
Autonomous Exploration of Mobile Robots via Deep Reinforcement Learning Based on Spatiotemporal Information on Graph

Abstract
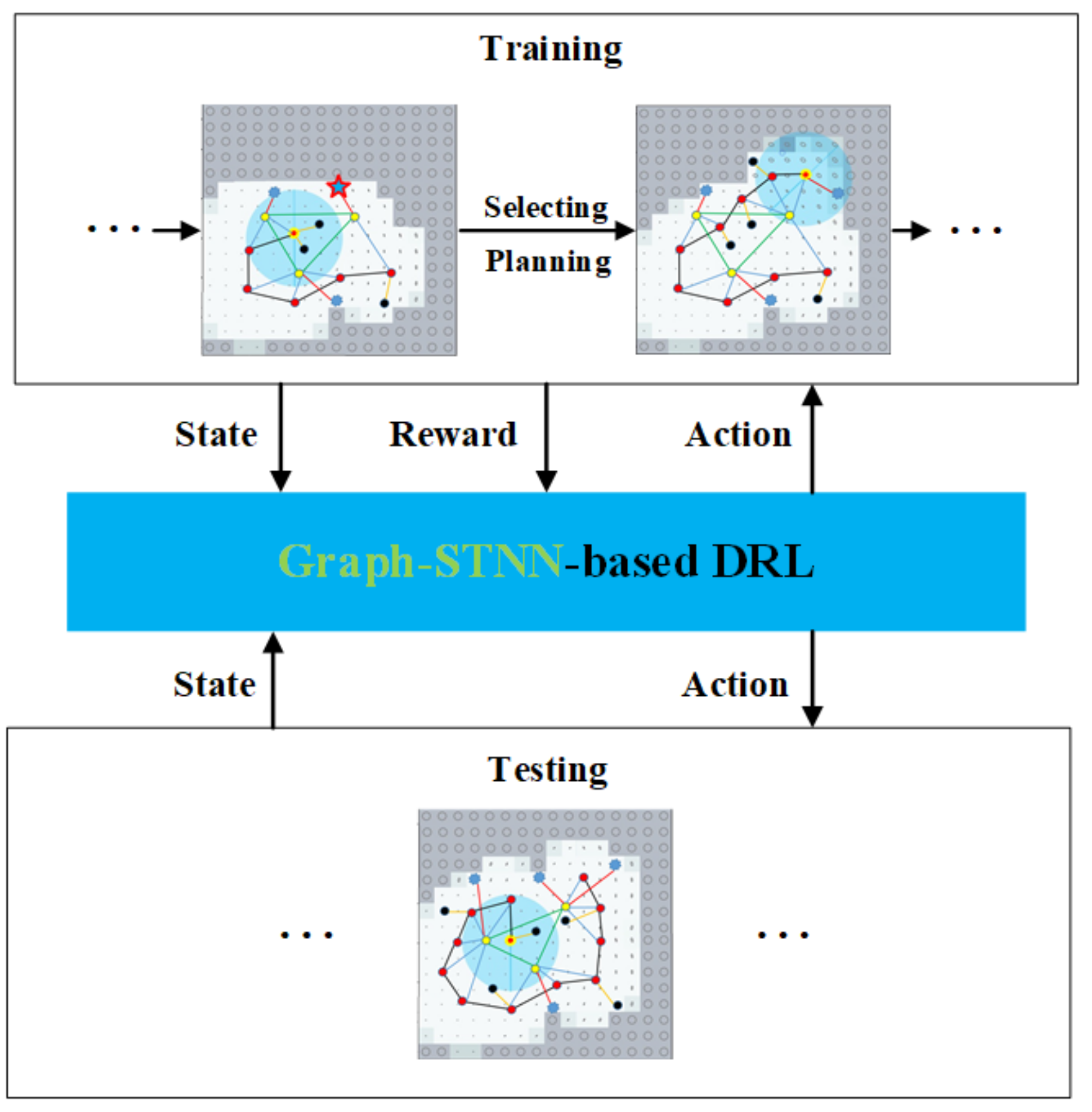
:1. Introduction
2. Related Work
3. Our Approach
3.1. Problem Formulation
3.2. Exploration Graph
3.3. Graph-STNN
3.3.1. Spatial Encoder
3.3.2. Temporal Encoder
3.3.3. State Encoder
3.4. Policy Training with DRL
4. Experimental Evaluation
4.1. Experimental Setup
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lluvia, I.; Lazkano, E.; Ansuategi, A. Active Mapping and Robot Exploration: A Survey. Sensors 2021, 21, 2445. [Google Scholar] [CrossRef] [PubMed]
- Juliá, M.; Gil, A.; Reinoso, Ó. A comparison of path planning strategies for autonomous exploration and mapping of unknown environments. Auton. Robot. 2012, 33, 427–444. [Google Scholar] [CrossRef]
- Stachniss, C. Robotic Mapping and Exploration; Springer: Berlin/Heidelberg, Germany, 2009; Volume 55. [Google Scholar]
- Chen, F.; Wang, J.; Shan, T.; Englot, B. Autonomous Exploration Under Uncertainty via Graph Convolutional Networks. In Proceedings of the International Symposium on Robotics Research, Hanoi, Vietnam, 6–10 October 2019. [Google Scholar]
- Tai, L.; Liu, M. Mobile robots exploration through cnn-based reinforcement learning. Robot. Biomim. 2016, 3, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, S.; Chen, F.; Englot, B. Toward autonomous mapping and exploration for mobile robots through deep supervised learning. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2379–2384. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Chen, F. Autonomous Exploration under Uncertainty via Deep Reinforcement Learning on Graphs. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 6140–6147. [Google Scholar]
- Li, H.; Zhang, Q.; Zhao, D. Deep reinforcement learning-based automatic exploration for navigation in unknown environment. IEEE Trans. Neural Netw. Learn. Syst. (TNNLS) 2019, 31, 2064–2076. [Google Scholar] [CrossRef] [PubMed]
- Niroui, F. Deep reinforcement learning robot for search and rescue applications: Exploration in unknown cluttered environments. IEEE Robot. Autom. Lett. (RA-L) 2019, 4, 610–617. [Google Scholar] [CrossRef]
- Yamauchi, B. A frontier-based approach for autonomous exploration. In Proceedings of the IEEE International Symposium on Computer Intelligence in Robotics and Automation (CIRA), Monterey, CA, USA, 10–11 July 1997; pp. 146–151. [Google Scholar]
- Makarenko, A.A. An experiment in integrated exploration. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Lausanne, Switzerland, 30 September–4 October 2002; Volume 1, pp. 534–539. [Google Scholar]
- Kaufman, E. Bayesian occupancy grid mapping via an exact inverse sensor model. In Proceedings of the IEEE American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 5709–5715. [Google Scholar]
