
Ensuring Data Integrity in Databases with the Universal Basis of Relations

 ,
,  ,
,
Abstract
1. Introduction
2. Related Works
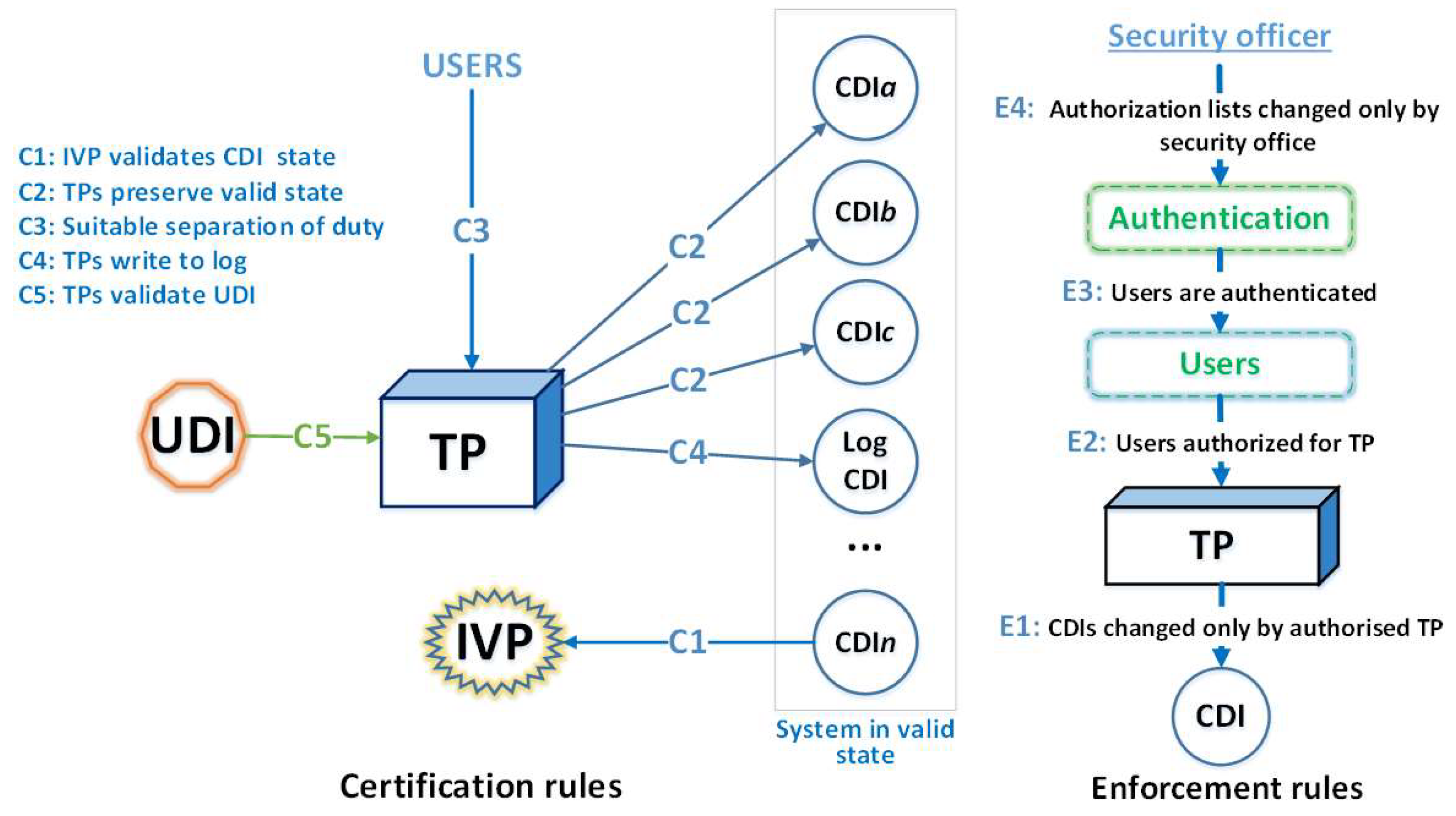
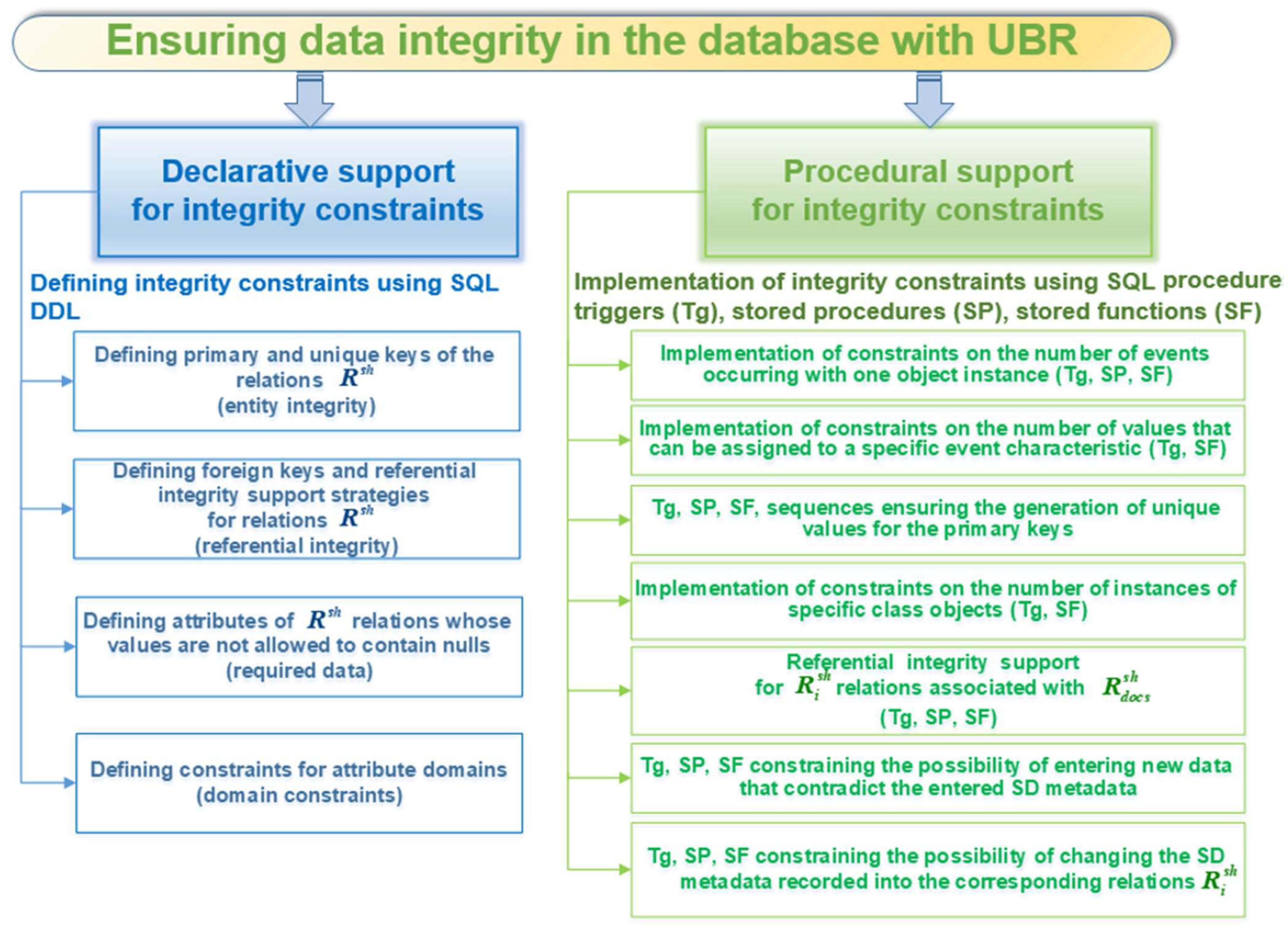
3. Applying the Clark–Wilson Model Recommendations to Ensure the Integrity of Databases with the Universal Basis of Relations
- –
- User relation :
- –
- The relation of the access privilege distribution to the data of other users :
- –
- A set of declarative commands (RLS policies) that determine how and when to apply user access restrictions (in accordance with their functional duties, according to rule C3) to the tuples of the main relations of the DB schema with the UBR;
- –
- A set of stored functions that are called when the conditions specified in the security policy (RLS policy) are performed;
- –
- Predicates formed by functions that the DBMS automatically appends to the end of the WHERE clause of user-executed SQL statements.
