1. Introduction
Students’ performance prediction (SPP) problem is a common challenge for institutions’ lecturers and decision-makers to develop the best educational strategies for students. To perform such a prediction, several educational parameters can be employed to evaluate the performance of students, such as exams grades, Grade Point Average (GPA), lecture absenteeism, number of attempts to pass a course or an exam. Moreover, other demographic features such as gender, family relationship, parent profession, marital status, and personal habits [
1,
2]. Predicting students’ performance for educational organizations has been conducted by many scientific communities. Examining a vast amount of educational data and extract their impacts on students’ performances is closely related to educational data mining (EDM) and machine learning (ML) algorithms. Generally speaking, EDM is a set of data mining methods that tries to extract hidden and valuable information from educational data to expand our understanding of students’ performance and enhance the learning process [
3,
4].
EDM applications require two types of data: (i) educational data collected from educational systems such as exams centers, virtual courses, registration offices, and e-learning systems, and (ii) demographic data that presents information about students. Demographic data is usually collected by surveys or personal meetings. Both types of data can be used to build a robust EDM application, which is able to manipulate seemingly meaningless educational data into valuable knowledge that can improve the learning process and avoid negative performance [
5]. In EDM, generally speaking, different kinds of data mining methods are needed, including but not limited to classifications [
6], clustering [
7], association rule mining [
8], and web mining [
9]. Moreover, due to modern learning technologies such as online classrooms, exams, and seminars, EDM applications can manipulate educational data accurately for a better understanding of the students’ performance, and learning process [
10]. Such EDM applications can assist both tutors and decision-makers in executing suitable learning strategies that fit their students.
In reality, there are many advantages of EDM applications, such as revealing the weaknesses of the learning process between the teachers and students, predicting dropout potential, and negative student behaviors [
11]. Moreover, it can determine the lapses and weaknesses of teaching strategies. EDM applications assist with reviewing the current learning models and evaluate their effectiveness. It can be used to evaluate the feedback information obtained from students and determine the limitations of the learning processes. EDM can cluster students based on their levels based on different criteria such as personal skills, learning behaviors, social attitudes, and interests [
12].
EDM and ML allow us to design a learning model(s) to predict students’ performance as a classification or recognition model(s). However, selecting a robust ML model is a challenging task due to several factors such as data nature, imbalanced data, noisy data, incomplete data, and the number of collected samples. Imbalanced data plays a vital role that affects the overall performance of ML models. For example, the number of passed students is much higher than the number of failed students, and the performance of learning model(s) will be influenced toward passed students. So, the learning process will suffer from overfitting problem. As a result, it is essential to analyze the educational data before building the EDM application. Moreover, the educational data should not have missing data to prevent the unstable behavior of the ML model. Several research papers addressed the imbalanced educational datasets while building ML models [
13,
14,
15]. In general, imbalanced data is manipulated based on data level (e.g., resampling methods) or algorithm level (e.g., cost-sensitive learning).
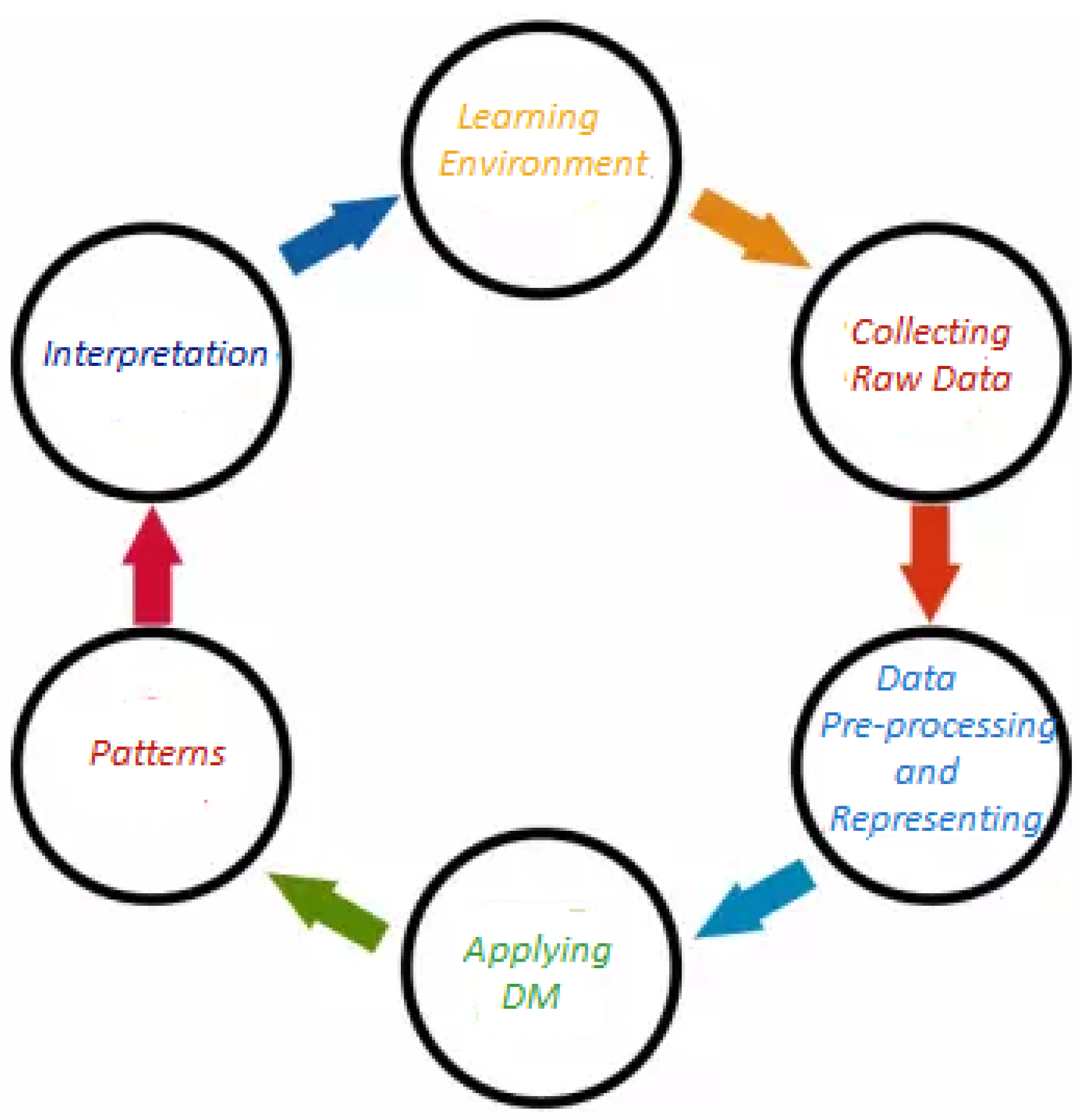
Figure 1 depicts the life cycle of EDM process.
In data mining techniques (e.g., classification), data preprocessing has a major impact on both the quality of chosen features and the performance of learning algorithms [
16,
17]. Feature selection (FS) is a fundamental preprocessing stage that aims to uncover and keep informative patterns (features) and remove noisy, uninformative, and irrelevant ones from the feature space. Detecting high-quality subset of features will boost the accuracy of learning classifiers and lessen the computational cost [
18,
19]. According to assessment criteria of the selected subset of features, FS techniques follow one of two branches: filters or wrappers [
19,
20]. Filter FS methods utilize scoring matrices for estimating the excellence of the selected subset of features. In other words, in filter type, features are weighted using a filter technique (e.g., information gain or chi-square), and then the features that possess weights less than a pre-set threshold are excluded from the features set. In the case of wrapper FS, a learning classifier (e.g., Linear Discriminant Analysis or K-Nearest Neighbour) is hired to decide the excellence of subsets of features produced by a search approach [
21,
22]. In general, in comparison with filter methods, wrapper FS can deliver better performance because it can implicitly discover and employ dependencies between features of a subset, whereas filter FS may miss such an advantage. However, the computational cost of using filter FS is cheaper than wrapper FS [
23].
Feature subset generation is identified as a search operation for finding a high-quality subset from a given set of patterns where a search mechanism such as complete/exact, random, or a heuristic is employed [
24,
25,
26]. In a complete search, all potentially obtainable feature subsets in the search space are formed and assessed. In other words, if a dataset includes
M features, then
subsets will be obtained and examined to identify the most valuable one. Complete search is impractical when dealing with massive datasets because of its high computational cost. Random search is another mechanism for generating subsets of features. In this mechanism, looking for the following feature subset in the feature space is done randomly [
27]. In some cases, the random search may lead to generate all potential subsets of features as in the complete search mechanism [
18,
28]. Compared to complete and random search, heuristic search is a different search mechanism for generating subsets of features. It is defined by Talbi [
28] as upper layer general methods that can be employed as guiding mechanisms to design underlying heuristics for resolving particular optimization problems. In contrast to complete/exact methods [
29,
30], meta-heuristics algorithms such as Particle Swarm Optimization (PSO) and Ant Colony Optimization (ACO) have demonstrated outstanding ability in solving many FS problems [
19,
31,
32,
33].
