An Identifier and Locator Decoupled Multicast Approach (ILDM) Based on ICN


Abstract
:1. Introduction
2. Related Work
2.1. IP Multicast
2.2. ICN Multicast
3. System Design
3.1. System Overview
3.2. Dynamic Core Management and Selection
3.2.1. Candidate Core Management
3.2.2. Core Discovery and Selection
3.2.3. Analysis of Core Load
3.3. Member Event Handling
3.4. Path State-Aware Multicast Tree Node Selection Mechanism
| Algorithm 1. Path State-Aware MTN Selection Algorithm | |
| Input: | |
| Output: | |
| 1: | Initialization: |
| 2: | for each in do: |
| 3: | Send Link Detection Message to the and get the and ; |
| 4: | if then: |
| 5: | ; |
| 6: | ; |
| 7: | ; |
| 9: | else if and then: |
| 10: | ; |
| 11: | ; |
| 12: | return |
3.5. Comparison of ILDM and PIM-SM
4. Simulation
4.1. Core Load
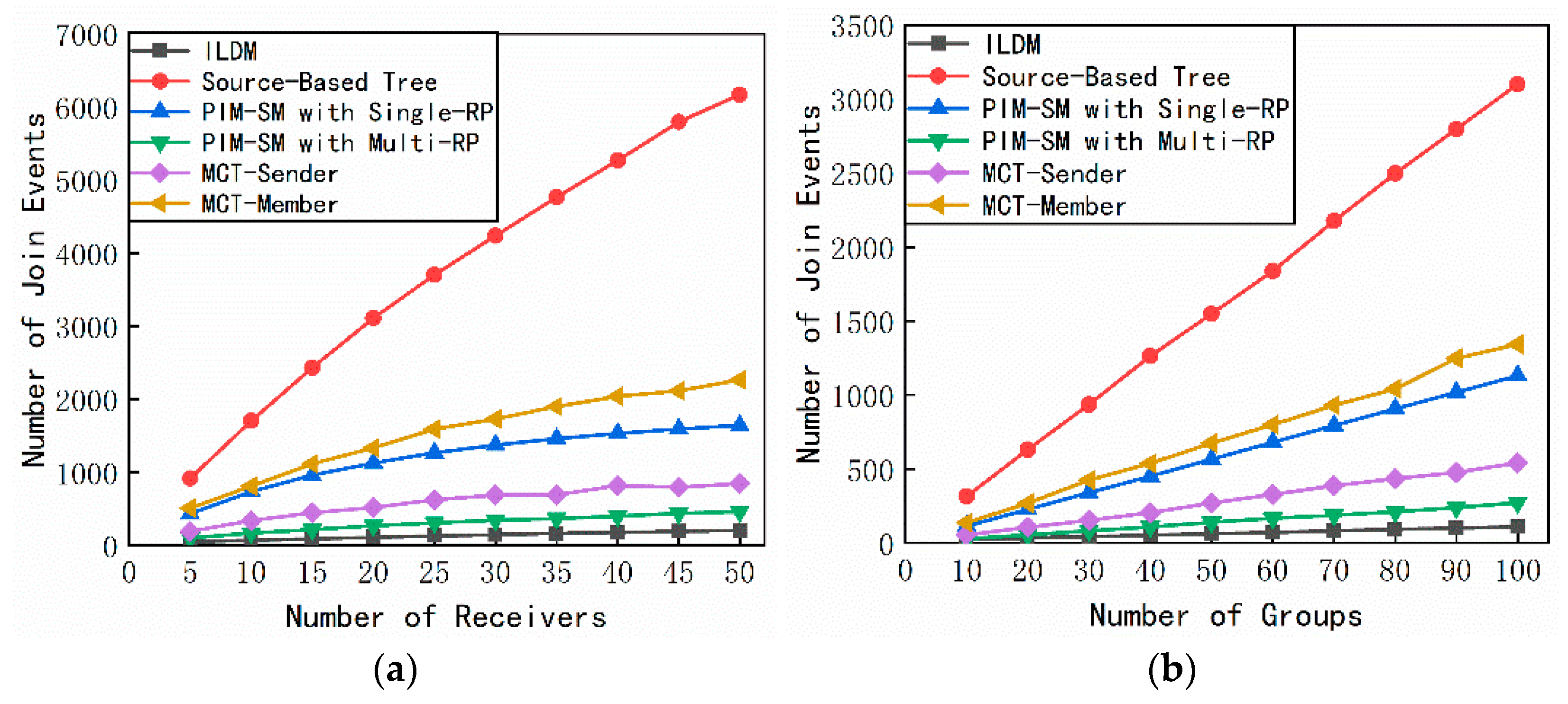
4.2. Number of Join Requests
4.3. Link Load
4.4. Traffic Concentration
4.5. Routing State
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Wang, G.; Baccelli, E.; Zhang, Y.; Burke, J.; Grieco, L.; Ravindran, R.; Raychadhuri, D. ICN based Architecture for IoT—Requirements and Challenges. Acm Sigmetrics Perform. Eval. Rev. 2015, 40, 65–76. [Google Scholar]
- Huang, J.; Duan, Q.; Zhao, Y.; Zheng, Z.; Wang, W. Multicast Routing for Multimedia Communications in the Internet of Things. IEEE Internet Things J. 2016, 4, 215–224. [Google Scholar] [CrossRef]
- Tsoukaneri, G.; Condoluci, M.; Mahmoodi, T.; Dohler, M.; Marina, M.K. Group Communications in Narrowband-IoT: Architecture, Procedures, and Evaluation. IEEE Internet Things J. 2018, 5, 1539–1549. [Google Scholar] [CrossRef] [Green Version]
- Cisco, V. Cisco Visual Networking Index: Forecast and Trends 2017–2022. White Pap. 2018, 1, 1. [Google Scholar]
- Baddi, Y.; Kettani, E.C.E. VNS-RP Algorithm for RP Selection in Multicast Routing Protocol PIM-SM. In Proceedings of the International Conference on Multimedia Computing and Systems, Tangier, Morocco, 10–12 May 2012. [Google Scholar]
