
Phishing Webpage Classification via Deep Learning-Based Algorithms: An Empirical Study


 ,
,  , and
, and 
Abstract
:1. Introduction
- We exploited the state-of-the-art DL algorithms and compared their performance using numerous evaluation metrics;
- We identified the most common parameters and examined their influences on the performance of four DL models;
- We highlighted several issues based on the findings from the empirical experiments and recommended possible solutions to address these issues.
2. Literature Review
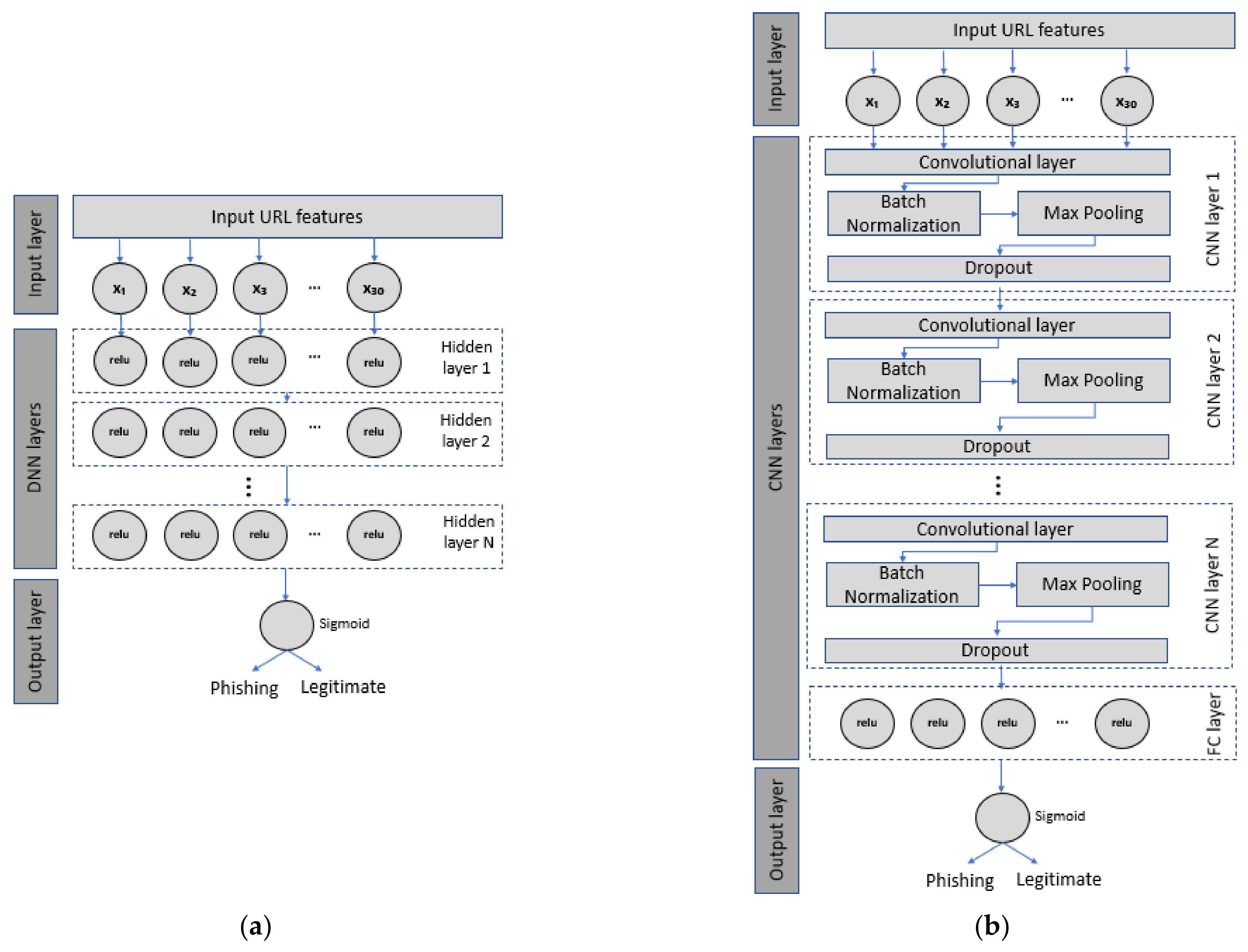
2.1. Deep Neural Network (DNN)
2.2. Convolutional Neural Network (CNN)
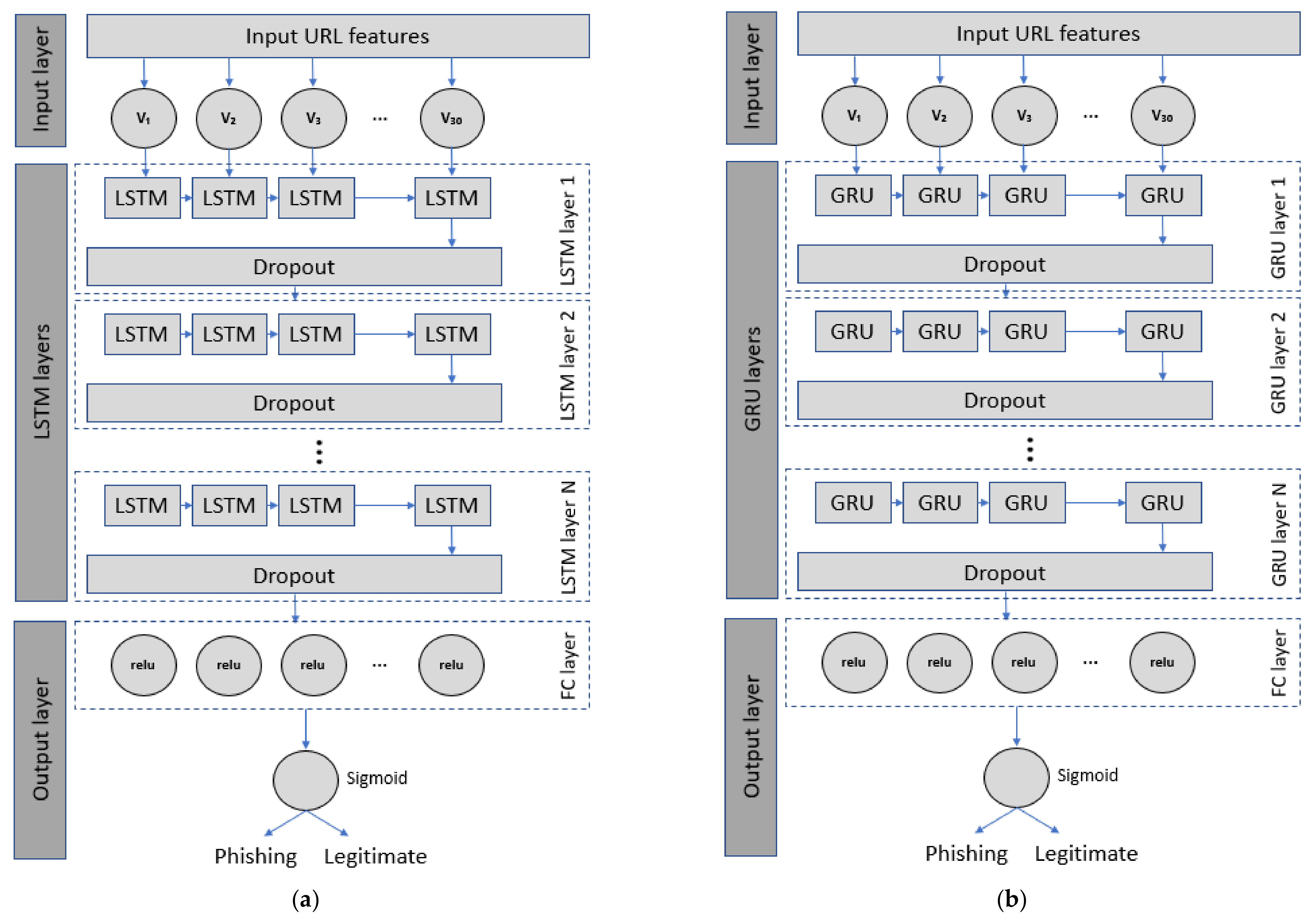
2.3. Long Short-Term Memory (LSTM)
2.4. Gated Recurrent Unit (GRU)
2.5. Hyper-Parameters
2.6. Performance Metrics
2.7. Research Novelty
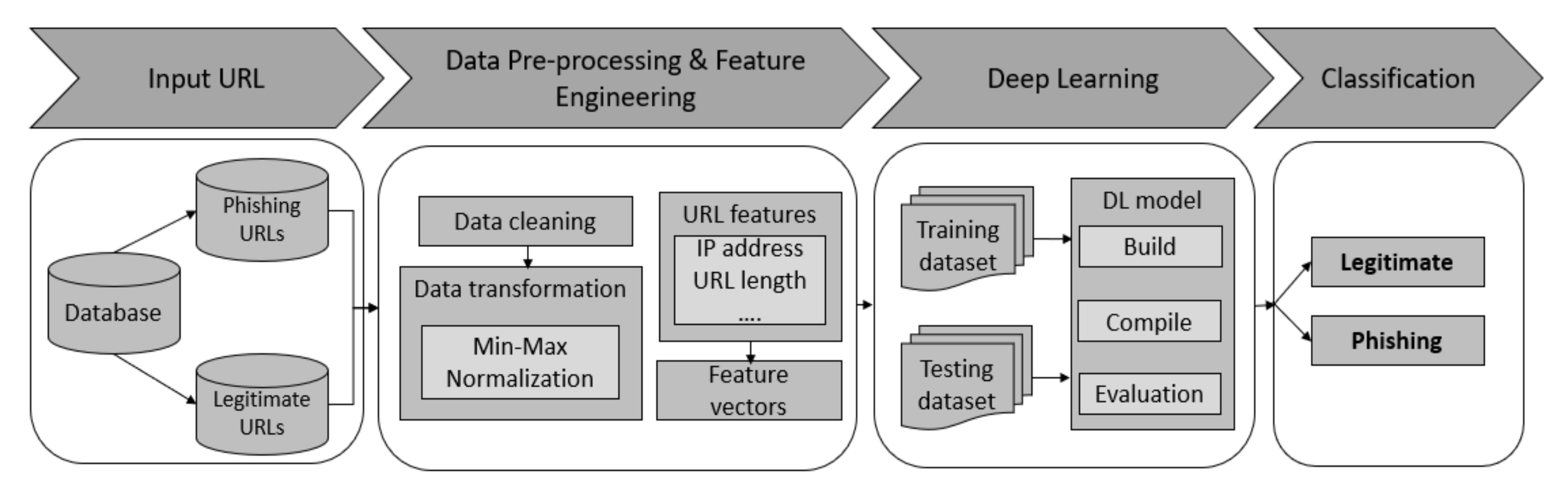
3. Research Methodology
3.1. Experiment Setup
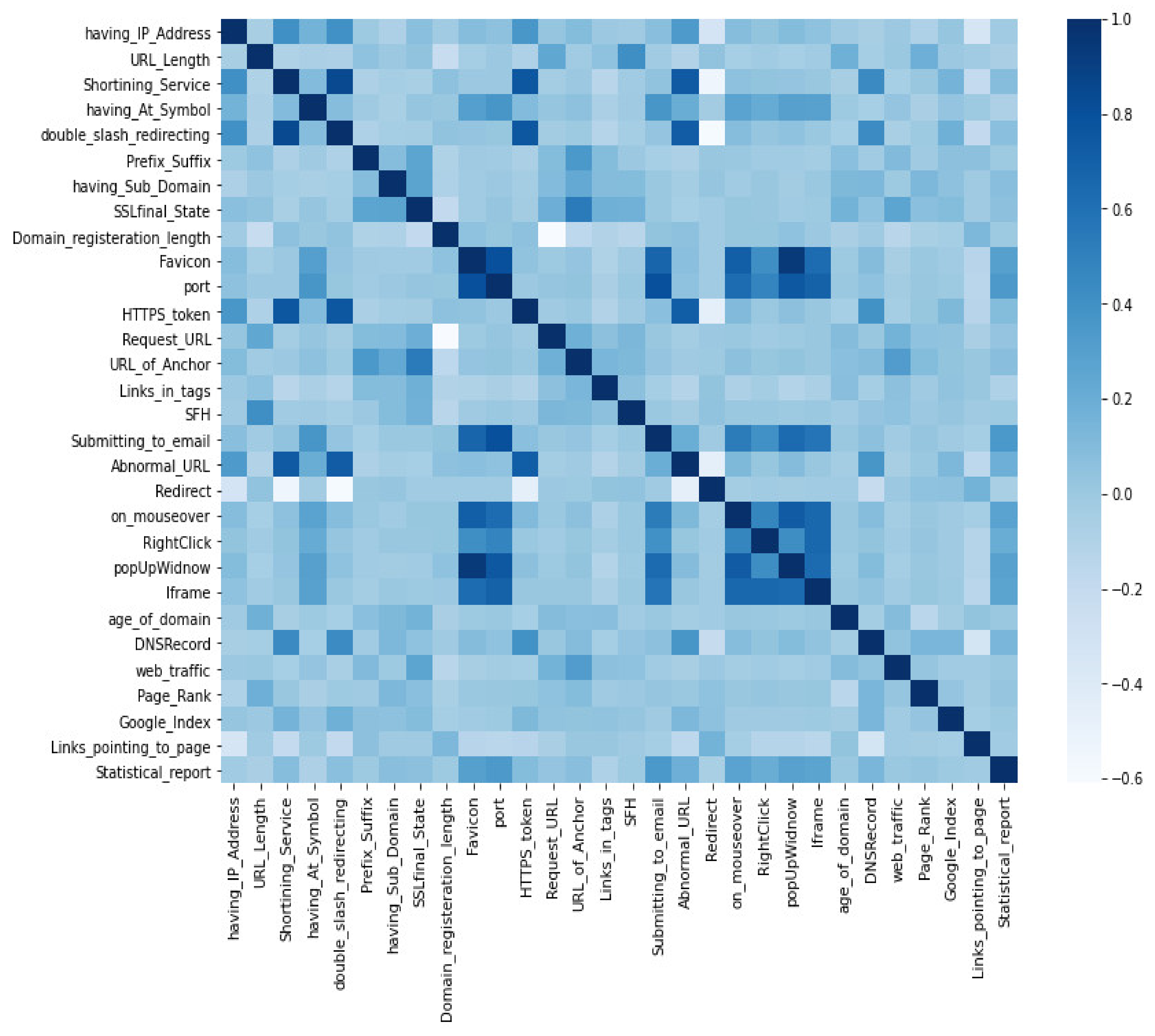
3.2. Website Features
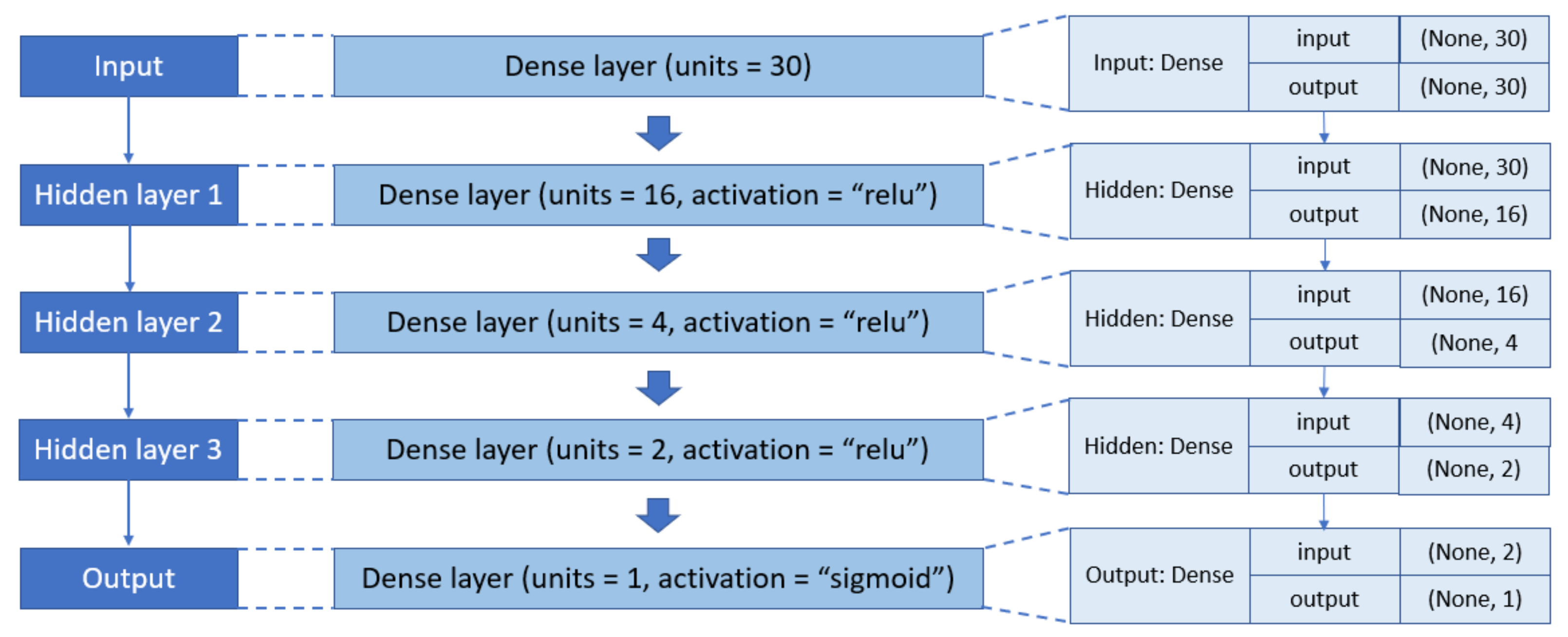
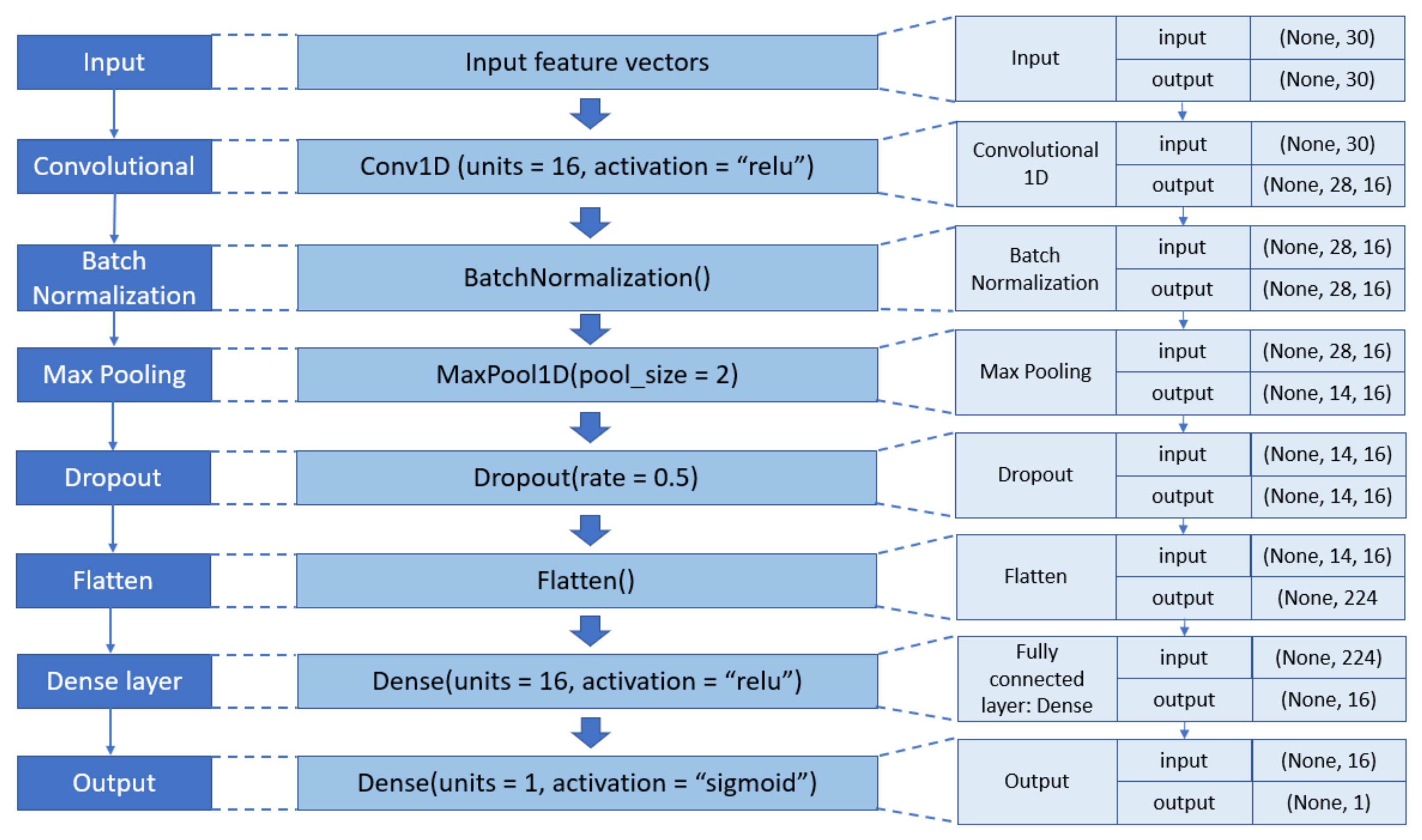
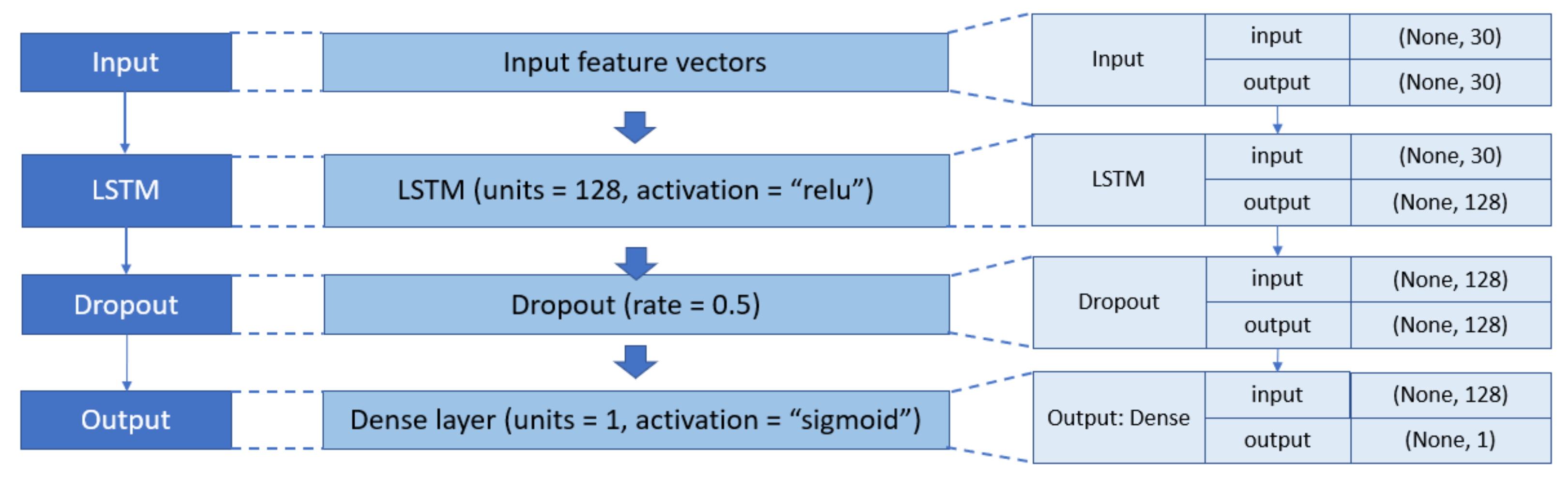
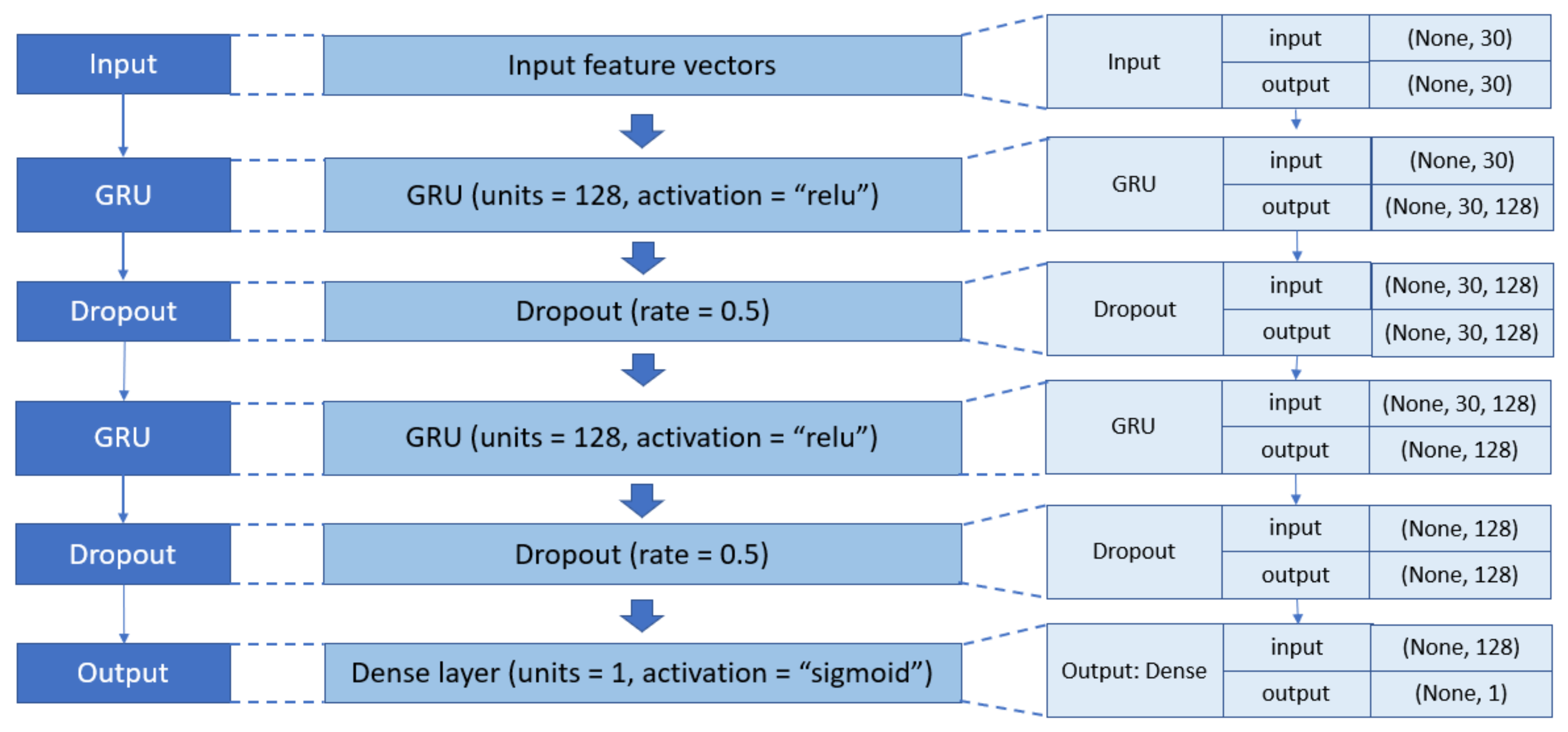
3.3. Deep Learning Models
3.4. Parameter Optimization
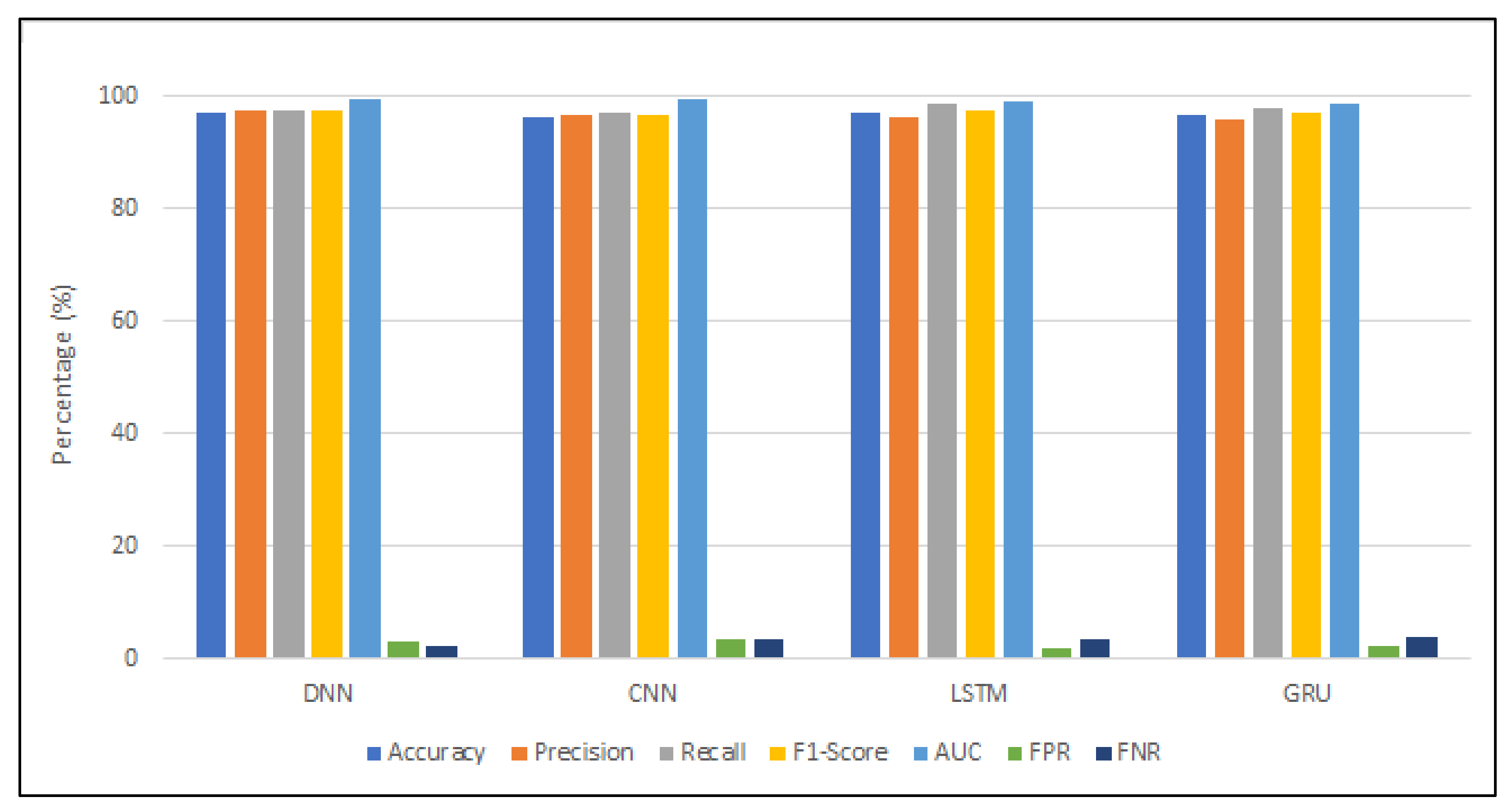
4. Results and Discussion
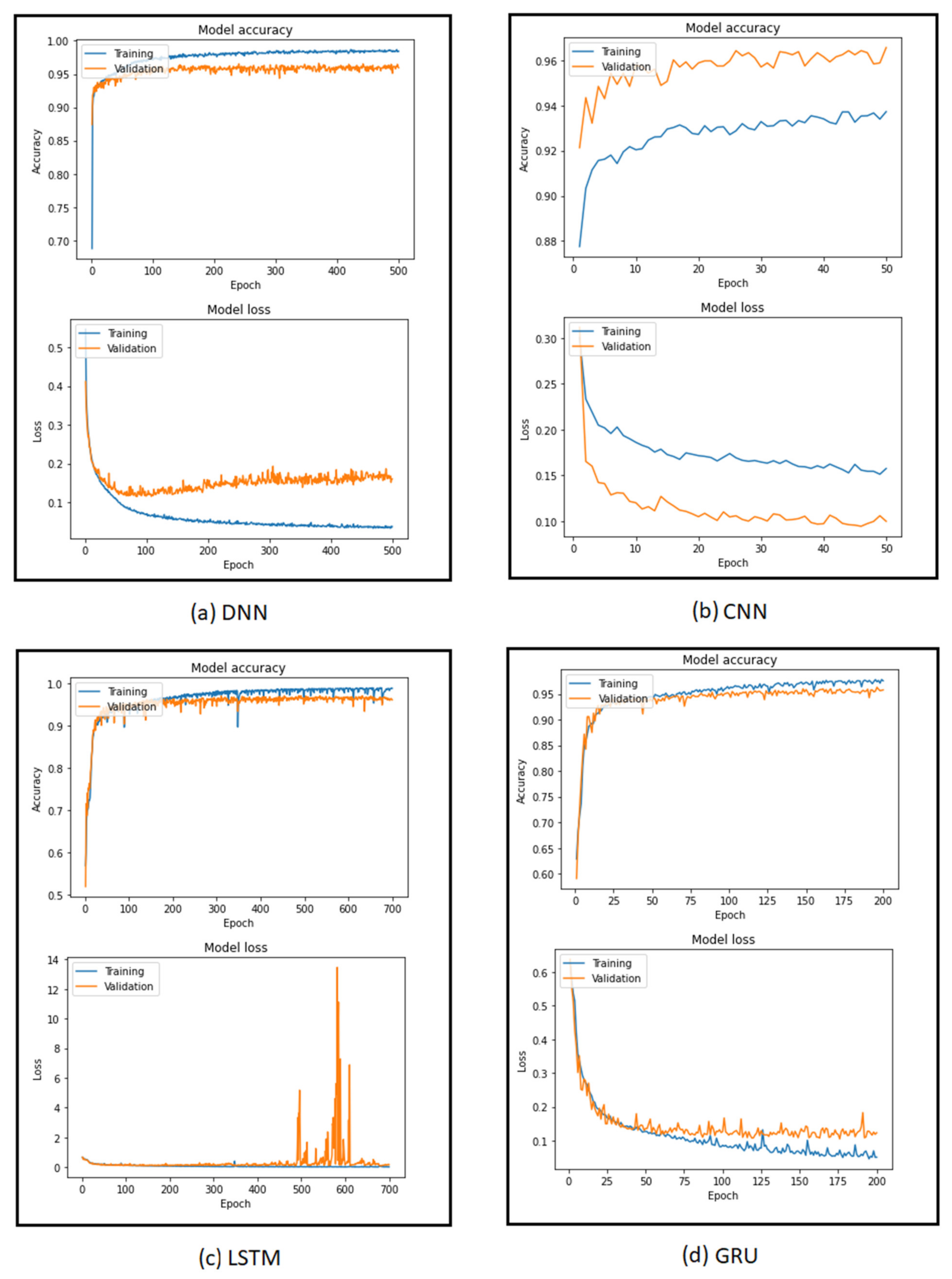
4.1. Results with DNN
4.2. Results with CNN
4.3. Results with LSTM
4.4. Results with GRU
4.5. Issues and Perspectives
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset | Dataset Size | Number of Neurons | Learning Rate | Batch Size | Epoch | ||
|---|---|---|---|---|---|---|---|---|
| Input | Hidden | Output | ||||||
| [18] | UCI | 11,055 | 30 | 20/10/5 | 2 | 0.01 | - | <200 |
| [19] | PhishTank | 73,575 | - | 20/40 | - | - | - | 100 |
| Yandex | ||||||||
| [22] | UCI | 17,700 | - | - | - | - | - | - |
| DMO | 10,000 | |||||||
| [42] | PhishTank | 2119 | 10 | 19/100/200/300 | 1 | 0.0001 | - | 6000 |
| Alexa | 1407 | |||||||
| [21] | PhishTank | 17,000 | - | - | - | - | - | - |
| DMOZ | 20,000 | |||||||
| PageRank | 480 | |||||||
| WHOIS | 480 | |||||||
| [64] | PhishTank Yahoo Own dataset | 11,055 | 30 | 20/10/5 | 2 | 0.001 | 32 | 150 |
| 1353 | 9 | - | 2 | |||||
| 58,645 | 111 | - | 2 | |||||
| 88,657 | 111 | - | 2 | |||||
| [20] | PhishTank Alexa | 3000 | 10 | 20/100/200/300/400/500 | 1 | 0.001 | 3100 | |
| Reference | Dataset | Dataset Size | Number of Kernels | Kernel Size | Pooling Size | Stride | Learning rate | Dropout Rate | Batch Size | Epoch |
|---|---|---|---|---|---|---|---|---|---|---|
| [37] | NA | 2000 | - | 5 | - | - | - | - | 16 | - |
| [7] | PhishTank | 318,642 | 256 | 3 | 3 | - | - | 0.5 | 128 | 20 |
| Com Crawl | 73,575 | |||||||||
| Yandex | 83,857 | |||||||||
| Alexa | 82,888 | |||||||||
| [8] | PhishTank | 2456 | 64 32 | 16 16 | - | - | - | - | - | - |
| Millersmiles | ||||||||||
| Yahoo | ||||||||||
| Starting point | ||||||||||
| [10] | PhishTank | 21,303 | - | 128 | 3 | 1 | 0.001 | 0.5 | 64 | 10 |
| Alexa/Amazon | 24,800 | |||||||||
| [11] | PhishTank | 4,820,940 | 32 | 3 × 1 | 2 | 3 × 1 | 0.0001 | 0.5 | - | - |
| Openphish | 16 | |||||||||
| Alexa | 8 | |||||||||
| [25] | DMOZ Own dataset | 3816 | 32 | 3 × 3 | (2,2) | - | - | - | 32 | 61 |
| 32 | ||||||||||
| 64 | ||||||||||
| [26] | ILSVRC-2012-CLS | 12 | - | - | - | - | 0.01 | - | 32 | 5000 |
| [30] | PhishTank | 2,585,146 | 64 | 2 | - | - | - | 0.2 | 64 | 3 |
| 64 | 3 | 0.5 | ||||||||
| [42] | PhishTank | 2119 | 32/64/64/128/128/264/512 | - | 2 | 1 | 0.001 | - | - | 200 |
| Alexa | 1407 | |||||||||
| [31] | Alexa, DMOZ, etc., Sophos | 611,894124,574 | 64 | 5 | 4 | - | 0.001 | - | - | 500 |
| [29] | PhishTank | 13,652 | 8/16/32/64/84 | 1/3/5/7/9 | - | - | - | - | - | - |
| Crawler | 10,000 | |||||||||
| [24] | PhishTank | 10,604 | - | 2 | 2 | 2 | 0.1 0.01 0.001 0.0005 | 0.5 | 45 | 15 |
| Common Crawl | 10,604 | |||||||||
| [32] | PhishTank | 245,385 | - | 5/6/7 | - | - | 0.01 | 0.9 | 2048 | 32 |
| Alexa | 245,023 | |||||||||
| [27] | PhishTank | 43,984 | - | 5 | - | - | - | - | 10 | 50 |
| 5000 Best Websites | 45,000 | |||||||||
| [33] | PhishTank | 1,021,758 | - | - | - | - | - | - | 64 | 20/45/64 |
| DMOZ | 989,021 | |||||||||
| [35] | PhishTank | 97,400 | 256 | 5/6/7 | 4 | - | 0.0001 | - | 32 | 200 |
