
Event Log Preprocessing for Process Mining: A Review


Abstract
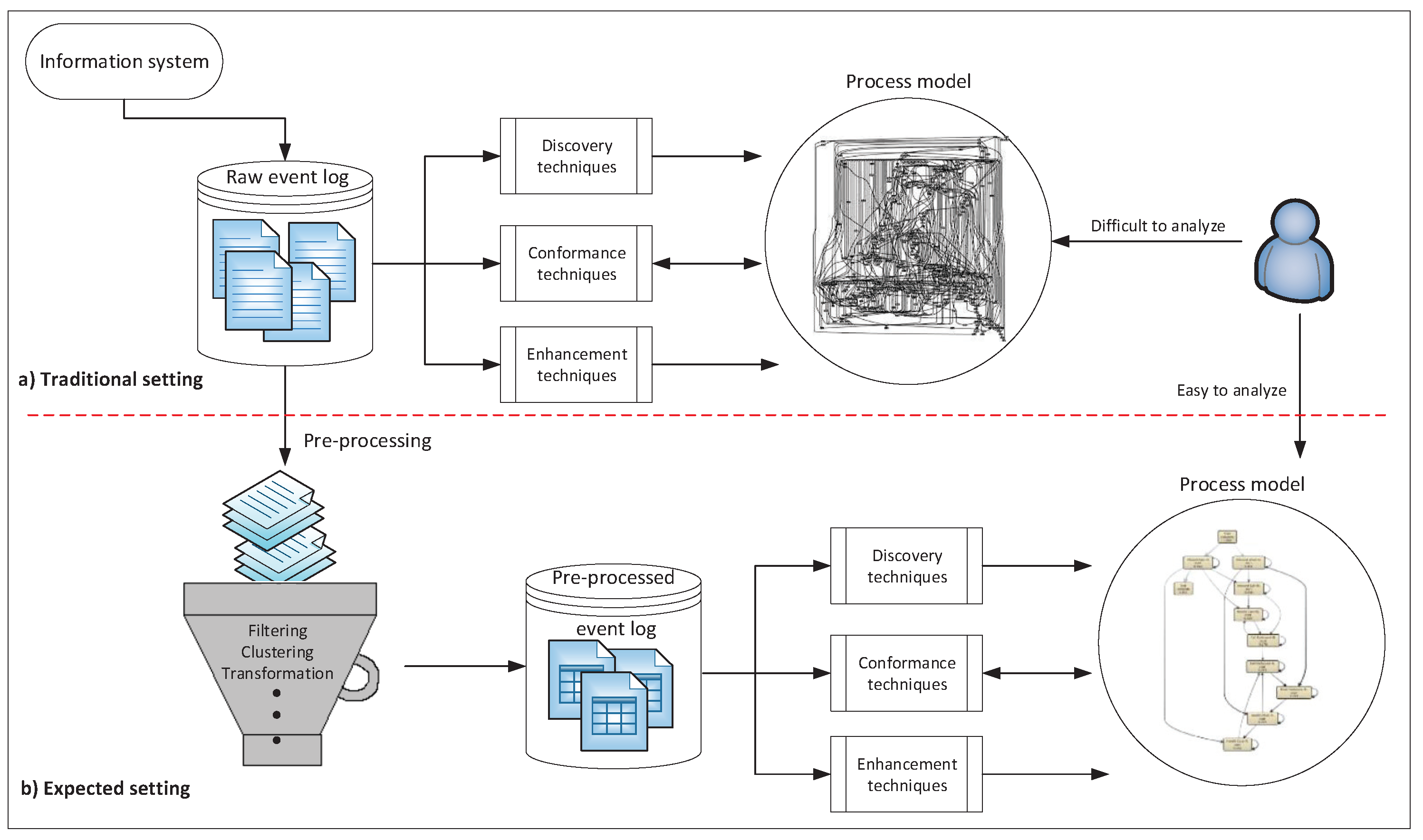
:1. Introduction
- We present, for the first time, a review of preprocessing techniques of event logs, also called data cleaning or data preparation techniques in the context of process mining.
- We provide a grouping of preprocessing and repairing techniques of event logs, required to build more robust process models.
- We present a study of relevant characteristics associated with preprocessing techniques used when making decisions about the use of a specific technique.
2. Preliminary Concepts
- An event log consists of cases.
- A case consists of events, such that each event relates to precisely one case.
- Events within a case are ordered.
- Events can have attributes. Examples of typical attributes are: activity name, time, costs, and resource.
3. Research Methodology
3.1. Systematic Review Process
3.1.1. Inclusion Criteria
- Research works written in English.
- Research works published in journals, conferences, or theses.
- Works published from at least 2005.
- Works explicitly addressing the preprocessing or cleaning of event logs.
3.1.2. Exclusion Criteria
- Works that are not related to process mining.
- Works that do not focus on specific domains in the field of process mining (industry, manufacturing); that is, ad hoc techniques for a given domain.
- Works that do not include evaluation and experimental results.
3.2. C1. Techniques
- Is there a way of grouping event log preprocessing techniques?
3.2.1. Transformation Techniques
3.2.2. Detection–Visualization Techniques
3.3. C2. Tools
- What tools are available for the event logs preprocessing task?
3.4. C3. Representation Schemes of Event Logs Used in Preprocessing Techniques
- What structures are more appropriate to represent and manipulate event logs in preprocessing techniques?
3.5. C4. Imperfection Types in the Event Log
- What kind of imperfections are commonly identified in the event logs?
3.6. C5. Related Tasks
- What are the tasks closely related to event log preprocessing?
3.6.1. Event Abstraction
3.6.2. Alignment
3.7. C6. Information Type
- What type of attributes or information the preprocessing techniques use to work?
