
A Reinforcement Learning Algorithm for Automated Detection of Skin Lesions

 and
and
Abstract
:1. Introduction
- The skin lesion image segmentation is proposed as an MDP. It is solved with the DDPG algorithm, similar to how the physicians delineate the lesion image ROIs.
- The proposed skin image segmentation executor is based on the quadratic Bezier curve (QBC) and uses the action bundle as a hyperparameter to further improve the Acc of the segmentation process.
- We use a modified experience replay memory (ERM) to train the segmentation agent efficiently. The ERM helps in efficiently utilizing the previous experiences by learning multiple times.
- We perform a quantitative statistical analysis of our skin lesion segmentation results to show the reliability of our segmentation method and compare our results to the current state-of-the-art approaches.
2. Related Work
3. Proposed Method
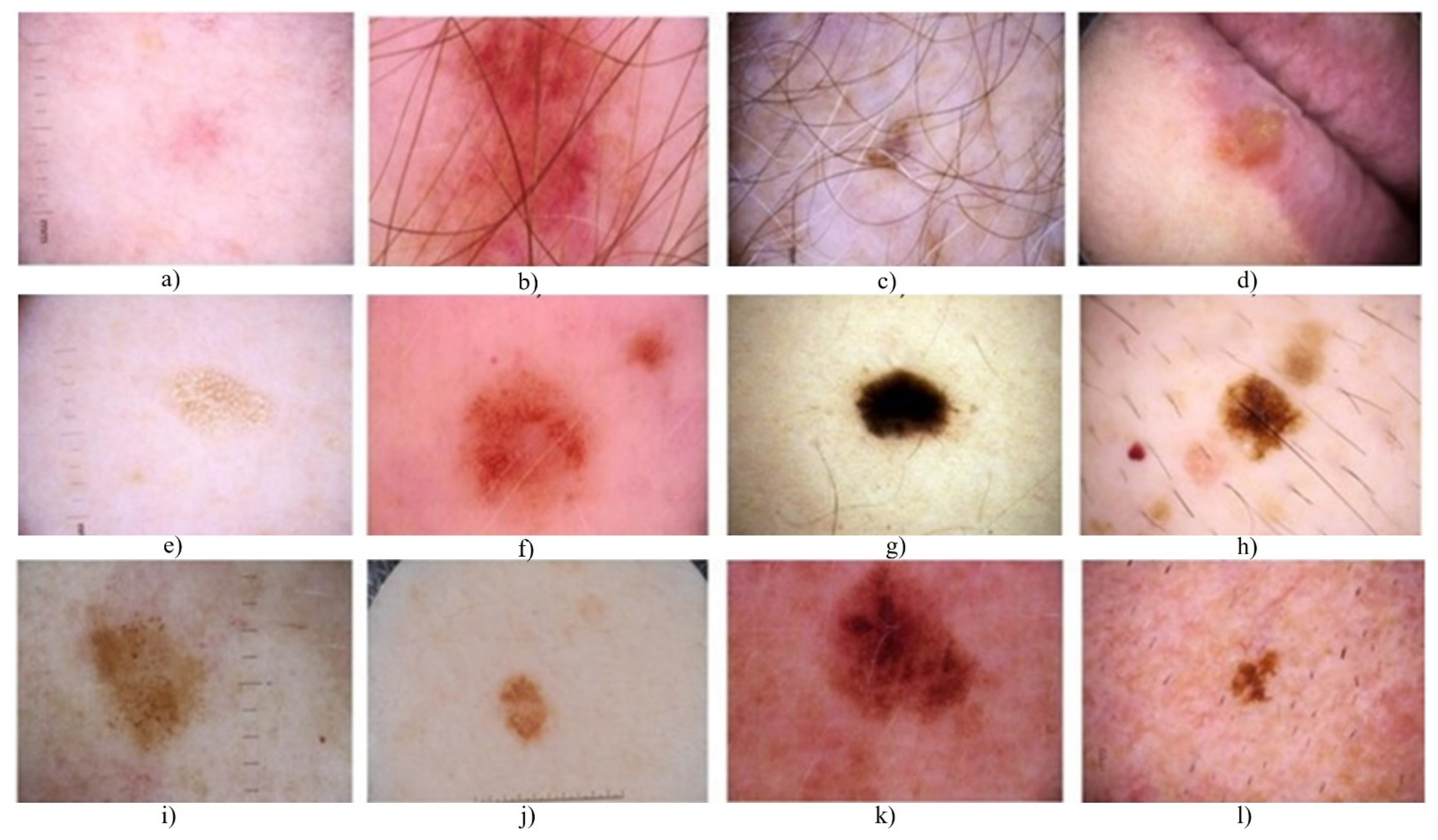
3.1. ISIC-2017 Segmentation Dataset
3.2. PH2 Dataset
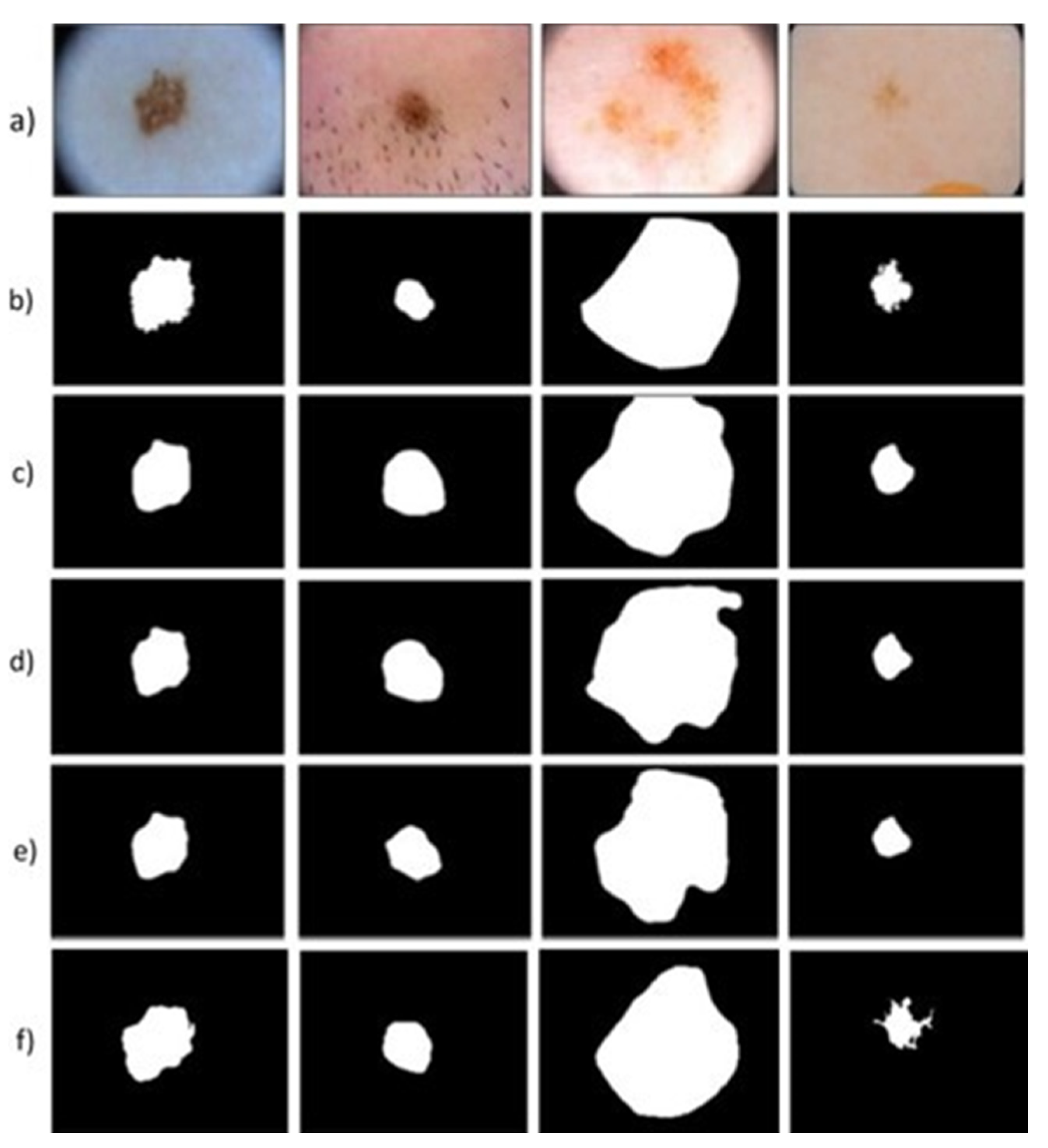
3.3. Overview of Our RL Method
| Algorithm 1 RL based image segmentation. |
| Randomly initializing actor network µ(s|θµ) and critic network Q(s, a|θQ) with weights θQ and θµ. |
| Initializing of the target networks µ’ and Q’ and weights θµ’ ← θµ, θQ’ ← θQ |
| Initializing of experience replay memory R |
| for episode e = 1, N do |
| Initializing a random process M for exploration of actions |
| Received s1 initial observation state |
| for x = 1, T do |
| Select action parameter set at = µ(st|θµ) + Nt accordingly to the exploration noise and the current policy |
| Feed the action parameters (As0,Ast,Ast+1,..AsT) in the segmentation executor. |
| Feed the updated segmentation mask Smt + 1 and the ground truth for computation of reward function r(t). |
| Execution of actions at and observing reward rt and observation of new state st+1 |
| Storing transition (st, at, rt, st+1) in R |
| Sampling of a random mini-batch (si, ai, ri, si+1) of N transitions from R |
| Set yi = ri + γQ’(si+1, µ’(si+1|θµ’)|θQ’) |
| Feed the ground truth Smt in the critic network |
| Feed the reward r(t) and long term expected return Q to the evaluation network. |
| Evaluation of the segmentation policy focused on reward r(t) and the long-term return Q. |
| Updating critic by minimize of the loss: L = 2 |
| Using the sampled policy gradient to update the actor policy: |
| ∇θµ J ≈ µ(s|θµ)|si |
| Updating the target networks: |
| θQ’ ← τθQ + (1 − τ) θQ’ |
| θµ’ ← τθµ + (1 − τ) θµ’ |
| end for |
| end for |
3.4. MDP for the Segmentation of Skin Lesion
3.5. Action Bundle and the Segmentation Executor
3.6. Modified ERM for DDPG
4. Results and Discussion
4.1. Experimental Setup
4.1.1. Implementation Details
4.1.2. Evaluation Metrics