| Virus Total | ||||||||||
| Yandex | 97,400 | |||||||||
| [28] | UCI | 11,055 | 8/16/32/64 | 10 | 2 | - | - | - | - | 220 |
| 5 | ||||||||||
| [34] | Own dataset | 340,000 | 128 | 2 | - | - | 0.01 | 0.5 | 100 | 30 |
| 65,000 | 128 | 4 | ||||||||
| [38] | PhishTank | 206,200 | 200 | 2 | 2 | 1 | - | - | - | - |
| MalwarePatrol | ||||||||||
| DMOZ, Alexa |
| Reference | Dataset | Dataset Size | Number of Layers | Number of Units | Learning Rate | Dropout Rate | Batch Size | Epoch |
|---|---|---|---|---|---|---|---|---|
| [41] | PhishTank | 1.5 million | 1 | 128 | 0.0001 | - | - | 25 |
| Common Crawl | 2 | |||||||
| [46] | PhishTank | 153,788 | 1 | 100 | 0.001 | 0.2 | 64 | 30 |
| Openphish | 7212 | |||||||
| Alexa | 170,552 | |||||||
| [42] | PhishTank | 2119 | - | 4 | 0.001 | - | - | 700 |
| Alexa | 1407 | |||||||
| [31] | Alexa, DMOZ, etc., Sophos | 611,894 124,574 | 1 | 70 | 0.001 | - | - | 500 |
| [44] | Vaderetro | 2000 | 1 | - | - | - | - | 200 |
| Alexa | 1,000,000 | |||||||
| [43] | PhishTank | 2000 | 5 | 128 | 0.001 | - | 128 | - |
| Yahoo Directory | 2000 | |||||||
| [33] | PhishTank | 1,021,758 | - | - | - | - | 64 | 20/140/ 256/578 |
| DMOZ | 989,021 | |||||||
| [35] | PhishTank | 97,400 | 1 | 32 | 0.0001 | - | 32 | 200 |
| Virus Total | ||||||||
| Yandex | 97,400 | |||||||
| [10] | PhishTank | 21,303 | 1 | 128 | 0.001 | 0.5 | 64 | 10 |
| Alexa/Amazon | 24,800 | |||||||
| [11] | PhishTank | 4,820,940 | 2 | 128 | 0.0001 | 0.5 | - | - |
| Openphish | ||||||||
| Alexa | ||||||||
| [47] | UCI | 2456 | 1 | - | 0.001 | - | - | 200 |
| 2 | 0.0001 | 600 | ||||||
| 3 | 0.0001 | 800 | ||||||
| 4 | 0.01 | 900 | ||||||
| 5 | 0.0001 | 1000 | ||||||
| [45] | PhishTank | 450,176 | 1 | 10 | - | 0.2 | - | 10 |
| [36] | OpenPhish Alexa | 52,000 | - | - | - | - | - | - |
| Reference | Dataset | Dataset Size | Number of Layers | Number of Units | Learning Rate | Dropout Rate | Batch Size | Epoch |
|---|---|---|---|---|---|---|---|---|
| [41] | PhishTank Common Crawl | 1.5 million | 1 2 | 128 | 0.0001 | - | - | 25 |
| [34] | Own dataset | 340,000 65,000 | 1 | 64 | 0.01 | 0.5 | 100 | 30 |
| [48] | PhishTank Common Crawl | 759,361 | 2 | 60 | 0.001 | - | 256 | 20 |
| Experiment (Exp.) | Learning Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| D1-1 | 0.0001 | 6.65 | 7.22 | 92.78 | 94.62 | 93.69 | 98.21 | 93.03 | 43 |
| D1-2 | 0.0005 | 8.24 | 5.16 | 94.84 | 93.63 | 94.23 | 98.47 | 93.49 | 26 |
| D1-3 | 0.001 | 5.11 | 4.63 | 95.37 | 96.06 | 95.71 | 98.97 | 95.16 | 45 |
| D1-4 | 0.005 | 3.80 | 6.20 | 93.80 | 97.19 | 95.46 | 99.12 | 94.80 | 54 |
| D1-5 | 0.01 | 6.95 | 4.32 | 95.68 | 94.27 | 94.97 | 98.58 | 94.48 | 53 |
| D1-6 | 0.05 | 5.20 | 7.88 | 92.12 | 96.50 | 94.26 | 98.57 | 93.17 | 53 |
| D1-7 | 0.1 | 6.35 | 7.76 | 92.24 | 94.98 | 93.59 | 98.01 | 92.85 | 54 |
| Exp. | Hidden Layer | Neurons in Each Hidden Layer | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|
| D2-1 | 1 | (30 20 1) | 5.88 | 5.96 | 94.04 | 95.35 | 94.69 | 99.00 | 94.08 | 53 |
| D2-2 | (30 16 1) | 5.11 | 4.63 | 95.37 | 96.06 | 95.71 | 98.97 | 95.16 | 45 | |
| D2-3 | (30 8 1) | 5.86 | 4.40 | 95.60 | 95.67 | 95.64 | 98.85 | 94.98 | 52 | |
| D2-4 | 2 | (30 20 16 1) | 6.47 | 5.07 | 94.93 | 94.77 | 94.85 | 98.53 | 94.30 | 53 |
| D2-5 | (30 20 8 1) | 5.69 | 4.38 | 95.62 | 95.30 | 95.46 | 99.06 | 95.02 | 51 | |
| D2-6 | (30 20 4 1) | 10.17 | 2.44 | 97.56 | 91.21 | 94.28 | 99.06 | 93.85 | 49 | |
| D2-7 | (30 16 8 1) | 6.61 | 3.63 | 96.37 | 94.66 | 95.51 | 99.03 | 95.03 | 36 | |
| D2-8 | (30 16 4 1) | 4.59 | 4.47 | 95.53 | 96.17 | 95.85 | 98.93 | 95.48 | 32 | |
| D2-9 | (30 8 4 1) | 7.69 | 4.22 | 95.78 | 93.49 | 94.62 | 98.89 | 94.17 | 50 | |
| D2-10 | 3 | (30 20 16 8 1) | 4.67 | 4.32 | 95.68 | 96.23 | 95.95 | 98.95 | 95.52 | 53 |
| D2-11 | (30 20 16 4 1) | 10.08 | 2.72 | 97.28 | 91.12 | 94.10 | 98.83 | 93.71 | 53 | |
| D2-12 | (30 20 16 2 1) | 3.81 | 6.27 | 93.73 | 97.19 | 95.43 | 98.77 | 94.75 | 53 | |
| D2-13 | (30 20 8 4 1) | 4.68 | 5.43 | 94.57 | 96.47 | 95.51 | 98.82 | 94.89 | 23 | |
| D2-14 | (30 20 8 2 1) | 4.61 | 5.77 | 94.22 | 96.68 | 95.44 | 98.64 | 94.71 | 53 | |
| D2-15 | (30 20 4 2 1) | 9.82 | 3.21 | 96.79 | 91.89 | 94.27 | 98.74 | 93.71 | 53 | |
