1. Introduction
We show an interesting result of the application of a modified neural architecture search (NAS) in [
1] to linguistic tasks (grammaticality judgment) for Korean and English syntactic phenomena. Based on the previous research on this subject in [
2], we show that the extension of the NAS method to English grammatical tasks provides a different architecture from the one generated for the Korean dataset. This is rather unexpected given the similarity of the input data. The major contribution of this paper is to show that the previous application of NAS to linguistically complex datasets of Korean [
2] can be extended to the linguistic phenomena of English. Notably, the different resulting architecture in these two experiments clearly indicates that the NAS method is sensitive to the different word order that contains multiple syntactic operations. The scientific purpose of this paper is to develop language models using NAS.
Deep learning has been applied successfully in various fields due to its powerful performance on difficult problems and pattern findings [
3,
4], such as image recognition [
5,
6] and natural language processing (NLP) [
7,
8]. Importantly, the application of deep learning methods to the field of psycholinguistics has been successful [
9]. As noted in the literature, the understanding of psycholinguistics in terms of the deep learning method may show how languages can be processed computationally. NAS aims to automate the architecture engineering, which can be applied to various fields [
10,
11,
12]. Although all the designs can be created manually, researchers have suggested an automated design process that can be efficient in various applications. NAS methods have shown successful results in various fields of studies, such as including image classification [
13,
14], object detection [
15], or semantic segmentation [
16]. The upshot of this is to reduce errors [
17] that could happen when we design architecture manually and make the automation to search for the best-performing learning algorithm [
18].
However, we take a different perspective on the application of NAS to the linguistic phenomenon. The main goal of this paper is to explore the resulting architecture out of NAS application in various linguistic data that contain different syntactic operations. The previous research of NAS application to linguistic data focused on the improvement of accuracy compared to existing language models [
19]. However, as they noted in the article, the research is somewhat limited as NAS does not provide a better language model. In this experiment, we will compare the resulting architecture of the Korean grammaticality judgment dataset to the architecture of the English grammaticality judgement dataset. Given that Korean and English have very different linguistic properties, we predict that NAS will generate different architecture that is fitting to each dataset, presented out.
In our previous research [
2] on Korean grammatical tasks, we applied the NAS method to word order patterns found in Korean. Word order patterns of Korean involve operations called ellipsis and scrambling, which add complexity to the dataset [
20]. A lot of deep learning studies have proven that the word order tasks can be performed without any explicit syntactic information [
21]. However, their research is somewhat limited in that they focus on the accuracy of a specific model. Given that the syntactic information may not be necessary for the deep learning task, the improved accuracy of a specific model does not guarantee that the language model is better.
The application of NAS method to Korean grammaticality patterns involving scrambling (1) and ellipsis (2) provides an architecture which was discussed in our previous paper [
2], which we will discuss in detail in
Section 2.
- (1)
| a. John-i | Mary-lul | coahanta |
| John-subject | Mary-object | like |
| ‘John likes Mary’ |
| b. Mary-lul | Johin-i | coahanta |
| Mary-object | John-subject | like |
| ‘John likes Mary’ |
- (2)
a. (John-i) | Mary-lul | coahanta |
| b. John-i | (Mary-lul) | coahanta |
c. (John-i) | (Mary-lul) | coahanta |
As we noted in the paper, the two linguistic phenomena in Korean add complexity to the dataset: (i) scrambling, which allows different ordering patterns of inputs (1) [
22], and (ii) argument ellipsis which involves invisible element in their sentence (2). Note here that these two operations are not available for English. NAS has provided a model that successfully learns the grammaticality of the Korean dataset.
This paper extends the NAS application to English data patterns. We applied the NAS method with the English dataset that has different grammatical properties from Korean. For example, English allows so-called verb fronting, which puts the verb in front of other items, as shown in (3) [
23].
- (3)
pass one now he has.
In this paper, we report that the application of NAS into Korean and English grammaticality tasks yields two different resulting architectures. To our knowledge, the finding sheds new light on the research of language modeling since the automation of architecture is sensitive to the grammatical information underlying the word order of languages.
The organization of this paper is as follows: in
Section 2 we briefly review the results of the previous research [
1]. In
Section 3 we show the methodology. We show the result of the experiment in
Section 4. Finally,
Section 5 concludes this paper.
