
Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning


Abstract
:1. Introduction
- We develop a novel and interpretable neural architecture for the high-level controller to derive the spatial and temporal latent features of the dynamic target and output continuous tracking speed commands directly. This compact architecture reduces the number of parameters of the high-level controller.
- End-to-end mapping from raw images to the high-level decision is trained via deep RL in the virtual environment based on V-REP [21]. We also leverage PyRep [22] to accelerate the simulation speed and run parallel environments for faster data collection. The simulation data are inexpensive, and no effort for ground-truth labeling is needed.
- To further accelerate the training process, we adopt auxiliary segmentation and motion-in-depth losses, which can generate denser training signals.
- Augmentation techniques are applied in the virtual environment to increase the robustness of the trained controller.
2. Preliminary Considerations
2.1. Markov Decision Process
2.2. Proximal Policy Optimization Algorithm
2.3. Generalized Advantage Estimation
3. Methodology
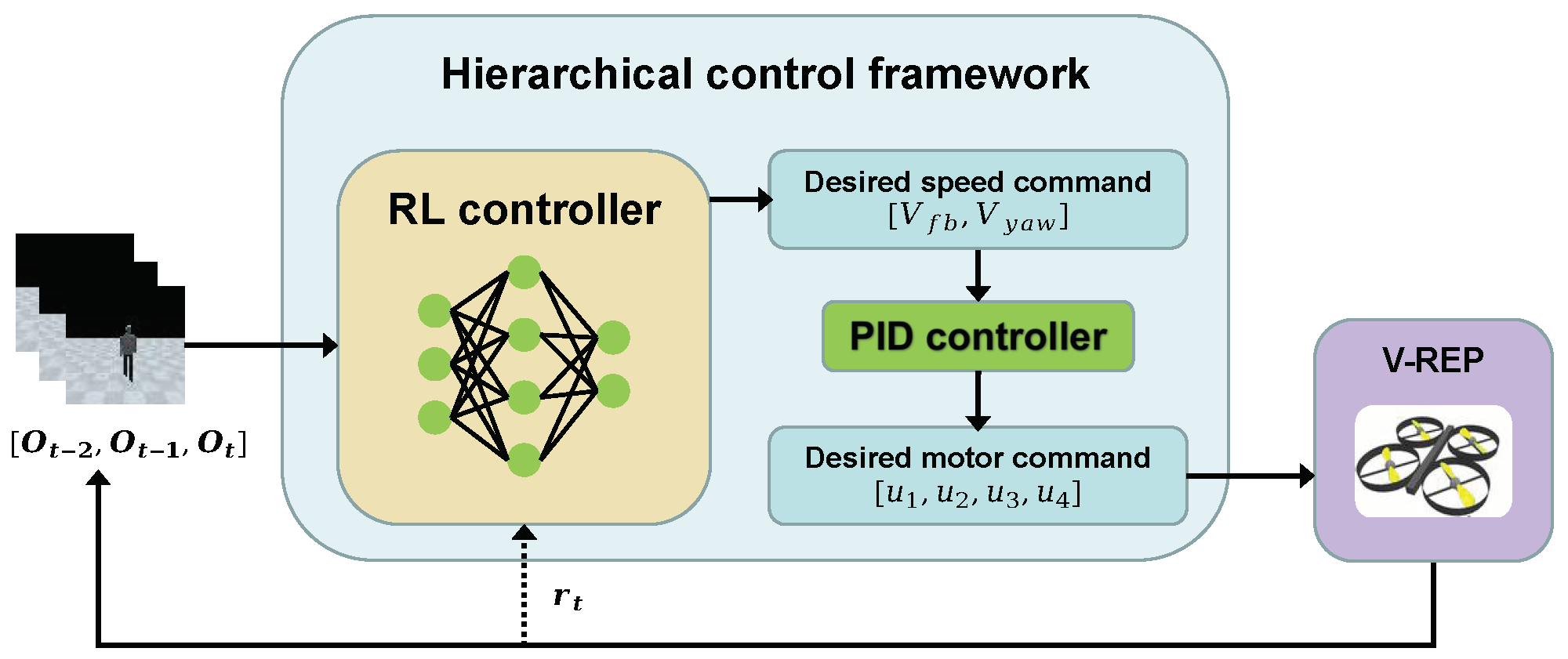
3.1. Hierarchical Control Framework
3.2. Simulator Set-Up and Augmentation
- Visual randomization: We divide the appearance of the target person into five parts—hair, skin, shirt, trousers, and shoes. Then, we change the color of each part at every timestep, which is helpful to learn the dynamic target’s more essential features rather than simply memorizing the colors.
