
Causality Mining in Natural Languages Using Machine and Deep Learning Techniques: A Survey


Abstract
:1. Introduction
1.1. Concept and Representation of Causality
1.2. Research Contributions
2. Machine Learning Techniques
2.1. Review Methodology for Machine Learning Techniques
- IEEE Xplore Digital Library
- Google Scholar
- ACM Digital Library
- Wiley Online Library
- Springer Link
- Science Direct
2.2. Mining Explicit Causality Based on Linguistics and Simple Cue Patterns
2.3. Mining Implicit and Heterogeneous Causality
3. Deep Neural Models, Frameworks, and Techniques
3.1. Neural Networks and Deep Learning
3.2. Loss Functions and Optimization Algorithms
3.3. Brief History of Deep Neural Network
3.4. Deep Neural Network for Natural Language Processing
3.5. Motivation for Causality Mining
3.6. Deep Learning Frameworks
3.7. Review Methodology for Deep Learning Techniques
- IEEE Xplore Digital Library
- Google Scholar
- ACM Digital Library
- Wiley Online Library
- Springer Link
- Science Direct
3.8. Deep Learning Techniques for Causality Mining
4. Comparing the Two Paradigms
5. Challenges and Future Guidelines
5.1. Ambiguous/Implicit Data
5.2. Features Engineering
5.3. Model Selection
5.4. Nature of Causality
5.5. Data Standardization
5.6. Computational Cost
5.7. Accuracy
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chan, K.; Lam, W. Extracting causation knowledge from natural language texts. Int. J. Intell. Syst. 2005, 20, 327–358. [Google Scholar] [CrossRef]
- Luo, Z.; Sha, Y.; Zhu, K.Q.; Wang, Z. Commonsense Causal Reasoning between Short Texts. In Proceedings of the Fifteenth International Conference on Principles of Knowledge Representation and Reasoning, KR’16, Cape Town, South Africa, 25–29 April 2016; pp. 421–430. [Google Scholar]
- Khoo, C.; Chan, S.; Niu, Y. The Many Facets of the Cause-Effect Relation. In The Semantics of Relationships; Springer: Berlin/Heidelberg, Germany, 2002; pp. 51–70. [Google Scholar]
- Theodorson, G.; Theodorson, A. A Modern Dictionary of Sociology; Crowell: New York, NY, USA, 1969; p. 469. [Google Scholar]
- Hassanzadeh, O.; Bhattacharjya, D.; Feblowitz, M. Answering Binary Causal Questions Through Large-Scale Text Mining: An Evaluation Using Cause-Effect Pairs from Human Experts. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019; pp. 5003–5009. [Google Scholar]
- Pearl, J. Causal inference in statistics: An overview. Stat. Surv. 2009, 3, 96–146. [Google Scholar] [CrossRef]
- Girju, R. Automatic detection of causal relations for question answering. In Proceedings of the ACL 2003 Workshop on Multilingual Summarization and Question Answering, Sapporo, Japan, July 2003; Volume 12, pp. 76–83. [Google Scholar]
- Khoo, C.; Kornfilt, J. Automatic extraction of cause-effect information from newspaper text without knowledge-based inferencing. Lit. Linguist. Comput. 1998, 13, 177–186. [Google Scholar] [CrossRef]
- Radinsky, K.; Davidovich, S.; Markovitch, S. Learning causality for news events prediction. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 909–918. [Google Scholar]
- Silverstein, C.; Brin, S.; Motwani, R.; Ullman, J. Scalable techniques for mining causal structures. Data Min. Knowl. Discov. 2000, 4, 163–192. [Google Scholar] [CrossRef]
- Riaz, M.; Girju, R. Another Look at Causality: Discovering Scenario-Specific Contingency Relationships with No Supervision. In Proceedings of the 2010 IEEE Fourth International Conference on Semantic Computing, Pittsburgh, PA, USA, 20–22 September 2010; pp. 361–368. [Google Scholar]
- Hashimoto, C.; Torisawa, K.; Kloetzer, J.; Sano, M. Toward future scenario generation: Extracting event causality exploiting semantic relation, coantext, and association features. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MA, USA, 22–27 June 2014; pp. 987–997. [Google Scholar]
- Ackerman, E. Extracting a causal network of news topics. Move Mean. Internet Syst. 2012, 7567, 33–42. [Google Scholar]
- Bollegala, D.; Maskell, S. Causality patterns for detecting adverse drug reactions from social media: Text mining approach. JMIR Public Health Surveill. 2018, 4, e8214. [Google Scholar] [CrossRef] [PubMed]
- Richardson, M.; Burges, C. Mctest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 193–203. [Google Scholar]
- Berant, J.; Srikumar, V. Modeling biological processes for reading comprehension. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1499–1510. [Google Scholar]
- Hassanzadeh, O.; Bhattacharjya, D.; Feblowitz, M.; Srinivas, K.; Perrone, M.; Sohrabi, S.; Katz, M. Causal Knowledge Extraction through Large-Scale Text Mining. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13610–13611. [Google Scholar]
- Khoo, C.S.; Myaeng, S.H.; Oddy, R.N. Using cause-effect relations in text to improve information retrieval precision. Inf. Process. Manag. 2001, 37, 119–145. [Google Scholar] [CrossRef]
- Khoo, C.; Chan, S. Extracting causal knowledge from a medical database using graphical patterns. In Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics, Hong Kong, China, 3–6 October 2000; pp. 336–343. [Google Scholar]
- Sachs, K.; Perez, O.; Pe’er, D.; Lauffenburger, D.A.; Nolan, G.P. Causal protein-signaling networks derived from multiparameter single-cell data. Science 2005, 308, 523–529. [Google Scholar] [CrossRef] [Green Version]
- Araúz, P.L.; Faber, P. Causality in the Specialized Domain of the Environment. In Proceedings of the Semantic Relations-II, Enhancing Resources and Applications Workshop Programme Lütfi Kirdar, Istanbul Exhibition and Congress Centre, Istanbul, Turkey, 22 May 2012; p. 10. [Google Scholar]
- General, P.W. Representing causation. J. Exp. Psychol. 2007, 136, 1–82. [Google Scholar]
- Talmy, L. Toward a Cognitive Semantics; Volume I: Concept Structuring Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 1–565. [Google Scholar]
- Semantics, J.H. Toward a useful concept of causality for lexical semantics. J. Semant. 2005, 22, 181–209. [Google Scholar]
- White Peter, A. Ideas about causation in philosophy and psychology. Psychol. Bull. 1990, 108, 1–3. [Google Scholar]
- Scaria, A.; Berant, J.; Wang, M.; Clark, P.; Lewis, J. Learning biological processes with global constraints. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1710–1720. [Google Scholar]
- Ayyoubzadeh, S.; Ayyoubzadeh, S. Predicting COVID-19 incidence through analysis of google trends data in iran: Data mining and deep learning pilot study. MIR Public Health Surveill. 2020, 6, e18828. [Google Scholar] [CrossRef] [PubMed]
- FAQ about Google Trends Data—Trends Help. Available online: https://support.google.com/trends/answer/4365533?hl=en# (accessed on 3 October 2021).