- –
- The constraints on the ability to enter new data that contradict the entered SD metadata (for relations associated with the SD data);
- –
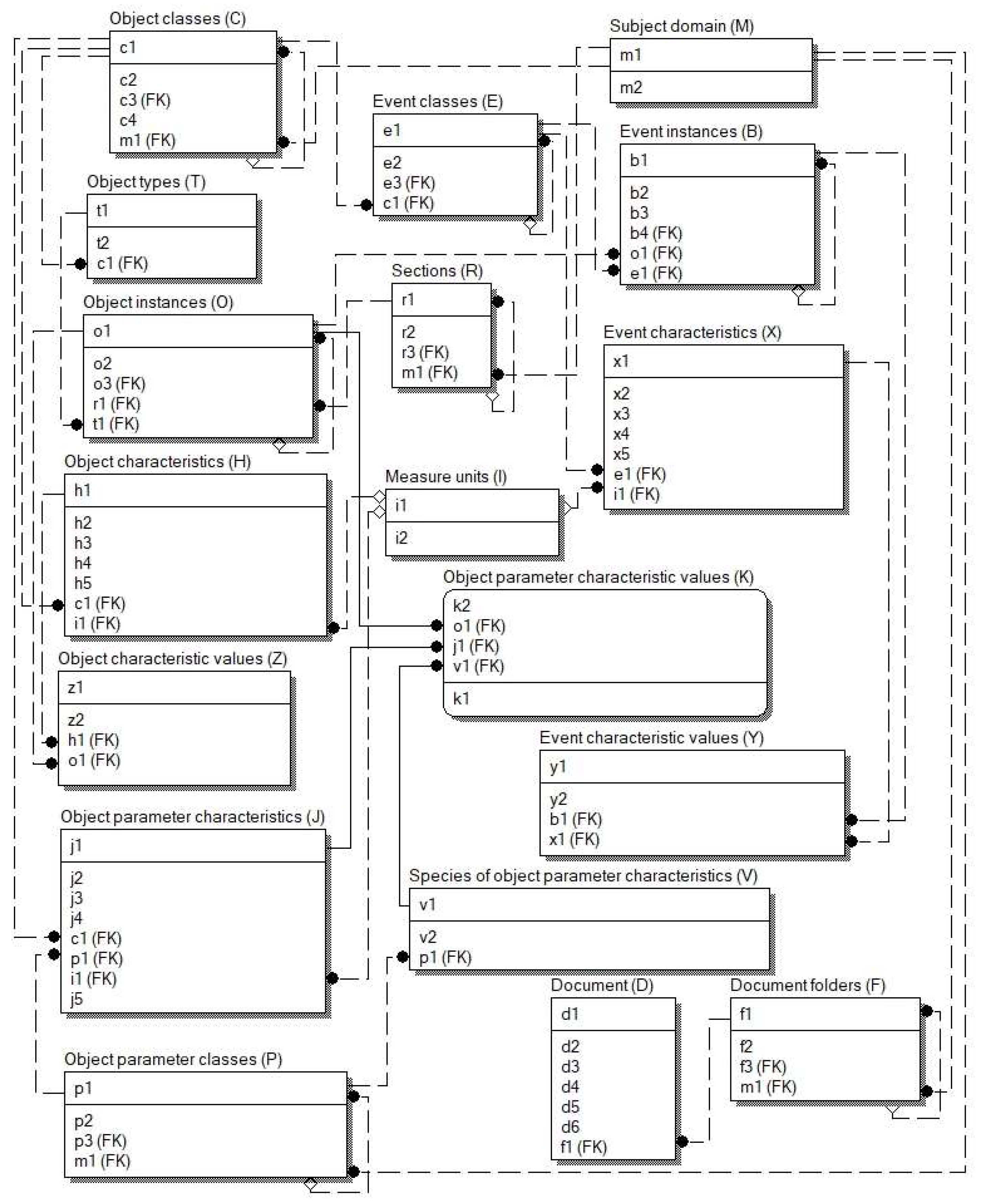
- Implementation of referential integrity for the schema relations associated with the relation (a specific document from relation is associated with a specific instance of the corresponding relation (Figure 1));
- –
- The constraint of the maximum number of instances of objects ( relations) for a certain class of objects ();
- –
- The constraint of the maximum number of values () that can be assigned to a certain event characteristic () for the event instance () of the specific class;
- –
- The constraints on the number of events () that occur with one object instance ():
- (a)
- At the same moment in time with one object instance, more than one event of the same class cannot occur;
- (b)
- One event that occurs with one object instance can have several subordinate events with different instances of objects occurring at the same time, but the specific event instance that occurs with the object instance of the certain class can have only one “event-owner”;
- –
- Generation of unique primary key values for schema relations and some others.
- –
- Structure;
- –
- Techniques of forming the genesis and subsequent blocks;
- –
- Verification methods (in the terminology of the Clark–Wilson model, this is ) of the PSM integrity, as well as two relations located in one of the privileged user database schemas, which are a mapping of the structure of blocks in the blockchain chain.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chapple, M.; Stewart, J.M.; Gibson, D. CISSP Certified Information Systems Security Professional Official Study Guide, 8th ed.; Sybex, John Wiley & Sons, Inc.: Indianapolis, IN, USA, 2018. [Google Scholar]
- Jueneman, R.R. Integrity controls for military and commercial applications. In Proceedings of the Fourth Aerospace Computer Security Applications, IEEE, Orlando, FL, USA, 12–16 September 1988; pp. 298–322. [Google Scholar] [CrossRef]
- Shcheglov, A.I. Protection of Computer Data from Unauthorized Access; Nauka i Technika: St. Petersburg, Russia, 2004. [Google Scholar]
