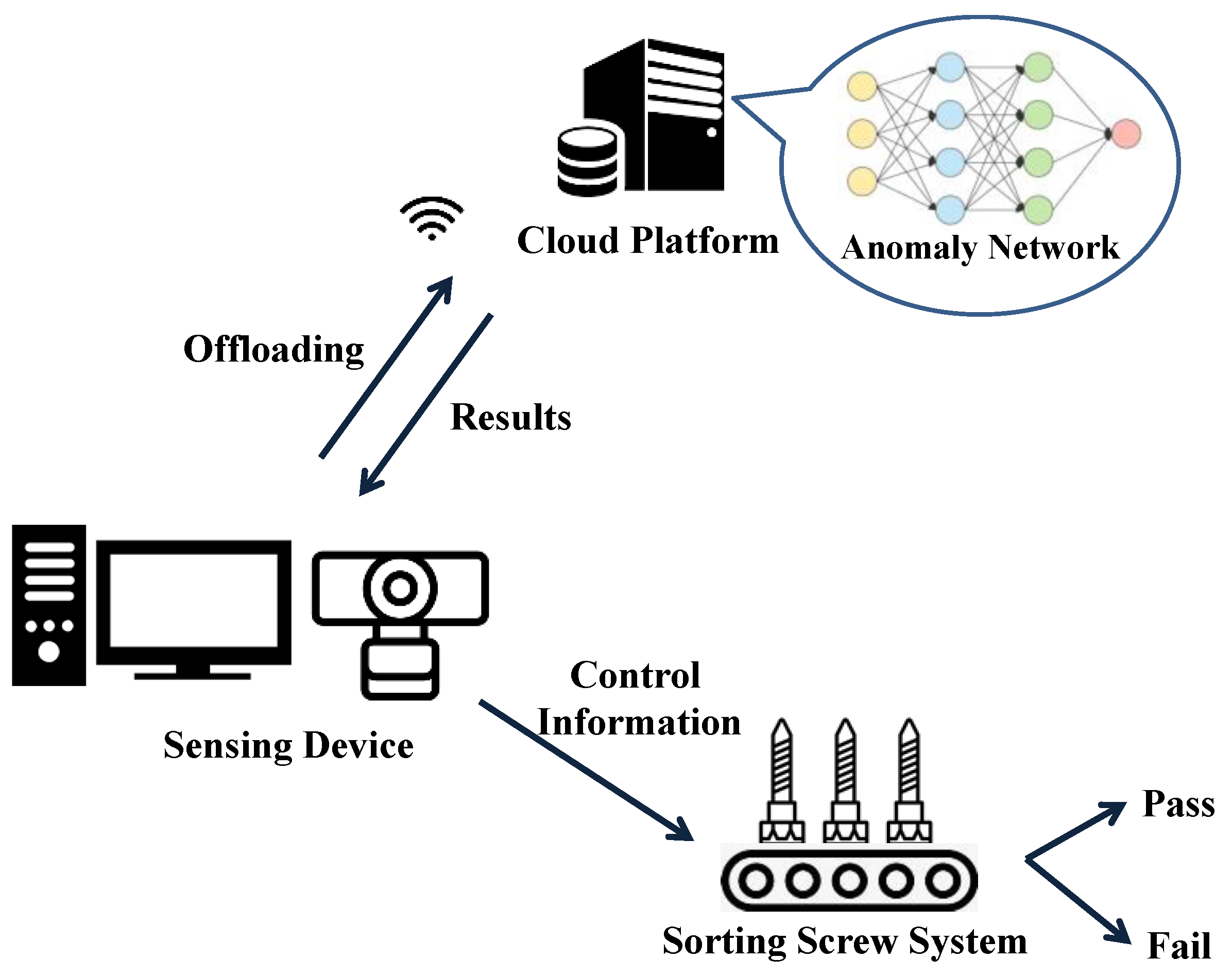
1. Introduction
Although the IoT technique has been proposed for a period time, it has not yet been widely adapted in the manufacturing industry. Integrating AI and internet of things (IoT) techniques into automated factories has turned into a trend in recent times [
1,
2]. The apparent difference between the smart factory and the traditional automated factory is whether IoT technology has been introduced or not. IoT systems are comprised of intelligent terminal equipment, wireless networks, cloud, and big data management. Considering the limitation of the devices, the IoT technology transfers big data from cameras or mechanical devices embedded with the sensors and software to the cloud platform through the network [
3]. Therefore, data clustering is utilized to handle big data. Factories can access big data that are stored in the cloud efficiently and quickly. Recently, several studies have introduced the IoT technique to improve the industrial problem, such as fault diagnosis [
4], insulator string defect detection [
5], and LCD display defect detection [
6]. A smart factory using IoT techniques can manage automation equipment and automated defect detection devices with more intelligence than automated factories, which can significantly improve product quality and production efficiency. The current screw factory manufacturing process mainly includes screw production, defect detection, and product packaging. A major concern for the screw factory is how to minimize defects and prevent the flow of defective products. The screw is designed to be fastened into position within a hole by means of the thread surrounding the flank surface, which is beneficial for fasteners since they cannot fall out and damage the machinery. Screws must comply with a strict quality and safety requirements. Critical applications with regard to high precision, stability, and safety are other important elements for selecting screws. Therefore, the task of detecting defective screws plays an important role in the process of producing screws.