- Wang, L.-X.; Cao, W.C. A Load Distribution Algorithm Based on an Ant Colony for Multi-Source Multicast Networks. J. Shandong Univ. (Nat. Sci.) 2011, 46, 28–32. [Google Scholar]
- Kumar, S.; Radoslavov, P.; Thaler, D.; Alaettino, L.C.; Estrin, D.; Handley, M. The MASC/BGMP Architecture for Inter-Domain Multicast Routing. In Proceedings of the ACM SIGCOMM ′98 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Vancouver, BC, Canada, 31 August–4 September 1998. [Google Scholar]
- Ahlgren, B.; Dannewitz, C.; Imbrenda, C.; Kutscher, D.; Ohlman, B. A survey of Information-Centric Networking. IEEE Commun. Mag. Artic. News Events Interest Commun. Eng. 2012, 50, 26–36. [Google Scholar] [CrossRef]
- Xylomenos, G.; Ververidis, C.N.; Siris, V.A.; Fotiou, N.; Tsilopoulos, C.; Vasilakos, X.; Katsaros, K.V.; Polyzos, G.C. A Survey of Information-Centric Networking Research. Commun. Surv. Tutor. IEEE 2014, 16, 1024–1049. [Google Scholar] [CrossRef]
- Jiang, X.; Bi, J.; Nan, G.; Li, Z. A Survey on Information-Centric Networking: Rationales, Designs and Debates. China Commun. 2015, 12, 1–12. [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking Named Nontent. Proc. Acm Conex. 2009, 1–12. [Google Scholar] [CrossRef]
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Papadopoulos, C.; Claffy, K.; Wang, L.; Crowley, P.; Zhang, B. Named Data Networking. Acm Sigcomm. Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Saxena, D.; Raychoudhury, V.; Suri, N.; Becker, C.; Cao, J. Named Data Networking: A survey. Comput. Rev. 2016, 19, 15–55. [Google Scholar] [CrossRef] [Green Version]
- Fotiou, N.; Nikander, P.; Trossen, D.; Polyzos, G.C. Developing Information Networking Further: From PSIRP to PURSUIT. In Proceedings of the International Conference on Broadband Communications, Networks and Systems, Athens, Greece, 25–27 October 2010; pp. 11–13. [Google Scholar] [CrossRef] [Green Version]
- Koponen, T.; Chawla, M.; Chun, B.G.; Ermolinskiy, A.; Stoica, I. A Data-Oriented (and Beyond) Network Architecture. ACM SIGCOMM Comput. Commun. Rev. 2007, 181–192. [Google Scholar] [CrossRef]
