1. Introduction
Terms such as ‘clarity’, ‘punch’, ‘warmth’ and ‘brightness’ are semantics often used to describe perceptual features found in musical mixes. These features are often subconsciously combined by a listener when assessing the overall quality of a musical mix. Whilst some of the perceptual features represented by the semantics outlined have an objective counterpart [
1,
2,
3,
4,
5], clarity does not.
Clarity in the context of this work is related to Pedersen and Zacharov’s sound wheel term ‘clean’ [
6], which is defined as: “It is easy to listen into the music, which is clear and distinct. Instruments and vocals are reproduced accurately and distinctly. The opposite of clean: dull, muddy.” Other similar definitions can be found in the literature, for example [
7,
8,
9,
10,
11]. Although none of these definitions are uniform in wording, they have a similar focus on the separability of the component parts of the mix, such that each part is distinctly audible. Potential links between the perception of single instrument clarity and brightness, measured using centroid and harmonic centroid, have been suggested [
7,
12]. This work evaluates a model-based approach to objective mix clarity prediction. Perceptually motivated metrics have their use in metering and control applications, as well as automatic mixing [
10,
13,
14,
15]. Additionally, understanding the underlying related signal characteristics of these perceptual features facilitates the proposal of formalised definitions.
It is noted that the idea of ‘clarity’ and ‘quality’ should not be conflated here. The perceived level of clarity for a given multitrack mix may not correlate directly to the perception of the overall quality, as this will depend on the content and intention of the multitrack mix itself. Furthermore, overall quality judgement is likely to be made based upon multiple perceptual features such as loudness [
5] and punch [
1] alongside that of clarity.
Considering the acoustic characteristics of a space, it is possible to objectively determine the clarity and intelligibility that can be achieved. Measures such as C50 (ratio between early and late arriving reflections) and early decay time (EDT) can be combined for this purpose. The direct to reverberant ratio (D/R) has also been linked to acoustic clarity [
16]. Furthermore, in a proposal for objective measurement for loudspeaker quality [
17], ‘clearness’ is considered to be a perceptual dimension. This is calculated based on perceived degradation imparted on a signal by the loudspeaker under test in reference to an ‘ideal’ loudspeaker signal. This approach is similar to established standards to objectively measure music and speech quality, PESQ [
18] and PEAQ [
19]. These compare encoded signals with their unencoded counterparts to estimate a perceived error signal caused by encoding, which can then be measured using a number of features to determine how disturbing it is. What is common between these measures is that they all compare a signal with an affected version of itself, for example altered by a room or a loudspeaker’s response. In the proposed model, there is not a processed version of the signal under test to compare to. Instead, the signal is decomposed and a comparison made between its constituent components to determine if they are suitably balanced.
In previous research [
20,
21], it has been suggested that masking between signals constituting a multitrack mix could be related to the perception of clarity of the overall mix. Auditory masking is a phenomenon of hearing in which energy present at the ear is not perceived, due to stronger neighbouring energy in frequency or time, known as frequency masking and temporal masking, respectively [
22]. The model proposed for mix clarity prediction is based on an analysis of the masking relationship between transient, steady-state, and residual components of the signal, utilising the MPEG Psychoacoustic Model II [
23,
24]. The model’s performance is assessed using a correlation test against subjective mix clarity scores elicited from a controlled listening test. In addition, further analysis of the model’s response to an independent dataset consisting of musical excerpts with varying degrees of controlled degradation is undertaken. Finally, the performance is discussed, including comparison to the model defined in previous research [
20,
21].
