
A Novel Intrusion Detection Approach Using Machine Learning Ensemble for IoT Environments

 , , ,
, , ,
Abstract
:1. Introduction
- A focus on mobile network appliances such as IoT-enabled platforms for IDSs.
- A machine learning-based binary classifier for identifying network traffic as benign or malicious to provide network security.
- Training, validating, and testing of the model using the random forest and gradient boosting machine (GBM) ensemble approach with a hyperparameter optimizer using the ‘CSE-CIC-IDS2018-V2’ dataset and demonstrating the performance test with attack categories like infiltration, SQL injection, etc.
2. Literature Review
2.1. Machine Learning Enabled Intrusion Detection for IoT Appliances
2.1.1. Intrusion Detection System
2.1.2. CSE-CIC-IDS2018-V2 Dataset
2.1.3. IoT-Enabled Networks
2.2. Classification Algorithm
2.2.1. Ensemble Classifiers
2.2.2. Gradient Boosting Machine (GBM)
2.2.3. Random Forest
3. Proposed Work
3.1. Data Preparation
3.1.1. Data Integration
3.1.2. Data Cleaning
3.1.3. Data Transformation
3.1.4. Data Normalization Utilizing Feature Scaling
3.2. Undersampling
3.3. Feature Selection
3.4. Target Grouping
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Metrics and Method of Model Evaluation and Validation
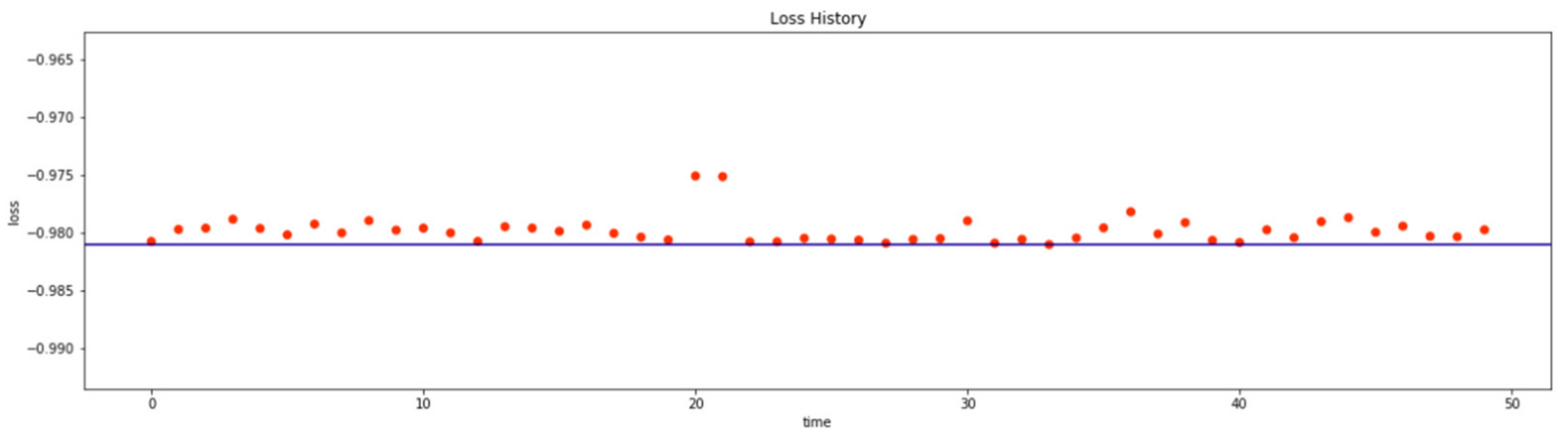
4.3. Hyperparameter Optimization for the Random Forest Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Choo, K.-K.R. The cyber threat landscape: Challenges and future research directions. Comput. Secur. 2011, 30, 719–731. [Google Scholar] [CrossRef]
- Gaikwad, D.P.; Thool, R.C. Intrusion detection system using bagging with partial decision treebase classifier. Procedia Comput. Sci. 2015, 49, 92–98. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.-C.; Ke, S.-W.; Tsai, C.-F. CANN: An intrusion detection system based on combining cluster centers and nearest neighbors. Knowl.-Based Syst. 2015, 78, 13–21. [Google Scholar] [CrossRef]
- Tran, N.N.; Sarker, R.; Hu, J. An approach for host-based intrusion detection system design using convolutional neural network. In Proceedings of the International Conference on Mobile Networks and Management, Melbourne, Australia, 13–15 December 2017; pp. 116–126. [Google Scholar]
- Denning, D. An intrusion detection system. In Proceedings of the Symposium on Security and Privacy, Oakland, CA, USA, 7–9 April 1986; IEEE Computer Society Press: Los Alamitos, CA, USA, 1986; pp. 118–131. [Google Scholar]
- Camastra, F.; Ciaramella, A.; Staiano, A. Machine learning and soft computing for ICT security: An overview of current trends. J. Ambient Intell. Humaniz. Comput. 2013, 4, 235–247. [Google Scholar] [CrossRef]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Liao, H.-J.; Lin, C.-H.R.; Lin, Y.-C.; Tung, K.-Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Modi, C.; Patel, D.; Borisaniya, B.; Patel, H.; Patel, A.; Rajarajan, M. A survey of intrusion detection techniques in cloud. J. Netw. Comput. Appl. 2013, 36, 42–57. [Google Scholar] [CrossRef]
- Besharati, E.; Naderan, M.; Namjoo, E. LR-HIDS: Logistic regression host-based intrusion detection system for cloud environments. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3669–3692. [Google Scholar] [CrossRef]
- Gope, P.; Sikdar, B.; Millwood, O. A Scalable Protocol Level Approach to Prevent Machine Learning Attacks on PUF-based Authentication Mechanisms for Internet-of-Medical-Things. IEEE Trans. Ind. Inform. 2021. [Google Scholar] [CrossRef]
- Kasinathan, P.; Pastrone, C.; Spirito, M.A.; Vinkovits, M. Denial-of-Service detection in 6LoWPAN based Internet of Things. In Proceedings of the 2013 IEEE 9th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Lyon, France, 7–9 October 2013; pp. 600–607. [Google Scholar]
