
Driver Fatigue Detection Based on Residual Channel Attention Network and Head Pose Estimation


Abstract
:Featured Application
Abstract
1. Introduction
- In this study, a new fatigue detection system is designed that calculates whether the driver is in the fatigue driving state based on the facial state and the head posture. The performance of the system is verified according to the existing and self-built datasets.
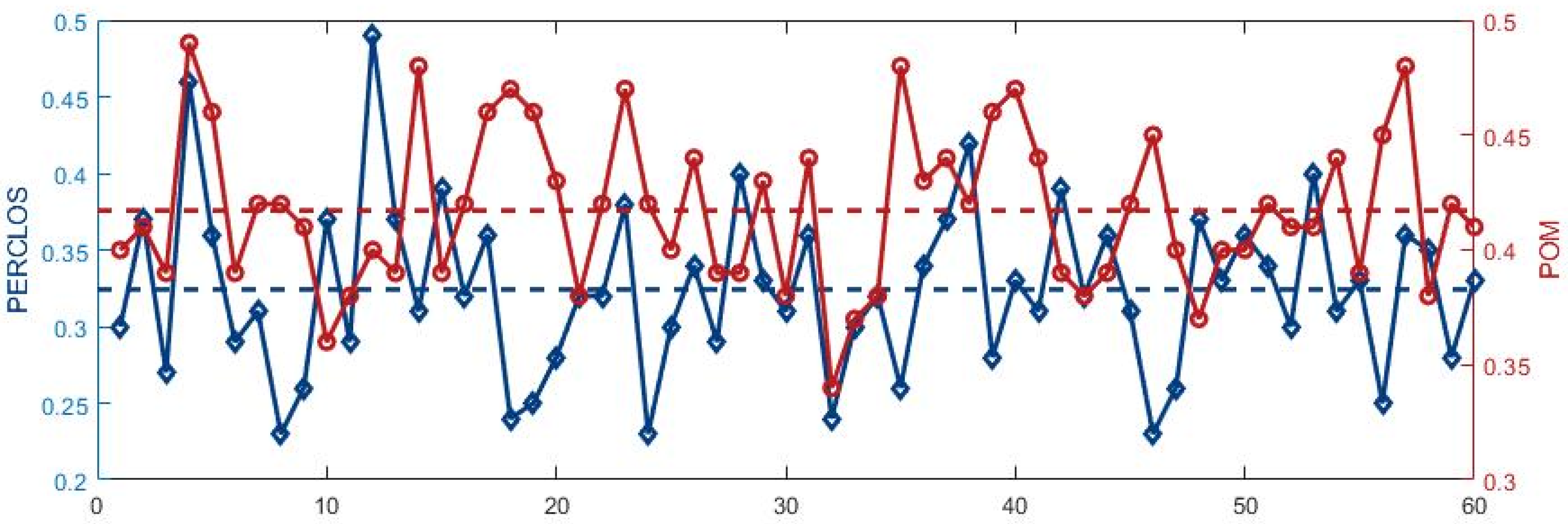
- In this study, the residual channel attention network (RCAN) is proposed to classify the states of eyes and the mouth, and a channel attention module is designed to be embedded in the RCAN. The attention module can adaptively extract the global semantic information of the image and significantly improve the accuracy of face state classification. Then PERCLOS and POM are used to evaluate whether the driver is in a fatigue state.