- Blanco, E.; Castell, N.; Moldovan, D. Causal Relation Extraction. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008; pp. 310–313. [Google Scholar]
- Hendrickx, I.; Kim, S.N.; Kozareva, Z.; Nakov, P.; Diarmuidó, D.; Diarmuidó, S.; Padó, S.; Pennacchiotti, M.; Romano, L.; Szpakowicz, S. SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals. arXiv 2019, arXiv:1911.10422. [Google Scholar]
- Sorgente, A.; Vettigli, G.; Mele, F. Automatic Extraction of Cause-Effect Relations in Natural Language Text. In Proceedings of the 7th International Workshop on Information Filtering and Retrieval Co-Located with the 13th Conference of the Italian Association for Artificial Intelligence (AI*IA 2013), Turin, Italy, 6 December 2013; pp. 37–48. [Google Scholar]
- Cresswell, M. Adverbs of causation. In Words, Worlds, and Contexts: New Approaches in Word Semantics; De Gruyter: Berlin, Germany, 1981; pp. 21–37. [Google Scholar]
- Simpson, J. Resultatives. In Papers in Lexical-Functional Grammar; Indiana University Linguistics Club: Bloomington, IN, USA, 1983; pp. 1–17. [Google Scholar]
- Altenberg, B. Causal linking in spoken and written English. Stud. Linguist. 1984, 38, 20–69. [Google Scholar] [CrossRef]
- Nastase, V. Semantic Relations across Syntactic Levels; University of Ottawa: Ottawa, ON, USA, 2004; pp. 1910–2010. [Google Scholar]
- Sadek, J. Automatic detection of arabic causal relations. In International Conference on Application of Natural Language to Information Systems (NLDB’13); Springer: Berlin/Heidelberg, Germany, 2013; pp. 400–403. [Google Scholar]
- Garcia, D. COATIS, an NLP system to locate expressions of actions connected by causality links. In Proceedings of the Knowledge Acquisition, Modeling and Management: 10th European Workshop, EKAW’97, Sant Feliu de Guixols, Catalonia, Spain, 15–18 October 1997; pp. 347–352. [Google Scholar]
- Asghar, N. Automatic extraction of causal relations from natural language texts: A comprehensive survey. arXiv 2016, arXiv:1605.07895. [Google Scholar]
- Gelman, A. Causality and statistical learning. Am. J. Sociol. 2011, 117, 955–966. [Google Scholar] [CrossRef]
- Athey, S.; Stat, G.I. Machine learning methods for estimating heterogeneous causal effects. Stat 2015, 1050, 1–26. [Google Scholar]
- Mooij, J.; Peters, J.; Janzing, D.; Zscheischler, J. Distinguishing cause from effect using observational data: Methods and benchmarks. J. Mach. Learn. Res. 2016, 17, 1103–1204. [Google Scholar]
- Spirtes, P.; Zhang, K. Causal discovery and inference: Concepts and recent methodological advances. Appl. Inform. 2016, 3, 1–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, R.; Cheng, L.; Li, J.; Hahn, P.R.; Liu, H. A Survey of Learning Causality with Data: Problems and Methods. ACM Comput. Surv. 2020, 53, 1–37. [Google Scholar]
- Quinlan, J. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Charniak, E. A maximum-entropy-inspired parser. In Proceedings of the 1st Meeting of the North American Chapter of the Association for Computational Linguistics, Seattle, WA, USA, 29 April–4 May 2000; pp. 132–139. [Google Scholar]
- Rosario, B.; On, M.H. Classifying the semantic relations in noun compounds via a domain-specific lexical hierarchy. In Proceedings of the 2001 Conference on Empirical Methods in Natural Language Processing (EMNLP-01), Pittsburgh, PA, USA, 3–4 June 2001; pp. 82–90. [Google Scholar]
- Chang, D.; KS, C. Causal relation extraction using cue phrase and lexical pair probabilities. In Proceedings of the 1st International Joint Conference on Natural Language Processing (IJCNLP’04), Hainan, China, 22–24 March 2004; pp. 61–70. [Google Scholar]
- Marcu, D.; Echihabi, A. An unsupervised approach to recognizing discourse relations. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 368–375. [Google Scholar]
- Rink, B.; On, S.H. Utd: Classifying semantic relations by combining lexical and semantic resources. In Proceedings of the 5th International Workshop on Semantic Evaluation; Association for Computational Linguistics, Uppsala, Sweden, 15–16 July 2010; pp. 256–259. [Google Scholar]
- Sil, A.; Huang, F.; Series, A.Y. Extracting action and event semantics from web text. In Proceedings of the 2010 AAAI Fall Symposium Series, Westin Arlington Gateway, Arlington, Virginia, 11–13 November 2010; pp. 108–113. [Google Scholar]
- Pal, S.; Pakray, P.; Das, D. JU: A supervised approach to identify semantic relations from paired nominals. In Proceedings of the 5th International Workshop on Semantic Evaluation, SemEval@ACL 2010, Uppsala University, Uppsala, Sweden, 15–16 July 2010; pp. 206–209. [Google Scholar]
- Li, Z.; Ding, X.; Liu, T.; Hu, J.E.; Durme, B. Van Guided Generation of Cause and Effect. arXiv 2020, arXiv:2107.09846, 1–8. [Google Scholar]
- Schank, R.C. Dynamic Memory: A Theory of Reminding and Learning in Computers and People; Cambridge University Press: Cambridge, UK, 1983; p. 234. [Google Scholar]
- Szpakowicz, S.; Nastase, V. Exploring noun-modifier semantic relations. In Proceedings of the Fifth International Workshop on Computational Semantics (IWCS-5), Tilburg University, Tilburg, The Netherlands, 15–17 January 2003; pp. 285–301. [Google Scholar]
- Tapanainen, P.; Natural, T.J. A non-projective dependency parser. In Proceedings of the Fifth Conference on Applied Natural Language Processing, Washington, DC, USA, 31 March–4 April 1997; pp. 64–71. [Google Scholar]
- Girju, R.; Beamer, B.; Rozovskaya, A. A knowledge-rich approach to identifying semantic relations between nominals. Inf. Process. Manag. 2010, 46, 589–610. [Google Scholar] [CrossRef]
- Girju, R.; Nakov, P.; Nastase, V.; Szpakowicz, S.; Turney, P.; Yuret, D. Semeval-2007 task 04: Classification of semantic relations between nominals. In Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), Prague, Czech Republic, 23 June 2007; pp. 13–18. [Google Scholar]
- Pakray, P.; Gelbukh, A. An open-domain cause-effect relation detection from paired nominals. In Mexican International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2014; pp. 263–271. [Google Scholar]
- Bethard, S.; HLT, J.M. Learning semantic links from a corpus of parallel temporal and causal relations. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies: Short Papers, Columbus, OH, USA, 16–17 June 2008; pp. 177–180. [Google Scholar]
- Bethard, S.; Corvey, W.; Klingenstein, S.; Martin, J.H. Building a Corpus of Temporal-Causal Structure. In Proceedings of the European Language Resources Association (ELRA), Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008; pp. 1–8. [Google Scholar]
- Rink, B.; Bejan, C. Learning textual graph patterns to detect causal event relations. In Proceedings of the Twenty-Third International FLAIRS Conference, Datona Beach, FL, USA, 19–21 May 2010; pp. 265–270. [Google Scholar]
- Do, Q.; Chan, Y.S.; Roth, D. Minimally Supervised Event Causality Identification. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing(EMNLP 2011), Edinburgh, Scotland, UK, 27–31 July 2011; pp. 294–303. [Google Scholar]
- Lin, Z.; Ng, H.T.; Kan, M.Y. A pdtb-styled end-to-end discourse parser. Nat. Lang. Eng. 2014, 20, 151–184. [Google Scholar] [CrossRef] [Green Version]
- Riaz, M.; Girju, R. Recognizing Causality in Verb-Noun Pairs via Noun and Verb Semantics. In Proceedings of the EACL 2014 Workshop on Computational Approaches to Causality in Language (CAtoCL), Gothenburg, Sweden, 26 April 2014; pp. 48–57. [Google Scholar]
- Yang, X.; Mao, K. Multi level causal relation identification using extended features. Expert Syst. Appl. 2014, 41, 7171–7181. [Google Scholar] [CrossRef]
- Kingsbury, P.; Palmer, M. From TreeBank to PropBank. In Proceedings of the Third International Conference on Language Resources and Evaluation (LREC’02), Las Palmas, Canary Islands, Spain, 29–31 May 2002; pp. 1989–1993. [Google Scholar]
- Mirza, P.; Kessler, F.B. Extracting Temporal and Causal Relations between Events. In Proceedings of the ACL 2014 Student Research Workshop, Baltimore, MA, USA, 22–27 June 2014; pp. 10–17. [Google Scholar]
- Mirza, P.; Sprugnoli, R.; Tonelli, S.; Speranza, M. Annotating Causality in the TempEval-3 Corpus; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2015; pp. 10–19. [Google Scholar]
- Zhao, S.; Liu, T.; Zhao, S.; Chen, Y.; Nie, J.-Y. Event causality extraction based on connectives analysis. Neurocomputing 2016, 173, 1943–1950. [Google Scholar] [CrossRef]