WOA is a modern meta-heuristic algorithm, introduced by Mirjalili and Lewis [
34]. It simulates the humpback whales’ intelligent foraging behavior. WOA possesses a simple structure that makes it easy to implement. It also has only two primary parameters that need to be adjusted. In addition, the WOA algorithm depends on just one parameter for smooth shifting from exploration to exploitation. WOA has shown high exploration ability. Unlike other meta-heuristic algorithms, WOA updates the position vector of a whale (solution) in the exploration stage with respect to the position vector of a randomly chosen search agent rather than the optimal search agent discovered so far [
17,
34,
35,
36]. Like other meta-heuristic algorithms, WOA has drawbacks like early convergence and the ease of falling into the local optimum. Hence, scholars have made several improvements to the basic version of WOA to overcome its limitation and employed it to solve various optimization problems. For instance, [
35] proposed an improved version of WOA based on Natural Selection Operators and applied it as a wrapper feature selection method for software fault prediction. Mafarja and Mirjalili [
17] combined WOA with simulated annealing (SA) algorithm to enhance its exploitation ability and applied their enhanced WOA-based approach for feature selection. Also, Ning and Cao [
36] proposed an improved variant of WOA and applied it for solving complex constrained optimization problems. A Mixed-Strategy-based WOA was proposed by Ding et al. [
37] for optimizing the parameter of a hydraulic turbine governing system (HTGS). Abdel-Basset et al. [
38] proposed Levy flight and logical chaos mapping based WOA approach and employed it to tackle virtual machine (VM) placement problem. As presented in [
39], WOA has the same problem as many other optimization algorithms and tends to be stuck into local optima. To overcome this problem, two enhancements for the WOA algorithm were proposed. The first improvement involves applying Elite Opposition-Based Learning (EOBL) the initialization stage of WOA, whereas the second one includes the integration of evolutionary operators comprising mutation, crossover, and selection from the Differential Evolution algorithm at the end of every WOA iteration. Since the WOA-based algorithms have been widely and effectively used in various applications, this is the foundation and motivation of this research as well.
This paper proposes an evolutionary-based SPP model that integrates an enhanced variant of WOA (EWOA) with an ML algorithm. The new variant EWOA is used to enhance the FS process and the prediction of students’ performance. The efficiency of the proposed model developed in this research is evaluated on two real, imbalanced, and public educational datasets adopted from the literature. To sum up, the main contributions of this research are as follows:
The ADASYN sampling technique is applied to handle the problem of imbalanced data.
Various types of well-known ML algorithms are assessed to select the best-performing one to handle the SPP problem.
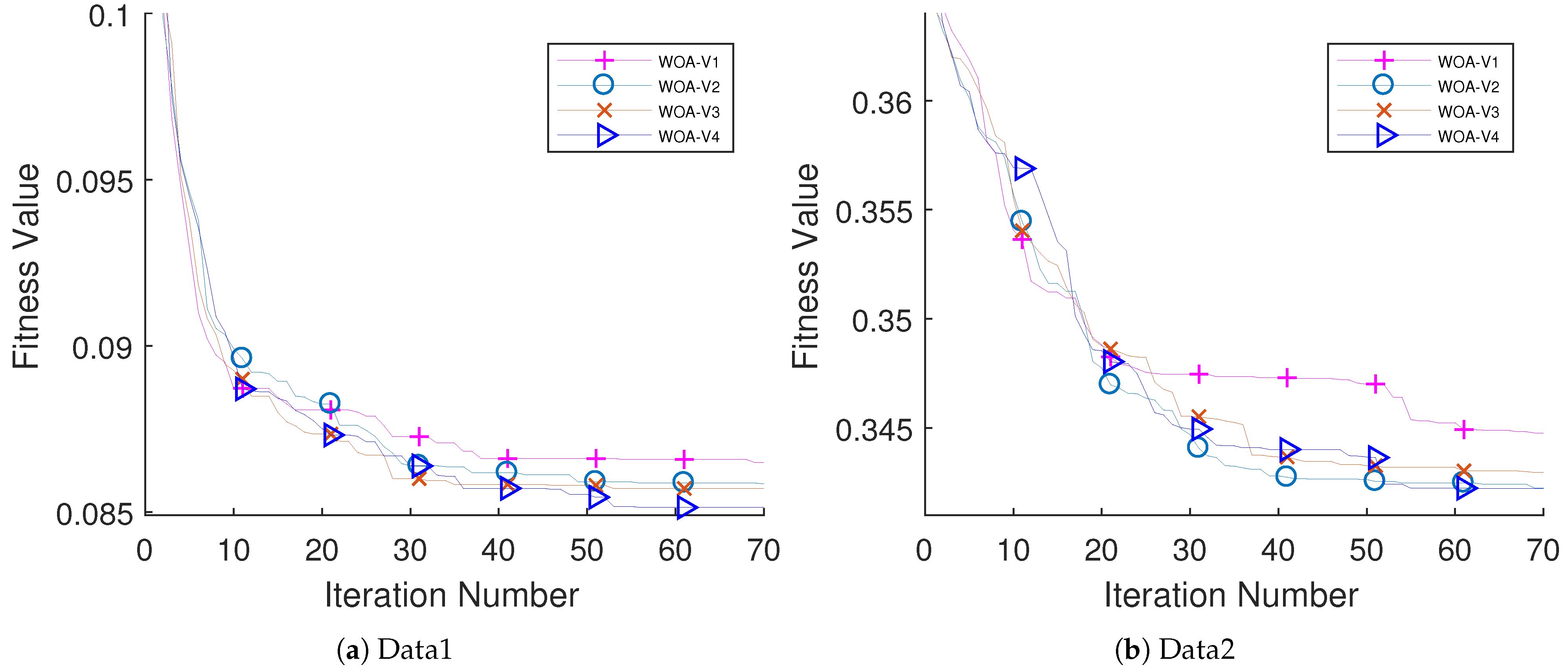
Eight fuzzy transfer functions from S-shaped and V-shaped families are examined to prepare WOA to match the binary search space of the FS problem.
An improved form of the WOA algorithm is introduced by combining it with the Sine Cosine Algorithm (SCA) and Logistic Chaotic Map (LCM) mechanism. The main objectives are overcoming the main weak point of WOA (i.e., weakness exploitation process) and keeping an appropriate scale between exploration and exploitation processes.
The performance of the proposed EWOA is evaluated against the state-of-the-art metaheuristic algorithms and shows promising results.
The rest of the paper is organized as follows:
Section 2 presents the related works of SPP and related EDM applications.
Section 3 explores the proposed methods.
Section 4 explores the educational datasets used in this work.
Section 5 presents the performance evaluation criteria for the proposed method. The results and analysis are presented in
Section 6. Finally, the conclusion and future works are presented in
Section 7.