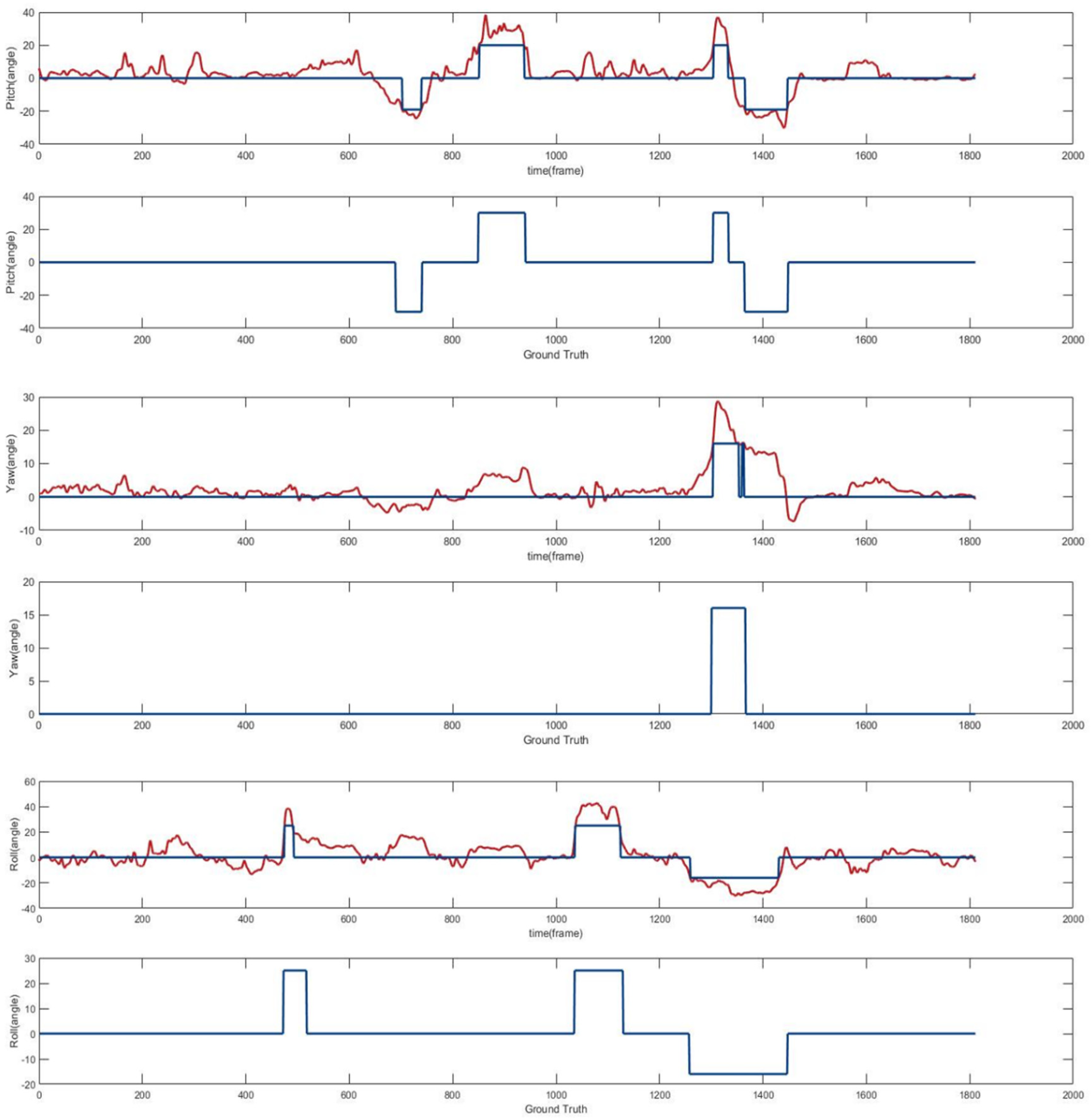
- The EPnP method is used to estimate the camera pose and then transform it into Euler angle of the head. This method only needs five landmark points of the face to estimate the Euler angle of the head pose. According to the self-built dataset, the rationality of head pose estimation as a supplement to driver fatigue detection is verified.
- The rest of this article is as follows. Section 2 introduces the methods related to driver fatigue detection used in recent years. Section 3 introduces the proposed driver fatigue detection system in detail. Section 4 declares the experiments and discusses the results. Section 5 concludes this article.
