
Benchmarking Deep Learning Methods for Aspect Level Sentiment Classification


Abstract
:1. Introduction
2. Overview of ABSA
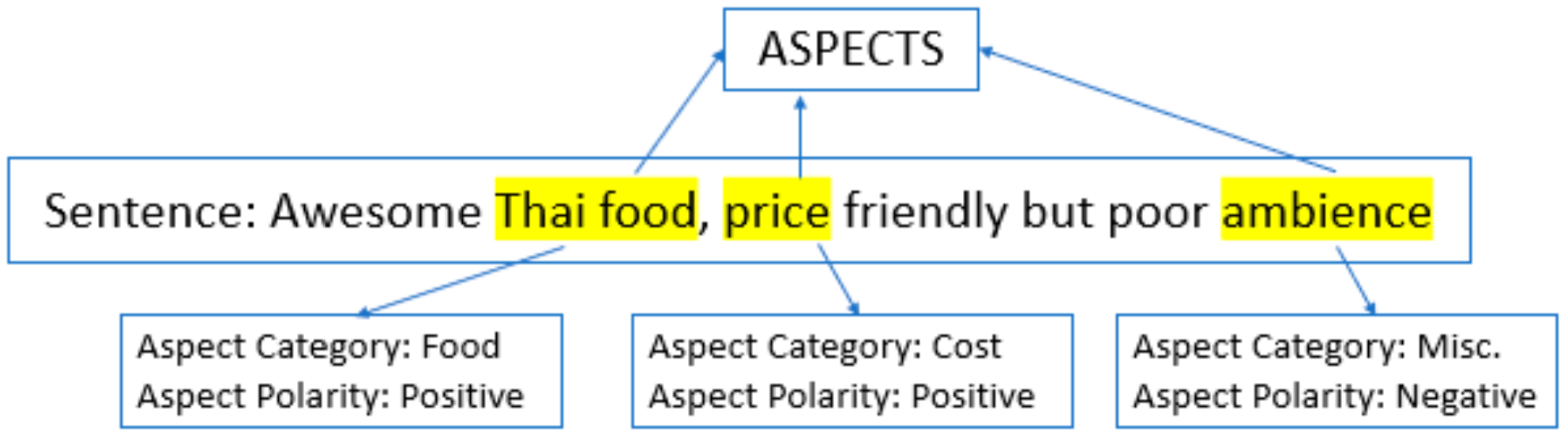
2.1. Aspect Based Sentiment Analysis
2.2. Aspect Level Sentiment Classification (ALSC)
3. Deep Learning Methods for Aspect Level Sentiment Classification
3.1. Recent Trends in Aspect Level Sentiment Classification
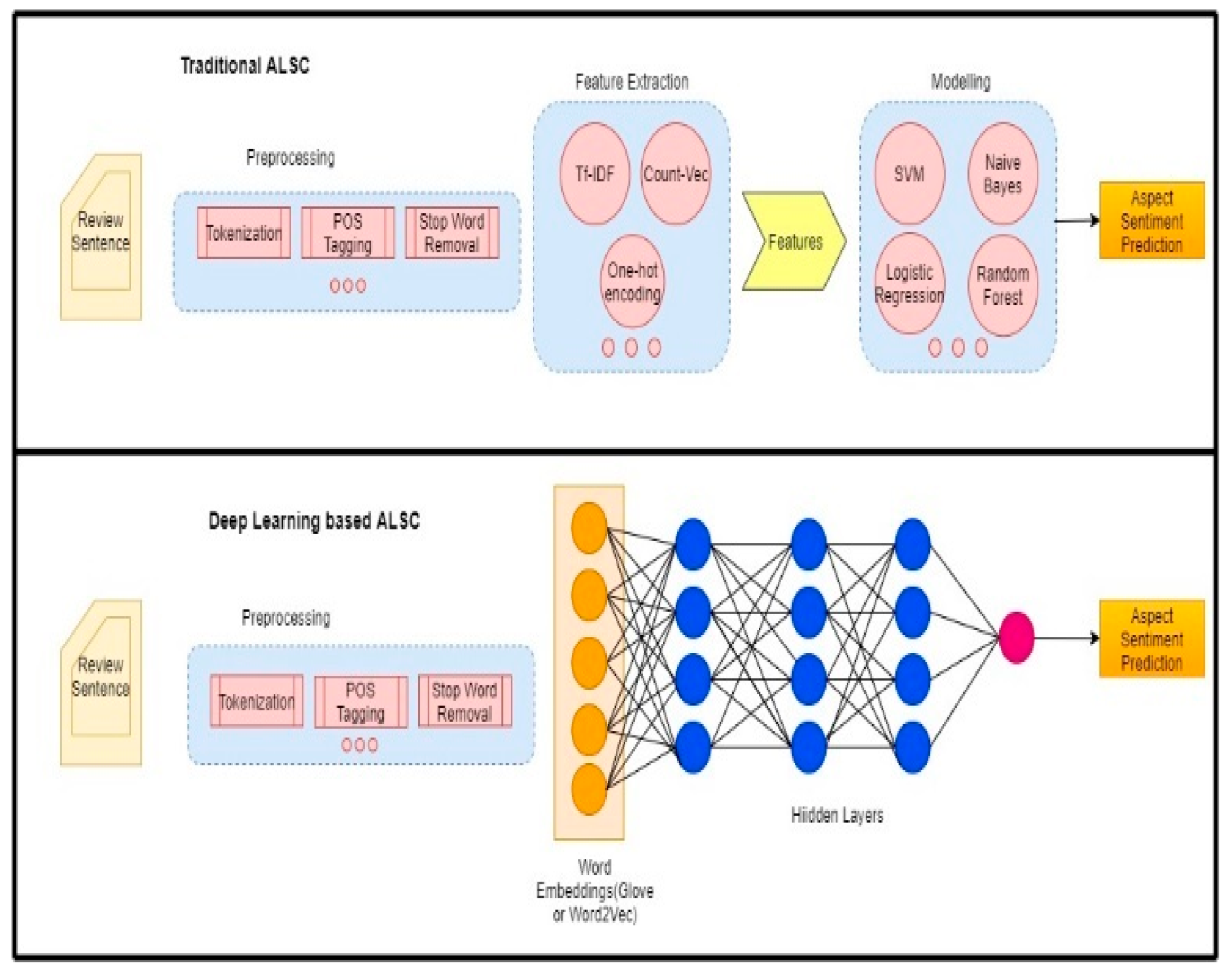
3.2. Data Modelling Procedure for Deep Learning-Based ALSC
4. Experimental Setup and Datasets
4.1. Characteristics of Datasets
4.2. Experimental Design
4.3. Evaluation Metrics
4.3.1. Accuracy
4.3.2. Macro-F1 Score
4.3.3. Time
4.4. Statistical Tests
4.4.1. Friedman Test
4.4.2. Post Hoc Tests
5. Experimental Results and Analysis
5.1. Discussion of Results
5.2. Statistical Comparison of Deep Learning Methods in Aspect Level Sentiment Classification
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cambria, E. Affective Computing and Sentiment Analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Rana, T.A.; Cheah, Y.-N. Aspect extraction in sentiment analysis: Comparative analysis and survey. Artif. Intell. Rev. 2016, 46, 459–483. [Google Scholar] [CrossRef]
- García-Pablos, A.; Cuadros, M.; Rigau, G. W2VLDA: Almost unsupervised system for Aspect Based Sentiment Analysis. Expert Syst. Appl. 2018, 91, 127–137. [Google Scholar] [CrossRef] [Green Version]
- Wagner, J.; Arora, P.; Cortes, S.; Barman, U.; Bogdanova, D.; Foster, J.; Tounsi, L. DCU: Aspect-based Polarity Classification for SemEval Task 4. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent Twitter Sentiment Classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Zhou, J.; Huang, J.X.; Chen, Q.; Hu, Q.V.; Wang, T.; He, L. Deep Learning for Aspect-Level Sentiment Classification: Survey, Vision and Challenges. IEEE Access 2019, 7, 78454–78483. [Google Scholar] [CrossRef]
- Do, H.H.; Prasad, P.; Maag, A.; Alsadoon, A. Deep Learning for Aspect-Based Sentiment Analysis: A Comparative Review. Expert Syst. Appl. 2018, 118, 272–299. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Nemenyi, P. Distribution-Free Multiple Comparisons; Princeton University: Princeton, NJ, USA, 1963; Volume 18. [Google Scholar]
- Kaur, A.; Kaur, K. Statistical Comparison of Modelling Methods for Software Maintainability Prediction. Int. J. Softw. Eng. Knowl. Eng. 2013, 23, 743–774. [Google Scholar] [CrossRef]
- Schouten, K.; Frasincar, F. Survey on Aspect-Level Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Mohammad, A.S. SemEval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016. [Google Scholar]
- Al-Ghuribi, S.M.; Noah, S.A.M.; Tiun, S. Unsupervised Semantic Approach of Aspect-Based Sentiment Analysis for Large-Scale User Reviews. IEEE Access 2020, 8, 218592–218613. [Google Scholar] [CrossRef]
- Fares, M.; Moufarrej, A.; Jreij, E.; Tekli, J.; Grosky, W. Unsupervised word-level affect analysis and propagation in a lexical knowledge graph. Knowl. Based Syst. 2018, 165, 432–459. [Google Scholar] [CrossRef]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Iyyer, M.; Boyd-Graber, J.; Claudino, L.; Socher, R.; Daum’e, H., III. A neural network for factoid question answering over paragraphs. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Cambria, E.; Poria, S.; Hazarika, D.; Kwok, K. SenticNet 5: Discovering conceptual primitives for sentiment analysis by means of context embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cambria, E.; Li, Y.; Xing, F.Z.; Poria, S.; Kwok, K. SenticNet 6: Ensemble Application of Symbolic and Subsymbolic AI for Sentiment Analysis. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. arXiv 2016, arXiv:1512.01100. [Google Scholar]
