1. Introduction
Studying in university involves class attendance, individual work and group work. Students interact in and out of the classroom because of previous friendships, affinities or the need for social interaction to study and to be part of the university community. Therefore, group work is usually inherent in the study process, both in the study of theory and in the implementation of practical exercises.
Students communicate, help each other and exchange knowledge (and it has always been so, although by other means). Thus, information interchange is very beneficial to the learning process. At the same time, teachers can encourage and promote group work, and they try to create situations in which collaboration is necessary, i.e., go beyond group work and foster communication, reflection and the construction of knowledge among students. All these technologies favour knowledge sharing and improve individual learning. In a broad sense, technology helps to maintain active learning communities. Unlike other configurations relating to group learning, in our case, the teacher does not organise the groups, the task or any communication tools. Groups and collaboration arise at the initiative of students when they study and do their assignments. This is called spontaneous collaborative learning (SCOLL) [
1]. Its main features are that collaboration is not organised or initiated by the teacher but arises from students’ finding a benefit in it; groups are usually small and stable throughout the course; communication may or may not be mediated by technology.
Group work is encouraged and promoted, but after several years of observing the students, from the results, this promotion of collaboration is mistaken by some students as an open door for dishonest behaviour such as cheating, copying or colluding. We cannot really speak of misunderstanding or confusion, even though that is the excuse the student offers when caught in such a situation. Plagiarism and other dishonest behaviours are alarming at university, especially in computer science studies, as has been highlighted by other studies and journalists [
2,
3,
4]. As teachers, we ask ourselves: where is the boundary among help, collaboration and plagiarism? Can we establish conditions or indicators that help to distinguish between the legitimate and the deceitful? These are the same questions addressed in [
5]. In this case, three levels were posed—collaboration, collusion and plagiarism—and the boundaries among them were discussed. Its author concluded that the bounds vary depending on the assignment and the course policy. It ultimately resolved that professors should establish and clearly state what the boundaries are so that programming students know the course rules and are sure that they are not acting unethically. This conclusion is correct, but it is still fuzzy and not quantifiable. The present paper tries to shed light on this situation in a subject similar to the one addressed by Fraser’s article [
5] with quantitative methods and real data.