3. NAS Method to English Grammaticality Judgement
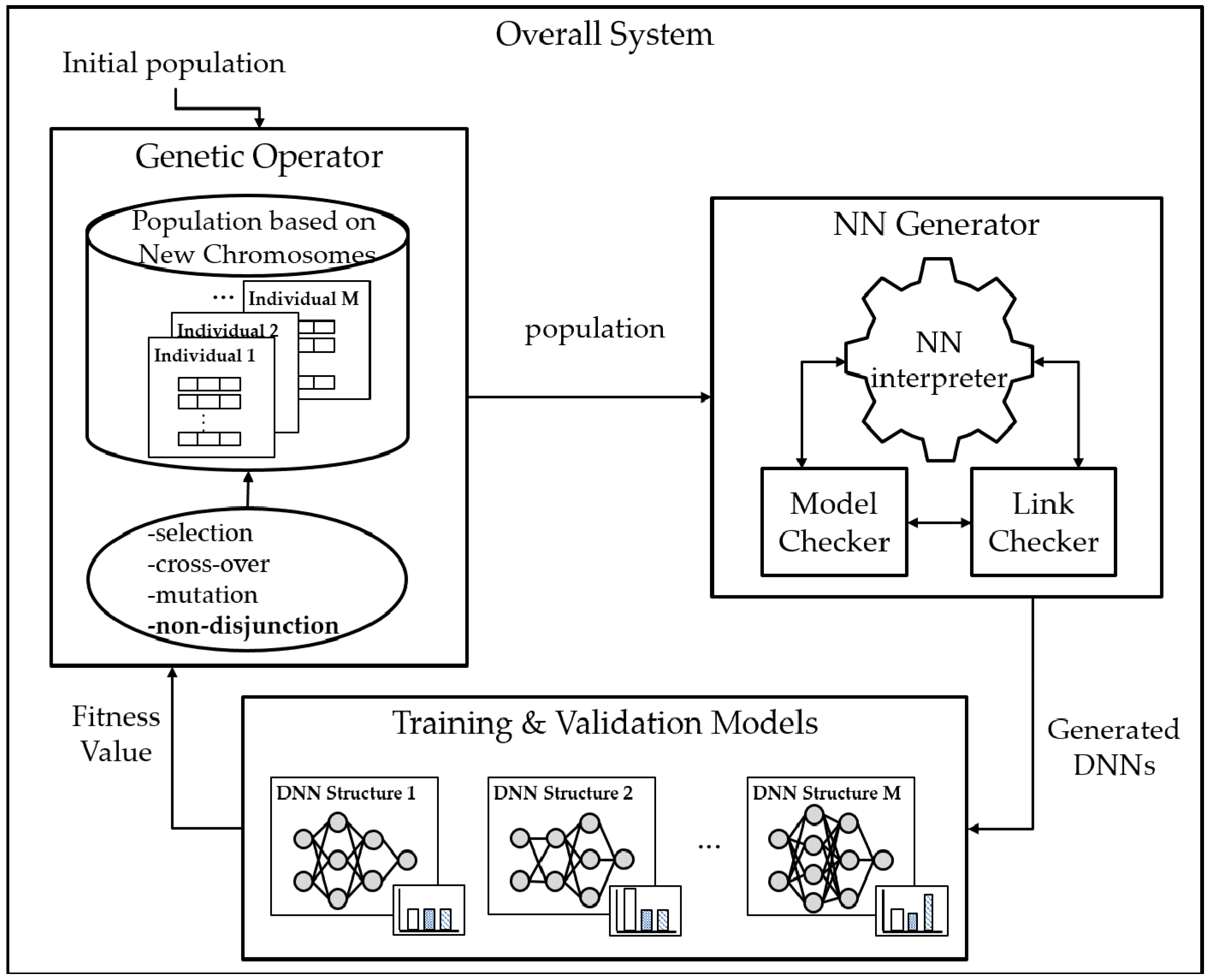
We replicated the experiment of the previous research [
2] to the English dataset. As mentioned before, the particular method is called VCGA. It is shown in
Figure 3. Since the main goal of this paper is to compare the resulting architecture between Korean and English, a shortened introduction of the method is provided. We refer readers to [
2] for a more detailed discussion of the method. As mentioned before, the upshot of VCGA is to involve destructive searching [
1]. The operation by the chromosome non-disjunction allows multiple generations of ANN architectures. Due to its property, the final result is identical regardless of the initial status of the input structure. This method consists of three phases; in the first phase, NN generator design NN based on chromosomes through model checker and link checker; in phase 2 generated NNs are trained and validated with the inputted dataset; in phase 3 genetic operators select individuals to survive and make offspring based on survived individuals as parents. More details of this method are expressed in previous papers [
1,
2]. The group of generators including a genetic algorithm generator and neural networks generators ensures the following properties: (i) a cross-over operation blending information of a parent for various offspring (ii) a mutation operation; and (iii) a non-disjunction operation [
1] making the distinction between the two offspring by less or more information. These operators change hyperparameters such as composition of layers, linkage, the number of nodes, activation function, etc. [
1].
