
Deep Convolutional Neural Network with KNN Regression for Automatic Image Annotation


Abstract
:1. Introduction
2. Related Work
3. Our Proposal
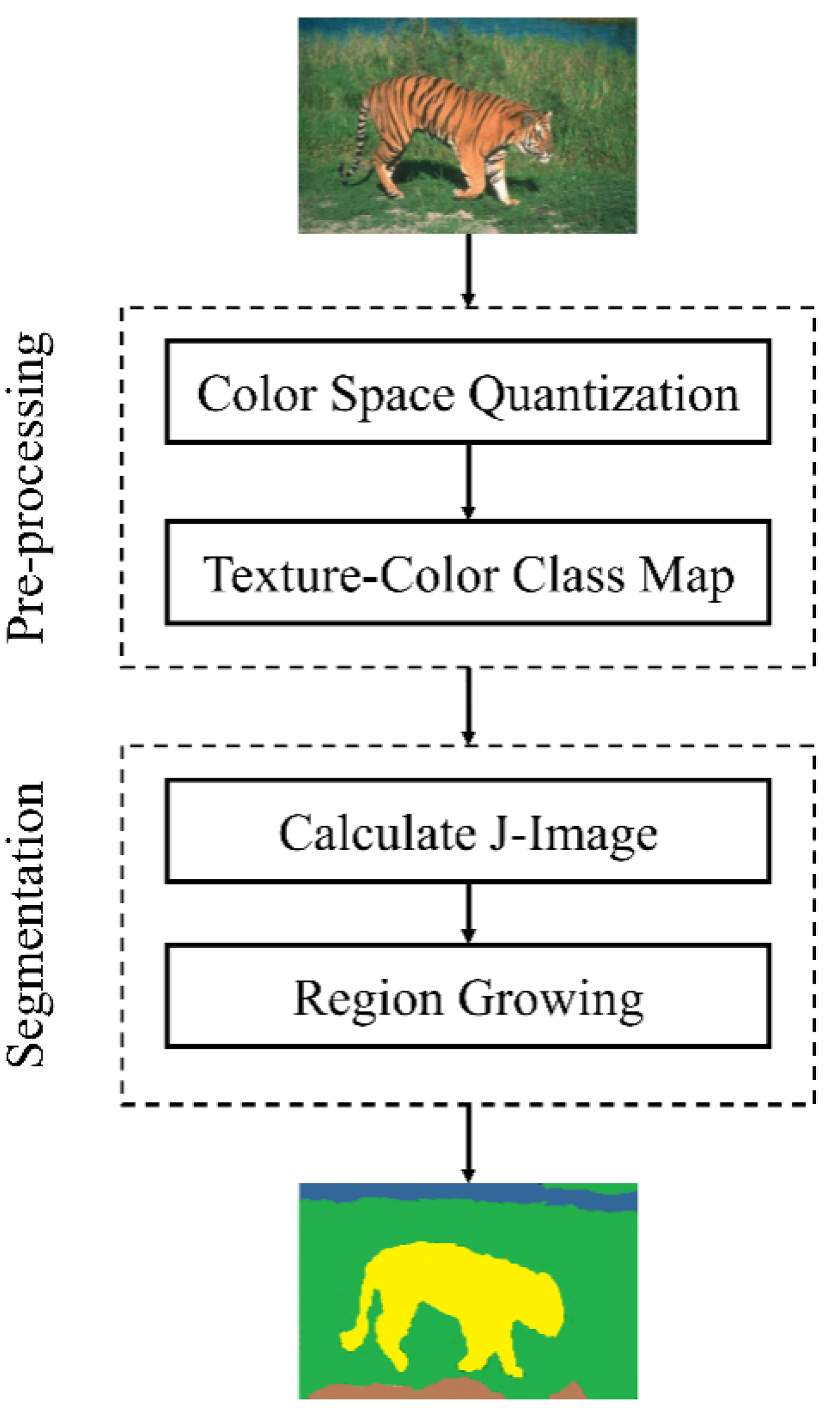
3.1. Image Segmentation Using JSEG Algorithm
3.2. Region Representation
3.3. Feature Aggregation
3.4. Calculating Blob–Label Co-Occurrences
3.5. Annotating New Images
- Embed descriptor into the appropriate manifold using the trained autoencoder model from N2D.
- Retrieve k-nearest clusters using a simple Euclidean distance Cri = {c1, c2, …, ck} and calculate, for each annotation ai in the dataset, a regression probability: . This regressed value will be considered as a representative of the region .
