1. Introduction
Gaze estimation has long been recognized as an important research topic since it has strong real-world applications, for instance, in human–computer interfaces [
1,
2], gaze-based interfaces [
3,
4], virtual reality [
5,
6], health care [
7], behavioral analysis [
8], and communication skills [
9]. Therefore, gaze estimation has become a well-established research topic in computer vision, especially in human–computer interaction (HCI) [
10,
11]. Early gaze estimation techniques required strict conditions to calculate gaze points, such as stabilizing a person’s head and controlling light conditions. These restraints bounded the applications to relatively restricted laboratory environments. For applying gaze estimation in natural environments, we have proposed many methods to mitigate these restraints and have uplifted gaze estimation towards being calibration-free, without person-specific and light independent gaze tracking [
12,
13].
Most of the available eye-tracking methods are expensive as they require specialized commercial hardware and software. With the growing number of applications that use eye-tracking, there is also a growing need for cheap and ubiquitous methods to obtain information about human gaze coordinates. Therefore, methods utilizing unmodified cameras currently built into almost every computer setup can play an essential role in popularizing eye-tracking since they are easily available and do not require additional costs.
Unmodified web cameras have been used in this paper to assess the possibility of utilizing them to estimate gaze coordinates. Nowadays, almost every computer is equipped with a camera that potentially may be used for gaze estimation. The main problem is that unmodified web cameras work only in visible light (and most have infrared filters). The next problem is that they typically have a wide-angle lens with limited (if any) possibilities to zoom. The result is that the image of the eyes is small (low resolution) and is highly dependent on light conditions. That is why using an unmodified camera for eye tracking is a big challenge.
Algorithms that use unmodified cameras are different from classical eye tracking algorithms, which utilize infrared cameras and an additional infrared light source that produces a glint (reflection from eyeball) to track the eyes. Although cameras with infrared light can detect eyes with high accuracy, they add an additional cost to the eye-tracking. In our research, we used standard unmodified cameras to detect face and eye regions, which reduces the eye-tracking cost significantly. Estimating the gaze coordinate from the unmodified cameras is a difficult task as compared to infrared cameras because, in unmodified cameras, the pupil cannot be located clearly all the time. In addition, different illumination conditions, head position, and eye angles can make it hard to estimate the person’s gaze.
In this research, the image taken by an unmodified web camera was fed to the state-of-the-art CNN network to produce the information about the region on a screen where the person was looking. The CNN network was trained and tested with several different architectures of the CNN network with several combinations of face, both eyes, and single eyes to estimate the gaze coordinate from the camera images. Our experimental findings show that it is possible to predict human gaze points from an unmodified camera with reasonable accuracy.
The main contribution of the paper is creating and testing a dataset that was collected in the wild by people sitting at their own laptops without any supervision. This dataset was used to train different networks. The low quality of the recordings made it challenging to assess the exact coordinates of the gaze points, but it was shown that it is possible to estimate with high accuracy the 20 screen areas the person is looking at.
The rest of the paper is structured as follows:
Section 2 presents related work for the gaze estimation.
Section 3 presents our dataset and the different network architectures used in this study.
Section 4 presents the experimental results of this study. Finally,
Section 5 includes concluding remarks and a summary and suggests future directions in gaze estimation.
2. Related Work
Gaze estimation has been studied for decades due to its variety of applications in different domains. The traditional approach is to record an image of an eye, use image processing techniques to find a pupil, sclera, light source reflections (Purkinje images), and then use their locations to estimate gaze. The main problem with this approach is that it requires a high-quality image of the eye. Therefore, professional video-based (VOG) eye trackers are equipped with high-quality cameras and have many restrictions for participants (such as using a chin-rest or bite-bar) to ensure that an eye image is visible in the camera.