- Dannewitz, C.; Kutscher, D.; Ohlman, B.R.; Farrell, S.; Ahlgren, B.; Karl, H. Network of Information (NetInf)—An Information-Centric Networking Architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar] [CrossRef]
- Venkataramani, A.; Kurose, J.F.; Banerjee, S.; Raychaudhuri, D.; Nagaraja, K.; Mao, Z.M. MobilityFirst: A Mobility-Centric and Trustworthy Internet Architecture. ACM Sigcomm. Comput. Commun. Rev. 2014, 44, 74–80. [Google Scholar] [CrossRef]
- Bari, M.F.; Chowdhury, S.R.; Ahmed, R.; Boutaba, R.; Mathieu, B. A Survey of Naming and Routing in Information-Centric Networks. IEEE Commun. Mag. 2012, 50, 44–53. [Google Scholar] [CrossRef]
- Liao, Y.; Sheng, Y.; Wang, J. A Survey on the Name Resolution Technologies in Information Centric Networking. J. Netw. New Media 2020, 9, 1–9. [Google Scholar]
- Zeng, L.; Ni, H.; Han, R. An Incrementally Deployable IP-Compatible-Information-Centric Networking Hierarchical Cache System. Appl. Sci. 2020, 10, 6228. [Google Scholar] [CrossRef]
- Lt, J.M.; Com, G.J. Multicast Extensions to OSPF. Ietf RFC 1994, 11, 82–89. [Google Scholar]
- Lt, T.P.; Com, G.P. Distance Vector Multicast Routing Protocol. IEEE Commun. Soc. 1988, 33, 10. [Google Scholar]
- Adams, A.; Nicholas, J.; Siadak, W. Protocol Independent Multicast-Dense Mode (PIM-DM): Protocol Specification (Revised). RFC 3973. Available online: https://www.hjp.at/doc/rfc/rfc3973.html (accessed on 8 January 2021).
- Bhattacharyya, S.; Diot, C.; Giuliano, L.; Rockell, R.; Meylor, J. An Overview of Source-Specific Multicast (SSM). RFC 3569. Available online: https://www.hjp.at/doc/rfc/rfc3569.html (accessed on 8 January 2021).
- Ballardie, T.; Francis, P.; Crowcroft, J. Core Based Trees (CBT). Acm Sigcomm. Comput. Commun. Rev. 1993, 23, 85–95. [Google Scholar] [CrossRef]
- Estrin, D.; Farinacci, D.; Helmy, A.; Thaler, D.; Deering, S.; Handley, M.; Jacobson, V.; Liu, C.-G.; Sharma, P.; Wei, L. Protocol Independent Multicast-Sparse Mode (PIM-SM): Protocol Specification. RFC 2362. Available online: https://dl.acm.org/doi/pdf/10.17487/RFC2362 (accessed on 8 January 2021).