In order to apply this method to the English case, we form a dataset which consists of English grammatical tasks with four words. The data are expressed as a combination of some digits, according to their grammatical categories (1: Noun; 2: Verb; 3: Adjectives; etc.). For example, the sentence ‘John likes beautiful Mary’ is expressed as ‘1, 2, 3, 1’ As such, the grammatical and non-grammatical sentences of all cases are expressed in digits.
We labeled this dataset based on whether they are grammatical or non-grammatical. We used this dataset as inputs of the NAS algorithm, similar to previous research [
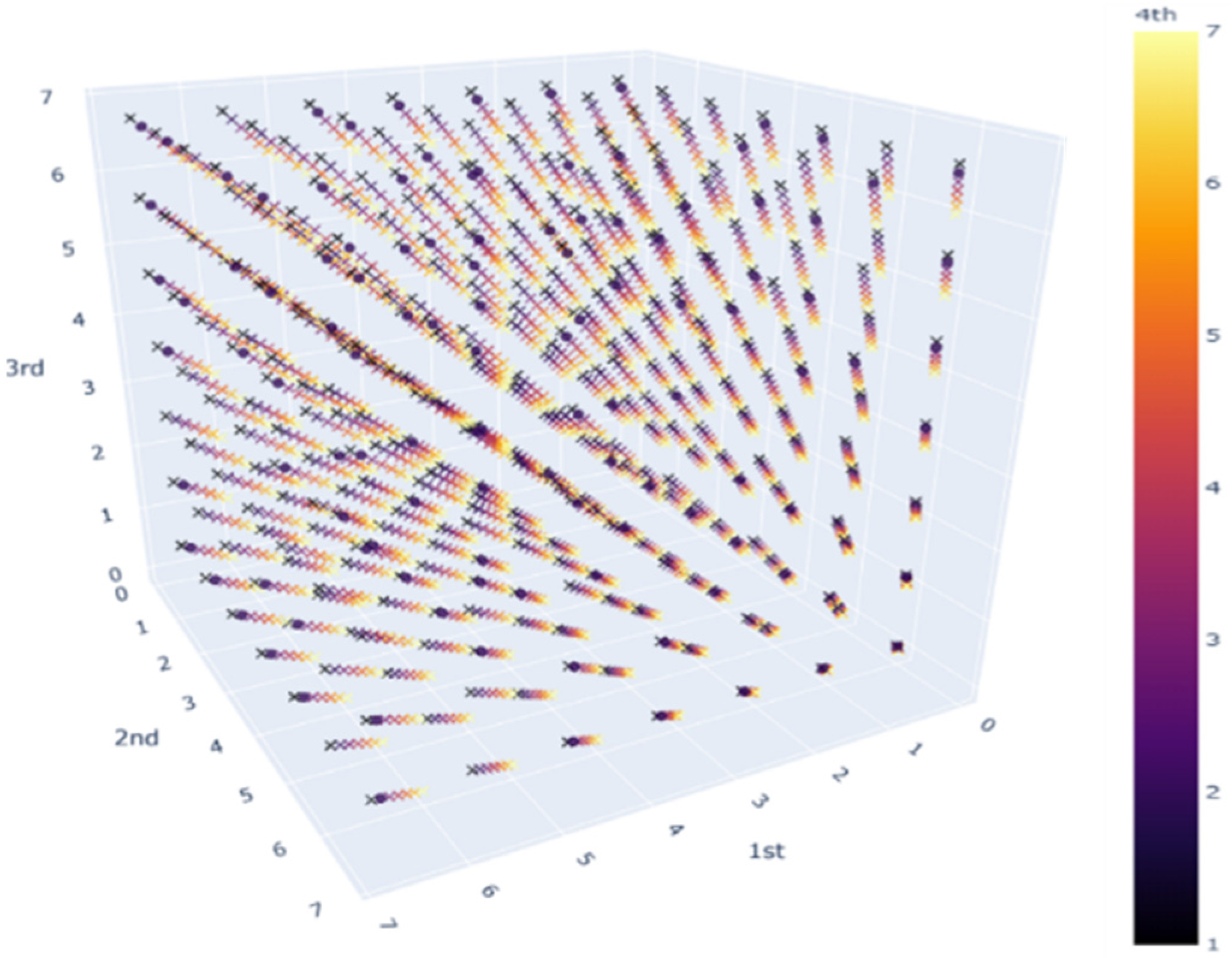
2]. We intentionally created a similar dataset in order to compare the resulting structure between Korean and English. The data consist of seven syntactic categories for four-word level sentences. We have obtained 2401 combinations of syntactic categories, and we consulted the grammaticality of the sentences with three linguistically trained native speakers of English. We plan to share the database upon the publication of this paper. The distribution of the grammaticality of the English dataset is given in
Figure 4, and the data are treated as training data for the NAS, and it is tuned to generate a neural architecture for grammaticality judgment of the English dataset.