3. Proposed Approach
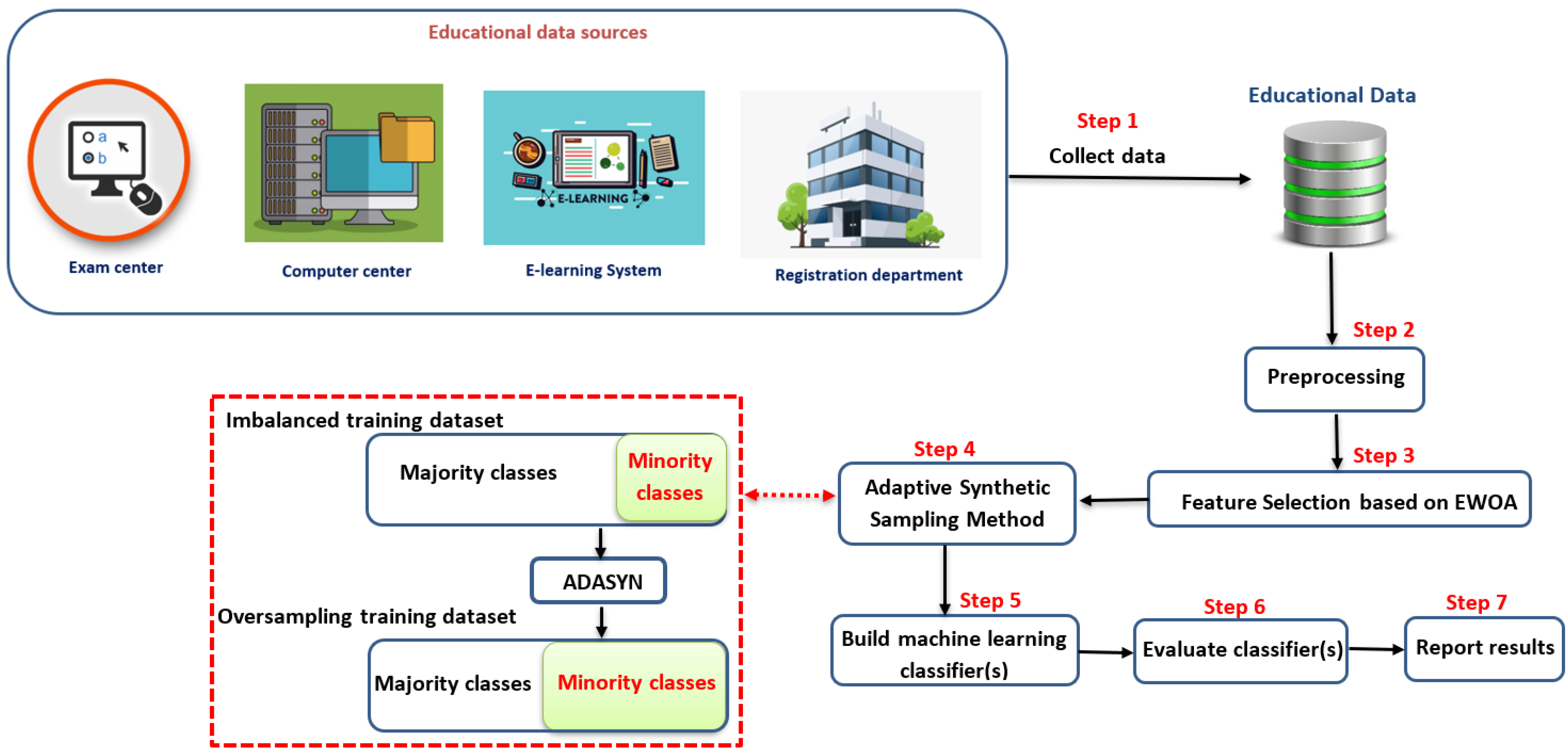
The proposed approach is depicted in
Figure 2. The proposed approach has seven steps as follows:
Collecting data from different educational resources, where this data may have different data types such as numbers (i.e., grades), letters (i.e., gender), strings (i.e., major, address, course names, etc.).
Preprocessing the collected data in order to be consistent. In this step, we removed all the records that have missing attributes and normalized the data between [0,1].
Apply EWAO as a feature selection to reduce the search space and remove the weakness attributes that have no impact on the overall performance.
Apply an ADASYN to overcome the imbalanced data and avoid overfitting problem while learning process.
Build a machine learning classifier that is able to predict the students’ performance.
Evaluate the obtained results based on the area under the ROC curve (AUC).
Finally, the obtained results are reported.
The following subsections explore the main methods employed in the proposed methodology. First, an overview of the ADASYN oversampling technique is presented in
Section 3.1. Second, an overview of the basic WOA is presented in
Section 3.2. Third, the main components of our enhancement over WOA are presented in
Section 3.3 and
Section 3.4, respectively. The Logistic Chaotic Map (LCM) is presented in sub
Section 3.3, where LCM is proposed inside the WOA to control the population diversity. The updating mechanism of the proposed enhancement is performed based on SCA, which is presented in
Section 3.4. The proposed EWOA is presented in
Section 3.5, which combines WOA, LCM, and SCA as a new FS algorithm.
Section 3.6 explains how transfer functions are used to convert the original WOA to match the binary search space for the FS problem. Finally,
Section 3.7 presents the formulation of FS as an optimization problem (i.e., fitness function and solution encoding).
3.1. ADASYN for Handling Imbalanced Data
Learning from imbalanced data is a significant challenge that could degrade the prediction quality of ML algorithms. This problem appears in most real classification problems where the target classes are not approximately equally represented [
69]. For instance, in binary classification problems, the data samples of one class are normally limited (rare instances) compared to other samples. In such situations, the classification algorithm is trained using highly imbalanced data. Thus, it tends to choose the patterns in the majority classes, which results in imprecise minority class prediction [
70].
ADASYN is a promising synthetic sampling approach developed basically over the idea of SMOTE approach, which both have been extensively employed to handle the problem of imbalanced learning [
71]. The main concept of ADASYN is to generate minority data samples considering their distributions adaptively. In specific, more synthetic data is produced for the samples of minority class that are difficult to learn in contrast with minority class samples that are simpler to learn. ADASYN facilitates learning from imbalanced data by achieving two objectives; it reduces the learning bias towards the dominant class and adapts the decision boundary to focus on those more challenging to learn samples. The detailed procedure of ADASYN can be found in [
71].
3.2. Whale Optimization Algorithm
Whales are considered the largest mammals that live in groups. Among the types of whales is the humpback whale [
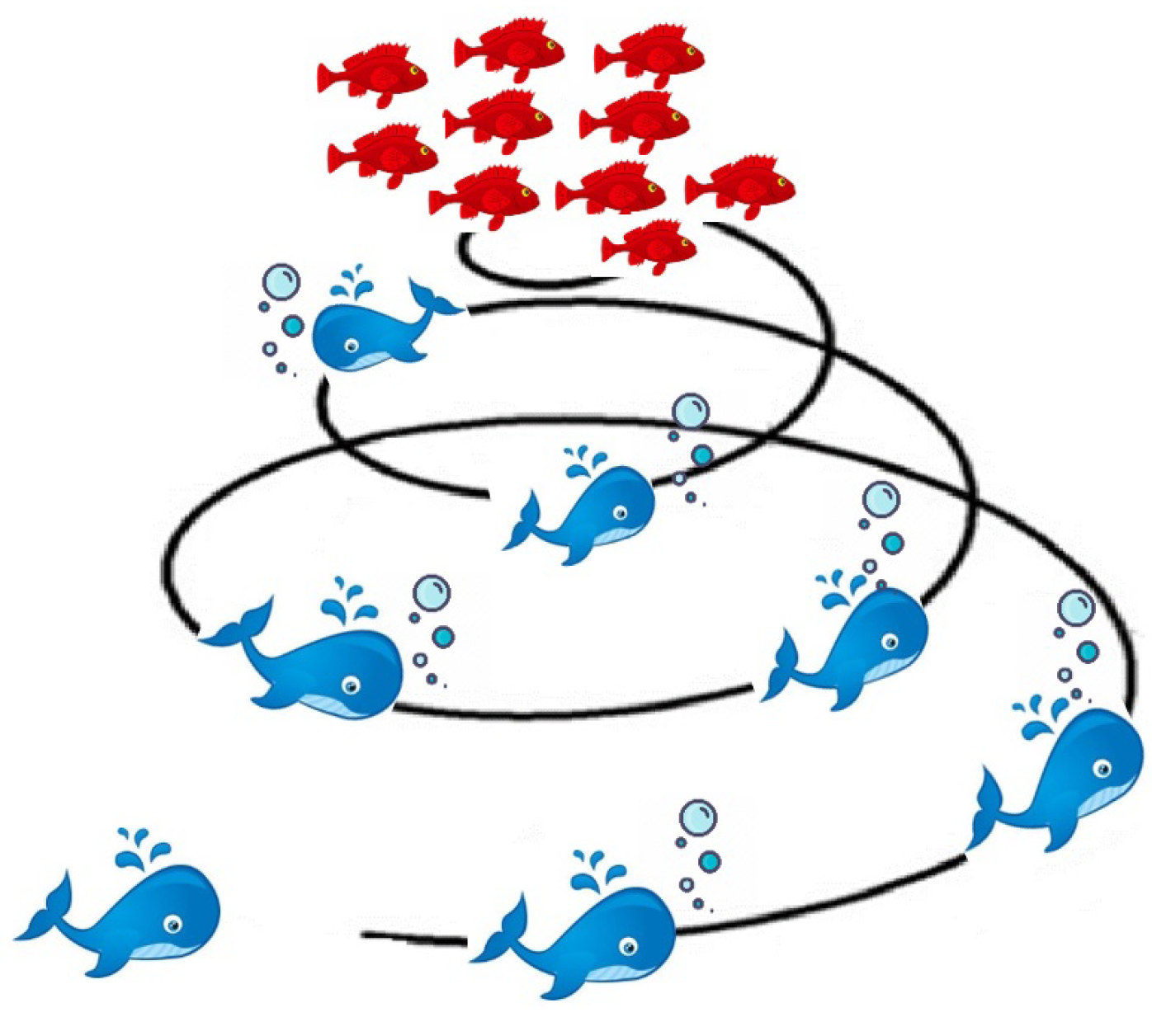
34]. In nature, Humpback whales have a wonderful hunting strategy to find food such as krill and fishes [
72]. The search strategy for humpback is named bubble-net feeding, in which humpback creates bubbles in an upward spiral swimming track around the target (i.e., fish, seals, squid, etc.) WOA is a swarm optimization method that simulates the process of the humpback whales while searching for their foods in the oceans based on creating bubble-nets to constrict the prey, and then whales move toward their preys in a spiral shape before the attack. Mirjalili and Lewis [
34] proposed WOA in 2016, which mimics the searching process for whales while hunting. The exploration process inside WOA simulates the encircling mechanism of the whales in nature. The authors represent the prey location as the best solution found so far, while the rest solutions represent the candidate whales.
