
Capturing Discriminative Information Using a Deep Architecture in Acoustic Scene Classification



Abstract
:1. Introduction
- We use an element-wise comparison between different filters of a convolution layer’s output as the non-linear activation function, to emphasize the specific details of features to improve the performance on frequently misclassified pairs of classes that share common acoustic properties.
- We investigated two data augmentation methods, mix-up and specAugment, and two deep architecture modules, convolutional block attention module (CBAM) and squeeze and excitation (SE) networks, to reduce overfitting and sustain the system’s discriminative power for the most confused classes.
2. Characteristics of ASC
3. Proposed Framework
3.1. Adopting the LCNN
3.2. Regularization and Deep Architecture Modules
4. Experiments
4.1. Dataset
4.2. Experimental Configurations
5. Result Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Plumbley, M.D.; Kroos, C.; Bello, J.P.; Richard, G.; Ellis, D.P.; Mesaros, A. Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018; Tampere University of Technology, Laboratory of Signal Processing: Tampere, Finland, 2018. [Google Scholar]
- Mandel, M.; Salamon, J.; Ellis, D.P.W. Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019; New York University: New York, NY, USA, 2019. [Google Scholar]
- McDonnell, M.D.; Gao, W. Acoustic scene classification using deep residual networks with late fusion of separated high and low frequency paths. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 141–145. [Google Scholar]
- Pham, L.; Phan, H.; Nguyen, T.; Palaniappan, R.; Mertins, A.; McLoughlin, I. Robust acoustic scene classification using a multi-spectrogram encoder-decoder framework. Digit. Signal Process. 2021, 110, 102943. [Google Scholar] [CrossRef]
- Jung, J.W.; Heo, H.S.; Shim, H.J.; Yu, H.J. Knowledge Distillation in Acoustic Scene Classification. IEEE Access 2020, 8, 166870–166879. [Google Scholar] [CrossRef]
- Jung, J.W.; Shim, H.J.; Kim, J.H.; Yu, H.J. DCASENet: An integrated pretrained deep neural network for detecting and classifying acoustic scenes and events. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 621–625. [Google Scholar]
- Liu, Y.; Zhou, X.; Long, Y. Acoustic Scene Classification with Various Deep Classifiers. In Proceedings of the DCASE2020 Challenge, Virtually, 2–4 November 2020. Technical Report. [Google Scholar]
- Gharib, S.; Drossos, K.; Cakir, E.; Serdyuk, D.; Virtanen, T. Unsupervised adversarial domain adaptation for acoustic scene classification. arXiv 2018, arXiv:1808.05777. [Google Scholar]
- Primus, P.; Eitelsebner, D. Acoustic Scene Classification with Mismatched Recording Devices. In Proceedings of the DCASE2019 Challenge, New York, NY, USA, 25–26 October 2019. Technical Report. [Google Scholar]
- Kosmider, M. Calibrating neural networks for secondary recording devices. In Proceedings of the Detection and Classification of Acoustic Scenes and Events Workshop (DCASE), New York, NY, USA, 25–26 October 2019; pp. 25–26. [Google Scholar]