Gaze estimation methods can be categorized into model-based, also known as feature-based, and appearance-based approaches [
14]. Model-based methods make use of 3D geometric eye models to estimate gaze direction [
15,
16]. They usually explore the characteristics of the human eye to identify a set of distinctive features of the eyes. The limbus, pupil (dark/bright pupil images), and cornea reflections are common features used to estimate gaze direction. Furthermore, these methods also require infrared light sources together with high-resolution cameras. Although this approach can accurately estimate gaze direction, it requires specialized hardware that limits its range of application. If the iris contour alone is used to detect the line of sight, the need for specialized eyewear can be relaxed [
17]. In conclusion, these methods are effective for short-distance scenarios in which high-resolution observations are available, but their effectiveness in mid-distance scenarios is unclear.
Most commercial eye trackers ordinarily depend on active illumination, i.e., pupil center corneal reflections (PCCR) based eye-tracker uses infrared illumination, which provides high accuracy [
18]. However, these types of eye trackers are expensive and generally used in a laboratory setting together with a chin rest or bite bar that stabilizes the head. To reduce the restriction on head movement, the authors proposed different solutions [
19,
20]. However, these eye trackers do not work well in outdoor situations because of the sun’s infrared radiation.
Appearance-based methods have achieved great success in gaze estimation in recent years due to their ability to learn the gaze direction directly from the image of the eye without any feature extraction. These methods require only off-the-shelf cameras, which are normally available, that simplify capturing gaze coordinates in indoor and outdoor conditions. However, attaining a high accuracy is challenging due to many factors such as changes in appearance, lighting conditions, and head pose [
21]. With the success of convolutional neural networks (CNNs) in computer vision, researchers have adopted using CNN in appearance-based gaze estimation, which has reduced estimation errors [
22]. Trained with high quality diverse real and synthesized datasets covering a wide range of variation [
22,
23], a deep CNN network can learn to compensate much of the variability present in the dataset [
13,
24].
Deep learning is a powerful technique that has developed fast and is widely used in many applications [
25,
26] including computer vision [
27] and gaze estimation [
28,
29]. Furthermore, there have been several open-source datasets for gaze estimation from the research community, for instance, MPIIGaze [
22], GazeCapture [
30], TabletGaze [
31], including head pose and gaze database [
32], ETH-XGaze [
33], and RT-GENE [
34]. Several approaches have been proposed for appearance-based gaze estimation. For instance, in [
22], the authors proposed a multimodal convolutional neural network, but before sending input to this network, the authors used the SURF cascade method [
35] and constrained local mode framework to detect faces and facial landmark [
36]. Furthermore, the authors also used a space normalization technique to normalize the input image and head pose space into a polar coordinate angle space [
23]. Furthermore, in [
30], the authors trained an iTracker based on CNN network on the GazeCapture dataset; the network takes the eye image and face image with its location associated in face grid. The face-based 2D and 3D gaze estimation was proposed in [
37]. The authors used a special weight mechanism that takes the information of different parts of the entire face and learns the pattern using a standard CNN network. In [
24], the authors addressed the person and head pose as an independent problem for 3D gaze estimation by using a recurrent convolution network from remote cameras. They combined the eyes region, face, and facial landmark points as an independent input into the CNN network, and they used a many-to-one recurrent network for gaze coordinate prediction.
In [
38], the authors proposed a so-called
Gazemap for gaze estimation, which is an abstract pictorial representation of the eyeball, iris, and pupil at its center. Instead of directly regressing two angles of the eyeball, the authors regressed an intermediate pictorial representation that simplifies the gaze estimation task. For estimating the gaze information from the ocular region of an image, a capsules network was proposed [
39]. The authors used the concept of capsules that converts pixel intensities to instantiation parameters of features, which accumulate into a higher level of features as the depth of the network increases, and proposed pose-aware Gaze-Net architecture for gaze estimation.
Although several studies are available for gaze estimation, only a few studies have covered gaze estimation using unmodified cameras. For instance, in [
40], the authors propose a two-stage gaze estimation method that relies on deep learning methods and logistic regression. Their proposed method can be applied to various mobile platforms without additional hardware devices or systematic prior knowledge. In [
28], an artificial neural network is proposed to estimate the gaze coordinate from the standard webcam. Their experiment showed a promising result for the development of low-cost tracking using a standard webcam. Model-based gaze estimation is also proposed by Wood et al. for unmodified tablet computers [
41]. They presented an EyeTab method based on a model-based approach for binocular gaze estimation that runs solely on an unmodified tablet.
