Recognizing the activity a human is doing at any given moment is a technique that has a wide range of areas of application. From health and care applications [
1,
2,
3] to automation and context-awareness [
4,
5,
6], sports [
7,
8], social media [
9] and even security surveillance [
10]. Dependent on the use case, the applicability of a certain approach in regards to sensors, attributes or models can vary.
2.1. Machine Learning
Machine learning has long become one of the predominant tools for HAR. Already in 2004, before the mass adoption of smartphones and wearables which provide unobtrusive access to typically used sensors like accelerometers or gyroscopes, Bao and Intille [
11] used a setup of biaxial accelerometers attached to each of the limbs and the hip to gather and annotate sensor data. Using simple machine learning models like C4.5 decision trees, Naive Bayes and K-Nearest Neighbours (KNN), they achieved activity recognition accuracies of around 84% for the C4.5 and the KNN models. Most probably helped by their obtrusive setup with multiple sensors in different positions capturing motion in several important areas at once [
11].
He and Jin [
12] use a triaxial accelerometer placed in the typical place for a smartphone, the trouser pocket of the test subjects, to record their data set. Using the DCT, they represent the acceleration signals as a set of the
N most important underlying cosine signals. Using DCT instead of DFT, they do not have to deal with the underlying complex components but instead only get the real-valued cosine components which still provides them with a very good representation of the data and a reduction in complexity, as their best results come from using only the first 48 low-frequency components instead of 512 sensor readings per axis. As a next step, they reduce the feature dimension even further by using PCA. When using 20 principal components they lose no recognition performance even though this is a big reduction from 144 features (48 times 3 axes). Using these feature extraction methods and using a SVM as a classifier, He and Jin report a recognition accuracy of 97.51% for their four activities, running, standing still, walking and jumping [
12].
Krishnan and Panchanathan [
13] also use a SVM as a classifier in their approach. They compare it to a boosting based classifier with AdaBoost and to a regularized logistic regression classifier. The used data set was recorded by Bao and Intille [
11] and contains seven activities (walking, sitting, standing, running, bicycling, lying down and climbing stairs). From this data, they extract several statistical and spectral features and combine them with statistical features from the first derivative (the rate of change) of the acceleration, without going into more detail on the exact features, unfortunately. They achieve their best results of 92.81% accuracy for subject independent training using the AdaBoost classifier. The AdaBoost classifier works by using a base classifier, typically a weak learner like a simple decision tree, to train lots of them one after the other on the same dataset whilst modifying weights in between to focus on misclassified samples, that normally might be harder to classify. They also try to use temporal relations of sequences of activities (e.g., changing from walking to running) to increase their recognition performance. Including three of the previous frames to influence the recognition of the current frame results in a 2.5–3% increase in performance [
13].
Bayat et al. [
14] in addition to evaluating multiple classifiers available in the Weka toolkit with Multilayer Perceptron, SVM, Random Forest, LMT, Simple Logistic and Logit Boost classifiers, also propose to split acceleration signals of smartphones into gravitational and body acceleration signals. They do so by using a digital low-pass filter, as the high-frequency components of the acceleration signals represent the body movements and the low-frequency components represent the gravitational part. This results in multiple, more specialized, acceleration signals from which statistical features can be extracted. To calculate those descriptive features, they use consecutive windows with a 50 percent overlap on the time-series signals. For each window they extract features like the mean, the number of periodic peaks, the time between each of the periodic peaks, the root mean square (RMS), the standard deviation, the difference between the minimum and maximum values and the correlation between different axes. As the best result for accelerometer data of a smartphone placed in the pocket, they report 89.72%, achieved by a Multilayer Perceptron. They also try to combine multiple classifiers, which boosts their reported performance up to 91.15% accuracy [
14].
As those summaries above show, besides evaluating and choosing a classifier, quite a lot of focus goes towards engineering features that represent the data in the best way possible and that can be modelled well by the classifiers.