- Wang, Y.; Huang, M.; Zhao, L.; Zhu, X. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Kardakis, S.; Perikos, I.; Grivokostopoulou, F.; Hatzilygeroudis, I. Examining Attention Mechanisms in Deep Learning Models for Sentiment Analysis. Appl. Sci. 2021, 11, 3883. [Google Scholar] [CrossRef]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained attention network for aspect-level sentiment classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Huang, B.; Ou, Y.; Carley, K.M. Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, SBP-BRiMS, Washington, DC, USA, 10–13 July 2018. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive Attention Networks for Aspect-Level Sentiment Classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect Level Sentiment Classification with Deep Memory Network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent Attention Network on Memory for Aspect Sentiment Analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Jiang, Q.; Chen, L.; Xu, R.; Ao, X.; Yang, M. A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Su, J.; Yu, S.; Luo, D. Enhancing Aspect-Based Sentiment Analysis With Capsule Network. IEEE Access 2020, 8, 100551–100561. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Xiao, Y.; Zhou, G. Syntactic Edge-Enhanced Graph Convolutional Networks for Aspect-Level Sentiment Classification With Interactive Attention. IEEE Access 2020, 8, 157068–157080. [Google Scholar] [CrossRef]
- Xu, G.; Liu, P.; Zhu, Z.; Liu, J.; Xu, F. Attention-Enhanced Graph Convolutional Networks for Aspect-Based Sentiment Classification with Multi-Head Attention. Appl. Sci. 2021, 11, 3640. [Google Scholar] [CrossRef]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Bai, X.; Liu, P.; Zhang, Y. Investigating Typed Syntactic Dependencies for Targeted Sentiment Classification Using Graph Attention Neural Network. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 503–514. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanov, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT 20194171–4186, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Targeted Sentiment Classification with Attentional Encoder Network. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019. [Google Scholar]
- Yang, H.; Zeng, B.; Yang, J.; Song, Y.; Xu, R. A multi-task learning model for Chinese-oriented aspect polarity classification and aspect term extraction. Neurocomputing 2020, 419, 344–356. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, H.; Zeng, Y.; Huang, Z.; Wu, Z. Content Attention Model for Aspect Based Sentiment Analysis. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, Lyon, France, 23–27 April 2018. [Google Scholar]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Zheng, S.; Xia, R. Left-center-right separated neural network for aspect-based sentiment analysis with rotatory attention. arXiv 2018, arXiv:1802.00892. [Google Scholar]