- Speed randomization: To learn an RL controller that is less sensitive to the target’s velocity, we change the walking speed of the target person at every timestep in the interval uniformly.
- Path randomization: To increase the robustness of the RL controller to the gestures and relative position of the target, we randomly sample n control points between the beginning and the end of the path and then generate a smooth trajectory using a B-spline for every training episode. The target person will follow the random trajectories under control.
3.3. RL Controller Architecture
3.3.1. Attention-Based Spatial Feature Encoder
3.3.2. Feature Difference-Based Temporal Feature Encoder
3.3.3. Decision-Making and Value-Fitting Layer
3.4. Reward Engineering
3.5. Auxiliary Segmentation and Motion-in-Depth Loss
3.5.1. Auxiliary Segmentation Loss
3.5.2. Auxiliary Motion-in-Depth Loss
4. Experiments
4.1. Training
4.1.1. Environment Settings
- The dynamic target is out of the view of the quadrotor.
- The distance between the target and the quadrotor is out of the interval of [2, 4] m.
- The target reaches its end position.
4.1.2. Implementation Details
| Algorithm 1:PPO with auxiliary losses. |
 |
4.1.3. Ablation Studies in the Learning Process
- The proposed hierarchical active tracking controller framework, which uses the RL controller for perception and high-level decision-making, and the PID controller is used for low-level dynamic control.
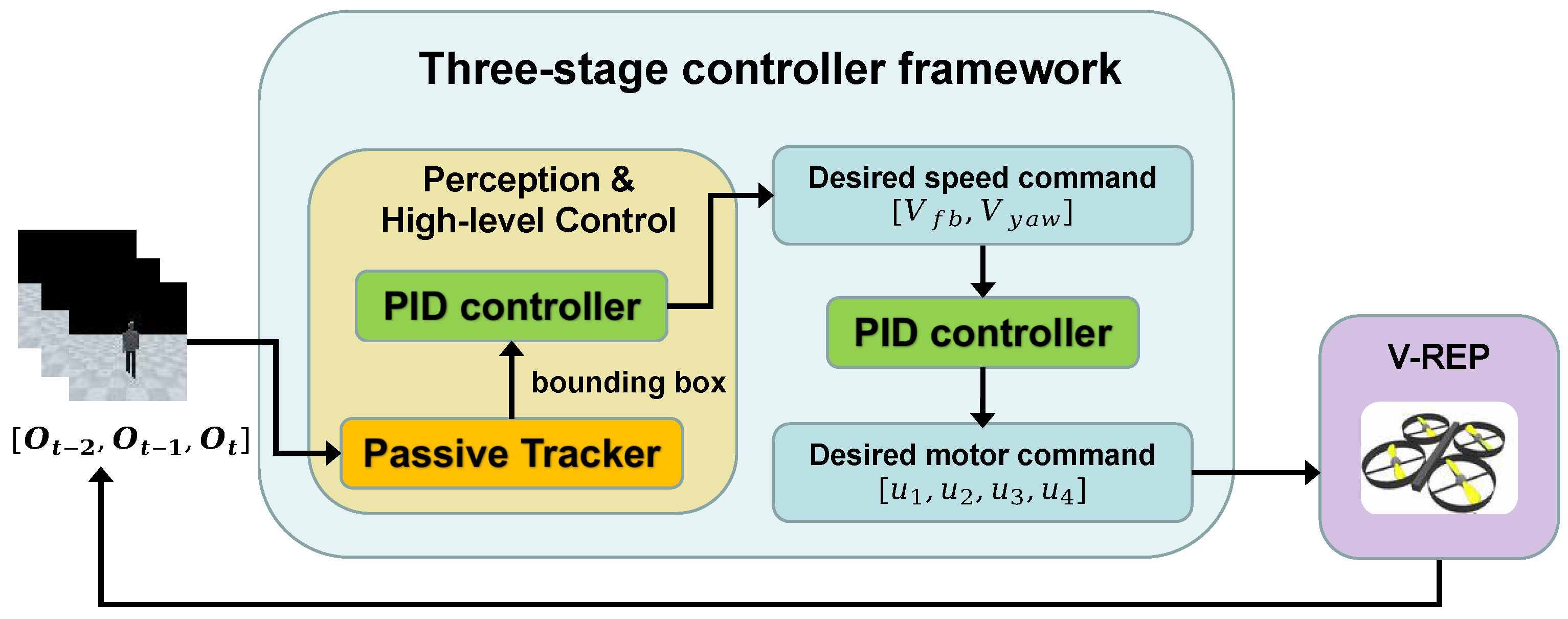
- The end-to-end active tracking controller framework, which maps raw image observations to a UAV’s motor commands directly.