We present a study conducted over four years with Introduction to Programming, a first-year course in the Bachelor of Mathematics that uses Haskell as a programming language. The aim of the paper was to observe how group studies are formed and how they are organised over the course of an academic year. As a result, this article studies and characterises how students construct solutions to their practical programming tasks. Our method consists of looking for similarities among students’ solutions using automatic tools. We looked for answers to the following research questions:
Is it possible to quantify how students share knowledge in a classroom through SCOLL? How much of the work is entirely individual and how much is done with classmates?
Is it possible to identify study groups in a classroom? How large are they? Do they have ethical behaviour?
How are successful learners organised? How do they interact with their classmates in the classroom? Are they members of the study groups?
The rest of the paper is organised as follows: in the next section, a short literature review of topics related to the paper is presented. Then, in
Section 3, we describe the tools and methodology followed in the collection and analysis of data for our study.
Section 4 discusses the results obtained for each research question in studies 1, 2 and 3, respectively. The article ends with a set of conclusions and recommendations.
5. Discussion
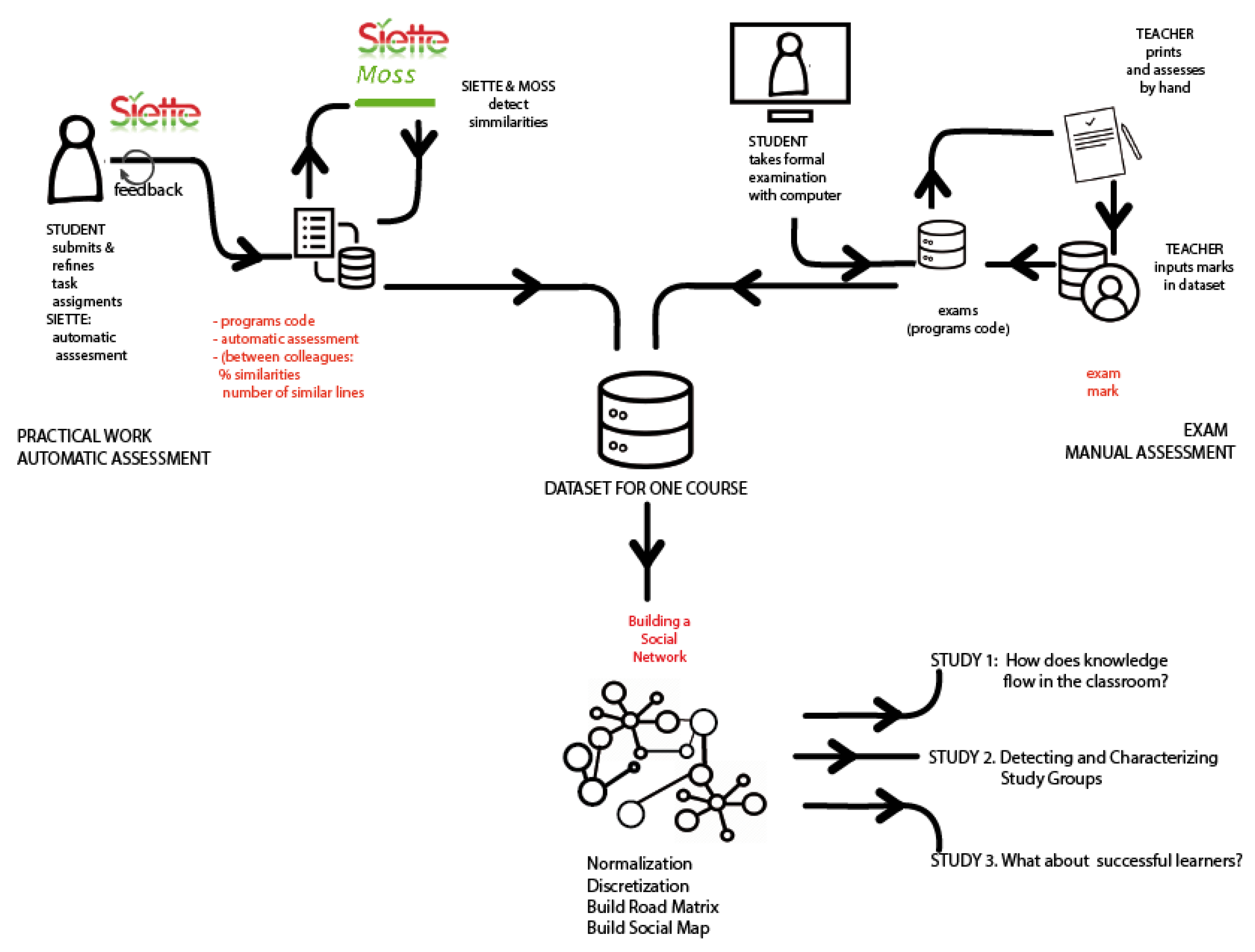
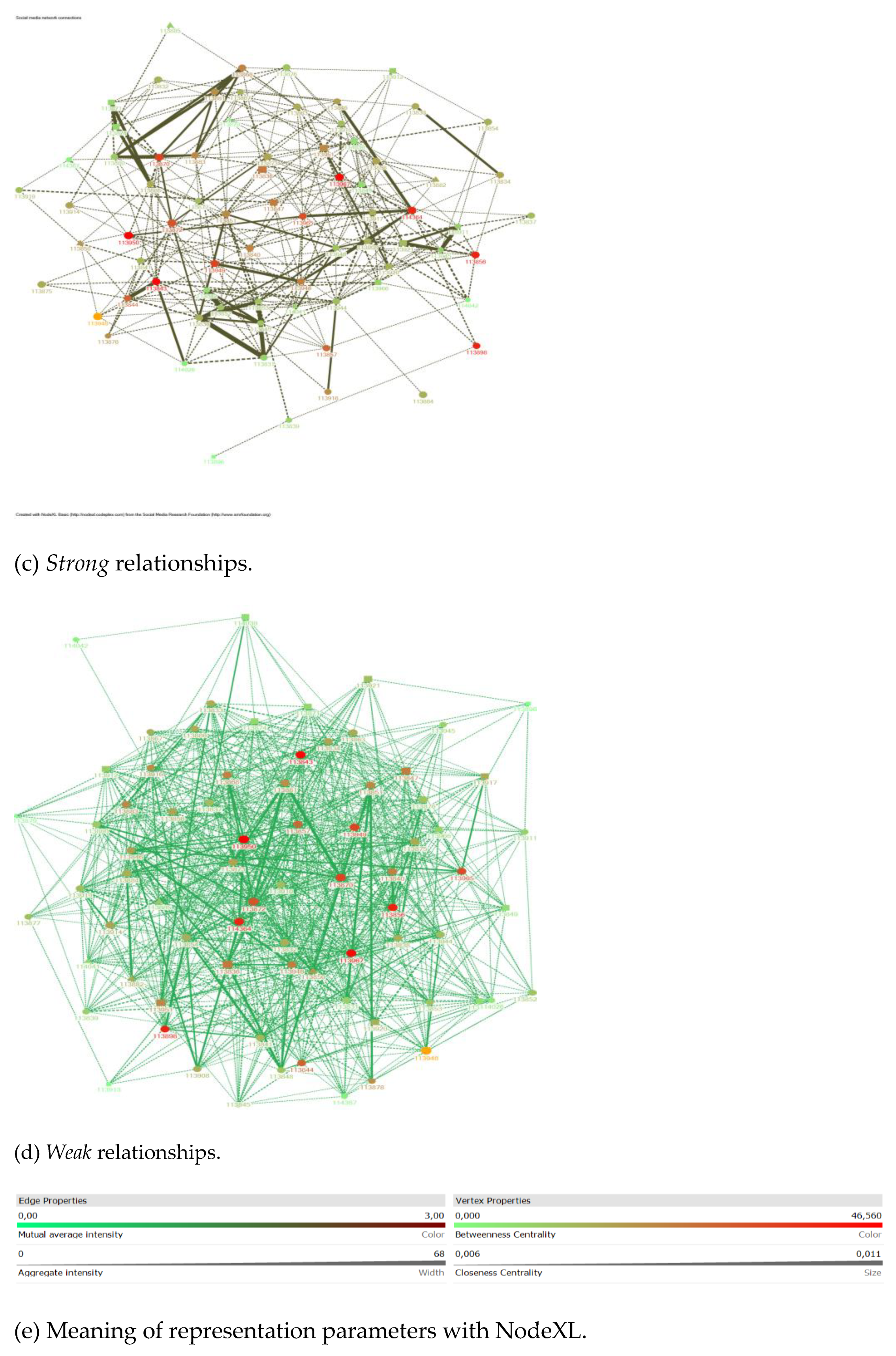
In the previous section, we described three studies that we conducted over four academic years on the same subject. Using a computer-based assessment environment (SIETTE) and an automatic plagiarism detection tool (MOSS), we collected data ono the relationships among the solutions given by the students during each course to a whole set of programming assignments. Programming assignments were different every academic year, but their average difficulty can be considered equivalent. Over the course, students were discouraged to copy their solutions for the sake of ethical conduct and to avoid a strong penalty in case they were caught, but they were encouraged to work together in study groups, helping each other and sharing their knowledge. This large amount of data was mined to discover behavioural patterns using statistical and social network analysis tools and analysing which strategies successful students followed.
Programming is an activity where each individual has his/her own style. Leaving aside the common knowledge of the activities carried out in class and the basics of programming, it is possible to analyse the partial similarities among documents and, from there, to infer groups of document types from which study groups can be obtained without asking the students or analysing virtual campus forums through the results they generate and deliver to the teacher.
In this paper, we showed that it is possible to characterise how much knowledge flow there is between one student and another (creating a relationship between them) by comparing documents by different authors. We formalised this concept and defined the Similar_cod function as well as all the tools necessary to study our data using this approach.