- Li, X.; Bing, L.; Lam, W.; Shi, B. Transformation networks for target-oriented sentiment classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive Recursive Neural Networkfor target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–24 June 2014. [Google Scholar]
- Mitchell, M.; Aguilar, J.; Wilson, T.; Durme, B.V. Open Domain Targeted Sentiment. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Saeidi, M.; Bouchard, G.; Liakata, M.; Riedel, S. SentiHood: Targeted Aspect Based Sentiment Analysis Dataset for Urban Neighbourhoods. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016. [Google Scholar]
- Ganu, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions using Review Text Content. WebDB 2009, 9, 1–6. [Google Scholar]
- Dozat, T.; Manning, C.D. Deep Biaffine Attention for Neural Dependency Parsing. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Xu, Q.; Zhu, L.; Dai, T.; Yan, C. Aspect-based sentiment classification with multi-attention network. Neurocomputing 2020, 388, 135–143. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Benavoli, A.; Corani, G.; Mangili, F. Should We Really Use Post-Hoc Tests Based on Mean-Ranks? J. Mach. Learn. Res. 2016, 17, 152–161. [Google Scholar]
- Freitas, A.A. A critical review of multi-objective optimization in data mining: A position paper. ACM SIGKDD Explor. Newsl. 2004, 6, 77–86. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Ohsawa, Y. Sentiment Analysis on the Online Reviews Based on Hidden Markov Model. J. Adv. Inf. Technol. 2018, 9. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Deep Learning Method | Description | Input to the Method | Neural Network Layer in the Architecture | Attention Used | Syntactical Information |
|---|---|---|---|---|---|---|
| DL1 | ContextAvg [29] | Utilizes the deep memory network for capturing context and then the average context vector is fed into the softmax layer for aspect sentiment prediction. | S, A | Memory Network | No | No |
| DL2 | AEContextAvg [29] | Extension of ContextAvg (DL1) method in which average of aspect vector is also fed with context word vector to the softmax layer for prediction. | S | Memory Network | No | No |
| DL3 | MemNet [29] | MemNet is a variant of DL1 that utilizes a deep memory network with only context attention enabled for prediction purposes. | C, A, Cl | Memory Network | Yes | No |
| DL4 | AT-LSTM [22] | Attention-based LSTM is used to generate the hidden vector for the sentence representation which can provide attention to different parts of a sentence depending on the aspect term. | S | LSTM | Yes | No |
| DL5 | ATAE-LSTM [22] | Attention Based LSTM with aspect embedding is an extension of AT-LSTM(DL4) where aspect embeddings are also used to generate a better representation of sentences for prediction. | S, A | LSTM | Yes | No |
| DL6 | LSTM [21] | Utilizes Long Short Term Network (LSTM) for generating hidden vector for the sentence which is fed into softmax layer for predicting the sentiment polarity of an aspect. | S | LSTM | No | No |
| DL7 | TD-LSTM [21] | TD-LSTM (Target dependent-LSTM) model utilizes two LSTMs: LSTML and LSTMR for collectively considering left and right context of target. | , | LSTM | No | No |