4.1.3. Evaluation and Comparison on the ISIC 2017 Dataset, HAM10000, and the PH2 Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2016. CA Cancer J. Clin. 2016, 66, 7–30. [Google Scholar] [CrossRef] [Green Version]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Kroemer, S.; Frühauf, J.; Campbell, T.M.; Massone, C.; Schwantzer, G.; Soyer, H.P.; Hofmann-Wellenhof, R. Mobile teledermatology for skin tumour screening: Diagnostic accuracy of clinical and dermoscopic image tele-evaluation using cellular phones. Br. J. Dermatol. 2011, 164, 973–979. [Google Scholar] [CrossRef]
- Alves, J.; Moreira, D.; Alves, P.; Rosado, L.; Vasconcelos, M.J.M. Automatic focus assessment on dermoscopic images acquired with smartphones. Sensors 2019, 19, 4957. [Google Scholar] [CrossRef] [Green Version]
- Ngoo, A.; Finnane, A.; McMeniman, E.; Soyer, H.P.; Janda, M. Fighting melanoma with smartphones: A snapshot of where we are a decade after app stores opened their doors. Int. J. Med. Inform. 2018, 118, 99–112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stolz, W. ABCD rule of dermatoscopy: A new practical method for early recognition of malignant melanoma. Eur. J. Dermatol. 1994, 4, 521–527. [Google Scholar]
- Hazen, B.P.; Bhatia, A.C.; Zaim, T.; Brodell, R.T. The clinical diagnosis of early malignant melanoma: Expansion of the ABCD criteria to improve diagnostic sensitivity. Dermatol. Online J. 1999, 5, 3. [Google Scholar] [PubMed]
- Argenziano, G.; Fabbrocini, G.; Carli, P.; Giorgi, V.D.; Sammarco, E.; Delfino, M. Epiluminescence microscopy for the diagnosis of doubtful melanocytic skin lesions: Comparison of the ABCD rule of dermatoscopy and a new 7-point checklist based on pattern analysis. Arch. Dermatol. 1998, 134, 1563–1570. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pehamberger, H.; Steiner, A.; Wolff, K. In vivo epiluminescence microscopy of pigmented skin lesions. I. Pattern analysis of pigmented skin lesions. J. Am. Acad. Dermatol. 1987, 17, 571–583. [Google Scholar] [CrossRef]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P.A. Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Trans. Med. Imaging 2016, 36, 994–1004. [Google Scholar] [CrossRef]
- Liu, L.; Mou, L.; Zhu, X.X.; Mandal, M. Automatic skin lesion classification based on mid-level feature learning. Comput. Med. Imaging Graph. 2020, 84, 101765. [Google Scholar] [CrossRef] [PubMed]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (ISBI), hosted by the international skin imaging collaboration (ISIC). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Li, Y.; Shen, L. Skin lesion analysis towards melanoma detection using deep learning network. Sensors 2018, 18, 556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, V.K.; Abdel-Nasser, M.; Rashwan, H.A.; Akram, F.; Pandey, N.; Lalande, A.; Presles, B.; Romani, S.; Puig, D. FCA-net: Adversarial learning for skin lesion segmentation based on multi-scale features and factorized channel attention. IEEE Access 2019, 7, 130552–130565. [Google Scholar] [CrossRef]