Although the automated optical inspection (AOI) technique is broadly applied using a sorting machine to inspect for defective screws, the detection of defective screws with a high degree of precision is still a challenging issue. At present, the texture analysis carried out by a computer vision algorithm of Fourier-based restoration is widely used to identify defective screw surfaces [
7]. The idea of Fourier transformation method transfers the thread image into a frequency domain. Then, the notch-rejected filter is used to eliminate the high-energy frequency of thread pattern and transform it back to the spatial domain, for the defective internal thread to be detected. However, the limitation of the Fourier transformation method is that the thread pattern with different densities has a distinct frequency, leading to the tedious work of adjusting the parameters of the algorithm. Owing to the mutual restraint of the complex algorithm parameters, the parameter variables are highly dependent on the production environment, such as inhomogeneous illumination, low contrast, and blurry contour, resulting in the instability of detection results. If different parameters are set, the results may be overkill (potential good units being killed) or underkill (potential bad units escaping) of defective images. Moreover, the parameter setting of these complex algorithms requires well-trained professional operators to constantly adjust the parameters, which is a time-consuming and tiresome task. The AI technology can automatically learn the features of the defects. Consequently, adapting AI technology to detect screw surface defects can greatly improve traditional methods. Combining AI and IoT techniques is the latest development trend [
8]. Images can be uploaded to a cloud platform for centralized management by the IoT technology, and the AI model can be trained in a more professional manner. The detection results of the screw products can be sent to the cloud for data aggregation and statistics collection, which can monitor the operation status of the entire inspection system, enabling the screw factory to operate more efficiently.
With the rapid development of technology, artificial intelligence techniques have achieved impressive success and turned into a hot topic in image processing research. Utilizing deep learning techniques to solve the defect detection issue can alleviate the need for complicated manual feature extraction. Deep learning techniques can automatically learn and extract meaningful features from raw images more comprehensively than previously possible [
9]. Although deep learning technology can automatically extract features in a better way than the traditional manual methods of feature selection, this kind of supervised learning based on deep learning networks needs a large amount of labeled data for model training [
10]. It is difficult to acquire abnormal images in actual situations where defect detection is currently being conducted, resulting in limitations in developing supervised deep learning networks. Moreover, supervised learning needs to consider the data imbalance problem during the training process. Furthermore, deep learning models fail to generalize well on small-scale datasets. Unsupervised learning of anomaly detection has been a hot technique in the defect detection field, which can solve the problem of supervised learning with a large number of defective images and data imbalances for model training. The goal of the unsupervised learning method is to learn the represented features of the normal image and reconstruct the input image. The anomaly features that deviate from the normal features can be detected through the residual error between the reconstructed and original images. Moreover, the state-of-the-art unsupervised learning network can be trained without labeled data [
11,
12,
13,
14]. The comparison between supervised learning and unsupervised learning is shown in
Table 1.