- Kaufman, E.; Lee, T.; Ai, Z. Autonomous exploration by expected information gain from probabilistic occupancy grid mapping. In Proceedings of the IEEE International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR), San Francisco, CA, USA, 13–16 December 2016; pp. 246–251. [Google Scholar]
- Carrillo, H. Autonomous robotic exploration using occupancy grid maps and graph slam based on shannon and rényi entropy. In Proceedings of the IEEE International Conference on Robotics & Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 487–494. [Google Scholar]
- Bai, S. Information-theoretic exploration with Bayesian optimization. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 1816–1822. [Google Scholar]
- González-Banos, H.H.; Latombe, J.C. Navigation strategies for exploring indoor environments. Int. J. Robot. Res. (IJRR) 2002, 21, 829–848. [Google Scholar] [CrossRef]
- Wu, Z. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. (TNNLS) 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mnih, V. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Rossi, L.; Paolanti, M.; Pierdicca, R.; Frontoni, E. Human trajectory prediction and generation using LSTM models and GANs. Pattern Recognit. 2021, 120, 108136. [Google Scholar] [CrossRef]
- Rossi, L.; Ajmar, A.; Paolanti, M.; Pierdicca, R. Vehicle trajectory prediction and generation using LSTM models and GANs. PLoS ONE 2021, 16, e0253868. [Google Scholar]
- Ye, F.; Yang, J. A Deep Neural Network Model for Speaker Identification. Appl. Sci. 2021, 11, 3603. [Google Scholar] [CrossRef]
- Wang, J.; Englot, B. Autonomous Exploration with Expectation-Maximization. In Robotics Research; Springer: Cham, Switzerland, 2020; pp. 759–774. [Google Scholar]
- Kaess, M.; Dellaert, F. Covariance recovery from a square root information matrix for data association. J. Robot. Auton. Syst. (RAS) 2009, 57, 1198–1210. [Google Scholar] [CrossRef]
- Rumelhart, D.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the International Conference on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Wang, Z. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Cho, K.; van Merrienboe, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Fortunato, M.; Azar, M.G.; Piot, B.; Menick, J.; Hessel, M.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; et al. Noisy Networks For Exploration. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Dellaert, F. Factor Graphs and GTSAM: A Hands-on Introduction; Technical Report GT-RIM-CP&R-2012-002; Georgia Institute of Technology: Atlanta, GA, USA, 2012. [Google Scholar]
- Brownlee, J. Long Short-Term Memory Networks with Python: Develop Sequence Prediction Models with Deep Learning; Machine Learning Mastery: San Juan, PR, USA, 2017. [Google Scholar]
