Uncertainty Reduction of Unlabeled Features in Landslide Inventory Using Machine Learning t-SNE Clustering and Data Mining Apriori Association Rule Algorithms


 ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Study Area
3. Methodology
3.1. t-Distributed Stochastic Neighbor Embedding
3.2. Association Rule Learning
- First-item support: an indication of how frequently an itemset appears in the dataset. It is the number of records containing the itemset divided by the total number of records in the database.
- Confidence: the support count of x U y (i.e., the number of times “x” and “y” occur together) divided by the support count of “x.”
- Lift: the observed support relative to the support expected if “x” and “y” were independent. It is calculated as the support count of x U y divided by the product of individual support counts of “x” and “y” support the count of x U y divided by the product of individual support counts of “x” and “y.”
- Consistent classification: a fixed number of classes for each thematic map. All the continuous data were converted into a categorical data structure. The potential classification methods (equal interval, natural break, standard deviation, and quantile) are appropriate for different data structures and applications. In landslide research, natural breaks, which preserve the natural distribution of the histogram, including real steps or changes, are commonly used [21]. Jenks Natural Breaks (Fisher–Jenks optimization algorithm) in the R classInt package (https://github.com/r-spatial/classInt/) was used to classify the continuous data into five index classes (for consistency with other naturally categorized maps).
- Normalization of the classification with meaningful names, i.e., convert the integer values to ordinal listings. We used 5–1, representing very high, high, moderate, low, and very low values.
3.3. Lnadslides Inventory Validation
- A dark object subtraction algorithm was used to correct atmospheric effects on the multispectral bands.
- Inversion of principal component bands, produced by PCA, was used to reduce noise.
- The ETM+ panchromatic band (15 m) was used to enhance the spatial resolution of the ETM+ multispectral bands.
- A map of change was created, from both band ratios, using image differencing change detection.
- The resultant change maps were classified using the IsoData algorithm, which is more efficient than other unsupervised classification algorithms (k-means and Expectation Maximization) for automatic extraction of objects from multispectral data [24].
4. Results and Discussion
4.1. t-SNE Findings
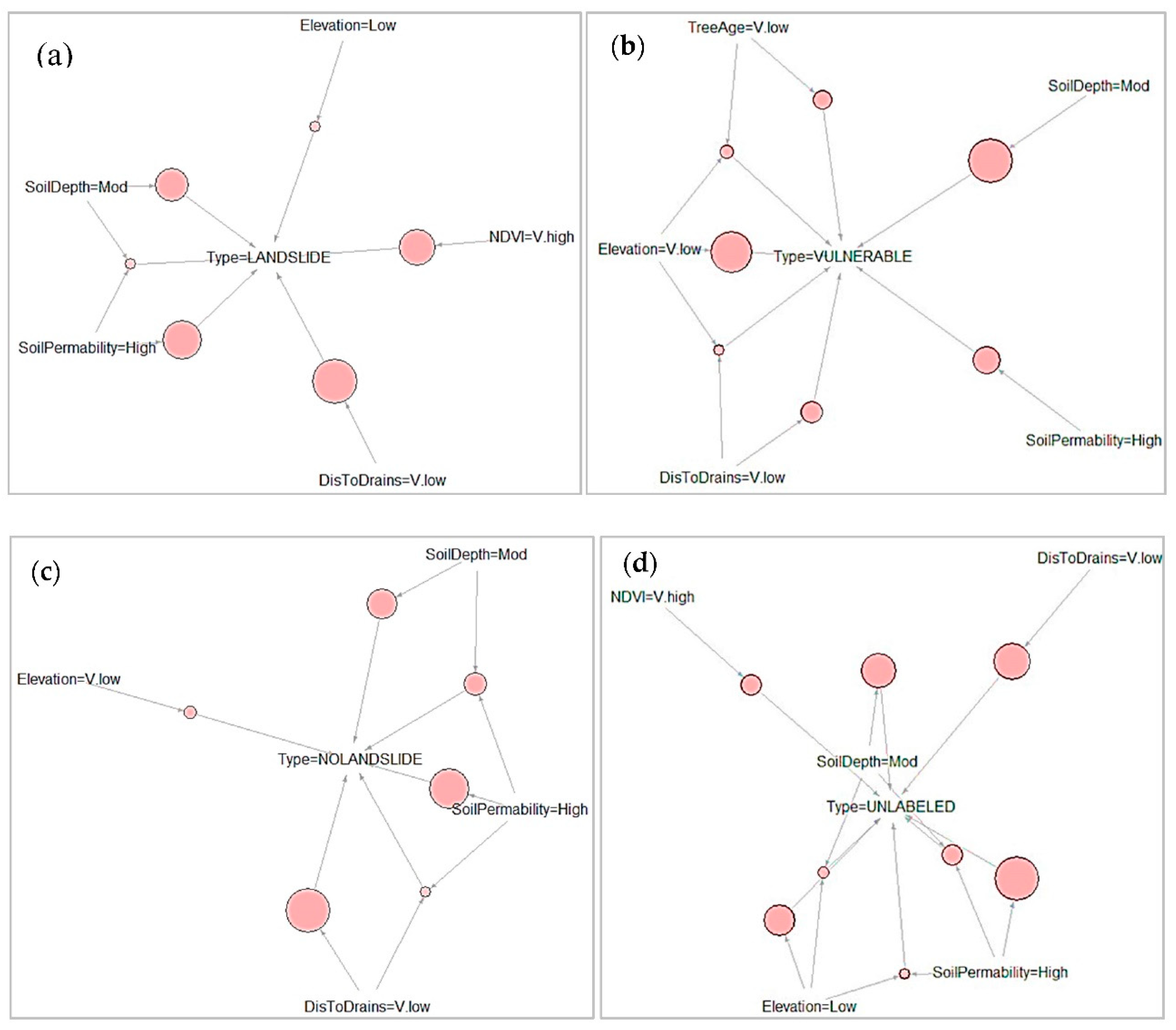
4.2. Apriori Analysis Results
4.3. Automatic Landslide Detection for Validation
- “A” represents the original inventory items count.