- Hidey, C.; Mckeown, K. Identifying Causal Relations Using Parallel Wikipedia Articles. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1424–1433. [Google Scholar]
- Qiu, J.; Xu, L.; Zhai, J.; Luo, L. Extracting Causal Relations from Emergency Cases Based on Conditional Random Fields. Procedia Comput. Sci. 2017, 112, 1623–1632. [Google Scholar] [CrossRef]
- Rehbein, I.; Ruppenhofer, J. Catching the Common Cause: Extraction and Annotation of Causal Relations and their Participants. In Proceedings of the 11th Linguistic Annotation Workshop, Valencia, Spain, 3 April 2017; pp. 105–114. [Google Scholar]
- Koehn, P. Europarl: A Parallel Corpus for Statistical Machine Translation. In Proceedings of the MT Summit, Phuket, Thailand, 12–16 September 2005; Volume 5, pp. 79–86. [Google Scholar]
- Dunietz, J.; Levin, L.; Carbonell, J. The BECauSE Corpus 2.0: Annotating Causality and Overlapping Relations. In Proceedings of the 11th Linguistic Annotation Workshop, Valencia, Spain, 3 April 2017; pp. 95–104. [Google Scholar]
- Zhao, S.; Jiang, M.; Liu, M.; Qin, B.; Liu, T. CausalTriad: Toward Pseudo Causal Relation Discovery and Hypotheses Generation from Medical Text Data. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health, Washington, DC, USA, 29 August–1 September 2018; pp. 184–193. [Google Scholar]
- Ning, Q.; Feng, Z.; Wu, H.; Roth, D. Joint reasoning for temporal and causal relations. In Proceedings of the ACL 2018—56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2278–2288. [Google Scholar]
- Craciunescu, T.; Murari, A.; Gelfusa, M. Causality detection methods applied to the investigation of malaria epidemics. Entropy 2019, 21, 784. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prasad, R.; Dinesh, N.; Lee, A.; Miltsakaki, E.; Robaldo, L.; Joshi, A.K.; Webber, B.L. The Penn Discourse TreeBank 2.0. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008; pp. 1–8. [Google Scholar]
- Pustejovsky, J.; Hanks, P.; Saurí, R.; See, A.; Gaizauskas, R.; Setzer, A.; Radev, D.; Sundheim, B.; Day, D.; Ferro, L.; et al. The TIMEBANK Corpus. Corpus Linguist. 2003, 2003, 40. [Google Scholar]
- Radinsky, K.; Davidovich, S.; Markovitch, S. Learning to Predict from Textual Data. J. Artif. Intell. Res. 2012, 45, 641–684. [Google Scholar] [CrossRef]
- Riaz, M.; Girju, R. Toward a Better Understanding of Causality between Verbal Events: Extraction and Analysis of the Causal Power of Verb-Verb Associations. In Proceedings of the 14th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGdial), Metz, France, 22–24 August 2013; pp. 21–30. [Google Scholar]
- Ishii, H.; Ma, Q.; Yoshikawa, M. Incremental Construction of Causal Network from News Articles. J. Inf. Process. 2012, 20, 207–215. [Google Scholar] [CrossRef] [Green Version]
- Peng, N.; Poon, H.; Quirk, C.; Toutanova, K.; Yih, W. Cross-Sentence N -ary Relation Extraction with Graph LSTMs. Trans. Assoc. Comput. Linguist. 2017, 5, 101–115. [Google Scholar] [CrossRef] [Green Version]
- Marcus, M.; Kim, G.; Marcinkiewicz, M.A.; Macintyre, R.; Bies, A.; Ferguson, M.; Katz, K.; Schasberger, B. The Penn TreeBank: Annotating Predicate Argument Structure. In Proceedings of the Human Language Technology: Proceedings of a Workshop, Plainsboro, NJ, USA, 8–11 March 1994; pp. 110–115. [Google Scholar]
- Sandhaus, E. The new york times annotated corpus. In Proceedings of the Linguistic Data Consortium, University of Philadelphia, Philadelphia, PA, USA, 17 October 2008; p. e26752. [Google Scholar]
- Smith, N.A.; Cardie, C.; Washington, A.L.; Wilkerson, J.D. Overview of the 2014 NLP Unshared Task in PoliInformatics. In Proceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science, Baltimore, MD, USA, 26 June 2014; pp. 5–7. [Google Scholar]
- Ide, N.; Baker, C.; Fellbaum, C.; Passonneau, R. The Manually Annotated Sub-Corpus: A Community Resource for and By the People. In Proceedings of the ACL 2010 Conference Short Papers, Stroudsburg, PA, USA, 11–16 July 2010; pp. 68–73. [Google Scholar]
- UZMAY, G.; Gokce, K. The Causality Effect of Interest in the Financial Crisis and Oil Market on Food Prices: A Case Study of Internet Search Engine Behavior. In Proceedings of the IX. IBANESS Congress Series, Edirne, Turkey, 29–30 September 2018; pp. 1–10. [Google Scholar]
- Faes, L.; Nollo, G.; Porta, A. Information-based detection of nonlinear Granger causality in multivariate processes via a nonuniform embedding technique. Phys. Rev. 2011, 83, 51112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eckmann, J.; Kamphorst, S. Recurrence plots of dynamical systems. World Sci. Ser. Nonlinear Sci. Ser. A 1995, 16, 441–446. [Google Scholar]
- Society, C.G. Investigating causal relations by econometric models and cross-spectral methods. Econom. J. Econom. Soc. 1969, 37, 424–438. [Google Scholar]
- Marinazzo, D.; Pellicoro, M. Kernel method for nonlinear Granger causality. Phys. Rev. Lett. 2008, 100, 144103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, A.; Peng, C. Causal decomposition in the mutual causation system. Nat. Commun. 2018, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Craciunescu, T.; Murari, A.; Gelfusa, M. Improving entropy estimates of complex network topology for the characterization of coupling in dynamical systems. Entropy 2018, 20, 891. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haque, U.; Hashizume, M.; Glass, G.E.; Dewan, A.M.; Overgaard, H.J.; Yamamoto, T. The role of climate variability in the spread of malaria in bangladeshi highlands. PLoS ONE 2010, 5, e14341. [Google Scholar] [CrossRef] [PubMed]
- Hanf, M.; Adenis, A.; Nacher, M.; Journal, B.C. The role of El Niño southern oscillation (ENSO) on variations of monthly Plasmodium falciparum malaria cases at the cayenne general hospital, 1996–2009. Malar. J. 2011, 10, 1–4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Syamsuddin, M.; Fakhruddin, M. Causality analysis of Google Trends and dengue incidence in Bandung, Indonesia with linkage of digital data modeling: Longitudinal observational study. J. Med. Internet Res. 2020, 22, e17633. [Google Scholar] [CrossRef]
- Deng, L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process. 2014, 3, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Foundations; MIT Press: Cambridge, CA, USA, 1986; pp. 399–421. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Neural, Y.B. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Burney, A.; Syed, T.Q. Crowd Video Classification Using Convolutional Neural Networks. In Proceedings of the 2016 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 19–21 December 2016; pp. 247–251. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Chen, M.; Saad Sadiq, M.; Shyu, M.-L. Efficient Imbalanced Multimedia Concept Retrieval by Deep Learning on Spark Clusters. Int. J. Multimed. Data Eng. Manag. IJMDEM 2017, 8, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Chen, M.; Shyu, M. Deep learning for imbalanced multimedia data classification. In Proceedings of the 2015 IEEE international symposium on multimedia (ISM), Miami, FL, USA, 14–16 December 2015; pp. 483–488. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2016, arXiv:1408.5882. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MA, USA, 22–27 June 2014; pp. 655–665. [Google Scholar]
- Dos Santos, C.; Gatti, M. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Eventh IEEE International Conference on Computer Vision, TKerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Dalal, N.; Histograms, B.T.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1–21. [Google Scholar] [CrossRef] [Green Version]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fukushima, K.; Miyake, S. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Visual Pattern Recognition. In Proceedings of the Competition and cooperation in neural nets, Berlin, Heidelberg, Kyoto, Japan, 15–19 February 1982; pp. 267–285. [Google Scholar]
- Jordan, M. Serial order: A parallel distributed processing approach. Adv. Psychol. 1997, 121, 471–495. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Misic, M.; Đurđević, Đ.; Tomasevic, M. (PDF) Evolution and Trends in GPU Computing. Available online: https://www.researchgate.net/publication/261424611_Evolution_and_trends_in_GPU_computing (accessed on 19 August 2021).