| DL8 | TC-LSTM [21] | Target Connection-LSTM is an extension of TD-LSTM(DL7) with the enablement of a target connection mechanism to establish the relation between the target and each context word. | , , | LSTM | No | No |
| DL9 | IAN [28] | Interactive Attention Network utilizes two separate attention-based LSTMs for capturing the interaction between aspect and context words using the pooling layer. | S, A | LSTM | Yes | No |
| DL10 | RAM [30] | Recurrent Attention Memory network utilizes a multi-attention mechanism to capture sentiment features and uses RNN as a memory component. | S, A | LSTM, GRU | Yes | No |
| DL11 | CABASAC [41] | Content Attention Based Aspect Sentiment Classification (CABASC) model uses two attention enhancing mechanisms. The sentence-level and context level mechanisms are then used for better prediction of multi-aspect sentences. | S, A, , | GRU | Yes | No |
| DL12 | GCAE [42] | Gated Convolutional network with Aspect Embedding makes use of gating mechanism combined with convolution layers and aspect embedding to predict the aspect sentiment polarity. | S, A | CNN | Yes | No |
| DL13 | LCR-Rot [43] | Left-Centre-Right separated neural network with Rotatory Attention network utilized three LSTMs along with rotary attention to capturing the relation between left, right context, and target phrase(in the center). | LSTM | Yes | No | |
| DL14 | AOA [27] | Attention over Attention Network has an AOA module to capture the interaction between aspect and context using LSTM networks. | LSTM | Yes | No | |
| DL15 | TNET [44] | Transformation network leverages Target Specific Transformation (TST) representation for words of the sentence along with Bi-LSTM and convolution layers. | LSTM, CNN | No | No | |
| DL16 | MGAN [26] | Multi Grained Attention Network combines both coarse-grained and fine-grained attention mechanism for capturing the interaction between the aspect and the context. | LSTM | Yes | No | |
| DL17 | ASCNN [33] | Aspect Specific Convolution Neural Network utilizes syntactical information using a simple Convolution Neural Network. | LSTM, CNN | Yes | No | |
| DL18 | ASGCN [33] | Aspect Specific Graph Convolution Network leverages syntactical information of sentence by building graph convolution network over dependency graph. | , | LSTM, Graph Convolution | Yes | Yes |
| DL19 | ASTCN [33] | Aspect Specific Tree Convolution Network leverages dependency tree for incorporating syntactical information | , | LSTM, Graph Convolution | Yes | Yes |
| DL20 | ATAE-BiGRU [7] | Utilizes Bi-directional GRU and aspect embedding for generating sentence vector representation | LSTM | Yes | No | |
| DL21 | ATAE-BiLSTM [7] | Utilizes Bi-directional LSTM and aspect embedding for generating sentence vector representation | BiLSTM | Yes | No | |
| DL22 | ATAE-GRU(Zhou et al., 2019) | Utilizes aspect embedding along with Attention-based GRU for generating the sentence vector representation. | GRU | Yes | No | |
| DL23 | AT-BiGRU [7] | Utilizes Bi-directional GRU along with attention mechanism to generate sentence vector representation. | BiGRU | Yes | No | |
| DL24 | AT-GRU [7] | Attention Based GRU is used for generating the hidden vectors for the sentence. | GRU | Yes | No | |