There are some works that are similar to our work. For instance, the authors in [
42] designed a differential gaze estimation by training a differential neural network. However, the authors in this paper used calibrated high-quality eye images for training their network, which is different from our method because, in our approach, we used only low-resolution images without calibration. In another work [
43], the authors designed a hardware-friendly CNN model that utilizes a minimum computational requirement for efficient gaze estimation on low consumer devices. However, they tested their model on MPIIgaze, the dataset that is a calibrated dataset in which on-screen gaze position is converted to the 3D position in the camera coordinate system using a camera calibration procedure from the OpenCV library.
The work most similar to the investigation presented in this paper is [
40]. However, the authors of that paper proposed their method solely for mobile devices. Furthermore, they tested their method on a dataset collected from a single device. Contrary to that, the model presented our paper is tested on desktop computers and laptops. Additionally, the dataset was collected from multiple devices so that it can be generalized for other desktop setups.
3. Materials and Methods
This section first describes the data collection methodology for the conducted research. The following section provides information about data preprocessing steps that are necessary for deep learning. In the third section, information about the dataset used in this research is presented. Finally, the last subsection presents a detailed overview of different architectures tested in this study.
3.1. Data Collection Methodology
This section presents the data acquisition method, which plays a significant role in deep learning methods. The quality of the acquired data, with the help of which the neural network is trained, has a paramount influence on the process itself because any image that deviates from the others can negatively affect the entire process of training the neural network.
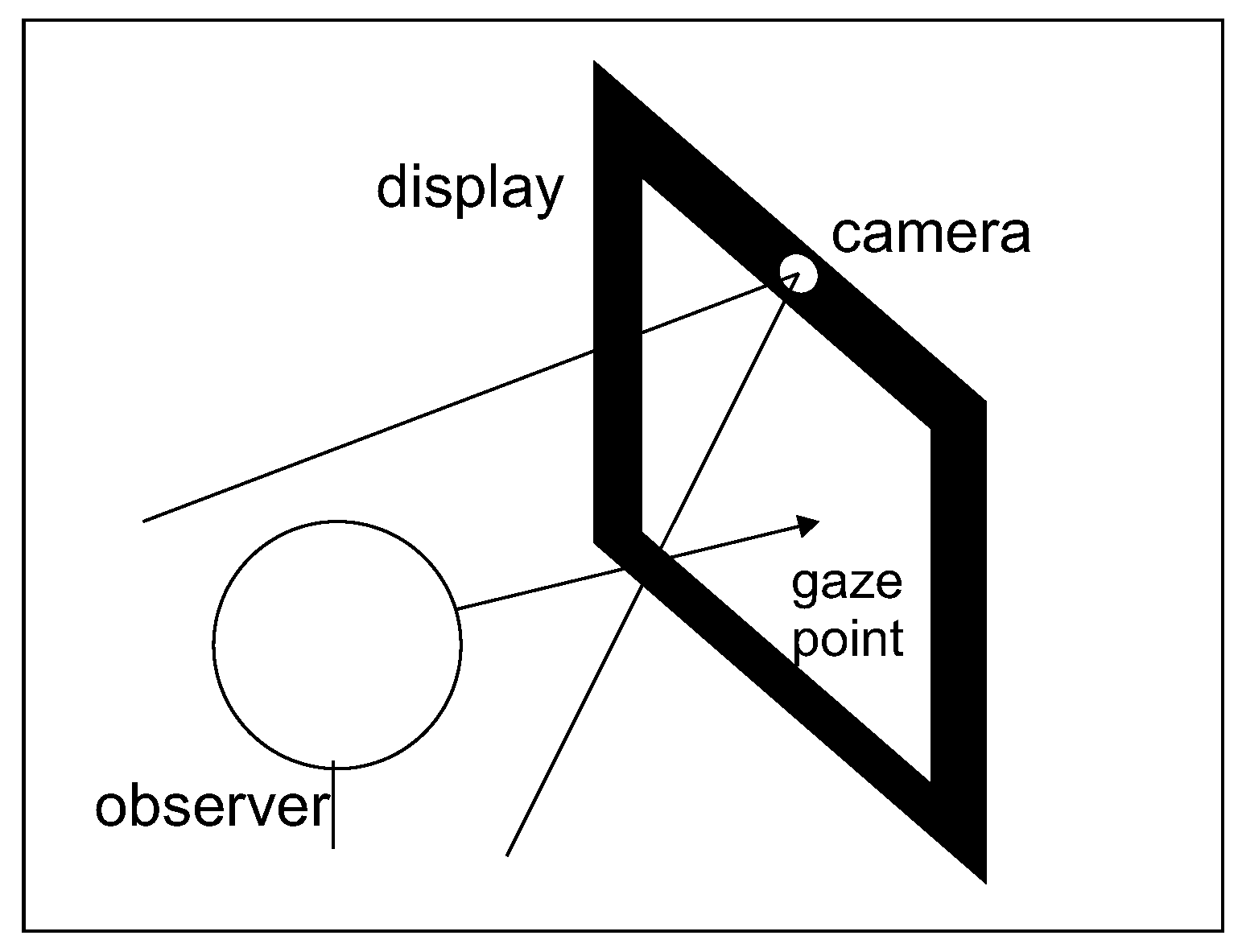
Data were collected using the
EyeTrackerDataCollector application, which is a desktop application registering images from a camera. No specific hardware requirements were made. The only hardware requirement was to have a webcam, preferably built into the top of the laptop screen (see