- Raina, R.; Madhavan, A.; Ng, A.Y. Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 873–880. [Google Scholar]
- Osborne, J. Google’s Tensor Processing Unit Explained: This is Google Scholar. Available online: https://scholar.google.com/scholar?q=Google%27s+Tensor+Processing+Unit+explained%3A+this+is+what+the+future+of+computing+looks+like (accessed on 21 August 2021).
- Ian, G.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 436–444. [Google Scholar]
- Azarkhish, E.; Rossi, D.; Loi, I. Neurostream: Scalable and energy efficient deep learning with smart memory cubes. Proc. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 420–434. [Google Scholar] [CrossRef] [Green Version]
- McMahan, H.; Moore, E.; Ramage, D.; y Arcas, B. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Yan, Y.; Zhu, Q.; Shyu, M.-L.; Chen, S.-C. A Classifier Ensemble Framework for Multimedia Big Data Classification. In Proceedings of the 2016 IEEE 17th International Conference on Information Reuse and Integration (IRI), Pittsburgh, PA, USA, 28–30 July 2016; pp. 615–622. [Google Scholar]
- Kaiser, Ł.; Brain, G.; Gomez, A.N.; Shazeer, N.; Vaswani, A.; Parmar, N.; Research, G.; Jones, L.; Uszkoreit, J. One Model to Learn Them All. arXiv 2017, arXiv:1706.05137. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012): 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Goller, C. A Connectionist Approach for Learning Search Control Heuristics for Automated Deduction Systems; Akademische Verlagsgesellschaft AKA: Berlin, Germany, 1999; pp. 1–8. [Google Scholar]
- Socher, R.; Chiung, C.; Lin, Y.; Ng, A.Y.; Manning, C.D. Parsing Natural Scenes and Natural Language with Recursive Neural Networks. In Proceedings of the 28th International Conference on Machine Learning, ICML, Bellevue, WA, USA, 28 June 28–2 July 2011; pp. 129–136. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Li, X.; Wu, X. Constructing long short-term memory based deep recurrent neural networks for large vocabulary speech recognition. In Proceedings of the ICASSP 2015—2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4520–4524. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 29th Pacific Asia conference on language, information and computation, Shanghai, China, 30 October–1 November 2015; pp. 73–78. [Google Scholar]
- Vaswani, A.; Brain, G.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Alec, R.; Karthik, N.; Tim, S.; Ilya, S. Improving language understanding with unsupervised learning. Citado 2018, 17, 1–12. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K.; Language, G.A.I. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognit. 1982, 15, 455–469. [Google Scholar] [CrossRef]
- Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. arXiv 2014, arXiv:1404.5997, 1–7. [Google Scholar]
- Socher, R.; Huang, E.; Pennin, J. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection. Adv. Neural Inf. Process. Syst. 2011, 24, 1–9. [Google Scholar]
- Hinton, G. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Statistics, G.H. Deep boltzmann machines. In Proceedings of the Artificial Intelligence and Statistics, Hilton Clearwater Beach Resort, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 448–455. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. An efficient learning procedure for deep Boltzmann machines. Neural Comput. 2012, 24, 1967–2006. [Google Scholar] [CrossRef] [Green Version]
- Fausett, L. Fundamentals of Neural Networks: Architectures, Algorithms and Applications; Pearson Education: London, UK, 1994; p. 480. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Honza, J.; Cernocky, J.H.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Mikolov, T.; Kombrink, S.; Burget, L.; Černocký, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Mikolov, T.; Deoras, A.; Povey, D.; Burget, L. Strategies for training large scale neural network language models. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Hilton Waikoloa Village Resort, Big Island, HI, USA, 11–15 December 2011; pp. 196–201. [Google Scholar]
- El Hihi, S.; Bengio, Y. Hierarchical recurrent neural networks for long-term dependencies. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 493–499. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Radford, A.; Metz, L. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114, 1–14. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Greff, K.; Srivastava, R.; Koutník, J. LSTM: A search space odyssey. IEEE Trans. Neural Networks Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–9 July 2002; pp. 79–86. [Google Scholar]
- Harris, Z.S. Distributional Structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Popov, M.; Kulnitskiy, B.; Perezhogin, I.; Mordkovich, V.; Ovsyannikov, D.; Perfilov, S.; Borisova, L.; Blank, V. A Neural Probabilistic Language Model. Fuller. Nanotub. Carbon Nanostruct. 2003, 3, 1137–1155. [Google Scholar]
- Collobert, R.; Bengio, S.; Mariethoz, J. Torch: A Modular Machine Learning Software Library. Available online: http://publications.idiap.ch/downloads/reports/2002/rr02-46.pdf (accessed on 15 October 2020).
- Abadi, M.; Agarwal, A.; Barham, E.B. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Skymind Skymind. Deeplearning4j Deep Learning Framework. 2017. Available online: https://deeplearning4j.org/ (accessed on 16 October 2020).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Al-Rfou, R. Theano: A Python Framework for Fast Computation of Mathematical Expressions. arXiv 2016, arXiv:1605.02688. [Google Scholar]
- Agarwal, A.; Akchurin, E.; Basoglu, C.; Chen, G.; Cyphers, S.; Droppo, J.; Eversole, A.; Guenter, B.; Hillebrand, M.; Huang, X.; et al. An Introduction to Computational Networks and the Computational Network Toolkit. MSR-TR-2014-112 (DRAFT Vol.1.0). 2016, pp. 1–50. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2014/08/CNTKBook-20160217.pdf (accessed on 1 October 2021).
- NervanaSystems. The Neon Deep Learning Framework. Available online: https://github.com/NervanaSystems/neon (accessed on 11 May 2017).
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Wood, M. Introducing Gluon: A New Library for Machine Learning from AWS and Microsoft: Introducing Gluon. 2017. Available online: https://aws.amazon.com/blogs/aws/introducing-gluon-a-new-library-for-machine-learning-from-aws-and-microsoft/ (accessed on 1 October 2021).