| D2-16 | (30 16 8 4 1) | 4.01 | 5.62 | 94.38 | 96.91 | 95.63 | 99.19 | 95.07 | 53 | |
| D2-17 | (30 16 8 2 1) | 3.64 | 5.17 | 94.83 | 97.27 | 96.03 | 99.11 | 95.48 | 53 | |
| D2-18 | (30 16 4 2 1) | 3.89 | 4.35 | 95.65 | 97.16 | 96.39 | 98.53 | 95.84 | 47 | |
| D2-19 | (30 8 4 2 1) | 7.55 | 3.00 | 97.00 | 93.47 | 95.20 | 99.04 | 94.84 | 52 |
| Experiment (Exp.) | Batch Size | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| D3-1 | 8 | 4.23 | 5.40 | 94.60 | 96.63 | 95.60 | 99.00 | 95.12 | 124 |
| D3-2 | 16 | 10.25 | 3.03 | 96.97 | 91.64 | 94.23 | 98.42 | 93.62 | 54 |
| D3-3 | 32 | 3.89 | 4.35 | 95.65 | 97.16 | 96.39 | 98.53 | 95.84 | 47 |
| D3-4 | 64 | 6.94 | 4.96 | 95.04 | 94.51 | 94.78 | 98.24 | 94.17 | 3 |
| D3-5 | 128 | 4.52 | 5.87 | 94.13 | 96.50 | 95.30 | 98.33 | 94.71 | 3 |
| D3-6 | 256 | 5.58 | 6.67 | 93.33 | 95.56 | 94.43 | 97.93 | 93.80 | 3 |
| D3-7 | 512 | 6.20 | 6.67 | 93.33 | 95.22 | 94.27 | 98.56 | 93.53 | 3 |
| D3-8 | 1024 | 7.57 | 7.06 | 92.94 | 93.93 | 93.44 | 96.52 | 92.72 | 3 |
| Experiment (Exp.) | Number of Epochs | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| D4-1 | 50 | 3.89 | 4.35 | 95.65 | 97.16 | 96.39 | 98.53 | 95.84 | 47 |
| D4-2 | 100 | 5.33 | 3.07 | 96.93 | 95.84 | 96.38 | 98.97 | 95.93 | 103 |
| D4-3 | 150 | 3.29 | 5.43 | 94.57 | 97.48 | 96.00 | 98.97 | 95.48 | 153 |
| D4-4 | 200 | 3.55 | 3.10 | 96.90 | 97.13 | 97.01 | 98.95 | 96.70 | 203 |
| D4-5 | 250 | 2.63 | 4.92 | 95.08 | 97.96 | 96.50 | 99.08 | 96.07 | 253 |
| D4-6 | 300 | 6.72 | 2.52 | 97.48 | 94.78 | 96.11 | 98.28 | 95.61 | 303 |
| D4-7 | 500 | 3.01 | 2.47 | 97.53 | 97.53 | 97.53 | 99.40 | 97.29 | 503 |
| D4-8 | 700 | 3.73 | 3.69 | 96.31 | 97.09 | 96.70 | 98.48 | 96.29 | 703 |
| Experiment (Exp.) | Learning Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| C1-1 | 0.0001 | 5.23 | 6.65 | 93.35 | 96.18 | 94.75 | 98.31 | 93.94 | 52 |
| C1-2 | 0.0005 | 5.18 | 5.75 | 94.25 | 96.32 | 95.27 | 98.92 | 94.48 | 53 |
| C1-3 | 0.001 | 4.57 | 5.96 | 94.04 | 96.66 | 95.33 | 99.04 | 94.62 | 53 |
| C1-4 | 0.005 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 |
| C1-5 | 0.01 | 3.25 | 8.04 | 91.96 | 97.66 | 94.72 | 98.94 | 93.89 | 54 |
| C1-6 | 0.05 | 16.34 | 3.94 | 96.06 | 85.13 | 90.27 | 97.32 | 89.78 | 53 |
| Experiment (Exp.) | Dropout Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| C5-1 | 0.1 | 5.31 | 2.98 | 97.02 | 95.40 | 96.21 | 99.36 | 95.93 | 54 |
| C5-2 | 0.2 | 5.37 | 3.32 | 96.68 | 95.57 | 96.12 | 99.45 | 95.75 | 53 |
| C5-3 | 0.3 | 3.53 | 5.36 | 94.64 | 97.20 | 95.90 | 99.21 | 95.43 | 81 |
| C5-4 | 0.4 | 3.96 | 4.23 | 95.77 | 96.93 | 96.34 | 99.27 | 95.88 | 54 |
| C5-5 | 0.5 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 |
| Experiment (Exp.) | Kernel Size | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| C2-1 | 1 | 8.24 | 12.60 | 87.40 | 94.07 | 90.61 | 94.85 | 89.15 | 54 |
| C2-2 | 2 | 6.00 | 9.81 | 90.19 | 95.50 | 92.77 | 97.81 | 91.77 | 53 |
| C2-3 | 3 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 |
| C2-4 | 4 | 3094 | 5.19 | 94.81 | 97.02 | 95.90 | 99.19 | 95.34 | 54 |
| C2-5 | 5 | 6.42 | 3.50 | 96.50 | 94.96 | 95.72 | 99.30 | 95.21 | 53 |
| C2-6 | 6 | 6.26 | 4.46 | 95.54 | 94.66 | 95.10 | 99.10 | 94.71 | 53 |
| Experiment (Exp.) | Number of Kernels | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| C3-1 | 8 | 3.41 | 6.61 | 93.39 | 97.51 | 95.41 | 98.81 | 94.71 | 54 |
| C3-2 | 16 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 |
| C3-3 | 32 | 4.87 | 5.29 | 94.71 | 96.31 | 95.50 | 99.24 | 94.89 | 54 |
| C3-4 | 64 | 4.44 | 4.19 | 95.81 | 96.51 | 96.16 | 99.46 | 95.70 | 53 |
| C3-5 | 128 | 3.01 | 5.70 | 94.30 | 97.73 | 95.99 | 99.28 | 95.43 | 153 |
| C3-6 | 256 | 10.93 | 1.95 | 98.05 | 90.38 | 94.06 | 99.13 | 93.67 | 199 |
| C3-7 | 512 | 6.56 | 4.56 | 95.44 | 94.57 | 95.00 | 98.96 | 94.53 | 253 |
| Exp. | Conv. Layer | Number of Kernels | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score(%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|
| C6-1 | 1 | 64 | 4.44 | 4.19 | 95.81 | 96.51 | 96.16 | 99.46 | 95.70 | 53 |
| C6-2 | 32 | 4.87 | 5.29 | 94.71 | 96.31 | 95.50 | 99.24 | 94.89 | 54 | |
| C6-3 | 16 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 | |
| C6-4 | 8 | 3.41 | 6.61 | 93.39 | 97.51 | 95.41 | 98.81 | 94.71 | 54 | |