- Maximize the following Bayesian probability: , where , and , g(ci) calculates the center of the cluster ci.
- Assign the top fit concepts C* = {aj} to the input image.
4. Experiments and Result Analysis
4.1. Experiment Setup
- Datasets:
- Evaluation Metrics:
4.2. Scenario 1: Parameter Tuning
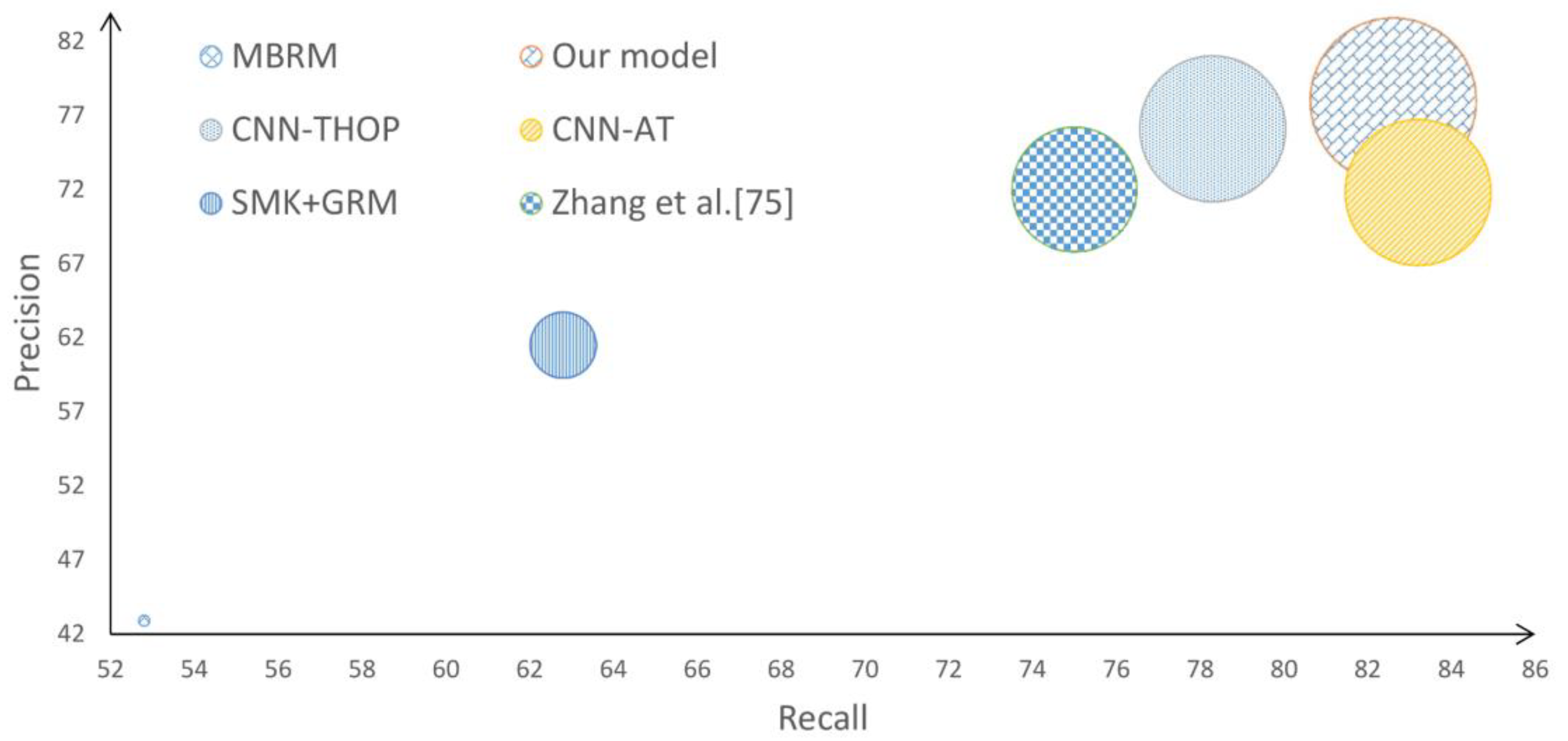
4.3. Scenario 2: Comparing Our Method to the State of the Art
4.4. Scenario 3: Computing Cost
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, J.; Ying, P.; Fu, X.; Luo, X.; Guan, H.; Wei, K. Automatic tagging by leveraging visual and annotated features in social media. IEEE Trans. Multimed. 2021, 9210, 1–12. [Google Scholar]
- Stangl, A.; Morris, M.R.; Gurari, D. Person, Shoes, Tree. Is the Person Naked? What People with Vision Impairments Want in Image Descriptions. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Ben, H.; Pan, Y.; Li, Y.; Yao, T.; Hong, R.; Wang, M.; Mei, T. Unpaired Image Captioning with Semantic-Constrained Self-Learning. IEEE Trans. Multimed. 2021, 1. [Google Scholar] [CrossRef]
- Moran, S.; Lavrenko, V. Sparse kernel learning for image annotation. In Proceedings of the ICMR 2014—ACM International Conference on Multimedia Retrieval 2014, Glasgow, UK, 1–4 April 2014; pp. 113–120. [Google Scholar]
- Zhang, S.; Huang, J.; Li, H.; Metaxas, D.N. Automatic image annotation and retrieval using group sparsity. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 838–849. [Google Scholar] [CrossRef]
- Guillaumin, M.; Mensink, T.; Verbeek, J.; Schmid, C. TagProp: Discriminative metric learning in nearest neighbor models for image auto-annotation. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 309–316. [Google Scholar]
- Murthy, V.N.; Maji, S.; Manmatha, R. Automatic image annotation using deep learning representations. In Proceedings of the ICMR 2015—5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 603–606. [Google Scholar]
- Murthy, V.N.; Can, E.F.; Manmatha, R. A hybrid model for automatic image annotation. In Proceedings of the ICMR 2014—ACM International Conference on Multimedia Retrieval 2014, Glasgow, UK, 1–4 April 2014; pp. 369–376. [Google Scholar]
- Makadia, A.; Pavlovic, V.; Kumar, S. A new baseline for image annotation. In Lecture Notes in Computer Science (LNCS); Springer: Berlin/Heidelberg, Germany, 2008; Volume 5304, pp. 316–329. [Google Scholar]
- Xiang, Y.; Zhou, X.; Chua, T.S.; Ngo, C.W. A revisit of generative model for automatic image annotation using markov random fields. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition Work (CVPR Work), Miami, FL, USA, 20–25 June 2009; Volume 2009, pp. 1153–1160. [Google Scholar]
- Verma, Y.; Jawahar, C.V. Image Annotation Using Metric Learning in Semantic Neighbourhoods. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 836–849. [Google Scholar]
- Verma, Y.; Jawahar, C.V. Exploring SVM for image annotation in presence of confusing labels. In Proceedings of the BMVC 2013—British Machine Vision Conference, BMVC 2013, Bristol, UK, 9–13 September 2013. [Google Scholar]
- Yang, C.; Dong, M.; Hua, J. Region-based image annotation using asymmetrical support vector machine-based multiple-instance learning. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2006, 2, 2057–2063. [Google Scholar]