- Suricata, I.D.S. Open-Source IDS/IPS/NSM Engine. 2014. Available online: https://cybersecurity.att.com/blogs/security-essentials/open-source-intrusion-detection-tools-a-quick-overview (accessed on 15 October 2021).
- Lee, T.-H.; Wen, C.-H.; Chang, L.-H.; Chiang, H.-S.; Hsieh, M.-C. A lightweight intrusion detection scheme based on energy consumption analysis in 6LowPAN. In Advanced Technologies, Embedded and Multimedia for Human-Centric Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1205–1213. [Google Scholar]
- Sonar, K.; Upadhyay, H. An approach to secure internet of things against DDoS. In Proceedings of the International Conference on ICT for Sustainable Development, Ahmedabad, India, 3–4 July 2015; Springer: Singapore, 2016; pp. 367–376. [Google Scholar]
- Dunkels, A.; Gronvall, B.; Voigt, T. Contiki-a lightweight and flexible operating system for tiny networked sensors. In Proceedings of the 29th Annual IEEE International Conference on Local Computer Networks, Tampa, FL, USA, 16–18 November 2004; pp. 455–462. [Google Scholar]
- Tama, B.A.; Rhee, K.-H. An in-depth experimental study of anomaly detection using gradient boosted machine. Neural Comput. Appl. 2019, 31, 955–965. [Google Scholar] [CrossRef]
- Primartha, R.; Tama, B.A. Anomaly detection using random forest: A performance revisited. In Proceedings of the 2017 International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar]
- Douglas, P.K.; Harris, S.; Yuille, A.; Cohen, M.S. Performance comparison of machine learning algorithms and number of independent components used in fMRI decoding of belief vs. disbelief. Neuroimage 2011, 56, 544–553. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Misra, S.; Krishna, P.V.; Agarwal, H.; Saxena, A.; Obaidat, M.S. A learning automata based solution for preventing distributed denial of service in internet of things. In Proceedings of the 2011 International Conference on Internet of Things and 4th International Conference on Cyber, Physical and Social Computing, Dalian, China, 19–22 October 2011; pp. 114–122. [Google Scholar]
- Li, J.; Lyu, L.; Liu, X.; Zhang, X.; Lv, X. FLEAM: A federated learning empowered architecture to mitigate DDoS in industrial IoT. IEEE Trans. Ind. Inform. 2021. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Funchal, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. Adv. Neural Inf. Process. Syst. 2013, 26, 431–439. [Google Scholar]
- Nour, M.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Smirti, D.; Pujari, M.; Sun, W. A Comparative Study on Contemporary Intrusion Detection Datasets for Machine Learning Research. In Proceedings of the 2020 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 9–10 November 2020; pp. 1–6. [Google Scholar]
- Mohanad, S.; Layeghy, S.; Moustafa, N.; Portmann, M. Towards a standard feature set of nids datasets. arXiv 2021, arXiv:2101.11315. [Google Scholar]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble methods in machine learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Undercofer, J. Intrusion Detection: Modeling System State to Detect and Classify Aberrant Behavior. 2004. Available online: https://ebiquity.umbc.edu/person/html/J./Undercofer (accessed on 15 October 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ting, K.M. Sensitivity and Specificity. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Gaba, G.S.; Kumar, G.; Kim, T.-H.; Monga, H.; Kumar, P. Secure device-to-device communications for 5g enabled internet of things applications. Comput. Commun. 2021, 169, 114–128. [Google Scholar] [CrossRef]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Gaba, G.S.; Kumar, G.; Monga, H.; Kim, T.-H.; Liyanage, M.; Kumar, P. Robust and lightweight key exchange (lke) protocol for industry 4.0. IEEE Access 2020, 8, 132808–132824. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 115–123. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intrusion detection prone area | Based on dedicated host Based on dedicated network Based on remote accessibility Based on analytics of network behavior |