| C6-5 | 2 | (64 64) | 0.83 | 10.97 | 89.03 | 99.43 | 93.94 | 99.05 | 92.90 | 108 |
| C6-6 | (64 32) | 4.09 | 8.50 | 91.50 | 97.13 | 94.23 | 98.61 | 93.26 | 104 | |
| C6-7 | (64 16) | 2.63 | 10.71 | 89.29 | 97.97 | 93.43 | 98.34 | 92.63 | 104 | |
| C6-8 | (64 8 | 5.13 | 7.42 | 92.58 | 96.22 | 94.37 | 98.63 | 93.53 | 103 | |
| C6-9 | (32 32) | 2.57 | 9.13 | 90.87 | 98.11 | 94.35 | 98.89 | 93.53 | 91 | |
| C6-10 | (32 16) | 6.14 | 8.06 | 91.94 | 95.25 | 93.57 | 98.34 | 92.76 | 104 | |
| C6-11 | (32 8) | 11.34 | 5.76 | 94.24 | 91.27 | 92.73 | 97.84 | 91.77 | 54 | |
| C6-12 | (16 16) | 6.22 | 8.37 | 91.63 | 94.87 | 93.22 | 97.97 | 92.58 | 53 | |
| C6-13 | (16 8) | 6.75 | 8.39 | 91.61 | 94.76 | 93.16 | 97.71 | 92.31 | 54 | |
| C6-14 | (8 8) | 8.42 | 10.02 | 89.98 | 93.81 | 91.85 | 96.58 | 90.64 | 54 |
| Experiment (Exp.) | Batch Size | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| C7-1 | 8 | 4.34 | 6.08 | 93.92 | 96.67 | 95.27 | 98.81 | 94.66 | 166 |
| C7-2 | 16 | 3.64 | 5.63 | 94.37 | 97.26 | 95.79 | 99.19 | 95.21 | 85 |
| C7-3 | 32 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 |
| C7-4 | 64 | 4.94 | 6.05 | 93.95 | 96.04 | 94.99 | 98.83 | 94.44 | 54 |
| C7-5 | 128 | 3.26 | 6.11 | 96.74 | 97.59 | 95.70 | 99.15 | 95.07 | 14 |
| C7-6 | 256 | 3.31 | 4.95 | 95.05 | 97.50 | 96.26 | 99.29 | 95.75 | 8 |
| C7-7 | 512 | 3.89 | 6.11 | 93.89 | 96.97 | 95.41 | 98.96 | 94.84 | 3 |
| C7-8 | 1024 | 3.37 | 6.43 | 93.57 | 97.50 | 95.49 | 98.94 | 94.84 | 4 |
| Experiment (Exp.) | Number of Epochs | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| C8-1 | 50 | 3.50 | 3.39 | 96.61 | 97.09 | 96.85 | 99.51 | 96.56 | 54 |
| C8-2 | 100 | 4.81 | 4.62 | 95.38 | 96.43 | 95.90 | 99.30 | 95.30 | 103 |
| C8-3 | 150 | 2.93 | 5.18 | 94.82 | 97.70 | 96.24 | 99.32 | 95.79 | 153 |
| C8-4 | 200 | 5.17 | 3.84 | 96.16 | 95.85 | 96.00 | 99.34 | 95.57 | 204 |
| C8-5 | 250 | 3.63 | 4.97 | 95.03 | 97.13 | 96.07 | 99.29 | 95.61 | 254 |
| C8-6 | 300 | 3.41 | 5.66 | 94.34 | 97.40 | 95.85 | 99.22 | 95.30 | 302 |
| C8-7 | 500 | 4.57 | 4.16 | 95.84 | 96.31 | 96.08 | 99.28 | 95.66 | 503 |
| C8-8 | 700 | 3.91 | 6.53 | 93.47 | 97.23 | 95.31 | 99.06 | 94.53 | 704 |
| Experiment (Exp.) | Learning Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| L1-1 | 0.0001 | 19.16 | 7.27 | 92.73 | 83.77 | 88.02 | 95.56 | 86.97 | 6.80 |
| L1-2 | 0.0005 | 5.49 | 6.96 | 93.04 | 95.77 | 94.38 | 98.19 | 93.67 | 5.90 |
| L1-3 | 0.001 | 14.82 | 6.64 | 93.36 | 87.12 | 90.13 | 97.01 | 89.42 | 6.72 |
| Experiment (Exp.) | Dropout Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| L2-1 | 0.1 | 8.28 | 8.12 | 91.88 | 93.86 | 92.86 | 97.24 | 91.81 | 6.23 |
| L2-2 | 0.2 | 8.28 | 5.00 | 95.00 | 93.40 | 94.19 | 98.39 | 93.53 | 5.30 |
| L2-3 | 0.3 | 7.84 | 6.33 | 93.67 | 93.59 | 93.63 | 98.13 | 92.99 | 6.75 |
| L2-4 | 0.4 | 11.53 | 6.97 | 93.03 | 90.62 | 91.81 | 97.59 | 90.95 | 5.95 |
| L2-5 | 0.5 | 5.49 | 6.96 | 93.04 | 95.77 | 94.38 | 98.19 | 93.67 | 5.90 |
| Exp. | No of Layer | Units per Layer | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|---|
| L3-1 | 1 | 256 | 3.82 | 1047 | 89.53 | 97.34 | 93.27 | 98.27 | 92.13 | 19.78 |
| L3-2 | 128 | 5.49 | 6.96 | 93.04 | 95.77 | 94.38 | 98.19 | 93.67 | 5.90 | |
| L3-3 | 64 | 12.42 | 5.34 | 94.66 | 88.74 | 91.61 | 97.32 | 91.18 | 3.40 | |
| L3-4 | 32 | 9.01 | 10.73 | 89.27 | 93.02 | 91.11 | 95.68 | 90.00 | 2.57 | |
| L3-5 | 16 | 12.57 | 14.32 | 85.68 | 90.10 | 87.83 | 93.85 | 86.43 | 2.57 | |
| L3-6 | 2 | (128 128) | 4.37 | 8.18 | 91.82 | 96.75 | 94.22 | 98.06 | 93.40 | 13.08 |
| L3-7 | (128 64) | 6.88 | 7.57 | 92.43 | 95.00 | 93.70 | 97.79 | 92.72 | 10.97 | |
| L3-8 | (128 32) | 5.17 | 8.23 | 91.77 | 95.95 | 93.81 | 97.98 | 93.08 | 10.97 | |
| L3-9 | (128 16) | 9.61 | 5.93 | 94.07 | 91.82 | 92.93 | 98.22 | 92.36 | 8.87 | |
| L3-10 | 3 | (128 128 128) | 10.87 | 6.92 | 93.08 | 91.03 | 92.04 | 96.78 | 91.27 | 22.38 |
| L3-11 | (128 128 64) | 6.46 | 7.27 | 92.73 | 95.06 | 93.88 | 98.06 | 93.08 | 20.40 | |
| L3-12 | (128 128 32) | 9.37 | 5.19 | 94.81 | 93.20 | 94.00 | 97.79 | 93.03 | 18.92 | |
| L3-13 | (128 128 16) | 12.17 | 6.80 | 93.20 | 89.96 | 91.55 | 97.33 | 90.73 | 15.92 | |
| L3-14 | (128 64 64) | 11.71 | 7.48 | 92.52 | 90.41 | 91.45 | 97.27 | 90.59 | 14.27 | |