2.2. Deep Learning
Compared to typical machine learning methods, deep learning methods can train more complex models to model more complex data. With ML models, the practitioner needs to help it understand the data by extracting more representable features. Deep models on the other hand can have so many trainable parameters through their different layers and various amounts of units to be able to understand raw data. The more trainable parameters a deep model has, the more complex data it can represent. The tradeoff between overfitting and underfitting data with a model is present for both approaches, but for deep models, the focus can shift from applying domain knowledge and extracting the most useful features to balancing that tradeoff by using different architectures, learning parameters and regularization methods. Given enough data, deep models outperform typical models like support vector machines in many problem domains. This section will highlight approaches for the domain of HAR using various architectures for deep models.
As mentioned in the introduction, finding the best performing architecture and hyperparameters is key to modeling complex data and still achieving good recognition performances. Hammerla et al. [
15] focus on this exact problem by evaluating several architectures with ranges of hyperparameters regarding learning, regularization and architectural constraints. Their chosen architectures consist of a deep feed forward neural net (DNN), a CNN and three different RNNs. For the RNNs, they use Long Short Term Memory (LSTM) setups denoted LSTM-F, LSTM-S and b-LSTM-S. The LSTM-F and LSTM-S are deep feed forward LSTMs with recurrent cells only connected forwards in time whilst the b-LSTM-S is connected forwards and backwards using two parallel recurrent layers that are followed by a layer to combine them. The second distinguishing feature of those LSTMs is the way the input is fed into them. With the LSTM-F using predefined timespans of sensor readings and the LSTM-S and the b-LSTM-S only using one single sensor reading at a time [
15]. Hammerla et al. [
15] use fANOVA analysis to estimate the impact each of architectural, learning, regularization parameters and beneficial interactions between those three on the performance of the model. The hyperparameters for each trained model were chosen at random. On average, architectural parameters and learning parameters are equally important whilst the regularization, to reduce overfitting, is less important. But a very significant portion of the variance comes from beneficial interactions of certain parameters in combination with each other, which indicates that focusing on one single type is not as important as finding the best combination of different kinds of parameters [
15].
In contrast to the work by Hammerla et al. [
15], most of the research focuses on one single deep learning approach and one or more datasets to evaluate its performance. Ronao and Cho [
16] for instance use a CNN on the dataset also used in our work. They propose CNNs as a good solution for HAR due to their ability to exploit local temporal relations within time-series signals and cancel out smaller translations in the sensor readings. They report a peak performance of 94.79% accuracy for a model consisting of three convolutional and pooling layers followed by a fully connected layer and a softmax layer. They also report their evaluation results of the performance increase received by changing the number of convolutional layers, the kernel size of the convolutional layers and the pooling size of the pooling layers. While the pooling size had no effect on performance, the kernel size shows major performance increases up to a kernel size of 9. For the input of the complex raw sensor data, the amount of convolutional layers is quite important. Going from one to two convolutional layers, the performance increases drastically, with a small improvement available when adding a third layer. The fourth layer on the other hand already introduces too much complexity and probably overfitting which results in a slight decrease in performance [
16].
Jiang and Yin [
17] also use a CNN, as it seems to be the most used deep architecture. Compared to other works using CNNs, they use a novel approach regarding their use of input data. They use all three axes of the gyroscope signal, all three axes of the total acceleration signal (body motion and gravity) and all three axes of the linear acceleration signal (only body motion) to append them as rows of an image. This allows the two dimensional CNN to also learn from relations between those signals [
17].
Their algorithm to calculate this image includes all of these signals multiple times per image in differently ordered sequences to make sure the relations of one signal with multiple others can be captured. The magnitude of the Discrete Fourier Transform (DFT) is then used to get the activity image. These activity images (
in this case) are fed into two different two-dimensional convolutional layers with subsampling layers in between followed by a fully connected layer and a softmax layer to arrive at the activity predictions. Similar to the findings of Ronao and Cho [
16], they achieve the best results using two convolutional layers, compared to their other evaluated architectures with only one or three or more convolutional layers. For their best performing model, they report an accuracy of 95.18% for the UCI HAR Smartphone dataset [
17].