- Yang, X.; Zeng, Z.; Yeo, S.Y.; Tan, C.; Tey, H.L.; Su, Y. A novel multi-task deep learning model for skin lesion segmentation and classification. arXiv 2017, arXiv:1703.01025. [Google Scholar]
- Xie, Y.; Zhang, J.; Xia, Y.; Shen, C. A mutual bootstrapping model for automated skin lesion segmentation and classification. IEEE Trans. Med. Imaging 2020, 39, 2482–2493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Humayun, J.; Malik, A.S.; Kamel, N. Multilevel thresholding for segmentation of pigmented skin lesions. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques, Penang, Malaysia, 17–18 May 2011; pp. 310–314. [Google Scholar]
- Mirikharaji, Z.; Hamarneh, G. Star shape prior in fully convolutional networks for skin lesion segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 737–745. [Google Scholar]
- Kaymak, R.; Kaymak, C.; Ucar, A. Skin lesion segmentation using fully convolutional networks: A comparative experimental study. Expert Syst. Appl. 2020, 161, 113742. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S. Interactive medical image segmentation using deep learning with image-specific fine tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 105–112. [Google Scholar]
- Xie, N.; Zhao, T.; Tian, F.; Zhang, X.H.; Sugiyama, M. Stroke-based stylization learning and rendering with inverse reinforcement learning. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wong, A.; Scharcanski, J.; Fieguth, P. Automatic skin lesion segmentation via iterative stochastic region merging. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 929–936. [Google Scholar] [CrossRef] [PubMed]
- Riaz, F.; Naeem, S.; Nawaz, R.; Coimbra, M. Active contours-based segmentation and lesion periphery analysis for characterization of skin lesions in dermoscopy images. IEEE J. Biomed. Health Inform. 2018, 23, 489–500. [Google Scholar] [CrossRef] [PubMed]
- Abbas, Q.; Fondón, I.; Sarmiento, A.; Celebi, M.E. An improved segmentation method for non-melanoma skin lesions using active contour model. In Proceedings of the International Conference Image Analysis and Recognition, Vilamoura, Portugal, 22–24 October 2014; pp. 193–200. [Google Scholar]
- Tang, J. A multi-direction GVF snake for the segmentation of skin cancer images. Pattern Recognit. 2009, 42, 1172–1179. [Google Scholar] [CrossRef]
- Jafari, M.H.; Samavi, S.; Soroushmehr, S.M.R.; Mohaghegh, H.; Karimi, N.; Najarian, K. Set of descriptors for skin cancer diagnosis using non-dermoscopic color images. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2638–2642. [Google Scholar]