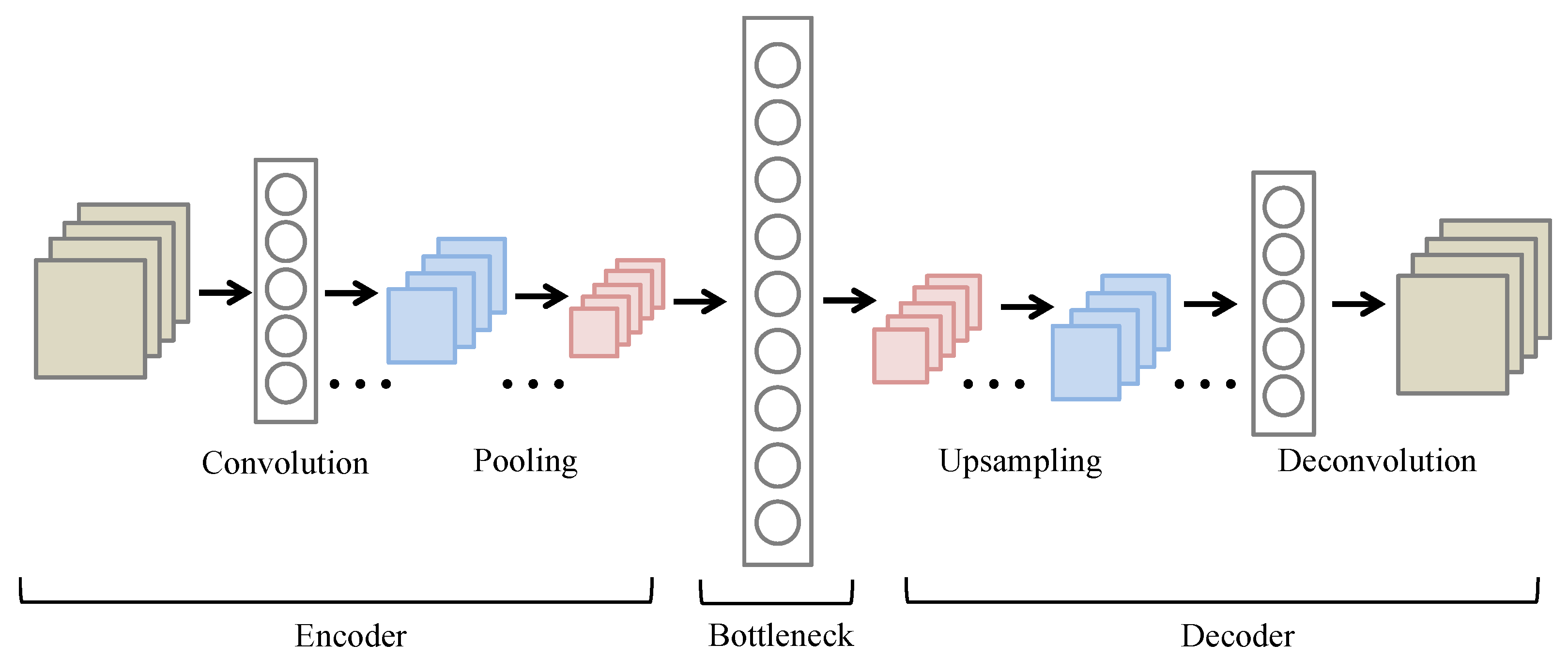
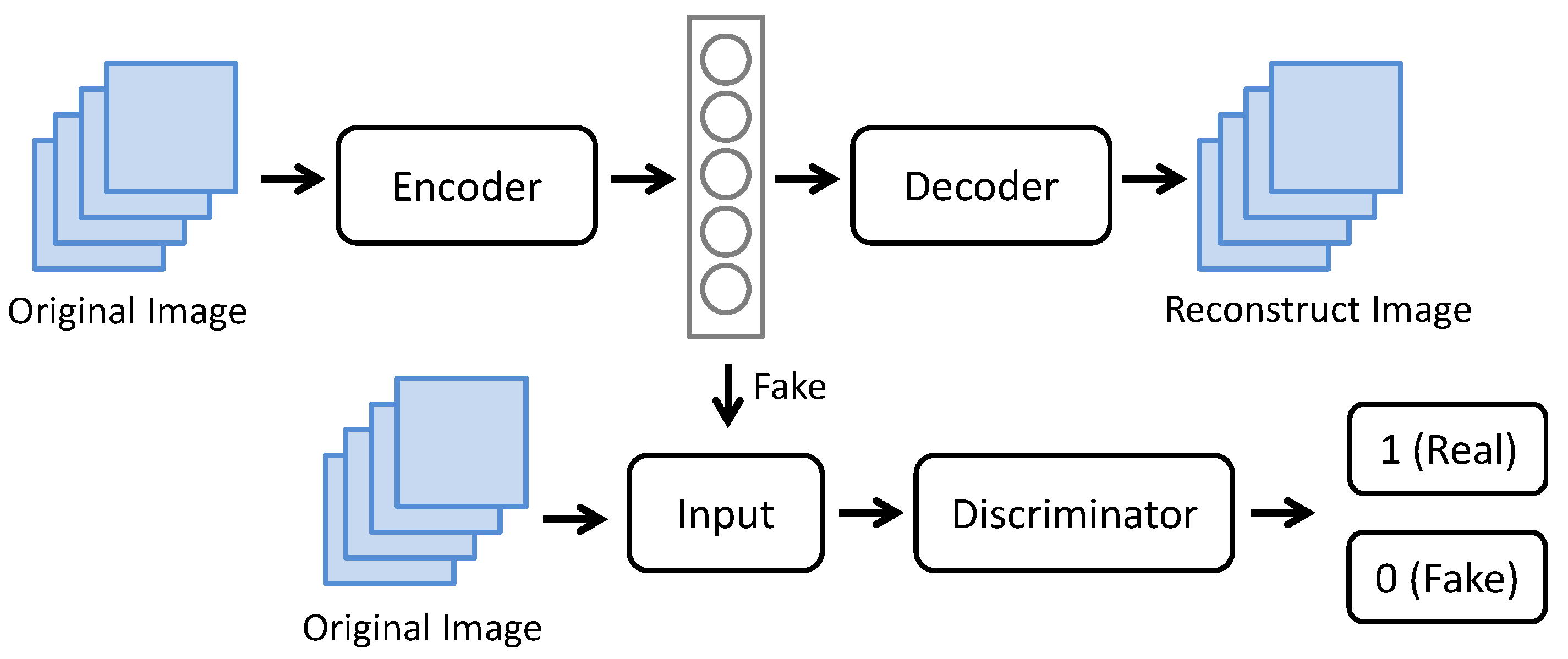
Famous unsupervised models such as convolutional autoencoder, adversarial autoencoders [
15], denoising adversarial autoencoders [
16], etc., have been successfully applied to anomaly detection. For example, J. Yu et al. [
17] proposed a two-dimensional principal component analysis-based convolutional autoencoder network for detecting defects on wafer maps. J. K. Chow et al. [
18] utilized a convolutional autoencoder network for detecting the defect on concrete structure. Compared with the other segmentation models, the convolutional autoencoder network was adaptable for detecting the defect with a wide range of scale. G. Kang et al. [
19] proposed a detection system, which combined the faster R-CNN and deep denoising autoencoder models to analyze the defect on the insulator surface. The experiment results showed that the defect state can be determined by the score of classification and anomaly network. S. Mei et al. [
20] proposed the convolutional denoising autoencoder networks to detect and localize the defects at the same time. The experimental results showed that the proposed approach can effectively detect the defect on homogeneous and non-regular textured surface. The above researches have shown that anomaly detection models could be applied to industrial defect detection applications without having a defect dataset for model training, which provides more convenience and effectiveness for analyzing defective images. Most of the reconstruction models are based on the encoding-decoding structure, where the CAE network is one of the most well-known reconstruction models. The CAE model can extract features from the normal image in the compression and decompression processes. Moreover, the AAE network is a type of generative adversarial network (GAN) based on the encoding-decoding architecture. The main idea of the AAE model is to generate fake images that are similar to the original input image through the process of minimizing the differences between the input and output image, in order to detect the defective region. Although numerous