
A Two-Phase Deep Learning-Based Recommender System: Enhanced by a Data Quality Inspector


Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- Develop a sentiment predictor of textual reviews that acts as a quality inspector of the ratings.
- (2)
- Determine if a quality inspector based on textual comments truly enhances the performance of a recommender system.
- (3)
- Apply state-of-the-art deep learning algorithms for constructing effective sentiment predictors and collaborative filtering recommenders.
2. Literature Review
2.1. Deep Learning-Based Collaborative Filtering
2.2. Deep Learning-Based Sentiment Analysis
2.3. Use of Text Information in Collaborative Filtering
3. Materials and Methods
3.1. System Overview
3.2. Deep Learning-Based Quality Inspector
3.2.1. Text Preprocessing Tasks
3.2.2. Deep Learning-Based Sentiment Predictor
- Model 1: Long-Short Term Memory Network
- Model 2: Bidirectional LSTM
- Model 3: Convolutional Neural Network
- Model 4: Two Deep Views Ensemble Method
- Model 5: BERT
3.2.3. Process to Build a Quality Inspector
3.3. Deep Learning-Based Product Recommender
- Model 1: Neural Network Matrix Factorization
- Model 2: Deep Learning-based Recommender
4. Results
4.1. Data Collection and Datasets Preparation
4.2. Deep Learning-Based Sentiment Inspector
4.2.1. Performance Measures
4.2.2. Text Preprocessing Tasks
4.2.3. Predictors Comparison
4.3. Deep Learning-Based Product Recommender
4.3.1. Performance Measures
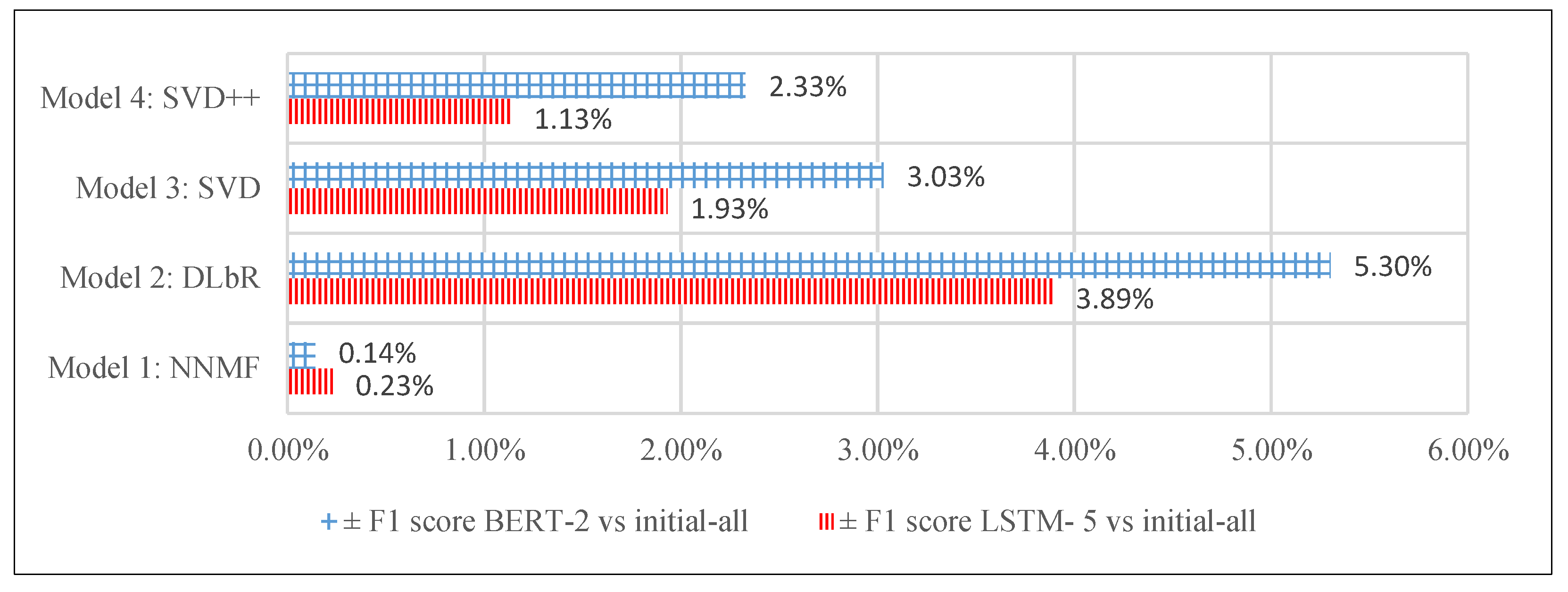
4.3.2. Quality Inspector Results
4.3.3. Recommenders Comparison
4.3.4. Other Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Çano, E.; Morisio, M. Hybrid recommender systems: A systematic literature review. Intell. Data Anal. 2017, 21, 487–1524. [Google Scholar] [CrossRef] [Green Version]
- Zdziebko, T.; Sulikowski, P. Monitoring human website interactions for online stores. Adv. Intell. Syst. Comput. 2015, 354, 375–384. [Google Scholar] [CrossRef]
- Zins, A.-H.; Bauernfeind, U. Explaining online purchase planning experiences with recommender websites. In Proceedings of the 12th International Conference on Information and Communication Technologies in Travel and Tourism, Innsbruck, Austria, 26–28 June 2005; pp. 137–148. [Google Scholar] [CrossRef]
- Tsai, C.-Y.; Chiu, Y.-F.; Chen, Y.-J. A Two-Stage Neural Network-Based Cold Start Item Recommender. Appl. Sci. 2021, 11, 4243. [Google Scholar] [CrossRef]
- Maslowska, E.; Segijn, C.-M.; Vakeel, K.-A.; Viswanathan, V. How consumers attend to online reviews: An eye-tracking and network analysis approach. Int. J. Advert. 2020, 39, 282–306. [Google Scholar] [CrossRef] [Green Version]
- Sulikowski, P.; Zdziebko, T.; Coussement, K.; Dyczkowski, K.; Kluza, K.; Sachpazidu-Wójcicka, K. Gaze and Event Tracking for Evaluation of Recommendation-Driven Purchase. Sensors 2021, 21, 1381. [Google Scholar] [CrossRef]
- Park, D.; Kim, H.; Choi, I.; Kim, J. A literature review and classification of recommender systems research. Expert Syst. Appl. 2012, 39, 10059–10072. [Google Scholar] [CrossRef]
- Liu, D.; Li, J.; Du, B.; Chang, J.; Gao, R.; Wu, Y. A hybrid neural network approach to combine textual information and rating information for item recommendation. Knowl. Inf. Syst. 2021, 63, 621–646. [Google Scholar] [CrossRef]