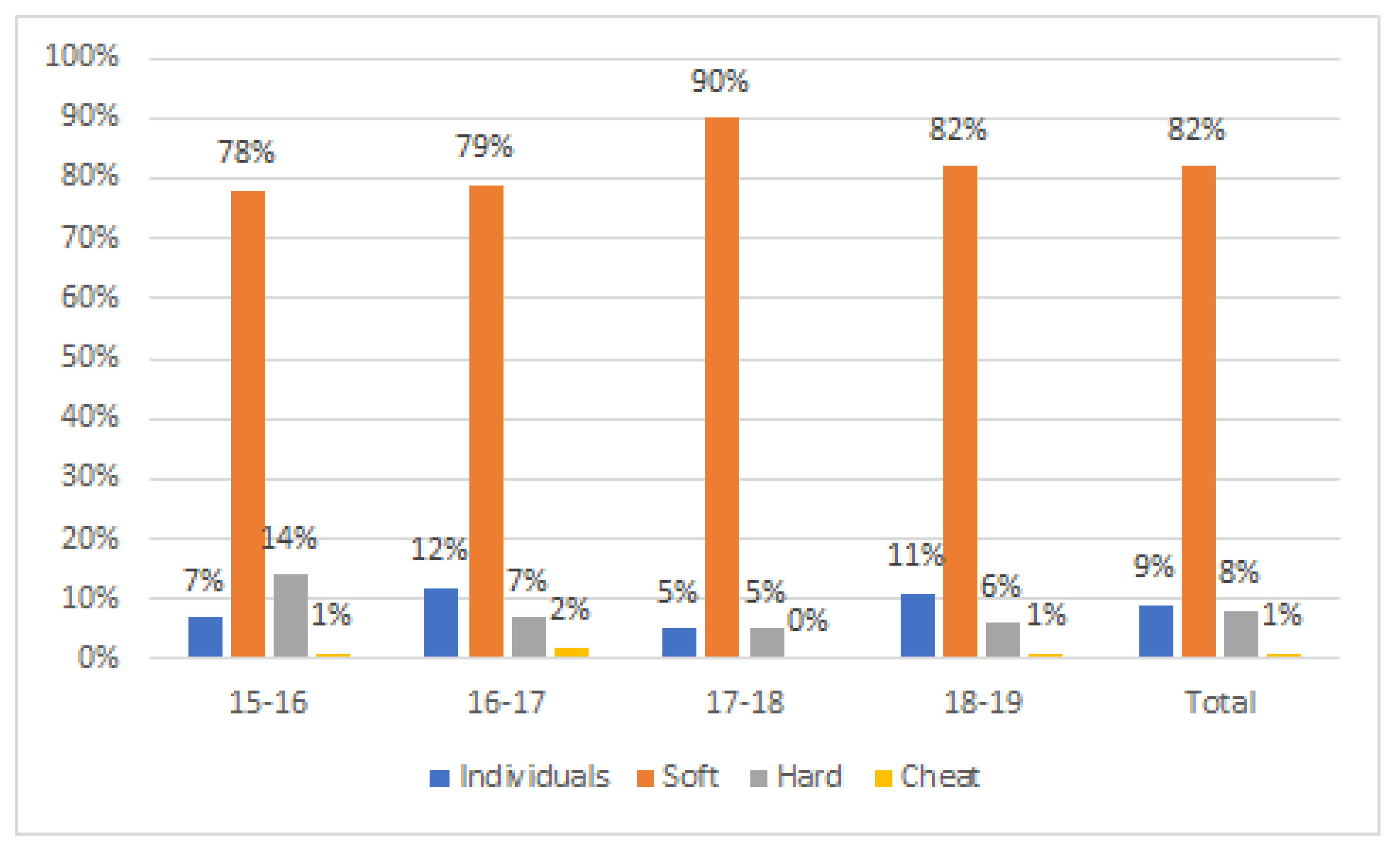
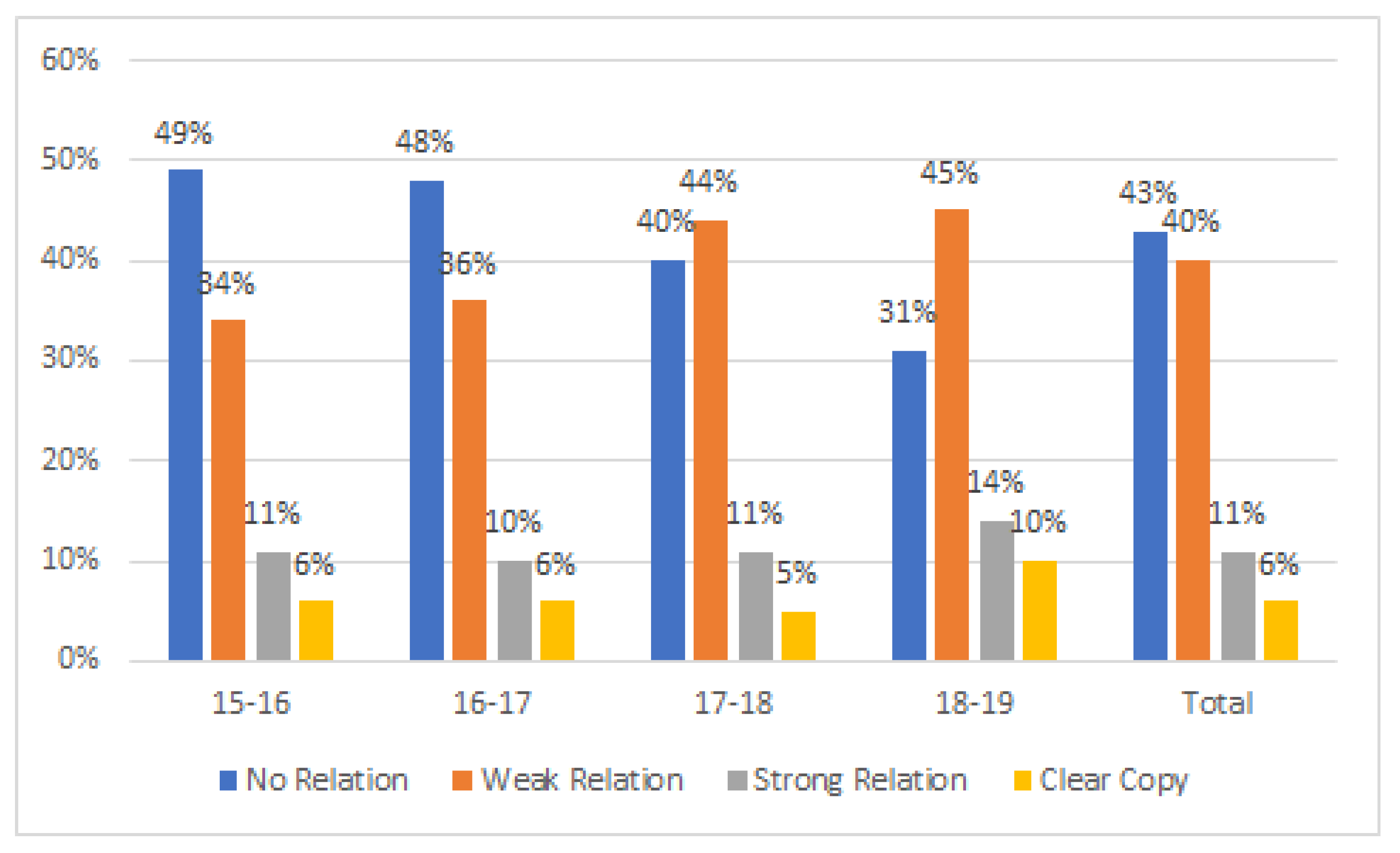
By analysing the intensity of the flow of knowledge among individuals in a course, we can also define the boundary between collaboration and dishonest behaviour. The answer lies in the amount of knowledge flowing from one individual to another in each practical exercise and its continuity over the course. We considered that a one-off flow was not the same as a continuous flow throughout the whole course. We also considered that “some flow” was not the same as “a lot of knowledge flow”. This is the reason why we made an aggregate sum of knowledge flows throughout the course. We used the resulting values to draw our conclusions. In the same way, we considered that a continuous but low flow was also ethical and beneficial. In the end, by adding up all the flows, we have classified the behaviour of the learners and inferred borderline values that allowed us to distinguish among the different behaviours of the learners. Therefore, the boundary was on the borderline between the Qhard groups and the Qcheat groups, which we quantified, with our data, in a cumulative value of document similarity between the first and second quartile of the course. This means that in the Qcheat groups there was help, discussion and exchange of knowledge among the bodies, but this exchange was much higher than in the Qhard groups, so much so that it cannot be considered very honest.