2. Related Works
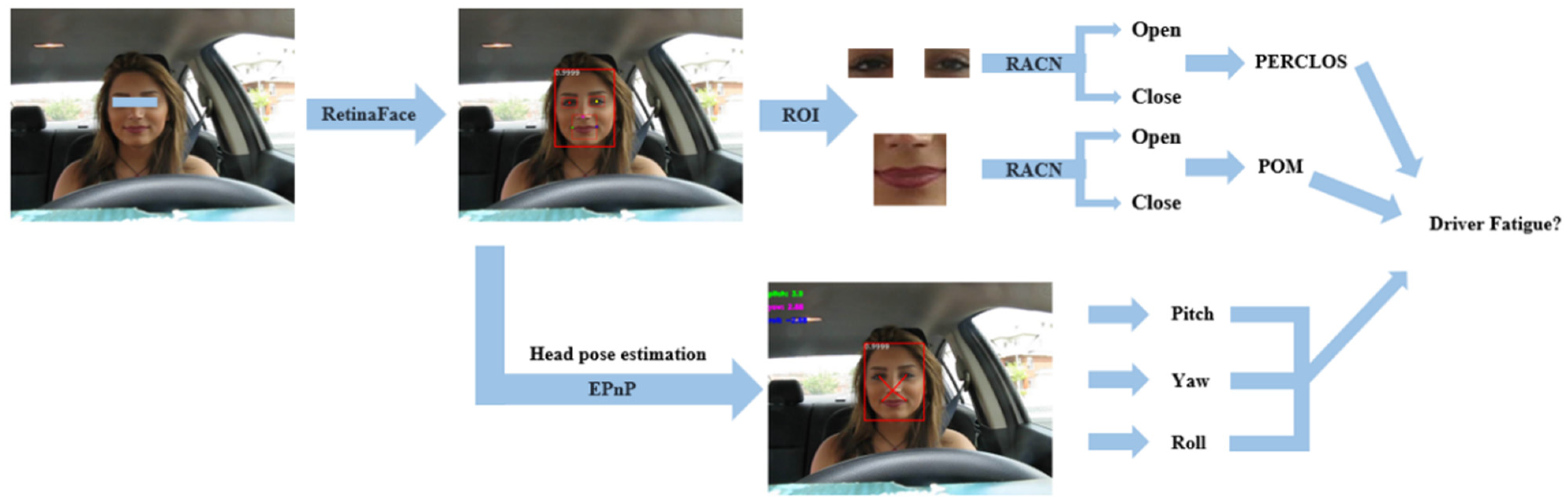
3. Materials and Methods
3.1. Facial State Recognition
3.2. Head Pose Estimation
3.3. Driver Fatigue Detection
3.3.1. PERCLOS
3.3.2. POM
3.3.3. Head Pose Angle
3.3.4. Driver Fatigue Detection
4. Experiments and Results
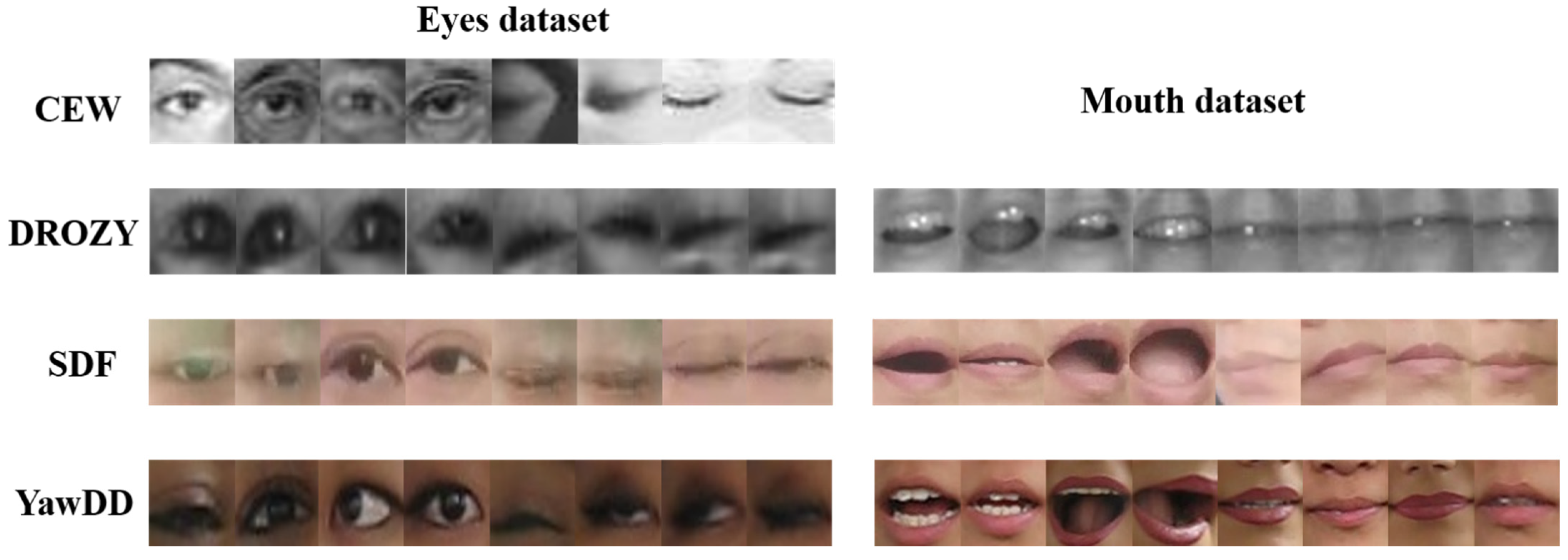
4.1. Dataset
4.2. Implementation Details
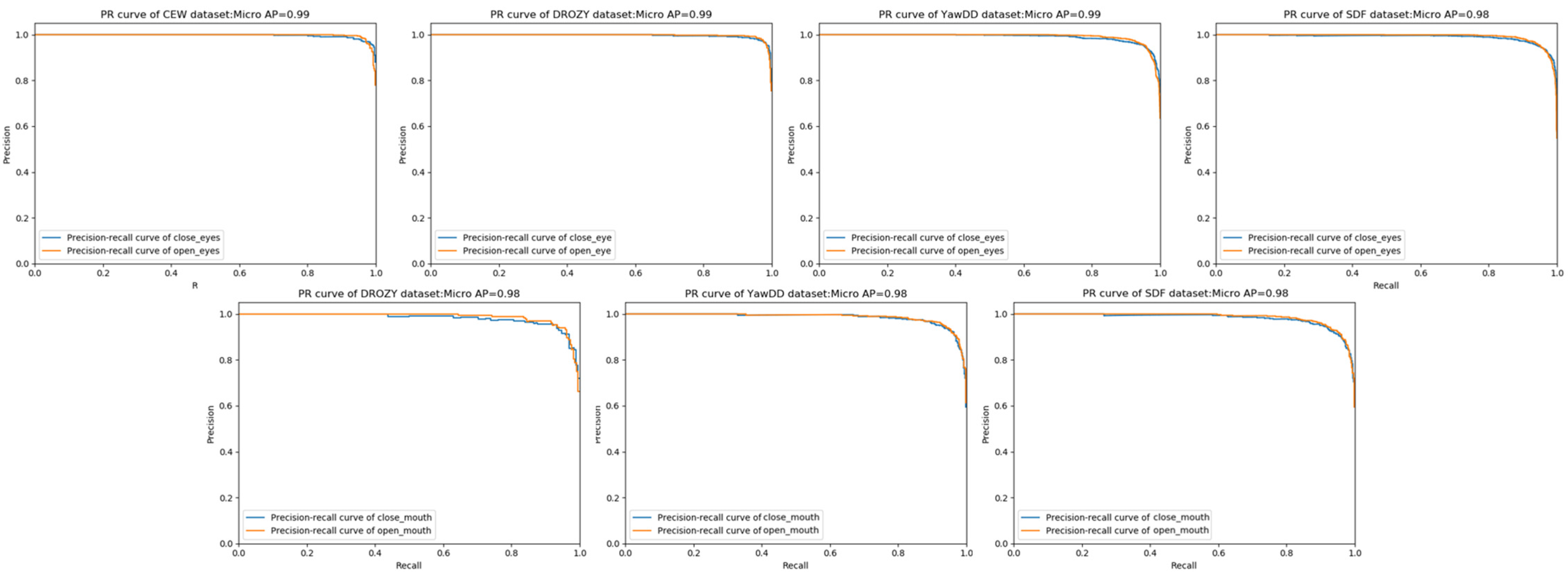
4.3. Performance of the RCAN
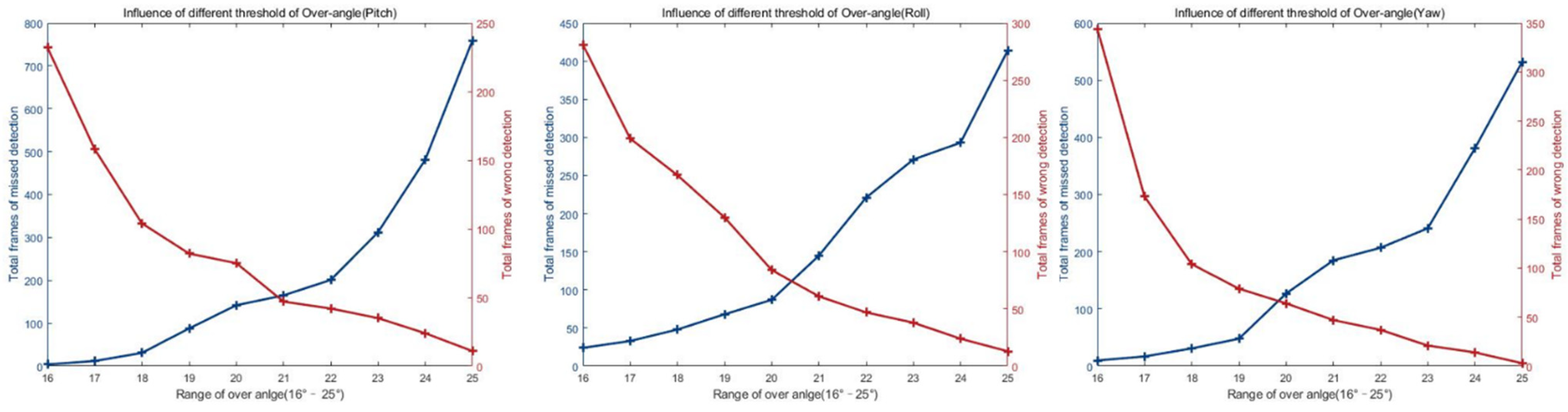
4.4. Selection of the Over-Angle
4.5. Fatigue State Recognition
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Koesdwiady, A.; Soua, R.; Karray, F.; Kamel, M.S. Recent Trends in Driver Safety Monitoring Systems: State of the Art and Challenges. IEEE Trans. Veh. Technol. 2016, 66, 4550–4563. [Google Scholar] [CrossRef]
- Chai, M.; Li, S.W.; Sun, W.C.; Guo, M.Z.; Huang, M.Y. Drowsiness monitoring based on steering wheel status. Transp. Res. Part D Transp. Environ. 2019, 66, 95–103. [Google Scholar] [CrossRef]
- Lawoyin, S. Novel Technologies for the Detection and Mitigation of Drowsy Driving. Bachelor’s Thesis and Diploma Thesis, Virginia Commonwealth University, Richmond, VA, USA, 2014. [Google Scholar]
- Tango, F.; Botta, M. Real-time detection system of driver distraction using machine learning. IEEE Trans. Intell. Transp. Syst. 2013, 14, 894–905. [Google Scholar] [CrossRef] [Green Version]
- Min, J.; Xiong, C.; Zhang, Y.; Cai, M. Driver fatigue detection based on prefrontal EEG using multi-entropy measures and hybrid model. Biomed. Signal Process. Control 2021, 69, 102857. [Google Scholar] [CrossRef]
- Zhang, G.; Etemad, A. Capsule Attention for Multimodal EEG-EOG Representation Learning with Application to Driver Vigilance Estimation. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1. [Google Scholar] [CrossRef]
