
A Secure Key Aggregate Searchable Encryption with Multi Delegation in Cloud Data Sharing Service

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
1.1. Motivation
- The first is a case in which time-critical work such as immediate life-threatening, bodily harm, and property benefits of the DO is required. For example, in the event of an emergency involving the DO’s life and body, the DU must delegate the authority to another DU when the DU who has been authorized to access information such as the DO’s health information management is absent.
- In addition, it is necessary to use various information and generate revenue through information sharing. A DU who has received information rights can use the information to make a profit. However, it is difficult to expect visible revenue generation from a single user. In this case, the DU can create new services and revenue by delegating limited access rights to other DUs.
- DUs authorized to provide services by data owners often struggle to manage large amounts of data. In this case, the DU should be able to perform load balancing by assigning limited administrative privileges to some users.
1.2. Contribution
- Group data sharing with a keyword search: In the proposed scheme, DOs can delegate access to and retrieval of data in an encrypted state for data sets requested by DUs. Additionally, each ciphertext in the shared set can be retrieved as a trapdoor of constant size generated using the aggregate key. Furthermore, the proposed system can confirm whether keywords exist in the data set to be searched using a bloom filter [14].
- Multi-access prevention and privacy preservation: The authentication of the proposed scheme prevents unauthorized DUs from accessing the trapdoor multiple times. In particular, if an unauthenticated user attempts to intercept and submit a trapdoor, the system prevents it. The identity submitted for authentication is a pseudonym identity which is masked and sent to protect the privacy of the DU. Moreover, keyword ciphertext, the hidden access policy defined by DO, and trapdoor does not disclosure information about related keywords.
- Fine-grained delegation: In the proposed scheme, the DO provides authentication credentials to delegators and delegates. When a delegator wants to delegate authority, it authenticates with the delegate through the authentication credential. If authentication is valid, delegates can delegate the rights they have received to another users in fine-grained manner.
2. Related Works
2.1. Literature Reviews
2.2. Preliminaries
2.2.1. Bilinear Map
- Bilinearity: For all , and , we have .
- Non-degeneracy: If u and v are generators of , .