Figure 1). This assumption allowed for the acquisition of images under real-world conditions and not typical laboratory conditions. These measures were designed to answer the question of whether anyone owning standard webcam equipment could use a classifier capable of determining where on the screen a person is focusing their attention. Test subjects were asked to pay attention to the lighting during image acquisition. A problem with the lack of robustness to this factor was noted at the outset. Failure to adjust the lighting resulted in very low-quality, dark even black, or completely overexposed images. The subject sat centrally facing the screen with the built-in camera at the height of the horizontal axis of the eyes at a distance of about 35 to 50 cm from the monitor. During every session, the subject was required to click 20 points displayed subsequently on screen in different evenly distributed locations (in a five by four grid). After each click, a series of three camera images was taken and stored together with information about the point’s location.
3.2. Data Preprocessing
Figure 2 presents the image processing steps. The original images as taken from the camera are presented on the left side of the figure, while the right side presents the images that were additionally sharpened using a function available in the OpenCV library. Step (1) is to take a picture with a webcam. Step (2) is to convert the image to grayscale. Step (3) is to cut out the face detected by the Viola–Jones classifier using a proper Haar cascade [
44]. This method was presented by Paul Viola and Michael Jones in 2001. The proposed solution is based on machine learning and uses Haar-like features. The cascade feature is trained on a large number of positive and negative images. It is then used to detect objects in other images. In the first stage, the algorithm needs a large number of positive images, i.e., images that will be targeted for detection, such as images containing a face, and a large number of negative images that do not contain the object to be detected in a later stage. It is important to keep the size of the images the same. To achieve this goal, the images must be scaled appropriately to equal size. It allows the algorithm to omit any unnecessary and meaningless factors that would also have to be considered during learning. Once trained, such a classifier returns a value of “1” when an object is found or “0” if an object is not found. To search for an object across the image, the classifier, in the form of a window, moves across the image in search of the object by checking each location. The classifier is designed to be easily expandable and modifiable. It allows searching for objects of different sizes. Such a solution translates into the classifier’s efficiency because the size of the input image is not required to change. To find an object of unknown size in the image, the scanning procedure is repeated several times, and the scaling factor of the classifier is modified each time. We used the cascades available in the OpenCV library.