| L3-15 | (128 64 32) | 8.70 | 7.05 | 92.95 | 93.10 | 93.03 | 97.62 | 92.22 | 14.73 | |
| L3-16 | (128 64 16) | 3.28 | 9.20 | 90.80 | 97.65 | 94.10 | 98.02 | 93.17 | 13.53 | |
| L3-17 | (128 32 32) | 3.48 | 9.19 | 90.81 | 97.61 | 94.09 | 98.25 | 93.03 | 12.48 | |
| L3-18 | (128 32 16) | 6.29 | 6.84 | 93.16 | 95.13 | 94.13 | 98.17 | 93.40 | 10.13 | |
| L3-19 | (128 16 16) | 4.66 | 8.17 | 91.83 | 96.63 | 94.17 | 97.95 | 93.26 | 10.50 |
| Experiment (Exp.) | Batch Size | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| L4-1 | 8 | 6.70 | 6.03 | 93.97 | 94.44 | 94.21 | 98.35 | 93.67 | 18.53 |
| L4-2 | 16 | 8.07 | 5.86 | 94.14 | 93.76 | 93.95 | 98.08 | 93.17 | 12.32 |
| L4-3 | 32 | 5.49 | 6.96 | 93.04 | 95.77 | 94.38 | 98.19 | 93.67 | 5.90 |
| L4-4 | 64 | 11.33 | 6.28 | 93.72 | 90.42 | 92.04 | 97.14 | 91.36 | 5.07 |
| L4-5 | 128 | 4.10 | 15.08 | 84.92 | 97.31 | 90.70 | 96.34 | 88.92 | 4.22 |
| L4-6 | 256 | 2.81 | 19.89 | 80.11 | 98.36 | 88.30 | 95.09 | 85.62 | 3.38 |
| Experiment (Exp.) | Number of Epochs | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| L5-1 | 50 | 5.49 | 6.96 | 93.04 | 95.77 | 94.38 | 98.19 | 93.67 | 5.90 |
| L5-2 | 100 | 5.47 | 6.74 | 93.26 | 95.77 | 94.50 | 98.71 | 93.80 | 13.40 |
| L5-3 | 150 | 3.86 | 8.51 | 91.49 | 97.15 | 94.23 | 98.05 | 93.40 | 20.42 |
| L5-4 | 200 | 3.77 | 3.91 | 96.09 | 96.96 | 96.53 | 99.29 | 96.16 | 41.12 |
| L5-5 | 250 | 3.28 | 4.90 | 95.10 | 97.49 | 96.28 | 99.23 | 95.79 | 54.23 |
| L5-6 | 300 | 5.91 | 7.44 | 92.56 | 95.43 | 93.96 | 98.23 | 93.22 | 65.07 |
| L5-7 | 500 | 2.97 | 4.18 | 95.82 | 97.75 | 96.77 | 98.54 | 96.34 | 120.27 |
| L5-8 | 700 | 1.80 | 3.55 | 96.45 | 98.63 | 97.53 | 99.11 | 97.20 | 169.17 |
| Experiment (Exp.) | Learning Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| G1-1 | 0.0001 | 14.64 | 7.21 | 92.79 | 88.14 | 90.40 | 95.99 | 89.37 | 5.45 |
| G1-2 | 0.0005 | 6.36 | 7.51 | 92.49 | 95.00 | 93.73 | 98.39 | 92.99 | 6.40 |
| G1-3 | 0.001 | 5.85 | 5.50 | 94.50 | 95.49 | 94.99 | 98.76 | 94.35 | 5.40 |
| G1-4 | 0.005 | 4.90 | 9.03 | 90.97 | 96.18 | 93.50 | 97.74 | 92.72 | 6.42 |
| G1-5 | 0.01 | 9.06 | 7.82 | 92.18 | 92.85 | 92.51 | 96.98 | 91.63 | 5.40 |
| Experiment (Exp.) | Dropout Rate | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| G2-1 | 0.1 | 3.83 | 8.26 | 91.74 | 97.00 | 94.30 | 98.66 | 93.62 | 5.40 |
| G2-2 | 0.2 | 7.61 | 5.55 | 94.45 | 93.91 | 94.18 | 98.81 | 93.53 | 6.42 |
| G2-3 | 0.3 | 7.36 | 5.45 | 94.55 | 93.76 | 94.15 | 98.77 | 93.67 | 6.42 |
| G2-4 | 0.4 | 7.72 | 6.01 | 93.99 | 94.22 | 94.10 | 98.50 | 93.26 | 5.40 |
| G2-5 | 0.5 | 5.85 | 5.50 | 94.50 | 95.49 | 94.99 | 98.76 | 94.35 | 5.40 |
| Exp. | No of Layer | Units per Layer | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|---|
| G3-1 | 1 | 256 | 5.18 | 6.27 | 93.73 | 95.89 | 94.80 | 98.94 | 94.21 | 10.40 |
| G3-2 | 128 | 5.85 | 5.50 | 94.50 | 95.49 | 94.99 | 98.76 | 94.35 | 5.40 | |
| G3-3 | 64 | 6.05 | 7.61 | 92.39 | 95.09 | 93.72 | 98.02 | 93.08 | 4.42 | |
| G3-4 | 32 | 4.91 | 11.06 | 88.94 | 96.63 | 92.63 | 97.82 | 91.32 | 3.42 | |
| G3-5 | 16 | 7.61 | 5.86 | 94.14 | 93.76 | 93.95 | 98.11 | 93.35 | 2.98 | |
| G3-6 | 2 | (128 128) | 5.04 | 5.17 | 94.83 | 96.00 | 95.41 | 98.99 | 94.89 | 24.40 |
| G3-7 | (128 64) | 6.01 | 5.78 | 94.22 | 95.29 | 94.75 | 98.80 | 94.12 | 22.40 | |
| G3-8 | (128 32) | 7.19 | 5.62 | 94.38 | 94.07 | 94.22 | 98.70 | 93.67 | 23.42 | |
| G3-9 | (128 16) | 5.32 | 6.37 | 93.63 | 95.97 | 94.78 | 98.71 | 94.08 | 22.42 | |
| G3-10 | 3 | (128 128 128) | 7.43 | 5.56 | 94.44 | 94.22 | 94.33 | 98.19 | 93.62 | 33.43 |
| G3-11 | (128 128 64) | 10.23 | 3.60 | 96.40 | 91.71 | 94.00 | 98.61 | 93.35 | 32.87 | |
| G3-12 | (128 128 32) | 4.19 | 8.05 | 91.95 | 96.93 | 94.37 | 98.73 | 93.53 | 33.42 | |
| G3-13 | (128 128 16) | 7.76 | 5.72 | 94.28 | 94.13 | 94.20 | 98.67 | 93.40 | 34.43 | |
| G3-14 | (128 64 64) | 3.96 | 7.46 | 92.54 | 97.23 | 94.83 | 98.68 | 93.94 | 35.82 | |
| G3-15 | (128 64 32) | 4.07 | 7.05 | 92.95 | 96.90 | 94.88 | 98.92 | 94.21 | 33.32 | |
| G3-16 | (128 64 16) | 3.15 | 6.67 | 93.33 | 97.65 | 95.44 | 98.95 | 94.80 | 34.43 | |
| G3-17 | (128 32 32) | 6.12 | 6.33 | 93.67 | 95.33 | 94.49 | 98.67 | 93.76 | 12.43 | |