- Computability: there is an efficient algorithm to compute for any .
2.2.2. Bloom Filter
- : hashes the data set S to for producing an m-bit bloom filter.
- : returns 0 if and 1 otherwise.
3. System Model and Threat Model
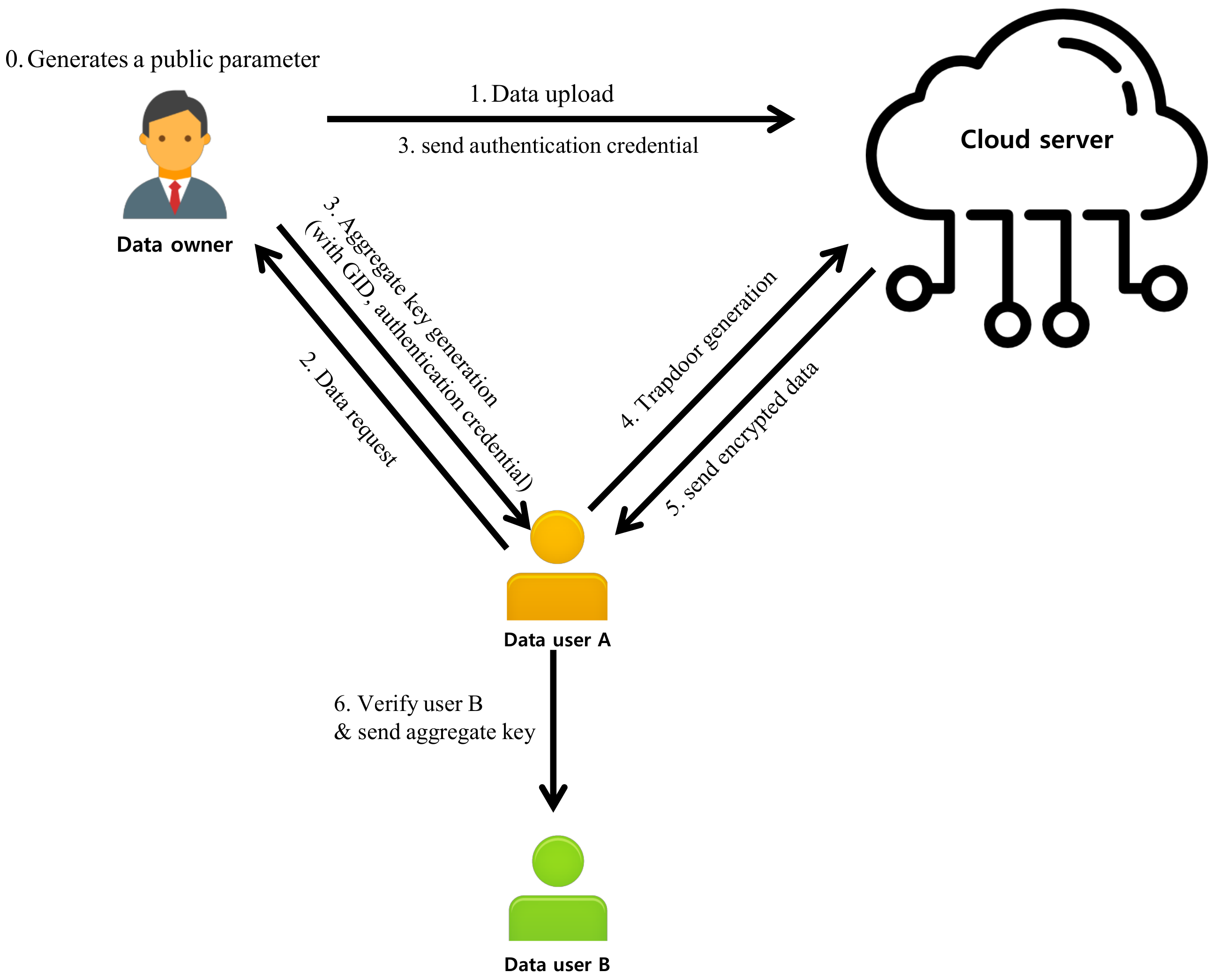
3.1. System Model
- Data Owner (DO): is an entity that independently manages data as an owner of data and information without TTP. When data are requested from , encrypts data and related keywords and stores them in the cloud server, delivering a single aggregate key of a fixed size. encrypts the group identity for delegation of authority of delegatee and delegator to define delegation of authority.
- Data User (DU): receives aggregate key when requesting data from the user. generates a trap door to retrieve data from using aggregate key and keyword, receives encrypted data through authentication with , and then decrypts to receive data.
- Cloud Server (CS): Since is an honest but curious entity, it may legitimately try to learn all the information from a received message. provides with storage and computing power. In addition, searches data through the trapdoor received from and performs keyword verification.
3.2. Threat Model
- The attacker has full control over and learns from messages sent over open channels. The attacker can then insert, modify, or remove valid messages.
- Because guessing more than one value at a time is a “computationally infeasible operation”, the attacker can only guess one value in polynomial time.
3.3. Notations
4. Our Proposed Scheme
4.1. Setup Phase
4.2. Data Upload Phase
4.3. Data Request Phase
4.4. Data Retrieve Phase
4.5. Authentication for Delegation Phase
4.6. Group Identity Revocation Phase
5. Security Analysis
5.1. Informal Analysis
5.1.1. Correctness
5.1.2. Impersonation Attacks
5.1.3. Data User Anonymity
5.1.4. Perfect Forward Secrecy
5.1.5. Privileged-Insider Attacks
5.1.6. Replay and Man-In-The-Middle Attacks
5.1.7. Known Session-Specific Temporary Information Attacks
5.1.8. Ephemeral Secret Leakage (ESL) Attacks
5.1.9. Session Key Disclosure Attacks
5.1.10. Mutual Authentication
5.2. BAN Logic Analysis
5.2.1. Logical Rules of BAN Logic
- 1.
- Jurisdiction rule :
- 2.
- Nonce verification rule :
- 3.
- Message meaning rule :
- 4.
- Belief rule :
- 5.
- Freshness rule :
5.2.2. Goals for Data Retrieve Phase
- Goal 1:
- ,
- Goal 2:
- ,
- Goal 3:
- ,
- Goal 4:
- ,
5.2.3. Idealized Forms for Data Retrieve Phase
- M1 :
- M2 :
5.2.4. Assumptions for Data Retrieve Phase
- A1 :
- A2 :
- A3 :
- A4 :
- A5 :
- A6 :
5.2.5. Proof Using BAN Logic for Data Retrieve Phase
- Step 1:
- can be obtained from: .