Concerning the behaviour of the individuals, we observed three types which we called dishonest behaviour, isolated behaviour and collaborative behaviour.
With the data we have, the
dishonest behaviour of the students was not as alarming as many studies—especially those in Computer Science and Information Technology [
2,
3,
4,
5]—suggest. The low incidence of dishonest behaviour in this subject may be due to the strict control exerted over the solutions of all classmates. In general, “control causes self-control”. This conclusion is in line with the results obtained by other authors [
44], who also achieved a substantial decrease in their plagiarism rates in programming tasks thanks to the announced use of automatic copy detection tools (from 14% to 5% or 7%, similar to our results). Works such as [
45] also defend the need to inform students about plagiarism control and the consequences this approach has on their academic curriculum.
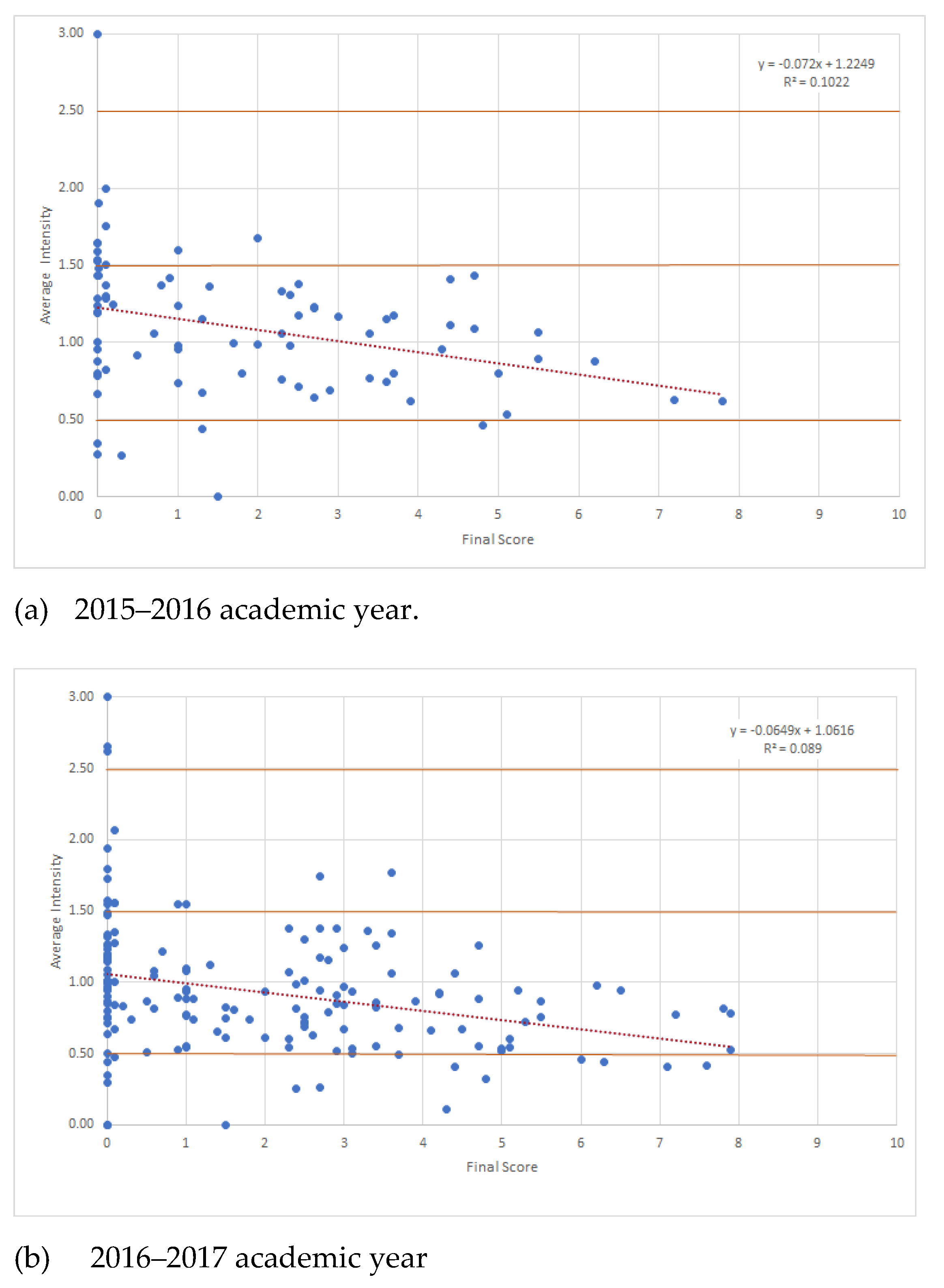
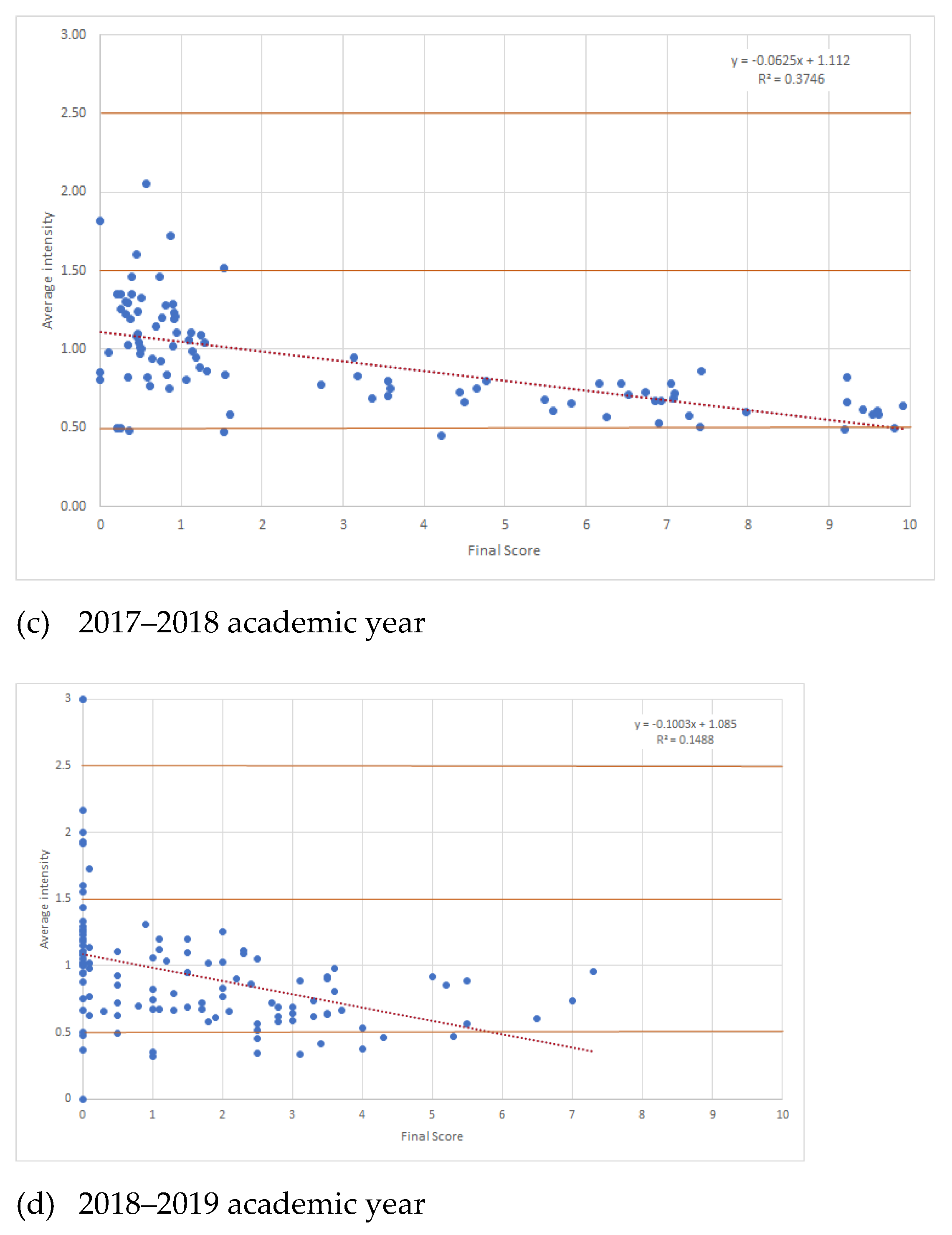
At the other extreme was isolated behaviour in which students did the assignments individually as requested in the course requirements. The similarity between the exercises of these students and their peers was what we called the common background. In general, there was a lot of discussion about the dishonest behaviour of the students, but it can be seen that there was a group of individuals who made an effort to follow the rules, work individually and succeed via their own efforts to pass the subject satisfactorily, although the best students were not always in this group. As we have already shown in this study, these students usually passed the course in their first try with a final score of 7 over 10, often with difficulty, except for the 2017–2018 academic year.