The right and left eyes are found and marked by using another Haar cascade in step (4). The face is detected first, and then the eyes are detected in the face image. This approach reduced the susceptibility of misclassification of eyes in the image by detecting objects that are confusingly similar to eyes. Step (5) is to precisely cut out the eye itself if possible. Step (6) (the final set) is to mask the eye from the fifth stage with a white ellipse with a black border. Performing the fifth and final sixth stages helps to reduce the influence of meaningless pixels surrounding the eye as much as possible. This approach increases the quality of the trained neural network.
The last step before using the data to train the CNN is to resize the images. For proper operation, the neural network requires that each of the input images should be of the same size. Therefore, all eye images were rescaled to 60 × 30 pixels and all face images to 227 × 227 pixels using methods available in the OpenCV library.
The data prepared with this method must be manually verified. It consists of checking all collected images for their correct content. There are situations when the Haar cascade classifier used for eye detection localizes another element deceptively resembling the eye on the image. There are also cases when the person performing the examination has looked at another place. These cases should not be taken into consideration. There is also a possibility that the person blinks when the picture is taken, and a nearly closed eye is detected. Such deviating images should be manually excluded from the dataset and not subjected to the neural network training process. In the future, we plan to develop more automated methods to identify deviations. Examples of images that have been excluded from the dataset are marked in red and shown in
Figure 3 and
Figure 4. The first figure shows the situation when the subject blinked when taking the image, while in the second figure, the Haar cascade classifier mistakenly detected an additional element in the image deceptively similar to the eye feature. The detected element is a fragment of the subject’s hair.
The final step of pre-processing is image value normalization, which amounts to normalizing the pixel values of an image. The images belonging to the dataset used for the neural network training and testing process are normalized by dividing the values by 255, resulting in the value of each image pixel between 0 and 1.
3.3. Datasets
Two datasets were created and used for the neural network training process. The first dataset consisted of images acquired from a single person. There are approximately 6000 images in this dataset, which is the sum of all images acquired for all 20 points. It implies that there are about 300 sets of images for each point consisting of left and right eye images and a face image. The second dataset consists of images acquired from four subjects, where one of the subjects additionally performed the tests twice—the first time without glasses (with lenses) and the second time with glasses. In this set, the number of images is more than quadrupled because each tested person was required to provide the same set of data.
3.4. Network Architecture of the Tested Models
This section presents a description of three designed models, each of which takes a different set of input images. Each of the designed network architectures has fixed elements implemented: the output layer activation functions used, the hidden layer activation functions, the weight initialization strategy, and the loss function. The presented architectures are already refined models, which are the final ones that emerged after multiple tests of different parameters.
The output of each network is a vector of 20 values. Every value represents a probability that the input images are registered when a person looked at a given area in the 5 by 4 grid of 20 areas.
Every network consists of three kinds of components:
Convolutional layer (Convolution): The layer’s input is an image with some number of channels, and the layer creates another image with the number of layers equal to the number of filters. The number and the size of filters used to convert the image are two parameters of such layer;
Pooling Layer (Subsampling): The layer’s input is an image, and the output is the image reduced in both dimensions. Only Max Pooling layers were used, which reduced the image by representing the area of a given size by one pixel, which is the brightest. There is only one parameter for this layer—the size of the reduction. Only two sizes, 2 × 2 and 3 × 3, were used;
Fully connected layer (FC): It is a classic neural network’s layer that consists of some number of neurons, and every neuron received a weighted combination of all input values.
ADAM optimizer [
45] was used to train the CNN network with the initial value of the learning rate set to a value equal to 0.00015. The Rectified Linear Unit (ReLU) [
46] was used as the hidden layer activation function. Xavier initialization [
47] was used as the initialization strategy for weights, while the output layer used an activation function in the form of a normalized Softmax exponential function (see Equation (
1)):
where
represents the output from the network, and
is the number of classes.
Negative Log-Likelihood (NLL) was taken as the loss function, which works well with the Softmax activation function for solving multi-class neural network learning and image classification problems considering a set of pixels as input. Equation (
2) represents the mathematical formula for the NLL function:
where
is the parameter of the function,
Y denotes the output values,
X represents the features of the image, and
M is the number of samples.