4. Lessons Learned and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dakic, D.; Stefanović, D.; Cosic, I.; Lolić, T.; Medojevic, M. Business Process Mining Application: A Literature Review. In Proceedings of the 29th International DAAAM Symposium 2018, Zadar, Croatia, 24–27 October 2018; pp. 0866–0875. [Google Scholar] [CrossRef]
- van der Aalst, W. Process Mining: Discovery, Conformance and Enhancement of Business Processes; Springer: Berlin/Heidelberg, Germany, 2011; Volume 136. [Google Scholar] [CrossRef]
- Bose, R.P.J.C.; Mans, R.S.; van der Aalst, W.M.P. Wanna improve process mining results? In Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; pp. 127–134. [Google Scholar] [CrossRef]
- Mans, R.S.; van der Aalst, W.M.P.; Vanwersch, R.J.B.; Moleman, A.J. Process Mining in Healthcare: Data Challenges When Answering Frequently Posed Questions. In Process Support and Knowledge Representation in Health Care; Springer: Berlin/Heidelberg, Germany, 2013; pp. 140–153. [Google Scholar]
- Emamjome, F.; Andrews, R.; ter Hofstede, A.; Reijers, H. Alohomora: Unlocking data quality causes through event log context. In Proceedings of the 28th European Conference on Information Systems (ECIS2020), Marrakech, Morocco, 15–17 June 2020; Association for Information Systems: Atlanta, GA, USA, 2020; pp. 1–16. [Google Scholar]
- Batini, C.; Scannapieco, M. Data Quality: Concepts, Methodologies and Techniques; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Wand, Y.; Wang, R.Y. Anchoring Data Quality Dimensions in Ontological Foundations. Commun. ACM 1996, 39, 86–95. [Google Scholar] [CrossRef]
- van der Aalst, W.M.P. Process Mining-Data Science in Action, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Wang, J.; Song, S.; Zhu, X.; Lin, X.; Sun, J. Efficient Recovery of Missing Events. IEEE Trans. Knowl. Data Eng. 2016, 28, 2943–2957. [Google Scholar] [CrossRef]
- Conforti, R.; Rosa, M.L.; ter Hofstede, A.H.M. Filtering Out Infrequent Behavior from Business Process Event Logs. IEEE Trans. Knowl. Data Eng. 2017, 29, 300–314. [Google Scholar] [CrossRef] [Green Version]
- van Zelst, S.J.; Fani Sani, M.; Ostovar, A.; Conforti, R.; La Rosa, M. Filtering Spurious Events from Event Streams of Business Processes. In Advanced Information Systems Engineering; Krogstie, J., Reijers, H.A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 35–52. [Google Scholar]
- Dixit, P.M.; Suriadi, S.; Andrews, R.; Wynn, M.T.; ter Hofstede, A.H.M.; Buijs, J.C.A.M.; van der Aalst, W.M.P. Detection and Interactive Repair of Event Ordering Imperfection in Process Logs. In Advanced Information Systems Engineering; Krogstie, J., Reijers, H.A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 274–290. [Google Scholar]
- Fani Sani, M.; van Zelst, S.J.; van der Aalst, W.M.P. Repairing Outlier Behaviour in Event Logs. In Business Information Systems; Springer International Publishing: Cham, Switzerland, 2018; pp. 115–131. [Google Scholar]
- Sani, M.F.; van Zelst, S.J.; van der Aalst, W.M.P. Applying Sequence Mining for Outlier Detection in Process Mining. On the Move to Meaningful Internet Systems. In Proceedings of the OTM 2018 Conferences-Confederated International Conferences: CoopIS, C&TC, and ODBASE 2018, Valletta, Malta, 22–26 October 2018; pp. 98–116. [Google Scholar]
- Tax, N.; Sidorova, N.; van der Aalst, W.M.P. Discovering more precise process models from event logs by filtering out chaotic activities. J. Intell. Inf. Syst. 2019, 52, 107–139. [Google Scholar] [CrossRef] [Green Version]
- Van Dongen, B.F.; de Medeiros, A.K.A.; Verbeek, H.; Weijters, A.; Van Der Aalst, W.M. The ProM framework: A new era in process mining tool support. In International Conference on Application and Theory of Petri Nets; Springer: Berlin/Heidelberg, Germany, 2005; pp. 444–454. [Google Scholar]
- van der Aalst, W.M.P.; Bolt, A.; van Zelst, S.J. RapidProM: Mine Your Processes and Not Just Your Data. arXiv 2017, arXiv:1703.03740. [Google Scholar]
- Bezerra, F.; Wainer, J. Anomaly Detection Algorithms in Logs of Process Aware Systems. In Proceedings of the 2008 ACM Symposium on Applied Computing, SAC’08, Fortaleza, Brazil, 16–20 March 2008; ACM: New York, NY, USA, 2008; pp. 951–952. [Google Scholar] [CrossRef]
- Jalali, H.; Baraani, A. Genetic-based anomaly detection in logs of process aware systems. World Acad. Sci. Eng. Technol. 2010, 64, 304–309. [Google Scholar]
- de Lima Bezerra, F.; Wainer, J. A Dynamic Threshold Algorithm for Anomaly Detection in Logs of Process Aware Systems. JIDM 2012, 3, 316–331. [Google Scholar] [CrossRef]
- Bezerra, F.; Wainer, J. Algorithms for Anomaly Detection of Traces in Logs of Process Aware Information Systems. Inf. Syst. 2013, 38, 33–44. [Google Scholar] [CrossRef]
- Cheng, H.; Kumar, A. Process mining on noisy logs-Can log sanitization help to improve performance? Decis. Support Syst. 2015, 79, 138–149. [Google Scholar] [CrossRef]
- Sani, M.F.; van Zelst, S.J.; van der Aalst, W.M.P. Improving Process Discovery Results by Filtering Outliers Using Conditional Behavioural Probabilities. In Proceedings of the Business Process Management Workshops-BPM 2017 International Workshops, Barcelona, Spain, 10–11 September 2017; pp. 216–229. [Google Scholar] [CrossRef]