- Ali, A.R.; Couceiro, M.S.; Hassenian, A.E. Melanoma detection using fuzzy C-means clustering coupled with mathematical morphology. In Proceedings of the 14th International Conference on Hybrid Intelligent Systems, Mubarak Al-Abdullah, Kuwait, 14–16 December 2014; pp. 73–78. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Maninis, K.K.; Caelles, S.; Pont-Tuset, J.; Gool, L.V. Deep extreme cut: From extreme points to object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 616–625. [Google Scholar]
- Jafari, M.H.; Karimi, N.; Nasr-Esfahani, E.; Samavi, S.; Soroushmehr, S.M.R.; Ward, K.; Najarian, K. Skin lesion segmentation in clinical images using deep learning. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 337–342. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Berseth, M. ISIC 2017-skin lesion analysis towards melanoma detection. arXiv 2017, arXiv:1703.00523. [Google Scholar]
- Chang, H. Skin cancer reorganization and classification with deep neural network. arXiv 2017, arXiv:1703.00534. [Google Scholar]
- Liu, L.; Mou, L.; Zhu, X.X.; Mandal, M. Skin Lesion Segmentation based on improved U-net. In Proceedings of the IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4. [Google Scholar]
- Abhishek, K.; Hamarneh, G.; Drew, M.S. Illumination-based transformations improve skin lesion segmentation in dermoscopic images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 728–729. [Google Scholar]
- Yuan, Y. Automatic skin lesion segmentation with fully convolutional-deconvolutional networks. arXiv 2017, arXiv:1703.05165. [Google Scholar]
- Al-Masni, M.A.; Al-Antari, M.A.; Choi, M.T.; Han, S.M.; Kim, T.S. Skin lesion segmentation in dermoscopy images via deep full resolution convolutional networks. Comput. Methods Programs Biomed. 2018, 162, 221–231. [Google Scholar] [CrossRef]
- Bi, L.; Kim, J.; Ahn, E.; Kumar, A.; Feng, D.; Fulham, M. Step-wise integration of deep class-specific learning for dermoscopic image segmentation. Pattern Recognit. 2019, 85, 78–89. [Google Scholar] [CrossRef] [Green Version]
- Sarker, M.M.K.; Rashwan, H.A.; Akram, F.; Banu, S.F.; Saleh, A.; Singh, V.K.; Chowdhury, F.U.; Abdulwahab, S.; Romani, S.; Radeva, P. SLSDeep: Skin lesion segmentation based on dilated residual and pyramid pooling networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 21–29. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Karthik, R.; Gupta, U.; Jha, A.; Rajalakshmi, R.; Menaka, R. A deep supervised approach for ischemic lesion segmentation from multimodal MRI using Fully Convolutional Network. Appl. Soft Comput. 2019, 84, 105685. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-preserving mask r-cnn. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 660–676. [Google Scholar]
