2 | Good-b 2 | Immature | Sour | Insect-f 2 | Insect-b 2 | Withered | Acc |
|---|---|---|---|---|---|---|---|---|---|
| Cut | 125 | 0 | 0 | 0 | 1 | 3 | 0 | 8 | 91.2% |
| Good-f 2 | 0 | 181 | 4 | 0 | 0 | 0 | 0 | 0 | 97.8% |
| Good-b 2 | 0 | 10 | 277 | 0 | 0 | 0 | 0 | 0 | 96.9% |
| Immature | 0 | 0 | 0 | 163 | 0 | 0 | 0 | 3 | 98.2% |
| Sour | 4 | 0 | 0 | 0 | 108 | 0 | 2 | 0 | 95.6% |
| Insect-f 2 | 3 | 0 | 0 | 0 | 0 | 202 | 0 | 2 | 97.6% |
| Insect-b 2 | 0 | 0 | 0 | 2 | 2 | 2 | 148 | 11 | 90.3% |
| Withered | 11 | 0 | 0 | 4 | 0 | 3 | 5 | 157 | 88.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, S.-J.; Huang, C.-Y. Deep Learning Model for the Inspection of Coffee Bean Defects. Appl. Sci. 2021, 11, 8226. https://doi.org/10.3390/app11178226
Chang S-J, Huang C-Y. Deep Learning Model for the Inspection of Coffee Bean Defects. Applied Sciences. 2021; 11(17):8226. https://doi.org/10.3390/app11178226
Chicago/Turabian StyleChang, Shyang-Jye, and Chien-Yu Huang. 2021. "Deep Learning Model for the Inspection of Coffee Bean Defects" Applied Sciences 11, no. 17: 8226. https://doi.org/10.3390/app11178226
APA StyleChang, S.-J., & Huang, C.-Y. (2021). Deep Learning Model for the Inspection of Coffee Bean Defects. Applied Sciences, 11(17), 8226. https://doi.org/10.3390/app11178226