- Bezerra, F.; Wainer, J.; van der Aalst, W.M.P. Anomaly Detection Using Process Mining. In Enterprise, Business-Process and Information Systems Modeling; Springer: Berlin/Heidelberg, Germany, 2009; pp. 149–161. [Google Scholar]
- Böhmer, K.; Rinderle-Ma, S. Multi-perspective Anomaly Detection in Business Process Execution Events. In Proceedings of the On the Move to Meaningful Internet Systems: OTM 2016 Conferences, Rhodes, Greece, 24–28 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 80–98. [Google Scholar]
- Kong, L.; Li, C.; Ge, J.; Li, Z.; Zhang, F.; Luo, B. An Efficient Heuristic Method for Repairing Event Logs Independent of Process Models. In Proceedings of the 4th International Conference on Internet of Things, Big Data and Security, Heraklion, Crete, Greece, 2–4 May 2019; Volume 1: IoTBDS, INSTICC. SciTePress: Setúbal, Portugal, 2019; pp. 83–93. [Google Scholar] [CrossRef]
- Sani, M.F.; van Zelst, S.J.; van der Aalst, W.M.P. Repairing Outlier Behaviour in Event Logs using Contextual Behaviour. Enterp. Model. Inf. Syst. Archit. Int. J. Concept. Model. 2019, 14, 5:1–5:24. [Google Scholar] [CrossRef]
- Song, S.; Cao, Y.; Wang, J. Cleaning Timestamps with Temporal Constraints. Proc. VLDB Endow. 2016, 9, 708–719. [Google Scholar] [CrossRef] [Green Version]
- Suriadi, S.; Andrews, R.; ter Hofstede, A.H.; Wynn, M.T. Event log imperfection patterns for process mining: Towards a systematic approach to cleaning event logs. Inf. Syst. 2017, 64, 132–150. [Google Scholar] [CrossRef]
- Hsu, P.Y.; Chuang, Y.C.; Lo, Y.C.; He, S.C. Using contextualized activity-level duration to discover irregular process instances in business operations. Inf. Sci. 2017, 391–392, 80–98. [Google Scholar] [CrossRef]
- Tax, N.; Alasgarov, E.; Sidorova, N.; van der Aalst, W.M.P.; Haakma, R. Time-Based Label Refinements to Discover More Precise Process Models. arXiv 2017, arXiv:1705.09359. [Google Scholar] [CrossRef] [Green Version]
- Andreas, R.S.; Ronny, S.; van der Aalst, W.M.P.; Mathias, W. Repairing Event Logs Using Timed Process Models. In Proceedings of the On the Move to Meaningful Internet Systems: OTM 2013 Workshops, Graz, Austria, 9–13 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 705–708. [Google Scholar]
- Fischer, D.A.; Goel, K.; Andrews, R.; van Dun, C.; Wynn, M.; Röglinger, M. Enhancing Event Log Quality: Detecting and Quantifying Timestamp Imperfections. In Proceedings of the Business Process Management: 18th International Conference BPM 2020, Seville, Spain, 13–18 September 2020; Springer: Cham, Switzerland, 2020; Volume 392, pp. 309–326. [Google Scholar]
- Song, M.; Günther, C.W.; van der Aalst, W.M.P. Trace Clustering in Process Mining. In Business Process Management Workshops; Ardagna, D., Mecella, M., Yang, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 109–120. [Google Scholar]
- Bose, R.P.J.C.; van der Aalst, W.M.P. Trace Clustering Based on Conserved Patterns: Towards Achieving Better Process Models. In Business Process Management Workshops; Rinderle-Ma, S., Sadiq, S., Leymann, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 170–181. [Google Scholar]
- Evermann, J.; Thaler, T.; Fettke, P. Clustering Traces Using Sequence Alignment. In Business Process Management Workshops; Reichert, M., Reijers, H.A., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 179–190. [Google Scholar]
- Xu, J.; Liu, J. A Profile Clustering Based Event Logs Repairing Approach for Process Mining. IEEE Access 2019, 7, 17872–17881. [Google Scholar] [CrossRef]
- Bose, R.P.J.C.; van der Aalst, W.M.P. Context Aware Trace Clustering: Towards Improving Process Mining Results. In Proceedings of the SIAM International Conference on Data Mining, SDM 2009, Sparks, NV, USA, 30 April–2 May 2009; pp. 401–412. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Zhang, L.; Cai, H. Using Suffix-Tree to Identify Patterns and Cluster Traces from Event Log. In Signal Processing and Information Technology; Springer: Berlin/Heidelberg, Germany, 2012; pp. 126–131. [Google Scholar]
- Jagadeesh Chandra Bose, R. Process Mining in the Large: Preprocessing, Discovery, and Diagnostics. Ph.D. Thesis, Department of Mathematics and Computer Science, Eindhoven, The Netherlands, 2012. [Google Scholar] [CrossRef]
- Hompes, B.; Buijs, J.; van der Aalst, W.; Dixit, P.; Buurman, J. Discovering deviating cases and process variants using trace clustering. In Proceedings of the 27th Benelux Conference on Artificial Intelligence, Hasselt, Belgium, 5–6 November 2015. [Google Scholar]
- Sun, Y.; Bauer, B.; Weidlich, M. Compound Trace Clustering to Generate Accurate and Simple Sub-Process Models. In Service-Oriented Computing; Springer International Publishing: Cham, Switzerland, 2017; pp. 175–190. [Google Scholar]
- Greco, G.; Guzzo, A.; Pontieri, L.; Sacca, D. Discovering expressive process models by clustering log traces. IEEE Trans. Knowl. Data Eng. 2006, 18, 1010–1027. [Google Scholar] [CrossRef]
- Ferreira, D.; Zacarias, M.; Malheiros, M.; Ferreira, P. Approaching Process Mining with Sequence Clustering: Experiments and Findings. In Proceedings of the 5th International Conference on Business Process Management, BPM’07, Brisbane, Australia, 24–28 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 360–374. [Google Scholar]