| G3-18 | (128 32 16) | 2.94 | 8.51 | 91.49 | 97.90 | 94.59 | 98.39 | 93.71 | 10.45 | |
| G3-19 | (128 16 16) | 9.84 | 4.34 | 95.66 | 91.67 | 93.62 | 98.77 | 93.08 | 11.45 |
| Experiment (Exp.) | Batch Size | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| G4-1 | 8 | 8.16 | 4.19 | 95.81 | 93.24 | 94.51 | 98.89 | 93.98 | 35.42 |
| G4-2 | 16 | 2.28 | 10.51 | 89.49 | 98.35 | 93.71 | 98.67 | 92.76 | 17.42 |
| G4-3 | 32 | 5.04 | 5.17 | 94.83 | 96.00 | 95.41 | 98.99 | 94.89 | 24.40 |
| G4-4 | 64 | 1.63 | 12.26 | 87.74 | 98.83 | 92.96 | 98.93 | 91.86 | 11.43 |
| G4-5 | 128 | 5.03 | 7.16 | 92.84 | 96.05 | 94.42 | 98.79 | 93.76 | 8.42 |
| G4-6 | 256 | 4.59 | 6.99 | 93.01 | 96.50 | 94.72 | 98.36 | 94.03 | 6.42 |
| Experiment (Exp.) | Number of Epochs | FPR (%) | FNR (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) | Accuracy (%) | Time (min) |
|---|---|---|---|---|---|---|---|---|---|
| G5-1 | 50 | 5.04 | 5.17 | 94.83 | 96.00 | 95.41 | 98.99 | 94.89 | 24.40 |
| G5-2 | 100 | 3.54 | 4.69 | 95.31 | 97.37 | 96.33 | 98.84 | 95.79 | 16.42 |
| G5-3 | 150 | 3.58 | 4.44 | 95.56 | 97.25 | 96.40 | 98.67 | 95.93 | 35.43 |
| G5-4 | 200 | 2.48 | 3.94 | 96.06 | 98.03 | 97.04 | 98.79 | 96.70 | 55.07 |
| G5-5 | 250 | 7.97 | 5.79 | 94.21 | 94.35 | 94.28 | 98.41 | 93.31 | 58.15 |
| G5-6 | 300 | 5.80 | 4.75 | 95.25 | 95.63 | 95.44 | 98.79 | 94.80 | 83.43 |
| G5-7 | 500 | 16.00 | 8.51 | 91.49 | 87.38 | 89.39 | 94.58 | 88.10 | 140.43 |
| G5-8 | 700 | 50.70 | 42.55 | 57.45 | 73.51 | 64.50 | 48.79 | 55.09 | 205.00 |
References
- Ahmad, R.; Alsmadi, I. Machine learning approaches to IoT security: A systematic literature review. Internet Things 2021, 14, 100365. [Google Scholar] [CrossRef]
- Amanullah, M.A.; Habeeb, R.A.A.; Nasaruddin, F.H.; Gani, A.; Ahmed, E.; Nainar, A.S.M.; Akim, N.M.; Imran, M. Deep learning and big data technologies for IoT security. Comput. Commun. 2020, 151, 495–517. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Asharf, J.; Moustafa, N.; Khurshid, H.; Debie, E.; Haider, W.; Wahab, A. A Review of Intrusion Detection Systems Using Machine and Deep Learning in Internet of Things: Challenges, Solutions and Future Directions. Electronics 2020, 9, 1177. [Google Scholar] [CrossRef]
- Bello, I.; Chiroma, H.; Abdullahi, U.A.; Gital, A.Y.; Jauro, F.; Khan, A.; Okesola, J.O.; Abdulhamid, S.M. Detecting ransomware attacks using intelligent algorithms: Recent development and next direction from deep learning and big data perspectives. J. Ambient Intell. Humaniz. Comput. 2020, 12, 8699–8717. [Google Scholar] [CrossRef]
- Al-Ahmadi, S. PDMLP: Phishing Detection Using Multilayer Perceptron. Int. J. Netw. Secur. Its Appl. 2020, 12. SSRN:3624621. Available online: https://papers.ssrn.com/abstract=3624621 (accessed on 12 May 2021). [CrossRef]
- Aljofey, A.; Jiang, Q.; Qu, Q.; Huang, M.; Niyigena, J.-P. An Effective Phishing Detection Model Based on Character Level Convolutional Neural Network from URL. Electronics 2020, 9, 1514. [Google Scholar] [CrossRef]
- Al-Milli, N.; Hammo, B.H. A Convolutional Neural Network Model to Detect Illegitimate URLs. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 220–225. [Google Scholar] [CrossRef]
- Feng, J.; Zou, L.; Nan, T. A Phishing Webpage Detection Method Based on Stacked Autoencoder and Correlation Coefficients. J. Comput. Inf. Technol. 2019, 27. [Google Scholar] [CrossRef]
- Feng, J.; Zou, L.; Ye, O.; Han, J. Web2Vec: Phishing Webpage Detection Method Based on Multidimensional Features Driven by Deep Learning. IEEE Access 2020, 8, 221214–221224. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, Q.; Qin, J.; Wen, W. Phishing URL Detection via CNN and Attention-Based Hierarchical RNN. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science And Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 112–119. [Google Scholar] [CrossRef]
- Chen, Z. Deep Learning for Cybersecurity: A Review. In Proceedings of the 2020 International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 1–2 August 2020; pp. 7–18. [Google Scholar]
- Naway, A.; LI, Y. A Review on The Use of Deep Learning in Android Malware Detection. arXiv 2018, arXiv:181210360. Available online: http://arxiv.org/abs/1812.10360 (accessed on 3 April 2021).