- Wang, Y.; Mei, T.; Gong, S.; Hua, X.S. Combining global, regional and contextual features for automatic image annotation. Pattern Recognit. 2009, 42, 259–266. [Google Scholar] [CrossRef]
- Rejeb, I.B.; Ouni, S.; Barhoumi, W.; Zagrouba, E. Fuzzy VA-Files for multi-label image annotation based on visual content of regions. Signal Image Video Process. 2018, 12, 877–884. [Google Scholar] [CrossRef]
- Zhang, J.; Gao, Y.; Feng, S.; Yuan, Y.; Lee, C.H. Automatic image region annotation through segmentation based visual semantic analysis and discriminative classification. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; Volume 2016, pp. 1956–1960. [Google Scholar]
- Yuan, J.; Li, J.; Zhang, B. Exploiting spatial context constraints for automatic image region annotation. Proc. ACM Int. Multimed. Conf. Exhib. 2007, 595–604. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Mu, Y.; Feng, S.; Li, K.; Yuan, Y.; Lee, C. Image region annotation based on segmentation and semantic correlation analysis. IET Image Process. 2018, 12, 1331–1337. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Li, D.; Chen, Z.; Yuan, Y. A novel image annotation model based on content representation with multi-layer segmentation. Neural Comput. Appl. 2015, 26, 1407–1422. [Google Scholar] [CrossRef]
- Chen, Y.; Zeng, X.; Chen, X.; Guo, W. A survey on automatic image annotation. Appl. Intell. 2020, 50, 3412–3428. [Google Scholar] [CrossRef]
- Jerhotová, E.; Švihlík, J.; Procházka, A. Biomedical Image Volumes Denoising via the Wavelet Transform. In Applied Biomedical Engineering; Gargiulo, G.D., McEwan, A., Eds.; IntechOpen: London, UK, 2011; pp. 435–458. [Google Scholar] [CrossRef] [Green Version]
- Bnou, K.; Raghay, S.; Hakim, A. A wavelet denoising approach based on unsupervised learning model. EURASIP J. Adv. Signal Process. 2020, 2020, 36. [Google Scholar] [CrossRef]
- Ma, Y.; Xie, Q.; Liu, Y.; Xiong, S. A weighted KNN-based automatic image annotation method. Neural Comput. Appl. 2020, 32, 6559–6570. [Google Scholar] [CrossRef]
- Carneiro, G.; Vasconcelos, N. Formulating semantic image annotation as a supervised learning problem. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2005, II, 163–168. [Google Scholar]
- Blei, D.M.; Jordan, M.I. Modeling annotated data. In Proceedings of the 26th ACM/SIGIR International Symposium on Information Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; p. 127. [Google Scholar]
- Li, L.J.; Socher, R.; Fei-Fei, L. Towards total scene understanding: Classification, annotation and segmentation in an automatic framework. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. Work 2009, 2009, 2036–2043. [Google Scholar]
- Brown, P.F.; Pietra, S.D.; Pietra, V.J.D.; Mercer, R.L. The Mathematics of Statistical Machine Translation: Parameter Estimation. Comput. Linguist. 1994, 19, 263–311. [Google Scholar]
- Jeon, J.; Lavrenko, V.; Manmatha, R. Automatic Image Annotation and Retrieval using Cross-Media Relevance Models. In Proceedings of the 26th ACM/SIGIR International Symposium on Information Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 119–126. [Google Scholar]
- Feng, S.L.; Manmatha, R.; Lavrenko, V. Multiple Bernoulli relevance models for image and video annotation. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2004, 2, 1002–1009. [Google Scholar]