4. Experiment
4.1. English Grammaticality Judgement
The basic structure of the experiment is identical to the previous experiment on Korean. The main goal behind this design is to compare the resulting structures of NAS application on Korean and English grammaticality judgement tasks. In this experiment, we have created four-word level sentences with seven syntactic categories: noun, verb, preposition, adjective, adverbs, complementizer, and auxiliary phrases.
The grammar of English is radically different from that of Korean [
27]. However, the different grammar is only expressed on the linear order of the word inputs. Thus on the input level it seems very similar as the only difference here is the number of the correct sentences by different combinations of syntactic categories.
In detail, the verbs in Korean must come at the end of the sentence, whereas English allows the verb to appear with a major degree of placement [
28]. The dataset in question consists of 2401 combinations, where 136 sentences are grammatical. The dataset was consulted with two linguists who are native English speakers. In comparison to the Korean dataset, the overlapping cases were 53. The first slot of four words is expressed in the X-axis, and Y and Z, respectively, represent the second and the third slot. The fourth word slot is represented by the color spectrum. The O/X represents grammaticality.
Figure 4 shows the distribution of the English grammaticality dataset.
We used a fitness function to determine the next generation on the genetic algorithm. Fitness function (Equation (1)) is defined as follows:
4.2. Experiment Setups
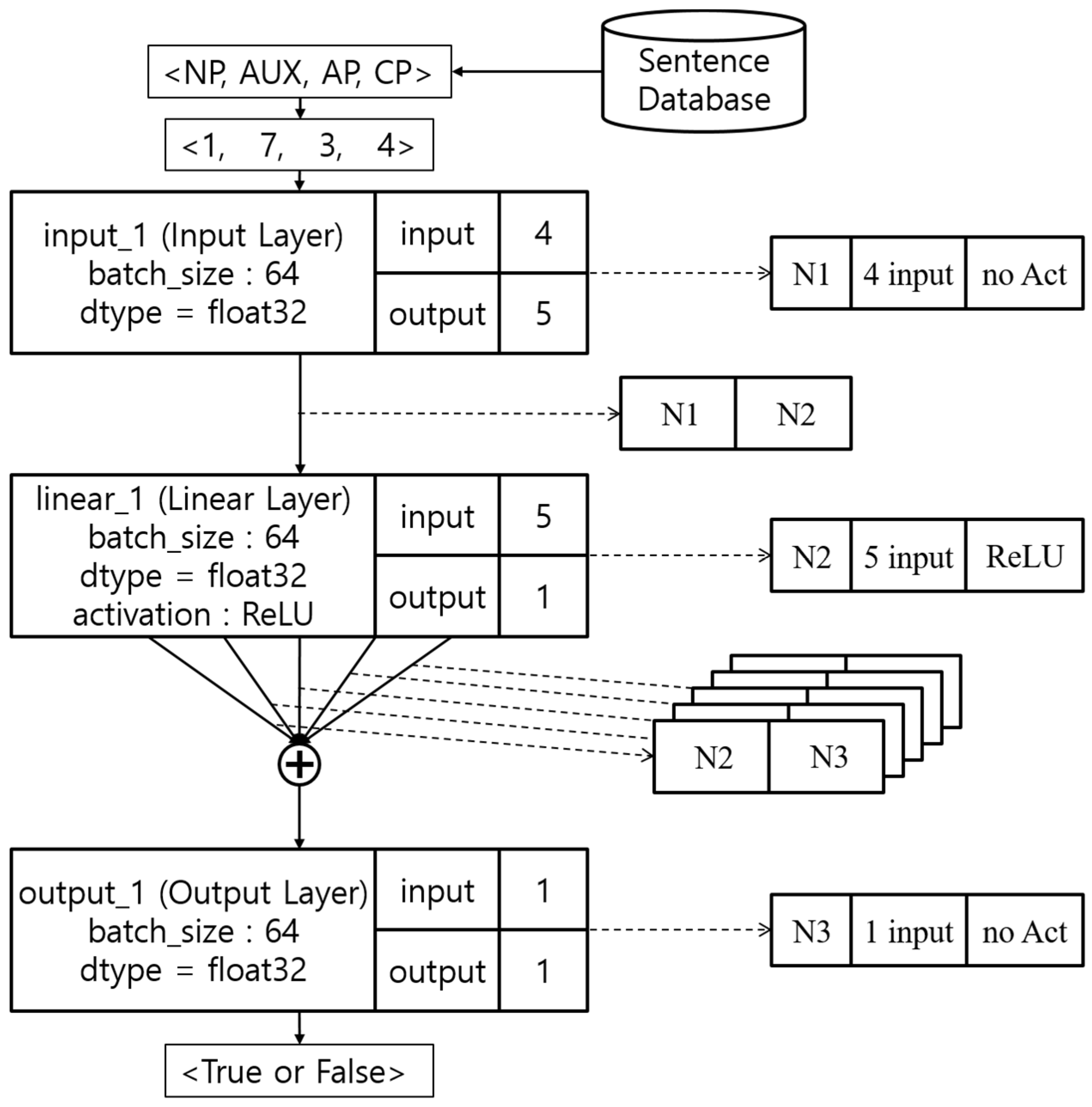
The experiment setup for English grammaticality tasks is identical to the previous experiment for the Korean dataset. We carefully controlled the system in that the resulting architecture of NAS application is able to be compared. The diagram for the initial network is given in
Figure 5: an input layer, a hidden layer, and an output layer. There are five nodes in the hidden layer. Rectified Linear Unit (ReLU) functions as an activation function. The loss of the initial neural architecture model is about 0.002338. Parameters of these experiments are shown in
Table 3.
All neural networks in our search space are composed of linear layers with identical structure but with different weights. The proposed NAS algorithm searches neural architectures using VCGA [
1] which optimizes overall structure, including composition of layers, connections between layers, the number of nodes and activation function, using input neural networks. In order to optimize the initial neural network, we use the number of chromosomes and loss value of generated neural networks as the fitness value and generated neural networks use Korean and English datasets.
4.3. Experiment Results
The experiment result is interesting. The resulting architecture for the English dataset is radically different from the one for the Korean dataset, despite their distributional similarity; Korean has 113 grammatical sentences, and English has 136, as shown in
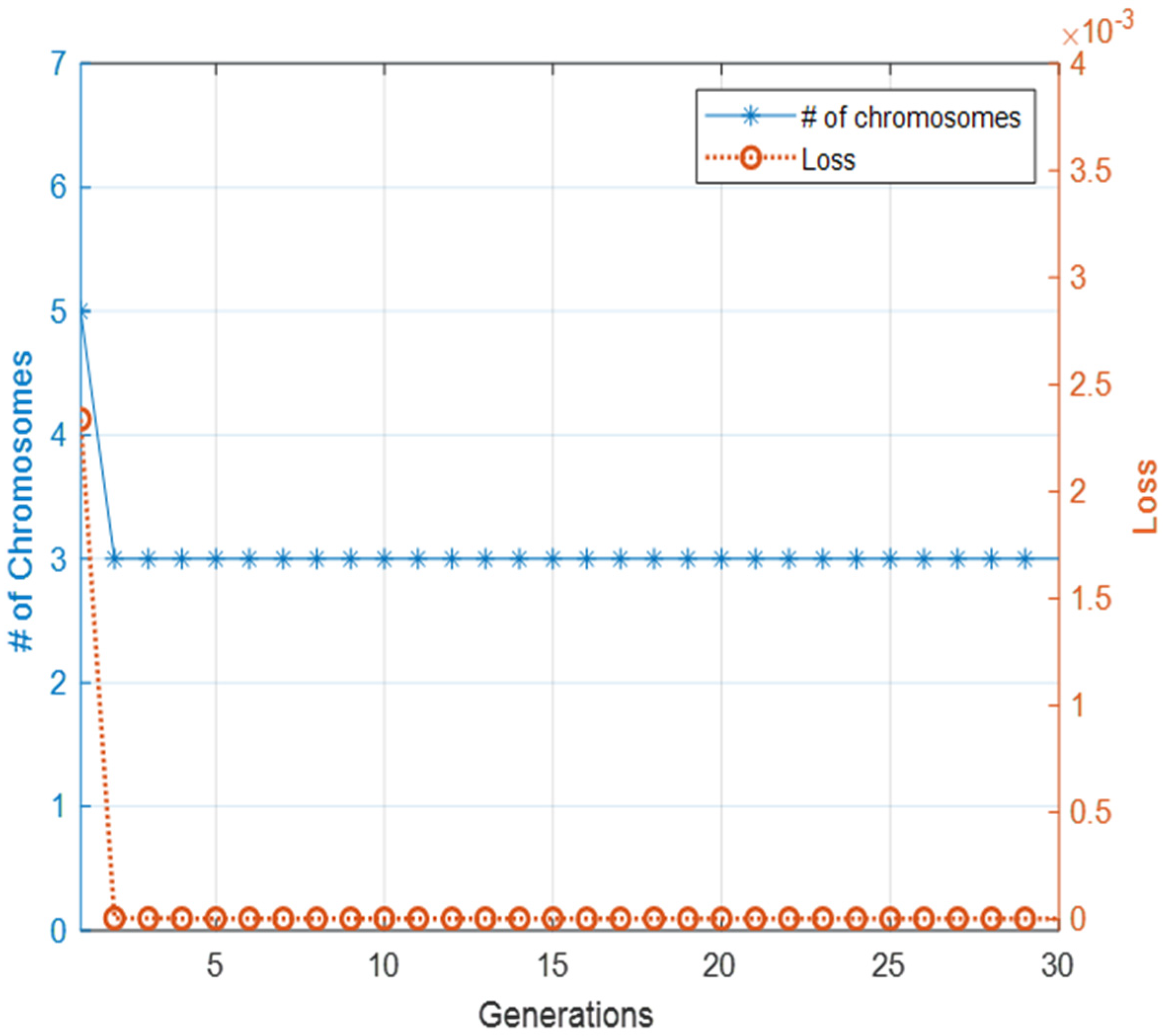
Table 3. The evolution process of the experiment is presented in