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. CSUR 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Turian, J.; Ratinov, L.; Bengio, Y. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 384–394. [Google Scholar]
- De Silva, T.N.; Zhibo, X.; Rui, Z.; Kezhi, M. Causal relation identification using convolutional neural networks and knowledge based features. Int. J. Comput. Syst. Eng. 2017, 11, 696–701. [Google Scholar]
- Kruengkrai, C.; Torisawa, K.; Hashimoto, C.; Kloetzer, J.; Oh, J.-H.; Tanaka, M. Improving Event Causality Recognition with Multiple Background Knowledge Sources Using Multi-Column Convolutional Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3466–3473. [Google Scholar]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column Deep Neural Networks for Image Classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, Rhode Island, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Oh, J.; Torisawa, K.; Kruengkrai, C.; Iida, R.; Kloetzer, J. Multi-column convolutional neural networks with causality-attention for why-question answering. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, CA, USA, 6–10 February 2017; pp. 415–424. [Google Scholar]
- Ponti, E.M.; Korhonen, A. Event-related features in feedforward neural networks contribute to identifying causal relations in discourse. In Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, Valencia, Spain, 3 April 2017; pp. 25–30. [Google Scholar]
- Roemmele, M.; Gordon, A.S. An Encoder-decoder Approach to Predicting Causal Relations in Stories. In Proceedings of the First Workshop on Storytelling, New Orleans, Louisiana, 5 June 2018; pp. 50–59. [Google Scholar]
- Dasgupta, T.; Saha, R.; Dey, L.; Naskar, A. Automatic extraction of causal relations from text using linguistically informed deep neural networks. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, Melbourne, Australia, 12–14 July 2018; pp. 306–316. [Google Scholar]
- Nauta, M.; Bucur, D.; Seifert, C. Causal Discovery with Attention-Based Convolutional Neural Networks. Mach. Learn. Knowl. Extr. 2019, 1, 312–340. [Google Scholar] [CrossRef] [Green Version]
- Ayyanar, R.; Koomullil, G.; Ramasangu, H. Causal Relation Classification using Convolutional Neural Networks and Grammar Tags. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Marwadi University, Rajkot, India, 13–15 December 2019; pp. 1–3. [Google Scholar]
- Li, P.; Mao, K. Knowledge-oriented Convolutional Neural Network for Causal Relation Extraction from Natural Language Texts. Expert Syst. Appl. 2019, 115, 512–523. [Google Scholar] [CrossRef]
- Kayesh, H.; Islam, M.S.; Wang, J. On Event Causality Detection in Tweets. arXiv 2019, arXiv:1901.03526. [Google Scholar]
- Kayesh, H.; Islam, M.S.; Wang, J.; Kayes, A.S.M.; Watters, P.A. A deep learning model for mining and detecting causally related events in tweets. Concurr. Comput. Pract. Exp. 2020, e5938. [Google Scholar] [CrossRef]
- Kadowaki, K.; Iida, R.; Torisawa, K.; Oh, J.H.; Kloetzer, J. Event causality recognition exploiting multiple annotators’ judgments and background knowledge. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5816–5822. [Google Scholar]
- Mehrabadi, M.A.; Dutt, N.; Rahmani, A.M. The Causality Inference of Public Interest in Restaurants and Bars on COVID-19 Daily Cases in the US: A Google Trends Analysis. JMIR Public Health Surveill. 2020, 7, 1–6. [Google Scholar]
- Liu, J.; Chen, Y.; Zhao, J. Knowledge Enhanced Event Causality Identification with Mention Masking Generalizations. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 July 2020; pp. 3608–3614. [Google Scholar]
- Speer, R.; Lowry-Duda, J. ConceptNet at SemEval-2017 Task 2: Extending word embeddings with multilingual relational knowledge. arXiv 2017, arXiv:1704.03560. [Google Scholar]
- Ma, J.; Dong, Y.; Huang, Z.; Mietchen, D.; Li, J. Assessing the Causal Impact of COVID-19 Related Policies on Outbreak Dynamics: A Case Study in the US. arXiv 2021, arXiv:2106.01315. [Google Scholar]
- Li, Z.; Li, Q.; Zou, X.; Ren, J. Causality extraction based on self-attentive BiLSTM-CRF with transferred embeddings. Neurocomputing 2021, 423, 207–219. [Google Scholar] [CrossRef]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual String Embeddings for Sequence Labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Khetan, V.; Ramnani, R.; Anand, M.; Sengupta, S.; Fano, A.E. Causal-BERT: Language models for causality detection between events expressed in text. arXiv 2021, arXiv:2012.05453v2, 965–980. [Google Scholar]
- Gurulingappa, H.; Rajput, A.; Roberts, A.; Fluck, J. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. J. Biomed. 2012, 45, 885–892. [Google Scholar] [CrossRef] [PubMed]





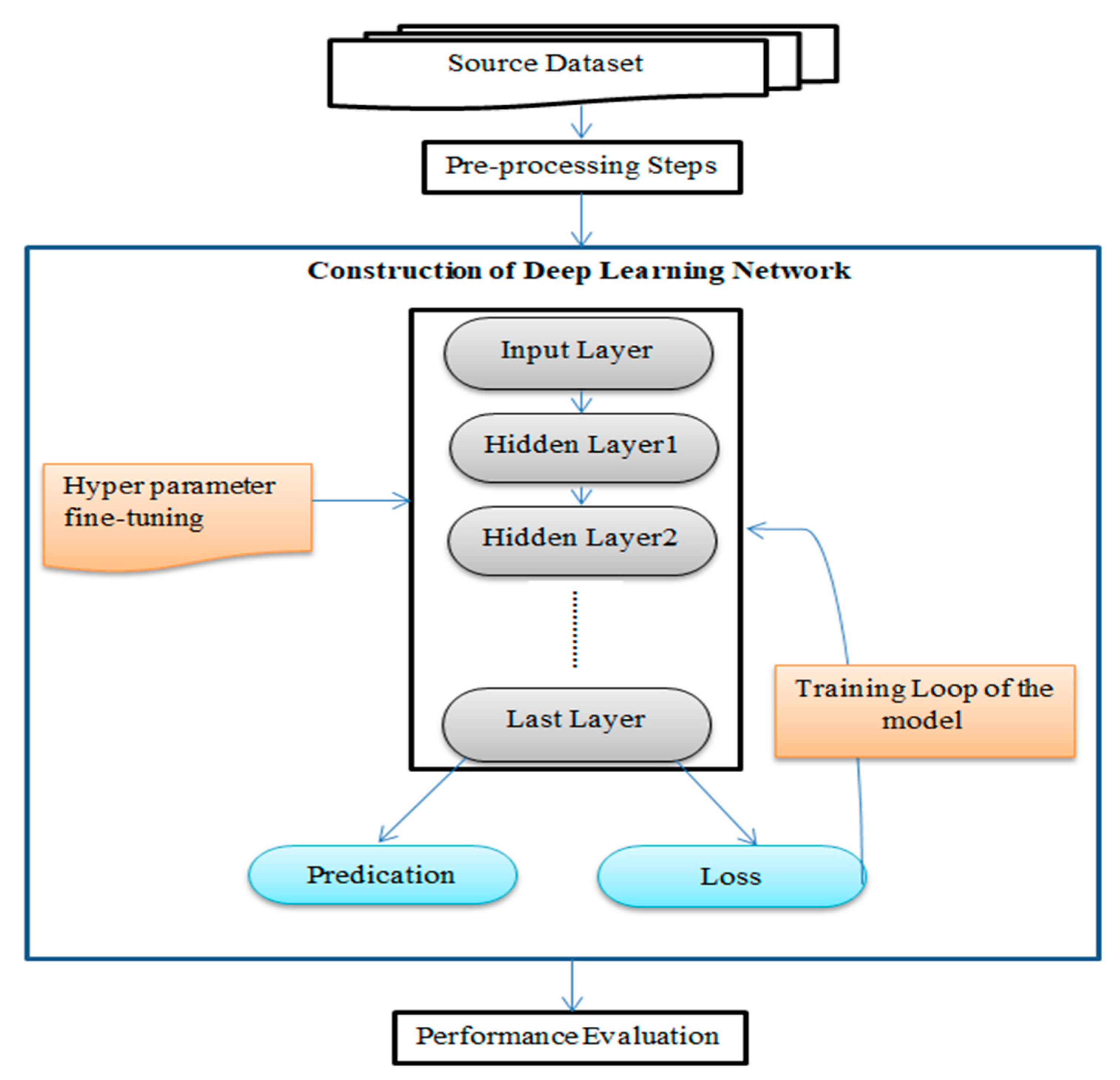


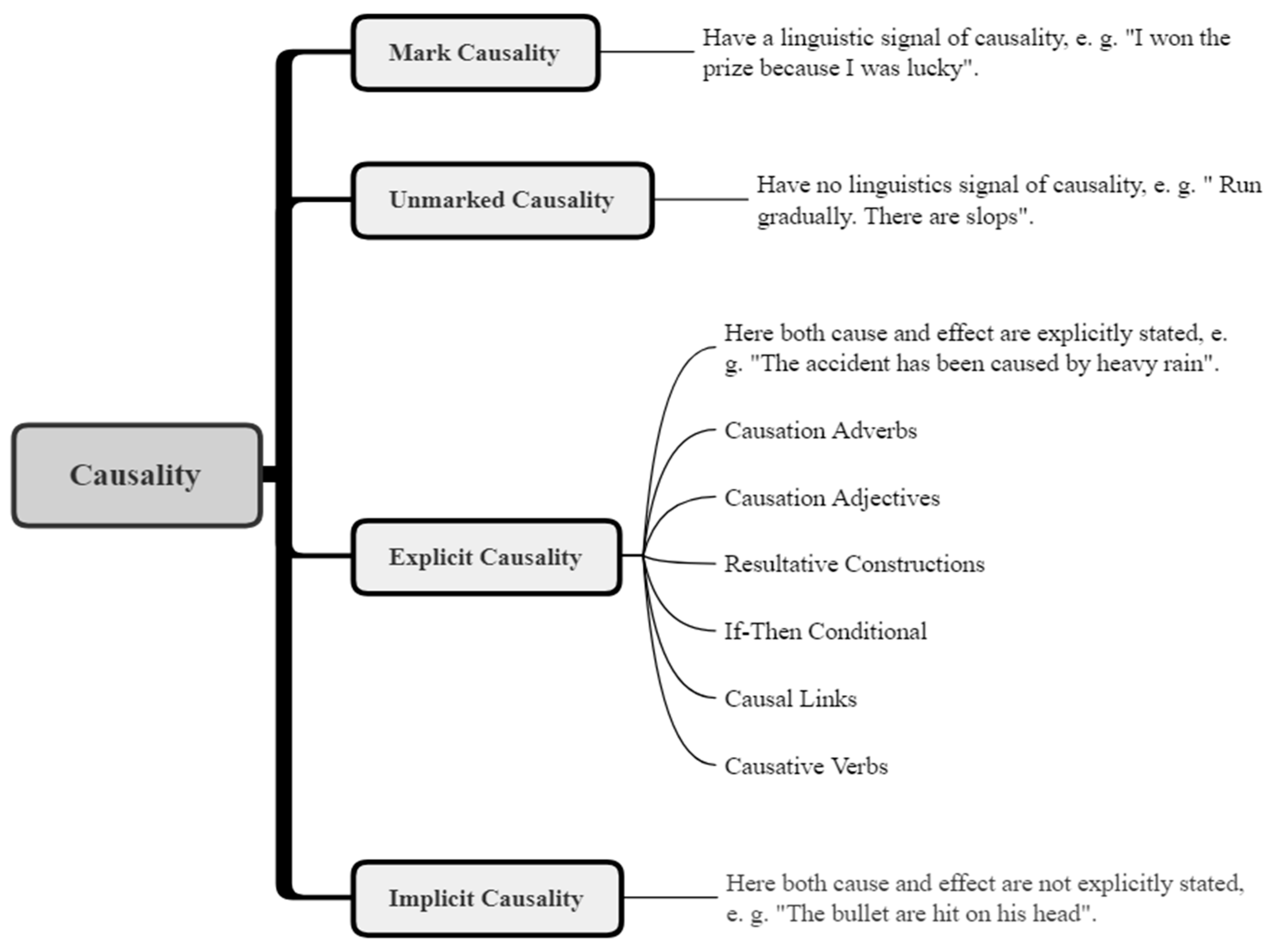{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNo | Reference | Description | Pattern/Structure | Applications | Data Corpus | Languages | Limitations |
|---|---|---|---|---|---|---|---|
| 1. | [7] | Improved version of C4.5 decision tree is used [44]. | A pattern of causative verbs NP1-verb-NP2 are used. | Question Answering. | Domain-independent text. LATIMES section of the TREC 9 text group. | English | Not mentioned. |
| 2. | [29] | A supervised approach for explicit causations. | Syntactic patterns (Phrase-relator-Cause). | SemCor 2.1 corpus for training. | ✓ | Only considered marked and explicit causations. | |
| 3. | [30] | Decision trees are used over POS-tagged data, and WordNet is used for mining semantic relations. | WordNet and POS-tagging features based features | Knowledge acquisition for decision making. | SemEval 2010 Task # 8 datasets (7954 instances for training and 2707 for testing) [30]. | ✓ | Cost much more time in feature extraction. |
| 4. | [45] | Syntactic parser for NP1-Verb-NP2 relation and WordNet knowledge base are used. | Used NP1-Verb-NP2 relation. | Penn Treebank dataset. | ✓ | Lack of ambiguity resolution and use of small dataset. | |
| 5. | [46] | Identifying relations among two-word noun compounds | Nouns pair patterns | Information retrieval, Information extraction, Text summarization | Bio-medical Text | ✓ | Only for nominal compound relations |
| 6. | [47,48] | Use of Connexor dependency parser to extract NP1-CuePhrase-NP2 for inter-sentence relation. | NP1-CuePhrase-NP2 Pattern, cue phrase, and lexical pair probability. | ✓ | Five million articles from LA TIMES and WSJ for training set, two manually annotated test sets, including, WSJ article and Medline medical encyclopedia of A.D.A.M. | ✓ | System recall or F-score are ignored and no explanation of the use of NBC is provided. |
| 7. | [49] | SemEvel2007 task-4 is applied for finding 7 frequently occurring semantic relations. | Events pair patterns of 7 relation types. | ✓ | Benchmark dataset to let the evaluation of diverse semantic relation classification algorithms | Only restricted to nominal based classification | |
| 8. | [50] | ‘PRE POST’ model, extracted common-sense knowledge for the problem of CM. | Use Pre- and Post-condition pattern and SVM classifier | Knowledge acquisition for AI tasks. | Web text. | Based on a small set of labeled data. | |