- Satti, A.T.; Kim, J.; Yi, E.; Cho, H.Y.; Cho, S. Microneedle array electrode-based wearable EMG system for detection of driver drowsiness through steering wheel grip. Sensors 2021, 21, 5091. [Google Scholar] [CrossRef]
- Zhao, Z.; Xia, S.; Xu, X.; Zhang, L.; Yan, H.; Xu, Y.; Zhang, Z. Driver Distraction Detection Method Based on Continuous Head Pose Estimation. Comput. Intell. Neurosci. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vision 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-Stage Dense Face Localisation in the Wild. arXiv 2019, arXiv:1905.00641. Available online: https://arxiv.org/abs/1905.00641 (accessed on 6 September 2021).
- Benoit, A.; Caplier, A. Fusing bio-inspired vision data for simplified high level scene interpretation: Application to face motion analysis. Comput. Vis. Image Underst. 2010, 114, 774–789. [Google Scholar] [CrossRef]
- Bakheet, S.; Al-Hamadi, A. A framework for instantaneous driver drowsiness detection based on improved hog features and naïve Bayesian classification. Brain Sci. 2021, 11, 240. [Google Scholar] [CrossRef]
- Akrout, B.; Mahdi, W. A novel approach for driver fatigue detection based on visual characteristics analysis. J. Ambient. Intell. Humaniz. Comput. 2021, 1–26. [Google Scholar] [CrossRef]
- Gu, W.H.; Zhu, Y.; Chen, X.D.; He, L.F.; Zheng, B.B. Hierarchical CNN-based real-time fatigue detection system by visual-based technologies using MSP model. IET Image Process. 2018, 12, 2319–2329. [Google Scholar] [CrossRef]
- Ji, Y.; Wang, S.; Zhao, Y.; Wei, J.; Lu, Y. Fatigue State Detection Based on Multi-Index Fusion and State Recognition Network. IEEE Access 2019, 7, 64136–64147. [Google Scholar] [CrossRef]