- Roozbahani, Z.; Rezaeenour, J.; Emamgholizadeh, H.; Bidgoly, A.J. A systematic survey on collaborator finding systems in scientific social networks. Knowl. Inf. Syst. 2020, 62, 3837–3879. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Chen, L.; Chen, G.; Wang, F. Recommender systems based on user reviews: The state of the art. User Model. User-Adapt. Interact. 2015, 25, 99–154. [Google Scholar] [CrossRef]
- Kumar, B.; Sharma, N. Approaches, issues and challenges in recommender systems: A systematic review. Indian J. Sci. Technol. 2016, 9, 1–12. [Google Scholar] [CrossRef]
- Elahi, M.; Ricci, F.; Rubens, N. A survey of active learning in collaborative filtering recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Raghavan, S.; Gunasekar, S.; Ghosh, J. Review quality aware collaborative filtering. In Proceedings of the 6th ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; pp. 123–130. [Google Scholar] [CrossRef] [Green Version]
- Pero, Š.; Horváth, T. Opinion-driven matrix factorization for rating prediction. In Proceedings of the 21st International Conference on User Modeling, Adaptation, and Personalization, Rome, Italy, 10–14 June 2013; pp. 1–13. [Google Scholar] [CrossRef]
- Dang, C.-N.; Moreno-García, M.-N.; Prieta, F.D.L. An Approach to Integrating Sentiment Analysis into Recommender Systems. Sensors 2021, 21, 5666. [Google Scholar] [CrossRef] [PubMed]
- Sedhain, S.; Menon, A.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar] [CrossRef]
- Zheng, Y.; Tang, B.; Ding, W.; Zhou, H. A neural autoregressive approach to collaborative filtering. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 764–773. [Google Scholar]
- Du, C.; Li, C.; Zheng, Y.; Zhu, J.; Liu, C.; Zhou, H.; Zhang, B. Collaborative filtering with user-item co-autoregressive models. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2175–2182. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar] [CrossRef] [Green Version]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New avenues in opinion mining and sentiment analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef] [Green Version]
- Collobert, R. Deep learning for efficient discriminative parsing. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 224–232. [Google Scholar]
- Devipriya, K.; Prabha, D.; Pirya, V.; Sudhakar, S. Deep learning sentiment analysis for recommendations in social applications. Int. J. Sci. Technol. Res. 2020, 9, 3812–3815. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Xue, B.; Fu, C.; Shaobin, Z. A study on sentiment computing and classification of sina weibo with word2vec. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 358–363. [Google Scholar] [CrossRef]
- Dos Santos, C.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 626–634. [Google Scholar] [CrossRef]
- Zhang, Z.; Hu, Z.; Yang, H.; Zhu, R.; Zuo, D. Factorization machines and deep views-based co-training for improving answer quality prediction in online health expert question-answering services. J. Biomed. Inform. 2018, 87, 21–36. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations ICLR, Banff, AB, Canada, 14–16 April 2014; pp. 1–15. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the ACL: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Kumar, S.; De, K.; Roy, P.P. Movie recommendation system using sentiment analysis from microblogging data. IEEE Trans. Comput. Soc. Syst. 2020, 7, 915–923. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 1–20. [Google Scholar] [CrossRef]