- Heo, H.S.; Jung, J.W.; Shim, H.J.; Yu, H.J. Acoustic Scene Classification Using Teacher-Student Learning with Soft-Labels. arXiv 2019, arXiv:1904.10135. [Google Scholar]
- Jung, J.W.; Heo, H.; Shim, H.J.; Yu, H.J. Distilling the Knowledge of Specialist Deep Neural Networks in Acoustic Scene Classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019; pp. 114–118. [Google Scholar]
- Wu, X.; He, R.; Sun, Z. A Lightened CNN for Deep Face Representation. arXiv 2015, arXiv:1511.02683. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wu, X.; He, R.; Sun, Z.; Tan, T. A light cnn for deep face representation with noisy labels. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2884–2896. [Google Scholar] [CrossRef] [Green Version]
- Lavrentyeva, G.; Novoselov, S.; Tseren, A.; Volkova, M.; Gorlanov, A.; Kozlov, A. STC antispoofing systems for the ASVSpoof2019 challenge. arXiv 2019, arXiv:1904.05576. [Google Scholar]
- Lai, C.I.; Chen, N.; Villalba, J.; Dehak, N. ASSERT: Anti-Spoofing with squeeze-excitation and residual networks. arXiv 2019, arXiv:1904.01120. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. arXiv 2013, arXiv:1302.4389. [Google Scholar]
- Mun, S.; Park, S.; Han, D.K.; Ko, H. Generative adversarial network based acoustic scene training set augmentation and selection using SVM hyper-plane. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017; pp. 93–97. [Google Scholar]
- Heittola, T.; Mesaros, A.; Virtanen, T. Acoustic scene classification in DCASE 2020 Challenge: Generalization across devices and low complexity solutions. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), Virtually, 2–4 November 2020. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Xie, W.; Zisserman, A. Voxceleb: Large-scale speaker verification in the wild. Comput. Speech Lang. 2020, 60, 101027. [Google Scholar] [CrossRef]
- Jung, J.W.; Heo, H.S.; Shim, H.J.; Yu, H.J. DNN based multi-level feature ensemble for acoustic scene classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018; pp. 113–117. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Shim, H.J.; Kim, J.H.; Jung, J.W.; Yu, H.J. Audio Tagging and Deep Architectures for Acoustic Scene Classification: Uos Submission for the DCASE 2020 Challenge. In Proceedings of the DCASE2020 Challenge, Virtually, 2–4 November 2020. Technical Report. [Google Scholar]
- Cramer, J.; Wu, H.H.; Salamon, J.; Bello, J.P. Look, Listen and Learn More: Design Choices for Deep Audio Embeddings. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3852–3856. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. icml 2013, 30, 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, D.; Wang, H.; Zou, Y. Unsupervised Multi-Target Domain Adaptation for Acoustic Scene Classification. arXiv 2021, arXiv:2105.10340. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Type | Kernel/Stride | Output |
|---|---|---|
| Conv_1 | 7 × 3/1 × 1 | l × 124 × 64 |
| MFM_1 | - | l × 124 × 32 |