2. Proposed Model
The proposed model has some similarities to a cross-adaptive approach employed to minimise masking between composite signals of a multitrack mix in automatic mixing systems [
10,
14]. The automatic mixing system employed in [
10] was shown to increase the perceived clarity of the mixes where the amount of masking had been reduced. To achieve this, a cross-adaptive masking metric was used to calculate the level by which a given signal in the multitrack was masked by the sum of all other signals of the multitrack mix. The signals contributing to the given multitrack mix are then processed in such a way to minimise the amount they are masked, thus lowering the amount of masking occurring in the multitrack mix overall. Their work was congruent with [
25] which proposes a cross-analysis based model. This compares the partial loudness (frequency dependent loudness) of a signal in isolation to the partial loudness of the signal when masked by the other signals present in the multitrack mix. Subjective testing showed the greater the disparity in partial loudness between the masked and unmasked forms of a signal, the lower the probability of it being successfully identified in the multitrack mix. A similar approach was also proposed as a Hierarchical Perceptual Mixing (HPM) system [
26], which first determines the most important signals present in the mix as a function of time based on a user parameter, then calculates the perceptual masking threshold of these dominant signals and removes the masked energy of the non-dominant signals present in the mix. It is suggested this approach may improve the clarity of the resulting mix. However, this was not related to any subjective testing.
In typical MIR applications, a multitrack based approach cannot be used directly as it assumes access to all of the signals present which make up the multitrack mix. Additionally, it is unable to calculate masking occurring contained within a single signal, for example, if multiple instruments were captured by a single microphone. Whilst there is an emerging field of source separation methods utilising deep learning techniques to ‘unmix’ mixed signals, such as Spleeter [
27], these systems are unsuited in this case as they are only able to classify a limited number of instruments. This results in the cross-masking being poorly represented in cases where the given mix is split into only 1 or 2 instrument categories.
The proposed model assumes no knowledge of the individual signals making up the multitrack mix. It utilises a novel approach which calculates the level of perceived masking between the separated transient, steady-state, and residual (TSR) components of the multitrack mix. The model outline is shown in
Figure 1 and consists of the TSR separation stage, a component energy and masking calculation stage (utilising the MPEG Psychoacoustic model II), and finally a statistical output calculation stage which generates the representation of the masking occurring between the separated components.
2.1. Transient, Steady-State, and Residual Separation Stage
When considering a spectrogram representation, the TSR components are characterised as follows:
Transient components: Spectrally broadband and temporally transient bursts of energy which form strong vertical beams on the magnitude spectrogram [
28], and unpredictable changes in phase between consecutive frames [
29].
Steady-state components: Slowly evolving harmonic partials with predictably evolving phase between consecutive frames [
29], forming strong horizontal beams on the magnitude spectrogram [
28].
Residual components: Cannot be classified as transient or steady-state. These are noise-like components of the signal, described as the ‘texture’ of the sound [
30], which are generally broadband and stochastic in terms of magnitude and phase.
The TSR model gives a more general description of signal components that do not require specific instrument classification. Following the suggested negative impact of noise-like signals on mix clarity [
20,
21], greater masking of the residual (
R) component would indicate a less audible residual component and therefore a potentially higher perceived mix clarity. Additionally, and perhaps more importantly, less masking of the transient and steady-state (TSS) components would indicate greater audibility of the percussive (rhythmic) and harmonic (pitched) parts of the signal. Transient onsets have also been linked to instrument identification [
31], suggesting potentially greater mix clarity perception where TSS components are less masked. Considering the HPM system [
26], masked residual energy bears some resemblance to the idea of masked non-dominant signals, whose presence may be unnecessary or even detrimental to the perceived clarity of the mixed signal. Moreover, the importance of TSS and R components can be thought of as a simple hierarchy, where the presence of the TSS components take priority over
R components. In this regard, the residual energy may not necessarily be detrimental to the perception of clarity where it is below a level which would mask the TSS energy. On the contrary, as the residual information contains cues which dictate the texture and timbre of instruments, its presence may be beneficial to a mix where it is properly balanced.