Figure 6; it starts with five chromosomes within three layers, and it evolves into three chromosomes.
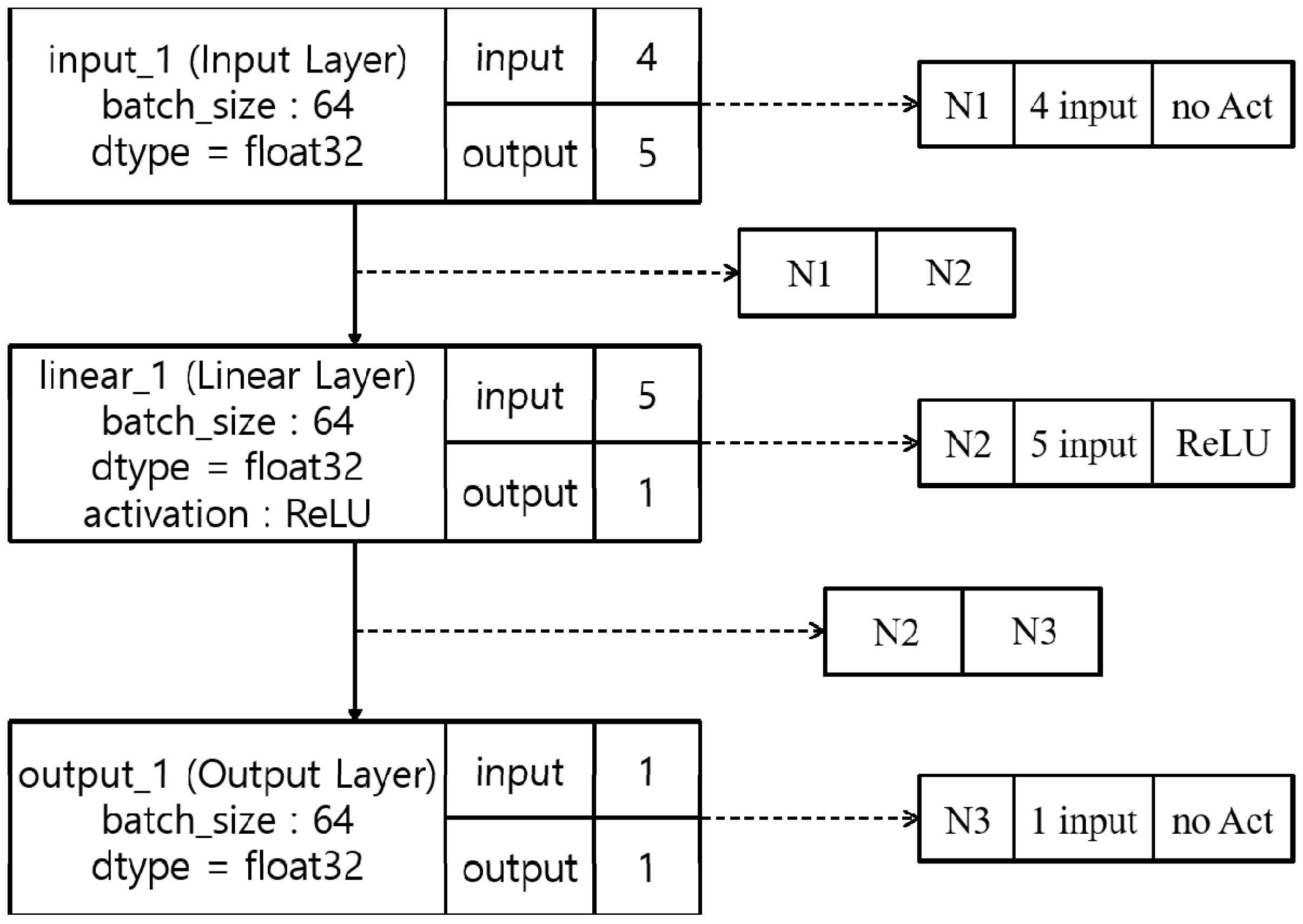
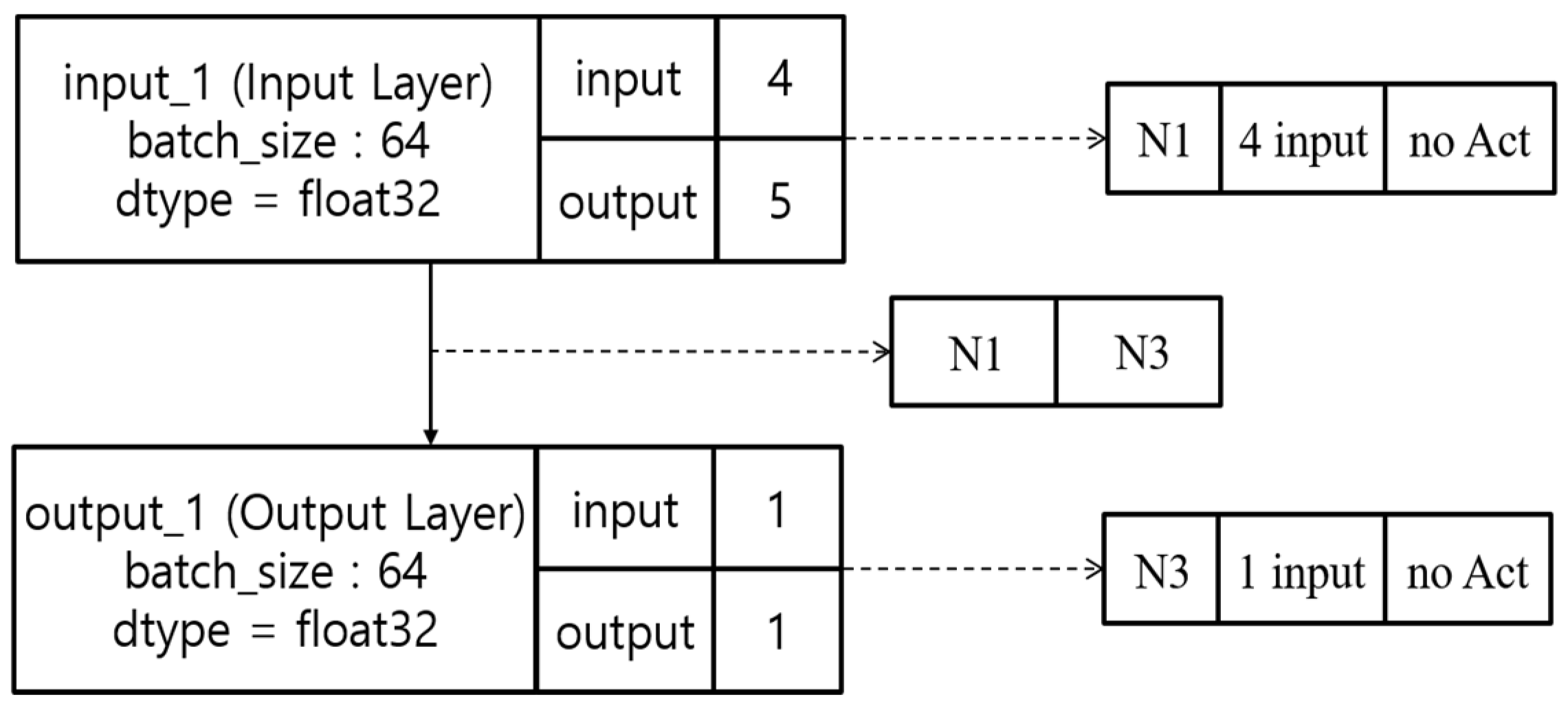
The loss is reduced from 0.002338 to 0.000004 during this process. The final architecture does not have any hidden layer between the input and output layers. The resulting topology given in
Figure 7 is interesting. This network calculated four-word ordering in an English grammaticality task without a hidden layer. This was very different from the results of the Korean grammaticality task.
The resulting topology is surprising, given that the dataset for Korean and English is almost identical. The distribution of these two types of data seems to be similar. There are 53 of 2401 matching cases for 113 and 136 grammatical sentences in the respective laguages.
Figure 8 compares generated ANN architecture of the Korean grammaticality task and the English grammaticality task.
Figure 8a presents the generated architecture of the Korean grammaticality task. It has one hidden layer with five nodes and four additional links between the hidden layer with ReLU as an activation function and the output layer, instead of leaky ReLU, because of calculation speed. Each layer uses float 32 data type.
Figure 8b presents the generated architecture of the English grammaticality task. It has an input layer with four nodes without a hidden layer.
Table 4 shows a summary of Korean and English grammaticality judgment tasks. English patterns have more grammatical combinations. Nevertheless, the complexity of the resulting neural architecture is less complicated compared to Korean.