- Chen, B.; Li, J.; Lu, G.; Yu, H.; Zhang, D. Label Co-Occurrence Learning With Graph Convolutional Networks for Multi-Label Chest X-Ray Image Classification. IEEE J. Biomed. Health Inform. 2020, 24, 2292–2302. [Google Scholar] [CrossRef] [PubMed]
- Mori, Y.; Takahashi, H.; Oka, R. Image-to-Word Transformation Based on Dividing and Vector Quantizing Images with Words; CiteSeerX: Princeton, NJ, USA, 1999. [Google Scholar]
- Duygulu, P.; Barnard, K.; de Freitas, J.F.G.; Forsyth, D.A. Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2353, pp. 97–112. [Google Scholar]
- Barnard, K.; Duygulu, P.; Forsyth, D.; de Freitas, N.; Blei, D.M.; Jordan, M.I. Matching words and pictures. J. Mach. Learn. Res. 2003, 3, 1107–1135. [Google Scholar]
- Darwish, S.M. Combining firefly algorithm and Bayesian classifier: New direction for automatic multilabel image annotation. IET Image Process. 2016, 10, 763–772. [Google Scholar] [CrossRef]
- Gould, S.; Fulton, R.; Koller, D. Decomposing a scene into geometric and semantically consistent regions. Proc. IEEE Int. Conf. Comput. Vis. 2009, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Bhagat, P.; Choudhary, P. Image Annotation: Then and Now, Image and Vision Computing; Elsevier: Amsterdam, The Netherlands, 2018; Volume 80, pp. 1–23. [Google Scholar]
- Deng, Y.; Manjunath, B.; Shin, H. Color image segmentation. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 446–451. [Google Scholar]
- Khattab, D.; Ebied, H.M.; Hussein, A.S.; Tolba, M.F. Color image segmentation based on different color space models using automatic GrabCut. Sci. World J. 2014, 2014, 126025. [Google Scholar] [CrossRef]
- Aloun, M.S.; Hitam, M.S.; Yussof, W.N.H.W.; Hamid, A.A.K.A.; Bachok, Z. Modified JSEG algorithm for reducing over-segmentation problems in underwater coral reef images. Int. J. Electr. Comput. Eng. 2019, 9, 5244–5252. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2014, 1717–1724. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8689, pp. 818–833. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lai, S.; Zhu, Y.; Jin, L. Encoding Pathlet and SIFT Features With Bagged VLAD for Historical Writer Identification. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3553–3566. [Google Scholar] [CrossRef]
- McConville, R.; Santos-Rodriguez, R.; Piechocki, R.J.; Craddock, I. N2D: (not too) deep clustering via clustering the local manifold of an autoencoded embedding. Proc. Int. Conf. Pattern Recognit. 2020, 5145–5152. [Google Scholar] [CrossRef]
- Khaldi, B.; Aiadi, O.; Kherfi, M.L. Combining colour and greylevel cooccurrence matrix features: A comparative study. IET Image Process. 2019, 13, 1401–1410. [Google Scholar] [CrossRef]
- Khaldi, B.; Aiadi, O.; Lamine, K.M. Image representation using complete multi-texton histogram. Multimed. Tools Appl. 2020, 79, 8267–8285. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C. Image annotation based on feature fusion and semantic similarity. Neurocomputing 2015, 149, 1658–1671. [Google Scholar] [CrossRef]
- Su, F.; Xue, L. Graph Learning on K Nearest Neighbours for Automatic Image Annotation. In Proceedings of the ICMR 2015—5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 403–410. [Google Scholar]