| DL25 | AT-BiLSTM [7] | Utilizes Bi-direction LSTM along with attention mechanism to generate the hidden vectors for feeding into softmax function. | BiLSTM | Yes | No | |
| DL26 | BiGRU [7] | Bi-directional Gated Recurrent Unit Network is used to generate the hidden vector that can be fed into the softmax layer. | BiGRU | No | No | |
| DL27 | BiLSTM [7] | Bi-directional LSTM is used to generate the hidden vector that can be fed into softmax layer for sentiment prediction. | BiLSTM | No | No | |
| DL28 | CNN [7] | Uses simple Convolution Neural Network for aspect sentiment polarity prediction. | CNN | No | No | |
| DL29 | GRU [7] | Utilizes simple Gated Recurrent Unit Network for generating hidden vector for a sentence which is fed into the softmax layer for prediction. | GRU | No | No | |
| DL30 | AEN-BERT [39] | Attention Encoder Network uses attention-based encoder network with pre-trained BERT embeddings for context target representation. | BERT, CNN | Yes | No | |
| DL31 | CapsNet [31] | Capsule Network utilizes BiGRU encoding layer and capsule-guided routing along with BERT for ALSC. | BiGRU, Transformer | Yes | No | |
| DL32 | RGAT [36] | Relational Graph Attention Network handlesthe ALSC task by generating an Aspect-oriented dependency tree from an ordinary dependency tree. | Transformer, Graph attention | Yes | Yes | |
| DL33 | BERT-SPC [40] | BERT-SPC is a simple pre-trained BERT model designed for ALSC task. | BERT | Yes | No | |
| DL34 | GAT-Glove [37] | GAT leverages dependency relation by adopting a Relation graph attention network for exchanging the information between words based on the dependency tree. | BiLSTM, Graph Attention Network | Yes | Yes | |
| DL35 | GAT-BERT [37] | Variant of GAT(DL34) leveraging contextual BERT embeddings. | BiLSTM, Graph Attention Network | Yes | Yes |
| Dataset | Positive Samples | Negative Samples | Neutral Samples | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Rest14 | 2164 | 728 | 805 | 196 | 633 | 196 |
| Lap14 | 987 | 341 | 866 | 128 | 460 | 169 |
| 1561 | 173 | 1560 | 173 | 3127 | 3146 | |
| Rest15 | 1198 | 454 | 403 | 346 | 53 | 45 |
| Rest16 | 1657 | 611 | 749 | 204 | 101 | 44 |
| Sentihood | 2480 | 1217 | 921 | 462 | - | - |
| Mitchell | 695 | 695 | 269 | 269 | 2259 | 2259 |
| MAMS | 3380 | 400 | 2764 | 329 | 5042 | 607 |
| Accuracy | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Lap14 | Rest14 | Rest15 | Rest16 | MAMS | Sentihood | Michell | Average | ||
| ContexTAvg | 0.6347 | 0.7348 | 0.657 | 0.7881 | 0.6604 | 0.4902 | 0.803 | 0.7604 | 0.6911 |
| AEContexTAvg | 0.6379 | 0.7071 | 0.827 | 0.7857 | 0.6734 | 0.6272 | 0.804 | 0.8278 | 0.7363 |
| MemNet | 0.6159 | 0.7035 | 0.639 | 0.7892 | 0.6473 | 0.6384 | 0.7796 | 0.771 | 0.698 |
| AT-LSTM | 0.5987 | 0.7116 | 0.6449 | 0.7275 | 0.6305 | 0.4902 | 0.8123 | 0.7825 | 0.6748 |
| ATAE-LSTM | 0.63 | 0.7098 | 0.6615 | 0.7424 | 0.6372 | 0.6025 | 0.8129 | 0.9137 | 0.7138 |
| LSTM | 0.5956 | 0.683 | 0.628 | 0.7334 | 0.6228 | 0.4827 | 0.759 | 0.7036 | 0.651 |
| TD-LSTM | 0.642 | 0.7378 | 0.6879 | 0.7939 | 0.6632 | 0.7447 | 0.8094 | 0.8817 | 0.7476 |
| TC-LSTM | 0.6097 | 0.6991 | 0.6497 | 0.745 | 0.6315 | 0.7402 | 0.7814 | 0.7837 | 0.705 |