anomaly deep learning networks have achieved remarkable success, the existing studies mainly focus on the performance of deep learning networks in relation to defect detection applications. Yet, seldom research has considered the application of anomaly network algorithms in defective screw systems. Therefore, the proposed smart sorting screw system employs anomaly deep learning networks of two classical models and IoT technology to detect the defective screws. The research contribution can be summarized as follows:
- (1)
A template matching algorithm is utilized to expand the curved screw surface images into panoramic images, which can comprehensively and automatically detect the defective surface of the spiral screw.
- (2)
A novel anomaly detection method running on convolutional autoencoder and adversarial autoencoder networks is utilized to automatically recognize the defective areas without the benefit of defective images for model training.
- (3)
To improve the process of deep learning training, the IoT technology is introduced to the defective screw detection system, which can upload images to a cloud platform for more efficient model training.
The remainder of this research is organized as follows. The proposed method is presented in
Section 2, which contains the structure of the proposed system, an image stitching technique, and two anomaly detection techniques. The experiment and discussion in this study are illustrated in detail in
Section 3. Finally, the conclusions drawn from of this study are provided in
Section 4.
3. Experiment and Discussion
To evaluate the performance of the proposed methods, template matching combined with anomaly models of CAE and AAE networks are investigated in this section. Initially, the datasets utilized in this work are described in detail. Then, three experiment parts are presented. Moreover, the template matching method is evaluated first to view the effectiveness of the merged images. Thereafter, the comprehensive results of the two anomaly networks, namely CAE and AAE, are discussed and compared to explore the detection performance. Finally, specific descriptions are provided.