This aspect was discussed among the students, and they claimed that the practical work was very time-consuming. In general, they recognised that they had learned and were satisfied with the knowledge achieved, but because they worked alone, they did not know as many tricks or shortcuts to solve the problems on the theory exam in the time allotted for it. The programs they wrote reached a correct solution, but they did not usually finish all sections of the exam. This was the reason for why their results were good but not the best.
In the middle were the students who helped each other,
collaborated and studied together, and we distinguished between those who studied together and those “who study and pass information to each other”, which corresponded to Q
hard and Q
soft in our study. We posit that these learners self-organise into study groups that give rise to small learning communities. Collaboration is beneficial for learning [
46]. It is a form of study that conforms to a social and active learning method in which learners discuss their own and their peers’ knowledge and help each other with explanations or tricks in order to reach the goal. This process of social construction of knowledge [
7,
47,
48] is an effective way of learning and should not be penalised but encouraged among students, especially if they are at the university level.
The comparison of the documents clearly indicated that a small number of students were responsible for most of the document similarities; that is, there were a set of students that decided to engage in unethical behaviour throughout the course, regardless of the consequences. The analysis clearly identified them as a marginal problem (1%). The data obtained for each academic year were similar, which reinforces these conclusions.
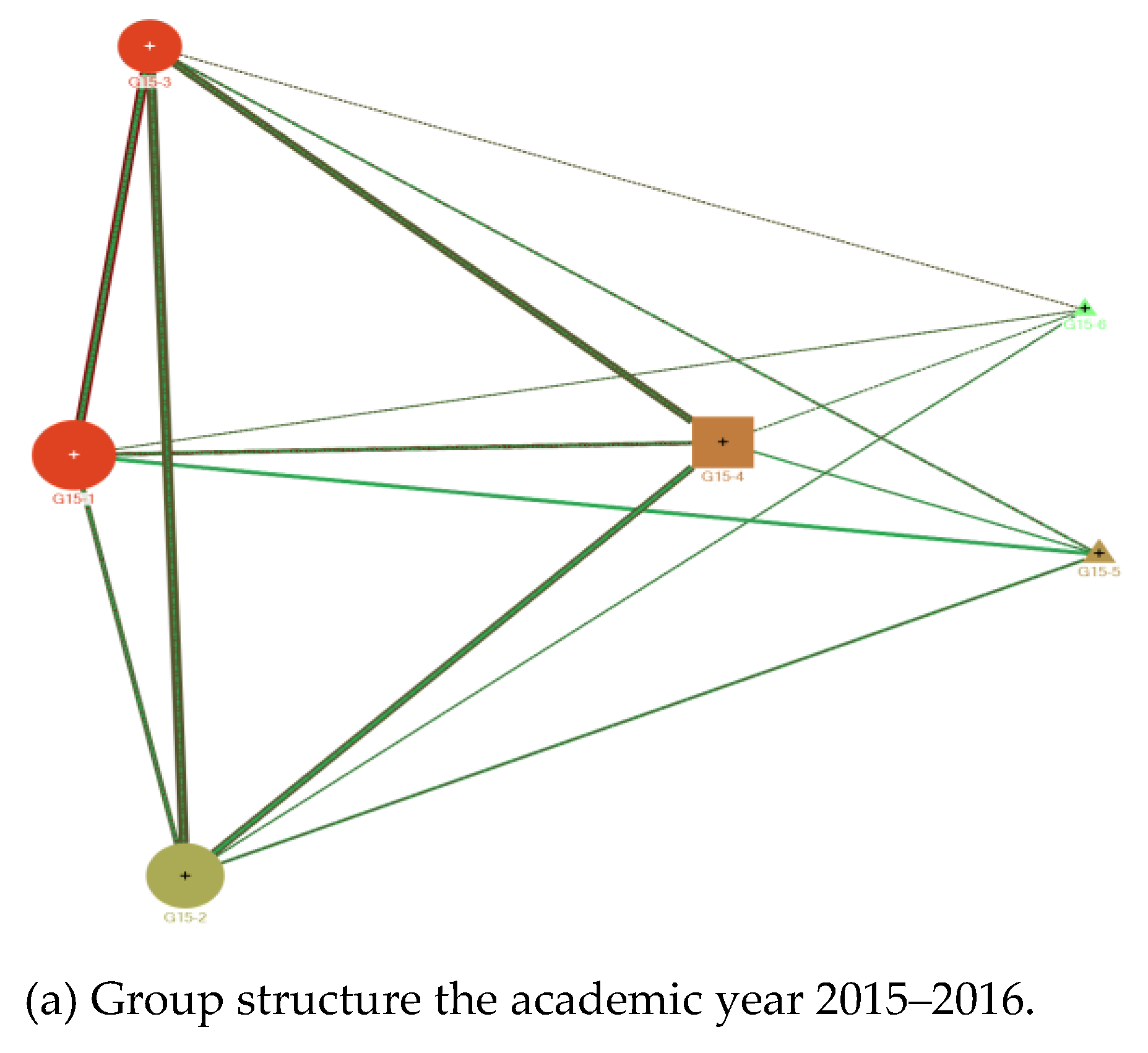
The second study tried to determine how students organise themselves in study groups. Using the Wakita–Tsurumi algorithm, study groups emerged from the data. The number of groups varied from academic year to academic year, and they also varied in the number of students and in their statistical and SNA measures (
Table 5). However, the groups of students can be further classified into three different types (
Table 6) according to a supervised clustering technique.