An identical naming convention for the neural network layers was adopted for each experiment. The LRE symbol designation refers to layers using the right eye images, the LLE symbol refers to layers describing the left eye, and LF refers to layers pertaining to face images. The Convolution layers always have information about the size of the filter, and the numbers of filters are provided in the text or tables. The Subsampling layers have information about the reduction size. The number of neurons for each Full Connected layer is explained in the corresponding text. The FC symbol indicates fully connected layers where, for example, FC-RE refers to the fully connected layer for the right eye.
3.4.1. One Eye Image as a Neural Network Input
For this experiment, a network architecture was prepared by accepting an image of one eye in its parameter. The architecture is shown in
Figure 5. The neural network consists of three convolutional layers, one subsampling layer with a filter size of 2 × 2, and one fully connected layer. The first convolutional layer (LLE1) has 96 filters, the LLE3 layer has 384 filters, and LLE4 has 256 filters. The fully connected layer (FC1) has 256 neurons, and the last layer outputs the vector of 20 values. There were two models trained: one with left eyes images and one with right eyes images (further referred to as ARCH-LE and ARCH-RE).
3.4.2. Face Image as Neural Network Input
The neural network architecture prepared for the second experiment takes face images as its parameters. The schema of the architecture is shown in
Figure 6. The developed neural network was composed of five convolutional layers, three subsampling layers with filter size 3 × 3, and two fully connected layers FC1 and FC2. The information of the neural network layers is presented in
Table 1. The number of neurons of the fully connected layers was 4096 for FC1 and 1000 for FC2. This solution will be referred to as ARCH-F in the rest of the paper.
3.4.3. Both Eye Images as a Neural Network Input
For this experiment, a network architecture was prepared to accept left and right eye images as its input parameters. The schema is shown in
Figure 7. The neural network consists of three convolutional layers, one subsampling layer 2 × 2, one concatenation layer, and three fully connected layers. The fully connected layers consist of a layer for each input image, i.e., FC-LE1 and FC-RE1 with 1024 neurons, the concatenate layer, and two layers: FC1 with 2048 neurons and FC2 with 1024 neurons. The details of the convolutional layers of the neural network are presented in
Table 2. The output of the developed neural network architecture is a set of twenty points representing the position of the area on which the subject focuses his/her gaze. This solution will be referred to as ARCH-LRE.
All three presented network architectures are a little bit different in terms of topology. For instance, one eye image architecture contains only three convolutional layers, one subsampling layer, and one fully connected layer (
Figure 5). Face image architecture is more complicated and contains two sets of alternate convolutions and subsampling layers and then again three convolutional layers, one subsampling layer, and finally two fully connected layers (
Figure 6). For both eyes architecture (
Figure 7), the network has a similar architecture as one eye network, but the outputs from the left eye and right eye stacks are concatenated at the end and sent to two fully connected layers. All three architectures have a different number of parameters because they all have a different numbers of layers. The proposed architectures were chosen from a set of several possibilities that were initially studied. These networks are not generic, and the search for possible better architectures requires further studies.
4. Experiments and Results
This section presents a cross section of the research conducted and the results obtained. In the beginning, the methodology of the conducted research is presented, defining how the results were acquired. The following sections contain a description of each of the experiments conducted. The final section is a summary of the results obtained and conclusions of the research performed.
4.1. Research Methodology
The training set and the test set were determined automatically and randomly in a ratio of 70% for the training dataset and the remaining 30% for the test dataset. Numerically, this translates to approximately 4200 left and right eye and face images for the training set and the remaining 1800 images for the test set for Dataset 1.
Each neural network configuration was repeatedly changed in terms of architecture or hyperparameters and then retested. All experiments were performed on a laptop with Intel Core i7 and 16 GB RAM hardware specifications. The prediction quality was determined by the precision index built into the DeepLearning4j library calculated from the classification accuracy of the test set.
4.2. Results
This section presents the results of tests performed using the designed neural network architectures for the given data. The main goal of the conducted research was to find the optimal architecture capable of correctly classifying the gaze focus point. The resulting models, trained with training sets during the course of the experiments, were embedded in the specially designed EyeTracker application, allowing their performance to be tested in real-time.