3.1. Dataset Descriptions and Experiment Setup
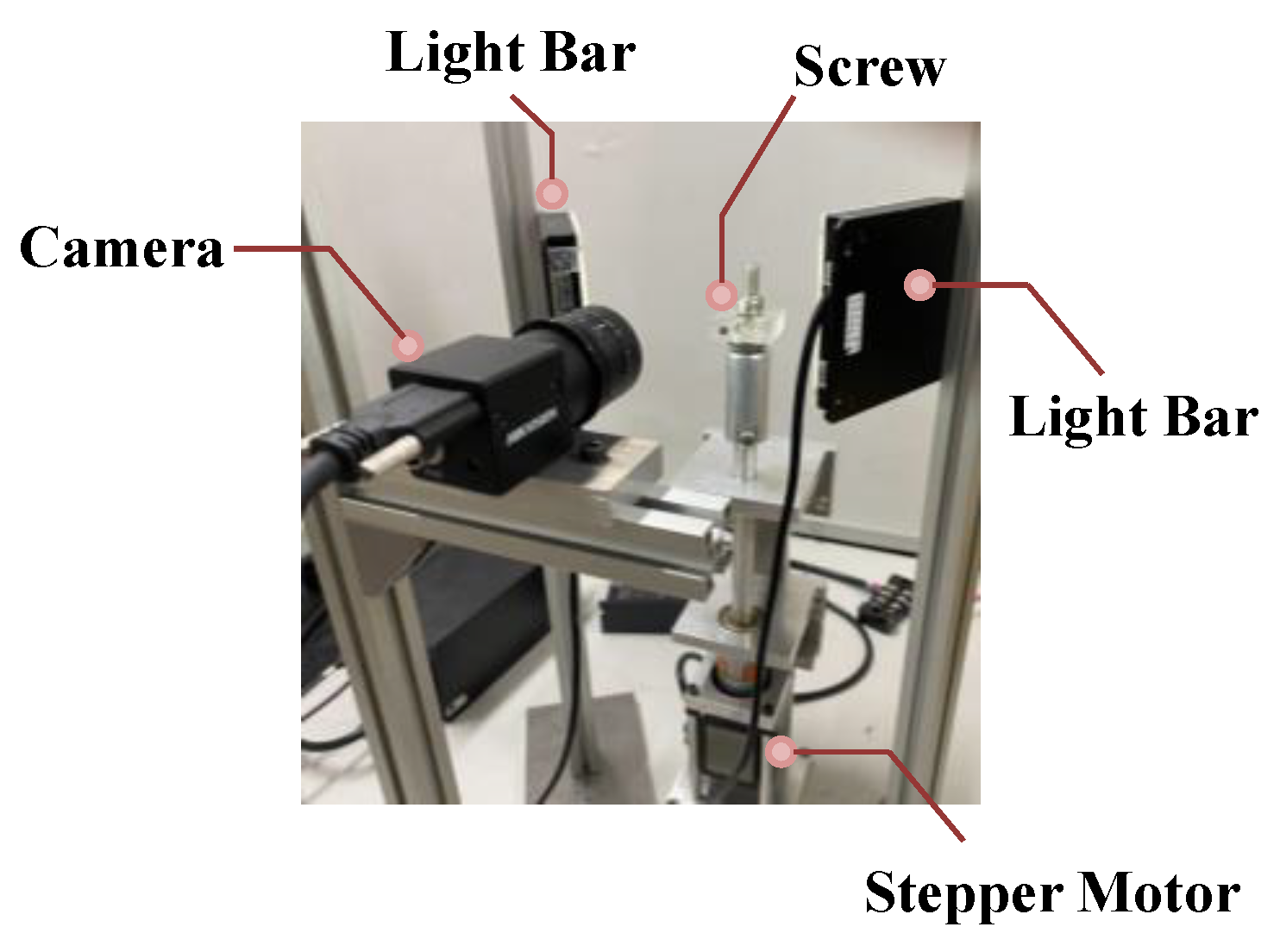
In this study, the dataset of screw images is captured from the sensing device of the developed optical instrument. The developed system of the optical instrument provides more details, as shown in
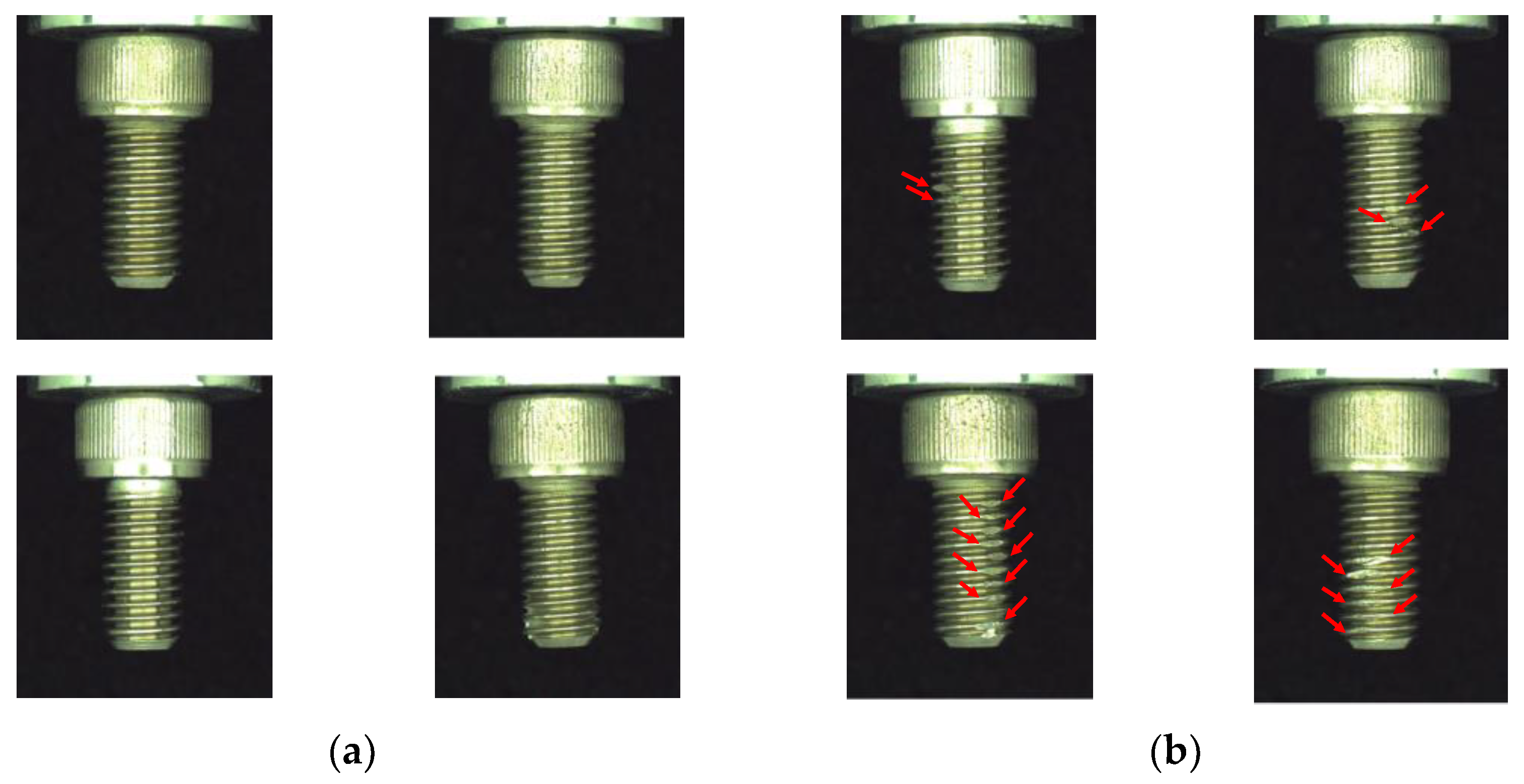
Figure 4. In order to comprehensively capture the spiral screw, the developed optical instrument is designed to place the screw on the rotating plate, which is perpendicular to the lens. In addition, the stepper motor can drive the rotating plate to rotate in 360 degrees. For each screw product, about 200 images of screw images can be captured in 5 s. Moreover, the image quality is an essential factor, which will affect the result of the subsequent analysis in this study. The screw images are captured on the Hikvision camera coupled with the MORITEX lens, which can generate the high quality of the screw images. To capture the defective region on the screw more clearly, the front light of the light bars are placed on two sides of the object to create strong reflections on the screw surface. The experimental images of the spiral screw are shown in
Figure 5, where the defective region on the spiral screw is indicated with the red arrow, and each image has the same scale with 762 × 920 pixels. The image resolution is approximately 0.03 mm/pixel.
Moreover, the convolutional and adversarial autoencoders are used as the core AI models for detecting the defective region on the screw image. In this experiment, both of these two networks are implemented on the cloud platform of NVIDIA GTX 1080 GPU with the TensorFlow framework. The hyper parameters of CAE were set as 8500 epochs, 0.05 learning rate, mean squared error of loss function, and Adam optimizer. The AAE model parameters were set as 10,000 epochs, 0.0002 learning rate, mean squared error and binary cross-entropy of loss function, and Adam optimizer.
