
A Shallow–Deep Feature Fusion Method for Pedestrian Detection

Abstract
:1. Introduction
2. Related Work
2.1. Pedestrian Detection via Sliding Window
2.2. Region Proposal via Pedestrian Detection
3. The Proposed Work
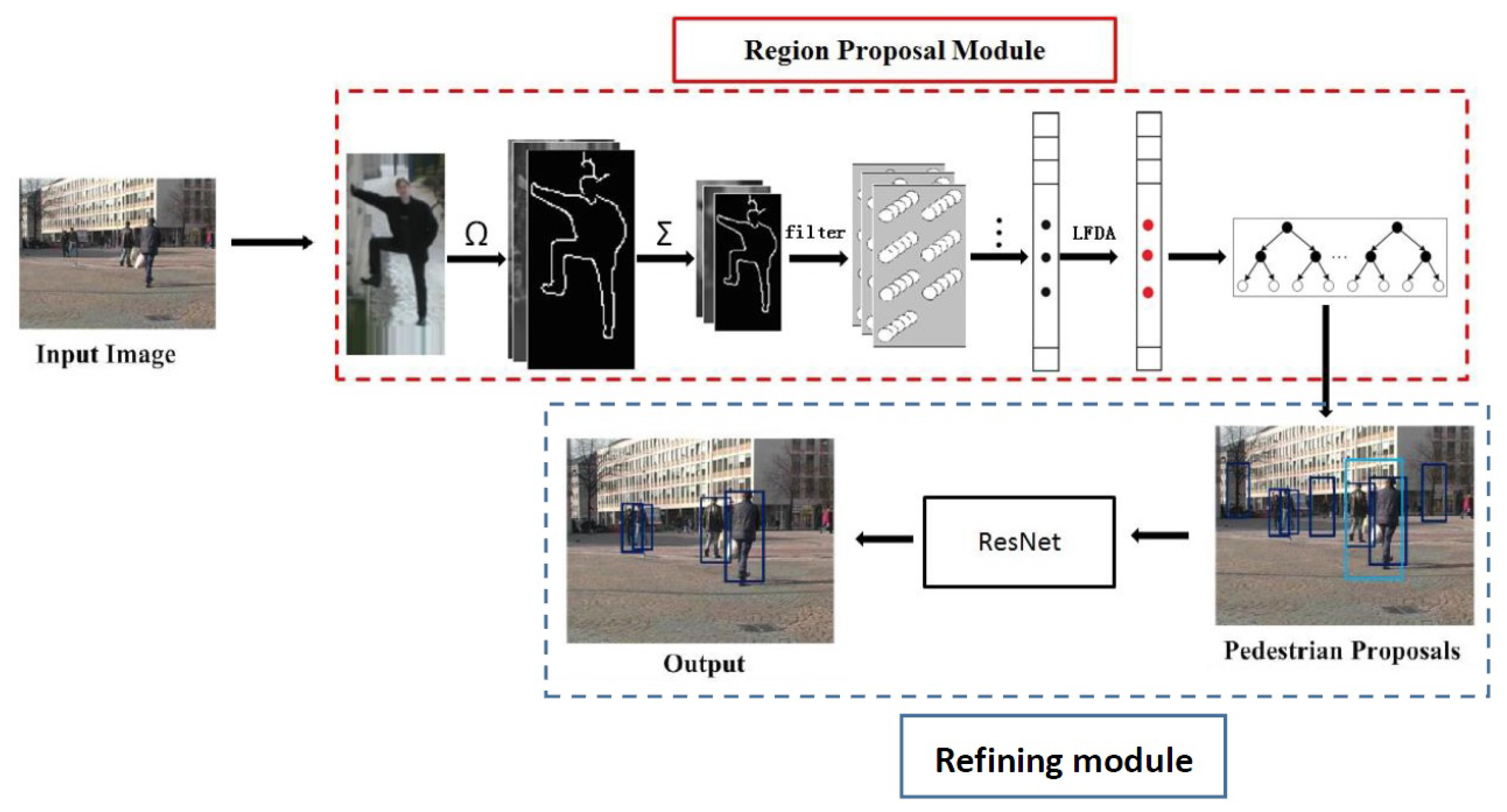
3.1. The Proposed Pedestrian Detection Framework
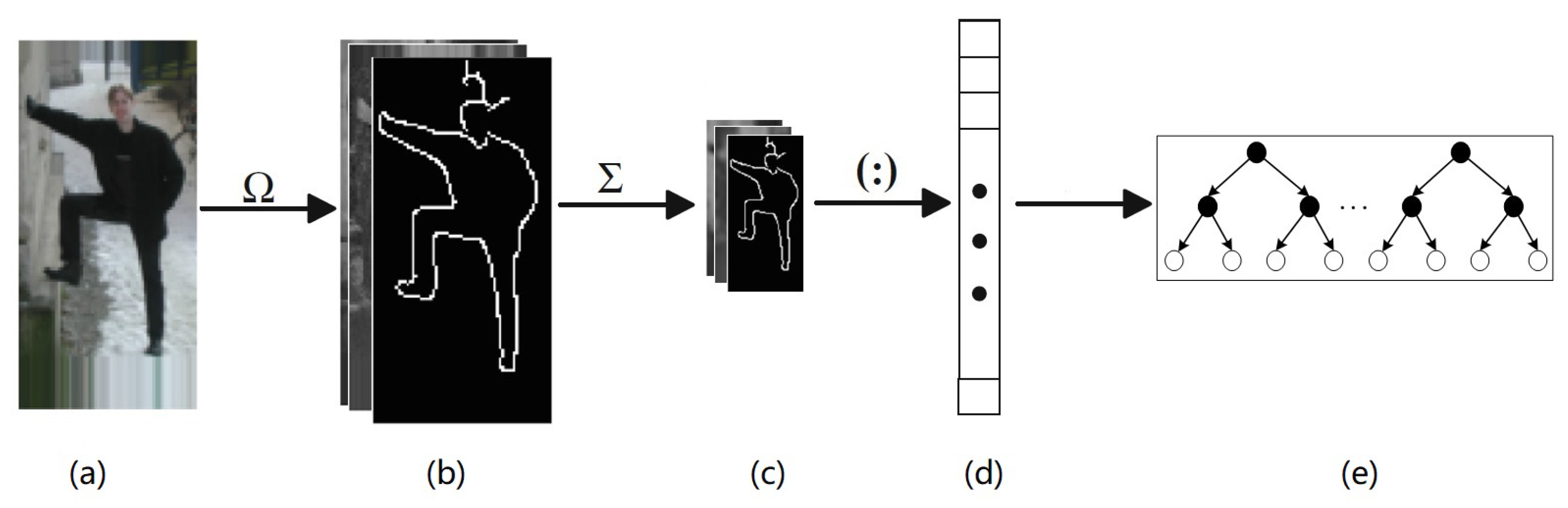
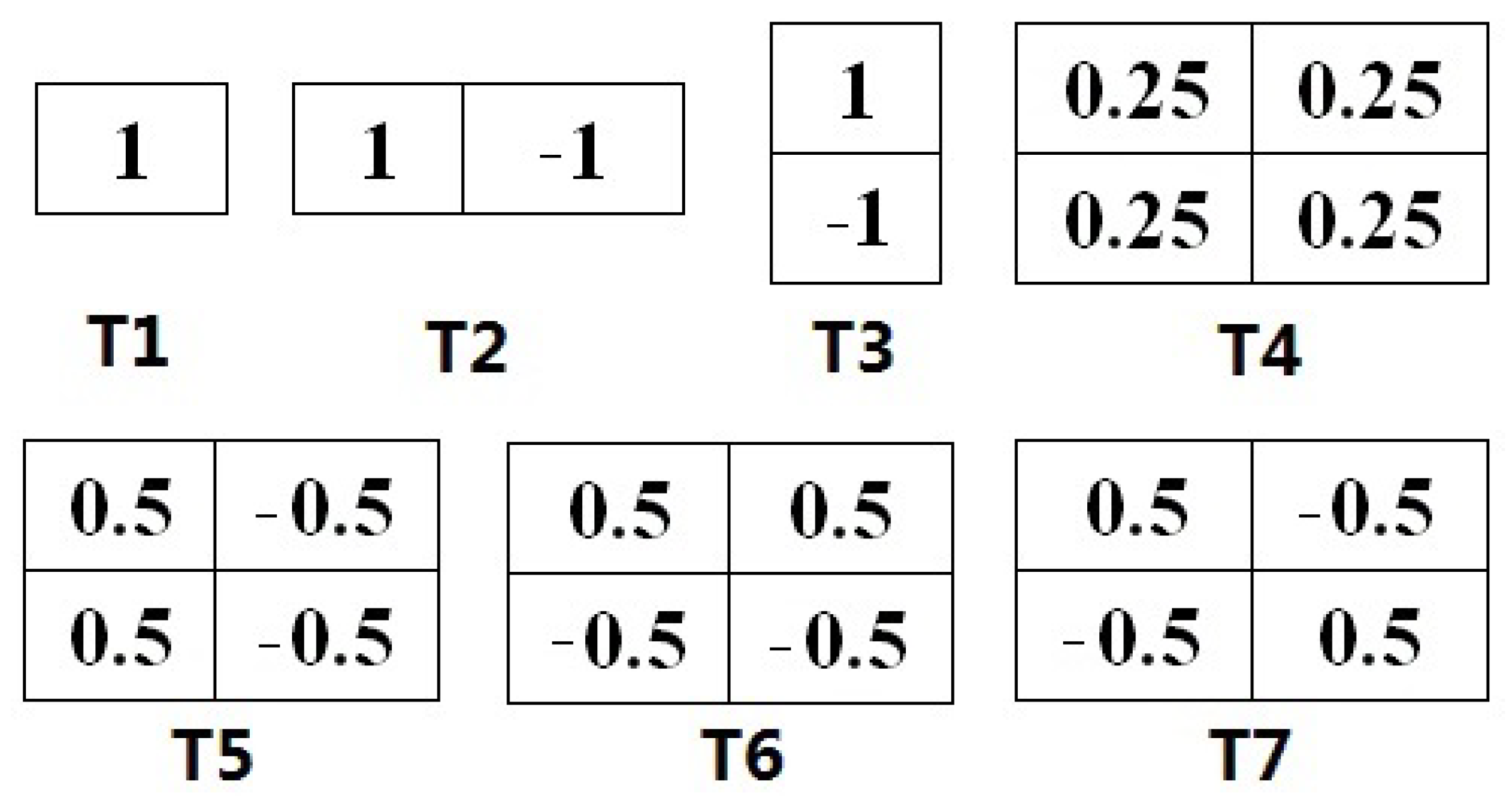
3.2. Shallow Feature-Region Proposal Generation
3.3. Deep Feature Based Pedestrian Refining
4. Experiments
4.1. The Dataset and Setup
4.2. Discussion on Pedestrian Proposals
4.3. Experimental Results
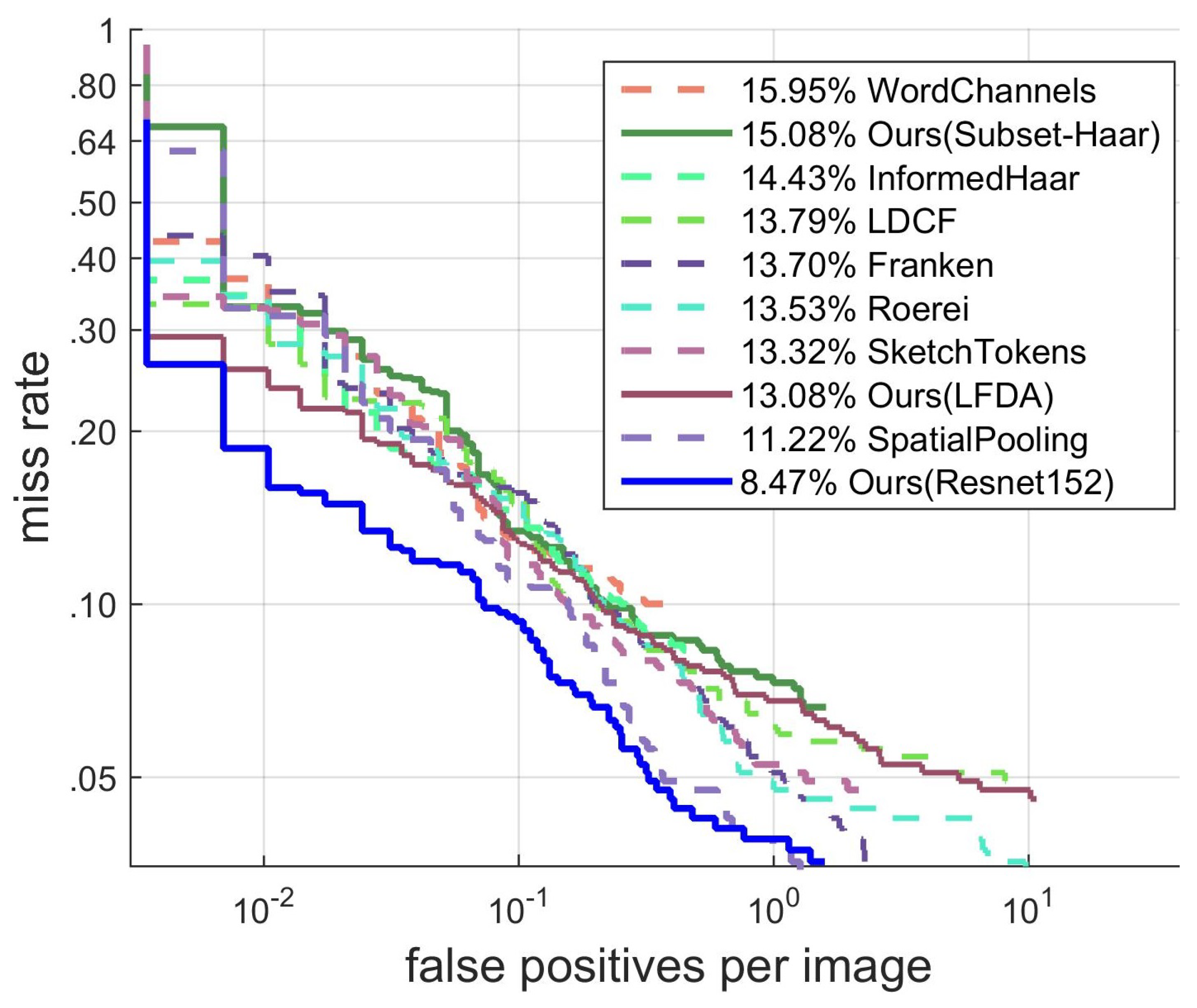
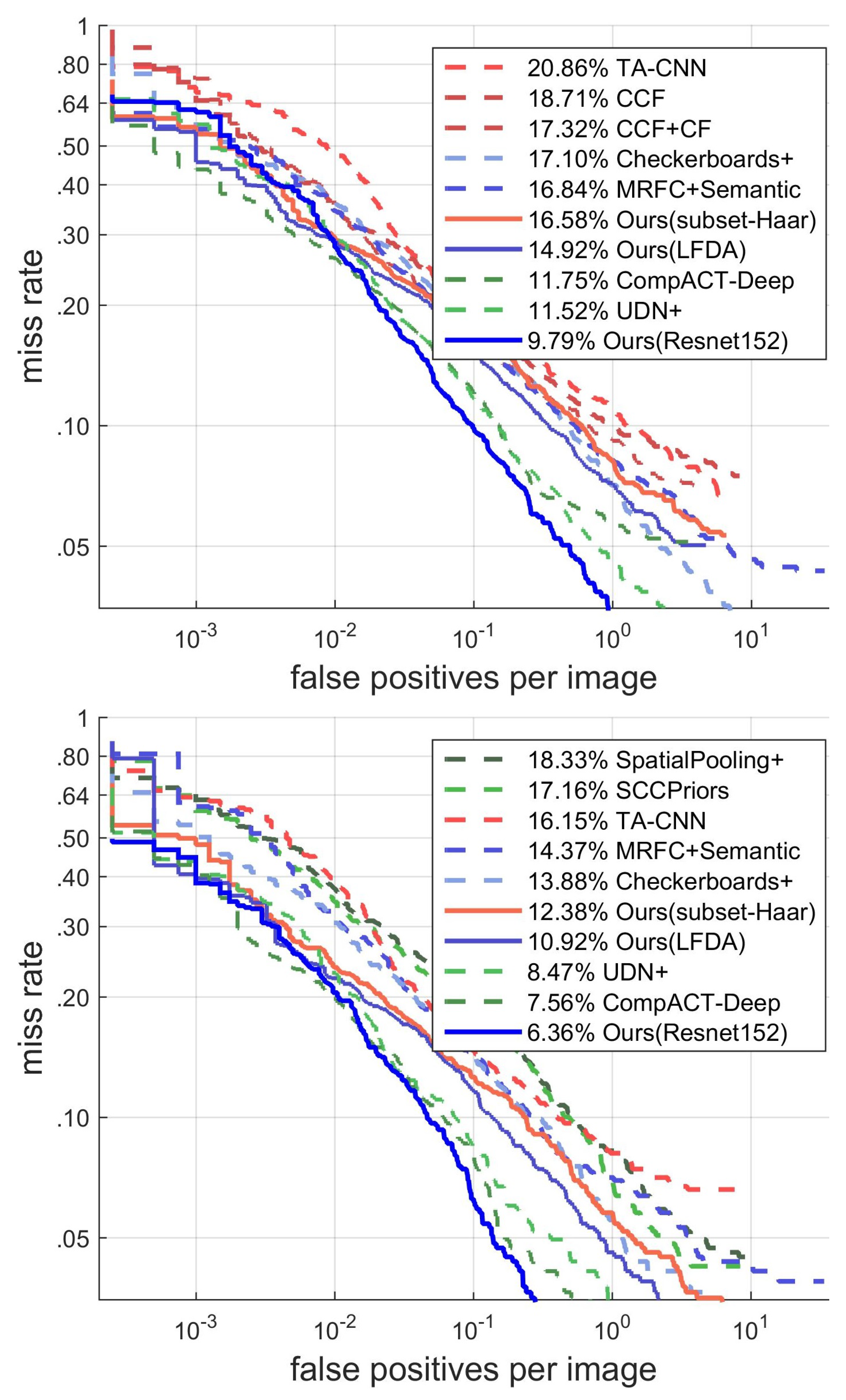
4.3.1. Results on INRIA Dataset
4.3.2. Results on Caltech Dataset
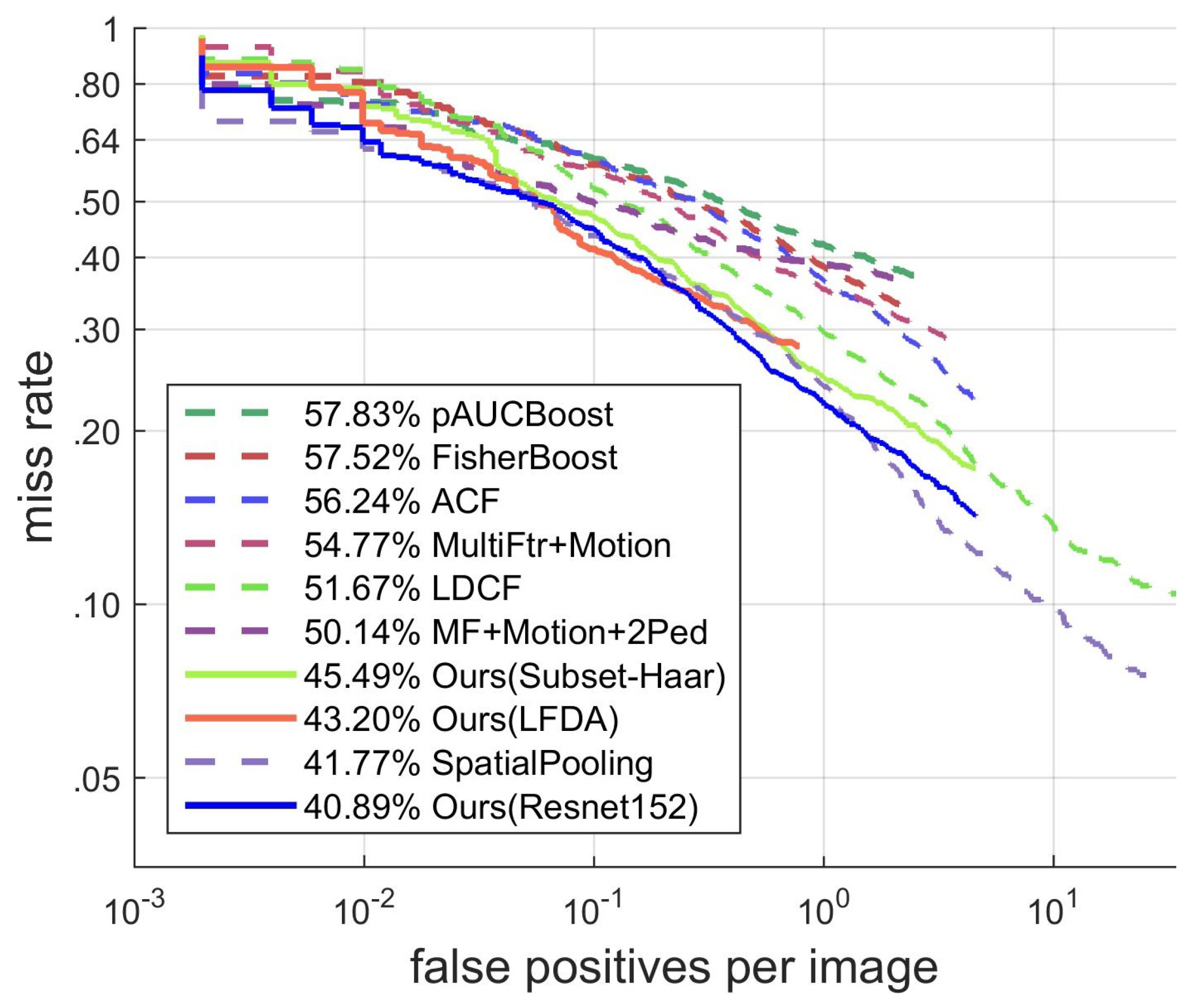
4.3.3. Results on the TUD-Brussel dataset
4.3.4. Comparison with FRCNN, YOLOV4 and SSD