| 9. | [51] | The similar SemEval-2010 task-8 used separate rule-based features for every type of relation. | Prepositions and verbs present among every nominal pair in combination with WordNet. | For information retrieval between nominal. | Training data of 8000 sentences, and test data of 2717 sentences | ✓ | Not specific to implicit causalities. |
| 10. | [52] | Conditional text generation model. | Causal patterns and Cause-Effect graph. | Cause-effect event pairs generation. | Causal Bank corpus. | ✓ | Targeted only cause-effect event pairs |
| SNo | Reference | Description | Pattern/Structure | Application Domain | Data Corpus | Language | Limitation |
|---|---|---|---|---|---|---|---|
| 1. | [2] | Network (CausalNet) of cause-effect terms in a large web corpus. | Linguistic pattern, ‘A (event1) causes B (event2)’. | Predication in short text. | 10TB corpus from Bing. | English | Over-fitting issues. |
| 2. | [9] | Pundit algorithm for future events prediction. | Handcrafted rules. | Predictions | News corpus last from 150 years news reports. | ✓ | It only applicable to textually denoted environment. |
| 3. | [14] | Proposed ADRs. | Lexical patterns. | Healthcare field to decreases drug-related diseases. | Twitter and Facebook data. | ✓ | Worked only for explanatory messages related to drug and diseases. |
| 4. | [31] | Applied pattern matching by phrasal and causative verbs that links ML and traditional methods. | Syntactic patterns | Used for large scale AI problems of events prediction. | News articles over 150 years old. | ✓ | Use of unrelated data, which result irrelevant causality predication. |
| 5. | [59] | Extracting parallel and temporal causal relations, and differentiate among them | Feature based on WordNet and the Google N-gram corpus. | Decision making. | Their own corpus of temporal and causal relations . | ✓ | Hard to perform well on domain-independent data |
| 6. | [60] | Discovered parallel temporal and causal relations. | PDTB, Prop Bank, and Time Bank data patterns. | Decision making. | Their own annotated corpus | ✓ | Overlooked in-depth analysis of both corpus and relations. |
| 7. | [61] | A graphical framework for implicit causalities. | Semantic, lexical, and syntactic features. | Information retrieval in NLP. | Same corpus used [59]. | English | Some vague verbs cause most of the errors. |
| 8. | [62] | A distributional and connectives probability approach for event causality detection. | Follow features described Ruby-based discourse System [63]. | Decision making. | Using news articles collected from CNN (http://www.cnn.com). | ✓ | More focused on explicit connective, and overlook implicit connective. |
| 9. | [64] | Classifying causality among the verb and noun pairs. | Grammatically linked verb-noun pairs pattern based on extra knowledge with Linguistic features. | Prediction | Acquired 2 158 causal and 65, 777 non-causal from FrameNet. | ✓ | Bound to limited feature. |
| 10. | [65] | MLR (The source code for relation mining is available in https://github.com/YangXuefeng/MLRE), mine all probable causality with any preposition or verb based. | Constituent and linguistic knowledge of the dependency grammar. | Extract causality in all language expression levels. | Prop bank [66], | ✓ | Small manually annotated dataset, typically lead to over fitting problem. |
| 11. | [67] | Mine causal and temporal relations, and propose guidelines to annotate casualty. | Used <CLINK> tag to indicate a causal link, and presented the idea of causal signals through the <C-SIGNAL> tag. | Prediction, risk analysis, and decision making. | Annotated dataset followed [68] guidelines. | ✓ | Complex annotation scheme. |
| 12. | [69] | RHNB algorithm manages interactions among diverse features. | RHNB model based patterns | Prediction | SemEval-2010-Task8 dataset. | ✓ | Work on large set of feature vector, which usually slow the model processing. |
| 13. | [70] | Explicit discourse connectives for mining alternative lexicalizations (AltLexes) of causal discourse relations. | Two kind of features: Parallel corpus derived feature and lexical semantic features. | Question Answering and text summarization. | Wikipedia from 11 Sept 2015. | ✓ | // |
| 14. | [71] | CRF based model for CM. | Time-based sequence labeling, Lexical and syntactic features. | Emergency management. | Emergency cases corpus about typhoon disasters. | ✓ | Based on raw corpus which leads to low performance. |
| 15. | [72] | First effort toward German causal language. | Annotated training suite and lexicon. | Identify new causal triggers. | English-German part of Europarl corpus [73]. | German causal language. | Only focused English-German parallel corpus. |
| 16. | [74] | BECauSE 2.0 corpus with broadly annotated expressions of causal language. | Annotated expression of causality. | Annotating causal relation. | BECauSE 2.0 corpus (https://github.com/duncanka/BECauSE). | English | Missing semantically fuzzy relations. |
| 17. | [75] | CausalTriad, to mine causalities | Traid structures. | Medical related predication. | Health Boards dataset (https://www.healthboards.com/) and Traditional Chinese Medicine dataset. | ✓ | Only used for medical domain, and not useful in other domains. |
| 18. | [76] | TCR, a joint inference model for understanding temporal and causal reasoning. | Using CCMs and ILP in the extraction of temporal and Causal relations. | Decision making in defense department. | Causal and temporal relations from the text (http://cogcomp.org/page/publication_view/835). | ✓ | Omitted the concept of jointly learning of temporal and Causal relations. |
| 19 | [77] | Extracting causality | Investigation of Malaria Epidemics | HAQUE-data and HANF-data | ✓ | Only targetd malaria related problems |
| SNo | References | Deep Neural Networks | Applications and Structure |
|---|---|---|---|
| 1. | [101,103,106,126] | CNN | CNN’s are made upon Fukashima’s neurocognition [138,139], where the name originates from the convolution operation in signal processing and mathematics. CNN’s use some specific type of function called filters, which lets simultaneous analysis of diverse features in the source data [101,140]. Though, CNN is considered as the foundation and inspiration of DL approaches, which beats its predecessors. It is based on a mash structure of neurons/nodes for information exchange, leading to various many-layered learning networks. In the beginning, it was applicable for computer vision. Further, enhanced to NLP. |
| 2. | [127,128] | RvNN | Like CNNs, RvNN uses a method of weight sharing to decrease training. Though CNN’s share their weights within a layer (horizontally), RvNN share weights between layers (vertically). This is interesting because it lets easy modeling of parse trees structures. In RvNN, a single tensor of parameters can be applied at a low level in the tree and further recursively used sequentially at higher levels [141]. It is applicable for sequential NLP tasks by using a tree-like architecture. |