- de Medeiros, A.K.A.; Guzzo, A.; Greco, G.; van der Aalst, W.M.P.; Weijters, A.J.M.M.; van Dongen, B.F.; Saccà, D. Process Mining Based on Clustering: A Quest for Precision. In Business Process Management Workshops; ter Hofstede, A., Benatallah, B., Paik, H.Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 17–29. [Google Scholar]
- De Weerdt, J.; vanden Broucke, S.; Vanthienen, J.; Baesens, B. Active Trace Clustering for Improved Process Discovery. IEEE Trans. Knowl. Data Eng. 2013, 25, 2708–2720. [Google Scholar] [CrossRef]
- Nguyen, P.; Slominski, A.; Muthusamy, V.; Ishakian, V.; Nahrstedt, K. Process Trace Clustering: A Heterogeneous Information Network Approach. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 279–287. [Google Scholar] [CrossRef] [Green Version]
- Folino, F.; Greco, G.; Guzzo, A.; Pontieri, L. Mining Usage Scenarios in Business Processes: Outlier-aware Discovery and Run-time Prediction. Data Knowl. Eng. 2011, 70, 1005–1029. [Google Scholar] [CrossRef]
- Chatain, T.; Carmona, J.; van Dongen, B. Alignment-Based Trace Clustering. In Conceptual Modeling; Mayr, H.C., Guizzardi, G., Ma, H., Pastor, O., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 295–308. [Google Scholar]
- Boltenhagen, M.; Chatain, T.; Carmona, J. Generalized Alignment-Based Trace Clustering of Process Behavior. In Application and Theory of Petri Nets and Concurrency; Donatelli, S., Haar, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 237–257. [Google Scholar]
- Ukkonen, E. On-Line Construction of Suffix Trees. Algorithmica 1995, 14, 249–260. [Google Scholar] [CrossRef]
- Ghionna, L.; Greco, G.; Guzzo, A.; Pontieri, L. Outlier Detection Techniques for Process Mining Applications. In Foundations of Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 150–159. [Google Scholar]
- Chapela-Campa, D.; Mucientes, M.; Lama, M. Discovering Infrequent Behavioral Patterns in Process Models. In Business Process Management; Carmona, J., Engels, G., Kumar, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 324–340. [Google Scholar]
- Jagadeesh Chandra Bose, R.P.; van der Aalst, W.M.P. Abstractions in Process Mining: A Taxonomy of Patterns. In Business Process Management; Dayal, U., Eder, J., Koehler, J., Reijers, H.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 159–175. [Google Scholar]
- Günther, C.W.; van der Aalst, W.M.P. Fuzzy Mining–Adaptive Process Simplification Based on Multi-perspective Metrics. In Business Process Management; Alonso, G., Dadam, P., Rosemann, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 328–343. [Google Scholar]
- Gu, C.-Q.; Chang, H.-Y.; Yi, Y. Workflow mining: Extending the alpha algorithm to mine duplicate tasks. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 10 January 2008; Volume 1, pp. 361–368. [Google Scholar] [CrossRef]
- Folino, F.; Greco, G.; Guzzo, A.; Pontieri, L. Discovering Expressive Process Models from Noised Log Data. In Proceedings of the 2009 International Database Engineering & Applications Symposium, IDEAS’09, Calabria, Italy, 16–18 September 2009; ACM: New York, NY, USA, 2009; pp. 162–172. [Google Scholar] [CrossRef]
- Weijters, A.J.M.M.; Ribeiro, J.T.S. Flexible Heuristics Miner (FHM). In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 310–317. [Google Scholar] [CrossRef] [Green Version]
- Leemans, S.J.J.; Fahland, D.; van der Aalst, W.M.P. Discovering Block-Structured Process Models from Event Logs Containing Infrequent Behaviour. In Proceedings of the Business Process Management Workshops-BPM 2013 International Workshops, Beijing, China, 26 August 2013; pp. 66–78. [Google Scholar] [CrossRef]
- Leemans, S.J.J.; Fahland, D.; van der Aalst, W.M.P. Discovering Block-Structured Process Models from Incomplete Event Logs. In Application and Theory of Petri Nets and Concurrency; Ciardo, G., Kindler, E., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 91–110. [Google Scholar]
- Mannhardt, F.; de Leoni, M.; Reijers, H.A.; van der Aalst, W.M.P. Data-Driven Process Discovery—Revealing Conditional Infrequent Behavior from Event Logs. In Advanced Information Systems Engineering; Dubois, E., Pohl, K., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 545–560. [Google Scholar]
- vanden Broucke, S.K.; Weerdt, J.D. Fodina: A robust and flexible heuristic process discovery technique. Decis. Support Syst. 2017, 100, 109–118. [Google Scholar] [CrossRef]
- Jagadeesh Chandra Bose, R.P.; van der Aalst, W. Trace Alignment in Process Mining: Opportunities for Process Diagnostics. In Business Process Management; Hull, R., Mendling, J., Tai, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 227–242. [Google Scholar]
- van Dongen, B.F.; Adriansyah, A. Process Mining: Fuzzy Clustering and Performance Visualization. In Business Process Management Workshops; Rinderle-Ma, S., Sadiq, S., Leymann, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 158–169. [Google Scholar]
- Günther, C.W.; Rozinat, A.; van der Aalst, W.M.P. Activity Mining by Global Trace Segmentation. In Business Process Management Workshops; Springer: Berlin/Heidelberg, Germany, 2010; pp. 128–139. [Google Scholar]
- Bose, R.J.C.; van der Aalst, W.M. Process diagnostics using trace alignment: Opportunities, issues, and challenges. Inf. Syst. 2012, 37, 117–141. [Google Scholar] [CrossRef]