Figure 3 demonstrates the spiral movement of the whale while searching for food. Since WOA is a population-based algorithm, the first phase of WOA is to create the initial population (humpback whales), as shown in the following Algorithm 1.
|
Algorithm 1 First phase of WOA algorithm. |
Create initial population of whales(LB, UB, nopop, n) = [, ,..., ] = [, ,..., ] for j=1:nopop do for m=1:n do initial population(j,m)=() × rand +
|
where
presents lower bound of the decision variables,
presents the upper bound of the decision variables,
presents the size of population, and
n denotes number of decision variables.
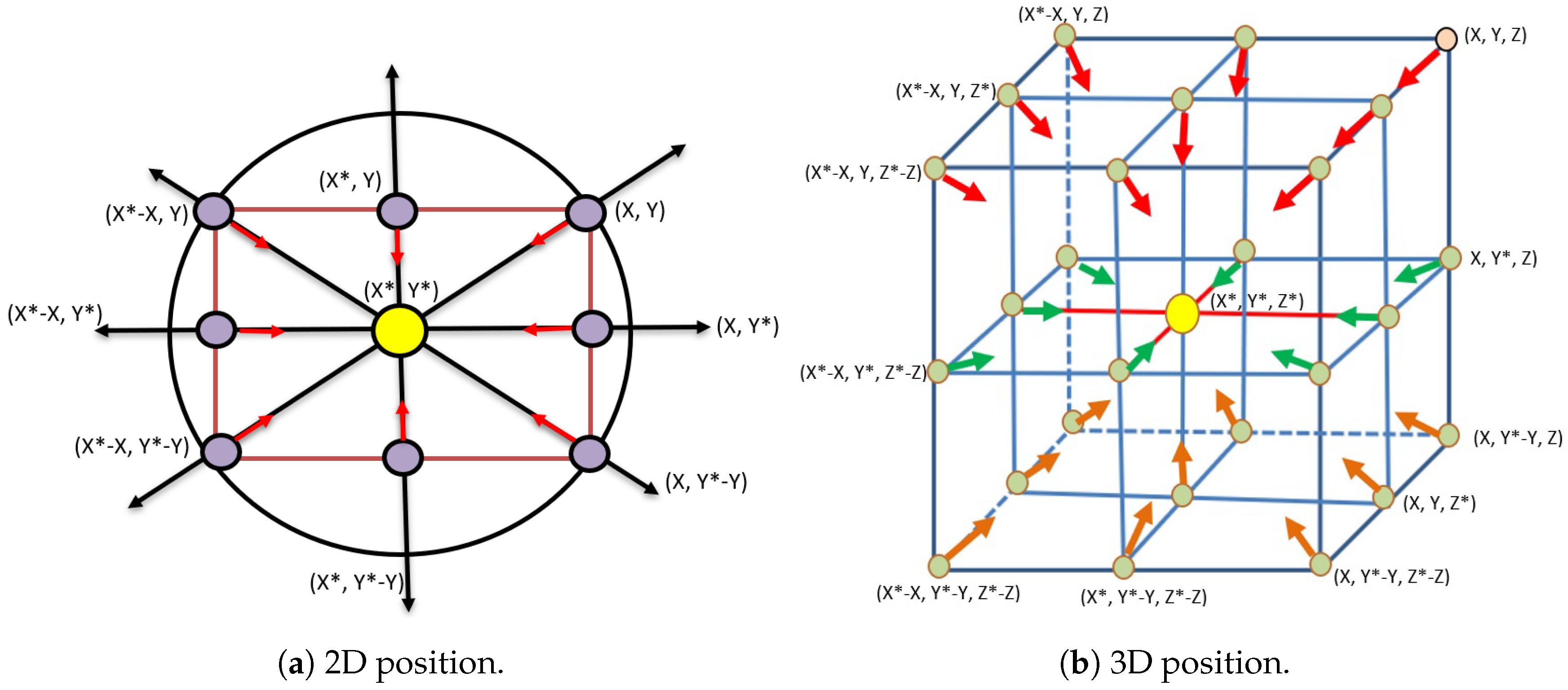
3.2.1. Encircling Prey
The second phase of the WOA is to determine the best solution (whale) based on the fitness function. Each solution is structured as a vector of the decision variables. The rest solutions will update their positions in the search space with respect to the best solution using Equations (
1) and (
2).
where
k presents the current iteration,
presents the best solution so far, and
and
denote specific coefficient vectors estimated based on Equations (
3) and (
4), respectively.
denotes the absolute value, and · is a component-by-component multiplication. Note that the dimension of vectors is equal to the number of variables (features) of the problem being solved.
where
presents a variable with initial value equals 2. This variable will linearly decrease toward 0 after a set of iterations as in Equation (
5).
is a random vector between 0 and 1, which is produced using a uniform distribution. Equations (
1) and (
2) give the WOA the ability to search in n-dimensional solution space (i.e., 2D and 3D) in an efficient manner as shown in
Figure 4.
where
k is the current iteration, while
K is the maximum number of iterations.
3.2.2. Bubble-Net Attacking
Two mathematical models have been proposed to mimic the whale performance while attacking their prays: The shrinking encircling mechanism and Spiral updating position. To update the whales’ position around the best solution in the search space, the shrinking encircling mechanism mimics this process by reducing the value of variable
over the course of generations in a linear manner.
Figure 5 demonstrates the expected positions of whales around the best solution.
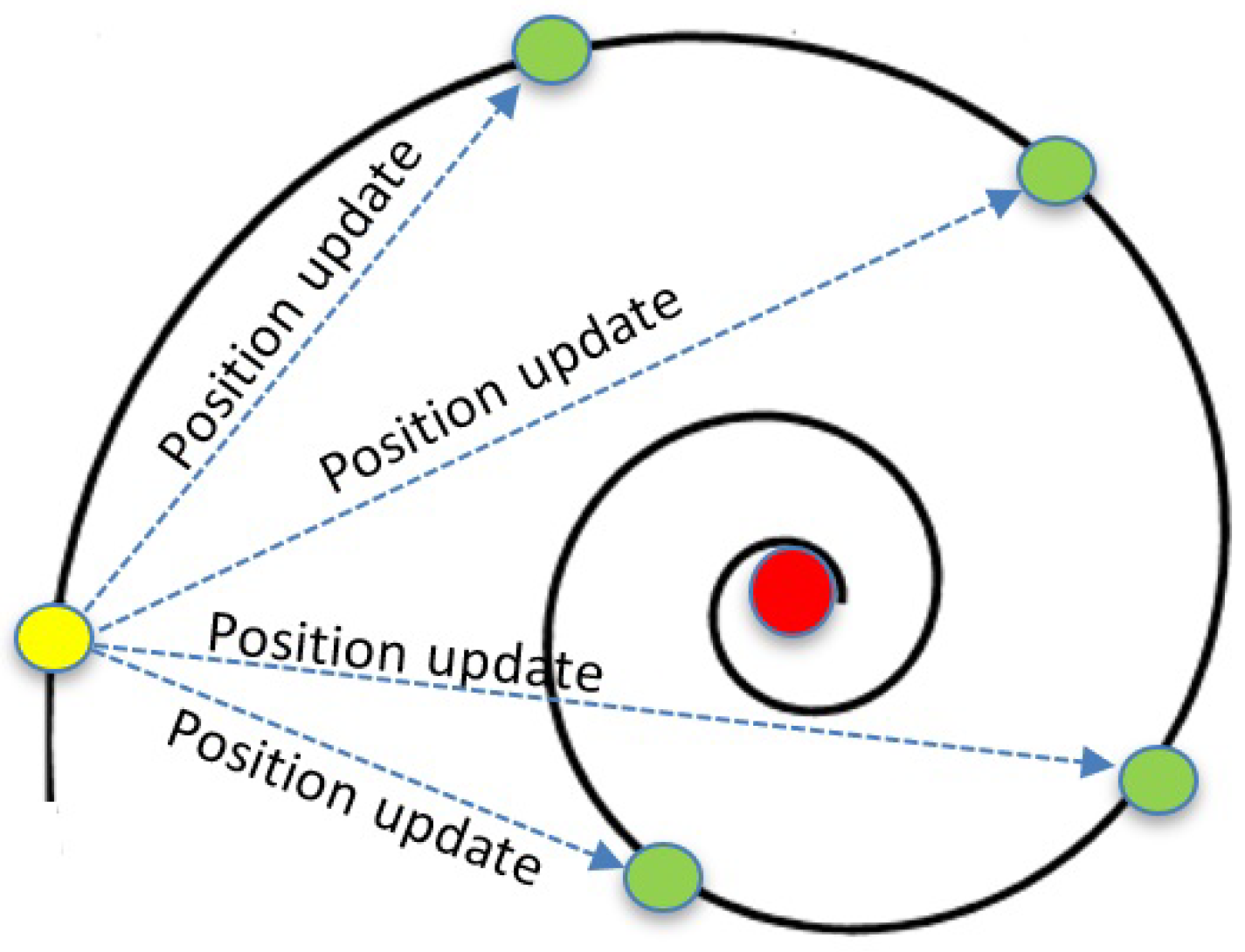
In nature, whales swim in an upward spiral path while hunting their food. To mimic this process, a logarithmic spiral function is used, as shown in Equation (
6).