- Amiri, S.H.; Jamzad, M. Efficient multi-modal fusion on supergraph for scalable image annotation. Pattern Recognit. 2015, 48, 2241–2253. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, W.; Xie, Y. Image automatic annotation via multi-view deep representation. J. Vis. Commun. Image Represent. 2015, 33, 368–377. [Google Scholar] [CrossRef]
- Rad, R.; Jamzad, M. Automatic image annotation by a loosely joint non-negative matrix factorisation. IET Comput. Vis. 2015, 9, 806–813. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, H.; Guo, X.; Liu, S.; Meng, D. SLED: Semantic Label Embedding Dictionary Representation for Multilabel Image Annotation. IEEE Trans. Image Process. 2015, 24, 2746–2759. [Google Scholar]
- Li, J.; Yuan, C. Automatic Image Annotation Using Adaptive Weighted Distance in Improved K Nearest Neighbors Framework. In Pacific Rim Conference on Multimedia; Springer: Cham, Switzerland, 2016; Volume 2, pp. 345–354. [Google Scholar]
- Le, H.M.; Nguyen, T.-O.; Ngo-Tien, D. Fully Automated Multi-label Image Annotation by Convolutional Neural Network and Adaptive Thresholding. In Proceedings of the Seventh Symposium on Information and Communication Technology, Ho Chi Minh City, Vietnam, 8–9 December 2016. [Google Scholar]
- Jin, C.; Jin, S.-W. Image distance metric learning based on neighborhood sets for automatic image annotation, Journal of Visual Communication and Image Representation. J. Vis. Commun. Image Represent. 2016, 34, 167–175. [Google Scholar] [CrossRef]
- Jing, X.-Y.; Wu, F.; Li, Z.; Hu, R.; Zhang, D. Multi-Label Dictionary Learning for Image Annotation. IEEE Trans. Image Process. 2016, 25, 2712–2725. [Google Scholar] [CrossRef]
- Jiu, M.; Sahbi, H. Nonlinear Deep Kernel Learning for Image Annotation. IEEE Trans. Image Process. 2017, 26, 1820–1832. [Google Scholar] [CrossRef] [PubMed]
- Ke, X.; Zhou, M.; Niu, Y.; Guo, W. Data equilibrium based automatic image annotation by fusing deep model and semantic propagation. Pattern Recognit. 2017, 71, 60–77. [Google Scholar] [CrossRef]
- Rad, R.; Jamzad, M. Image annotation using multi-view non-negative matrix factorization with different number of basis vectors. J. Vis. Commun. Image Represent. 2017, 46, 1–12. [Google Scholar] [CrossRef]
- Khatchatoorian, A.G. Post rectifying methods to improve the accuracy of image annotation. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, NSW, Australia, 29 November–1 December 2017; pp. 406–412. [Google Scholar]
- Zhang, W.; Hu, H.; Hu, H. Training Visual-Semantic Embedding Network for Boosting Automatic Image Annotation. Neural Process. Lett. 2018, 48, 1503–1519. [Google Scholar] [CrossRef]
- Khatchatoorian, A.G.; Jamzad, M. An Image Annotation Rectifying Method Based on Deep Features. In Proceedings of the 2018 2nd International Conference on Digital Signal Processing, Tokyo, Japan, 25–27 February 2018; pp. 88–92. [Google Scholar]
- Wang, X.L.; Hongwei, G.E.; Liang, S. Image automatic annotation algorithm based on canonical correlation analytical subspace and k-nearest neighbor. J. Ludong Univ. 2018. [Google Scholar]
- Ning, Z.; Zhou, G.; Chen, Z.; Li, Q. Integration of image feature and word relevance: Toward automatic image annotation in cyber-physical-social systems. IEEE Access 2018, 6, 44190–44198. [Google Scholar] [CrossRef]