The TSR separation stage adopts a median filter based approach [
30], chosen for its efficiency in the perceptual measure of punch [
1,
32] and its relative simplicity. For this, the magnitude spectrogram (
S(k, t)) of the input signal is taken using a short time Fourier transform (STFT), where
k indicates bin index, and
t indicates frame index. In this case, the STFT was performed on a 2048 sample window, multiplied with a Hanning window function, and a 50% overlap between frames. The magnitude spectrogram is then filtered with a sliding 17th order median filter. Filtering is performed vertically across the bins, yielding the transient emphasised spectrogram (
ST), and horizontally across the frames yielding the steady-state emphasised spectrogram (
SSS). Binary masks (
BM) were then defined for the transient and steady-state components as:
where
is a small offset to avoid division by 0,
is the transient threshold set at 1.75, and
is the steady-state threshold set at 1. These parameter values were chosen based on previous works, namely the perceptual punch meter [
1,
32].
The residual component mask is determined to be any bins which do not appear in the transient or steady-state masks, as:
Using the masks, the spectrograms of the transient (
T), steady-state (
S) and residual (
R) components can then be extracted:
The separated component signals are then resynthesised by inverse STFT and overlap add procedure, before being combined by addition without the residual to form the TSS signal. The TSS and R signals are then passed to MPEG Psychoacoustic Model II stage.
It is worth noting that ideally the separation stage incorporated in the model would leave no residual energy in the TSS component and vice versa. In practice, however, with a purely white noise input, the output of energy to both TSS and R components is approximately even. This is not an issue in the present application as the white noise example simply represents the upper-bound of overall masking scores.
2.2. Component Energy and Masking Calculation Stage
The MPEG Psychoacoustic Model’s output, the signal-to-mask ratio (SMR), is employed in the cross-adaptive automatic mixing system [
10]. It is also utilised in the proposed model where it is used to represent masking occurring across sub-bands of the frequency spectrum, called ‘scale-factor bands’ (
sb) [
23]. SMR indicates the ratio of the energy (
E) of the input signal to a masking threshold (
MT), which is calculated as a function of frequency and time [
23,
24]. Thus, the SMR is defined as:
where
MT is calculated by grouping spectral bins into threshold calculation partitions, which represent approximately a third of a critical bandwidth. Energy in these partitions is spread and then weighted based on a tonality measure. The tonality measure is a sliding scale indicating how noise-like or tone-like the input is. More noise-like partitions result in an increased masking threshold as they are more effective maskers. This weighted masking threshold is then compared with the threshold in quiet and the largest of the two is taken as the final masking threshold in each partition. By calculating the masking threshold of an external signal, the SMR reflects the level at which the external signal will be perceived to mask the input signal.
Three implementations of the MPEG Psychoacoustic Model were explored in the objective testing of the clarity model, these were the layer 2 (L2PM), layer 3 (L3PM) and modified L3PM. This allowed for the performance of the implementations to be compared, with a view to establishing which would perform optimally in the proposed mix clarity model. There are three key differences between SMR calculation in the L2PM and L3PM. Firstly, the L3PM employs two window lengths, a long window, and a short window. This improves the temporal resolution of the tonality measure at high frequencies using the short windows, while retaining spectral resolution at low frequencies using the long windows. The L3PM can also employ a window switching technique, such that SMR calculation for particularly transient information is performed solely using the short window length, to reduce pre-ringing. When using only short windows the number of scale-factor bands output is reduced as the masking calculation has lower frequency resolution. Secondly, the L2PM masking thresholds are calculated in approximately one third of critical bands which are then spread back over the spectral bins of the Fourier transform. The spread masking threshold is then grouped into linearly spaced scale-factor bands, from which the SMR calculation is performed. In the L3PM, the masking thresholds are also calculated in approximately one third of critical bands. These are converted directly into scale-factor bands spaced to approximate the critical bands of human hearing. As such, while masking threshold calculations in both are perceptually derived, the L3PM scale-factor band spacing is more closely related to human perception than the L2PM scale-factor band spacing. Finally, due to the more complex nature of the L3PM, it requires more computational overhead than the L2PM.
The modified L3PM is a combined approach devised for the present work. It performs the masking threshold calculation from the L3PM, which is then spread back over the spectral bins of the Fourier transform and used to calculate the SMR in linearly grouped scale-factor bands employed in the L2PM. This allowed for assessment of the impact of the scale-factor band spacing on the model performance presented in
Section 4.