- Jin, H.; Xiang, G.; Zou, D.; Zhao, F.; Li, M.; Yu, C. A guest-transparent file integrity monitoring method in virtualization environment. Comput. Math. Appl. 2010, 60, 256–266. [Google Scholar] [CrossRef][Green Version]
- Sandhu, R.S.; Jajodia, S. Data and database security and controls. In Handbook of Information Security Management; Auerbach Publishers: Boca Raton, FL, USA, 1993; pp. 481–499. [Google Scholar]
- Yesin, V.I.; Karpinski, M.; Yesina, M.V.; Vilihura, V.V. Formalized representation for the data model with the universal basis of relations. Int. J. Comput. 2019, 18, 453–460. [Google Scholar] [CrossRef]
- Yesin, V.I.; Karpinski, M.; Yesina, M.V.; Vilihura, V.V.; Veselska, O.; Wieclaw, L. Approach to Managing Data From Diverse Sources. In Proceedings of the 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Date, C.J. An Introduction to Database Systems, 8th ed.; Pearson Education Inc.: New York, NY, USA, 2004. [Google Scholar]
- Connolly, T.M.; Begg, C.E. Database Systems: A Practical Approach to Design, Implementation, and Management; Pearson Education Limited: London, UK, 2015. [Google Scholar]
- Sadalage, P.J.; Fowler, M. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence; Pearson Education: London, UK, 2013. [Google Scholar]
- Meier, A.; Kaufmann, M. SQL & NoSQL Databases. Databases Models, Languages, Consistency Options and Architectures for Big Data Management; Springer Fachmedien: Wiesbaden, Germany, 2019. [Google Scholar] [CrossRef]
- Harrison, G. Next Generation Databases: NoSQL, NewSQL, and Big Data; Apress: Berkeley, CA, USA, 2015. [Google Scholar]
- Pavlo, A.; Aslett, M. What’s really new with NewSQL? ACM SIGMOD Record 2016, 45, 45–55. [Google Scholar] [CrossRef]
- Garcia-Molina, H.; Ullman, J.D.; Widom, J. Database Systems. The Complete Book, 2nd ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Clark, D.D.; Wilson, D.R. A Comparison of Commercial and Military Computer Security Policies. In Proceedings of the IEEE Symposium on Research in Security and Privacy (SP’87), Oakland, CA, USA, 27–29 April 1987; IEEE Press: Oakland, CA, USA, 1987; pp. 184–193. [Google Scholar]
- Bernstein, P.A.; Dayal, U.; DeWitt, D.J.; Gawlick, D.; Gray, J.; Jarke, M.; Lindsay, B.G.; Lockemann, P.C.; Maier, D.; Neuhold, E.J.; et al. Future Directions in DBMS Research—The Laguna Beach Participants. ACM SIGMOD 1989, 18, 17–26. [Google Scholar] [CrossRef]
