
Gate Attentional Factorization Machines: An Efficient Neural Network Considering Both Accuracy and Speed



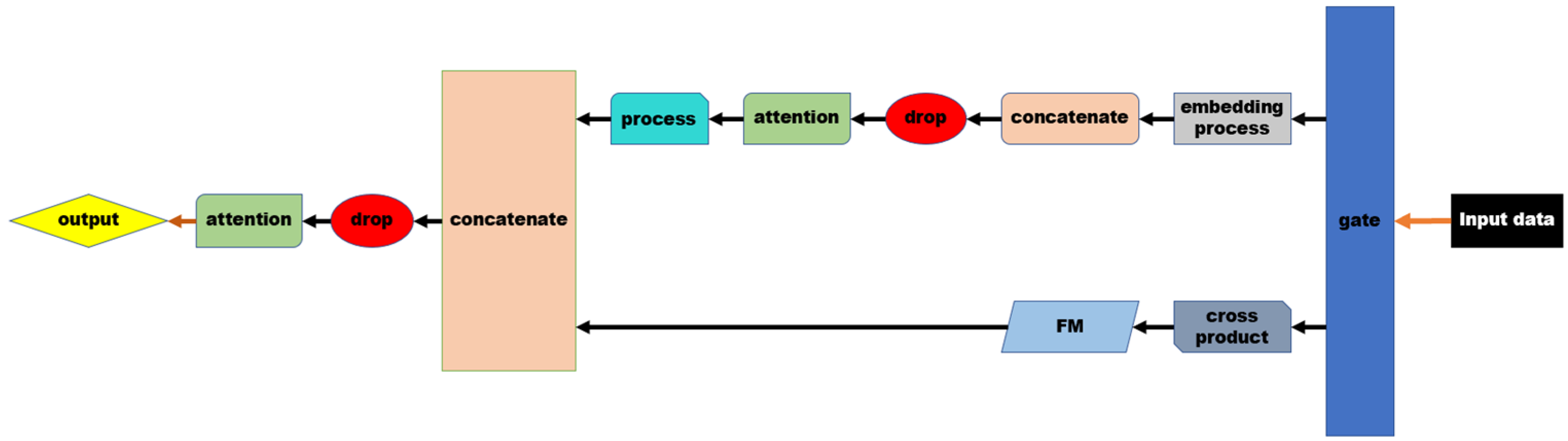{kind=link}
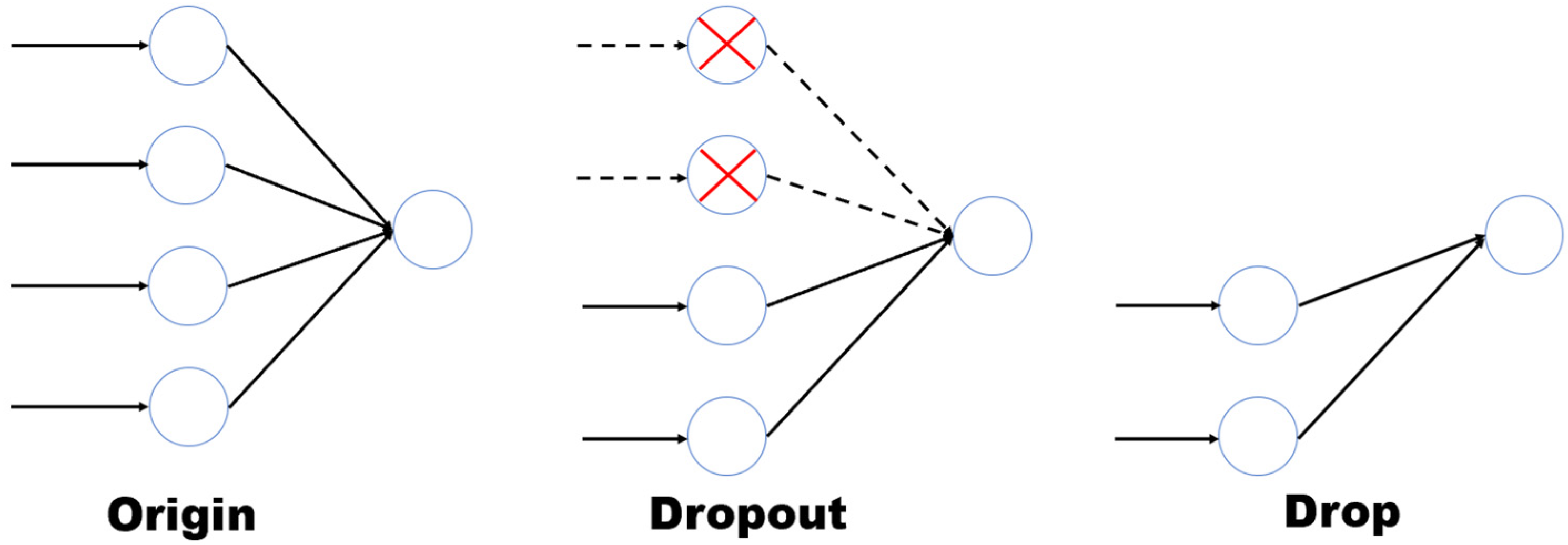{kind=link}