| 3. | [142,143] | DBNs | Applicable for unsupervised learning-based directed connections. |
| 4. | [144,145] | Deep Boltzmann Machine (DBM) | Applicable for unsupervised learning based on undirected connections. |
| 5. | [129,130,146,147,148,149] | RNN | RNN is a type of RvNN, comprehensively used in many NLP tasks. Since NLP is dependent on the sequence of words such as sentences /phonemes, it is beneficial to have a memory of the preceding elements when processing new ones. Sometimes, backward dependencies exist that correct processing of certain words/tokens may depend on words that follow it. Hence, it is crucial for RNN to look at the sentences in the forward and backward direction and integrate their outputs. This organization of RNN’s is known as a bidirectional RNN. This design may allow the effect of input to longer than a single RNN layer and letting for longer-term effects. This sequential design of RNN cells is known RNN stack [150]. RNN is applicable for sequential NLP tasks, and as well as for speech processing. |
| 6. | [151,152] | Generative Adversarial Network (GAN) | Applicable for unsupervised learning and using game-theoretical context. |
| 7. | [153] | Variational Autoencoder (VAE) | Applicable for unsupervised learning and based on the Probabilistic Graphical model. |
| 8. | [131,154] | GRU | GRU is an extended version of RNN and a simpler variant of the LSTM, usually perform better than standard LSTMs in several NLP sequential tasks. |
| 9. | [130,132,155] | LSTM | LSTM is one of the prominently enhanced forms of RNN. In LSTMs, the recursive neurons are consist of many different neurons linked in a sequential structure to preserve, expose, or forget some precise information. While standard RNN’s of the single node serving back to them and have some memory of long passed outcomes, these outcomes are merged in each consecutive iteration. Usually, it is significant to remember data from the distant past, however and at the same time, other very latest data may not be vital. LSTM can remember important data much longer, while inappropriate data can be forgotten. It plays a very important in sequential computation. |
| 10. | [133] | bi-LSTM | Bi-LSTM is an enhanced form of LSTM that works in both left and right directions to deal with the problem. It is applicable for sequential NLP tasks and uses derived features from lexical resources such as NLP and WordNet systems. |
| 11. | [134] | Transformer | Encoder-Decoder pair is typically used for text summarization, machine translation, or captioning, results is in textual form. An encoding ANN is used to yield a vector of a specific length and a decoding ANN is used to return variable size text based on the vector. Issue in this system: RNN is enforced to encode the whole sequence to a finite length vector without affections to whether or not any of the inputs are more significant than others. A strong solution to this issue: Using the attention mechanism. The first prominent use of an attention mechanism is the condensed layer for an annotated parameter of RNN hidden state, letting the network obtain what to pay attention in accordance with the annotation and current hidden state [156]. It is applicable for supervised learning with multi-head attention. |
| 12. | [135] | ELMo | They used a feature-based approach and task-specific architectures that contain pre-trained representations as additional features. |
| 13. | [136] | Generative Pre-trained Transformer (OpenAI GPT) | Applicable for unsupervised learning by Improving language understanding. |
| 14. | [137] | BERT-base | BERT-base is the enhance form of Transformer, which deal the source sentence in both direction. It uses a bi-directional encoder-decoder along with attention mechanism. It is conceptually very simple and empirically influential. |
| Frameworks | References | Primary Language | Interface Provision | RNN and CNN Provision | Key Note to Know About |
|---|---|---|---|---|---|
| Torch | [160] | C and Lua | Python, C/C++, and Lua | Yes |
|
| TensorFlow (TF) | [161] | Python and C++ | Python, Java, JavaScript, C/C++, Julia, C#, and Go | Yes |
|
| DL4j | [162] | Java, JVM | Python, Java, and Scala | Yes |
|
| Caffe | [163] | C++ | MATLAB and Python | Yes |
|
| MXNet | [164] | // | Python, C++, Perl, R, Go, Matlab, Scala, and Julia. | Yes |
|
| Theano | [165] | Python | Python | Yes |
|
| CNTK | [166] | C++/C# | C++, Python, and BrainScript | Yes |
|
| Neon | [167] | Python | Python | Yes |
|
| Keras | [168] | Python | Python | Yes |
|
| Gluon | [169] | Python | Python | Yes |
|
| SNo | Architecture | References | Targets | Datasets | Language | Drawbacks |
|---|---|---|---|---|---|---|
| 1. | Deep CNN with Knowledge-based features | [173] | This model mine both implicit and explicit causality, and direction of causality. | SemEval-2007 Task-4 and SemEval-2010 Task 8 datasets in English language. | English | Work on simple knowledge-based features |
| 2. | MCNNs + BK | [174] | This work targeted implicit and ambiguous causality. | Four billion web pages in Japanese corpus. | Japanese | Only concentrated on Japanese corpus |
| 3. | CA-MCNN | [176] | Target implicitly expressed cause-effect relations. | 600 million Japanese web pages. | ✓ | ✓ |
| 4. | FFNN | [177] | This architecture targeted implicit and ambiguous causalities. | The Penn Discourse Treebank and CST News Corpus in English language. | English | Over-fitting problem |
| 5. | COPA Encoder-decoder models | [178] | They targeted causally related entities. | The Visual Storytelling (VIST), CNN/Daily Mail corpus, and CMU Book/Movie Plot Summaries in English language. | ✓ | Complex network design |
| 6. | bi-LSTM | [179] | They focused causal events and their effects inside a sentence. | The BBC News Article, SemEval2010 task-8, and ADE (Adverse drug effect) datasets in English language. | ✓ | Time complexity |
| 7. | Temporal Causal Discovery Framework (TCDF) | [180] | They learned temporal causal graph design by mining causality in a continuous observational time series data. | The simulated financial market (SFM) and simulated functional magnetic resonance imaging (SFMRI) dataset in English language. | ✓ | They executes rather worse on short time series. |
| 8. | Deep CNN with grammar tags | [181] | Identifying cause-effect pair from nominal words. | SemEval-2010 Task 8 corpus. | ✓ | Over-fitting problem. |
| 9. | Knowledge-Oriented CNN (K-CNN) | [182] | They targeted implicit causalities. | The Causal-Time Bank (CTB), SemEval-2010 task-8, and Event Story Line datasets in English language. | ✓ | Model over-fitting issue |
| 10. | FFNN + BK | [183] | They targeted implicit causalities social media tweets. | Tweets associated to commonwealth Games, held in 2018 in Australia, in English language. | ✓ | This results in info loss. Due to opinionated posts. |
| 11. | This technique applying a deep causal event detection and context word extension approach | [184] | They targeted implicit causalities in tweets. | More than 207k tweets related to Commonwealth Games-2018 held in Australia, in English language. | ✓ | Have knowledge or Information loss |