In the case of the cross-adaptive masking metric [
10], the energy and threshold calculation for the scale-factor bands is kept the same, though they define a masker-to-signal ratio (MSR) given in decibels as:
where
MT′ is the threshold calculated for the sum of accompanying signals, and
E is the energy of the signal of interest. They assume masking occurs in any band where
E <
MT′. An overall masking metric is defined as the sum of scale-factor bands where
E <
MT′, which is then scaled by a predefined
Tmax value of 20 dB, giving the final masking metric as:
where
N is the number of scale-factor bands.
The model proposed in this paper first calculates the MSRs for the TSS energy (
ETSS) compared to the masking threshold calculated from the R component (
MTR), and the R energy (
ER) compared to the masking threshold calculated from the TSS component (
MTTSS), following Equation (5):
Then, the overall amount of the TSS component is masked by the R component (
AMTSS) and vice versa (
AMR) is calculated as the sum of MSRs, following Equation (6):
Since the number of scale-factor bands output by the L3PM and modified L3PM can vary, depending on whether a long or short window is used, the overall masking scores for each component (
AMTSS and
AMR) are normalised by the number of scale-factor bands output:
2.3. Statistical Output Calculation Stage
A statistical representation of each metric is taken to represent an overall score for the given analysis window, in this case 10 s, as this was the length of the stimuli included in the listening test. These are as follows: the 5th percentile of
AMTSS giving the points where the TSS component is minimally masked, and the 95th percentile of
AMR giving the points where the R component is maximally masked. The overall masking metric is defined as the ratio between the statistical representations of masking expressed in decibels:
As such, where AMR is low and AMTSS is high a large overall score is given and in the opposing case a low overall score is given, thus the score is negatively correlated with mix clarity perception.
4. Model Evaluation
To evaluate the model’s performance, the outputs of the clarity model variants were correlated against the MCSs obtained from the controlled listening test detailed in
Section 3.3. Both Pearson’s correlation coefficient
r and Spearman’s rank correlation coefficient
rho were calculated, as a lack of a bivariate normal distribution or linear relationship between the two variables can cause the Pearson’s coefficient to provide an inaccurate measure of association. Pearson’s coefficient is still provided, as a non-linear relationship is suggested in cases where
rho is greater than
r, and a linear relationship where
r is greater than
rho. The Spearman’s rank coefficient is non-parametric, so is more robust, and is the focus of the following analysis. Both correlation coefficients for each model variation are given in
Table 2 for the sake of comparison.
When correlating the ranked L2PM clarity model masking scores against the MCSs, a strong negative Spearman rank correlation of
rho = −0.8382,
p < 0.01 was achieved. This correlation is shown in
Figure 3, where the box plots indicate the distribution about the MCSs obtained, ordered by rank determined by the overall masking score calculated by the proposed model.
This was the highest Spearman rank correlation achieved by any implementation of the model, with most deviations from the line of best fit still within the interquartile range of the MCSs. The least well ranked stimulus, ‘126410′, was also poorly predicted by a different mix clarity model suggested in previous work [
20]. This implementation also achieved
r = −0.7884,
p < 0.01, which suggests a strong and slightly non-linear parametric relationship between the model output and the subjective scores.
The model was also implemented using the L3PM, forming the L3PM clarity model. This achieved a significant, but weaker correlation of
rho = −0.6882,
p < 0.01, shown in
Figure 4. Again, a lesser Pearson correlation (
r = −0.6682,
p < 0.01) was seen, indicating a somewhat non-linear relationship.