- Kim, M.; Woo, S.; Kim, D.; Kweon, I.S. The devil is in the boundary: Exploiting boundary representation for basis-based instance segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–9 January 2021; pp. 929–938. [Google Scholar]
- Castrejon, L.; Kundu, K.; Urtasun, R.; Fidler, S. Annotating object instances with a polygon-rnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5230–5238. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Lu, H.; Kondo, M.; Li, Y.; Tan, J.; Kim, H.; Murakami, S.; Aoki, T.; Kido, S. Supervoxel graph cuts: An effective method for ggo candidate regions extraction on CT images. IEEE Consum. Electron. Mag. 2019, 9, 61–66. [Google Scholar] [CrossRef]
- Lu, H.; Li, B.; Zhu, J.; Li, Y.; Li, Y.; Xu, X.; He, L.; Li, X.; Li, J.; Serikawa, S. Wound intensity correction and segmentation with convolutional neural networks. Concurr. Comput. Pract. Exp. 2017, 29, e3927. [Google Scholar] [CrossRef]
- Yoshino, Y.; Miyajima, T.; Lu, H.; Tan, J.; Kim, H.; Murakami, S.; Aoki, T.; Tachibana, R.; Hirano, Y.; Kido, S. Automatic classification of lung nodules on MDCT images with the temporal subtraction technique. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1789–1798. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Jagadeesan, S.; Subbiah, J. Real-time personalization and recommendation in Adaptive Learning Management System. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4731–4741. [Google Scholar] [CrossRef]
- Kim, D.; Lee, T.; Kim, S.; Lee, B.; Youn, H.Y. Adaptive packet scheduling in IoT environment based on Q-learning. Procedia Comput. Sci. 2018, 141, 247–254. [Google Scholar] [CrossRef]
- Alansary, A.; Oktay, O.; Li, Y.; Folgoc, L.L.; Hou, B.; Vaillant, G.; Kamnitsas, K.; Vlontzos, A.; Glocker, B.; Kainz, B. Evaluating reinforcement learning agents for anatomical landmark detection. Med. Image Anal. 2019, 53, 156–164. [Google Scholar] [CrossRef] [Green Version]
- Caicedo, J.C.; Lazebnik, S. Active object localization with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Liu, F.; Li, S.; Zhang, L.; Zhou, C.; Ye, R.; Wang, Y.; Lu, J. 3DCNN-DQN-RNN: A deep reinforcement learning framework for semantic parsing of large-scale 3D point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5678–5687. [Google Scholar]
- Rao, Y.; Lu, J.; Zhou, J. Attention-aware deep reinforcement learning for video face recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3931–3940. [Google Scholar]
- Sahba, F.; Tizhoosh, H.R.; Salama, M.M. Application of reinforcement learning for segmentation of transrectal ultrasound images. BMC Med. Imaging 2008, 8, 8. [Google Scholar] [CrossRef] [Green Version]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Wang, Z.; Sarcar, S.; Liu, J.; Zheng, Y.; Ren, X. Outline objects using deep reinforcement learning. arXiv 2018, arXiv:1804.04603. [Google Scholar]