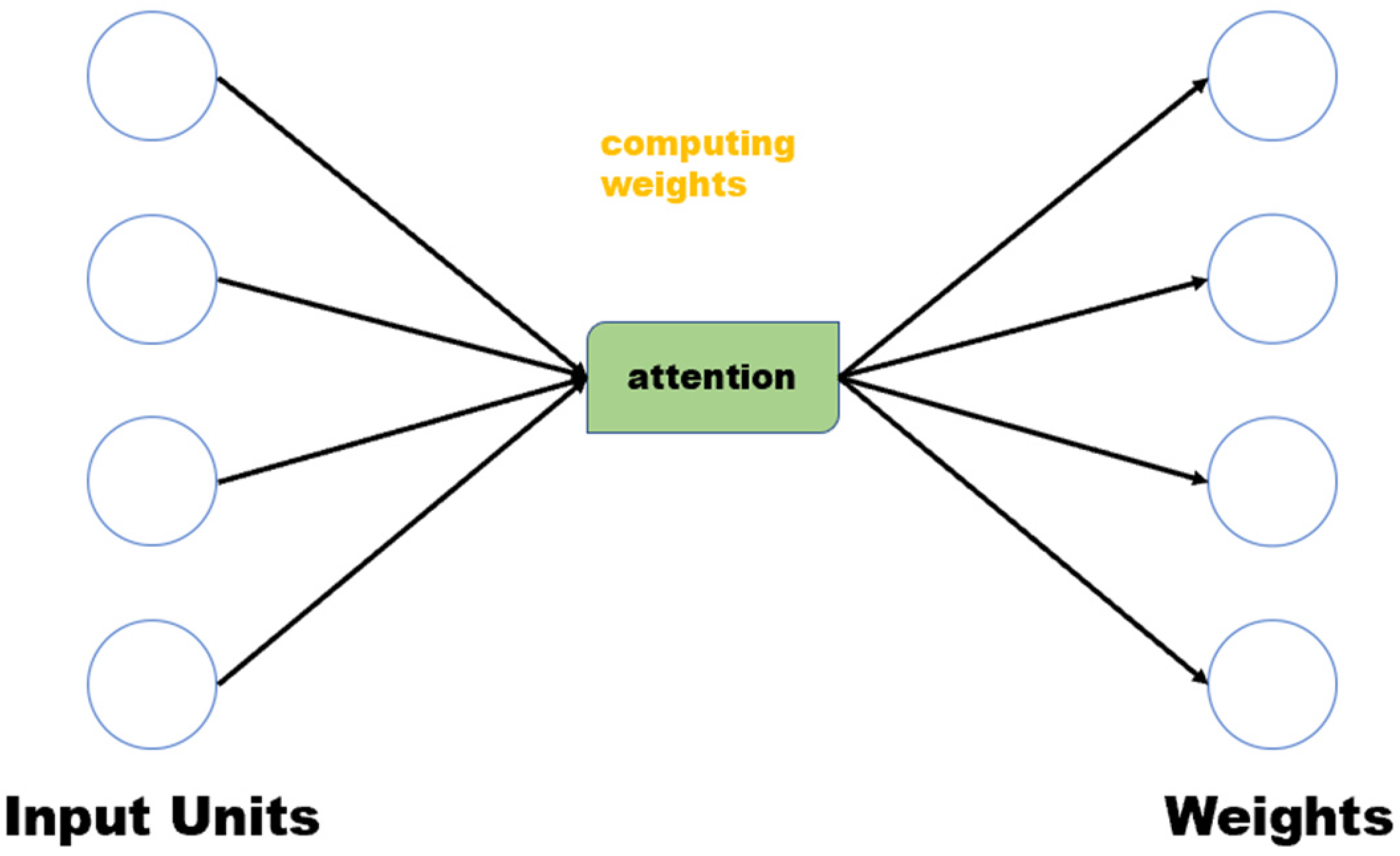{kind=link}
{kind=link}
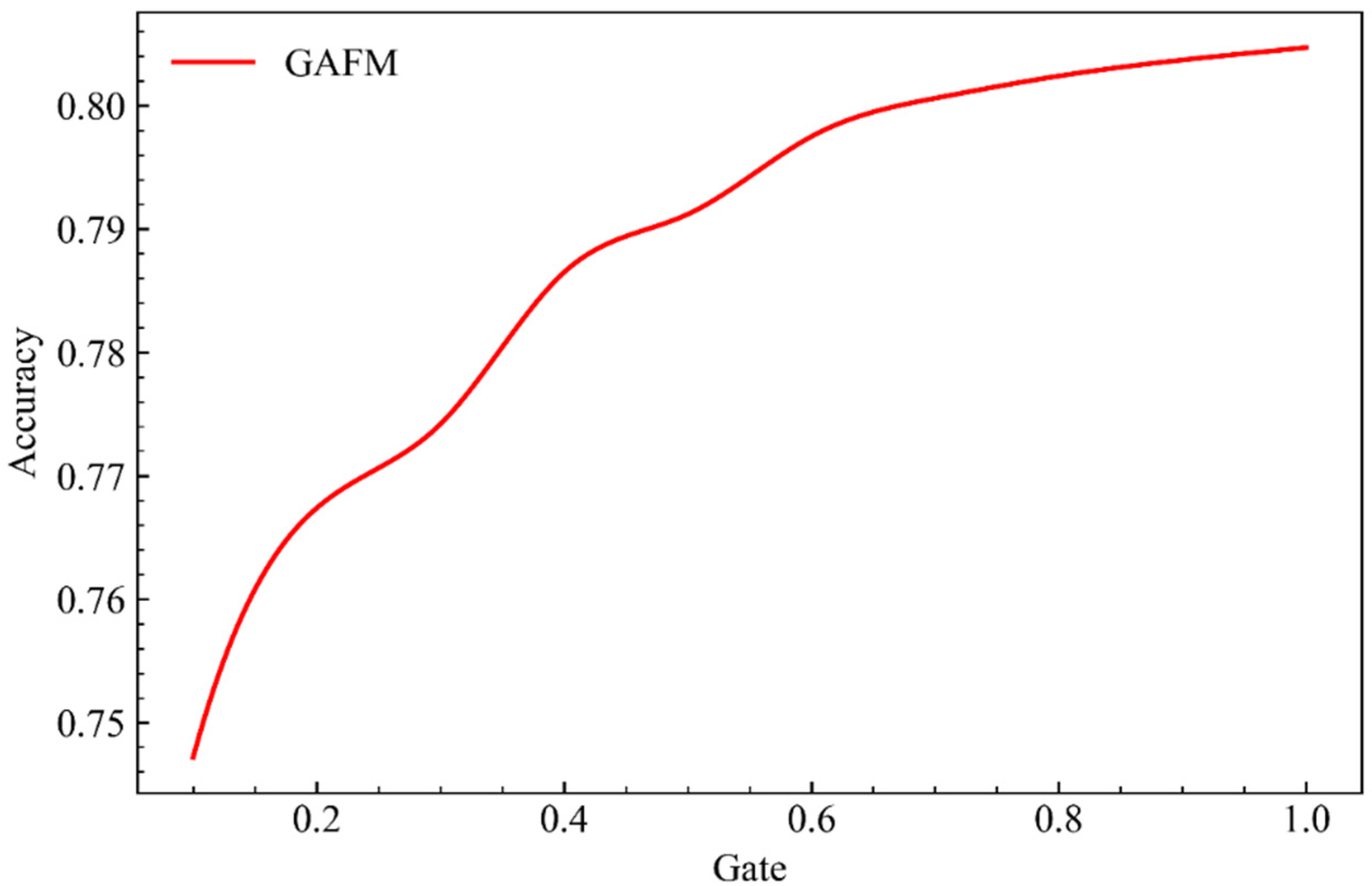{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
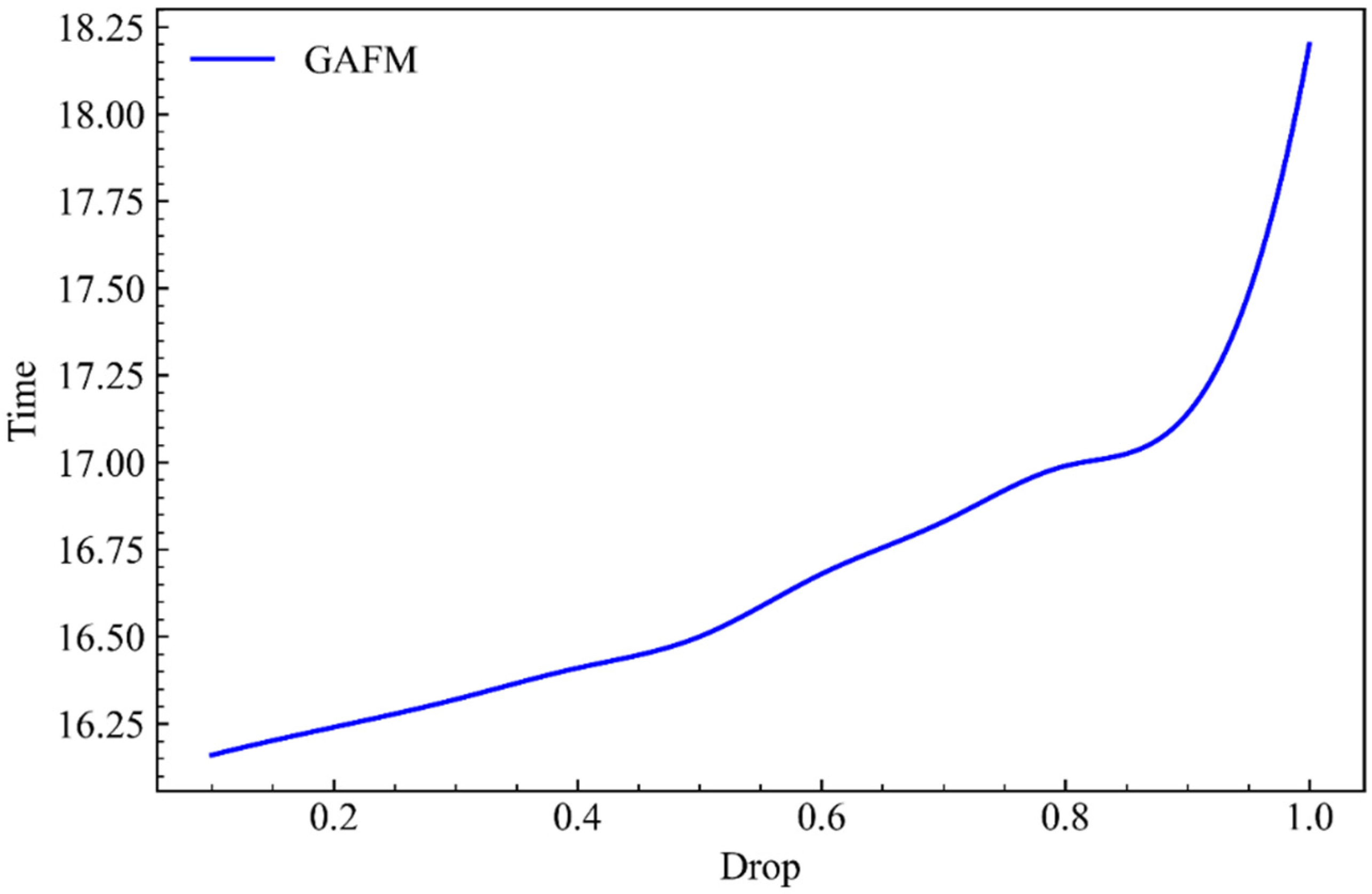