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Generalizable Pedestrian Detection: The Elephant in the Room. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 21–24 June 2021; pp. 11328–11337. [Google Scholar]
- Lima, J.P.; Roberto, R.; Figueiredo, L.; Simoes, F.; Teichrieb, V. Generalizable Multi-Camera 3D Pedestrian Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 21–24 June 2021; pp. 1232–1240. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Brunetti, A.; Buongiorno, D.; Trotta, G.F.; Bevilacqua, V. Computer vision and deep learning techniques for pedestrian detection and tracking: A survey. Neurocomputing 2018, 300, 17–33. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; McAllester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; Volume 2, p. 7. [Google Scholar]
- Zang, K.; Shen, J.; Yang, W. Using LFDA to Learn Subset-Haar-Like Intermediate Feature Weights for Pedestrian Detection. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Dalian, China, 22–23 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 215–230. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Oren, M.; Papageorgiou, C.; Sinha, P.; Osuna, E.; Poggio, T. Pedestrian detection using wavelet templates. In Proceedings of the Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; Volume 97, pp. 193–199. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Zhao, K.; Deng, J.; Cheng, D. Real-time moving pedestrian detection using contour features. Multimed. Tools Appl. 2018, 77, 30891–30910. [Google Scholar] [CrossRef]
- Zhu, Q.; Yeh, M.C.; Cheng, K.T.; Avidan, S. Fast human detection using a cascade of histograms of oriented gradients. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1491–1498. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar]