- Step 2:
- For obtaining , we apply the message meaning rule with: .
- Step 3:
- For obtaining , we apply the freshness rule with: .
- Step 4:
- For obtaining , we apply the nonce verification rule with and: .
- Step 5:
- For obtaining , we apply the belief rule: . (Goal 2)
- Step 6:
- For obtaining , we apply the jurisdiction rule with: . (Goal 1)
- Step 7:
- can be obtained from: .
- Step 8:
- For obtaining , we apply the message meaning rule with: .
- Step 9:
- For obtaining , we apply the freshness rule with: .
- Step 10:
- For obtaining , we apply the nonce verification rule with and: .
- Step 11:
- For obtaining , we apply the belief rule: . (Goal 4)
- Step 6:
- For obtaining , we apply the jurisdiction rule with: . (Goal 3)
5.3. AVISPA Simulation Analysis
6. Security and Efficiency Features Comparison
6.1. Functionality and Security Features Comparison
6.2. Comparison of Computation Costs
- Platform 1: The platform 1 is general personal computer environment, and the detailed performance of the personal computer is as follows: “Ubuntu 18.04.4 LTS with memory 8 GiB, processor: Intel Core i7-4790 @ 3.60GHz × 4, CPU Architecure: 64-bit.” The experiments are executed for “one-way-hash-function ”, “Bilinear pairing operation ”, “Scalar point multiplication ”, and “Exponentiation operation ” for 100 runs. After that the average run-time in milliseconds are recorded for these operations or functions from 100runs, which are 0.003 ms, 6.575 ms, 2.373 ms, and 0.819 ms, respectively.
- Platform 2: The platform 2 is Raspberry PI environment for considering mobile device, and the detailed performance of the Raspberry PI is as follows: “Model: Raspberry PI 3 B, with CPU 64-bit, Processor: 1.2 GHz Quad-core, Memory: 1 GiB, and OS: Ubuntu 20.04.2 LTS 64-bit.” Figure 8 shows the setting of Raspberry PI environment. The experiments are executed for “one-way-hash-function ”, “Bilinear pairing operation ”, “Scalar point multiplication ”, and “Exponentiation operation ” for 100 runs. After that the average run-time in milliseconds are recorded for these operations or functions from 100runs, which are 0.020 ms, 21.348 ms, 5.686 ms, and 2.973 ms, respectively.
6.3. Comparison of Computation and Communication Complexity
6.4. Discussion of Comparison
7. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Holst, A.; Statista. Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2024. 2020. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 30 January 2021).
- Kamara, S.; Lauter, K. Cryptographic Cloud Storage. In Proceedings of the International Conference on Financial Cryptography and Data Security, Tenerife, Spain, 25–28 January 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 136–149. [Google Scholar]
- Osanaiye, O.; Choo, K.K.R.; Dlodlo, M. Distributed denial of service (DDoS) resilience in cloud: Review and conceptual cloud DDoS mitigation framework. J. Netw. Comput. Appl. 2016, 67, 147–165. [Google Scholar] [CrossRef]
- Juliadotter, N.V.; Choo, K.K.R. Cloud attack and risk assessment taxonomy. IEEE Cloud Comput. 2015, 2, 14–20. [Google Scholar] [CrossRef]
- MiData. The Midata Project. Available online: https://www.midata.coop (accessed on 9 August 2021).
- Fiat, A.; Naor, M. Broadcast encryption. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 22–26 August 1993; pp. 480–491. [Google Scholar]
- Ferrailol, D.F.; Kuhn, D.R. Role based access control national computer security conference. In Proceedings of the 15th National Computer Security Conference (NCSC), Baltimore, ML, USA, 13–16 October 1992; pp. 554–563. [Google Scholar]
- Sahai, A.; Waters, B. Fuzzy identity-based encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005; Volume 3494, pp. 457–473. [Google Scholar]
- Chu, C.K.; Chow, S.S.; Tzeng, W.G.; Zhou, J.; Deng, R.H. Key-aggregate cryptosystem for scalable data sharing in cloud storage. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 468–477. [Google Scholar]
- Cui, B.; Liu, Z.; Wang, L. Key-aggregate searchable encryption (KASE) for group data sharing via cloud storage. IEEE Trans. Comput. 2016, 65, 2374–2385. [Google Scholar] [CrossRef]
- Burrows, M.; Abadi, M.; Needham, R. A logic of authentication. ACM Trans. Comput. Syst. 1990, 8, 18–36. [Google Scholar] [CrossRef]
- AVISPA. Automated Validation of Internet Security Protocols and Applications. Available online: http://www.avispa-project.org/ (accessed on 9 August 2021).