- Bernstein, P.; Brodie, M.; Ceri, S.; DeWitt, D.; Franklin, M.; Garcia-Molina, H.; Gray, J.; Held, J.; Hellerstein, J.; Jagadish, H.V.; et al. The Asilomar report on database research. ACM SIGMOD 1998, 27, 74–80. [Google Scholar] [CrossRef]
- Silverstone, L. The Data Model Resource Book, Vol. 1: A Library of Universal Data Models for All Enterprises; John Wiley & Sons, Inc.: Indianapolis, IN, USA, 2001. [Google Scholar]
- Silverstone, L. The Data Model Resource Book, Vol. 3: Universal Patterns for Data Modeling; John Wiley & Sons, Inc.: Indianapolis, IN, USA, 2009. [Google Scholar]
- Vyazilov, E.; Fedortsov, A.; Kobelev, A. Unification of data structure for field research, exploration and resources using of World Ocean. In Proceedings of the 10th All-Russian Scientific Conference “Digital Libraries: Advanced Methods and Technologies, Digital Collections”, Dubna, Russia, 7–11 October 2008. [Google Scholar]
- Vyazilov, E.D.; Fedortsov, A.A. Universal data storage model taking into account the life cycle of objects. In Proceedings of the Sixth All-Russian Open Annual Conference “Modern Problems of Remote Sensing of the Earth from Space”, Moscow, Russia, 10–14 November 2008. [Google Scholar]
- Tanenbaum, A.S.; Bos, H. Modern Operating Systems, 4th ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- Schott, M.; Krätzer, C.; Dittmann, J.; Vielhauer, C. Extending the Clark-Wilson security model for digital long-term preservation use-cases. In Proceedings of the SPIE 7542, Multimedia on Mobile Devices, San Jose, CA, USA, 27 January 2010. 75420M. [Google Scholar] [CrossRef]
- Biba, K.J. Integrity Considerations for Secure Computer Systems; Mitre Corp: Bedford, MA, USA, 1977. [Google Scholar]
- Whitman, M.E.; Mattord, H.J. Principles of Information Security, 6th ed.; Cengage Learning: Boston, MA, USA, 2017. [Google Scholar]
- Katzke, S.; Ruthberg, Z. Report of the Invitational Workshop on Integrity Policy in Computer Information Systems (WIPCIS). NIST Special Publication 500-160. Available online: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication500-160.pdf (accessed on 24 August 2021).