- Bourdev, L.; Malik, J. Poselets: Body part detectors trained using 3d human pose annotations. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1365–1372. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S. Integral Channel Features. In Proceedings of the British Machine Conference, London, UK, 7–10 September 2009; pp. 91.1–91.11. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Filtered channel features for pedestrian detection. CVPR 2015, 1, 4. [Google Scholar]
- Nam, W.; Dollár, P.; Han, J.H. Local decorrelation for improved pedestrian detection. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 424–432. [Google Scholar]
- Shen, J.; Zuo, X.; Li, J.; Yang, W.; Ling, H. A novel pixel neighborhood differential statistic feature for pedestrian and face detection. Pattern Recognit. 2017, 63, 127–138. [Google Scholar] [CrossRef]
- You, M.; Zhang, Y.; Shen, C.; Zhang, X. An extended filtered channel framework for pedestrian detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1640–1651. [Google Scholar] [CrossRef]
- Ouyang, W.; Zeng, X.; Wang, X. Modeling mutual visibility relationship in pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3222–3229. [Google Scholar]
- Daniel Costea, A.; Nedevschi, S. Semantic channels for fast pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2360–2368. [Google Scholar]
- Sheng, B.; Hu, Q.; Li, J.; Yang, W.; Zhang, B.; Sun, C. Filtered shallow-deep feature channels for pedestrian detection. Neurocomputing 2017, 249, 19–27. [Google Scholar] [CrossRef]