- MIRACL Cryptographic SDK: Multiprecision Integer and Rational Arithmetic Cryptographic Library. Available online: https://github.com/miracl/MIRACLAccessed (accessed on 9 August 2021).
- Zheng, Q.; Xu, S.; Atenise, G. VABKS: Verifiable attribute-based keyword search over outsourced encrypted data. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 522–530. [Google Scholar]
- Guo, C.; Luo, N.; Bhuiyan, M.Z.A.; Jie, Y.; Chen, Y.; Feng, B.; Alam, M. Key-aggregate authentication cryptosystem for data sharing in dynamic cloud storage. Future Gener. Comput. Syst. 2018, 84, 190–199. [Google Scholar] [CrossRef]
- Alimohammadi, K.; Bayat, M.; Javadi, H.H. A secure key-aggregate authentication cryptosystem for data sharing in dynamic cloud storage. Multimedia Tools Appl. 2020, 79, 2855–2872. [Google Scholar] [CrossRef]
- Zhou, R.; Zhang, X.; Du, X. File-centric multikey aggregate keyword searchable encryption for industrial internet of things. IEEE Trans. Ind. Inf. 2018, 14, 3648–3658. [Google Scholar] [CrossRef]
- Li, T.; Liu, Z.; Li, P. Verifiable searchable encryption with aggregate keys for data sharing in outsourcing storage. In Proceedings of the Australasian Conference on Information Security and Privacy, Melbourne, VIC, Australia, 4–6 July 2016; pp. 153–169. [Google Scholar]
- Padhya, M.; Jinwala, D.C. MULKASE: A novel approach for key-aggregate searchable encryption for multi-owner data. Front. Inf. Technol. Electron. Eng. 2019, 20, 1717–1748. [Google Scholar] [CrossRef]
- Liu, Z.; Li, T.; Li, P. Verifiable searchable encryption with aggregate keys for data sharing system. Future Gener. Comput. Syst. 2018, 78, 778–788. [Google Scholar] [CrossRef]
- Yu, S.; Lee, J.; Lee, K.; Park, K.; Park, Y. Secure authentication protocol for wireless sensor networks in vehicular communications. Sensors 2018, 18, 3191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, S.; Lee, J.; Park, K.; Das, A.K.; Park, Y. IoV-SMAP: Secure and efficient message authentication protocol for IoV in smart city environment. IEEE Access 2020, 8, 167875–167886. [Google Scholar] [CrossRef]
- Kwon, D.; Yu, S.; Lee, J.; Son, S.; Park, Y. WSN-SLAP: Secure and lightweight mutual authentication protocol for wireless sensor networks. Sensors 2021, 21, 936. [Google Scholar] [CrossRef] [PubMed]
- Oh, J.; Yu, S.; Lee, J.; Son, S.; Kim, M.; Park, Y. A secure and lightweight authentication protocol for IoT-based smart homes. Sensors 2021, 21, 1488. [Google Scholar] [CrossRef]
- Lee, J.; Yu, S.; Park, K.; Park, Y.; Park, Y. Secure three-factor authentication protocol for multi-gateway IoT environments. Sensors 2019, 19, 2358. [Google Scholar] [CrossRef] [Green Version]
- Park, K.; Noh, S.; Lee, H.; Das, A.K.; Kim, M.; Park, Y.; Wazid, M. LAKS-NVT: Provably secure and lightweight authentication and key agreement scheme without verification table in medical internet of things. IEEE Access 2020, 8, 119387–119404. [Google Scholar] [CrossRef]
- Lee, J.; Kim, G.; Das, A.K.; Park, Y. Secure and Efficient Honey List-Based Authentication Protocol for Vehicular Ad Hoc Networks. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2412–2425. [Google Scholar] [CrossRef]
- Wazid, M.; Bagga, P.; Das, A.K.; Shetty, S.; Rodrigues, J.J.; Park, Y. AKM-IoV: Authenticated key management protocol in fog computing-based Internet of vehicles deployment. IEEE Internet Things J. 2019, 6, 8804–8817. [Google Scholar] [CrossRef]
- Boneh, D.; Franklin, M. Identity-based encryption from the Weil pairing. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 213–229. [Google Scholar]