where
denotes the distance between the
ith solution and the optimal solution found so far, the parameter
b creates the shape of the spiral function and
I is random number between
and 1.
Figure 6 depicts the spiral swimming process for whales while hunting.
To model the shrinking encircling and spiral swimming behaviors, a probability of
is assumed to select between these two behaviors throughout the course of optimization. Each whale selects the operation to be performed randomly based on its location with respect to the optimal solution so far. Equation (
7) explores the operation selection based on a random number
p.
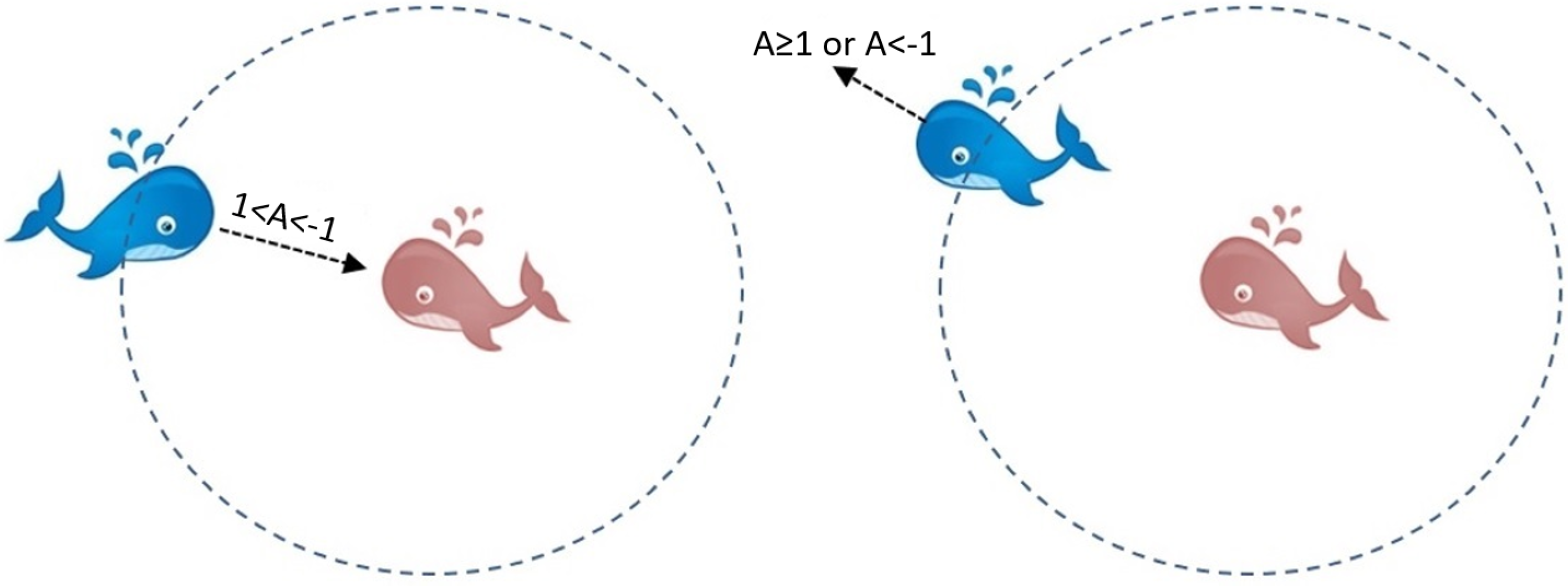
In simple, the exploration phase in WAO occurs once each whale in the population updates its position based on an arbitrarily selected whale. The next position for the whale will be in the area between its current position and the position of a randomly selected. The exploration phase occurs when the variable (A) has a value between −1 and 1 as shown in
Figure 7. The exploitation phase occurs when each whale updates its current position based on the position of the best whale so far, where a linear decreeing of the variable (A). In simple, Equations (
8) and (
9) present the exploration phase of WOA. Finally, the Pseudo-code of WOA is presented in Algorithm 2.
| Algorithm 2 Pseudo-code of WOA. |
Initialize a random population of whales Initialize all coefficients Evaluate all solutions using fitness function Determine the optimal solution so far (denoted as ) while (k < maximum number of iterations) do for each solution (whale) do Update a, A, C, l, and p coefficients. if (p < 0.5) then if then Update the current solution’s position by Eq.( 2). else if then Pick a random solution from the population Update the position of using Eq.( 9) else if (p≥ 0.5) then Update the position of by Eq.( 6) Estimate the fitness value for each in the population. Update return
|
3.3. Logistic Chaotic Map (LCM)
To improve the population diversity and increase the exploratory behaviour of WOA, a logistic chaotic map strategy is employed in this work. The chaotic map strategy is an efficient method to adjust parameter values to improve the exploration process and final solution. Moreover, the chaotic map strategy enhances the convergence speed and the search precision [
73,
74]. A chaotic sequence number is introduced to replace a random number in WAO algorithm (called
p in WOA). The Equation (
10) generates a logistic chaotic sequence number.
where
is a chaotic sequence at iteration
t. The initial value for
is usually
, and the value interval is within [0,1]. The chaotic sequence number is employed to balance between two updating mechanisms (i.e., spiral-path and shrinking-circles path) inside the WOA. As a result, a logistic chaotic map will guarantee that
of the iterations will go for each updating mechanisms.
Chaotic maps are frequently used to improve the performance of optimization algorithms. They are essentially utilized to enhance the convergence behaviors of meta-heuristic optimization algorithms and avoid being stuck into local optima. Chaotic maps are employed in meta-heuristic algorithms to produce chaotic variables instead of random ones. Chaos is a non-linear approach that has deterministic dynamic manners [
74,
75]. It is highly sensitive to its initial state where a large number of sequences can be simply produced by adjusting its initial state [
74,
75]. In addition, chaos has the characteristic of ergodicity and non-repetition. Hence, it can accomplish straightforward and faster searches in contrast with the stochastic searches that basically depend on probability distributions [
76]. Chaotic maps have been used to promote the performance of many optimization algorithms such as particle swarm optimization (PSO) [
74,
77], Artificial bee colony (ABC) [
75], Krill Herd optimization algorithm (KH) [
76] and Bat Algorithm (BA) [
78].
3.4. Sine-Cosine Algorithm
Sine-Cosine algorithm (SCA) is a population-based optimization algorithm that was introduced by Mirjalili in 2016 [
79]. The main idea of SCA is that each solution will update its position with respect to the position of the best solution in the search space using Equations (
11) and (
12).
where
represents the position of the current solution in the
ith dimension at iteration
k.
represents the
ith dimension of the best solution so far,
,
, and
are three random variables, and
indicates the absolute value. To simplify Equations (
11) and (
12), both equations have been combined for final position updating as shown in in Equation (
13).
where the parameter
determines the updating direction, that represents the space between
solution and
solution. The parameter
determines the updating distance between the current solution and the best solution so far. The parameter
, however, balances emphasizing or de-emphasizing the influence of desalination in describing the distance by giving random weights for the best solution
. Finally, the parameter
is used to switch between the sine and cosine components in Equation (
13).