| IAN | 0.6253 | 0.7071 | 0.6923 | 0.7939 | 0.643 | 0.6167 | 0.8106 | 0.7437 | 0.7041 |
| RAM | 0.605 | 0.7026 | 0.6816 | 0.7904 | 0.6632 | 0.6227 | 0.804 | 0.7102 | 0.6975 |
| CABASAC | 0.6034 | 0.6848 | 0.6532 | 0.7625 | 0.6286 | 0.607 | 0.8022 | 0.7812 | 0.6904 |
| GCAE | 0.6159 | 0.7214 | 0.6923 | 0.7718 | 0.6632 | 0.6482 | 0.8129 | 0.7477 | 0.7092 |
| LCRS | 0.6065 | 0.6839 | 0.6355 | 0.752 | 0.6343 | 0.6654 | 0.801 | 0.7458 | 0.6906 |
| AOA | 0.6724 | 0.7616 | 0.6881 | 0.8198 | 0.6849 | 0.654 | 0.7756 | 0.7437 | 0.725 |
| MGAN | 0.6693 | 0.7571 | 0.5978 | 0.8523 | 0.6618 | 0.686 | 0.8256 | 0.7882 | 0.7298 |
| Tnet-LF | 0.71 | 0.7875 | 0.6015 | 0.8613 | 0.6965 | 0.76 | 0.833 | 0.7945 | 0.7555 |
| ASCNN | 0.746 | 0.8092 | 0.7952 | 0.8766 | 0.722 | 0.7813 | 0.8481 | 0.899 | 0.8097 |
| ASGCN | 0.7502 | 0.8169 | 0.7896 | 0.8771 | 0.7196 | 0.7826 | 0.9078 | 0.9008 | 0.8181 |
| ASTCN | 0.732 | 0.8175 | 0.7976 | 0.8874 | 0.723 | 0.777 | 0.8491 | 0.8005 | 0.798 |
| ATAE-BiGRU | 0.6097 | 0.7323 | 0.6627 | 0.7706 | 0.6199 | 0.6107 | 0.804 | 0.7784 | 0.6985 |
| ATAE-BiLSTM | 0.6363 | 0.691 | 0.6627 | 0.7811 | 0.6473 | 0.5868 | 0.8034 | 0.7306 | 0.6924 |
| ATAE-GRU | 0.598 | 0.7125 | 0.6615 | 0.7916 | 0.6401 | 0.625 | 0.8094 | 0.7309 | 0.6961 |
| AT-BiGRU | 0.5877 | 0.729 | 0.6305 | 0.7753 | 0.52 | 0.5134 | 0.8171 | 0.829 | 0.6715 |
| AT-BiLSTM | 0.6159 | 0.7312 | 0.6532 | 0.7846 | 0.6343 | 0.4985 | 0.8123 | 0.7871 | 0.6896 |
| AT-GRU | 0.5893 | 0.7241 | 0.6816 | 0.7438 | 0.6098 | 0.5097 | 0.7849 | 0.9069 | 0.6938 |
| BiGRU | 0.6332 | 0.6767 | 0.6331 | 0.759 | 0.6343 | 0.4618 | 0.7945 | 0.8886 | 0.6852 |
| BiLSTM | 0.5893 | 0.6928 | 0.6248 | 0.7718 | 0.6372 | 0.4708 | 0.7879 | 0.8557 | 0.6788 |
| CNN | 0.6175 | 0.7375 | 0.643 | 0.7718 | 0.6604 | 0.478 | 0.782 | 0.8104 | 0.6876 |
| GRU | 0.5956 | 0.6785 | 0.6307 | 0.762 | 0.5751 | 0.4513 | 0.8052 | 0.713 | 0.6514 |
| AEN-BERT | 0.7696 | 0.8098 | 0.8173 | 0.8799 | 0.7384 | 0.75 | 0.877 | 0.8954 | 0.8172 |
| CapsNet | 0.772 | 0.816 | 0.754 | 0.8771 | 0.7221 | 0.8 | 0.8706 | 0.7804 | 0.799 |
| RGAT | 0.7742 | 0.833 | 0.8004 | 0.887 | 0.7557 | 0.821 | 0.882 | 0.892 | 0.8307 |
| BERT-SPC | 0.7774 | 0.8473 | 0.845 | 0.9075 | 0.7111 | 0.822 | 0.9022 | 0.89 | 0.8378 |
| GAT-BERT | 0.7921 | 0.8471 | 0.8332 | 0.9075 | 0.7613 | 0.8296 | 0.9111 | 0.9002 | 0.8478 |
| GAT-Glove | 0.6052 | 0.688 | 0.742 | 0.766 | 0.569 | 0.624 | 0.882 | 0.7715 | 0.706 |
| Macro F1 Score | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Lap14 | Rest14 | Rest15 | Rest16 | MAMS | Sentihood | Mitchell | Average | ||
| ContexTAvg | 0.55 | 0.5792 | 0.424 | 0.5059 | 0.6246 | 0.362 | 0.4905 | 0.469 | 0.5007 |
| AEContexTAvg | 0.5571 | 0.5699 | 0.512 | 0.513 | 0.6508 | 0.6043 | 0.483 | 0.6306 | 0.5651 |
| MemNet | 0.5094 | 0.5677 | 0.433 | 0.4921 | 0.6178 | 0.6241 | 0.4262 | 0.5322 | 0.5253 |
| AT-LSTM | 0.5151 | 0.5636 | 0.4295 | 0.5363 | 0.5878 | 0.3709 | 0.4908 | 0.4827 | 0.4971 |
| ATAE-LSTM | 0.5252 | 0.5461 | 0.4274 | 0.5277 | 0.5977 | 0.5864 | 0.4902 | 0.8575 | 0.5698 |
| LSTM | 0.4852 | 0.5041 | 0.426 | 0.5058 | 0.5935 | 0.3896 | 0.459 | 0.283 | 0.4558 |
| TD-LSTM | 0.5698 | 0.5805 | 0.4566 | 0.5431 | 0.641 | 0.7388 | 0.489 | 0.7433 | 0.5953 |
| TC-LSTM | 0.522 | 0.5784 | 0.4427 | 0.5454 | 0.5961 | 0.7313 | 0.4599 | 0.5051 | 0.5476 |