| Methodologies of intrusion detection | Based on authorized signature values Based on data pattern irregularity or anomaly Based on analytics of stateful protocols |
| Author | Attacks Coverage | Dataset | Methodology | Performance Metric |
|---|---|---|---|---|
| Gope et al. [11] | Man-in-middle, replay, DoS, security-against-any-learner, tracking, scalability | - | Physically unclonable function (PUF), registration, and authentication | - |
| Li et al. [22] | DDoS, bot, attacker-centric mitigation | UNSW NB15 dataset | FLEAM architecture | Mitigation response time; detection accuracy |
| Sonar and Upadhyay [15] | DoS, DDoS, volumetric flooding attack | - | Attack recover algorithm along with traditional Grey List and Black List | Packet delivery ratio |
| Lee et al. [14] | DoS, wormhole, selective forwarding | - | 6LoWPAN Jammer | Energy consumption |
| Class | UNSW-NB15 | ToN-IoT | BoT-IoT | CSE-CIC-IDS2018 |
|---|---|---|---|---|
| Benign | 1,550,712 | 270,279 | 13,859 | 7,373,198 |
| DoS | 5051 | 17,717 | 56,833 | 269,361 |
| DDoS | 0 | 326,345 | 56,844 | 380,096 |
| Web Attacks | 0 | 0 | 0 | 4394 |
| Infiltration | 0 | 0 | 0 | 62,072 |
| Brute Force | 0 | 0 | 0 | 287,597 |
| Bot | 0 | 0 | 0 | 15,683 |
| Training Labels | Validation Labels | Test Labels | |
|---|---|---|---|
| Infiltration | 129,547 | 16,193 | 16,194 |
| SQL Injection | 70 | 9 | 8 |
| Brute Force-Web | 489 | 61 | 61 |
| Brute Force-XSS | 184 | 23 | 23 |
| DoS Slowloris Attacks | 8792 | 1099 | 1099 |
| Benign | 10,787,766 | 1,348,471 | 1,348,471 |
| Bot | 228,953 | 28,619 | 28,619 |
| DDOS-HOIC Attacks | 548,809 | 68,601 | 68,602 |
| DDoS-LOIC-HTTP Attacks | 460,953 | 57,619 | 57,619 |
| Parameter Description | Parameter Identifier | Hyperparameter Search Space Training | Hyperparameter Search Space Result |
|---|---|---|---|
| Number of tree estimators | (n_estimators) | Uniform integer space in the interval of [10, 100]. | The optimal number of tree estimators seems to be in the interval of [60, 100]. |
| Information gain criterion | (criterion) | Choice of Gini or entropy. | The entropy criterion yields a better performance than the Gini criterion in our search run. |
| Maximum depth of a single tree | (max_depth) | Uniform integer space in the interval of [10, 100] or None resulting in an unbounded tree. | Restricting the depth of the trees seems to perform better than using unrestricted trees. A value in the interval of [20, 50] for the maximum tree depth yields a good performance. |
| Maximum features for the best split | (max_features) | Choice of sqrt or log2. | The sqrt option seems to perform better than log2. |
| Minimum samples to split a node | (min_samples_split) | Uniform integer space in the interval of [1, 10]. | The optimal number of minimum samples to split a node is in the interval of [4, 6]. |
| Minimum samples at a leaf node | (min_samples_leaf) | Uniform integer space in the interval of [2, 10]. | Given our search run, there is no conclusive best option for the minimum numbers of samples in a leaf node. However, the values {3, 6, 7, 8} seem to perform well. |