- Maihami, V.; Yaghmaee, F. Automatic image annotation using community detection in neighbor images. Phys. A Stat. Mech. Its Appl. 2018, 507, 123–132. [Google Scholar] [CrossRef]
- Xue, Z.; Li, G.; Huang, Q. Joint multi-view representation and image annotation via optimal predictive subspace learning. Inf. Sci. 2018, 451–452, 180–194. [Google Scholar] [CrossRef]
- Ke, X.; Zou, J.; Niu, Y. End-to-End Automatic Image Annotation Based on Deep CNN and Multi-Label Data Augmentation. IEEE Trans. Multimed. 2019, 21, 2093–2106. [Google Scholar] [CrossRef]
- Ma, Y.; Liu, Y.; Xie, Q.; Li, L. CNN-feature based automatic image annotation method. Multimed. Tools Appl. 2019, 78, 3767–3780. [Google Scholar] [CrossRef]
- Jiu, M.; Sahbi, H. Deep Context-Aware Kernel Networks. arXiv 2019, arXiv:1912.12735. [Google Scholar]
- Song, H.; Wang, P.; Yun, J.; Li, W.; Xue, B.; Wu, G. A Weighted Topic Model Learned from Local Semantic Space for Automatic Image Annotation. IEEE Access 2020, 8, 76411–76422. [Google Scholar] [CrossRef]
- Chen, S.; Wang, M.; Chen, X. Communications, Mobilenbsp;, and 2020, Image annotation via reconstitution graph learning model. Wirel. Commun. Mob. Comput. 2020, 2020, 1–9. [Google Scholar]
- Khatchatoorian, A.G.; Jamzad, M. Architecture to improve the accuracy of automatic image annotation systems. IET Comput. Vis. 2020, 14, 214–223. [Google Scholar] [CrossRef]
- Zhu, Z.; Hangchi, Z. Image annotation method based on graph volume network. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City, ICITBS 2020, Vientiane, Laos, 11–12 January 2020; pp. 885–888. [Google Scholar]
- Cao, J.; Zhao, A.; Zhang, Z. Automatic image annotation method based on a convolutional neural network with threshold optimization. PLoS ONE 2020, 15, e0238956. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, M.; Gao, J.; Li, P. Image Annotation based on Semantic Structure and Graph Learning. In Proceedings of the IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress, Calgary, AB, Canada, 17–22 August 2020; pp. 451–456. [Google Scholar]
- Zhang, W.; Hu, H.; Hu, H.; Yu, J. Automatic image annotation via category labels. Multimed. Tools Appl. 2020, 79, 11421–11435. [Google Scholar] [CrossRef]
- Tian, D.; Shi, Z. A two-stage hybrid probabilistic topic model for refining image annotation. Int. J. Mach. Learn. Cybern. 2019, 11, 417–431. [Google Scholar] [CrossRef]
- Ge, H.; Zhang, K.; Hou, Y.; Yu, C.; Zhao, M.; Wang, Z.; Sun, L. Two-stage Automatic Image Annotation Based on Latent Semantic Scene Classification. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Chen, Y.; Liu, L.; Tao, J.; Chen, X.; Xia, R.; Zhang, Q.; Xiong, J.; Yang, K.; Xie, J. The image annotation algorithm using convolutional features from intermediate layer of deep learning. Multimed. Tools Appl. 2020, 80, 4237–4261. [Google Scholar] [CrossRef]
- Wei, W.; Wu, Q.; Chen, D.; Zhang, Y.; Liu, W.; Duan, G.; Luo, X. Automatic image annotation based on an improved nearest neighbor technique with tag semantic extension model. Procedia Comput. Sci. 2021, 183, 616–623. [Google Scholar] [CrossRef]
- Li, Z.; Lin, L.; Zhang, C.; Ma, H.; Zhao, W.; Shi, Z. A Semi-supervised Learning Approach Based on Adaptive Weighted Fusion for Automatic Image Annotation. ACM Trans. Multimedia Comput. Commun. Appl. 2021, 17, 1–23. [Google Scholar]