| IAN | 0.5708 | 0.5649 | 0.4611 | 0.5477 | 0.6147 | 0.5798 | 0.4956 | 0.3935 | 0.5285 |
| RAM | 0.5261 | 0.5594 | 0.4542 | 0.502 | 0.6357 | 0.6089 | 0.4813 | 0.3079 | 0.5094 |
| CABASAC | 0.4911 | 0.5399 | 0.4219 | 0.5239 | 0.5911 | 0.575 | 0.4898 | 0.5546 | 0.5234 |
| GCAE | 0.4933 | 0.6005 | 0.4564 | 0.4815 | 0.6368 | 0.637 | 0.4921 | 0.418 | 0.527 |
| LCRS | 0.5146 | 0.55 | 0.3926 | 0.495 | 0.595 | 0.6385 | 0.4221 | 0.4128 | 0.5026 |
| AOA | 0.598 | 0.6583 | 0.4103 | 0.4956 | 0.6566 | 0.6645 | 0.4468 | 0.4725 | 0.5503 |
| MGAN | 0.5823 | 0.5865 | 0.2494 | 0.5325 | 0.6266 | 0.6798 | 0.482 | 0.5123 | 0.5314 |
| TNET | 0.649 | 0.6754 | 0.403 | 0.5491 | 0.6692 | 0.7516 | 0.522 | 0.5334 | 0.575 |
| ASCNN | 0.7031 | 0.7221 | 0.5882 | 0.6615 | 0.704 | 0.7744 | 0.5392 | 0.711 | 0.6754 |
| ASGCN | 0.7079 | 0.7376 | 0.6071 | 0.6783 | 0.7007 | 0.7769 | 0.5336 | 0.6995 | 0.6854 |
| ASTCN | 0.7113 | 0.7318 | 0.615 | 0.7003 | 0.7022 | 0.7709 | 0.5353 | 0.7005 | 0.6802 |
| ATAE-BiGRU | 0.4744 | 0.5612 | 0.4392 | 0.5015 | 0.5992 | 0.5898 | 0.4916 | 0.4721 | 0.5161 |
| ATAE-BiLSTM | 0.5391 | 0.5468 | 0.435 | 0.4944 | 0.5993 | 0.538 | 0.462 | 0.362 | 0.4971 |
| ATAE-GRU | 0.4374 | 0.5655 | 0.4298 | 0.5043 | 0.6106 | 0.605 | 0.4936 | 0.3631 | 0.5012 |
| AT-BiGRU | 0.4753 | 0.5618 | 0.3986 | 0.4824 | 0.1333 | 0.3867 | 0.4901 | 0.5799 | 0.4385 |
| AT-BiLSTM | 0.5032 | 0.616 | 0.4269 | 0.505 | 0.5842 | 0.3841 | 0.4973 | 0.4826 | 0.4999 |
| AT-GRU | 0.515 | 0.5312 | 0.4539 | 0.5164 | 0.5821 | 0.4751 | 0.4277 | 0.8608 | 0.5453 |
| BiGRU | 0.5199 | 0.5235 | 0.3935 | 0.4419 | 0.6163 | 0.2763 | 0.4809 | 0.831 | 0.5104 |
| BiLSTM | 0.5073 | 0.5452 | 0.3912 | 0.5003 | 0.583 | 0.3533 | 0.4755 | 0.7411 | 0.5121 |
| CNN | 0.5306 | 0.603 | 0.4043 | 0.4754 | 0.6408 | 0.2769 | 0.4334 | 0.518 | 0.4853 |
| GRU | 0.4835 | 0.5379 | 0.3969 | 0.5326 | 0.5654 | 0.3761 | 0.4903 | 0.3129 | 0.462 |
| AEN-BERT | 0.7378 | 0.692 | 0.5545 | 0.6694 | 0.7128 | 0.7476 | 0.5777 | 0.6881 | 0.6725 |
| RGAT | 0.7376 | 0.7608 | 0.6223 | 0.6111 | 0.7382 | 0.6984 | 0.5678 | 0.6997 | 0.6795 |
| CapsNet | 0.7002 | 0.7225 | 0.6552 | 0.6141 | 0.7002 | 0.7709 | 0.5548 | 0.7223 | 0.68 |
| BERT-SPC | 0.7309 | 0.7774 | 0.7229 | 0.6992 | 0.674 | 0.8206 | 0.5799 | 0.7008 | 0.7132 |
| GAT-BERT | 0.75 | 0.7869 | 0.7229 | 0.7336 | 0.7539 | 0.8208 | 0.598 | 0.733 | 0.7374 |
| GAT-Glove | 0.5423 | 0.4946 | 0.5536 | 0.655 | 0.4758 | 0.5732 | 0.5124 | 0.656 | 0.5579 |
| Time (in Seconds) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Lap14 | Rest14 | Rest15 | Rest16 | MAMS | Sentihood | Mitchell | Average | ||
| ContexTAvg | 0.837 | 1.202 | 0.667 | 0.881 | 1.986 | 3.514 | 1.277 | 1.543 | 1.488 |
| AEContexTAvg | 0.987 | 1.466 | 1.624 | 1.045 | 2.424 | 4.394 | 1.494 | 1.739 | 1.897 |
| MemNet | 1.302 | 2.002 | 1.483 | 1.396 | 3.240 | 6.188 | 1.972 | 2.221 | 2.475 |
| AT-LSTM | 1.298 | 1.880 | 0.999 | 1.329 | 2.824 | 5.843 | 1.818 | 1.997 | 2.249 |
| ATAE-LSTM | 1.486 | 2.188 | 1.098 | 1.533 | 3.421 | 6.857 | 2.106 | 2.247 | 2.617 |
| LSTM | 1.124 | 1.616 | 1.550 | 1.142 | 2.376 | 4.815 | 1.500 | 1.717 | 1.980 |
| TD-LSTM | 1.453 | 2.111 | 1.065 | 2.10 | 3.343 | 10.201 | 2.002 | 2.133 | 3.051 |
| TC-LSTM | 1.676 | 2.466 | 1.002 | 1.702 | 3.893 | 7.843 | 2.309 | 2.508 | 2.925 |