- de Leoni, M.; Maggi, F.M.; van der Aalst, W.M.P. Aligning Event Logs and Declarative Process Models for Conformance Checking. In Business Process Management; Barros, A., Gal, A., Kindler, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 82–97. [Google Scholar]
- Rogge-Solti, A.; Mans, R.S.; van der Aalst, W.M.P.; Weske, M. Improving Documentation by Repairing Event Logs. In The Practice of Enterprise Modeling; Grabis, J., Kirikova, M., Zdravkovic, J., Stirna, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 129–144. [Google Scholar]
- Baier, T.; Mendling, J. Bridging Abstraction Layers in Process Mining by Automated Matching of Events and Activities. In Business Process Management; Daniel, F., Wang, J., Weber, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 17–32. [Google Scholar]
- Lu, X.; Fahland, D.; van der Aalst, W.M.P. Conformance Checking Based on Partially Ordered Event Data. In Business Process Management Workshops; Fournier, F., Mendling, J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 75–88. [Google Scholar]
- Song, W.; Xia, X.; Jacobsen, H.; Zhang, P.; Hu, H. Heuristic Recovery of Missing Events in Process Logs. In Proceedings of the 2015 IEEE International Conference on Web Services, New York, NY, USA, 27 June–2 July 2015; pp. 105–112. [Google Scholar] [CrossRef]
- Lu, X.; Fahland, D.; van der Aalst, W.M.P. Interactively Exploring Logs and Mining Models with Clustering, Filtering, and Relabeling. In Proceedings of the BPM Demo Track 2016 Co-located with the 14th International Conference on Business Process Management (BPM 2016), Rio de Janeiro, Brazil, 21 September 2016; pp. 44–49. [Google Scholar]
- Sun, Y.; Bauer, B. A Graph and Trace Clustering-based Approach for Abstracting Mined Business Process Models. In Proceedings of the 18th International Conference on Enterprise Information Systems, ICEIS 2016, Rome, Italy, 25–28 April 2016; SCITEPRESS-Science and Technology Publications: Lda, Portugal, 2016; pp. 63–74. [Google Scholar] [CrossRef]
- Mannhardt, F.; de Leoni, M.; Reijers, H.A.; van der Aalst, W.M.P.; Toussaint, P.J. From Low-Level Events to Activities—A Pattern-Based Approach. In Business Process Management; La Rosa, M., Loos, P., Pastor, O., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 125–141. [Google Scholar]
- Song, W.; Xia, X.; Jacobsen, H.a.; Zhang, P.; Hu, H. Efficient Alignment Between Event Logs and Process Models. IEEE Trans. Serv. Comput. 2016, 10, 136–149. [Google Scholar] [CrossRef]
- Mannhardt, F.; Tax, N. Unsupervised Event Abstraction using Pattern Abstraction and Local Process Models. In Proceedings of the Radar tracks at the 18th International Working Conference on Business Process Modeling, Development and Support (BPMDS), Essen, Germany, 12–13 June 2017; pp. 55–63. [Google Scholar]
- Tax, N.; Sidorova, N.; Haakma, R.; van der Aalst, W.M.P. Event Abstraction for Process Mining Using Supervised Learning Techniques. In Proceedings of the SAI Intelligent Systems Conference (IntelliSys), London, UK, 21–22 September 2016; Bi, Y., Kapoor, S., Bhatia, R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 251–269. [Google Scholar]
- Alharbi, A.M. Unsupervised Abstraction for Reducing the Complexity of Healthcare Process Models. Ph.D. Thesis, School of Computing, University of Leeds, Leeds, UK, 2019. [Google Scholar]
- Huang, Y.; Zhong, L.; Chen, Y. Filtering Infrequent Behavior in Business Process Discovery by Using the Minimum Expectation. Int. J. Cogn. Informatics Nat. Intell. (IJCINI) 2020, 14, 1–15. [Google Scholar] [CrossRef]
- Vidgof, M.; Djurica, D.; Bala, S.; Mendling, J. Cherry-Picking from Spaghetti: Multi-Range Filtering of Event Logs; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2020; Volume 387, pp. 135–149. [Google Scholar] [CrossRef]
- Denisov, V.; Fahland, D.; Aalst, W. Repairing Event Logs with Missing Events to Support Performance Analysis of Systems with Shared Resources. In Petri Nets 2020; Springer: Paris, France, 2020. [Google Scholar]
- Workflow and Case Management. 2009. Available online: www.lexmark.com (accessed on 21 January 2021).
- Interstage Business Process Manager Analytics By Fujitsu Ltd. 2009. Available online: www.fujitsu.com (accessed on 18 October 2020).
- Minit By Gradient ECM. 2015. Available online: https://golden.com/wiki/Minit-5NNVAR (accessed on 20 April 2021).
- myInvenio By Cognitive Technology. 2016. Available online: www.my-invenio.com (accessed on 21 January 2021).
- T.A. Foundation. Apromore-Advanced Process Analytics Platform. The University of Melbourne, 2011. Available online: https://apromore.org/ (accessed on 19 April 2021).
- Celonis, S.E.; Munich, G. Celonis Process Mining; CELONIS: New York, NY, USA, 2009; Available online: https://www.celonis.com/ (accessed on 19 April 2021).
- Mans, R.; van der Aalst, W.; Verbeek, H. Supporting process mining workflows with RapidProM. In Proceedings of the BPM Demo Sessions 2014 co-located with BPM 2014, Eindhoven, The Netherlands, 20 September 2014; Limonad, L., Weber, B., Eds.; pp. 56–60. [Google Scholar]
- BV, F. Discover Your Processes. Fluxicon Process Mining for Professionals. 2011. Available online: https://fluxicon.com/disco/ (accessed on 20 April 2021).