This correlation shows some heteroscedasticity, where the stimuli given higher masking scores were predicted less accurately than those given low masking scores, though many of the interquartile ranges cross the line of best fit. The weaker correlation of this model compared to the L2PM clarity model was somewhat unexpected, as the L3PM is more efficient in coding applications, and the SMR values are calculated in scale-factor bands which approximate critical bands. These are more reflective of perception than the L2PM scale-factor bands which are linearly spaced. The better performance of the L2PM clarity model suggests a greater importance of masking occurring between higher frequency energy, due to the model calculating the overall masking of a given frame in each component as the sum of masking within the scale-factor bands (Equation (8)). Other work has suggested an importance of high frequency energy in clarity perception for some single instrument sounds [
7,
12]. The L3PM also employs window switching which the L2PM implementation does not [
24]; whereby, shorter analysis windows and fewer scale-factor bands are used in determining the energy and masking thresholds of highly transient frames. For the stimuli used in the present testing, the perceptual entropy threshold was not crossed by any frames of any of the stimuli. Therefore, short analysis frames were not used in any of the masking calculations and thus could not be responsible for the difference in performance between the L2PM and L3PM clarity model variants.
To confirm that the difference in scale-factor bands was largely responsible for the weaker correlation of the L3PM clarity model, a modified version of the L3PM was devised. This calculated the energy and masking thresholds following the L3PM [
23,
24], however, rather than calculating the SMR directly in scale-factor bands which approximate critical bandwidth, the masking thresholds were spread back across the spectral bins of the Fourier transform and the SMR was calculated for the linearly distributed bands specified in the L2PM [
23]. This saw an increase in performance to a level similar to, but lower than the L2PM clarity model, achieving
rho = −0.8088,
p < 0.01 and is shown in
Figure 5.
The modified L3PM clarity model improves the position of the L3PM clarity model’s most severe outlier, ‘94414’, though a number of outliers remain. The remaining differences between the L2PM and modified L3PM clarity models were due to the difference in how the models calculate the masking threshold. Whist this implementation of the clarity model had a slightly weaker Spearman and Pearson correlation (r = −0.7868, p < 0.01) than the L2PM clarity model, the Spearman and Pearson correlation coefficient values are similar, suggesting a more linear relationship between the modified L3PM clarity model and the subjective scores.