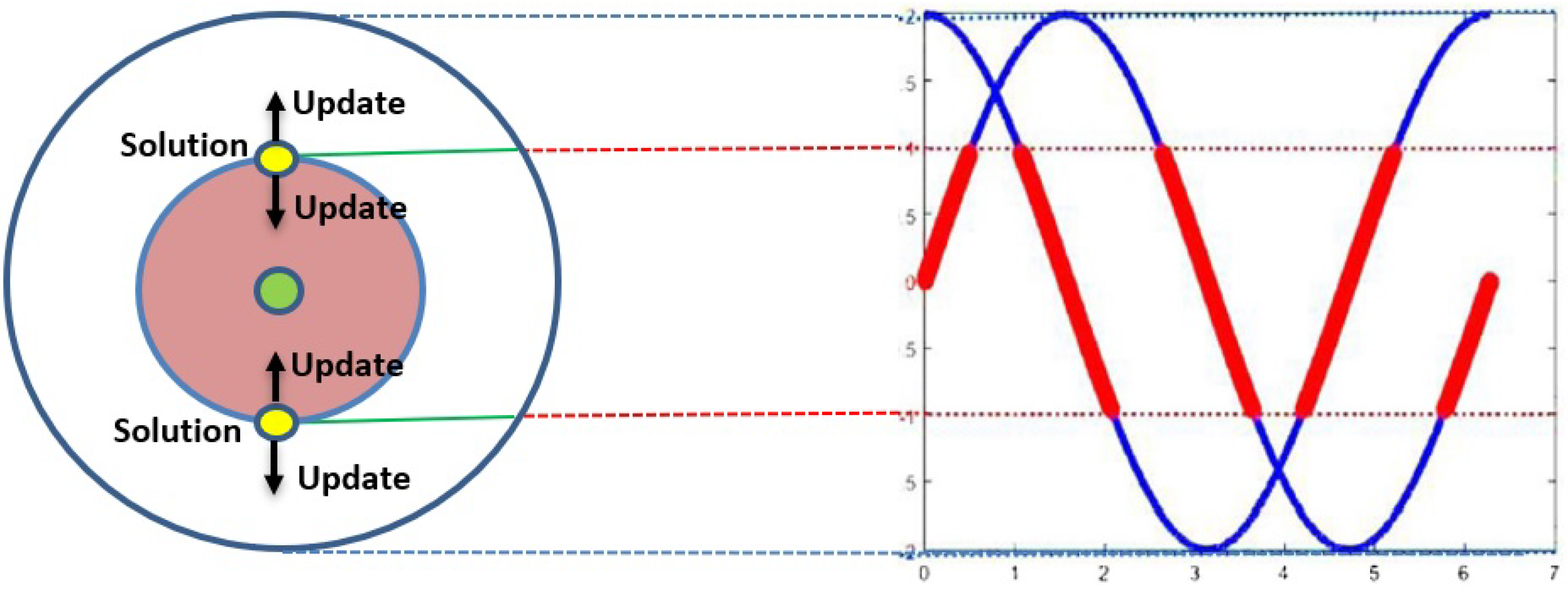
Figure 8 demonstrates the switching mechanism between sine and cosine algorithms with the range in [−2, 2]. The exploration process in SCA is guaranteed in this range, since each solution may update its location outside the feasible search space.
Any metaheuristic algorithm should achieve a proper trade-off between exploration and exploitation processes. In SCA, this balance between exploration and exploitation through optimization is obtained by decreasing the range of sine and cosine, as shown in Equation (
14).
where variables
k and
K represent current, and maximum iterations, respectively.
a is a constant.
Figure 9 explores the way of decreasing the range of the sine and cosine after a set of iterations at
. Algorithm 3 presents the pseudo-code of the SCA algorithm.
| Algorithm 3 Pseudo-code of SCA. |
Initialize a random population of search agents (solutions) (X) Evaluate all solutions by the objective function P= the optimal solution found so far. while () do Update , , and for each search agent in the population do if () then else if () then Estimate the value of objective function for each search agent. Update P k=k+1. returnP
|
3.5. Enhanced Whale Optimization Algorithm
In this subsection, we are using the concepts of the three methods mentioned above (i.e., WOA, SCA, and LCM) to propose a new hybrid algorithm that improves the overall performance of WOA. In the original WOA, the position vector of a whale (solution) is updated in the exploration stage with respect to the position vector of a randomly chosen search agent rather than the optimal search agent discovered so far. As a result, the performance of the exploration process is excellent, while the performance of the exploitation process is weak. This weakness also comes from selecting the updating mechanism (i.e., spiral-path and shrinking-circles path), which is performed randomly. To overcome this weakness, LCM is employed to ensure that of the iterations go for each updating mechanism.
Since SCA benefits from superior exploitation [
79] and the exploration occurs once the obtained value from sine or cosine function is larger than 1 and smaller than −1, we adopted the SCA to enhance the worst half of the population in WAO after each iteration. The worst half of the population is considered as an initial population for SCA. This will improve the exploitation of WOA. Algorithm 4 shows the proposed enhanced WOA (EWOA).
| Algorithm 4 Pseudo-code of EWOA. |
Initialize a random population of whales Initialize all coefficients Evaluate all solutions using fitness function Determine The optimal solution so far (denoted as ) while (k < maximum number of iterations) do for each solution (whale) do Update a, A, C, l, and p coefficients. p= LCM() if (p < 0.5) then if then Update the current solution’s position by Eq.( 2). else if then Pick a random solution from the population Update the position of using Eq.( 9) else if (p≥ 0.5) then Update the position of by Eq.( 7) Estimate the fitness value for each solution (whale) in the population. Apply SCA on worst half of the population. Update return
|
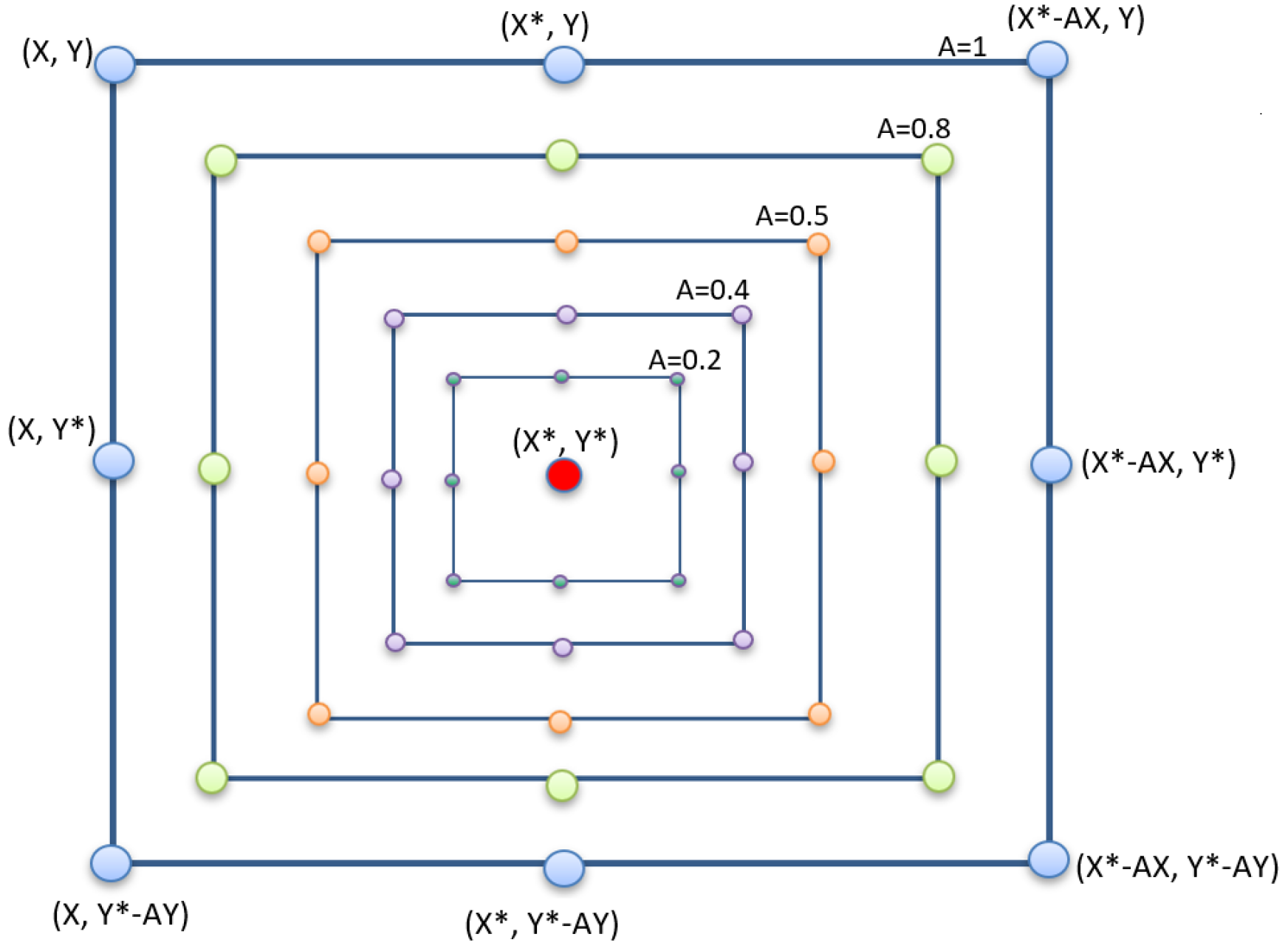
3.6. Transfer Functions to Develop Binary Variant of WOA
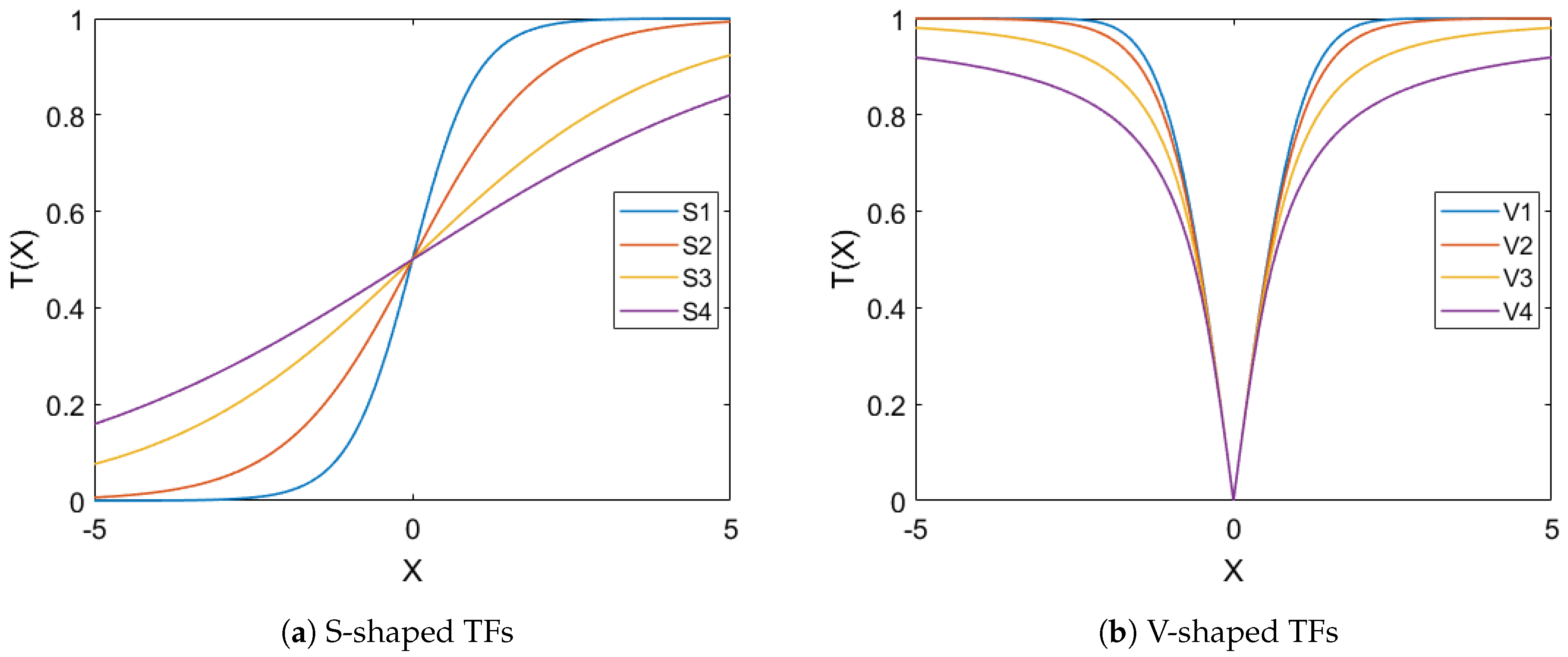
WOA is a continuous search algorithm by nature. Therefore, it is not applicable in its original form to deal with FS which is a binary optimization problem. Accordingly, it is imperative to convert WOA to a binary structure by utilizing a binarization scheme. Transfer Function (TF) is deemed as one of the most frequently applied binarization schemes [