- Gschwandtner, T.; Aigner, W.; Miksch, S.; Gärtner, J.; Kriglstein, S.; Pohl, M.; Suchy, N. TimeCleanser: A visual analytics approach for data cleansing of time-oriented data. In Proceedings of the 14th International Conference on Knowledge Management and Data-Driven Business, I-KNOW’14, Graz, Austria, 16–19 September 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Li, G.; van der Aalst, W. A framework for detecting deviations in complex event logs. Intell. Data Anal. 2017, 21, 759–779. [Google Scholar] [CrossRef] [Green Version]
- Sani, M.F.; Berti, A.; van Zelst, S.J.; van der Aalst, W.M.P. Filtering Toolkit: Interactively Filter Event Logs to Improve the Quality of Discovered Models. In Proceedings of the Dissertation Award, Doctoral Consortium, and Demonstration Track at BPM 2019, Vienna, Austria, 1–6 September 2019; Volume 2420, pp. 134–138. [Google Scholar]
- Wang, J.; Song, S.; Lin, X.; Zhu, X.; Pei, J. Cleaning structured event logs: A graph repair approach. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 30–41. [Google Scholar] [CrossRef]
- Mueller-Wickop, N.; Schultz, M. ERP Event Log Preprocessing: Timestamps vs. Accounting Logic. In Design Science at the Intersection of Physical and Virtual Design; vom Brocke, J., Hekkala, R., Ram, S., Rossi, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 105–119. [Google Scholar]
- van Zelst, S.; Mannhardt, F.; de Leoni, M.; Koschmider, A. Event Abstraction in Process Mining -Literature Review and Taxonomy. Granul. Comput. 2020. [Google Scholar] [CrossRef]
- de Leoni, M.; van der Aalst, W.M.P. Aligning Event Logs and Process Models for Multi-perspective Conformance Checking: An Approach Based on Integer Linear Programming. In Business Process Management; Daniel, F., Wang, J., Weber, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 113–129. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Search String | IEEE Xplore | Springer Link | Science Direct |
|---|---|---|---|
| (“filtering” OR “cleaning” OR “repairing” OR “clustering” OR “refinement” OR “preprocessing”) “event log” “process mining” | 110 | 32,440 | 310 |
| (“filtering” OR “cleaning” OR “repairing” OR “clustering” OR “refinement” OR “preprocessing”) “trace” “process mining” | 227 | 63,897 | 401 |
| (“ordered” OR “aligning”) “event log” “process mining” | 139 | 41,385 | 213 |
| (“anomalous detection” OR “infrequent behavior” OR “noisy” OR “imperfection”) “event log” “process mining” | 16 | 1813 | 87 |
| (“anomalous detection” OR “infrequent behavior” OR “noisy” OR “imperfection”) “trace” “process mining” | 24 | 2106 | 95 |
| ID | Characteristic | Description |
|---|---|---|
| Techniques | Two main families of techniques: (1) transformation techniques and (2) detection and visualization techniques | |
| Tools | ProM, Disco, RapidProM, Celonis, Apromore, RapidMiner, Java application, preprocessing framework | |
| Representation schemes | Sequences of events/traces or vectors, graphs, automatons | |
| Imperfection types | Form-based event capture, inadvertent time travel, unanchored event, scattered event, elusive case, scattered case, collateral events, polluted label, distorted label, synonymous labels, homonymous label, timestamp granularity, unusual temporal ordering | |
| Related tasks | Two types: event abstraction and alignment | |
| Types of information | Event label, timestamp, ID, cost, resource, additional event payload |
| Year | Authors | Ref | Model | Approach | Algorithms |
|---|---|---|---|---|---|
| 2019 | Boltenhagen et al. | [50] | Framework for trace clustering of process behavior | Based on generalized alignment | Trace clustering ATC, APOTC, or AMSTC |
| 2019 | Xu and Liu | [37] | Trace clustering using log profiles | Based on trace profiles and missing trace profiles | Self-Organizing Map (SOM) |
| 2017 | Chatain et al. | [49] | Technique trace clustering | Based on the concept of multi-alignments, which groups log traces according to representative full runs of a given model, considering the problem of alignment | A pseudo-Boolean solver Min− isat+ |
| 2017 | Yaguang et al. | [42] | Compound trace clustering | Convert the trace clustering problem based on notion of similarity trace into a clustering problem guided by the complexity of the sub-process modes derived from sub-logs | (1) context aware trace clustering technique (GED); (2) sequence clustering technique (SCT); (3) flexible heuristic miner (FHM) to discover process models (4) HIF algorithm to locate behavioral patterns recorded in the event log |
| 2016 | Evermann et al. | [36] | K-means trace clustering | Based on local alignment of sequences and subsequent multidimensional scaling | Smith–Waterman–Gotoh algorithm for sequence alignment, k-means clustering |
| 2016 | Nguyen et al. | [47] | Hierarchical trace clustering | Using the process traces representation to reduce the high dimensionality of event logs | (1) Greedy approximation algorithm based on extensible heterogeneous information networks (HINs). (2) Heuristics miner |