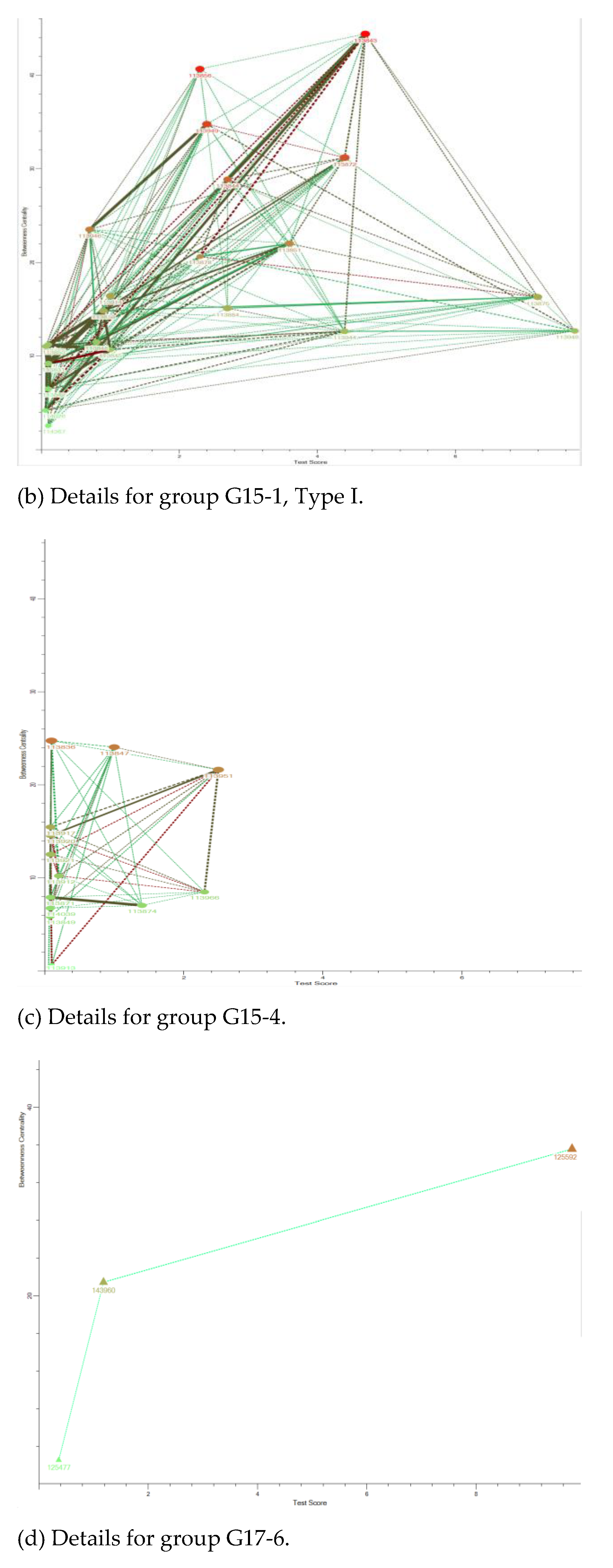
The study groups had an average size of more than 10 and less than 15, which indicates the number of individuals in the class with whom some of the individuals related to on an ongoing basis throughout the course. The relationship was not the same in every case, but each individual mixed better with some classmates than with others. If we consider the groups that emerged, it can be seen that there were direct relationships and relationships of relationships in the group. We identified three types of study groups. Those in Type I were those with the best results, with a more continuous and stable relationship throughout the course. They were students who have a soft relationship with their classmates and who were in study groups with an average size of 18.6, although these students had an average of 6.22 direct relationships in the study group, higher than the average for the network (4.46), compared to 4.22 for the type II group and 0.75 for type III. It could be said that their knowledge flowed more towards the group.
Our third research question was regarding the students with the best results. We saw that they had a Qsoft-type relationship in medium-sized study groups, and that their most continuous relationships were with students in their group at a similar level, while their Qhard relationships were few and with students in their group who had poor results. This leads us to posit that the student who knows less benefits (sometimes dishonestly) from the student who knows more. Another way of interpreting these results is to think that a student who understands the subject and interacts a lot with their classmates but in an honest way (possibly explaining and helping in the practical exercises) has better results in the exam. We understand that this is because they have reflected more on their knowledge, practiced and knew more methods to answer all the exam questions correctly in the exam’s period of time. There were also students who performed very poorly in Type I groups. Here, we can clearly infer which students were the source of knowledge and which were the recipients. In this case, the exam scores were very low, and there was a lot of similarity (Qhard or Qcheat relationships in the subnetwork of that study group) with the peers in the group (not necessarily with the top scorers but in a chain of relationships from one to another).