- Dolev, D.; Yao, A. On the security of public key protocols. IEEE Trans. Inf. Theory 1983, 29, 198–208. [Google Scholar] [CrossRef]
- Canetti, R.; Krawczyk, H. Universally composable notions of key exchange and secure channels. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Amsterdam, The Netherlands, 17 April 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 337–351. [Google Scholar]
- Son, S.; Lee, J.; Kim, M.; Yu, S.; Das, A.K.; Park, Y. Design of secure authentication protocol for cloud-assisted telecare medical information system using blockchain. IEEE Access 2020, 8, 192177–192191. [Google Scholar] [CrossRef]
- Park, K.; Park, Y.; Das, A.K.; Yu, S.; Lee, J.; Park, Y. A dynamic privacy-preserving key management protocol for V2G in social internet of things. IEEE Access 2019, 7, 76812–76832. [Google Scholar] [CrossRef]
- Lee, J.; Yu, S.; Kim, M.; Park, Y.; Lee, S.; Chung, B. Secure key agreement and authentication protocol for message confirmation in vehicular cloud computing. Appl. Sci. 2020, 10, 6268. [Google Scholar] [CrossRef]
- Kim, M.; Lee, J.; Park, K.; Park, Y.; Park, K.H.; Park, Y. Design of Secure Decentralized Car-Sharing System Using Blockchain. IEEE Access 2021, 9, 54796–54810. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Meanings |
|---|---|
| jth data user and their identity, respectively, | |
| Data owner | |
| Cloud server | |
| The hidden identity of jth data user | |
| Bilinear groups | |
| The ’s public key for encrypt data | |
| The ’s public key for authentication | |
| Master secret key and secret key of | |
| The public key of data user and cloud server, respectively | |
| The group identity defined by data owner and its hidden identity | |
| Current timestamps | |
| Maximum transmission delay | |
| Random nonces | |
| W | The keyword |
| The encrypted keyword | |
| The trapdoor | |
| Data concatenation operator | |
| The hash function | |
| The map-to-point hash function , | |
| ⊕ | Bitwise exclusive-or operator |
| Notations | Meaning |
|---|---|
| The used session key in current authentication session | |
| The statement is fresh | |
| sees the statement | |
| believes the statement | |
| once said | |
| Formula is united with formula | |
| Encrypt the formula encrypted the key | |
| and uses as shared key for communicating | |
| controls the statement |
| Security Properties | Cui et al. [10] | Liu et al. [20] | Ours |
|---|---|---|---|
| Man-in-the-middle attack | o | o | o |
| Replay attack | o | o | o |
| Impersonation attack | x | x | o |
| User anonymity | o | o | o |
| Privileged-insider attack | x | o | o |
| Session key disclosure attack | x | o | o |
| Mutual authentication | x | x | o |
| Multi-access | - | - | o |
| Multi-delegation | - | - | o |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, M.; Oh, J.; Park, Y.; Park, K.; Noh, S. A Secure Key Aggregate Searchable Encryption with Multi Delegation in Cloud Data Sharing Service. Appl. Sci. 2021, 11, 8841. https://doi.org/10.3390/app11198841
Lee J, Kim M, Oh J, Park Y, Park K, Noh S. A Secure Key Aggregate Searchable Encryption with Multi Delegation in Cloud Data Sharing Service. Applied Sciences. 2021; 11(19):8841. https://doi.org/10.3390/app11198841
Chicago/Turabian StyleLee, JoonYoung, MyeongHyun Kim, JiHyeon Oh, YoungHo Park, KiSung Park, and Sungkee Noh. 2021. "A Secure Key Aggregate Searchable Encryption with Multi Delegation in Cloud Data Sharing Service" Applied Sciences 11, no. 19: 8841. https://doi.org/10.3390/app11198841