- Zhao, G.; He, Y.; Yang, H.; Tao, Y. Research on fatigue detection based on visual features. IET Image Process. 2021. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ruiz, N.; Chong, E.; Rehg, J.M. Fine-grained head pose estimation without keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2074–2083. [Google Scholar]
- Abate, A.F.; Barra, P.; Pero, C.; Tucci, M. Head pose estimation by regression algorithm. Pattern Recognit. Lett. 2020, 140, 179–185. [Google Scholar] [CrossRef]
- Abate, A.F.; Barra, P.; Pero, C.; Tucci, M. Partitioned iterated function systems by regression models for head pose estimation. Mach. Vis. Appl. 2021, 32, 1–8. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An Accurate O(n) Solution to the PnP Problem. Int. J. Comput. Vis. 2008, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Wan, Y.; Xie, J. One algorithm of driver fatigue detecting based on PERCLOS. Agric Equip Technol. 2009, 35, 25–28. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. Int. Conf. Mach. Learn. 2019, 97, 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2016; 2014; pp. 1701–1708. [Google Scholar]
- Geng, L.; Yuan, F.; Xiao, Z.T. Driver fatigue detection method based on facial behavior analysis. Comput. Eng. 2018, 44, 274–279. [Google Scholar]
- Song, F.Y.; Tan, X.Y.; Liu, X.; Chen, S.C. Eyes closeness detection from still images with multi-scale histograms of principal oriented gradients. Pattern Recognit. 2014, 47, 2825–2838. [Google Scholar] [CrossRef]