Further to testing the clarity model variations’ correlations to the subjective data, they were also evaluated using the independent dataset (
Section 3.4).
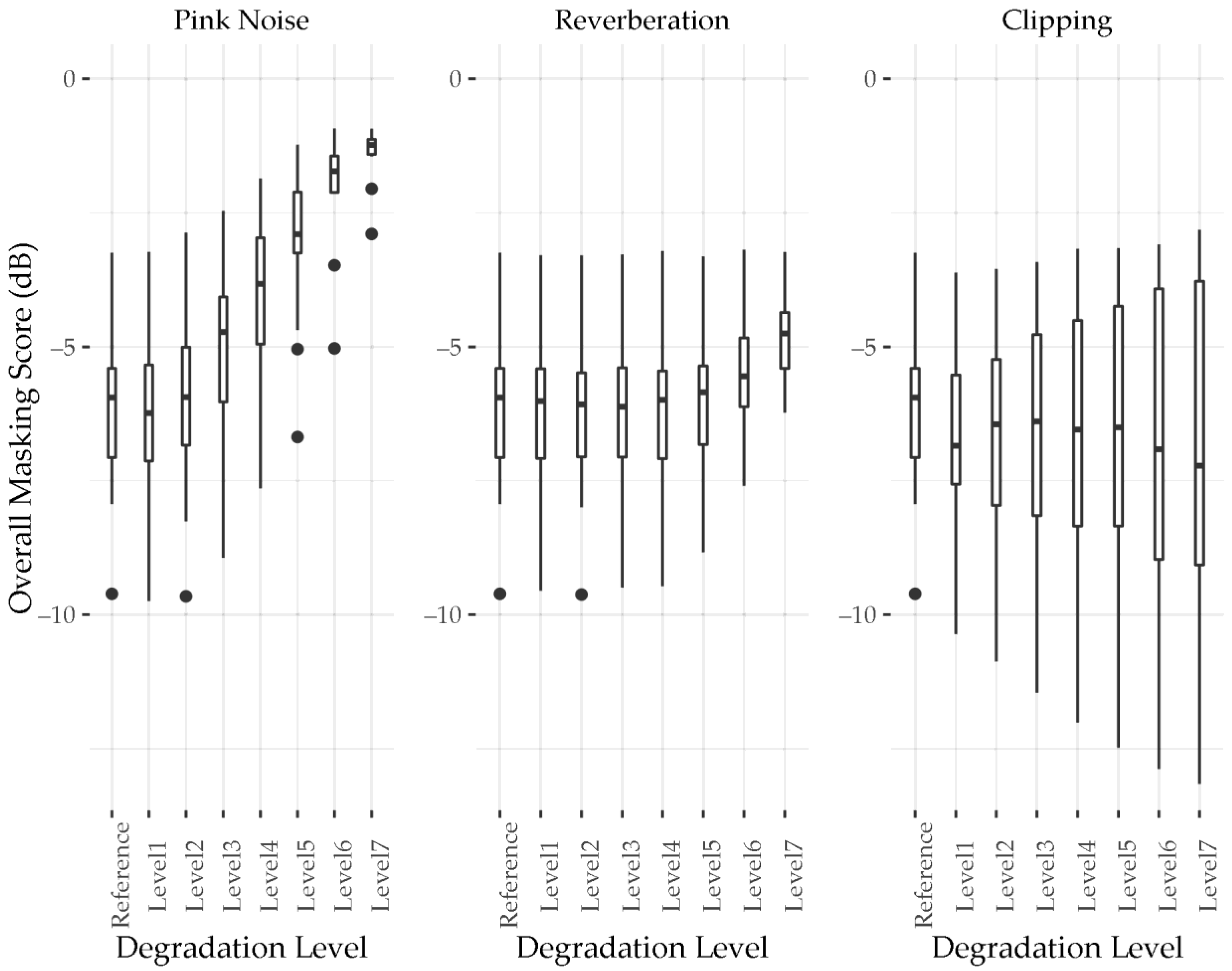
Figure 6,
Figure 7 and
Figure 8 show the scores calculated for audio examples at the various levels of degradation for each of the three degradation methods. Box plots show median and interquartile range as well as outliers at each degradation level.
Figure 6 shows clarity scores calculated by the L2PM clarity model for the independent dataset. The addition of pink noise sees the addition of broadband residual energy resulting in the masking of transient and steady-state components of the stimuli. As such, the masking scores progressively rise as more noise is added, until they reach a ceiling level where the TSS component is maximally masked. This ceiling causes a convergence of the clarity scores for the tested stimuli, with the tracks scoring a lower MCS in the subjective test tending to see less change when degraded by pink noise. This suggests that how noise-like the stimuli were may have had an influence on the MCSs they received from listeners.
The addition of reverberation had a similar though less extreme effect as adding pink noise. Unlike pink noise, the reverberated signal is still derived from and therefore correlated to the original signal. If viewed using a spectrogram, reverberation is somewhat akin to blurring an image where the energy is smeared over time, and to a lesser extent frequency. This smeared energy is largely characterised by the separation system as residual energy, increasing the level to which the TSS component is masked by the R component, and decreasing the level to which the R component is masked by the TSS component. The addition of reverberation tended to increase the masking score of the stimuli. However, a greater effect is seen for stimuli which received a higher MCS similarly to the addition of pink noise. Moreover, masking scores for stimuli which did not contain strong transient onsets from things such as drum hits, such as ‘137167’,’15541’, and ‘94414’ also showed less difference than those which did. This suggests the masking effect of reverberation is more severe for transient sounds, which is in line with the greater effect reverberation has on the temporal axis of the spectrogram.