80,
81]. For this purpose, we employed eight different TFs form two well-know groups that are S-shaped and V-shaped [
81] (see
Figure 10) to develop a binary variant of WOA for the FS problem. In the TF-based binarization scheme, two steps are performed. In the first step, a TF function is employed to convert the real-valued solution
into an intermediate normalized solution
within [0,1] such that each element in
I represent the probability of transforming the corresponding element in
into 0 or 1. In the second step, a binarization rule is used to convert the output of TF into binary. In the literature, the most common binarization rules are called standard method given in Equation (
15) and complement method given in Equation (
18). Broadly, The standard rule is used with S-shaped TFs while the complement rule is used with V-shaped TFs [
82].
Considering S2 sigmoid function, the probability of updating the generated real-valued solution of WOA into binary is presented in Equation (
15).
where
is a variable that represents the
jth element of the
ith real-valued solution
X,
k represents the current iteration. The updating process for S-shape group is presented in Equation (
16) for the next iteration.
where
represents the binary value of the corresponding
, and the
is the probability value that is evaluated based on Equation (
15).
The updating process for V-shape for the forthcoming iteration is presented in Equation (
18), which is evaluated based on the probability values that is illustrated in Equation (
17) [
83].
Table 1 explores the mathematical models for S-shape and V-shape TFs functions.
where ∽ is the complement. With the complement binarization rule, the new binary value (
is set considering the current binary solution, that is to say, based on the probability value
, the
jth element is either kept or flipped.
3.7. Whale Optimization Algorithm as a Feature Selection
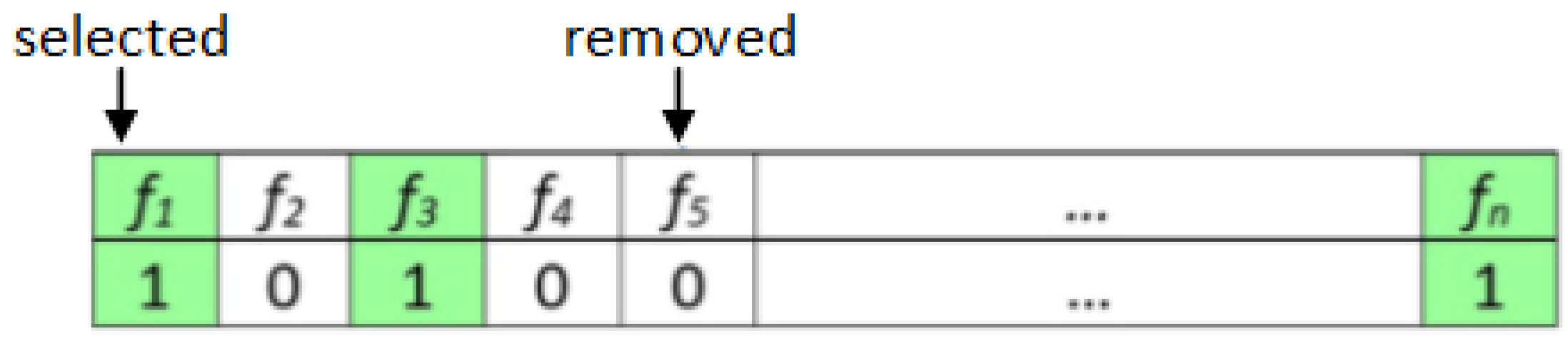
Adapting metaheuristic algorithms to handle any optimization problem requires identifying two fundamental parts, including solution encoding and evaluation (fitness) function. Employing WOA as a binary feature selection algorithm means that the potential solution (i.e., features subset) is is expressed as a binary vector with length
n (see
Figure 11), where
n presents the number of features in the original dataset. Each cell inside the binary vector has either 1 (i.e., selected feature) or 0 (i.e., not selected).
The main objective of the FS process is to find the smallest features subset that leads to achieving the maximum classification accuracy. Accordingly, FS can be defined as a complex multi-objective optimization problem. Aggregation is deemed one of the most common prior procedures where multiple objectives are combined into a single function. Each objective is assigned a weight to decide its significance [
84]. A good ratio between selected features and classification accuracy should be achieved to have a robust FS algorithm. So, the minimization fitness function used in this work is presented in Equation (
19) to assess the appropriateness of the selected subset of features.
where
is the fitness value of the subset
X,
represents the classification error rate for the employed internal classifier using the subset
X.