| 12. | BERT-based approach using multiple classifiers | [185] | Mining Implicit Causality inside web corpus. | 180 million news article snippets and titles corpus. | Japanese | Awareness and risk Management. |
| 13. | BiLSTM-CRF-based model | [190] | They focused on implicit CM. | SemEval 2010 task 8 dataset with extended annotation in English language. | ✓ | Over-fitting issues |
| 14. | Masked Event C-BERT, Event aware C-BERT, and C-BERT. | [192] | Influence the complete sentence context, events context, and events masked context for CM. | Semeval 2010 task 8 [30], Semeval 2007 task 4 [57], and ADE corpus. | ✓ | They simply focus to recognize possible causality among marked events in a given sequence of text, but it doesn’t find the validity of such relations. |
| SNo | Statistical /ML Techniques | Deep Learning Techniques |
|---|---|---|
| 1. | ML approaches used automatic tools for annotations, coding, and labeling e.g., crowdsourcing platforms like Amazon mechanical trunk (AMT). | DL approaches utilize deep neural architecture for analyzing data more deeply for automatic feature engineering. |
| 2. | ML techniques focus on finding patterns automatically through small seed patterns. | They focus on finding patterns automatically by deep analysis without using seed patterns. |
| 3. | They are trained and tested on huge textual corpora as compared to manual approaches. | They are trained and tested on unlimited text corpora. |
| 4. | They work well using domain-independent corpus. | They combine both domain-dependency and independency into one framework. |
| 5. | Such approaches are capable of catching those generalizations by appropriate feature sets. | Such approaches work well for both specific and other generalizes corpora. |
| 6. | By using class-specific probabilities, the ambiguities can be captured automatically with ML algorithms. | Those approaches use their deep architecture by targeting implicit and ambiguous relations more efficiently. |
| 7. | Such approaches focusing on both explicit and simple implicit causality. | They combine both implicit and explicit causalities into one model. |
| 8. | Those approaches use lexical Knowledge bases and some other broad-based corpora like Wikipedia and DBpedia by creating knowledge bases and ontologies for training. | Those approaches combine all semantic lexicons and use web archives as a source of world knowledge. |
| 9. | They are not working well for highly specialized domains. Besides, such annotated data may not be available in plenty, which results in good training and generalization. | Such approaches do not work well for highly specialized domains. |
| 10. | Such approaches lacking standardized corpora, yet, no work provided empirical comparisons with existing approaches. This makes it a surprising and relatively fruitless exercise to compare the recall, precision, and accuracy of one approach with others. | Similarly, those approaches lack of standardized corpora, and yet, no work provided empirical comparisons with existing models. This makes it a surprising and comparatively fruitless exercise to compare the precision, recall, and accuracy of different approaches with each other. |
| S_No | Challenges | Future Research Guidelines |
|---|---|---|
| 1. | Ambiguous Data | The deep model can memorize a huge amount of information and data, but due to the heterogeneous nature of data makes it a black-box solution for many applications. The existence of such datasets is a key challenge, which needs the interpretability of data- driven DL techniques that produce more satisfactory results. |
| 2. | Features Engineering | Using Deep CNN, RNN, GRU, LSTM, bi-LSTM, DCNN, BERT, and MCNN with their powerful feature abstraction capabilities to capture implicit and ambiguous features contribute most of the errors in the existing systems. Hence, new paradigms are required that can boost the learning ability of DL by integrating informative features-maps learned by supporting learners at the intermediate phases of DL models [70]. |
| 3. | Model Sel | DL approaches still facing trouble by modeling complex data modalities. To achieve the best performance at various datasets, the combination of diverse and multiple DL architectures (DeepCNN, DeepRNN, Transformer, BERT, TinyBERT, ELECTRA, and attention-based bi-LSTM) can benefit the model robustness and generalization on various relations by mining diverse levels of semantic representations. Ideas of dropout, batch normalization, and novel activation functions are also important. |
| 4. | Nature of Causality | For mining techniques implicit and ambiguous causality across the sentences is still a big challenge, which needs the ideas of single sentence rule and procedures that help us to develop a model for cross sentence CM. |
| 5. | Data Standardization | By the general lack of standardized datasets, this is a surprising and relatively fruitless exercise to compare the precision, recall, and accuracy of different techniques. This needs attention in the preparation of a standardized dataset. And an experimental comparison of the existing systems is required on standardized data sets, and for now, CM is still full of challenges, included counterfactual causality and credibility of causality in text. |
| 6. | Computational Cost | Review the applications of deep CNN on other associated tasks such as computer vision and NLP tasks will lead us to observe those models for CM. |
| 7. | Accuracy | Combining a general semantic relations classifier e.g., SemEval-Tasks with any existing causality extraction system would be a valuable attempt toward accuracy improvement. |
| 8. | Hypothesis generation | There is a need to use some techniques for event causality hypothesis generation and Scenario generation. |
| 9. | Area of Interest | There should need to use some techniques for event causality hypothesis and Scenario generation. |
| 10. | Attention | Attention is a fundamental visual organism in the human body, which automatically catches information from text and images in the surrounding. The attention system not simply mines the essential information from text and image but also stores its contextual relation with additional elements. In the future, research may be conceded in the track that reserves the whole semantics, syntactic features along with their discriminating features at the learning stages. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, W.; Zuo, W.; Ali, R.; Zuo, X.; Rahman, G. Causality Mining in Natural Languages Using Machine and Deep Learning Techniques: A Survey. Appl. Sci. 2021, 11, 10064. https://doi.org/10.3390/app112110064
Ali W, Zuo W, Ali R, Zuo X, Rahman G. Causality Mining in Natural Languages Using Machine and Deep Learning Techniques: A Survey. Applied Sciences. 2021; 11(21):10064. https://doi.org/10.3390/app112110064
Chicago/Turabian StyleAli, Wajid, Wanli Zuo, Rahman Ali, Xianglin Zuo, and Gohar Rahman. 2021. "Causality Mining in Natural Languages Using Machine and Deep Learning Techniques: A Survey" Applied Sciences 11, no. 21: 10064. https://doi.org/10.3390/app112110064