- Park, D.; Zitnick, C.L.; Ramanan, D.; Dollár, P. Exploring weak stabilization for motion feature extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2882–2889. [Google Scholar]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 391–405. [Google Scholar]
- Van de Sande, K.E.; Uijlings, J.R.; Gevers, T.; Smeulders, A.W. Segmentation as selective search for object recognition. ICCV 2011, 1, 7. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the objectness of image windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Cheng, B.; Wei, Y.; Shi, H.; Feris, R.S.; Xiong, J.; Huang, T.S. Revisiting RCNN: On Awakening the Classification Power of Faster RCNN. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster r-cnn doing well for pedestrian detection? In Proceedings of the European Conference on Computer Visio, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–457. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Sugiyama, M. Dimensionality reduction of multimodal labeled data by local fisher discriminant analysis. J. Mach. Learn. Res. 2007, 8, 1027–1061. [Google Scholar]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 11–14 October 2016; pp. 1259–1267. [Google Scholar]
- INRIA Person Dataset. Available online: http://pascal.inrialpes.fr/data/human/ (accessed on 30 September 2021).
- Caltech Pedestrian Detection Benchmark. Available online: http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/ (accessed on 30 September 2021).
- Wojek, C.; Walk, S.; Schiele, B. Multi-cue onboard pedestrian detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 794–801. [Google Scholar]
- Piotr’s Computer Vision Matlab Toolbox. Available online: http://pdollar.github.io/toolbox/ (accessed on 30 September 2021).