- Massoz, Q.; Langohr, T.; Francois, C.; Verly, J.G. The ULg multimodality drowsiness database (called DROZY) and examples of use. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Abtahi, S.; Omidyeganeh, M.; Shirmohammadi, S.; Hariri, B. YawDD: A yawning detection dataset. In Proceedings of the 5th ACM Multimedia Systems Conference, New York, NY, USA, 19 March 2014; pp. 24–28. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 6 September 2021).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhao, Z.; Zhou, N.; Zhang, L.; Yan, H.; Xu, Y.; Zhang, Z. Driver Fatigue Detection Based on Convolutional Neural Networks Using EM-CNN. Comput. Intell. Neurosci. 2020, 2020, 1–11. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Size | Filters | Stride | Output |
|---|---|---|---|---|
| - | 1 × 1 | 16 | 1 | 56 × 56 × 16 |
| - | 1 × 1 | 16 | 1 | 56 × 56 × 16 |
| RCAB1 | 1 × 1, 3 × 3 | 32 | 1 | 56 × 56 × 32 |
| Max-Pooling | 2 × 2 | - | 2 | 28 × 28 × 32 |
| RCAB2 | 1 × 1, 3 × 3 | 64 | 1 | 28 × 28 × 64 |
| Max-Pooling | 2 × 2 | - | 2 | 14 × 14 × 64 |
| RCAB3 | 1 × 1, 3 × 3 | 128 | 1 | 14 × 14 × 128 |
| Max-Pooling | 2 × 2 | - | 2 | 7 × 7 × 128 |
| FC Layer1 | 512 | FC | - | 512 |
| FC Layer2 | 512 | FC | - | 2 |
| Softmax | 2 | Softmax | - | 2 |
| Dataset | Train (Eyes) | Test (Eyes) | Total | Train (Mouth) | Test (Mouth) | Total |
|---|---|---|---|---|---|---|
| CEW | 3877 | 969 | 4846 | × | × | × |
| Open | 1907 | 477 | 2384 | × | × | × |
| Close | 1970 | 492 | 2462 | × | × | × |
| YawDD | 4408 | 1102 | 5510 | 3940 | 985 | 4925 |
| Open | 2408 | 601 | 3009 | 2299 | 575 | 2874 |
| Close | 2000 | 501 | 2501 | 1641 | 410 | 2051 |
| DROZY | 3128 | 782 | 3910 | 1840 | 460 | 2300 |
| open | 1560 | 390 | 1950 | 898 | 224 | 1122 |
| Close | 1568 | 392 | 1960 | 942 | 236 | 1178 |
| SDF | 14,567 | 3642 | 18,209 | 7818 | 1954 | 9772 |
