
A Tensor Space Model-Based Deep Neural Network for Text Classification



Abstract
:1. Introduction
2. Related Work
2.1. Deep Learning-Based Text Classification
2.2. The Tensor Space Model for Text Representation
3. Concept-Driven Deep Neural Networks for Text Classification
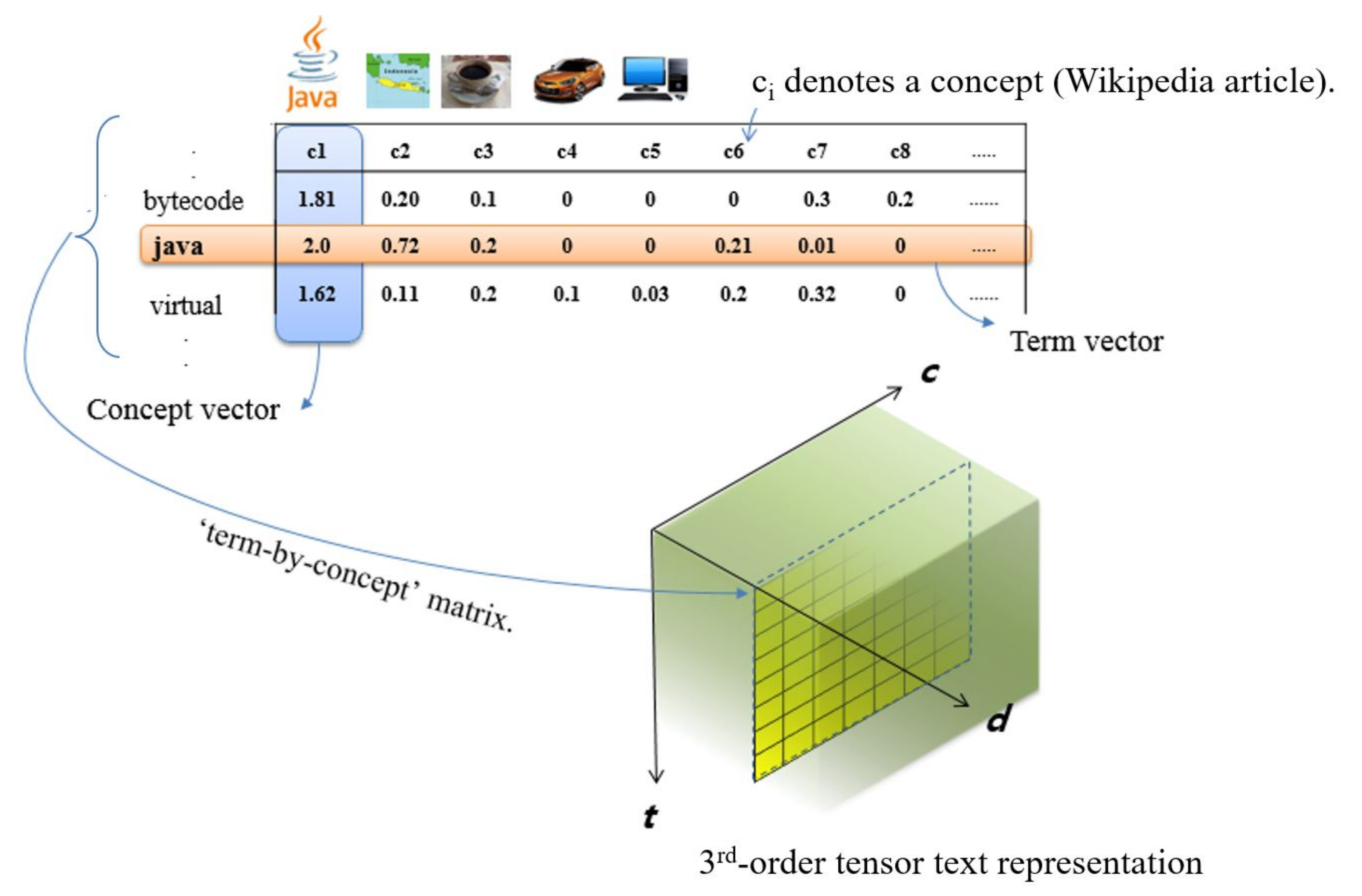
3.1. The Semantic Tensor Space Model
3.2. Embedding of Concepts and Documents
| Algorithm 1 Document embedding |
| Input: A term-by-concept matrix for a document i Output: A document embedding for a document i
|
3.3. The TSM-Based Deep Learning Architecture for Text Classification
- The first architecture (‘TSM-DNN’) is shown in Figure 7. In this architecture, the term-by-concept matrix for a given document is flattened and connected to form a single one-dimensional vector and then passed through multiple fully connected layers.
- The second architecture (‘concept-wise TSM-DNN’) is shown in Figure 8. This includes both the concept and document embedding layers introduced in Section 3.2. In other words, after creating a concept embedding vector for each concept, all concept embedding vectors are collected in two-dimensional form to create a document embedding.