Each experiment was conducted on two datasets. The first (denoted as D1) contained images acquired from one individual while the second (denoted as D2) contained images collected from four individuals, and one individual performed the test twice with contact lenses and with glasses, as mentioned in
Section 3.3. Every network architecture was trained up to 70 epochs.
The first test was aimed at checking if the model will work better after specific preprocessing. The first subset consisted of original grayscale images, and the second of the images was additionally sharpened by using an algorithm available in the OpenCV library. This experiment was performed based on images from the dataset containing data collected from one person (D1) and using ARCH-LRE architecture. The results of the experiment are presented in
Table 3 (columns two and three).
The second experiment aimed at comparing the results for both datasets D1 and D2. Since the first experiment already proved that the network works better when sharpened images are used, only sharpened images from D2 were used. The results are presented in the last column of
Table 3.
The following experiment performed the neural network learning process using an architecture that takes entire face images as input parameters. The schema of the developed ARCH-F architecture used in this experiment is presented in
Section 3.4.2. The results of that experiment for Datasets 1 and 2 are presented in
Table 4.
The last two experiments aimed to check if it is possible to use images of only one eye and achieve results comparable to the more complicated network utilizing two eyes. The results of these experiments for left and right eyes and both datasets are presented in
Table 5.
4.3. Discussion
The experiments presented in
Section 4.2 show that it is possible to achieve decent eye-tracking results even for unconstrained environments and using low-quality web cameras. Of course, the results are far from perfect—we checked only if one of the 20 areas could be determined based on eye image—but this outcome may be sufficient for many human–computer interface (HCI) applications.
The first experiment proved that sharpening the acquired image has a positive impact on further classification (accuracy increased from 77% to 81%). Therefore, all following experiments used the sharpened versions of the images. Not surprisingly, the results for the Dataset 2 were worse than for Dataset 1 for every experiment. However, it is worth noticing that these results are also quite good and had between 72% and 80% accuracy depending on the architecture. It should be remembered that random guessing for 20 classes provides about 5% accuracy, so the results are noticeably better than random ones.
Interestingly, the best results (over 88% accuracy) were achieved for the architecture in which only images of the left eye were used (ARCH-L) (
Table 5). The main reason for this phenomenon probably was that the network that uses two eye images and concatenates layers (ARCH-RL) was more complicated than ARCH-L, and 70 epochs were not enough to train it sufficiently.
Another interesting finding was the good accuracy of the model that uses face images instead of eyes. The model obviously has more data to analyze, but a large percentage of this data is probably irrelevant. Due to more extensive input, this model was also more challenging to train; the training process lasted significantly longer than for other models. However, good results suggest that eye detection algorithms may be omitted in some applications.
5. Conclusions
In this study, a possibility to track a person’s gaze using an unmodified camera has been investigated. Since commercial eye tracking devices are expensive, their availability is limited. In this research, the low-cost eye-tracking method was proposed which can be easily used for standard desktop or laptop computers without needing any additional equipment. The state-of-the-art CNN network with unmodified webcams commonly available with computers was used. The images acquired from the unmodified cameras are low quality and very sensitive to changing light conditions. Therefore, it was a big challenge to achieve reasonable results. However, this study shows that when the CNN network is used with a carefully designed topology and tuned hyper-parameters, it is possible to achieve results that may be usable in practical applications in a real-world environment.
Although this study achieved some significant results, there are some limitations associated with this study as well. For instance, calculating the exact gaze point was not treated as the regression problem but simplified into classifying gaze point as belonging to one of 20 areas, which makes it difficult to compare with other methods. Furthermore, the number of participants and the amount of data were limited, while it is well known that deep learning networks work and generalize better when trained using huge datasets. Moreover, this study did not include any publicly available datasets to perform the benchmark on them.
In our future research investigations, we plan to address the limitations mentioned above. We will consider extending our dataset and testing our model by using publicly available datasets of eye positions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}