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE TPAMI 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed Haar-Like Features Improve Pedestrian Detection. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar]
- Mathias, M.; Benenson, R.; Timofte, R.; Gool, L.V. Handling Occlusions with Franken-Classifiers. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1505–1512. [Google Scholar]
- Lim, J.J.; Zitnick, C.L.; Dollár, P. Sketch Tokens: A Learned Mid-level Representation for Contour and Object Detection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Sydney, Australia, 1–8 December 2013; pp. 3158–3165. [Google Scholar]
- Paisitkriangkrai, S.; Shen, C.; van den Hengel, A. Pedestrian Detection with Spatially Pooled Features and Structured Ensemble Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1243–1257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ouyang, W.; Zhou, H.; Li, H.; Li, Q.; Yan, J.; Wang, X. Jointly Learning Deep Features, Deformable Parts, Occlusion and Classification for Pedestrian Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1874–1887. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Convolutional Channel Features. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 82–90. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Pedestrian detection aided by deep learning semantic tasks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Santiago, Chile, 7–13 December 2015; pp. 5079–5087. [Google Scholar]
- Walk, S.; Majer, N.; Schindler, K.; Schiele, B. New features and insights for pedestrian detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1030–1037. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Template# | Feature Map Size | Feature Dimension |
|---|---|---|
| T1 | 32 × 16 | 512 |
| T2 | 32 × 15 | 480 |
| T3 | 31 × 16 | 496 |
| T4 | 31 × 15 | 465 |
| T5 | 31 × 15 | 465 |
| T6 | 31 × 15 | 465 |
| T7 | 31 × 15 | 465 |
| Total | / | 3348 |
| Method | MR [, ] |
|---|---|
| IOU-0.5-0.5 | 11.82 |
| IOU-0.5-0.5-16px | 10.45 |
| IOU-0.5-0.5-32px | 10.09 |
| IOU-0.6-0.4 | 10.29 |
| IOU-0.6-0.4-16px | 9.22 |
| IOU-0.6-0.4-32px | 10.05 |
| IOU-0.7-0.3 | 9.62 |
| IOU-0.7-0.3-16px | 8.6 |
| IOU-0.7-0.3-32px | 9.18 |
| IOU-0.8-0.2 | 12.95 |
| IOU-0.8-0.2-16px | 11.31 |
| IOU-0.8-0.2-32px | 12.05 |
| Datasets | Images | Proposals | Recall | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACF | HF | WHF | ACF | HF | WHF | ACF | HF | WHF | ||
| INRIA | 288 | 60,243 | 6221 | 5138 | 95.59% | 96.18% | 96.72% | 209.17 | 21.62 | 17.84 |
| Caltech | 4024 | 625,037 | 91,317 | 87,251 | 95.40% | 96.54% | 97.38% | 155.32 | 22.69 | 21.68 |
| Tud-Brussels | 508 | 16,818 | 5133 | 3816 | 86.38% | 87.82% | 88.32% | 33.11 | 10.12 | 7.51 |
| FRCNN + FPN | YOLOV4 | SSD512 | Ours | |
|---|---|---|---|---|
| INRIA | 11.82% | 12.77% | 19.25% | 8.47% |
| Caltech | 10.74% | 11.61% | 29.72% | 6.36% |
| Tud-Brussel | 48.70% | 50.83% | 54.44% | 40.89% |
| Method | FRCNN + FPN | YOLOV4 | SSD512 | Ours (P) | Ours (P + R) |
|---|---|---|---|---|---|
| Speed (FPS) | 15 | 46 | 22 | 32 | 21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Zang, K.; Shen, J. A Shallow–Deep Feature Fusion Method for Pedestrian Detection. Appl. Sci. 2021, 11, 9202. https://doi.org/10.3390/app11199202
Liu D, Zang K, Shen J. A Shallow–Deep Feature Fusion Method for Pedestrian Detection. Applied Sciences. 2021; 11(19):9202. https://doi.org/10.3390/app11199202
Chicago/Turabian StyleLiu, Daxue, Kai Zang, and Jifeng Shen. 2021. "A Shallow–Deep Feature Fusion Method for Pedestrian Detection" Applied Sciences 11, no. 19: 9202. https://doi.org/10.3390/app11199202
APA StyleLiu, D., Zang, K., & Shen, J. (2021). A Shallow–Deep Feature Fusion Method for Pedestrian Detection. Applied Sciences, 11(19), 9202. https://doi.org/10.3390/app11199202