- Barriere, V.; Kembellec, G. Short review of sentiment-based recommender systems. In Proceedings of the 1st ACM International Digital Tools & Uses Congress, Paris, France, 3–5 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Leung, C.; Chan, S.; Chung, F. Integrating collaborative filtering and sentiment analysis: A rating inference approach. In Proceedings of the ECAI 2006 Workshop on Recommender Systems, Riva del Garda, Italy, 28–29 August 2006; pp. 62–66. [Google Scholar]
- Zhang, W.; Ding, G.; Chen, L.; Li, C.; Zhang, C. Generating virtual ratings from Chinese reviews to augment online recommendations. Trans. Intell. Syst. Technol. 2013, 4, 1–17. [Google Scholar] [CrossRef]
- Poirier, D.; Fessant, F.; Tellier, I. Reducing the cold-start problem in content recommendation through opinion classification. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Toronto, ON, Canada, 31 August–3 September 2010; pp. 204–207. [Google Scholar] [CrossRef] [Green Version]
- Ozsoy, M.-G. From word embeddings to item recommendation. arXiv 2016, arXiv:1601.01356. [Google Scholar]
- Ozsoy, M.-G. Utilizing fasttext for venue recommendation. arXiv 2020, arXiv:2005.12982. [Google Scholar]
- Alexandridis, G.; Siolas, G.; Stafylopatis, A. ParVecMF: A paragraph vector-based matrix factorization recommender system. arXiv 2017, arXiv:1706.07513. [Google Scholar]
- Alexandridis, G.; Tagaris, T.; Siolas, G.; Stafylopatis, A. From free-text user reviews to product recommendation using paragraph vectors and matrix factorization. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 335–343. [Google Scholar] [CrossRef]
- Shin, D.; Cetintas, S.; Lee, K.; Dhillon, I. Tumblr blog recommendation with boosted inductive matrix completion. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 203–212. [Google Scholar] [CrossRef]
- Shen, X.; Yi, B.; Zhang, Z.; Shu, J.; Liu, H. Automatic recommendation technology for learning resources with convolutional neural network. In Proceedings of the International Symposium on Educational Technology, Beijing, China, 19–21 July 2016; pp. 30–34. [Google Scholar] [CrossRef]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning based recommendation system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef] [Green Version]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable convolutional neural networks with dual local and global attention for review rating prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 297–305. [Google Scholar] [CrossRef]
- Garcia, A.; Gonzalez, R.; Onoro, D.; Niepert, M.; Li, H. TransRev: Modeling reviews as translations from users to items. Adv. Inf. Retr. 2020, 12035, 234–248. [Google Scholar] [CrossRef] [Green Version]
- GeeksforGeeks. Available online: https://www.geeksforgeeks.org/removing-stop-words-nltk-python/ (accessed on 22 May 2017).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Colah’s Blog. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 27 August 2015).
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- The Data Science Blog. Available online: https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ (accessed on 11 August 2016).
- Towards Data Science. Available online: https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270 (accessed on 11 November 2018).
- Towards Machine Learning. Available online: https://towardsml.com/2019/09/17/bert-explained-a-complete-guide-with-theory-and-tutorial/ (accessed on 17 September 2019).
- Experiments in Data Science. Available online: http://blog.richardweiss.org/2016/09/25/movie-embeddings.html (accessed on 26 September 2016).