S refers to the number selected features.
N refers to the total number of features in the original dataset.
[0,1], whereas
are adopted from [
82,
85,
86].
7. Conclusions and Future Works
In this work, an enhanced approach as a wrapper feature selection that combines the Whale Optimization Algorithm (WOA) with Sine Cosine Algorithm (SCA) is introduced. The main idea is to enhance the performance of the WOA exploitation process by improving the worst half in the population based on the SCA algorithm at every iteration. In addition, to enhance the population diversity and increase the exploratory behaviour of WOA, chaotic sequence number generated by logistic chaotic map is employed to balance between two updating mechanisms (i.e., spiral-path and shrinking-circles path) inside the WOA.
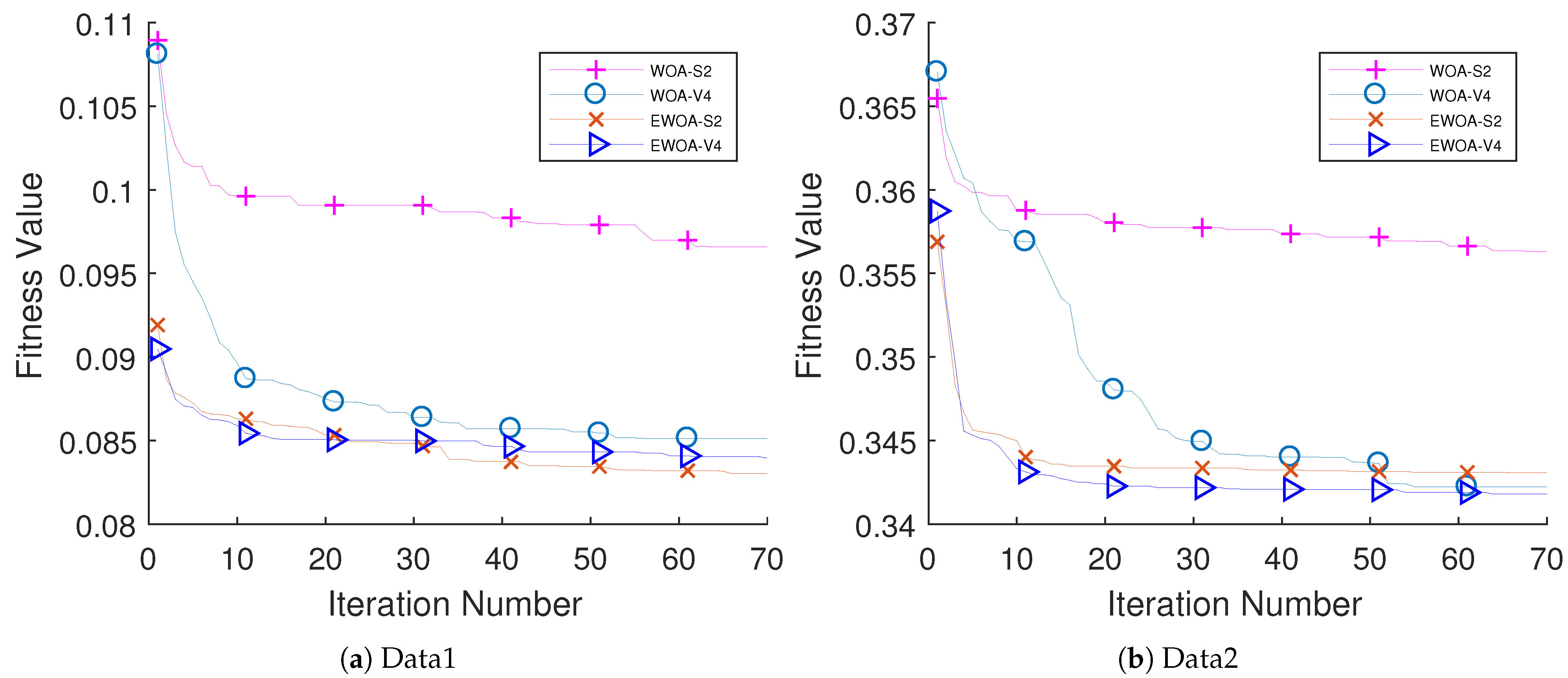
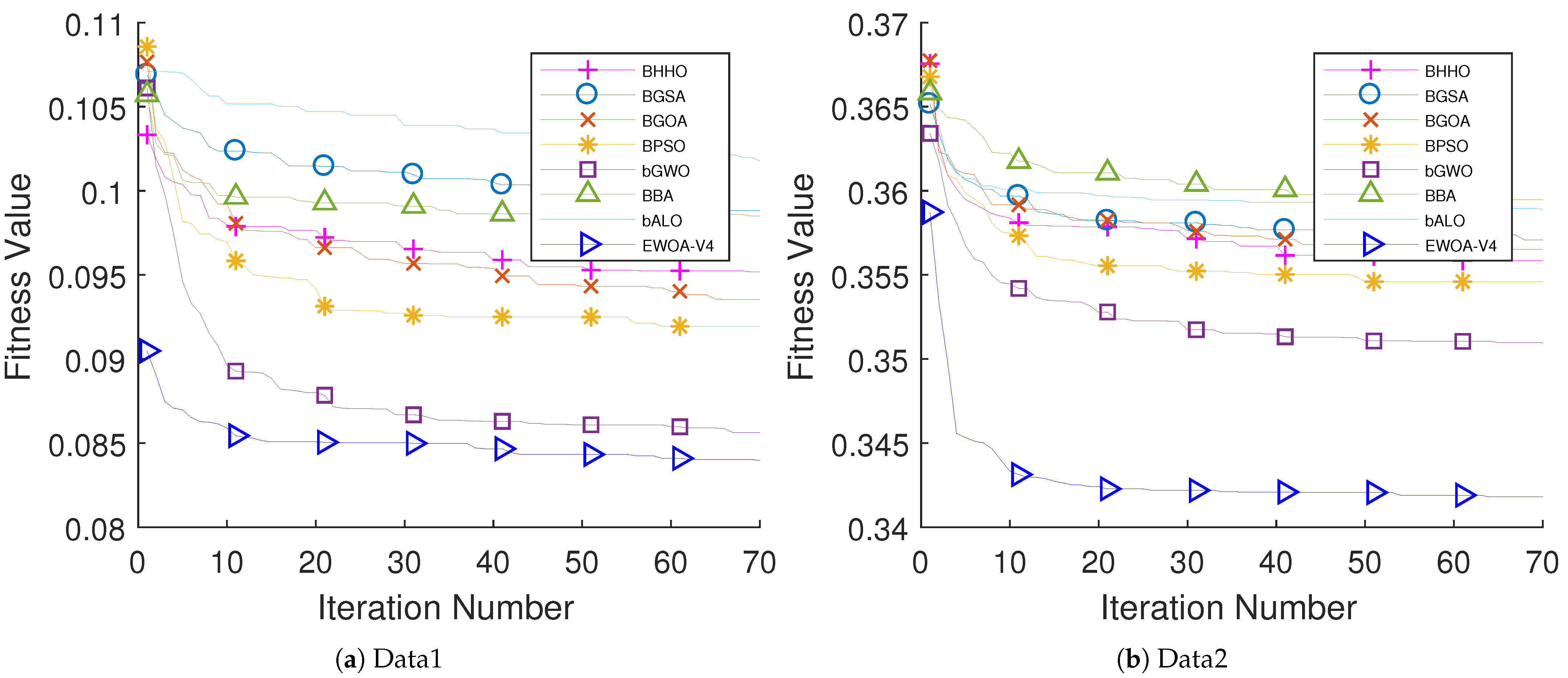
The performance of the proposed algorithm was examined on educational data come from two different schools. Five different classifiers have been examined (i.e., k-NN, DT, LDA, NB, and LB). The performance of LDA outperforms other classifiers with respect to the AUC value. The performance of EWOA with V4 TF (EWOA-V4) shows an outstanding performance compared to other algorithms in the literature.
The limitation of this work is the availability of students’ performance datasets, where few datasets are available for research. Another limitation of this work is that the proposed enhanced WOA has only been tested in the SPP domain. In addition, the parameters of the algorithms were set based on small simulations and common settings in the literature. In future works, we will examine the performance of the proposed approach in multi-objective optimization problems and more complex data such as medical and biological datasets. We will also conduct extensive experiments to determine the most appropriate values of common and internal parameters for the enhanced WOA as well as other utilized algorithms.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