In their work, Guan and Plötz [
18] iterate that most of the activity recognition setups treat individual frames of sensor data statistically independent but this actually gets rid of one important component of sensor readings in an activity recognition context, which is the temporal relation of one of these frames with for example its predecessors. This is why they view RNN approaches as a better alternative for the mostly used CNNs. Most of the RNN approaches focus on models with Long Short Term Memory (LSTM) layers, while Guan and Plötz focus on an ensemble of such models in order to better deal with their identified issues of current HAR solutions. The first of these identified issues is the data used for HAR, which is mostly recorded in mobile or wearable context, as this data tends to be very noisy with high variations even for one and the same activity. Besides data quality, the quantity of annotated data is an issue, as the recording of sensor data on mobile devices is trivial, but the experiments to record and annotate very big data sets, fitting for deep learning approaches, are challenging to do with good enough class balancing. This can also be seen in available public datasets for HAR that mostly suffer from bad class distribution. Additionally, most approaches are based on sliding window and frame-based predictions that skip the challenge of finding and locating certain relevant sequences of sensor readings in a sequential stream. Guan and Plötz want to address these issues by employing their ensemble-based approach. For each training epoch, they train multiple models on randomly sampled sequences of random length of the training data. The best models of these are determined by the validation data and the predictions of those best models are then fused to a single prediction for a specific sample from the test data at a specific point in time. This is essentially bagging, which is normally done with very simple classifiers like trees, with highly complex models. In their results, they observe that this ensemble method mostly has a positive impact on very challenging and similar classes and therefore could indicate better robustness against the previously mentioned issues with real-world data [
18].
Additionally to the above mentioned DNNs, RNNs and CNNs, Stacked Autoencoders and Deep Belief Networks (DBNs) are also used for HAR. Almasklukh et al. [
19] for example use a Stacked Autoencoder to train their model in two stages with the first stage being about learning to reconstruct the data in an unsupervised manner before refining the model by learning on the labelled data in a supervised manner. Autoencoders consist of a decoder and an encoder with the encoder producing the code and the decoder reconstructing the input from this code. Autoencoders are typically restricted in the way they can represent the data to not be able to do it perfectly and therefore force it to find good representations, that for example reduce the dimensionality of the input data, or extract more representative features. Different types of autoencoders are used for different applications. One of those types is the Sparse Autoencoder that serves the purpose of adding sparsity (many inactive hidden units) to the input data by applying a regularization function. This forces the units that are left active to learn very latent and powerful features in the input data to then have a representation that generalizes better on unseen data. For the stacked autoencoder employed by Almasklukh et al., they use two of those sparse autoencoders to be able to find good features in an unsupervised way in phase one and then align this with the labeled data to predict activities accurately in phase two. They report an accuracy of 97.5% on the UCI HAR Smartphone data set [
19].
DBNs as used by Zhang et al. [
20] consist of multiple stacked Restricted Boltzmann Machines (RBMs). An RBM is a variant of a Boltzmann machine with the constraint that connections between units of different groups (hidden and visible units) are allowed, but no connections between units of the same group. These RBMs are then stacked with each of the hidden layers being the visible layer of the following. The hidden units of the RBMs act as feature detectors with one RBM being trained after the other in an unsupervised manner. This training phase learns a generative model that is not yet able to classify the activities. To enable the model to do that, back-propagation is used to adapt the trained units to the labeled data [
20].
As shown by these highlighted papers, many different deep learning approaches are possible. The mostly used architectures are CNNs [
15,
16,
17,
21,
22,
23,
24,
25] followed by RNNs [
18,
26,
27,
28] and the occasional outlier with DNNs [
15], Autoencoders [
19], Deep Belief Networks [
20] or even Generative Adversarial Networks (GANs) for specific use cases [
29]. There seems to be not one single approach working especially well, as all of them achieve good results when tuned to a certain extent.