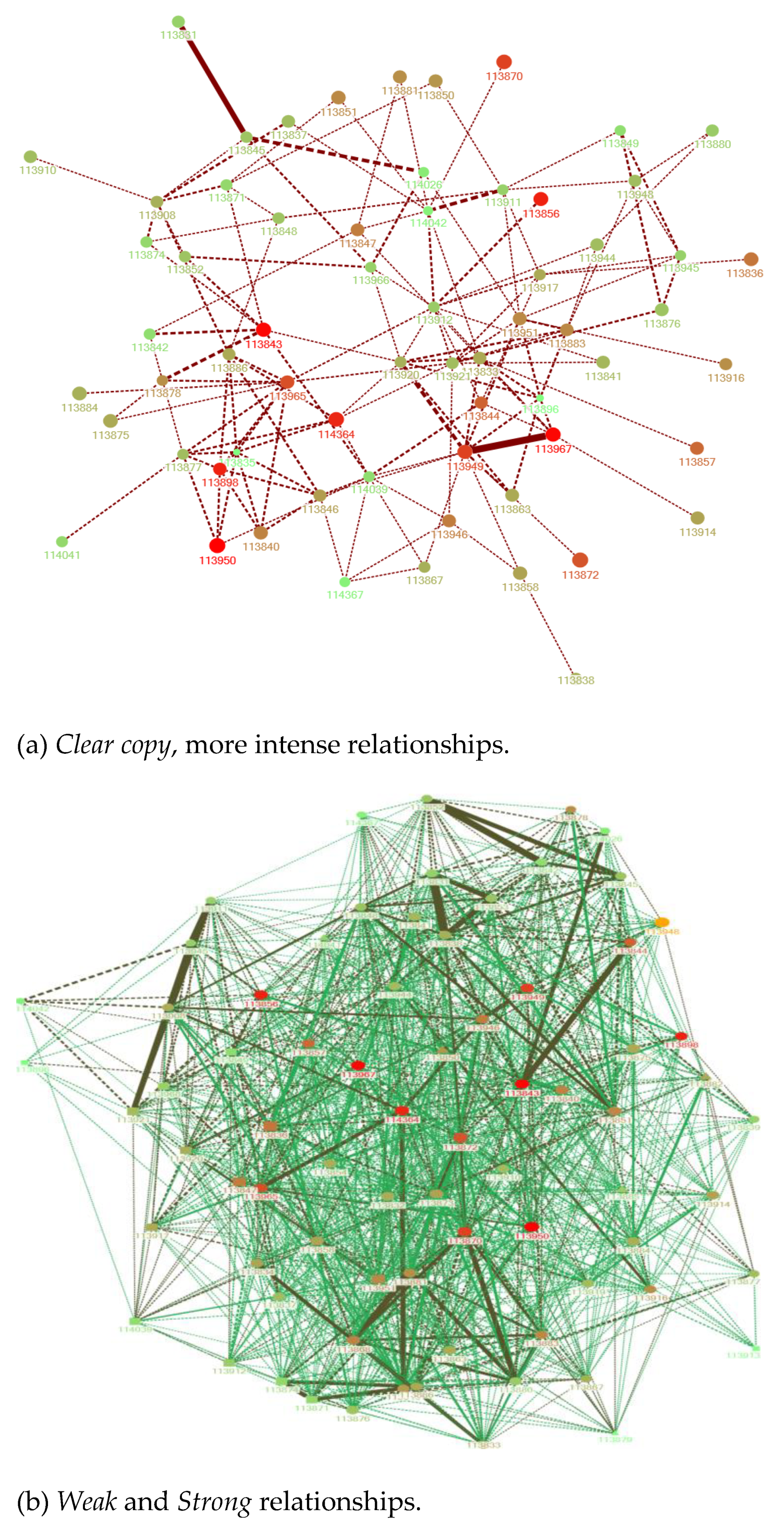
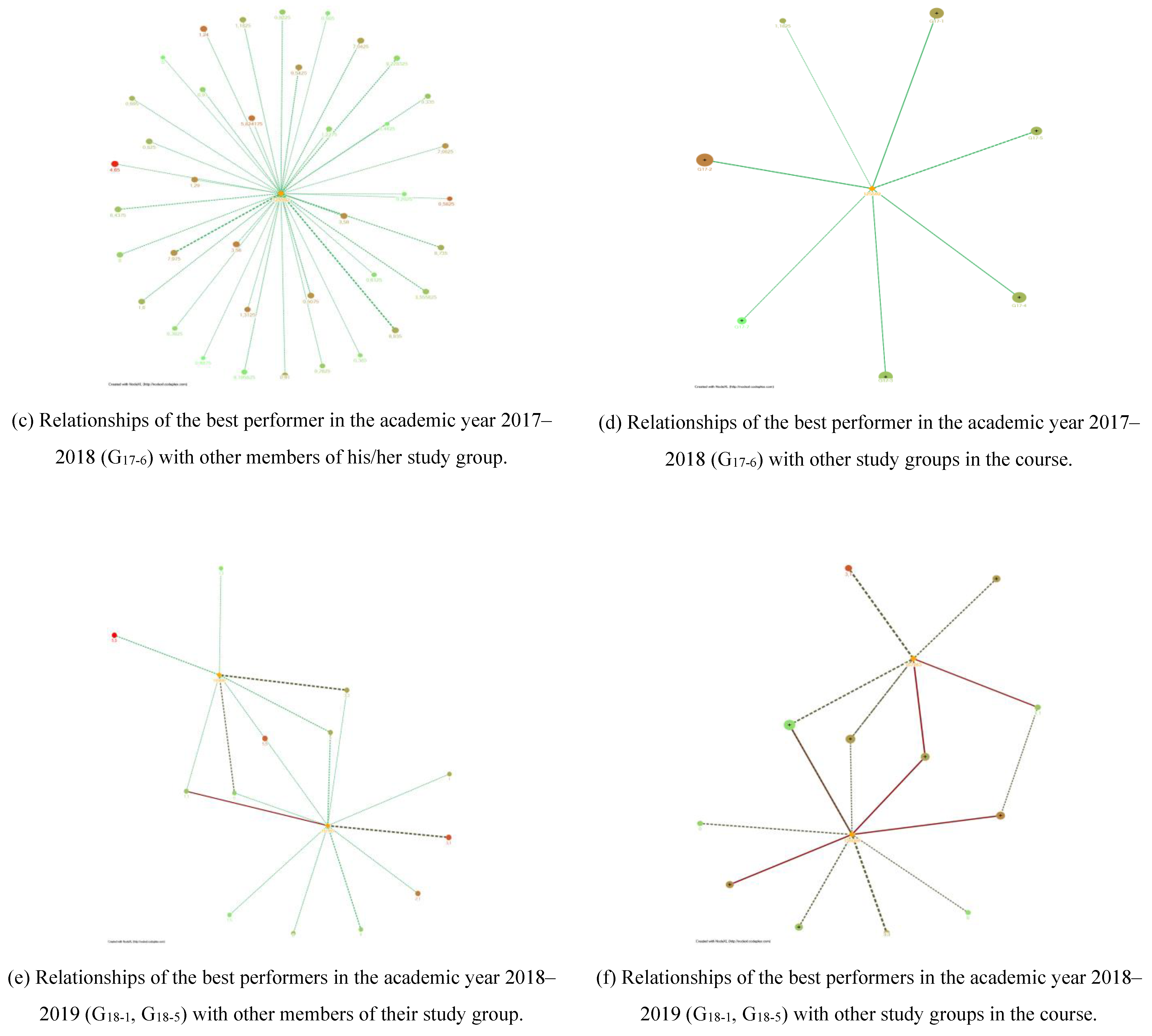
As we have seen in
Figure 10, the students with the best marks agglutinated in their direct relationships with students with very different profiles, and they always had some direct link to a node with high intermediation capacity (red) that allowed them to spread their knowledge among the rest of the group. The intensity of the direct relationships of an outstanding student with his peers varied from soft to cheat. This means that they interacted with their peers in different ways, but it can be interpreted as the advanced learner helping, explaining or even being copied by their peers. On the other hand, the intermediary nodes they interacted with had medium achievement, while the rest of the nodes had low achievement. This means that they interacted with students of the same level, and with these there was never a dishonest relationship. The relationship between nodes with higher marks usually did not exist or was of very low intensity, which tells us that the students gained an advantage in talking about their knowledge of the subject, but there was no evidence of transfer of material (no high similarity indexes). We can conclude that successful students had ethical behaviour and tried to help their colleagues. This conclusion is supported by analysing their social network. They were central nodes in the network and commonly belong to Type I study groups.