- Song, G.; Myeong, H.; Lee, K.M. Seednet: Automatic seed generation with deep reinforcement learning for robust interactive segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1760–1768. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Finlayson, G.D.; Trezzi, E. Shades of gray and colour constancy. In Proceedings of the Color and Imaging Conference, Scottsdale, AZ, USA, 9–12 November 2004; Volume 2, pp. 37–41. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International conference on machine learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2000; pp. 1057–1063. [Google Scholar]
- Xu, X.; Lu, H.; Song, J.; Yang, Y.; Shen, H.T.; Li, X. Ternary adversarial networks with self-supervision for zero-shot cross-modal retrieval. IEEE Trans. Cybern. 2019, 50, 2400–2413. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Arora, R.; Raman, B.; Nayyar, K.; Awasthi, R. Automated skin lesion segmentation using attention-based deep convolutional neural network. Biomed. Signal Process. Control. 2021, 65, 102358. [Google Scholar] [CrossRef]
- Sarker, M.M.K.; Rashwan, H.A.; Akram, F.; Singh, V.K.; Banu, S.F.; Chowdhury, F.U.; Choudhury, K.A.; Chambon, S.; Radeva, P.; Puig, D. SLSNet: Skin lesion segmentation using a lightweight generative adversarial network. Expert Syst. Appl. 2021, 183, 115433. [Google Scholar] [CrossRef]
- Liu, L.; Tsui, Y.Y.; Mandal, M. Skin lesion segmentation using deep learning with auxiliary task. J. Imaging 2021, 7, 67. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Jiang, X.; Ding, H.; Zhao, Y.; Liu, J. Knowledge-aware Deep Framework for Collaborative Skin Lesion Segmentation and Melanoma Recognition. Pattern Recognit. 2021, 120, 108075. [Google Scholar] [CrossRef]
- Wibowo, A.; Purnama, S.R.; Wirawan, P.W.; Rasyidi, H. Lightweight encoder-decoder model for automatic skin lesion segmentation. Inform. Med. Unlocked 2021, 25, 100640. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Measure | Basic Model | Modified ERM Included | With Action Bundle | With Both | K = 1 | K = 3 | K = 5 | K = 7 |
|---|---|---|---|---|---|---|---|---|
| Dice Index | 93.00 | 93.98 | 94.0 | 95.7 | 93.0 | 93.98 | 95.79 | 94.0 |
| Method | Dice Score | Jaccard Index | Acc | Sen | Spe |
|---|---|---|---|---|---|
| U-Net [36] | 0.89 | 0.81 | 0.94 | 0.93 | 0.94 |
| U-Net (all 64 filters) [37] | 0.90 | 0.81 | 0.94 | 0.93 | 0.95 |
| SE_U-Net [51] | 0.91 | 0.83 | 0.95 | 0.89 | 0.96 |
| BCDU [52] | 0.90 | 0.82 | 0.94 | 0.94 | 0.95 |
| Attn_U-Net+GN [75] | 0.91 | 0.83 | 0.95 | 0.94 | 0.95 |
| FCN-16s [15] | 0.88 | 0.80 | 0.91 | 0.93 | 0.88 |
| DeepLab V3+ [51] | 0.89 | 0.81 | 0.92 | 0.94 | 0.89 |
| Mask R-CNN [48] | 0.90 | 0.83 | 0.93 | 0.96 | 0.89 |
| Ensemble-S [75] | 0.93 | 0.90 | 0.83 | 0.96 | 0.92 |