3.2. Template Matching of Expanding the Spiral Screw
A characteristic of the screw product is the curved surface that must be turned around the screw product for detecting the defective region on the surface. The limitation of detecting the spiral screw product is selecting a specific angle to capture the defective screw region. The different capturing positions have different appearance results of the defective region. In order to address this issue, the template matching method is utilized to stitch several slices of the curved surface into a panoramic image. It is an important image preprocessing method before detecting the defective region of the screw images. The aim of the template matching approach is to find the best matched template image, which is drawn from the inspected images. The template matching process slices the template image over all the possible positions of the source image and finds the best similarity score pixel-by-pixel between the template image and the covered image. In this way, multiple slices of spiral screw images can be merged into a larger image. A schematic diagram of the template matching approach is shown in
Figure 6. The template image represents the region we expected to find across the source image. The template image is compared to the source image and the highest value of correlation based on the normalized cross-correlation is calculated. The red boundary box in
Figure 6c represents the region with the highest similarity to the source image. To acquire a comprehensive panoramic image, the template image will replace the overlapped region of the source image by finding the highest similarity score. The process of template matching by merging multiple sliced screw images into a panoramic image is illustrated in
Figure 7. The 360 degrees of spiral screw product is captured into slice images per 1 degree in this study. In total, approximately 300 images are captured for each screw product, and seven spiral screw products are used in this study analysis. The extended panoramic image with different angles for four screw products is given in
Figure 8, where the image resolution of the panoramic image is 2130 × 960 pixels. According to
Figure 8, the results show that the template image can be precisely matched to the source image and successfully expanded into a panoramic image. In addition, the location of the defective screw can be clearly shown by looking at the panoramic screw image. The defective regions of the panoramic image are marked with red and indicated in
Figure 8. Compared with the unstitched the screw image, the merged panoramic screw image illustrates the defective region more efficiently.
3.3. Performance of the CAE and AAE Models
3.3.1. The Patch Images Used for Study Analysis
Preparing the training and testing datasets is an important process before conducting the model training and testing. The two factors will affect the training results, which are the scale of the patch image and the total number of training dataset. According to these two factors, the following description provides more details for the experiment dataset. The scale of the patch image needs to be defined at first. If the patch images are either too large or too small, this would have an effect on the model training results. For the texture of the screw image, the features in the patch image need to contain the screw stripe. If the patch images are sliced too large, the details of the features cannot be learned well. In contrast, if the patch images are sliced too small, the network cannot learn the characteristic features over the whole image. Therefore, the dimension of the patch image is selected as 128 × 128 pixels for the best scale in the experiment. On the other hand, the number of the training dataset is another factor influencing the performance of the network. In order to have better performance on the training dataset, the screw panoramic images are sliced into multiple patch images in this study, which can create a large amount of positive datasets for model training as well as learn the normal features more effectively. In our experiments, a normal panoramic screw image is selected as the training dataset. Then, the whole panoramic screw image is sliced by the sliding window method, which is depicted in
Figure 9. The patch images are acquired with the sliding window of 128 × 128 pixels. In addition, 16 pixel strides move along the rows and columns. Therefore, the training dataset can be obtained by approximately 284 patch images. In the testing phase, the remaining panoramic screw images can be sliced into 25 image patches with the same scale of 128 × 128 pixels, which contains the normal and abnormal datasets. The slice patches of the panoramic screw image are shown in
Figure 10, where the resolution of the panoramic screw image for the testing phase is 384 × 768 pixels. Moreover, the data augmentation method of rotation and horizontal flipping is utilized to create more datasets in this article, which can prevent overfitting during the training process. The training dataset can be increased to 10,000 patch images for network training by the data augmentation method.
3.3.2. The Meaning of Patch Image for CAE and AAE Networks
Both the CAE and AAE networks learn the normal texture of the screw dataset in the training stage. In addition, abnormal datasets are utilized during the testing stage to evaluate the model performance. Prior to comparing the results produced by the two networks, the functioning of normal and abnormal images on the network is illustrated as follows. Normal images can be utilized to examine the reconstruction ability of the network. If the reconstruction ability is great, the reconstructed image can be restored as the original image. The residual image showing the difference between the original image and the reconstructed image would not appear in the anomaly region, which would be shown as a back graph. It represents the effectiveness of the network in extracting features from the source images during the process of encoding and decoding. Furthermore, for the abnormal images, the network could restore the defective region that appears in the images to the normal reconstructed image. The residual figure can be inspected to examine the difference between the original image and reconstructed image for detecting the features of the defective texture. The meaning of the normal patch images for two networks is shown in
Figure 11, where
Figure 11a is the original image of normal dataset trained by the network;
Figure 11b is the reconstructed image derived from the normal dataset extracted by the network;
Figure 11c is the residual image taken from the normal dataset, which shows the difference between the original image and reconstructed image; and
Figure 11d is a superimposed image, which combines the original and residual images taken from a normal dataset. The meaning of the abnormal patch for two networks is shown in
Figure 12, where
Figure 12a is the original image taken from an abnormal dataset tested by the network;
Figure 12b is the reconstructed image derived from an abnormal dataset detected by the network;
Figure 12c is the residual image taken from an abnormal dataset, which is the difference between the original image and reconstructed image; and
Figure 12d is the superimposed image, which combines the original and residual images from the abnormal dataset. The resolution of each patch is 128 × 128 pixels in
Figure 11 and
Figure 12.