| Precision | Recall | f1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.991 | 0.993 | 0.992 | 1,348,471 |
| 1 | 0.967 | 0.955 | 0.961 | 274,823 |
| Accuracy | 0.987 | 1,623,294 | ||
| Macro avg | 0.979 | 0.974 | 0.977 | 1,623,294 |
| Weighted avg | 0.987 | 0.987 | 0.987 | 1,623,294 |
| Misclassified | Total | Percent_Misclassified | |
|---|---|---|---|
| Infiltration | 12,252 | 16,193 | 0.756623 |
| SQL Injection | 1 | 9 | 0.111111 |
| Brute Force–Web | 4 | 61 | 0.065574 |
| Brute Force–XSS | 1 | 23 | 0.043478 |
| DoS attacks-Slowloris | 8 | 1099 | 0.007279 |
| Benign | 8820 | 1,348,471 | 0.006541 |
| Bot | 17 | 28,619 | 0.000594 |
| DDOS attack-HOIC | 22 | 68,601 | 0.000321 |
| DDoS attacks-LOIC-HTTP | 17 | 57,619 | 0.000295 |
| Parameter Description | Parameter Identifier | Hyperparameter Search Space Training | Hyperparameter Search Space Result |
|---|---|---|---|
| Maximum number of trees | (nr_iterations) | Uniform integer space in the interval of [100, 2000]. | A value in the interval of [1600, 1900] seems to perform best. |
| Maximum depth of a tree | (depth) | Uniform integer space in the interval of [4, 10]. | The optimal value for the maximum dept of trees is 10 in all best performing cases. This suggests that another round of hyperparameter search with a higher value might yield a better result. |
| L2 regularization coefficient | (l2_leaf_reg) | Uniform space in the interval of [1, 10]. | A value in the interval of [2, 6] yields good results. |
| Number of splits for numerical features | (border_count) | A choice of 128 and 254. | A border count of 254 was chosen for all the best models. |
| Amount of randomness used for scoring splits | (random_strength) | Uniform integer space in the interval of [0, 5]. | The optimal value seems to be in the interval of [3, 5]. |
| Precision | Recall | f1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.991 | 0.993 | 0.992 | 1,348,471 |
| 1 | 0.964 | 0.957 | 0.961 | 274,823 |
| Accuracy | 0.987 | 1,623,294 | ||
| Macro avg. | 0.978 | 0.975 | 0.976 | 1,623,294 |
| Weighted avg. | 0.987 | 0.987 | 0.987 | 1,623,294 |
| Misclassified | Total | Percent_Misclassified | |
|---|---|---|---|
| Infiltration | 11,690 | 16,193 | 0.721917 |
| SQL Injection | 1 | 9 | 0.111111 |
| Brute Force-XSS | 1 | 23 | 0.043478 |
| Brute Force-Web | 2 | 61 | 0.032787 |
| Benign | 9784 | 1,348,471 | 0.007256 |
| DoS-Slowloris Attacks | 6 | 1099 | 0.00546 |
| Bot | 35 | 28,619 | 0.001223 |
| DDoS-LOIC-HTTP Attacks | 13 | 57,619 | 0.000226 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verma, P.; Dumka, A.; Singh, R.; Ashok, A.; Gehlot, A.; Malik, P.K.; Gaba, G.S.; Hedabou, M. A Novel Intrusion Detection Approach Using Machine Learning Ensemble for IoT Environments. Appl. Sci. 2021, 11, 10268. https://doi.org/10.3390/app112110268
Verma P, Dumka A, Singh R, Ashok A, Gehlot A, Malik PK, Gaba GS, Hedabou M. A Novel Intrusion Detection Approach Using Machine Learning Ensemble for IoT Environments. Applied Sciences. 2021; 11(21):10268. https://doi.org/10.3390/app112110268
Chicago/Turabian StyleVerma, Parag, Ankur Dumka, Rajesh Singh, Alaknanda Ashok, Anita Gehlot, Praveen Kumar Malik, Gurjot Singh Gaba, and Mustapha Hedabou. 2021. "A Novel Intrusion Detection Approach Using Machine Learning Ensemble for IoT Environments" Applied Sciences 11, no. 21: 10268. https://doi.org/10.3390/app112110268
APA StyleVerma, P., Dumka, A., Singh, R., Ashok, A., Gehlot, A., Malik, P. K., Gaba, G. S., & Hedabou, M. (2021). A Novel Intrusion Detection Approach Using Machine Learning Ensemble for IoT Environments. Applied Sciences, 11(21), 10268. https://doi.org/10.3390/app112110268