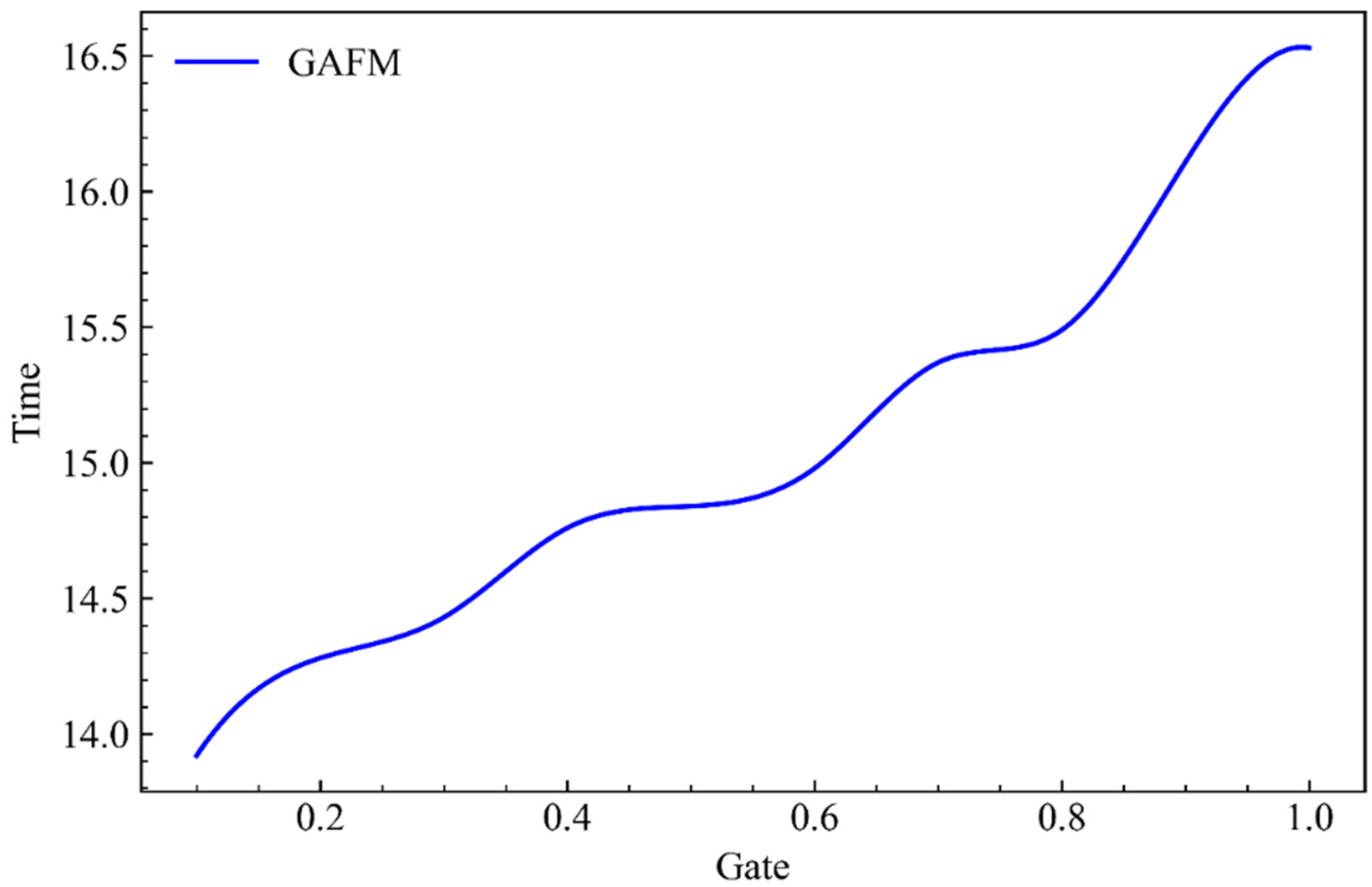
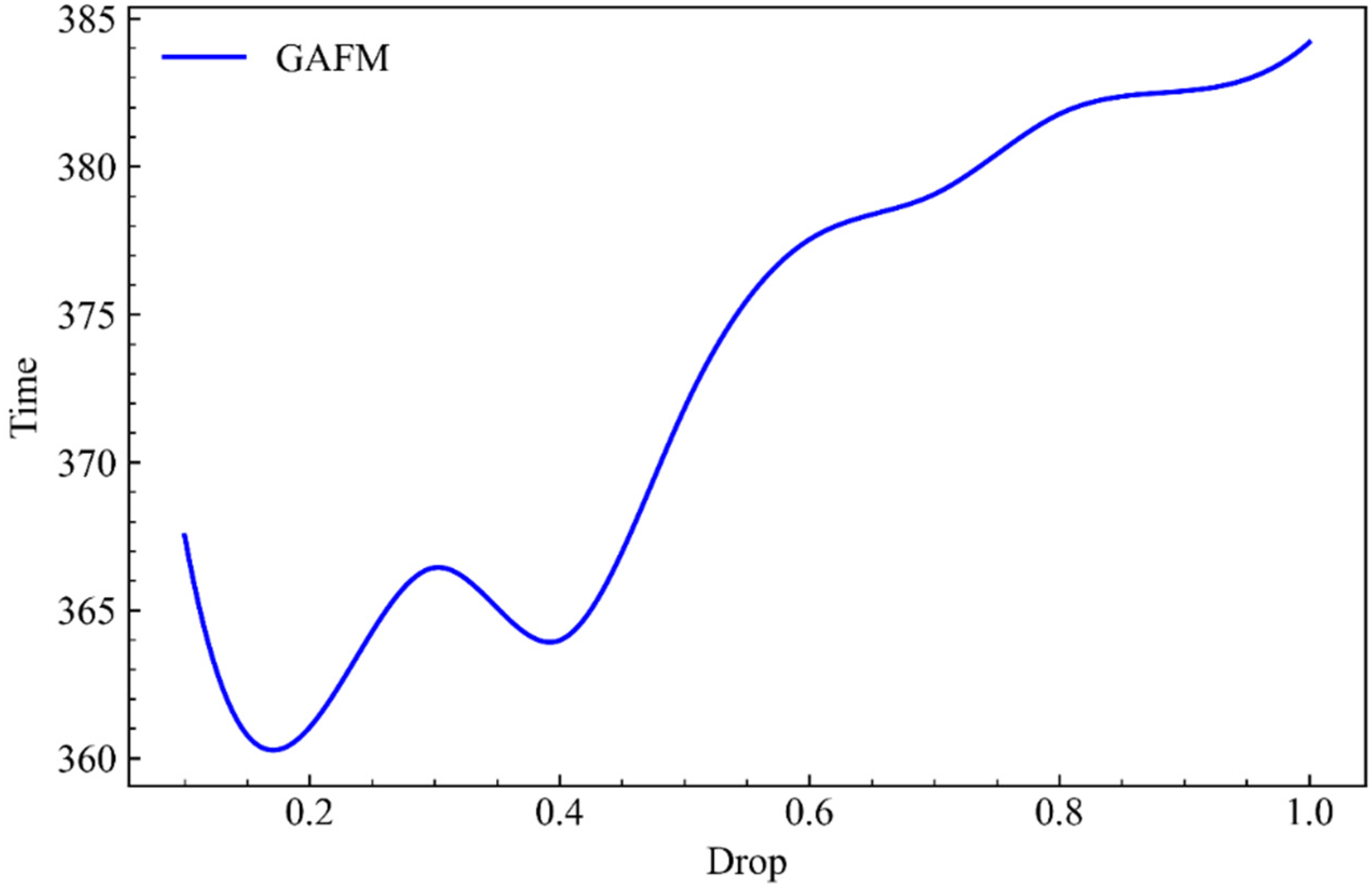
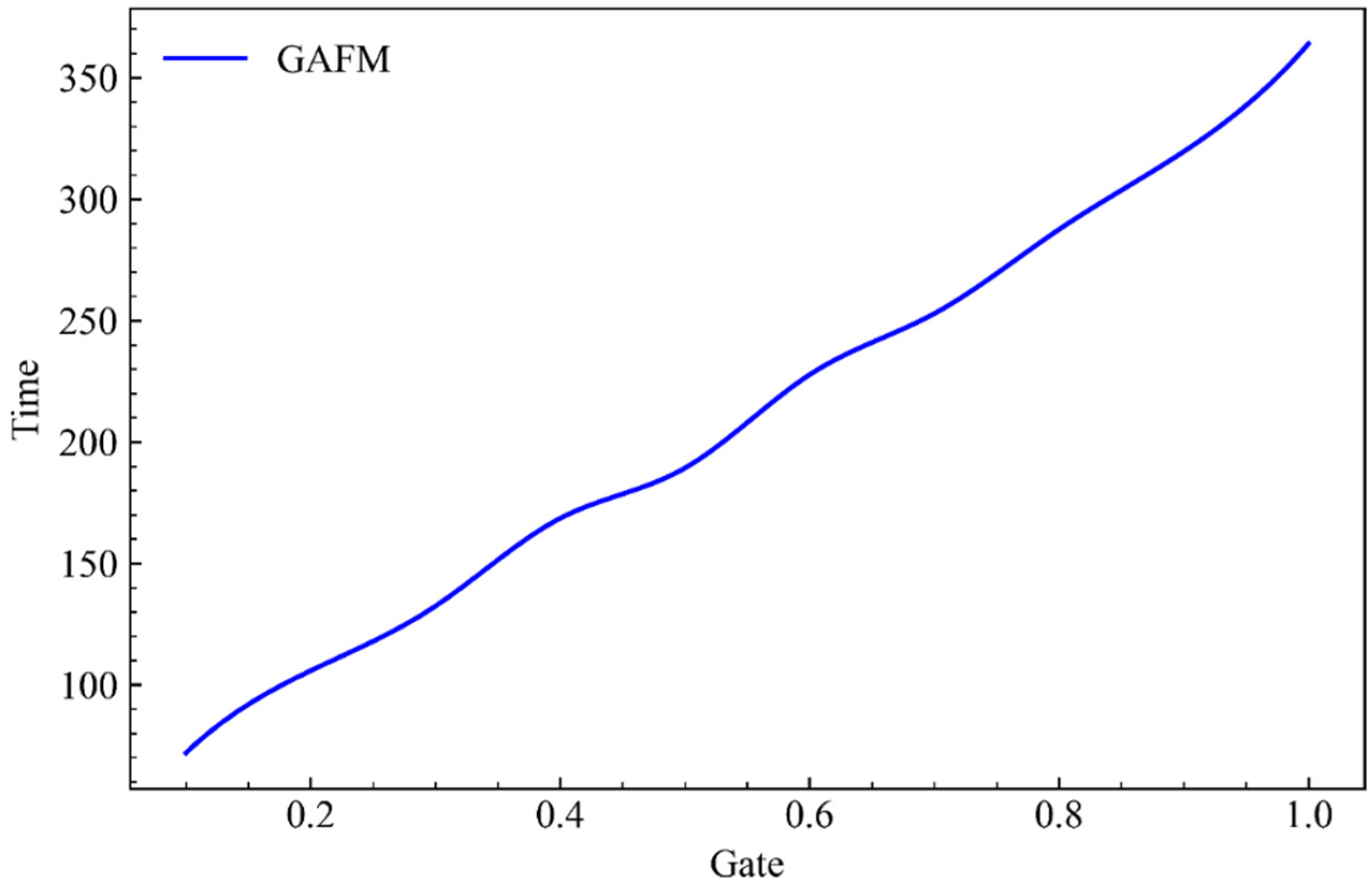
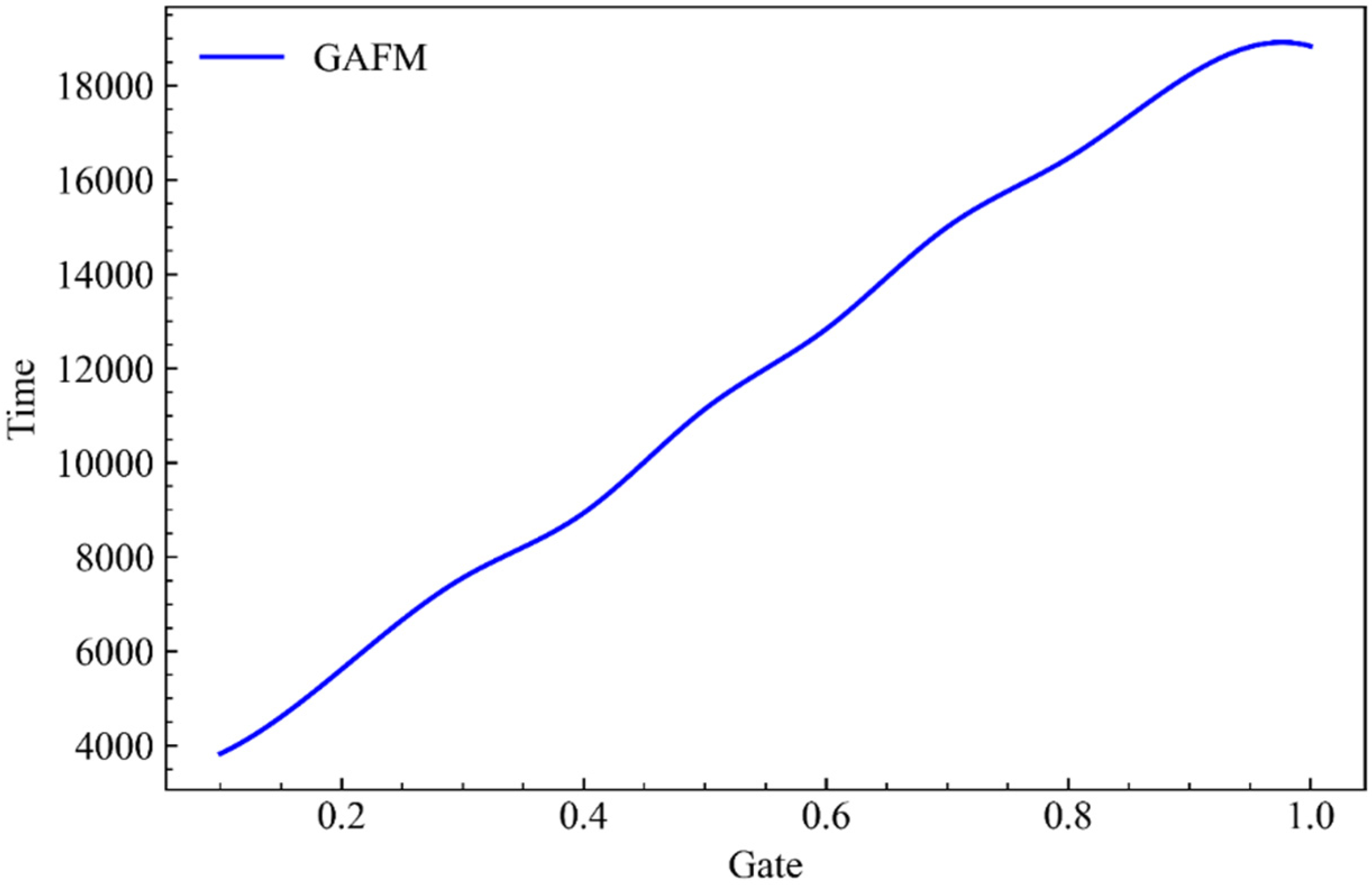
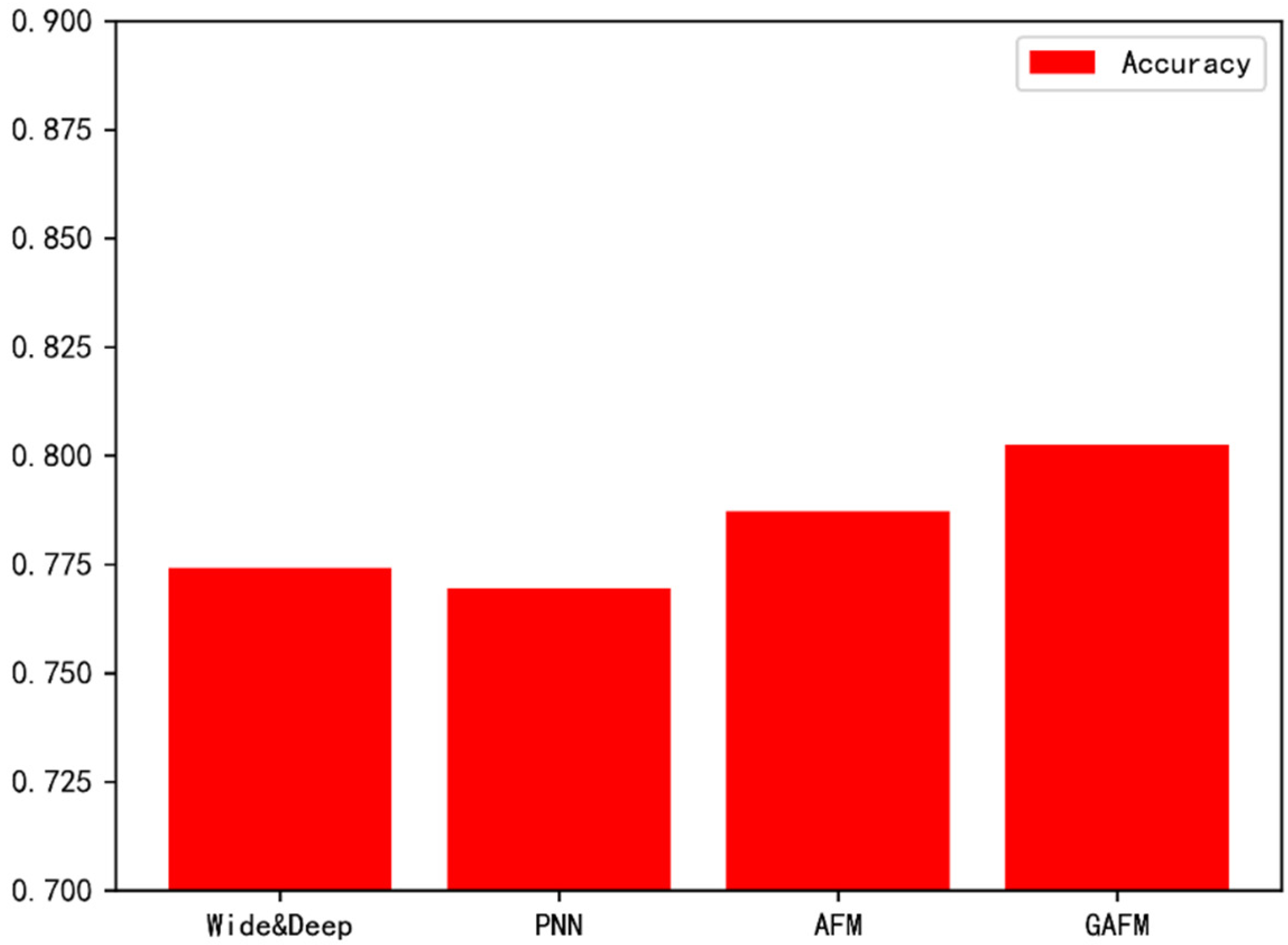