- Shields, C.; Garcia-Luna-Aceves, J.J. The ordered Core Based Tree Protocol. In Proceedings of the INFOCOM ‘97. Sixteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Kobe, Japan, 7–11 April 1997. [Google Scholar]
- Zappala, D.; Fabbri, A.; Lo, V. An Evaluation of Shared Multicast Trees with Multiple Active Cores. Telecommun. Syst. 2002, 19, 461–479. [Google Scholar] [CrossRef]
- Kabat, M.R.; Sahoo, S.P. Adaptive Tabu Search Algorithm for RP Selection in Protocol Independent Multicast—Sparse Mode. In Proceedings of the Information and Communication Technologies (WICT), 2011 World Congress, Piscataway, NJ, USA, 11–14 December 2011. [Google Scholar]
- Baddi, Y.; Kettani, E.C.E. D2V-VNS-RPS: Delay and Delay Variation Constrained Algorithm Based on Variable Neighborhood Search Algorithm for RP Selection Problem in PIM-SM Protocol. In Proceedings of the IEEE International Conference on Complex Systems (ICCS), Agadir, Morocco, 5–6 November 2012. [Google Scholar]
- Sinha, K.; Gupta, B.; Rahimi, S.; Bhattacharya, A. Candidate Core Selection for Load-Balanced Multicore Shared Tree Multicasting. In Proceedings of the 3rd International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 3–5 March 2016; pp. 35–40. [Google Scholar]
- Lee, D.L.; Youn, C.H.; Jeong, S.J. RP Reselection Scheme for Real-Time Applications in Delay-Constrained Multicast Networks. In Proceedings of the IEEE International Conference on Communications, New York, NY, USA, 28 April–2 May 2002. [Google Scholar]
- Ren, C.; Wang, S.; Ren, J.; Wang, X. Traffic Engineering and Manageability for Multicast Traffic in Hybrid SDN. KSII Trans. Internet Inf. Syst. 2018, 12. [Google Scholar]
- Liu, H.; Azhandeh, K.; de Foy, X.; Gazda, R. Comparative Study of Name Resolution and Routing Mechanisms in Information-Centric Networks. Digit. Commun. Netw. 2019, 5, 69–75. [Google Scholar] [CrossRef]
- D’Ambrosio, M.; Dannewitz, C.; Karl, H.; Vercellone, V. MDHT: A Hierarchical Name Resolution Service for Information-Centric Networks. In Proceedings of the ACM SIGCOMM Workshop on Information-Centric Networking, Toronto, ON, Canada, 15–19 August 2011. [Google Scholar]
- Dannewitz, C.; D’Ambrosio, M.; Vercellone, V. Hierarchical DHT-Based Name Resolution for Information-Centric Networks; Elsevier, B.V., Ed.; Elsevier Science Publishers: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Liao, Y.; Sheng, Y.; Wang, J. A Temporally Hierarchical Deployment Architecture for an Enhanced Name Resolution System. Appl. Sci. 2019, 9, 2891. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, S.; Bronzino, F.; Srinivasan, S.; Chen, J.; Raychaudhuri, D. Achieving Scalable Push Multicast Services Using Global Name Resolution. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- Yang, B.; Chen, X.; Xie, J.; Li, S.; Yang, J. Multicast Design for the MobilityFirst Future Internet Architecture. Proceedings of International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019. [Google Scholar]
- Medina, A.; Lakhina, A.; Matta, I.; Byers, J. BRITE: An Approach to Universal Topology Generation. In Proceedings of the International Workshop on Modeling, Cincinnati, OH, USA, 15–18 August 2001. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning | Symbol | Meaning |
|---|---|---|---|
| the load threshold of each router | the number of used cores | ||
| the number of routers | the load of the i-th core | ||
| the number of groups | the load of the core with the largest load | ||
| the number of sources per group |
| Symbol | Meaning | Symbol | Meaning |
|---|---|---|---|
| {} | the list of multicast tree nodes | the average link load of | |
| the optimal multicast tree node | the maximum link load of the | ||
| the maximum link load of | the average link load of the |
| Parameter | Value |
|---|---|
| CPUs | 8 Intel(R) Core (TM) i7-6700 CPU @ 3.40GHz |
| Memory | 16 GB |
| Operating system | Window10 |
| Topology | Waxman, |
| Node placement | Random |
| Number of routers | 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 100 |
| 5, 10, 15, 20, 25, 30, 35, 40, 45, 50 | |
| 5, 10, 15, 20, 25, 30, 35, 40, 45, 50 | |
| Number of groups | 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 120, 140, 160, 180, 200 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Wang, J. An Identifier and Locator Decoupled Multicast Approach (ILDM) Based on ICN. Appl. Sci. 2021, 11, 578. https://doi.org/10.3390/app11020578
Li B, Wang J. An Identifier and Locator Decoupled Multicast Approach (ILDM) Based on ICN. Applied Sciences. 2021; 11(2):578. https://doi.org/10.3390/app11020578
Chicago/Turabian StyleLi, Bo, and Jinlin Wang. 2021. "An Identifier and Locator Decoupled Multicast Approach (ILDM) Based on ICN" Applied Sciences 11, no. 2: 578. https://doi.org/10.3390/app11020578