| Open | 7821 | 1956 | 9777 | 4123 | 1031 | 5154 |
| Close | 6746 | 1686 | 8432 | 3695 | 923 | 4618 |
| Dataset | Training Object | Test Data | Method | Accuracy (%) |
|---|---|---|---|---|
| SDF | Eyes | 3642 | ResNetXt-50 | 97.968 |
| InceptionV4 | 97.831 | |||
| EfficientNet | 98.325 | |||
| RCAN(no attention) | 96.541 | |||
| RCAN (CBAM) | 98.465 | |||
| RCAN | 98.962 | |||
| Mouth | 1954 | ResNetXt-50 | 97.595 | |
| InceptionV4 | 97.697 | |||
| EfficientNet | 98.464 | |||
| RCAN (no attention) | 94.417 | |||
| RCAN(CBAM) | 98.327 | |||
| RCAN | 98.516 | |||
| DROZY | Eyes | 782 | ResNetXt-50 | 98.593 |
| InceptionV4 | 98.977 | |||
| EfficientNet | 98.721 | |||
| RCAN (no attention) | 98.082 | |||
| RCAN (CBAM) | 98.593 | |||
| RCAN | 99.233 | |||
| Mouth | 460 | ResNetXt-50 | 97.609 | |
| InceptionV4 | 97.391 | |||
| EfficientNet | 98.043 | |||
| RCAN (no attention) | 96.304 | |||
| RCAN (CBAM) | 98.261 | |||
| RCAN | 98.478 | |||
| YawDD | Eyes | 1102 | ResNetXt-50 | 98.457 |
| InceptionV4 | 98.276 | |||
| EfficientNet | 98.548 | |||
| RCAN (no attention) | 95.531 | |||
| RCAN (CBAM) | 98.557 | |||
| RCAN | 99.002 | |||
| Mouth | 985 | ResNetXt-50 | 98.172 | |
| InceptionV4 | 98.477 | |||
| EfficientNet | 98.782 | |||
| RCAN (no attention) | 94.188 | |||
| RCAN(CBAM) | 98.438 | |||
| RCAN | 98.678 | |||
| CEW | Eyes | 969 | ResNetXt-50 | 98.555 |
| Inception | 98.967 | |||
| EfficientNet | 98.762 | |||
| RCAN (no attention) | 97.751 | |||
| RCAN(CBAM) | 98.967 |
| Dataset | Type | P (%) | R (%) | F-Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| CEW | 99.278 | ||||
| Eye data | Open eyes | 99.370 | 99.161 | 99.265 | |
| Closed eyes | 99.189 | 99.39 | 99.289 | ||