| MaxPool_1 | 2 × 2/2 × 2 | (l/2) × 62 × 32 |
| Conv_2a | 1 × 1/1 × 1 | (l/2) × 62 × 64 |
| MFM_2a | - | (l/2) × 62 × 32 |
| BatchNorm_2a | - | (l/2) × 62 × 32 |
| Conv_2 | 3 × 3/1 × 1 | (l/2) × 62 × 96 |
| MFM_2 | - | (l/2) × 62 × 48 |
| CBAM_2 | - | (l/2) × 62 × 48 |
| MaxPool_2 | 2 × 2/2 × 2 | (l/4) × 31 × 48 |
| BatchNorm_2 | - | (l/4) × 31 × 48 |
| Conv_3a | 1 × 1/1 × 1 | (l/4) × 31 × 96 |
| MFM_3a | - | (l/4) × 31 × 48 |
| BatchNorm_3a | - | (l/4) × 31 × 48 |
| Conv_3 | 3 × 3/1 × 1 | (l/4) × 31 × 128 |
| MFM_3 | - | (l/4) × 31 × 64 |
| CBAM_3 | - | (l/4) × 31 × 64 |
| MaxPool_3 | 2 × 2/2 × 2 | (l/8) × 16 × 64 |
| Conv_4a | 1 × 1/1 × 1 | (l/8) × 16 × 128 |
| MFM_4a | - | (l/8) × 16 × 64 |
| BatchNorm_3a | - | (l/8) × 16 × 64 |
| Conv_4 | 3 × 3/1 × 1 | (l/8) × 16 × 64 |
| MFM_4 | - | (l/8) × 16 × 32 |
| CBAM_4 | - | (l/8) × 16 × 32 |
| BatchNorm_4 | - | (l/8) × 16 × 32 |
| Conv_5a | 1 × 1/1 × 1 | (l/8) × 16 × 64 |
| MFM_5a | - | (l/8) × 16 × 32 |
| BatchNorm_5a | - | (l/8) × 16 × 32 |
| Conv_5 | 3 × 3/1 × 1 | (l/8) × 16 × 64 |
| MFM_5 | - | (l/8) × 16 × 32 |
| CBAM_5 | - | (l/8) × 16 × 32 |
| MaxPool_5 | 2 × 2/2 × 2 | (l/16) × 8 × 32 |
| FC_1 | - | 160 |
| MFM_FC1 | - | 80 |
| FC_2 | - | 10 |
| System | Acc (%) |
|---|---|
| DCASE2019 baseline [2] | 46.5 |
| DCASE2020 baseline [24] | 51.4 |
| Ours-baseline | 65.3 |
| System | Config | Acc (%) |
|---|---|---|
| ResNet | - | 65.1 |
| ResNet(baseline) | mix-up | 65.3 |
| ResNet | SpecAug | 66.7 |
| ResNet | mix-up+SpecAug | 67.3 |
| LCNN | - | 67.1 |
| LCNN | mix-up | 68.4 |
| LCNN | SpecAug | 69.2 |
| LCNN | mix-up+SpecAug | 69.4 |
| LCNN | SE | 68.0 |
| LCNN | CBAM | 68.3 |
| LCNN | SE+CBAM | 68.2 |
| LCNN | mix-up+SpecAug+SE | 69.8 |
| LCNN (proposed) | mix-up+SpecAug+CBAM | 70.4 |
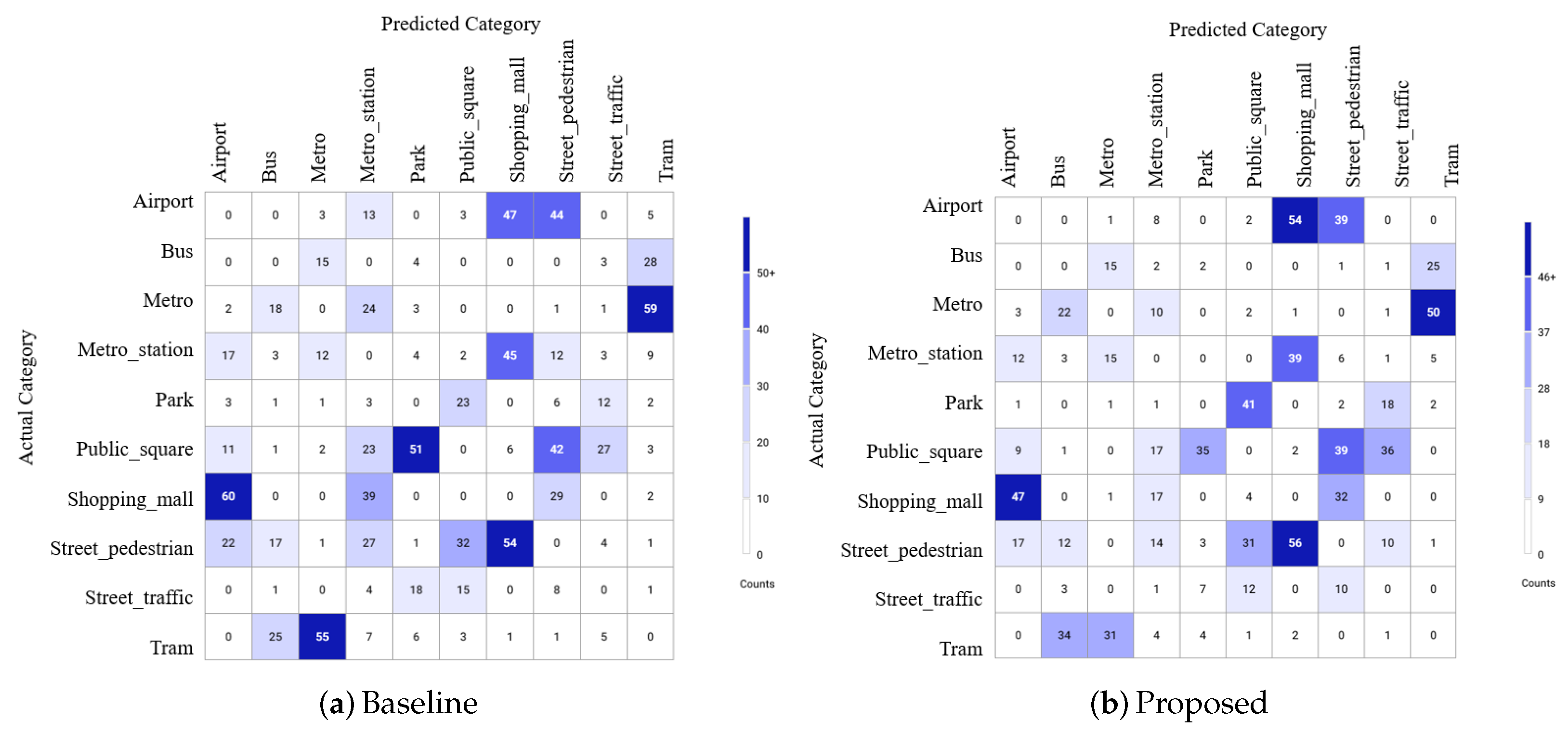
| Class | Baseline | Proposed | Reduction |
|---|---|---|---|
| Metro-Tram | 114 | 81 | 33 |
| Shopping-Airport | 107 | 101 | 6 |
| Shopping-Metro_st | 84 | 56 | 28 |
| Shopping-Street_ped | 83 | 88 | −5 |
| Public_square-Street_ped | 74 | 70 | 4 |
| Total | 462 | 396 | 66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shim, H.-j.; Jung, J.-w.; Kim, J.-h.; Yu, H.-j. Capturing Discriminative Information Using a Deep Architecture in Acoustic Scene Classification. Appl. Sci. 2021, 11, 8361. https://doi.org/10.3390/app11188361
Shim H-j, Jung J-w, Kim J-h, Yu H-j. Capturing Discriminative Information Using a Deep Architecture in Acoustic Scene Classification. Applied Sciences. 2021; 11(18):8361. https://doi.org/10.3390/app11188361
Chicago/Turabian StyleShim, Hye-jin, Jee-weon Jung, Ju-ho Kim, and Ha-jin Yu. 2021. "Capturing Discriminative Information Using a Deep Architecture in Acoustic Scene Classification" Applied Sciences 11, no. 18: 8361. https://doi.org/10.3390/app11188361
APA StyleShim, H.-j., Jung, J.-w., Kim, J.-h., & Yu, H.-j. (2021). Capturing Discriminative Information Using a Deep Architecture in Acoustic Scene Classification. Applied Sciences, 11(18), 8361. https://doi.org/10.3390/app11188361