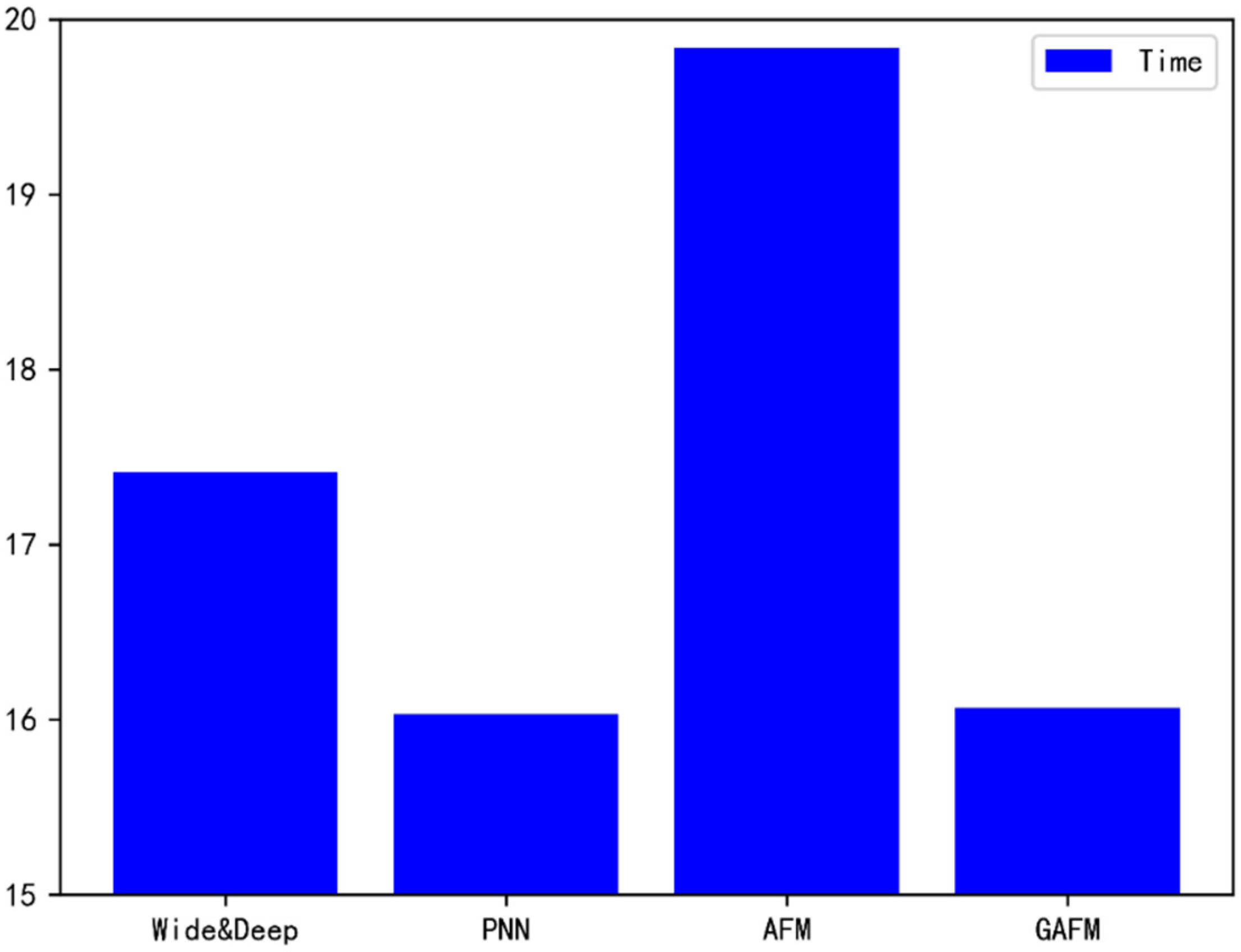
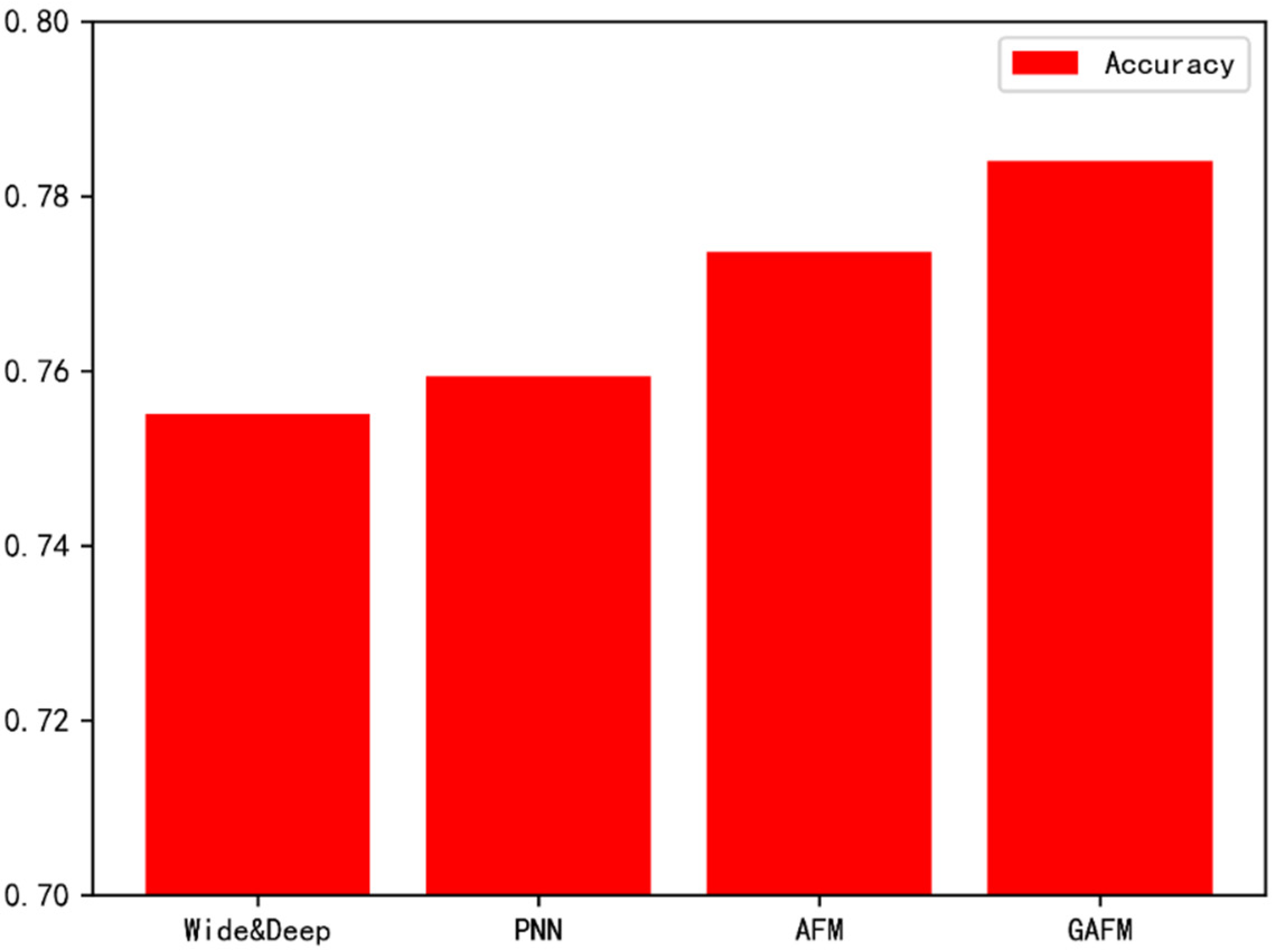
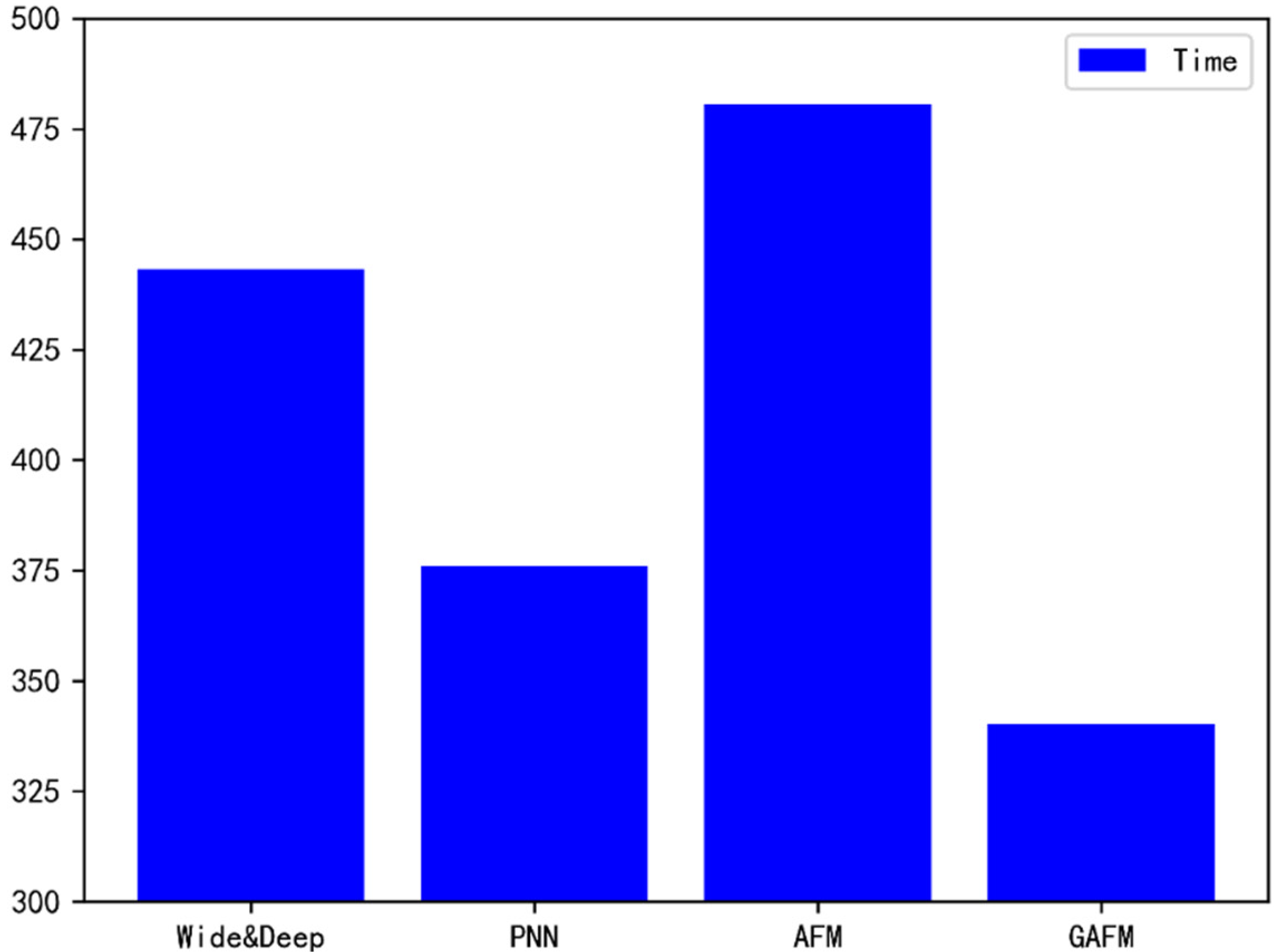
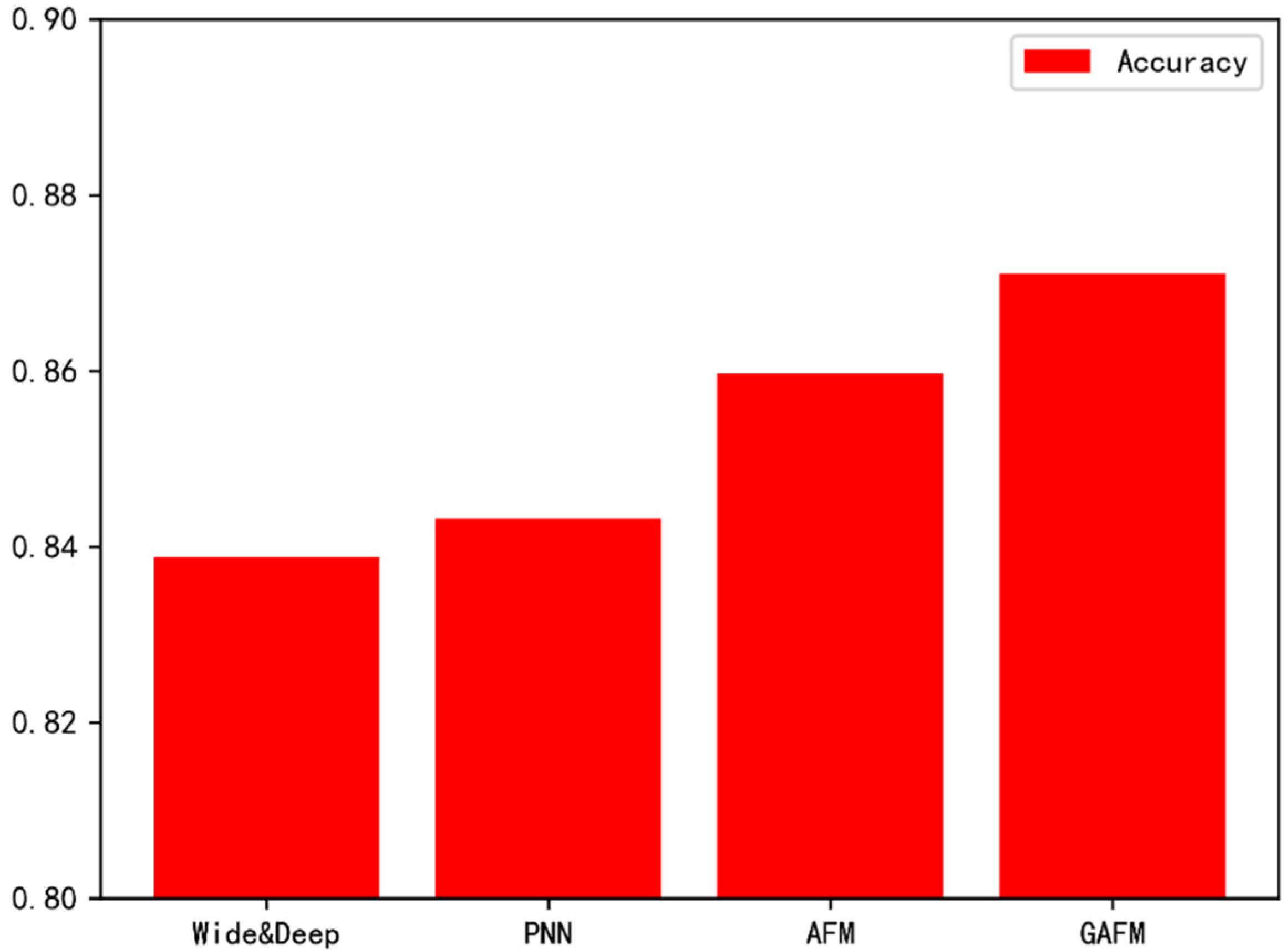
Abstract
Share and Cite
Yu, H.; Yin, J.; Li, Y. Gate Attentional Factorization Machines: An Efficient Neural Network Considering Both Accuracy and Speed. Appl. Sci. 2021, 11, 9546. https://doi.org/10.3390/app11209546
Yu H, Yin J, Li Y. Gate Attentional Factorization Machines: An Efficient Neural Network Considering Both Accuracy and Speed. Applied Sciences. 2021; 11(20):9546. https://doi.org/10.3390/app11209546
Chicago/Turabian StyleYu, Huaidong, Jian Yin, and Yan Li. 2021. "Gate Attentional Factorization Machines: An Efficient Neural Network Considering Both Accuracy and Speed" Applied Sciences 11, no. 20: 9546. https://doi.org/10.3390/app11209546
APA StyleYu, H., Yin, J., & Li, Y. (2021). Gate Attentional Factorization Machines: An Efficient Neural Network Considering Both Accuracy and Speed. Applied Sciences, 11(20), 9546. https://doi.org/10.3390/app11209546