- Shockley, N.R. Implementing the Clark-Wilson integrity policy using current technology. In Proceedings of the 11th National Computer Security Conference, Baltimore, MD, USA, 17–20 October 1988; pp. 29–37. [Google Scholar]
- Toapanta, S.M.T.; Trejo, J.A.O.; Gallegos, L.E.M. Analysis of Model Clark Wilson to Adopt to the Database of the Civil Registry of Ecuador. In Proceedings of the 21st conference of the Open Innovations Association FRUCT, Helsinki, Finland, 6–10 November 2017; pp. 513–518. [Google Scholar]
- Gollmann, D. Computer Security, 3rd ed.; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Ge, X.; Polack, F.; Laleau, R. Secure databases: An analysis of Clark-Wilson model in a database environment. In Advanced Information Systems Engineering. CAiSE 2004; Persson, A., Stirna, J., Eds.; Lecture Notes in Computer Science, 3084; Springer: Berlin/Heidelberg, Germany, 2004; pp. 234–247. [Google Scholar] [CrossRef]
- Goguen, J.A.; Meseguer, J. Security policies and security models. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 26–28 April 1982; pp. 11–20. [Google Scholar] [CrossRef]
- Sutherland, D. A Model of Information. In Proceedings of the 9th National Computer Security Conference, Baltimore, MD, USA, 15–18 September 1986; pp. 175–183. [Google Scholar]
- Van Tilborg, H.C.A.; Jajodia, S. Encyclopedia of Cryptography and Security, 2nd ed.; Springer Science & Business Media: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Row-Level Security in a Relational Database Management System/Curt Cotner, Gilroy, CA (US); Roger Lee Miller, San Jose, CA (US); International Business Machines Corporation, Armonk, NY (US)—N 10/233,397. US Patent 2004/0044655A1. 4 March 2004.
- Row-Level Security in a Relational Database Management System/Curt Cotner, Gilroy, CA (US); Roger Lee Miller, San Jose, CA (US); International Business Machines Corporation, Armonk, NY (US)—N 12/242,241. US Patent 8,131,664 B2. 6 March 2012.
- Row-Level Security in a Relational Database Management System/Curt Cotner, Gilroy, CA (US); Roger Lee Miller, San Jose, CA (US); International Business Machines Corporation, Armonk, NY (US)—N 15/343,568. US Patent 8,478,713 B2. 16 January 2018.
- Feuerstein, S.; Pribyl, B. Oracle PL/SQL Programming, 6th ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2014. [Google Scholar]
- Kyte, T. Expert Oracle; Apress: New York, NY, USA, 2005. [Google Scholar]
- Nanda, A.; Feuerstein, S. Oracle PL/SQL for DBAs; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2005. [Google Scholar]
- Yesin, V.I.; Yesina, M.V.; Rassomakhin, S.G.; Karpinski, M. Ensuring Database Security with the Universal Basis of Relations. In Proceedings of the Computer Information Systems and Industrial Management. CISIM 2018; Lecture Notes in Computer Science, 11127; Saeed, K., Homenda, W., Eds.; Springer: Cham, Switzerland, 2018; Chapter 42; pp. 510–522. [Google Scholar]
- Groff, J.; Weinberg, P.; Oppel, A. SQL. The Complete Reference, 3rd ed.; McGraw-Hill Inc.: New York, NY, USA, 2010. [Google Scholar]
- Yesin, V.I.; Yesina, M.V.; Vilihura, V.V. Monitoring the integrity and authenticity of stored database objects. Telecommun. Radio Eng. 2020, 79, 1029–1054. [Google Scholar] [CrossRef]
- Bashir, I. Mastering Blockchain: Distributed Ledger Technology, Decentralization, and Smart Contracts Explained, 2nd ed.; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Antonopoulos, A.M. Mastering Bitcoin: Programming the Open Blockchain, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Chapweske, J. Tree Hash Exchange Format. Available online: https://web.archive.org/web/20090803220648/http://open-content.net/specs/draft-jchapweske-thex-02.html (accessed on 24 August 2021).