- Ni, J.; Li, J.; McAuley, J. Justifying recommendations using distantly-labeled reviews and fined-grained aspects. In Proceedings of the Annual Conference on EMNLP, Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Review Time | User ID | Item ID | Rating | Textual Review |
|---|---|---|---|---|
| 2012 | A2M1CU2IRZG0K9 | 5089549 | 2 | So sorry I didn’t purchase this years ago … |
| 2011 | AFTUJYISOFHY6 | 5089549 | 3 | Believe me when I tell you that you will … |
| 2005 | A3JVF9Y53BEOGC | 503860X | 5 | I have seen X live many times, both in … |
| 2005 | A12VPEOEZS1KTC | 503860X | 4 | I was so excited for this! Finally, a live … |
| 2010 | ATLZNVLYKP9AZ | 503860X | 5 | X is one of the best punk bands ever. I do … |
| Model | Parameters |
|---|---|
| Model 1: LSTM (version 5) | 1 embedding layer (32)—1 lstm layer (32)—1 hidden lay. (256)— 1 output lay. (softmax)—batch: 500—epochs: 30—optimizer: adam |
| Model 2: Bi-LSTM (version 2) | 1 embedding layer (32)—1 bi-lstm layer (32)—1 hidden lay. (256)— 1 output lay. (softmax)—batch: 500—epochs: 30—optimizer: adam |
| Model 3: CNN (version 5) | 1 emb. lay. (32)—1 cnn lay.—100 filters—filt. size: 10—1 max pool.—1 hidden lay. (256)—1 out. lay. (softmax)—batch: 500—epochs: 30—optimizer: adam |
| Model 4: TDVE (version 3) | CNN view 1 emb. lay. (32)—1 cnn with l2 (0.01) const.—100 filters with size: 3, 4, 5—1 max pooling—1 hidden lay. (256)—1 out. lay. (softmax)—batch: 500—epochs: 30—optimizer: adadelta DSCNN view 1 emb. (32)—1 lstm (32)—1 cnn without l2–100 filters with size: 3, 4, 5—1 max pooling—1 hidden lay. (256)—1 out. lay. (softmax)—batch: 500—epochs: 30—optimizer: adadelta |
| Model 5: BERT (version 2) | 1 bert layer—1 avg. pooling—1 dropout: 0.2—1 hidden lay. (256)— 1 out. lay. (softmax)—batch: 16—epochs: 8—optimizer: adam |
| 1st Indicator | 2nd Indicator | 3rd Indicator | ||||||
|---|---|---|---|---|---|---|---|---|
| Ranking | Accuracy 0 | Ranking | Accuracy 1 | Ranking | Time (h) | |||
| 1 | BERT-2 | 94.37% | 1 | BERT-2 | 99.12% | 1 | CNN-5 | 2.5 |
| 2 | TDVE-3 | 92.02% | 2 | LSTM-5 | 99.04% | 2 | LSTM-5 | 3.6 |
| 3 | LSTM-5 | 91.02% | 3 | TDVE-3 | 98.94% | 3 | BILSTM-2 | 4.7 |
| 4 | BILSTM-2 | 89.90% | 4 | BILSTM-2 | 98.80% | 4 | TDVE-3 | 8.4 |
| 5 | CNN-5 | 88.30% | 5 | CNN-5 | 98.44% | 5 | BERT-2 | 23.2 |
| 6 | SVM-1 | 37.36% | 6 | SVM-1 | 69.53% | 6 | SVM-1 | 147.4 |
| Weights of Ind. | 35% | 50% | 15% | Final Score | Final Ranking of Models | |
|---|---|---|---|---|---|---|
| Models | 1st Ind. | 2nd Ind. | 3rd Ind. | |||
| BERT-2 | 1 | 1 | 5 | 1.60 | BERT-2 | 1st place |
| LSTM-5 | 3 | 2 | 2 | 2.35 | LSTM-5 | 2nd place |
| BILSTM-2 | 4 | 4 | 3 | 3.85 | TDVE-3 | 3rd place |
| CNN-5 | 5 | 5 | 1 | 4.40 | BILSTM-2 | 4th place |
| SVM-1 | 6 | 6 | 6 | 6.00 | CNN-5 | 5th place |
| TDVE-3 | 2 | 3 | 4 | 2.80 | SVM-1 | 6th place |
| Users Inputs (IDs) | Items Inputs (IDs) | ||
|---|---|---|---|
| GMF block | MLP block | ||
| embedding layer (32)—user latent vectors. | embedding layer (32)—item latent vectors. | embedding layer (32)—user latent vectors. | embedding layer (32)—item latent vectors. |
| dropout layer: 0.5 | dropout layer: 0.5 | ||
| GMF layer: inner product of user and item vectors. | MLP layer: concatenate user and item vectors. | ||
| dropout: 0.5—1 hidden lay. (128) with relu. | |||
| dropout: 0.5—1 hidden lay. (128) with relu. | |||