| DROZY (eyes) | 99.233 | ||||
| Eye data | Open eyes | 99.458 | 98.974 | 99.229 | |
| Closed eyes | 98.985 | 99.490 | 99.237 | ||
| DROZY (mouth) | 98.478 | ||||
| Mouth data | Open mouth | 98.655 | 98.214 | 98.434 | |
| Closed mouth | 98.312 | 98.729 | 98.520 | ||
| YawDD (eyes) | 99.002 | ||||
| Eye data | Open eyes | 99.167 | 99.002 | 99.084 | |
| Closed eyes | 98.805 | 99.002 | 98.903 | ||
| YawDD (mouth) | 98.678 | ||||
| Mouth data | Open mouth | 98.780 | 98.953 | 98.867 | |
| Closed mouth | 98.533 | 98.293 | 98.413 | ||
| SDF (eyes) | 98.962 | ||||
| Eye data | Open eyes | 99.084 | 98.983 | 99.034 | |
| Closed eyes | 98.820 | 98.937 | 98.878 | ||
| SDF (mouth) | 98.516 | ||||
| Mouth data | Open mouth | 98.735 | 98.448 | 98.592 | |
| Closed mouth | 98.272 | 98.592 | 98.432 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, M.; Zhang, W.; Cao, P.; Liu, K. Driver Fatigue Detection Based on Residual Channel Attention Network and Head Pose Estimation. Appl. Sci. 2021, 11, 9195. https://doi.org/10.3390/app11199195
Ye M, Zhang W, Cao P, Liu K. Driver Fatigue Detection Based on Residual Channel Attention Network and Head Pose Estimation. Applied Sciences. 2021; 11(19):9195. https://doi.org/10.3390/app11199195
Chicago/Turabian StyleYe, Mu, Weiwei Zhang, Pengcheng Cao, and Kangan Liu. 2021. "Driver Fatigue Detection Based on Residual Channel Attention Network and Head Pose Estimation" Applied Sciences 11, no. 19: 9195. https://doi.org/10.3390/app11199195
APA StyleYe, M., Zhang, W., Cao, P., & Liu, K. (2021). Driver Fatigue Detection Based on Residual Channel Attention Network and Head Pose Estimation. Applied Sciences, 11(19), 9195. https://doi.org/10.3390/app11199195