- “B” represents the total locations generated by the automatic classification change detection technique within all the inventory polygons (300 m diameter).
- “C” represents the maximum of one changes detected location per polygon in the study area.
- “C/A” represents is the ratio of polygons with a detected change to the number of original inventory items.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nilsen, T.H. Relative slope-stability mapping and land-use planning in the San Francisco Bay region, California. In Hillslope Processes; Routledge: London, UK, 2020. [Google Scholar]
- Althuwaynee, O.F.; Musakwa, W.; Gumbo, T.; Reis, S. Applicability of R statistics in analyzing landslides spatial patterns in Northern Turkey. In Proceedings of the 2017 2nd International Conference on Knowledge Engineering and Applications, ICKEA 2017, London, UK, 21–23 October 2017. [Google Scholar]
- Pokharel, B.; Althuwaynee, O.F.; Aydda, A.; Kim, S.-W.; Lim, S.; Park, H.-J. Spatial clustering and modelling for landslide susceptibility mapping in the north of the Kathmandu Valley, Nepal. Landslides 2020. [Google Scholar] [CrossRef]
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble decision tree-based CHi-squared Automatic Interaction Detection (CHAID) and multivariate logistic regression models in landslide susceptibility mapping. Landslides 2014, 11, 1063–1078. [Google Scholar] [CrossRef]
- Atangana Njock, P.G.; Shen, S.-L.; Zhou, A.; Lyu, H.-M. Evaluation of soil liquefaction using AI technology incorporating a coupled ENN/t-SNE model. Soil Dyn. Earthq. Eng. 2020, 130, 105988. [Google Scholar] [CrossRef]
- Brill, F.; Passuni Pineda, S.; Espichán Cuya, B.; Kreibich, H. A data-mining approach towards damage modelling for El Niño events in Peru. Geomat. Nat. Hazards Risk 2020, 11, 1966–1990. [Google Scholar] [CrossRef]
- Song, W.; Wang, L.; Liu, P.; Choo, K.K.R. Improved t-SNE based manifold dimensional reduction for remote sensing data processing. Multimed. Tools Appl. 2019, 78, 4311–4326. [Google Scholar] [CrossRef]
- Wong, K.Y.; Chung, F.-L. Visualizing Time Series Data with Temporal Matching Based t-SNE. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019; Department of Computing, Hong Kong Polytechnic University: Hong Kong, China, 2019. [Google Scholar]
- Halladin-Dabrowska, A.; Kania, A.; Kopeć, D. The t-SNE algorithm as a tool to improve the quality of reference data used in accurate mapping of heterogeneous non-forest vegetation. Remote Sens. 2020, 12, 39. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB’94, Santiago de, Chile, Chile, 12–15 September 1994. [Google Scholar]
- Duaimi, M.G.; Salman, A. Association rules mining for incremental database. Int. J. Adv. Res. Comput. Sci. Technol. 2014, 2, 346–352. [Google Scholar]
- Guo, W.; Zuo, X.; Yu, J.; Zhou, B. Method for mid-long-term prediction of landslides movements based on optimized Apriori algorithm. Appl. Sci. 2019, 9, 3819. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Zhan, F.B.; Zhang, K.; Deng, Q. Application of a two-step cluster analysis and the Apriori algorithm to classify the deformation states of two typical colluvial landslides in the Three Gorges, China. Environ. Earth Sci. 2016, 75, 1–16. [Google Scholar] [CrossRef]
- Aydda, A.; Algouti, A.; Algouti, A.; Essemani, M.; Taghya, Y. A new method to determine eroded areas in arid environment using Landsat satellite imagery. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Jakarta, Indonesia, 23–24 January 2014. [Google Scholar]
- Kim, K.S. Methods for Investigation and Analysis of Landslides on Natural Terrain in Korea. Ph.D. Thesis, Andong National University, Andong, Korea, 2006. [Google Scholar]
- Park, J.H.; Park, S. Analysis of Instances of Characteristics Land Creep on the Mine Area in Korea. J. Korean Soc. For. Sci. 2018, 107, 393–401. [Google Scholar]
- Van Der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Hahsler, M.; Grün, B.; Hornik, K. Arules—A computational environment for mining association rules and frequent item sets. J. Stat. Softw. 2005, 14, 1–25. [Google Scholar] [CrossRef]