| IAN | 1.786 | 2.597 | 1.299 | 1.814 | 4.116 | 8.177 | 2.457 | 2.625 | 3.109 |
| RAM | 2.319 | 3.429 | 1.807 | 2.372 | 5.424 | 10.980 | 3.435 | 3.371 | 4.142 |
| CABASAC | 1.276 | 1.898 | 1.035 | 1.362 | 3.133 | 5.638 | 1.901 | 2.040 | 2.285 |
| GCAE | 1.557 | 2.320 | 1.132 | 1.643 | 3.548 | 6.430 | 2.136 | 2.277 | 2.630 |
| LCRS | 2.596 | 3.890 | 1.891 | 2.300 | 6.566 | 12.707 | 4.894 | 4.004 | 4.856 |
| AOA | 1.918 | 2.739 | 5.809 | 6.033 | 7.100 | 2.642 | 6.243 | 3.5 | 4.498 |
| MGAN | 13.592 | 20.780 | 20.043 | 11.179 | 16.052 | 16.895 | 18.233 | 16.020 | 16.599 |
| TNET | 4.263 | 7.025 | 5.185 | 6.991 | 9.871 | 7.295 | 8.020 | 7.250 | 6.987 |
| ASCNN | 2.430 | 4.803 | 1.444 | 1.876 | 5.466 | 4.334 | 2.620 | 3.266 | 3.280 |
| ASGCN | 2.304 | 4.5 | 1.041 | 1.780 | 4.800 | 3.903 | 2.093 | 3.123 | 2.943 |
| ASTCN | 5.475 | 7.266 | 4.167 | 5.079 | 6.234 | 4.450 | 4.521 | 3.101 | 5.01 |
| ATAE-BiGRU | 1.649 | 2.406 | 1.262 | 1.674 | 3.946 | 7.802 | 2.700 | 2.528 | 2.996 |
| ATAE-BiLSTM | 1.747 | 2.550 | 1.277 | 1.744 | 4.053 | 8.177 | 2.375 | 2.502 | 3.053 |
| ATAE-GRU | 1.449 | 2.105 | 1.091 | 1.463 | 3.369 | 7.323 | 1.981 | 2.164 | 2.618 |
| AT-BiGRU | 1.445 | 2.101 | 1.132 | 1.463 | 3.450 | 7.214 | 2.070 | 2.160 | 2.629 |
| AT-BiLSTM | 1.566 | 2.223 | 1.128 | 1.566 | 3.480 | 17.310 | 2.124 | 2.197 | 3.949 |
| AT-GRU | 1.242 | 1.772 | 1.784 | 1.309 | 2.792 | 12.510 | 1.733 | 1.869 | 3.126 |
| BiGRU | 1.268 | 1.810 | 0.978 | 1.295 | 2.972 | 13.958 | 1.797 | 1.927 | 3.251 |
| BiLSTM | 1.385 | 1.967 | 1.778 | 1.399 | 3.277 | 15.622 | 1.803 | 1.977 | 3.651 |
| CNN | 0.974 | 1.432 | 1.523 | 1.031 | 2.373 | 6.867 | 1.222 | 1.602 | 2.128 |
| GRU | 1.258 | 2.104 | 0.797 | 2.035 | 2.496 | 12.567 | 1.459 | 2.791 | 3.188 |
| AEN-BERT | 34.000 | 101.222 | 15.557 | 22.364 | 28.589 | 87.486 | 25.204 | 21.120 | 41.943 |
| RGAT | 158.800 | 301.000 | 287.214 | 247.140 | 234.870 | 289.840 | 271.210 | 294.210 | 260.536 |
| CapsNet | 27.25 | 38.24 | 39.21 | 21.22 | 23.567 | 25 | 24.41 | 21.12 | 27.502 |
| BERT-SPC | 60.900 | 82.080 | 12.231 | 22.300 | 144.152 | 85.750 | 53.210 | 47.745 | 63.546 |
| GAT-BERT | 25.933 | 40.970 | 36.622 | 41.120 | 57.400 | 106.750 | 45.520 | 39.458 | 49.222 |
| GAT-Glove | 8.667 | 14.108 | 11.210 | 15.411 | 23.567 | 52.708 | 12.224 | 18.456 | 19.544 |
| ASGCN vs. GAT-BERT | |
|---|---|
| Evaluation Criteria | p-Value |
| Macro F1 score | 0.082 (-) |
| Accuracy | 0.32 (-) |
| Time | 0.0015 (↑) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, T.; Kaur, K. Benchmarking Deep Learning Methods for Aspect Level Sentiment Classification. Appl. Sci. 2021, 11, 10542. https://doi.org/10.3390/app112210542
Sharma T, Kaur K. Benchmarking Deep Learning Methods for Aspect Level Sentiment Classification. Applied Sciences. 2021; 11(22):10542. https://doi.org/10.3390/app112210542
Chicago/Turabian StyleSharma, Tanu, and Kamaldeep Kaur. 2021. "Benchmarking Deep Learning Methods for Aspect Level Sentiment Classification" Applied Sciences 11, no. 22: 10542. https://doi.org/10.3390/app112210542
APA StyleSharma, T., & Kaur, K. (2021). Benchmarking Deep Learning Methods for Aspect Level Sentiment Classification. Applied Sciences, 11(22), 10542. https://doi.org/10.3390/app112210542