- Zamiri, M.; Yazdi, H.S. Image annotation based on multi-view robust spectral clustering. J. Vis. Commun. Image Represent. 2020, 74, 103003. [Google Scholar] [CrossRef]
- Kuric, E.; Bielikova, M. ANNOR: Efficient Image Annotation Based on Combining Local and Global Features. Comput. Graph. 2016, 47, 1–15. [Google Scholar] [CrossRef]
- Zhang, J.; Tao, T.; Mu, Y.; Sun, H.; Li, D.; Wang, Z. Web image annotation based on Tri-relational Graph and semantic context analysis. Eng. Appl. Artif. Intell. 2019, 81, 313–322. [Google Scholar] [CrossRef]
- Vatani, A.; Ahvanooey, M.T.; Rahimi, M. An effective automatic image annotation model via attention model and data equilibrium. Int. J. Adv. Comput. Sci. Appl. 2001, 9, 269–277. [Google Scholar] [CrossRef] [Green Version]
- Kaoudja, Z.; Kherfi, M.L.; Khaldi, B. An efficient multiple-classifier system for Arabic calligraphy style recognition. In Proceedings of the International Conference on Networking and Advanced Systems (ICNAS), Annaba, Algeria, 26–27 June 2019. [Google Scholar]
- Aiadi, O.; Kherfi, M.L.; Khaldi, B. Automatic Date Fruit Recognition Using Outlier Detection Techniques and Gaussian Mixture Models. ELCVIA Electron. Lett. Comput. Vis. Image Anal. 2019, 18, 52–75. [Google Scholar] [CrossRef]
- Lu, Z.; Ip, H.H. Generalized relevance models for automatic image annotation. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5879, pp. 245–255. [Google Scholar]
- Lu, Z.; Ip, H.H.; He, Q. Context-based multi-label image annotation. In Proceedings of the International Conference on Image and Video Retrieval Santorini, Fira, Greece, 8–10 July 2009. [Google Scholar]
- Li, Z.; Zheng, Y.; Zhang, C.; Shi, Z. Combining Deep Feature and Multi-label Classification for Semantic Image Annotation. J. Comput. Des. Comput. Graph. 2018, 30, 318. [Google Scholar]
- Moran, S.; Lavrenko, V. sparse kernel relevance model for automatic image annotation. Int. J. Multimedia Inf. Retr. 2014, 3, 209–229. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corel-5k | MSRC v2 | |
|---|---|---|
| Dataset size | 5000 | 591 |
| Train set size | 4500 | 394 |
| Test set size | 500 | 197 |
| Number of labels | 371 | 23 |
| Mean labels per image | 3.4 | 2.5 |
| Mean images per label | 58.6 | 28.15 |
| Method | No. Cpt | P | R | F1 | N+ | |
|---|---|---|---|---|---|---|
| Holistic approach | CNN-R (2015) [7] | 374 | 32 | 41.3 | 36.1 | 166 |
| KCCA (2015) [7] | 374 | 39 | 53 | 44.9 | 184 | |
| CCA-KNN (2015) [7] | 374 | 42 | 52 | 46.5 | 201 | |
| Group Sparsity (2015) [47] | 260 | 30 | 33 | 31.4 | 146 | |
| GLKNN (2015) [48] | 260 | 36 | 47 | 40.8 | 184 | |
| MIAPS (2015) [49] | 260 | 39.98 | 42.66 | 41.28 | 177 | |
| MVSAE (2015) [50] | 260 | 37 | 47 | 42 | 175 | |
| LJNMF (2015) [51] | 260 | 35 | 43 | 39.1 | 175 | |
| SLED (2015) [52] | 260 | 35 | 51 | 41.5 | - | |
| AWD-IKNN (2016) [53] | 260 | 42 | 55 | 47.7 | 198 | |
| CNN-AT (2016) [54] | 374 | 26 | 17 | 21 | 88 | |
| NSIDML (2016) [55] | 260 | 44.12 | 51.76 | 47.76 | 194 | |
| MLDL (2016) [56] | 260 | 45 | 49 | 47 | 198 | |
| LDMKL (2017) [57] | 200 | 29 | 44 | 35 | 179 | |
| SDMKL (2017) [57] | 200 | 25 | 38 | 158 | ||
| L-ADA (2017) [58] | 260 | 31 | 38 | 34 | 164 | |
| NL-ADA (2017) [58] | 260 | 32 | 40 | 36 | 173 | |
| MVG-NMF (2017) [59] | 260 | 44 | 47.5 | 45.6 | 197 | |