| 2015 | B. Hompes et al. | [41] | Trace clustering | Finding variations and deviations of a process based on a set of selected perspectives | Markov cluster (MCL) algorithm |
| 2013 | De Weerdt et al. | [46] | Active trace clustering | Based on a top-down greedy approach inspired in active learning to solve the problem of finding an optimal distribution of execution traces over a given number of clusters | (1) A selective sampling strategy; (2) Heuristics miner |
| 2012 | R. Jagadeesh et al. | [40] | Trace clustering | A context-aware approach by defining process-centric feature and syntactic methods based on edit distance | Agglomerative hierarchical clustering algorithm |
| 2011 | Folino et al. | [48] | Markov, k-means and agglomerative hierarchical aware clustering | Based on the similarity criterion among the traces via a special kind of frequent structural patterns, which are preliminary discovered as an evidence of “normal” behavior | (1) Decision-tree algorithm; (2). OASC: an algorithm for detecting outliers in a process log; (3) LearnDADT: an algorithm for inducing a DADT model |
| 2011 | Wang et al. | [39] | Suffix tree clustering | A context aware approach for identifying patterns that occur in traces. It uses a suffix-tree based approach to categorize transformed traces into clusters | (1) An equivalent of a single-link algorithm to group base clusters into end clusters; (2) Alpha++ mining algorithm to generate process models of clusters |
| 2010 | Chandra Bose and van der Aalst | [35] | Agglomerative hierarchical trace clustering | Based on multiple feature sets for trace clustering considering sub-sequences of activities conserved across multiple traces | (1) Ukkonen algorithm [51] for the construction of suffix-trees in linear-time; (2) Heuristics Miner algorithm to evaluate the goodness of clusters |
| 2009 | Jagadeesh and van der Aalst | [38] | Agglomerative hierarchical trace clustering | Based on: (a) bag-of-activities, (b) k-gram model, (c) Levenshtein distance, and (d) generic edit distance | (1) Algorithm to maximize the score of two sequences based on the similarity; (2) algorithm to generates the scores for the insertion of activities; and (3) algorithm to evaluate the significance of clusters |
| 2008 | Minseok et al. | [34] | Trace clustering using Log profiles | Based on the divide and conquer approach in which profiles measure a number of features for each case | (1) k-Means; (2) quality threshold (QT); (3) agglomerative hierarchical clustering, (4) self-organizing maps (SOM) |
| 2008 | A. K. A. de Medeiros et al. | [45] | Trace clustering algorithm that avoids over-generalization | Iteratively splitting the log in clusters | K-means clustering algorithm |
| 2007 | Ferreira et al. | [44] | Sequence clustering | This approach is useful in new scenarios, where the business process analyst may not be familiar with, or where the potential for process mining is yet uncertain | Sequence clustering algorithm based on first-order Markov chains, expectation-maximization (EM) algorithm |
| 2006 | Greco et al. | [43] | Hierarchical trace clustering | Based on an iterative hierarchical refinement of a disjunctive schema | A greedy strategy |
| Ref | Tech | Tools | Task | Representation | Problem | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| D | C | E | mis | noi | div | irr | dup | ||||
| [43], 2006 | A2 | ProM | ✓ | ✓ | Dependency graph | ✓ | |||||
| [44], 2007 | A2 | Application | Sequences of activities | ✓ | |||||||
| [55], 2007 | A1,B2 | Fuzzy Miner in ProM | ✓ | Graphs | ✓ | ||||||
| [52], 2008 | A3,A1,A2 | Prototype system in Java | ✓ | ✓ | ✓ | Graphs | ✓ | ||||
| [34], 2008 | A2 | ProM | ✓ | Self-Organizing map (SOM) | ✓ | ||||||
| [56], 2008 | A4 | – | ✓ | SWF-nets | ✓ | ||||||
| [18], 2008 | A1 | – | ✓ | Sequences of graphs and traces | ✓ | ||||||
| [45], 2008 | A2 | ProM | ✓ | Sequences of events | ✓ | ||||||
| [24], 2009 | A1 | ProM | ✓ | Sequences of traces | ✓ | ||||||
| [54], 2009 | A3,B2 | ProM | ✓ | Sets of traces | ✓ | ||||||
| [38], 2009 | A2 | – | ✓ | K-gram model | ✓ | ||||||
| [57], 2009 | A4 | Enhanced-WFMiner | ✓ | Workflow schema | ✓ | ✓ | ✓ | ||||
| [35], 2010 | A2,A3 | – | ✓ | Context-aware feature sets | ✓ | ||||||
| [63], 2010 | B1 | ProM | ✓ | ✓ | Sets of traces | ✓ | ✓ | ||||
| [19], 2010 | A1 | ProM | ✓ | Sequences of traces | ✓ | ||||||
| [64], 2010 | B2,A2 | ProM | ✓ | Graphs Simple Precedence Diagram | ✓ | ||||||
| [65],2010 | B2,A2 | Stream Scope in Prom | ✓ | Sequences of events | ✓ | ||||||
| [58], 2011 | A4 | ProM | ✓ | Augmented-C-nets | ✓ | ||||||
| [48], 2011 | A2,A3 | Java prototype | ✓ | Set of traces | ✓ | ||||||
| [39], 2012 | A2,A3 | ProM | ✓ | Suffix-Trees | ✓ | ✓ | |||||
| [66], 2012 | B1 | ProM | ✓ | ✓ | Sequences of traces | ✓ | ✓ | ||||
| [40], 2012 | A2,A1,B2 | ProM | ✓ | ✓ | Sequences of traces | ✓ | ✓ | ||||
| [20], 2012 | A1 | ProM | ✓ | ✓ | ✓ | ✓ | |||||
| [67], 2012 | B1 | ProM | ✓ | Constraint Automaton | ✓ | ||||||
| [46], 2013 | A2 | ActiTraC in ProM 6 | ✓ | Sequences of traces | ✓ | ||||||
| [68], 2013 | B1,A5 | ProM | ✓ | Bayesian networks | ✓ | ||||||