Clipping appears to cause two different responses in the model output whereby some stimuli masking scores increase with degradation level and others decrease. The effect of this is almost symmetrical, keeping the median masking score relatively constant throughout the degradation levels whilst the interquartile range increases. Clipping had the effect of reducing AMR (Equation (8)), as the dynamic range was decreased and the difference between the R and TSS components was reduced. However, in cases where there was very little residual energy, the AMTSS (Equation (8)) was also reduced. Clipping can increase the harmonic density of transients which emphasises their spectrally broadband characteristic and thus increases the level of transient energy separated by the separation system. In cases where the present signal is largely steady-state energy, such as a sustained Rhodes piano chord, clipping can emphasise the temporally constant and more slowly evolving nature of steady-state energy and increase the level of steady-state energy separated by the separation system. Moreover, additional harmonics generated from clipping such a signal are spectrally narrowband and temporally constant, and as such are considered to be steady-state by the separation system, further contributing to the level of steady-state energy extracted. Therefore, stimuli that were more noise-like at the reference level, receiving high masking scores, received even higher masking scores as more degradation was applied. Conversely, stimuli that had a low level of residual energy at the reference level received even lower masking scores at higher degradation levels, as the reduction of the R component masking was lesser than the reduction of TSS component masking. Whilst the effects of clipping may potentially increase the perception of clarity, given the more complex effect compared to the addition of pink noise or reverberation, the clipping applied at the highest levels of degradation is extreme. The resulting signals are very noise-like, and as such were expected receive high masking scores, which they did not in the case of stimuli that scored middle or low masking scores at the reference level.
The L3PM clarity model responded similarly to the L2PM clarity model for all degradation types.
Figure 7 indicates that there was an increase of median masking score and convergence with increasing levels of degradation in the case of additional pink noise and reverberation. Moreover, there were somewhat diverging masking scores with a relatively constant median in the case of increasing levels of clipping. However, this response was muted in comparison to the response seen from the L2PM clarity model. Application of the signal degradation had a greater effect on the separated higher frequency energy than on the separated low frequency energy; this was as a result of the STFT based separation system employed having frequency resolution which increases with bin index. When measured using linearly spaced scale-factor bands of the L2PM, the high frequency bins represent a larger proportion of the scale-factor bands than when measured with more perceptually aligned scale-factor bands of the L3PM. Thus, less change in masking score is seen when degradation is applied in the case of the L3PM clarity model’s perceptually spaced bands, as fewer of these scale-factor bands correspond to the high frequency bins which have the greatest difference in separated energy between degradation levels. While the L3PM scale-factor bands are more aligned with human perception, in this case, a negative effect on correlation to the subjective scores was seen (
Figure 3 and
Figure 4).
Figure 8 shows the clarity model which employed the modified L3PM, using linearly grouped scale-factor bands like those used in the L2PM clarity model. The modified L3PM clarity model responded to the different types of degradation similarly to the L2PM clarity model (
Figure 6). The similarity of these results, and difference to the L3PM clarity model results (
Figure 7), suggests that the differences between the models’ responses could have largely been caused by the different scale-factor bands employed. The remaining differences then are due to the difference in masking threshold calculation between the L2PM and L3PM clarity models discussed previously, and detailed in [
23].
5. Discussion
All tested correlations showed significant (p < 0.01) results, with a worst-case correlation of r = −0.6682, rho = −0.6882 to the subjective scores. This suggests a link between the underlying concept of transient, steady-state and residual masking and mix clarity perception. However, as the tested subjective dataset contained only 16 stimuli, the model may be overfit, and a larger test containing more participants and stimuli should be performed to validate these results.
Previous work proposed a model of Inter-Band Relationship Analysis (IBR), which measures the correlation between dynamic ranges in three bands of the frequency spectrum over time [
20,
21]. The best performing L2PM model outperformed the IBR model scoring
rho = −0.8382 (
p < 0.01) versus
rho = 0.7882 (
p < 0.01). As the IBR model simply utilises the dynamic range across three bands, it only has an incidental relationship to human perception. Furthermore, the IBR model is prone to being ‘fooled’ by some signals. For example, it would rate sustained pink noise and sustained full-bandwidth harmonic signals equally. The present model supersedes IBR by negating these shortcomings, and by relating more directly to human perception of auditory masking. The model also incorporates a greater awareness of the makeup of the signal being measured due to the TSR component separation employed.