- Sarker, I.H. Deep Cybersecurity: A Comprehensive Overview from Neural Network and Deep Learning Perspective. SN Comput. Sci. 2021, 2, 154. [Google Scholar] [CrossRef]
- Quang, D.N.; Selamat, A.; Krejcar, O. Recent Research on Phishing Detection Through Machine Learning Algorithm. In Advances and Trends in Artificial Intelligence. Artificial Intelligence Practices; Fujita, H., Selamat, A., Lin, J.C.-W., Ali, M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 495–508. [Google Scholar]
- Wu, Y.; Wei, D.; Feng, J. Network Attacks Detection Methods Based on Deep Learning Techniques: A Survey. Secur. Commun. Netw. 2020, 2020, e8872923. [Google Scholar] [CrossRef]
- Mahdavifar, S.; Ghorbani, A.A. Application of deep learning to cybersecurity: A survey. Neurocomputing 2019, 347, 149–176. [Google Scholar] [CrossRef]
- Mahdavifar, S.; Ghorbani, A.A. DeNNeS: Deep embedded neural network expert system for detecting cyber attacks. Neural Comput. Appl. 2020, 32, 14753–14780. [Google Scholar] [CrossRef]
- Sahingoz, O.K.; Işılay Baykal, S.; Bulut, D. Phishing detection from urls by using neural networks. In Computer Science & Information Technology (CS & IT); AIRCC Publishing Corporation: Chennai, India, 2018; pp. 41–54. [Google Scholar] [CrossRef]
- Khan, M.F.; Al, E. Detection of Phishing Websites Using Deep Learning Techniques. Turk. J. Comput. Math. Educ. TURCOMAT 2021, 12, 3880–3892. [Google Scholar] [CrossRef]
- Sountharrajan, S.; Nivashini, M.; Shandilya, S.K.; Suganya, E.; Bazila Banu, A.; Karthiga, M. Dynamic Recognition of Phishing URLs Using Deep Learning Techniques. In Advances in Cyber Security Analytics and Decision Systems; Shandilya, S.K., Wagner, N., Nagar, A.K., Eds.; EAI/Springer Innovations in Communication and Computing; Springer International Publishing: Cham, Switzerland, 2020; pp. 27–56. ISBN 978-3-030-19353-9. [Google Scholar] [CrossRef]
- Selvaganapathy, S.; Nivaashini, M.; Natarajan, H. Deep belief network based detection and categorization of malicious URLs. Inf. Secur. J. Glob. Perspect. 2018, 27, 145–161. [Google Scholar] [CrossRef]
- Aldweesh, A.; Derhab, A.; Emam, A.Z. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowl.-Based Syst. 2020, 189, 105124. [Google Scholar] [CrossRef]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]
- Liu, D.; Lee, J.-H.; Wang, W.; Wang, Y. Malicious Websites Detection via CNN based Screenshot Recognition. In Proceedings of the 2019 International Conference on Intelligent Computing and its Emerging Applications (ICEA), Tainan, Taiwan, 30 August–1 September 2019; pp. 115–119. [Google Scholar] [CrossRef]
- Phoka, T.; Suthaphan, P. Image Based Phishing Detection Using Transfer Learning. In Proceedings of the 2019 11th International Conference on Knowledge and Smart Technology (KST), Phuket, Thailand, 23–26 January 2019; pp. 232–237. [Google Scholar] [CrossRef]
- Xiao, X.; Zhang, D.; Hu, G.; Jiang, Y.; Xia, S. CNN–MHSA: A Convolutional Neural Network and multi-head self-attention combined approach for detecting phishing websites. Neural Netw. 2020, 125, 303–312. [Google Scholar] [CrossRef] [PubMed]
- Yerima, S.Y.; Alzaylaee, M.K. High Accuracy Phishing Detection Based on Convolutional Neural Networks. In Proceedings of the 2020 3rd International Conference on Computer Applications Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Yu, L.; Tian, S.; Peng, Y.; Pei, X. Bidirectional LSTM Malicious webpages detection algorithm based on convolutional neural network and independent recurrent neural network. Appl. Intell. 2019, 49, 3016–3026. [Google Scholar] [CrossRef]
- Rasymas, T.; Dovydaitis, L. Detection of phishing URLs by using deep learning approach and multiple features combinations. Balt. J. Mod. Comput. 2020, 8, 471–483. [Google Scholar] [CrossRef]
- Srinivasan, S.; Vinayakumar, R.; Arunachalam, A.; Alazab, M.; Soman, K. DURLD: Malicious URL Detection Using Deep Learning-Based Character Level Representations. In Malware Analysis Using Artificial Intelligence and Deep Learning; Stamp, M., Alazab, M., Shalaginov, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 535–554. ISBN 978-3-030-62582-5. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, F.; Luo, X.; Zhang, S. PDRCNN: Precise Phishing Detection with Recurrent Convolutional Neural Networks. Secur. Commun. Netw. 2019, 2019, e2595794. [Google Scholar] [CrossRef]
- Yang, P.; Zhao, G.; Zeng, P. Phishing Website Detection Based on Multidimensional Features Driven by Deep Learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Yang, W.; Zuo, W.; Cui, B. Detecting Malicious URLs via a Keyword-Based Convolutional Gated-Recurrent-Unit Neural Network. IEEE Access 2019, 7, 29891–29900. [Google Scholar] [CrossRef]
- M, Y.V.; Janet, B.; Reddy, S. Anti-phishing System using LSTM and CNN. In Proceedings of the 2020 IEEE International Conference for Innovation in Technology (INOCON), Bangluru, India, 6–8 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- jaysinha. Available online: https://jaysinha.me/files/phishx_preprint.pdf (accessed on 18 September 2021).
- Al-Ahmadi, S. A Deep Learning Technique for Web Phishing Detection Combined URL Features and Visual Similarity. Soc. Sci. Res. Netw. 2020. SSRN:3716033. Available online: https://papers.ssrn.com/abstract=3716033 (accessed on 10 March 2021). [CrossRef]
- Zhang, Q.; Bu, Y.; Chen, B.; Zhang, S.; Lu, X. Research on phishing webpage detection technology based on CNN-BiLSTM algorithm. J. Phys. Conf. Ser. 2021, 1738, 012131. [Google Scholar] [CrossRef]
- Chen, D.; Wawrzynski, P.; Lv, Z. Cyber security in smart cities: A review of deep learning-based applications and case studies. Sustain. Cities Soc. 2021, 66, 102655. [Google Scholar] [CrossRef]
- Elnagar, S.; Thomas, M. A Cognitive Framework for Detecting Phishing Websites. In Proceedings of the International Conference on Advances on Applied Cognitive Computing (ACC 2018), Las Vegas, NV, USA, 30 July–2 August 2018; pp. 60–61. [Google Scholar]
- Feng, T.; Yue, C. Visualizing and Interpreting RNN Models in URL-based Phishing Detection. In Proceedings of the 25th ACM Symposium on Access Control Models and Technologies, Barcelona, Spain, 10–12 June 2020; pp. 13–24. [Google Scholar] [CrossRef]
- Somesha, M.; Pais, A.R.; Rao, R.S.; Rathour, V.S. Efficient deep learning techniques for the detection of phishing websites. Sādhanā 2020, 45, 165. [Google Scholar] [CrossRef]
- Su, Y. Research on Website Phishing Detection Based on LSTM RNN. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 284–288. [Google Scholar] [CrossRef]
- Torroledo, I.; Camacho, L.D.; Bahnsen, A.C. Hunting Malicious TLS Certificates with Deep Neural Networks. In Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security; Association for Computing Machinery: New York, NY, USA, 2018; pp. 64–73. [Google Scholar] [CrossRef]
- Afzal, S.; Asim, M.; Javed, A.R.; Beg, M.O.; Baker, T. URLdeepDetect: A Deep Learning Approach for Detecting Malicious URLs Using Semantic Vector Models. J. Netw. Syst. Manag. 2021, 29, 21. [Google Scholar] [CrossRef]
- Rao, R.S.; Vaishnavi, T.; Pais, A.R. PhishDump: A multi-model ensemble based technique for the detection of phishing sites in mobile devices. Pervasive Mob. Comput. 2019, 60, 101084. [Google Scholar] [CrossRef]
- Wang, S.; Khan, S.; Xu, C.; Nazir, S.; Hafeez, A. Deep Learning-Based Efficient Model Development for Phishing Detection Using Random Forest and BLSTM Classifiers. Complexity 2020, 2020, e8694796. [Google Scholar] [CrossRef]
- Yuan, L.; Zeng, Z.; Lu, Y.; Ou, X.; Feng, T. A Character-Level BiGRU-Attention for Phishing Classification. In Information and Communications Security; Zhou, J., Luo, X., Shen, Q., Xu, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 746–762. [Google Scholar] [CrossRef]
- Yi, P.; Guan, Y.; Zou, F.; Yao, Y.; Wang, W.; Zhu, T. Web Phishing Detection Using a Deep Learning Framework. Wirel. Commun. Mob. Comput. 2018, 2018, e4678746. [Google Scholar] [CrossRef]
- Robic-Butez, P.; Win, T.Y. Detection of Phishing websites using Generative Adversarial Network. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3216–3221. [Google Scholar] [CrossRef]
- Sohn, I. Deep belief network based intrusion detection techniques: A survey. Expert Syst. Appl. 2021, 167, 114170. [Google Scholar] [CrossRef]
- Alotaibi, R.; Al-Turaiki, I.; Alakeel, F. Mitigating Email Phishing Attacks using Convolutional Neural Networks. In Proceedings of the 2020 3rd International Conference on Computer Applications Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, C.; Huang, C.; Liu, L.; Yang, Y. Phishing Email Detection Using Improved RCNN Model With Multilevel Vectors and Attention Mechanism. IEEE Access 2019, 7, 56329–56340. [Google Scholar] [CrossRef]
- Berman, D.S.; Buczak, A.L.; Chavis, J.S.; Corbett, C.L. A Survey of Deep Learning Methods for Cyber Security. Information 2019, 10, 122. [Google Scholar] [CrossRef] [Green Version]
- Chatterjee, M.; Namin, A.-S. Detecting Phishing Websites through Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; Volume 2, pp. 227–232. [Google Scholar] [CrossRef]
- Odeh, A.; Keshta, I.; Abdelfattah, E. Efficient Detection of Phishing Websites Using Multilayer Perceptron International Association of Online Engineering. 2020, pp. 22–31. Available online: https://www.learntechlib.org/p/217754/ (accessed on 10 March 2021).
- Saha, I.; Sarma, D.; Chakma, R.J.; Alam, M.N.; Sultana, A.; Hossain, S. Phishing Attacks Detection using Deep Learning Approach. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 1180–1185. [Google Scholar] [CrossRef]
- Ya, J.; Liu, T.; Zhang, P.; Shi, J.; Guo, L.; Gu, Z. NeuralAS: Deep Word-Based Spoofed URLs Detection AgaIInst Strong Similar Samples. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Adebowale, M.A.; Lwin, K.T.; Hossain, M.A. Deep Learning with Convolutional Neural Network and Long Short-Term Memory for Phishing Detection. In Proceedings of the 2019 13th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Island of Ulkulhas, Maldives, 26–28 August 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Digwal, H.N.; Kavya, N.P. Detection of Phishing Website Based on Deep Learning. Int. J. Res. Eng. Sci. Manag. 2020, 3, 331–336. [Google Scholar]
- Pooja, A.S.S.V.L.; Sridhar, M. Analysis of Phishing Website Detection Using CNN and Bidirectional LSTM. In Proceedings of the 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 5–7 November 2020; pp. 1620–1629. [Google Scholar] [CrossRef]
- Kaggle. Available online: https://www.kaggle.com/isatish/phishing-dataset-uci-ml-csv (accessed on 12 April 2021).
- Github. Available online: https://github.com/quangdn83/WebsitePhishingDetection (accessed on 21 September 2021).
