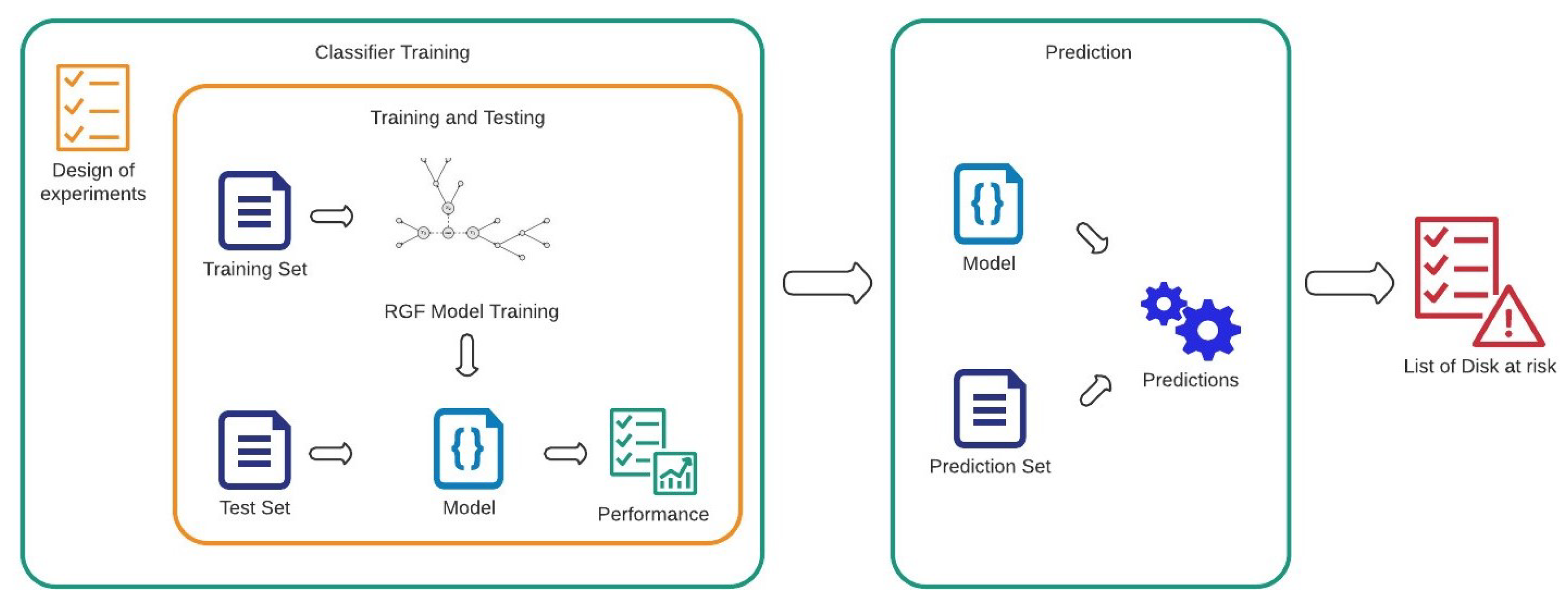
4.2.1. Training of Models
The considered dataset needs to be split into training, , and test, , sets. As there is a need to classify each hard disk according to its state of health, a binary classification distinguishing between “at-risk” and “not at risk” disks must be performed. The classification phase is performed by using the RGF model. The training algorithm requires a tuning of the hyperparameters.
The goal is to learn a single nonlinear function on some input vectors with labels Y, minimizing the argument of a loss function . The algorithms used for learning can be RGF with regularization on leaf-only models (referred to as “RGF” in the following), or the RGF with Minimum-Penalty Regularization (“RGF_Opt”) or RGF with min-penalty regularization with Sum-to-zero Sibling constraints (“RGF_Sib”).
The number of leaves is a data-dependent hyperparameter, and its tuning affects the training time. The number of leaves can be chosen in the range of (1000, 10,000). The degree of regularization can be adjusted choosing a value as small as needed . A lower value of reduces the importance of the regularization in the regularized loss functions. The hyperparameter mazimum depth is a parameter used only with the two Minimum-Penalty Regularization models and indirectly tunes the importance of nodes because a smaller value ensures a lesser penalty for deeper nodes. In the two min-penalty regularizers, the represents the distance from the root of the generic node , and the constant hyperparameter is elevated as . Thus, higher values of penalizes deeper nodes. The last hyperparameter of interest is the Test Interval, i.e., the number of leaves added per each iteration. Besides the ones just listed, there are others hyperparameters whose configurations, if not defined, do not prevent model training but can help improving its efficiency and effectiveness. Their contribution will not be discussed in this paper, and the amplitudes exploited during the performance assessment have been set to their default value.