3.3.3. Comparison between CAE and AAE Networks
To compare the performance of the AAE and CAE networks, this study partially selects the normal and abnormal patch images of the four screw images for discussion. A comparison illustrating the detection of the screw patch images with 128 × 128 pixels taken from normal and abnormal images of the model testing are shown in
Table 2. Examining the two anomaly detection networks, it can be observed that the AAE model can successfully restore the reconstructed image to the original normal image using both normal and abnormal datasets. Moreover, the AAE network has the ability to effectively recognize the defective region of the slice patch dataset.
3.3.4. Evaluation Criteria of CAE and AAE Networks
It is necessary to evaluate the predictive performance after the model training process. In this study, three evaluation criteria, the intersection over union (IoU), dice coefficient (DC), and frames per second (FPS) [
24] were used to quantify the experiment results of the two anomaly networks. IoU is known to be a popular metric to calculate the overlap percentage of the common pixels between the predicted region and ground truth. The range of the IoU is from 0 to 1, where an IoU of 0 represents no overlap between the predicted region and ground truth. An IoU of 1 indicates that the predicted region and ground truth perfectly overlap. Moreover, the dice coefficient is another widely used indicator, which is similar to the IoU. The dice coefficient is used to evaluate the similarity of the predicted region and ground truth. Both of these indicators were compared with the ground truth (GT), which were provided in Equations (10) and (11).
Seven screw datasets were employed to test the two networks under the same circumstances of the model parameters, such as the epoch and learning rate. The experiment results of AAE and CAE are shown in
Table 3. The quantitative detection of the two networks is given in
Table 4. According to the results, the average IoU of CAE and AAE are 0.31 and 0.34, respectively and the average DC of CAE and AAE are 0.45 and 0.51, respectively. It can be found that a predictive result of the AAE is similar to the ground truth. The AAE network exhibits a higher performance than the CAE network in detecting the defective region of the screw image. Moreover, the frame per second (FPS) number is another indicator to figure out the real-time detection on the AAE and CAE networks. The different structures of the networks have different depths, which affect the recognition rate of the network. The results show that with more complexity layers of the CAE network, the detection speed is slower.
3.3.5. Synthetization of the Patch Images
As previously stated, the CAE and AAE networks are used to train and test the slice patch images, which are generated from the original images. In order to examine the defective texture that appeared in the original screw image more clearly, this study synthesized the patch residual images to the original panoramic image. The patch images synthesized to the original panoramic image of CAE and AAE networks are shown in
Figure 13. From left to right, the images include the original synthesized image, the CAE synthesized image, and the AAE synthesized image, where the CAE synthesized image is the detection result of the CAE network, and the AAE synthesized image is the detection result of the AAE network. The resolution of the synthesized image is 387 × 768 pixels in
Figure 13. From an overview of these three images, it can be seen that the AAE network can comprehensively detect the defective region found in the panoramic screw image. Moreover, it indicates that the AAE network has an ability to generate a normal image more efficiently, with the result that the residual images of defective regions can be recognized with more precision.
4. Results and Discussion
The proposed smart sorting screw system integrates the image stitching technique, anomaly deep learning networks, and IoT technology to comprehensively and automatically identify the defective spiral screw products. According to the results of image stitching technique, the template matching method can merge the sliced screw image into panoramic images, which improves the effectiveness for analyzing defective images. Moreover, any rotation product problems can be detected using the template matching technique through the proposed system. The experimental results show that the AAE model can restore the abnormal region to a normal region in a better way than the CAE model. Although the quantitative results achieve a slightly lower accuracy in detecting the defective screw image, the proposed methods are more meaningful in a practical application, as it dramatically improves the traditional image processing techniques of adjusting the parameter setting. Moreover, the unsupervised learning method of learning image reconstruction overcomes the supervised learning strategy of requiring an extensive amount of normal and abnormal images for model training, which provides a breakthrough in practical industrial applications. In addition, the main challenge of anomaly detection model is the poor quality of the reconstruction image, which leads to imprecise defect localization. In future work, this study will mainly make an effort to enhance the quality of reconstruction image by adding more features or noises to the training stage, making the anomaly detection models more robust and precise.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



























