The L2PM clarity model showed the strongest rho correlation, though was non-linear, with a Spearman’s rank correlation test showing a stronger relationship than the Pearson correlation. This implementation of the model is also the least computationally expensive, as the L2PM is less complex than the L3PM. During independent testing, the model responded as expected to the addition of pink noise and reverberation, with the masking score increasing (clarity decreasing) as the degradation levels increased. The model’s response to clipping was less uniform than that of the additional pink noise or reverberation, showing a more complex effect on the relationship of the R and TSS components of the signal. While the response is understandable in terms of how the model operates, it is not expected to be congruent with perception. Low perceived clarity scores, corresponding to high masking scores, would be uniformly expected for all stimuli at the highest levels of clipping degradation, showing a potential shortcoming of the model. However, given the strong correlation to the subjective scores, this shortcoming did not seem to have a greatly detrimental effect for the tested stimuli in this case. Though, improving the response to this kind of degradation would improve the robustness of the model in extreme cases.
While the L3PM has a more complex calculation of masking threshold and provides more efficient encoding in the context of MPEG compression compared to the L2PM, the L3PM clarity model unexpectedly had the weakest correlation to the subjective scores. It is suggested this was largely due to L3PM’s perceptually aligned scale-factor bands not providing emphasis on masking occurring in high frequency bands as in the L2PM and modified L3PM variations of the clarity model. This could indicate a greater importance of masking occurring between high frequency energy to the perception of clarity. In terms of independent testing, the L3PM clarity model had a similar but less extreme response to all three degradation types than the L2PM clarity model. The L3PM is capable of calculating masking thresholds using shorter windows when transients occur, providing a higher time resolution and reducing pre-ringing artefacts in MPEG coding. Similarly, this window switching could be used in the clarity model to provide greater temporal resolution for masking occurring relating to transient passages in the signal under test. In the present testing only long windows were used, as none of the stimuli under test had transient content capable of triggering the short frame calculation. If a more appropriate onset detection method was used, the application of shorter windows may improve the clarity model’s performance.
A modified version of the L3PM was devised to employ linearly grouped scale-factor bands like the L2PM. The performance of the modified L3PM clarity model response was similar to the L2PM clarity model in both correlation with the subjective scores and to the independent dataset, affirming the difference in scale-factor bands was largely responsible for the difference in performance between the L2PM and L3PM clarity models. While the rho and r coefficients showed a slightly weaker correlation than that of the L2PM clarity model, the coefficients were more similar in value, which indicates a closer linear relationship to the subjective data. Additionally, being based on the L3PM clarity model, this model may also benefit from improving the onset detection system used for window switching.
6. Conclusions
A new perceptually motivated model for the prediction of mix clarity was proposed, based on the masking relationship between residual, transient and steady-state components of a musical signal. The model consists of a median filter-based separation system, which feeds the MPEG Psychoacoustic Model II used to calculate signal-to-mask ratios of the component parts which were then compared. Both layer 2 and layer 3 implementations of the MPEG Psychoacoustic Model II were tested along with a modified version of the layer 3 implementation, forming L2PM, L3PM, and modified L3PM variants, respectively.
Each variation was evaluated through both Pearson and Spearman’s rank correlation to subjective scores gathered in a controlled listening test. Their response to an independent dataset of stimuli degraded though the addition of pink noise, reverberation, and clipping was also evaluated. The L2PM clarity model showed the strongest correlation to the subjective scores, followed by the modified L3PM, with the L3PM clarity model showing the weakest relationship. Although the L3PM is most efficient in coding applications, the stronger correlation achieved by the modified L3PM clarity model showed that the linearly grouped scale-factor bands of the L2PM were advantageous to performance in this case. All variations of the model responded similarly to the degradation introduced in the independent dataset; the L3PM clarity model’s response was less extreme to that of the modified L3PM and L2PM clarity models, whose responses were very similar. Addition of pink noise and reverberation caused an increase in masking score, reflecting a decrease in clarity. Clipping caused a somewhat more complex response, where stimuli which were noise-like and received high masking scores at their reference level gained higher masking scores when clipped. Stimuli that had a low level of residual energy and a low masking score at their reference level received even lower masking scores when clipped.
Further work is ongoing to validate the proposed model’s performance against a larger subjective data set.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}