- The third architecture (‘concept-wise TSM-CNN’) is shown in Figure 9. This is similar to the second architecture, except that multiple convolutional layers are added after the document embedding layer. In general, convolutional layers afford high performance when used to classify two- or three-dimensional image data. As document embedding is two-dimensional, we expected that classification would be improved on inclusion of convolutional layers. The width of the first such layer equals the length of document embedding, and the filter size is set to 3. When the number of convolutional layers is excessive, the number of hyper-parameters is too large to optimize. Hence, it is desirable to control the number of convolutional layers using one-dimensional Max-pooling with the stride set to 2.
4. Experiments
4.1. Empirical Setup
4.2. Tuning the Deep Learning Architectures
4.3. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Korde, V.; Mahender, C.N. Text classification and classifiers: A survey. Int. J. Artif. Intell. Appl. 2012, 3, 85–99. [Google Scholar]
- Liu, P.; Qui, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Fei-Fei, L.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://blog.openai.com/language-unsupervised (accessed on 21 September 2021).
- Luong, M.T.; Socher, R.; Manning, C.D. Better word representations with recursive neural networks for morphology. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, Sofia, Bulgaria, 8–9 August 2013; pp. 104–113. [Google Scholar]
- Lee, J.Y.; Dernoncourt, F. Sequential short-text classification with recurrent and convolutional neural networks. arXiv 2016, arXiv:1603.03827. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Cai, D.; He, X.; Han, J. Tensor space model for document analysis. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 625–626. [Google Scholar]
- Kutty, S.; Nayak, R.; Li, Y. XML documents clustering using a tensor space model. In Proceedings of the 15th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Shenzhen, China, 24–27 May 2011; pp. 488–499. [Google Scholar]
- Liu, N.; Zhang, B.; Yan, J.; Chen, Z.; Liu, W.; Bai, F.; Chien, L. Text representation: From vector to tensor. In Proceedings of the 5th IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; pp. 4–10. [Google Scholar]
- Liu, T.; Chen, Z.; Zhang, B.; Ma, W.Y.; Wu, G. Improving text classification using local latent semantic indexing. In Proceedings of the 4th IEEE International Conference on Data Mining, Brighton, UK, 1–4 November 2004; pp. 162–169. [Google Scholar]
- Boubacar, A.; Niu, Z. Conceptual Clustering. In Future Information Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–8. [Google Scholar]
- Gabrilovich, E.; Markovitch, S. Wikipedia-based semantic interpretation for natural language processing. J. Artif. Intell. Res. 2009, 34, 443–498. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Hu, J.; Zeng, H.J.; Chen, Z. Using Wikipedia knowledge to improve text classification. Knowl. Inf. Syst. 2009, 19, 265–281. [Google Scholar] [CrossRef]
- Wille, R. Formal concept analysis as mathematical theory of concepts and concept hierarchies. In Formal Concept Analysis; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–33. [Google Scholar]
- Lesk, M. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. In Proceedings of the 5th ACM International Conference on Systems Documentation, Toronto, ON, Canada, 8–11 June 1986; pp. 24–26. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Jacovi, A.; Shalom, O.S.; Goldberg, Y. Understanding convolutional neural networks for text classification. arXiv 2018, arXiv:1809.08037. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVM | Naïve Bayes | DNN | CNN | VDCNN Depth-17 | VDCNN Depth-29 | TSM DNN | Concept-Wise TSM-DNN | Concept-Wise TSM-CNN | |
|---|---|---|---|---|---|---|---|---|---|
| Reuters-21578 | 0.9073 | 0.9104 | 0.9700 | 0.9823 | 0.9853 | 0.9853 | 0.9952 | 0.9956 | 0.9965 |
| 20Newsgroup | 0.9245 | 0.8792 | 0.7220 | 0.8653 | 0.9216 | 0.9290 | 0.9597 | 0.9562 | 0.9667 |
| OHSUMED | 0.7665 | 0.7279 | 0.5546 | 0.6574 | 0.5954 | 0.4898 | 0.8400 | 0.8461 | 0.8522 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-j.; Lim, P. A Tensor Space Model-Based Deep Neural Network for Text Classification. Appl. Sci. 2021, 11, 9703. https://doi.org/10.3390/app11209703
Kim H-j, Lim P. A Tensor Space Model-Based Deep Neural Network for Text Classification. Applied Sciences. 2021; 11(20):9703. https://doi.org/10.3390/app11209703
Chicago/Turabian StyleKim, Han-joon, and Pureum Lim. 2021. "A Tensor Space Model-Based Deep Neural Network for Text Classification" Applied Sciences 11, no. 20: 9703. https://doi.org/10.3390/app11209703
APA StyleKim, H.-j., & Lim, P. (2021). A Tensor Space Model-Based Deep Neural Network for Text Classification. Applied Sciences, 11(20), 9703. https://doi.org/10.3390/app11209703