| Xie et al. [16] | 0.88 | 0.80 | 0.92 | 0.98 | 0.86 |
| Sarker et al. [44] | 0.88 | 0.80 | 0.91 | 0.98 | 0.85 |
| SLSNet [76] | 0.90 | 0.81 | 0.94 | 0.87 | 0.95 |
| Lina et al. [77] | 0.87 | 0.79 | 0.94 | 0.88 | 0.95 |
| Wang et al. [78] | 0.89 | 0.82 | 0.87 | 0.62 | 0.94 |
| Wibowo et al. [79] | 0.88 | 0.80 | 0.93 | 0.86 | 0.96 |
| Our RL algorithm (proposed) | 0.94 | 0.92 | 0.96 | 0.9859 | 0.985 |
| Method | Acc | Dice Score | Jaccard Index | Sen | Spe |
|---|---|---|---|---|---|
| First: Yading Yuan (CDNN model) [35] | 0.934 | 0.849 | 0.765 | 0.825 | 0.975 |
| Second: Matt Berseth (U- Net) [37] | 0.932 | 0.847 | 0.762 | 0.820 | 0.978 |
| U-Net [36] | 0.901 | 0.763 | 0.616 | 0.672 | 0.972 |
| SegNet [38] | 0.918 | 0.821 | 0.696 | 0.801 | 0.954 |
| FrCN [47] | 0.940 | 0.870 | 0.771 | 0.854 | 0.967 |
| Ensemble-S [75] | 0.933 | 0.844 | 0.760 | 0.806 | 0.979 |
| Xie et al. [16] | 0.939 | 0.866 | 0.788 | 0.877 | 0.955 |
| Sarker et al. [44] | 0.941 | 0.871 | 0.793 | 0.899 | 0.950 |
| SLSNet [76] | 0.944 | 0.875 | 0.777 | 0.841 | 0.953 |
| Lina et al. [77] | 0.941 | 0.867 | 0.790 | 0.892 | 0.939 |
| Wang et al. [78] | 0.873 | 0.898 | 0.829 | 0.590 | 0.941 |
| Wibowo et al. [79] | 0.938 | 0.877 | 0.802 | 0.862 | 0.963 |
| Our RL algorithm (proposed) | 0.9539 | 0.957 | 0.840 | 0.950 | 0.985 |
| Method | Naevus | Melanoma | Seborrheic Keratosis | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dice | JSI | MCC | Dice | JSI | MCC | DICE | JSI | MCC | DICE | JSI | MCC | |
| FCN-AlexNet [10] | 85.61 | 77.01 | 82.91 | 75.94 | 64.32 | 70.35 | 75.09 | 63.76 | 71.51 | 82.15 | 72.55 | 78.75 |
| FCN-32s [11] | 85.08 | 76.39 | 82.29 | 78.39 | 67.23 | 72.70 | 76.18 | 64.78 | 72.10 | 82.44 | 72.86 | 78.89 |
| FCN-16s [15] | 85.60 | 77.39 | 82.92 | 79.22 | 68.41 | 73.26 | 75.23 | 64.11 | 71.42 | 82.80 | 73.65 | 79.31 |
| FCN-8s [41] | 85.33 | 76.07 | 81.73 | 80.08 | 69.58 | 74.39 | 68.01 | 56.54 | 65.14 | 81.06 | 71.87 | 77.81 |
| DeepLabV3+ [51] | 88.29 | 81.09 | 85.90 | 80.86 | 71.30 | 76.01 | 77.05 | 67.55 | 74.62 | 85.16 | 77.15 | 82.28 |
| Mask R-CNN [48] | 88.83 | 80.91 | 85.38 | 80.28 | 70.69 | 74.95 | 80.48 | 70.74 | 76.31 | 85.58 | 77.39 | 81.99 |
| Ensemble-S [75] | 87.93 | 80.46 | 85.58 | 78.45 | 68.42 | 73.61 | 76.88 | 66.62 | 74.05 | 84.42 | 76.03 | 81.51 |
| Xie et al. [16] | 88.87 | 81.69 | 85.93 | 83.05 | 74.01 | 77.98 | 81.71 | 72.50 | 77.68 | 86.66 | 78.82 | 83.14 |
| Sarker et al. [42] | 89.28 | 82.11 | 86.33 | 83.54 | 74.53 | 78.08 | 82.53 | 73.45 | 78.61 | 87.14 | 79.34 | 83.57 |
| SLSNet [76] | 86.59 | 78.76 | 79.80 | 92.12 | 79.25 | 79.53 | 86.12 | 74.52 | 77.12 | 88.27 | 77.54 | 78.81 |
| Lina et al. [77] | 87.12 | 80.35 | 85.14 | 86.25 | 78.69 | 80.25 | 84.35 | 81.32 | 83.25 | 85.90 | 80.12 | 82.88 |
| Wang et al. [78] | 88.12 | 79.14 | 80.12 | 89.12 | 77.24 | 80.37 | 86.37 | 83.40 | 81.42 | 87.87 | 79.90 | 80.63 |