- Training with auxiliary segmentation and motion-in-depth loss.
- Training with auxiliary segmentation but without motion-in-depth loss.
- Training without auxiliary segmentation but with motion-in-depth loss.
- Training without auxiliary segmentation and motion-in-depth loss.
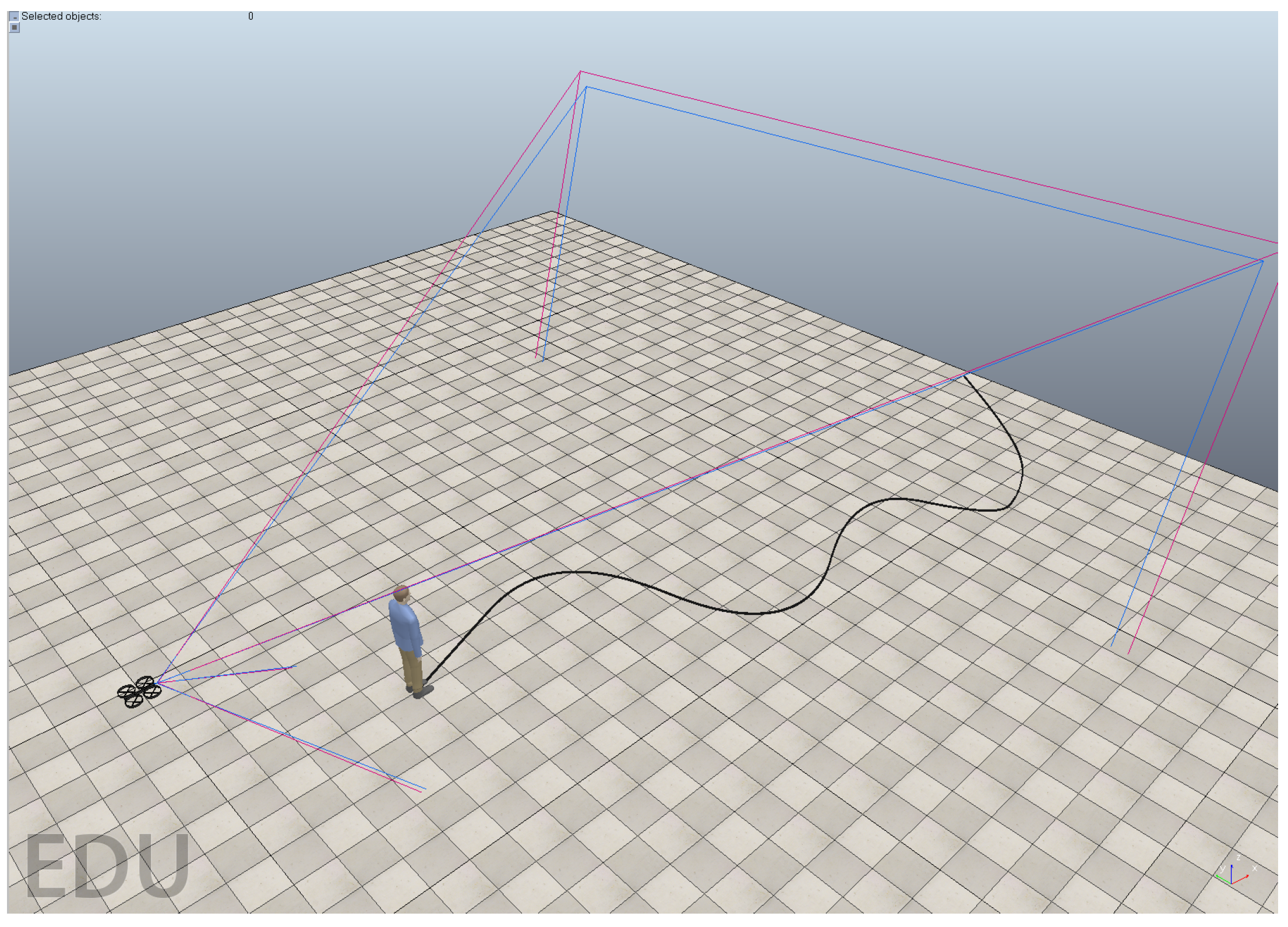
4.2. Simulation Results
4.2.1. Comparison with Baselines
4.2.2. Analysis of Simulation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Architecture of the Network

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Sub-Layers | Specification | Input Layer | |
|---|---|---|---|---|
| Spatial Features Encoder | Channel Attention Module | Conv1a + ReLU + BN | k = 3, s = 1, p = 1 | Input image (64 ∗ 64 ∗ 3) |
| Avg-Pool | / | Conv1a + ReLU + BN | ||
| Max-Pool | / | Conv1a + ReLU + BN | ||
| Shared Conv2a + ReLU | k = 1, s = 1, p = 1 | {Avg-Pool, Max-Pool} | ||
| Shared Conv2b | k = 1, s = 1, p = 0 | Conv2a + ReLU | ||
| Sum | / | Shared Conv2b | ||
| Sigmoid | / | Sum | ||
| Plus1 | / | {Sum, Conv1a + ReLU + BN} | ||
| Spatial Attention Module | mean | / | Plus1 | |
| max | / | Plus1 | ||
| Concat | / | mean, max | ||
| Conv3a | k = 3, s = 1, p = 1 | Concate | ||
| Sigmoid | / | Conv3a | ||
| Plus2 | / | {Plus1, Sigmoid} | ||
| Conv3b + Sigmoid | k = 3, s = 1, p = 1 | Plus2 | ||
| Temporal Features Encoder | Sub1 | / | {Plus2a, Plus2b} | |
| Sub2 | / | {Plus2b, Plus2c} | ||
| Concat | / | {Plus2a, Sub1, Plus2b, Sub2, Plus2c} | ||
| Conv4a + ReLU | k = 8, s = 3, p = 0 | Concate | ||
| Conv4b + Tanh | k = 8, s = 1, p = 0 | Conv4a + ReLU | ||
| Flatten + Fc1 + ReLU | 128 | Conv4b + Tanh | ||
| Decision-making Layer | FC2a + ReLU | 64 | Flatten + Fc1 + ReLU | |