- Toivonen, H. Apriori Algorithm. In Encyclopedia of Machine Learning and Data Mining; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Althuwaynee, O.F.; Pradhan, B.; Lee, S. Application of an evidential belief function model in landslide susceptibility mapping. Comput. Geosci. 2012, 44, 120–135. [Google Scholar] [CrossRef]
- Jeong, G.-C.; Kim, K.-S.; Choo, C.-O.; Kim, J.-T.; Kim, M.-I. Characteristics of landslides induced by a debris flow at different geology with emphasis on clay mineralogy in South Korea. Nat. Hazards 2011, 59, 347–365. [Google Scholar] [CrossRef]
- van der Meer, F.D.; van der Werff, H.M.A.; van Ruitenbeek, F.J.A.; Hecker, C.A.; Bakker, W.H.; Noomen, M.F.; van der Meijde, M.; Carranza, E.J.M.; de Smeth, J.B.; Woldai, T. Multi- and hyperspectral geologic remote sensing: A review. Int. J. Appl. Earth Obs. Geoinf. 2012, 14, 112–128. [Google Scholar] [CrossRef]
- Aydda, A.; Althuwaynee, O.F.; Pokharel, B. An easy method for barchan dunes automatic extraction from multispectral satellite data. In IOP Conference Series: Earth and Environmental Science; IOP Publishing Ltd: Bristol, UK, 2020. [Google Scholar]
- Pezzotti, N.; Lelieveldt, B.P.F.; Van Der Maaten, L.; Höllt, T.; Eisemann, E.; Vilanova, A. Approximated and user steerable tSNE for progressive visual analytics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1739–1752. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Jiang, X.; Hu, X.; Li, G. Visualization of genetic disease-phenotype similarities by multiple maps t-SNE with Laplacian regularization. BMC Med. Genomics 2014, 7, 1–9. [Google Scholar] [CrossRef] [Green Version]
- van der Maaten, L.; Hinton, G. User’s Guide for t-SNE Software. Structure 2008. Available online: https://sccn.ucsd.edu/svn/software/tags/EEGLAB7_0_2_9beta/external/fieldtrip-20090727/classification/toolboxes/maaten/tsne/tsne_user_guide2.pdf (accessed on 12 October 2020).
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble bivariate statistical evidential belief function with knowledge-based analytical hierarchy process and multivariate statistical logistic regression for landslide susceptibility mapping. Catena 2014, 114, 21–36. [Google Scholar] [CrossRef]
- Kayastha, P.; Dhital, M.R.; De Smedt, F. Application of the analytical hierarchy process (AHP) for landslide susceptibility mapping: A case study from the Tinau watershed, west Nepal. Comput. Geosci. 2013. [Google Scholar] [CrossRef]
- Lee, S.; Min, K. Statistical analysis of landslide susceptibility at Yongin, Korea. Environ. Geol. 2001. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Althuwaynee, O.F.; Aydda, A.; Hwang, I.-T.; Lee, Y.-K.; Kim, S.-W.; Park, H.-J.; Lee, M.-S.; Park, Y. Uncertainty Reduction of Unlabeled Features in Landslide Inventory Using Machine Learning t-SNE Clustering and Data Mining Apriori Association Rule Algorithms. Appl. Sci. 2021, 11, 556. https://doi.org/10.3390/app11020556
Althuwaynee OF, Aydda A, Hwang I-T, Lee Y-K, Kim S-W, Park H-J, Lee M-S, Park Y. Uncertainty Reduction of Unlabeled Features in Landslide Inventory Using Machine Learning t-SNE Clustering and Data Mining Apriori Association Rule Algorithms. Applied Sciences. 2021; 11(2):556. https://doi.org/10.3390/app11020556
Chicago/Turabian StyleAlthuwaynee, Omar F., Ali Aydda, In-Tak Hwang, Yoon-Kyung Lee, Sang-Wan Kim, Hyuck-Jin Park, Moon-Se Lee, and Yura Park. 2021. "Uncertainty Reduction of Unlabeled Features in Landslide Inventory Using Machine Learning t-SNE Clustering and Data Mining Apriori Association Rule Algorithms" Applied Sciences 11, no. 2: 556. https://doi.org/10.3390/app11020556
APA StyleAlthuwaynee, O. F., Aydda, A., Hwang, I.-T., Lee, Y.-K., Kim, S.-W., Park, H.-J., Lee, M.-S., & Park, Y. (2021). Uncertainty Reduction of Unlabeled Features in Landslide Inventory Using Machine Learning t-SNE Clustering and Data Mining Apriori Association Rule Algorithms. Applied Sciences, 11(2), 556. https://doi.org/10.3390/app11020556