| Wibowo et al. [79] | 86.32 | 79.45 | 81.22 | 85.67 | 76.27 | 80.27 | 85.39 | 79.58 | 79.38 | 85.79 | 78.40 | 80.29 |
| Our RL algorithm | 93.00 | 89.57 | 90.78 | 95.79 | 91.93 | 87.11 | 95.00 | 93.23 | 92.74 | 94.59 | 91.57 | 90.21 |
| Method | Naevus | Melanoma | Seborrheic Keratosis | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sen | Spe | Acc | Sen | Spe | Acc | Sen | Spe | Acc | Sen | Spe | Acc | |
| FCN-AlexNet [10] | 82.44 | 97.58 | 94.84 | 72.35 | 96.23 | 87.82 | 71.70 | 97.92 | 89.35 | 78.86 | 97.37 | 92.65 |
| FCN-32s [11] | 83.67 | 96.69 | 94.59 | 74.36 | 96.32 | 88.94 | 75.80 | 96.41 | 89.45 | 80.67 | 96.72 | 92.72 |
| FCN-16s [15] | 84.23 | 96.91 | 94.67 | 75.14 | 96.27 | 89.24 | 75.48 | 96.25 | 88.83 | 81.14 | 96.68 | 92.74 |
| FCN-8s [41] | 83.91 | 97.22 | 94.55 | 78.37 | 95.96 | 89.63 | 69.85 | 96.57 | 87.40 | 80.72 | 96.87 | 92.52 |
| DeepLabV3+ [51] | 88.54 | 97.21 | 95.67 | 77.31 | 96.37 | 89.65 | 74.59 | 98.55 | 90.06 | 83.34 | 97.25 | 93.66 |
| Mask R-CNN [48] | 87.25 | 96.38 | 95.32 | 78.63 | 95.63 | 89.31 | 82.41 | 94.88 | 90.85 | 84.84 | 96.01 | 93.48 |
| Ensemble-S [75] | 84.74 | 97.98 | 95.58 | 73.35 | 97.30 | 88.40 | 71.80 | 98.58 | 89.91 | 80.58 | 97.94 | 93.33 |
| Xie et al. [16] | 90.93 | 95.74 | 95.51 | 83.40 | 95.00 | 90.61 | 85.81 | 94.74 | 91.34 | 88.70 | 95.45 | 93.93 |
| Sarker et al. [42] | 92.08 | 95.37 | 95.59 | 84.62 | 94.20 | 90.85 | 87.48 | 94.41 | 91.72 | 89.93 | 95.00 | 94.08 |
| SLSNet [76] | 86.23 | 94.22 | 93.61 | 85.94 | 93.65 | 92.52 | 84.18 | 94.21 | 93.81 | 85.45 | 94.02 | 93.44 |
| Lina et al. [77] | 87.22 | 94.25 | 93.14 | 85.56 | 93.57 | 92.58 | 86.38 | 94.12 | 91.22 | 86.38 | 93.98 | 92.31 |
| Wang et al. [78] | 63.54 | 93.25 | 86.54 | 66.51 | 94.31 | 85.62 | 68.05 | 93.72 | 84.33 | 66.03 | 93.76 | 85.49 |
| Wibowo et al. [79] | 86.25 | 95.29 | 92.56 | 87.12 | 94.32 | 91.29 | 86.32 | 93.25 | 90.98 | 86.56 | 94.28 | 91.61 |
| Our RL algorithm | 96.79 | 98.60 | 96.33 | 93.96 | 98.59 | 95.39 | 93.39 | 98.60 | 94.27 | 96.25 | 98.50 | 95.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Usmani, U.A.; Watada, J.; Jaafar, J.; Aziz, I.A.; Roy, A. A Reinforcement Learning Algorithm for Automated Detection of Skin Lesions. Appl. Sci. 2021, 11, 9367. https://doi.org/10.3390/app11209367
Usmani UA, Watada J, Jaafar J, Aziz IA, Roy A. A Reinforcement Learning Algorithm for Automated Detection of Skin Lesions. Applied Sciences. 2021; 11(20):9367. https://doi.org/10.3390/app11209367
Chicago/Turabian StyleUsmani, Usman Ahmad, Junzo Watada, Jafreezal Jaafar, Izzatdin Abdul Aziz, and Arunava Roy. 2021. "A Reinforcement Learning Algorithm for Automated Detection of Skin Lesions" Applied Sciences 11, no. 20: 9367. https://doi.org/10.3390/app11209367