- Vrbančič, G.; Fister, I.; Podgorelec, V. Parameter Setting for Deep Neural Networks Using Swarm Intelligence on Phishing Websites Classification. Int. J. Artif. Intell. Tools 2019, 28, 1960008. [Google Scholar] [CrossRef]
- Chen, S.; Fan, L.; Chen, C.; Xue, M.; Liu, Y.; Xu, L. GUI-Squatting Attack: Automated Generation of Android Phishing Apps. IEEE Trans. Dependable Secure Comput. accepted. [CrossRef]











| Category | Algorithm | Frequency | Reference | |||
|---|---|---|---|---|---|---|
| NS 1 | RS 2 | PS 3 | FS 4 | |||
| Single | DNN | - | 1 | - | - | [19] |
| MLP | 1 | - | 2 | - | [6,56,57] | |
| CNN | - | - | 4 | - | [7,8,25,27] | |
| LSTM | - | 1 | 1 | - | [44,45] | |
| BiLSTM | 1 | - | - | - | [58] | |
| BiGRU | - | - | 1 | - | [48] | |
| Dual | CNN, CNN | - | - | 1 | - | [37] |
| CNN, LSTM | 1 | - | 4 | - | [30,31,33,59,60] | |
| CNN, BiLSTM | 3 | - | 1 | - | [10,36,40,61] | |
| CNN, GRU | - | - | 1 | - | [34] | |
| Multiple | CNN, RNN, MLP | - | - | 1 | - | [11] |
| DNN, DBM, SAE | 1 | - | - | - | [21] | |
| DNN, CNN, LSTM | - | - | 1 | - | [20] | |
| LSTM, GRU, BiLSTM, BiGRU | - | - | 1 | - | [41] | |
| DNN, CNN, LSTM, GRU | - | - | - | 1 | Our study | |
| Total | 7 | 2 | 18 | 1 | ||
| Reference | Algorithm | Parameters | ||||
|---|---|---|---|---|---|---|
| Learning Rate | Network Architecture | Dropout Rate | Batch Size | Epoch | ||
| [9] | SAE |  |  | x | x |  |
| [18] | DNN |  |  | x | x |  |
| [49] | DBN |  |  | x | x |  |
| [50] | GAN |  | x | x |  | x |
| [24] | CNN |  |  | x | x | x |
| [28] | CNN, CNN | x |  | x | x | x |
| [22] | DBN, DNN |  |  | x | x |  |
| [32] | CNN, BiLSTM | x |  | x |  |  |
| [42] | DNN, CNN, LSTM |  |  | x | x |  |
| [29] | CNN, RNN, BiLSTM | x |  | x | x | x |
| Our study | DNN, CNN, LSTM, GRU |  |  |  |  |  |
| Reference | Performance Metrics | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FPR | FNR | ACC | PR | RC | F1 | AUC | Training Time | Testing Time | Other | |
| [7] |  |  |  |  |  |  |  | |||
| [10] |  |  |  |  | ||||||
| [11] |  |  |  |  | ||||||
| [24] |  |  |  |  |  | GPU memory requirement Parameter set size, Loss Number of URL per second | ||||
| [28] |  |  |  |  |  |  | Parameter size | |||
| [32] |  |  |  |  |  |  |  | |||
| [33] |  |  |  |  |  | Detection cost, Epoch/s | ||||
| [34] |  |  |  |  | Parameter size | |||||
| [41] |  |  |  |  | Parameter size | |||||
| [48] |  |  |  |  | Model storage spaceParameter size | |||||
| Our study |  |  |  |  |  |  |  |  |  | GPU memory stageParameter size |
| Type | No | Feature | Name | Description | Value |
|---|---|---|---|---|---|
| Address bar-based | 1 | IP address | UsingIP | Having IP address in URL | −1, 1 |
| 2 | URL length | LongURL | Long URL to hide the suspicious part | −1, 0, 1 | |
| 3 | Shortening service | ShortURL | Using URL shortening services “TinyURL” | −1, 1 | |
| 4 | @ Symbol | Symbol@ | URL’s having @ symbol | −1, 1 | |
| 5 | “//” redirecting | Redirecting// | Having “//” within URL path for directing | −1, 1 | |
| 6 | Prefix suffix | PrefixSuffix | Adding prefix or suffix separated by (-) to the domain | −1, 1 | |
| 7 | Sub domain | SubDomains | Sub domain and multi sub domain | −1, 0, 1 | |
| 8 | SSL final state | HTTPS | Existence of HTTPS and validity of the certificate | −1, 0, 1 | |
| 9 | Domain registration | DomainRegLen | Expiry date of domains/Domain registration length | −1, 1 | |
| 10 | Favicon | Favicon | Favicon loaded from a domain | −1, 1 | |
| 11 | Port | NonStdPort | Using non-standard port | −1, 1 | |
| 12 | HTTPS token | HTTPSDomainURL | The existence of HTTPS token in the domain part of URL | −1, 1 | |
| Abnormal-based | 13 | Request URL | RequestURL | Request URL within a webpage/Abnormal request | −1, 1 |
| 14 | URL of anchor | AnchorURL | URL within <a> tag/Abnormal anchor | −1, 0, 1 | |
| 15 | Links in tags | LinksInScriptTags | Links in <Meta>, <Script> and <Link> tags | −1, 0, 1 | |
| 16 | SFH | ServerFormHandler | Server Form Handler | −1, 0, 1 | |
| 17 | InfoEmail | Submitting information to E-mail | −1, 1 | ||
| 18 | Abnormal URL | AbnormalURL | Host name is included in the URL/Whois | −1, 1 | |
| HTML and JavaScript-based | 19 | Redirecting | WebsiteForwarding | Number of times a website has been redirected | 0, 1 |
| 20 | On mouseover | StatusBarCust | On mouse over changes status bar/Status bar customization | −1, 1 | |
| 21 | Right click | DisableRightClick | Disabling right click | −1, 1 | |
| 22 | Pop-up window | UsingPopupWindow | Using Pop-up window | −1, 1 | |
| 23 | Iframe redirection | IframeRedirection | Using Iframe | −1, 1 | |
| Domain-based | 24 | Age of domain | AgeofDomain | Minimum age of a legitimate domain is 6 months | −1, 1 |
| 25 | DNS record | DNSRecording | Existence of DNS record for the domain | −1, 1 | |
| 26 | Website traffic | WebsiteTraffic | Being among top 100,000 in Alexa rank | −1, 0, 1 | |
| 27 | Page rank | PageRank | Having a page rank greater than 0.2 | −1, 1 | |
| 28 | Google index | GoogleIndex | Website indexed by Google | −1, 1 | |
| 29 | Link reference | LinksPoitingToPage | Number of links pointing to a page | −1, 0, 1 | |
| 30 | Statistical report | StatsReport | Top 10 domain and top 10 Ips from PhishTank | −1, 1 | |
| Result | class | Phishing or legitimate | −1, 1 |
| DL Algorithm | Number of Layers | Number of Units | Number of Kernels | Kernel Size | Learning Rate | Dropout Rate | Batch Size | Number of Epochs |
|---|---|---|---|---|---|---|---|---|
| DNN |  |  |  |  |  | |||
| CNN |  |  |  |  |  |  |  | |
| LSTM |  |  |  |  |  |  | ||
| GRU |  |  |  |  |  |  |
| Experiment | Description | Parameter | DL Algorithm | |||
|---|---|---|---|---|---|---|
| DNN | CNN | LSTM | GRU | |||
| 1 | Optimizing the learning rate | Learning rate | Table A5 | Table A9 | Table A16 | Table A21 |
| 2 | Optimizing the dropout rate | Dropout rate | - | Table A10 | Table A17 | Table A22 |
| 3 | Optimizing the neural network architecture | Number of layers/ Number of neurons per layer | Table A6 | Table A13 | Table A18 | Table A23 |
| Number of kernels | - | Table A12 | - | - | ||
| Kernel size | - | Table A11 | - | - | ||
| 4 | Optimizing the batch size | Batch size | Table A7 | Table A14 | Table A19 | Table A24 |
| 5 | Optimizing the number of epochs | Epoch | Table A8 | Table A15 | Table A20 | Table A25 |
| DL Algorithm | No of Layers | Number of Neurons | Number of Kernels | Kernel Size | Learning Rate | Dropout Rate | Batch Size | No of Epochs |
|---|---|---|---|---|---|---|---|---|
| DNN | 5 | (30 16 4 2 1) | - | - | 0.001 | - | 32 | 500 |
| CNN | 4 | (30 16 1) | 16 | 3 | 0.005 | 0.5 | 32 | 50 |
| LSTM | 3 | (30 128 1) | - | - | 0.0005 | 0.5 | 32 | 700 |
| GRU | 4 | (30 128 128 1) | - | - | 0.001 | 0.5 | 32 | 200 |
| DL Algorithm | Performance Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FPR (%) | FNR (%) | ACC (%) | PR (%) | RC (%) | F1(%) | AUC (%) | Training Time (min) | Testing Time (s) | Parameter Size | Memory Storage (MB) | |
| DNN | 3.01 | 2.47 | 97.29 | 97.53 | 97.53 | 97.53 | 99.40 | 8.38 | 0.470 | 1507 | 172 |
| CNN | 3.50 | 3.39 | 96.56 | 96.61 | 97.09 | 96.85 | 99.51 | 0.9 | 0.263 | 3745 | 325 |
| LSTM | 1.80 | 3.55 | 97.20 | 96.45 | 98.63 | 97.53 | 99.11 | 169.17 | 0.804 | 66,689 | 184 |
| GRU | 2.48 | 3.94 | 96.70 | 96.06 | 98.03 | 97.04 | 98.79 | 55.07 | 1.447 | 149,505 | 184 |
| Reference | DL Algorithm | Parameter Settings | ACC (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Learning Rate | Input Layer | Hidden Layer | Output Layer | Number of Kernels | Kernel Size | Dropout Rate | Batch Size | Epoch | |||
| [18] | DNN | 0.01 | 30 | (20 10 5) | 2 | - | - | - | - | 200 | 97.50 |
| [28] | CNN | - | 30 | (64 64) | 1 | 64/64 | 12/6 | - | - | 220 | 97.20 |
| [6] | MLP | - | - | (100 100) | - | - | - | - | - | - | 96.65 |
| [64] | DNN.BA 1 | 0.0185 | 30 | (50 30) | 2 | - | - | - | 44 | 155 | 95.76 |
| DNN.HBA 2 | 0.0462 | 30 | (42 30) | 2 | - | - | - | 101 | 135 | 95.00 | |
| DNN.FA 3 | 0.0053 | 30 | (50 30) | 2 | - | - | - | 37 | 192 | 96.65 | |
| Our study | DNN CNN LSTM GRU | 0.001 0.005 0.0005 0.001 | 30 30 30 30 | (16 4 2) (16) (128) (128 128) | 1 1 1 1 | - 16 - - | - 3 - - | - 0.5 0.5 0.5 | 32 32 32 32 | 500 50 700 200 | 97.29 96.56 97.20 96.70 |
| Ref. | DL Algorithm | Performance Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Conventional | Additional | |||||||||||
| FPR (%) | FNR (%) | ACC (%) | PR (%) | RC (%) | F1 (%) | AUC (%) | Training Time (min) | Testing Time (s) | Parameter size | Memory Storage (MB) | ||
| [18] | DNN | 1.80 | 3.30 | 97.50 | 97.70 | 96.70 | 97.20 | - | - | - | - | - |
| [28] | CNN | - | - | 97.20 | 96.90 | 98.10 | 97.50 | - | 10.67 | 0.472 | 27,985 | - |
| [6] | MLP | - | - | 96.65 | 96.65 | 96.65 | 96.65 | - | - | - | - | - |
| [64] | DNN.BA 1 | - | - | 95.76 | - | - | 95.70 | - | - | - | - | - |
| DNN.HBA 2 | - | - | 95.00 | - | - | 94.93 | - | - | - | - | - | |
| DNN.FA 3 | - | - | 96.65 | - | - | 96.61 | - | - | - | - | - | |
| Our study | DNN | 3.01 | 2.47 | 97.29 | 97.53 | 97.53 | 97.53 | 99.40 | 8.38 | 0.470 | 1,507 | 172 |
| CNN | 3.50 | 3.39 | 96.56 | 96.61 | 97.09 | 96.85 | 99.51 | 0.9 | 0.263 | 3,745 | 325 | |
| LSTM | 1.80 | 3.55 | 97.20 | 96.45 | 98.63 | 97.53 | 99.11 | 169.17 | 0.804 | 66,689 | 184 | |
| GRU | 2.48 | 3.94 | 96.70 | 96.06 | 98.03 | 97.04 | 98.79 | 55.07 | 1.447 | 149,505 | 184 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Do, N.Q.; Selamat, A.; Krejcar, O.; Yokoi, T.; Fujita, H. Phishing Webpage Classification via Deep Learning-Based Algorithms: An Empirical Study. Appl. Sci. 2021, 11, 9210. https://doi.org/10.3390/app11199210
Do NQ, Selamat A, Krejcar O, Yokoi T, Fujita H. Phishing Webpage Classification via Deep Learning-Based Algorithms: An Empirical Study. Applied Sciences. 2021; 11(19):9210. https://doi.org/10.3390/app11199210
Chicago/Turabian StyleDo, Nguyet Quang, Ali Selamat, Ondrej Krejcar, Takeru Yokoi, and Hamido Fujita. 2021. "Phishing Webpage Classification via Deep Learning-Based Algorithms: An Empirical Study" Applied Sciences 11, no. 19: 9210. https://doi.org/10.3390/app11199210
APA StyleDo, N. Q., Selamat, A., Krejcar, O., Yokoi, T., & Fujita, H. (2021). Phishing Webpage Classification via Deep Learning-Based Algorithms: An Empirical Study. Applied Sciences, 11(19), 9210. https://doi.org/10.3390/app11199210