| [59], 2013 | A4 | ProM | ✓ | Graphs | ✓ | ✓ | |||||
| [32], 2013 | A1,B1 | ✓ | Sequences of traces | ✓ | |||||||
| [21], 2013 | A1,B1 | Algorithms in ProM | ✓ | ✓ | Sequences of traces | ✓ | |||||
| [69], 2013 | B2 | ProM | ✓ | ✓ | ✓ | Sequence of activity instances | ✓ | ||||
| [60], 2014 | A4 | IMi in ProM | ✓ | Process trees | ✓ | ✓ | |||||
| [22], 2015 | A1 | Weka tool for creating rules | ✓ | Sequences of traces | ✓ | ||||||
| [70], 2015 | B1 | ProM | ✓ | Partially ordered traces | ✓ | ✓ | |||||
| [71], 2015 | B1,A1 | - | ✓ | ✓ | Workflow nets | ✓ | |||||
| [41], 2015 | A2 | ProM | Sequences of traces | ✓ | |||||||
| [36], 2016 | A2,B1 | Java application (AlignCluster) and ProM | ✓ | Sequences of traces | ✓ | ||||||
| [47], 2016 | A2 | – | ✓ | Heterogeneous graph | ✓ | ✓ | |||||
| [9], 2016 | A1,B1 | Java programs | ✓ | ✓ | Sequences of events | ✓ | |||||
| [72], 2016 | A2,A1 | TraceMatching tool in ProM | ✓ | Sequences of traces | ✓ | ✓ | |||||
| [28], 2016 | A5 | - | ✓ | Temporal networks | ✓ | ||||||
| [73], 2016 | B2,A2 | - | ✓ | Casual activity graphs | ✓ | ||||||
| [25], 2016 | A1 | Prototypical implementation | Likelihood graphs | ✓ | ✓ | ✓ | |||||
| [74], 2016 | B2,B1,A3 | ProM | ✓ | Sequence of events | ✓ | ✓ | |||||
| [75], 2016 | B1 | General framework and plugin Effa of ProM | ✓ | ✓ | ✓ | Sequence of event and graphs | ✓ | ✓ | ✓ | ||
| [10], 2017 | A1 | ProM | ✓ | Log automaton | ✓ | ✓ | |||||
| [29], 2017 | A3 | Disco | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| [76],2017 | B2,A3,A2 | - | ✓ | Sequence of events | ✓ | ||||||
| [23], 2017 | A1 | ProM, RapidProM | ✓ | ✓ | Sequences of activities | ✓ | ✓ | ||||
| [30], 2017 | A5 | – | ✓ | Acyclic graphs | ✓ | ✓ | |||||
| [31], 2017 | B2,A5 | Framework | ✓ | Sequences of traces | ✓ | ||||||
| [53], 2017 | A3 | WoMine-i app | ✓ | Causal nets | |||||||
| [61], 2017 | A4 | DHM in ProM | ✓ | Causal nets | ✓ | ||||||
| [42], 2017 | A2 | (CTC) Compound Trace Clustering | ✓ | ✓ | Sequences of traces | ✓ | |||||
| [49], 2017 | A2,B1 | tool DarkSider | ✓ | ✓ | Process model rendered traces | ✓ | ✓ | ||||
| [62], 2017 | A4 | Fodina | ✓ | Causal nets | ✓ | ✓ | |||||
| [14], 2018 | A1 | ProM, RapidProM | ✓ | Sequences of activities | ✓ | ||||||
| [12], 2018 | A1,A5 | ProM | ✓ | Sequences of activities | ✓ | ||||||
| [77], 2018 | B2 | ProM | ✓ | ✓ | Feature vectors | ✓ | |||||
| [11], 2018 | A1 | ProM and RapidProM | ✓ | ✓ | Probabilistic automata | ✓ | |||||
| [13], 2018 | A1 | ProM and RapidProM | ✓ | Sequences of activities | ✓ | ||||||
| [15], 2019 | A1 | RapidProM | ✓ | Sequences of activities | ✓ | ||||||
| [37], 2019 | A2 | Framework for missing event log | ✓ | Profiles-trace vector | ✓ | ||||||
| [50], 2019 | A2,B1 | Prototype tool | ✓ | ✓ | Sequence of traces | ||||||
| [26], 2019 | A1 | Java application | ✓ | Without loop traces | ✓ | ✓ | |||||
| [27], 2019 | A1 | Prom, RapidProM | ✓ | Sequences of activities | ✓ | ✓ | |||||
| [78], 2019 | B2,A5 | ProM | ✓ | Sequences of events | ✓ | ✓ | |||||
| [79], 2020 | A1 | – | ✓ | Accessibility matrix | ✓ | ✓ | |||||
| [80], 2020 | A1 | PM4Py library based Prototype | ✓ | Sequence of events | ✓ | ||||||
| [33], 2020 | A5 | ProM | ✓ | ✓ | ✓ | Sequence of events | ✓ | ✓ | ✓ | ✓ | ✓ |
| [81], 2020 | A5 | ProM | ✓ | ✓ | Sequence of events | ✓ | |||||
| Features | Prom 6.5.1 | Apromore | RapidProM | Disco | Celonis |
|---|---|---|---|---|---|
| Trace/event Filtering | Yes | Yes | Yes | Yes | Yes |
| Trace clustering | Yes | Yes | Yes | No | Yes |
| Timestamp repair | Yes | Yes | Yes | Yes | No |
| Remove attributes, events or activities | Yes | Yes | Yes | Yes | No |
| Embedded preprocessing | Yes | No | Yes | No | No |
| Abstraction | Yes | No | No | No | No |
| Alignment | Yes | Yes | Yes | No | No |
| Techniques (C1) | Tools (C2) | Representation Schemes (C3) | Imperfection Types (C4) | Related Tasks (C5) | Information Type (C6) |
|---|---|---|---|---|---|
| Filtering-based | ProM, Apromore, RapidProM, Disco, Celonis | sequences of traces/activities | noise and missing data | alignment | traces |
| Time-based | ProM, Apromore, RapidProM, Disco | graph structure and sequences of events | missing, noise, diverse, and duplicate data | abstraction | time attribute |
| Clustering | ProM, RapidProM Disco, Celonis | sequences of traces/events | noise and diversity data | abstraction | traces |
| pattern-based | ProM | raw event log | noise and diversity data | abstraction/alignment | traces |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marin-Castro, H.M.; Tello-Leal, E. Event Log Preprocessing for Process Mining: A Review. Appl. Sci. 2021, 11, 10556. https://doi.org/10.3390/app112210556
Marin-Castro HM, Tello-Leal E. Event Log Preprocessing for Process Mining: A Review. Applied Sciences. 2021; 11(22):10556. https://doi.org/10.3390/app112210556
Chicago/Turabian StyleMarin-Castro, Heidy M., and Edgar Tello-Leal. 2021. "Event Log Preprocessing for Process Mining: A Review" Applied Sciences 11, no. 22: 10556. https://doi.org/10.3390/app112210556