- Konolige, K.; Grisetti, G.; Kümmerle, R.; Burgard, W.; Limketkai, B.; Vincent, R. Efficient Sparse Pose Adjustment for 2D mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 22–29. [Google Scholar]
- Wen, J.; Zhang, X.; Bi, Q.; Pan, Z.; Feng, Y.; Yuan, J.; Fang, Y. MRPB 1.0: A Unified Benchmark for the Evaluation of Mobile Robot Local Planning Approaches. In Proceedings of the IEEE International Conference on Robotics & Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 8238–8244. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nodes | |
|---|---|
| 2 | frontier waypoint |
| 1 | landmark |
| 0 | robot’s current position |
| −1 | historical trajectory |
| −2 | obstacle |
| Method | e | |||
|---|---|---|---|---|
| 20 m × 20 m | 40 m × 40 m | 20 m × 20 m | 40 m × 40 m | |
| Graph-STNN | 0.8761 | 1.4607 | 1.7051 | 1.4032 |
| GCN-no_obs | 1.2328 | 2.0179 | 1.4630 | 0.8719 |
| GCN-obs | 0.9665 | 1.6894 | 1.5573 | 1.0270 |
| Entropy | 1.5038 | 1.7454 | 1.0219 | 1.0571 |
| Uncertainty | 1.2304 | 1.7406 | 1.1676 | 1.0651 |
| Random | 1.9614 | 3.1803 | 0.7536 | 0.7779 |
| Method | e | ||||||
|---|---|---|---|---|---|---|---|
| 20 m × 20 m | 30 m × 30 m | 40 m × 40 m | 20 m × 20 m | 30 m × 30 m | 40 m × 40 m | ||
| Graph-STNN | 1.0160 | 1.3088 | 1.7588 | 1.7051 | 1.5085 | 1.4032 | |
| no state | 1.9370 | 2.3748 | 2.7195 | 0.9039 | 0.9304 | 0.9153 | |
| no temporal | 1.4761 | 1.8144 | 2.2950 | 1.5585 | 1.4389 | 1.3101 | |
| no spatial | 1.6475 | 1.8303 | 2.5787 | 1.0854 | 1.4828 | 1.1593 | |
| no temporal and state | 1.5732 | 2.2140 | 2.5679 | 1.2563 | 0.9476 | 0.9950 | |
| no spatial and state | 1.9935 | 2.5510 | 2.7051 | 0.8231 | 0.7813 | 0.8142 | |
| no spatial and temporal | 1.7770 | 2.5523 | 2.3844 | 0.9823 | 1.3127 | 1.0719 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Shi, C.; Zhu, P.; Zeng, Z.; Zhang, H. Autonomous Exploration of Mobile Robots via Deep Reinforcement Learning Based on Spatiotemporal Information on Graph. Appl. Sci. 2021, 11, 8299. https://doi.org/10.3390/app11188299
Zhang Z, Shi C, Zhu P, Zeng Z, Zhang H. Autonomous Exploration of Mobile Robots via Deep Reinforcement Learning Based on Spatiotemporal Information on Graph. Applied Sciences. 2021; 11(18):8299. https://doi.org/10.3390/app11188299
Chicago/Turabian StyleZhang, Zhiwen, Chenghao Shi, Pengming Zhu, Zhiwen Zeng, and Hui Zhang. 2021. "Autonomous Exploration of Mobile Robots via Deep Reinforcement Learning Based on Spatiotemporal Information on Graph" Applied Sciences 11, no. 18: 8299. https://doi.org/10.3390/app11188299
APA StyleZhang, Z., Shi, C., Zhu, P., Zeng, Z., & Zhang, H. (2021). Autonomous Exploration of Mobile Robots via Deep Reinforcement Learning Based on Spatiotemporal Information on Graph. Applied Sciences, 11(18), 8299. https://doi.org/10.3390/app11188299