| PRM (2017) [60] | 260 | 40.78 | 53.64 | 46.33 | 205 | |
| VSE-2PKNN-ML (2018) [61] | 260 | 41 | 52 | 46 | 205 | |
| PRM DEEP (2018) [62] | 260 | 45.3 | 51.73 | 48.3 | 201 | |
| CCAKNN (2018) [63] | 260 | 41 | 43 | 42 | 185 | |
| IDFRW (2018) [64] | 260 | 38 | 49 | 43 | 185 | |
| CDNI (2018) [65] | 260 | 29.8 | 32.1 | 30.9 | 162 | |
| OPSL (2018) [66] | 260 | 38.3 | 55 | 45.2 | ||
| E2E-DCNN (2019) [67] | 260 | 41 | 55 | 47 | 192 | |
| SEM (2019) [68] | 260 | 37 | 52 | 43 | - | |
| L-Global CA (2019) [69] | 260 | 36 | 45 | 189 | ||
| S-Global CA (2019) [69] | 260 | 36 | 46 | 194 | ||
| L-Classwise CA (2019) [69] | 260 | 36 | 45 | 192 | ||
| LL-PLSA (2020) [70] | 260 | 37 | 48 | 42 | - | |
| RDPGKNN (2020) [71] | 260 | 40 | 45 | 40 | 195 | |
| Weight-KNN (2020) [23] | 260 | 22 | 15 | 18 | - | |
| Khatchatoorian et al. (2020) [72] | 260 | 55.46 | 56.55 | 56 | 212 | |
| GCN (2020) [73] | 260 | 48 | 52 | 49 | 200 | |
| CNN-THOP (2020) [74] | 260 | 52.7 | 58.3 | 55.3 | - | |
| SSGL (2020) [75] | 260 | 34 | 47 | 40 | 190 | |
| Zhang et al. (2020) [76] | 374 | 60 | 68 | 64 | 228 | |
| PLSA-MB (2020) [77] | 260 | 26 | 30 | 27.9 | ||
| TAIA (2020) [78] | 260 | 38.4 | 48.6 | 42.9 | 177 | |
| Y.chen et al. (2021) [79] | 260 | 26.93 | 41.43 | 32.64 | 161 | |
| TSEM (2021) [80] | 260 | 38 | 46 | 42 | - | |
| TSEM+LQP (2021) [80] | 260 | 45 | 40 | 43 | - | |
| SSL-AWF (2021) [81] | 260 | 51 | 48 | 49.5 | 203 | |
| CNN-SPP (2021) [81] | 260 | 46 | 43 | 44.4 | 196 | |
| HMAA (2021) [1] | 260 | 43 | 54 | 48 | ||
| MVRSC (2021) [82] | 260 | 54.3 | 42.9 | 47.9 | ||
| LDA-ECC (2021) [81] | 260 | 35 | 36 | 35.5 | 148 | |
| Region-based approach | MLSIA (2015) [19] | 374 | 23.35 | 26.24 | 23.54 | - |
| ANNOR-G (2015) [83] | 260 | 22 | 29 | 25 | 129 | |
| Zhang et al. (2016) [16] | 374 | 57.61 | 53.04 | 53.85 | - | |
| BG (2019) [84] | 374 | 33 | 41 | 170 | ||
| TG (2019) [84] | 374 | 36 | 45 | 189 | ||
| Vatani et al. (2020) [85] | 260 | 28 | 96 | 43 | - | |
| Our method | 374 | 48.63 | 64.94 | 54.85 | 236 | |
| Our method | 260 | 59.45 | 65.01 | 58.89 | 212 |
| Ground Truth | CMRM [26] | Our Method | |
|---|---|---|---|
1.  | car, tracks, grass | water, tree, sky, people, grass | car, tracks, turn, prototype |
2.  | sky, tree, castle | people, building, ohau, water, tree | sky, clouds, tree, house |
3.  | flowers, petals, leaf | sky, water, people, tree, grass | leaf, flowers, petals, stems |
4.  | flowers, tree, sky | flowers, tree, grass, lawn, sky | sky, tree, flower, tulip |
5.  | sky, plane, runway | plane, jet, sky, cars, tracks | plane, runway, prop |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bensaci, R.; Khaldi, B.; Aiadi, O.; Benchabana, A. Deep Convolutional Neural Network with KNN Regression for Automatic Image Annotation. Appl. Sci. 2021, 11, 10176. https://doi.org/10.3390/app112110176
Bensaci R, Khaldi B, Aiadi O, Benchabana A. Deep Convolutional Neural Network with KNN Regression for Automatic Image Annotation. Applied Sciences. 2021; 11(21):10176. https://doi.org/10.3390/app112110176
Chicago/Turabian StyleBensaci, Ramla, Belal Khaldi, Oussama Aiadi, and Ayoub Benchabana. 2021. "Deep Convolutional Neural Network with KNN Regression for Automatic Image Annotation" Applied Sciences 11, no. 21: 10176. https://doi.org/10.3390/app112110176