The hyperparameter tuning, together with the choice of the number of observation days, create a number of possible configurations that can rapidly reach a few thousands. A drastic reduction of the experiments number without losing significance can be made by means of a Design Of Experiments (DOE) using the Taguchi Orthogonal Array Designs [
17]; in particular, each combination of factor levels exploited to carry out a specific experiment is referred to as plan configuration. Some of the considered parameters, such as the width of the observation window, lambda, the number of leaves, etc., can assume values within large intervals. The purpose of the design of experiments is to evaluate the effect of all parameters in some significant configurations for training purposes; this way, for each parameter, a suitable, limited number of values has been established according to both their typical interval of variation and authors’ knowledge and experience.
The choice of levels for each factor is limited to the number of configurations of the experiment plan used. The risk of overfitting is averted. Due to the limited number of possible combinations, it is necessary to execute the experiment plan within intervals that reasonably already give good performance. The optimal configuration is therefore identified between levels of factors that do not cause overfitting. It is also possible to make a comparison between the performances obtained in the optimal case and in all cases foreseen by the experiment plan. This further comparison allows the system to obtain the certainty of having achieved the best performance among all the tested combinations.
Usually, the goal is generally to minimize false negatives to avoid risk targets being incorrectly predicted, thus assuring a conservative behavior from an operating point of view. The accuracy index is often used in contexts of methodologies based on predictors to give a quantization of the goodness of the model. Accuracy is defined as
where True Positives and True Negatives are the number of disks well predicted as healthy or non-healthy, respectively. Vice-versa, the number or disk wrongly predicted are False Positives (in case of an healthy disk predicted as to be replaced) and False Negatives (for disks that need to be replaced and actually predicted as healthy). The accuracy is usually used to have a first feeling on the effectiveness of the predictor since it returns the fraction of correctly predicted test cases out of the totality of all test cases. Although this index shows correctly executed predictions, it does not measure the predictor’s sensitivity to the distinctions between positive and negative cases. The method proposed in this work uses
Recall,
False Positive Rate (FPR) and
Positive Likelihood Ratio (LR+) to better evaluate the predictor’s performance.
The Recall index, defined as
is often preferred in this context; the higher the recall value, the better the reduction of false negatives.
As regards data-centers storage systems, characterized by tens of thousands of hard disks, a single percentage point of false positives corresponds, instead, to several hundred hard disks wrongly classified as “to be replaced” even if they are not. This way, in the considered application field, minimizing the false positive occurrences turns out to be as fundamental as maximizing the recall. The index associated with the risk of false positives is the False Positive Rate defined as:
The Taguchi DOE approach can be exploited to assess the factors’ impact on one performance index; to this aim, the
Positive Likelihood Ratio (
), defined as
and capable of simultaneously taking into account Recall and FPR, has been exploited. Before carrying out the training stage of the RGF model, input data have to suitably shuffled in order to guarantee independence from the temporal distribution of the measures and prevent biases related to the dataset
. Both training and test experiments are required for each of the plan configurations; to this aim, the whole dataset
is split according to a ratio of 70–30%, for training and testing, respectively.
| Algorithm 1 Classifier Training. |
- 1:
procedureDataSetCollection(D) - 2:
for each disk do - 3:
Get SMART tuples daily of - 4:
end for - 5:
Return S - 6:
end procedure - 7:
procedurePre-processing(S) - 8:
for each SMART tuple do - 9:
if is corrupted OR missed OR out-of-range then - 10:
Remove from S - 11:
end if - 12:
Label() according to Definition 1 - 13:
if is replaced in then - 14:
Remove from S - 15:
end if - 16:
end for - 17:
Return S - 18:
end procedure - 19:
procedureDesign of Experiment(S) - 20:
T= TaguchiDesign(, replicates = 30) - 21:
for each design do - 22:
- 23:
- 24:
- 25:
- 26:
end for - 27:
Select configuration C using - 28:
Return C - 29:
end procedure - 30:
procedureThreshold assessment() - 31:
- 32:
- 33:
Get Definitive Model - 34:
Get Probabilities - 35:
- 36:
Select Threshold using - 37:
Return - 38:
end procedure
|
The Regularized Greedy Forest is trained using the the training data set and tested using the testing data set .
Authors suggest at least 30 runs for each plan configuration in order to simultaneously assure statistical significance and feasible execution times. For each plan configuration, the values of Accuracy, Recall and FPR, expressed in percentage terms, are calculated as the median of the Accuracy, Recall and FPR achieved in the various runs. The final index of LP+ is calculated as the ratio of the median Recall and FPR.
The RGF classifier returns a probability for each tuple of SMART measures of likelihood with respect to the two classes of healthy or broken. The last step for the user is the choice of a proper threshold beyond which discriminating whether the considered tuple identifies a Hard Disk that needs to be replaced or not. The choice of the optimal threshold turns out to be a trade-off between false and true positive rates. To drive the choice of the right threshold, the Receiver Operating Characteristic (ROC) curve has been exploited. The ROC curve, a graphic tool for the evaluation of FPR and TPR, helps the developer, in fact, to identify the best trade-off threshold, which the authors experienced close to the beginning of the curve knee.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}