- Wei, W.; Yu, T. Integrity Assurance for Outsourced Databases without DBMS Modification. In Proceedings of the IFIP Annual Conference on Data and Applications Security and Privacy, Vienna, Austria, 14–16 July 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–16. [Google Scholar]
- Niaz, M.S.; Saake, G. Merkle Hash Tree based Techniques for Data Integrity of Outsourced Data. In Proceedings of the 27th GI-Workshop Grundlagen von Datenbanken, Gommern, Germany, 26–29 May 2015; pp. 66–71. [Google Scholar]
- Yesin, V.I.; Yesina, M.V. Language for universal data model. Inf. Process. Syst. 2011, 5, 193–197. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| 296987922 | 21-APR-20 06.00.13.000000 PM +03:00 | ua.xxx.com | WORKGR\DESKTOP-QRRDTTA | genesis block | D420161F35294B0A647DD3E6253C57AE258EC417D1014EFC483A66E7B6A91CE1 | D420161F35294B0A647DD3E6253C57AE258EC417D1014EFC483A66E7B6A91CE1 | 1 | … | |
| 296987923 | 22-APR-20 02.34.01.575000 PM +03:00 | ua.xxx.com | orcl | SYS | 4DC69C6660AF511F08D3F89FE899D19396269676F6578832EBC452EA45F4AD56 | 442F64B40C2CBA0E4786DEC2FB9FA64C310C8555F8E6F1582E1651AEB7501CEB | D420161F35294B0A647DD3E6253C57AE258EC417D1014EFC483A66E7B6A91CE1 | 9799 | … |
| 296987924 | 22-APR-20 02.36.24.606000 PM +03:00 | ua.xxx.com | orcl | user_1 | 3538FDE46591936C2FF53D069093231E9F72C316451629D44FAAE4AB221FE2D1 | F5415080C68CE7E671F5262A968CE013B70C6B3BEC200C9E90192D5AA22ED6EC | 442F64B40C2CBA0E4786DEC2FB9FA64C310C8555F8E6F1582E1651AEB7501CEB | 326 | … |
| … | … | … | … | … | … | … | F5415080C68CE7E671F5262A968CE013B70C6B3BEC200C9E90192D5AA22ED6EC | … | … |
| 296987923 | FUNCTION | AQ$_GET_SUBSCRIBERS | 05A85236D79D0FFB86DEB11B1F5D155C49B831A008C6E96F4A389C3896540107 |
| … | … | … | … |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yesin, V.; Karpinski, M.; Yesina, M.; Vilihura, V.; Warwas, K. Ensuring Data Integrity in Databases with the Universal Basis of Relations. Appl. Sci. 2021, 11, 8781. https://doi.org/10.3390/app11188781
Yesin V, Karpinski M, Yesina M, Vilihura V, Warwas K. Ensuring Data Integrity in Databases with the Universal Basis of Relations. Applied Sciences. 2021; 11(18):8781. https://doi.org/10.3390/app11188781
Chicago/Turabian StyleYesin, Vitalii, Mikolaj Karpinski, Maryna Yesina, Vladyslav Vilihura, and Kornel Warwas. 2021. "Ensuring Data Integrity in Databases with the Universal Basis of Relations" Applied Sciences 11, no. 18: 8781. https://doi.org/10.3390/app11188781
APA StyleYesin, V., Karpinski, M., Yesina, M., Vilihura, V., & Warwas, K. (2021). Ensuring Data Integrity in Databases with the Universal Basis of Relations. Applied Sciences, 11(18), 8781. https://doi.org/10.3390/app11188781