5.1. Limitations and Future Work
The present work was extensive and thorough, and the quantity and richness of the data we have allow us to carry out other studies that are also of great interest. We plan, for example, to conduct a study during the entire course to see how each student evolves in relation to the study groups and how the study groups themselves evolve. The first exercises were simple so that the student becomes familiar with the programming language, the programming environment and the automatic evaluation system. As they were first-year students, they did not have many acquaintances in the group at first. The difficulty increased as the course progressed, and so did the social relationships among students. This posed the challenge of establishing whether it was possible to infer from the data how the study groups were formed, how they evolved over time and their stability, performance and level of interaction. To address this task, we used TMOSS [
49], which analyses how students’ solutions evolve over time. Research is needed to define several phases over time, as well as a set of measures including exercise complexity modelling for the analysis.
In this article, the focus was on successful students and their relationship with the study groups. A detailed study of individuals and their behaviour in the groups remains to be conducted. It would be interesting to understand more about why they have little interaction with peers in the classroom. In the analysis of their documents, the scarce similarity that can be observed was due to the common background and the working style of the teacher. Are they shy students, are they socially integrated with their classmates? Do they show the same behaviour in other subjects? Is it because it is their first year at university?
An interesting aspect of the study’s topic that was not covered here concerns the reasons why students group together or why they cheat. Authors have worked on this topic (Sprajt et al., 2017) by asking students through questionnaires. We propose to model and automate the process with a mixed approach (quantitative and qualitative) to automatically detect situations that allow us to infer motives for some type of unethical behaviour in groups or individually.
An even more ambitious task would be to study a group throughout their entire degree. That would require observing students in at least one subject each year. The challenge is to see how long study groups last and what conditions make them effective for learning.
5.2. Implications
This research promotes the use of plagiarism control tools to obtain social relations between individuals and, from there it is possible to carry out sociological studies on how students work together. This approach is relevant because it proposes a new mechanism for grouping students—since most collaborative learning studies are carried out with groups distributed by the teacher—with specific conditions that aim to favour group work.
Another implication derived from this work is that, in Computer Science studies, students do not copy as much as the teacher initially perceives. Students often help each other, collaborate and share algorithms. However, they did this not in order to save time or improve their marks but as part of the training and learning process. The implication that follows from this conclusion concerns teachers: (1) it is necessary, so the students know how to act and to establish the boundaries between collaboration and cheating; (2) it is also the teacher’s task to propose work and conditions that favour the group’s learning process but that, at the same time, make it possible to differentiate between ethical and unethical behaviour.
It was found that the best performing groups were not made up of the best individual students but of students with different levels of knowledge. Moreover, they were not the largest or the smallest. Study groups arose for reasons more than just knowledge exchange; they were also grouped by social affinity. This implies that study groups were more of a social grouping. Apparently, the exchange of knowledge arises from the disparity of levels, which promotes group work and mutual help.
6. Conclusions
Our study focused on identifying and analysing the flow of knowledge that was produced and how it was produced for the realisation of different practical exercises in the course. The process was based on the similarity between the codes generated by each student. Therefore, the analysis carried out was quantitative in nature, but the social relationships that were established did not have a single goal. In fact, the groups that arose naturally in the classroom may be prompted by mutual convenience or for reasons of friendship, social affinity or other causes, which can only be established through multidisciplinary projects.
The first conclusion is that the study groups were beneficial, as collaboration is good. On the other hand, the affinity characteristics that promote grouping facilitate communication and learning mechanisms. Thus, those who were lagging behind benefited from the support of their peers, while those who were more advanced reinforced their learning by explaining or deepening their knowledge of the different topics. In this work, we identified, taking into account the metrics used, three different types of groups: Type I, II, and III.
Type I groups were characterised by a well-organised structure. They shared the task of knowledge generation and circulation. In this group, the most stable ethical study habits were consolidated, with a greater intensity of flow. In addition, Type I groups had a mainly academic objective, so they improved the performance of their members with ethical behaviour. Type II groups were characterised by a less organised circulation of knowledge flow and generated a less dense network with a weaker structure. On the other hand, a plausible hypothesis is that they may have had an origin external to the subject—a previous relationship or one built within the scope of the course—and therefore did not have an exclusively academic purpose. The most pronounced characteristic of Type III groups was that they formed a very loose network, with a very weak structure and low-intensity relationships. A plausible hypothesis could be that they were made up of students that cheated occasionally.
The social origin of the groups, in any case, requires another study to identify the psycho-social characteristics of the participants and relate them to the corresponding metrics of similarity, intensity and categories. Regarding the ethics of the observed behaviours, we can draw some interesting conclusions. There were not many cases of continuous dishonest behaviour among the students throughout the course.
Finally, in the subject under study, dishonest behaviour was low among the students. This is contrary to other studies on the subject in Computer Science and Engineering. As has already been discussed, we believe that this was due to the fact that the students knew that there was serious and strict control of the results they handed in, the penalties were harsh and the assignments were new every year. This leads us to think that avoiding dishonest behaviour is a task that affects both the students and the teaching staff, and by extension, the institution that certifies their degrees, i.e., their university.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