We varied the number of layers to verify the resulting structure. We also conducted an experiment with a randomized initial population, which also provides the identical results. Hyperparameters are controlled throughout the experiment. The batch size of this experiment is 64 with 20 epochs, and learning rate is 0.0002. GTX 1660ti is used for this experiment. Each layer is fully connected with five nodes. The activation function used ReLU.
We argue that the two different resulting structures between Korean and English captures the linguistic differences that are underlying beneath the word order patterns. For example, Korean word-order patterns contain the argument ellipsis operation (2) which means that the four-word sentences can involve more than four words in terms of their syntactic structure. Crucially, English does not have the counterpart of this operation. However, we do not insist that the single different operation in the syntactic operation would be directly connected to the number of layers, as English also has exclusive syntactic operation that is not available in Korean. However, the current experiment clearly indicates that the different syntactic operations can be detected by the NAS method.
5. Discussion and Conclusions
The results of this experiment show that NAS application in linguistic tasks is successful in two respects: (i) the NAS application easily finds the efficient language model for the given task; (ii) the NAS application is sensitive to the grammatical differences existing in the word order patterns. In other words, the searching process of NAS can provide interesting aspects of language modeling in that it provides different designs for different languages. Crucially, this work may also contribute to the field of computational psycholinguistics; as a result, it could be related to the black box problem of language models. The different resulting architecture indicates that the NAS method indeed creates a design that the human expert would not propose. In further research, we will enlarge the database in Korean and English, in addition to expanding the experiment to other languages. We expect that linguistically similar languages will have similar resulting architecture.
The limitation of this research needs to be clearly stated. The first issue is the size of the dataset. Since the entire database has to be checked manually by individual linguists, it requires more time to expand the data. We predict NAS is sensitive to the syntactic operations, thus the size would not affect the result, yet we still need to expand the dataset to confirm the resulting architecture. The second issue is to develop a methodology to compare resulting structures, and to understand the implication of it. We plan to add a third language to this experiment to investigate this issue.
Particularly, Japanese—which also has ellipsis and scrambling—is an interesting language to compare with Korean. We expect the NAS to generate a similar topology as a result. In further research, we will extend the experiment to Japanese by forming a relevant dataset.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}