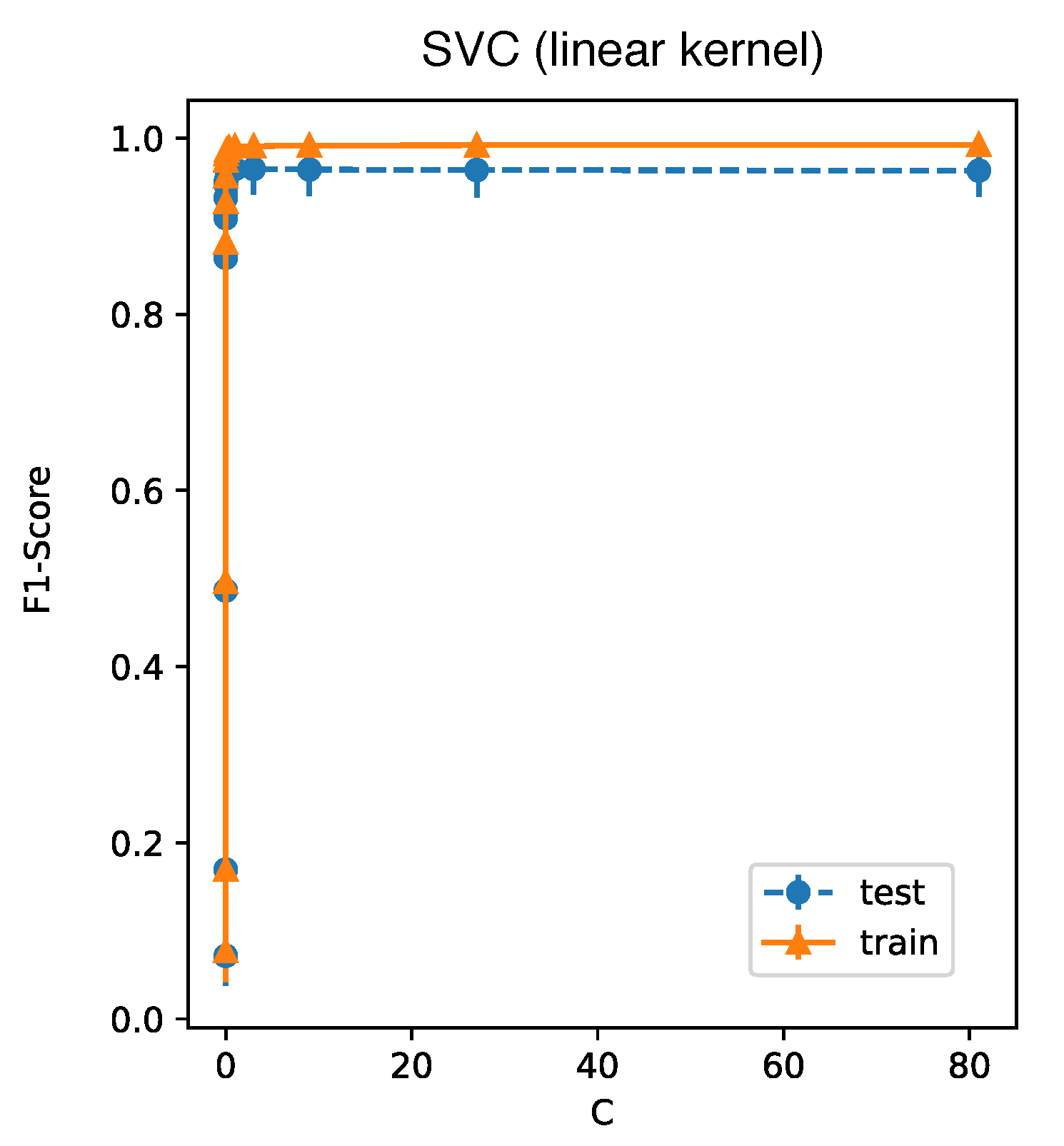

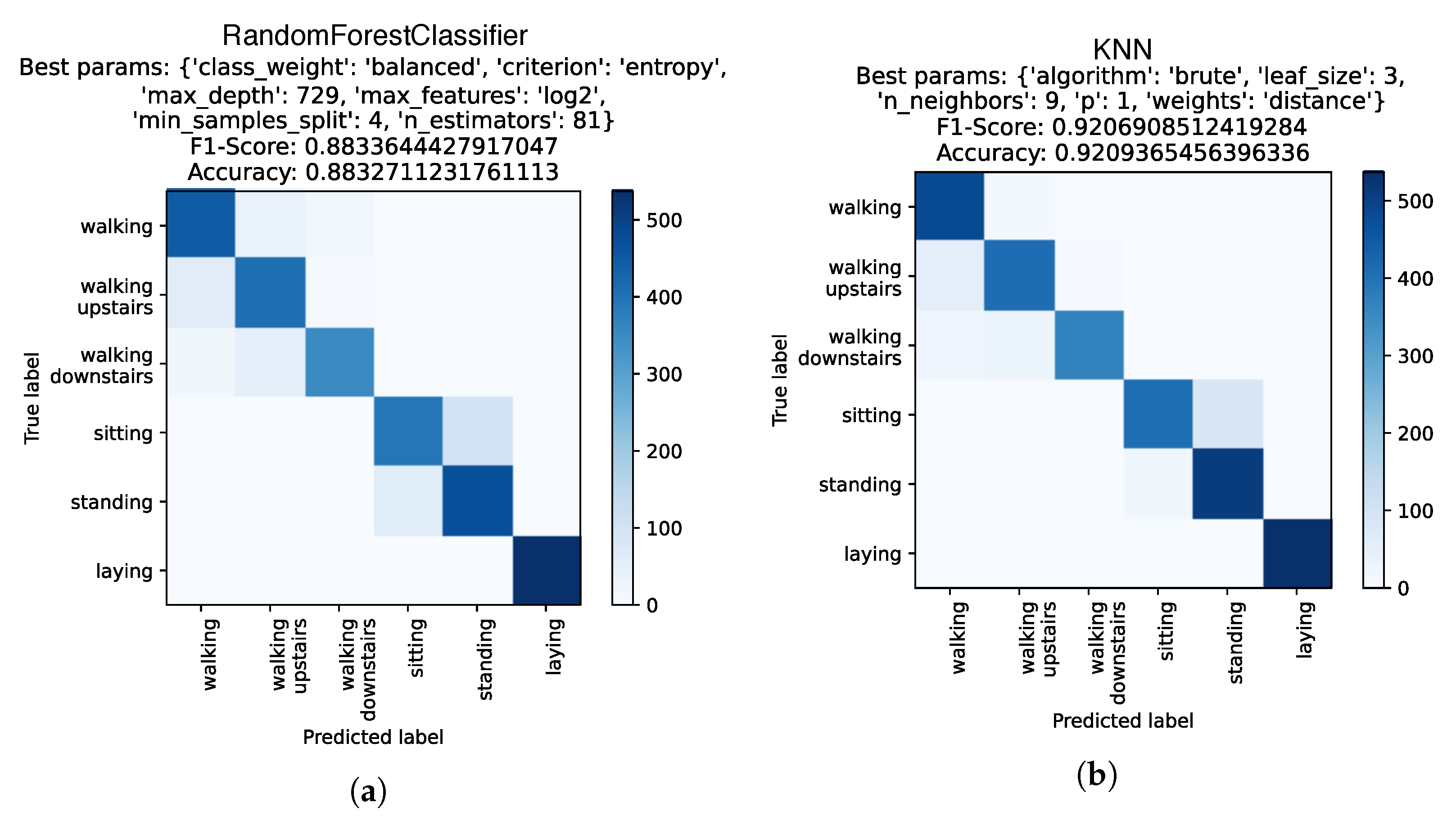







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}