| dropout: 0.5—1 hidden lay. (128) with relu. | |||
| concatenation layer to concatenate GMF and MLP feature vectors into a unique one. | |||
| 1 output layer (5) with softmax as activation function—Optimizer: adam—batch size: 500 | |||
| epochs: 20–100% (0% val.) trained and tested with the 100% of data. | |||
| Users Inputs (IDs) | Items Inputs (IDs) |
|---|---|
| embedding layer (32)—user latent vectors. | embedding layer (32)—item latent vectors. |
| dropout layer: 0.5—concatenation layer to concatenate user and item vectors into a unique one. | |
| 1 dropout layer: 0.5—1 hidden layer (128)—activation function: relu—1 batch normalization layer. | |
| 1 dropout layer: 0.5—1 hidden layer (128)—activation function: relu—1 batch normalization layer. | |
| 1 hidden layer (128)—activation function: relu. | |
| 1 output layer (5) with softmax as activation function—Optimizer: adam—batch size: 500 | |
| epochs: 20–100% (0% val.) trained and tested with 100% of data. | |
| NNMF | DLbR | SVD | SVD++ | ||
|---|---|---|---|---|---|
| DATAinit.-all | RMSE | 0.294 | 0.962 | 0.814 | 0.920 |
| F1 score | 98.48% | 83.07% | 50.42% | 60.67% | |
| accuracy | 98.79% | 84.69% | 73.38% | 76.15% | |
| time (min) | 26.44 | 24.72 | 4.22 | 6.82 | |
| DATApruned LSTM5 | RMSE | 0.287 | 0.902 | 0.801 | 0.894 |
| F1 score | 98.71% | 86.95% | 52.35% | 61.81% | |
| accuracy | 98.82% | 87.17% | 75.57% | 77.90% | |
| time (min) | 23.71 | 23.09 | 3.79 | 5.94 | |
| DATApruned BERT2 | RMSE | 0.284 | 0.869 | 0.805 | 0.892 |
| F1 score | 98.62% | 88.37% | 53.45% | 63.00% | |
| accuracy | 98.75% | 88.73% | 77.00% | 79.28% | |
| time (min) | 22.19 | 21.13 | 3.48 | 5.24 |
| NNMF | DLbR | SVD | SVD++ | ||
|---|---|---|---|---|---|
| K = 5 | NDCG | 99.77% | 91.37% | 95.90% | 91.50% |
| MAP | 40.00% | 55.00% | 28.00% | 28.00% | |
| K = 10 | NDCG | 99.77% | 91.37% | 95.90% | 91.50% |
| MAP | 20.00% | 33.21% | 14.00% | 19.29% | |
| K = 15 | NDCG | 99.77% | 91.37% | 95.90% | 91.50% |
| MAP | 13.33% | 22.14% | 9.33% | 9.33% |
| NNMF | DLbR | SVD | SVD++ | ||
|---|---|---|---|---|---|
| DATAinit.-all | RMSE | 0.097 | 0.792 | 0.832 | 0.844 |
| F1 score | 99.86% | 88.58% | 28.83% | 37.63% | |
| accuracy | 99.89% | 89.80% | 66.71% | 69.17% | |
| time (min) | 10.67 | 10.75 | 1.46 | 1.92 | |
| DATApruned LSTM5 | RMSE | 0.092 | 0.695 | 0.818 | 0.827 |
| F1 score | 99.87% | 89.98% | 29.91% | 39.50% | |
| accuracy | 99.90% | 91.04% | 70.00% | 72.43% | |
| time (min) | 9.03 | 8.58 | 1.21 | 1.69 | |
| DATApruned BERT2 | RMSE | 0.079 | 0.703 | 0.826 | 0.834 |
| F1 score | 99.89% | 90.94% | 31.60% | 40.77% | |
| accuracy | 99.91% | 91.91% | 68.39% | 70.94% | |
| time (min) | 10.00 | 8.32 | 1.15 | 1.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lemus Leiva, W.; Li, M.-L.; Tsai, C.-Y. A Two-Phase Deep Learning-Based Recommender System: Enhanced by a Data Quality Inspector. Appl. Sci. 2021, 11, 9667. https://doi.org/10.3390/app11209667
Lemus Leiva W, Li M-L, Tsai C-Y. A Two-Phase Deep Learning-Based Recommender System: Enhanced by a Data Quality Inspector. Applied Sciences. 2021; 11(20):9667. https://doi.org/10.3390/app11209667
Chicago/Turabian StyleLemus Leiva, William, Meng-Lin Li, and Chieh-Yuan Tsai. 2021. "A Two-Phase Deep Learning-Based Recommender System: Enhanced by a Data Quality Inspector" Applied Sciences 11, no. 20: 9667. https://doi.org/10.3390/app11209667