| FC2b + ReLU | 64 | FC2a + ReLU | ||
| FC2c + Tanh | 2 | FC2b + ReLU | ||
| Value-fitting Layer | FC3a + ReLU | 32 | Flatten + Fc1 + ReLU | |
| FC3b | 1 | FC3a + ReLU | ||
| Conv: Convolution, BN: Batch normalization, ReLU: Rectified linear unit, FC: Fully connected, Sub: Subtraction, k: kernel_size, s: stride, p: padding | ||||
References
- Dang, C.T.; Pham, H.T.; Pham, T.B.; Truong, N.V. Vision based ground object tracking using AR.Drone quadrotor. In Proceedings of the 2013 International Conference on Control, Automation and Information Sciences (ICCAIS), Nha Trang City, Vietnam, 25–28 November 2013; pp. 146–151. [Google Scholar] [CrossRef]
- Pestana, J.; Sanchez-Lopez, J.; Campoy, P.; Saripalli, S. Vision based GPS-denied Object Tracking and following for unmanned aerial vehicles. In Proceedings of the 2013 IEEE International Symposium on Safety, Security, and Rescue Robotics, Linköping, Sweden, 21–26 October 2013. [Google Scholar] [CrossRef]
- Mondragón, I.F.; Campoy, P.; Olivares-Mendez, M.A.; Martinez, C. 3D object following based on visual information for Unmanned Aerial Vehicles. In Proceedings of the IX Latin American Robotics Symposium and IEEE Colombian Conference on Automatic Control, Bogota, Colombia, 1–4 October 2011; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Boudjit, K.; Larbes, C. Detection and implementation autonomous target tracking with a Quadrotor AR.Drone. In Proceedings of the 2015 12th International Conference on Informatics in Control, Automation and Robotics (ICINCO), Colmar, France, 21–23 July 2015; Volume 2, pp. 223–230. [Google Scholar]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the Computer Vision—ECCV 2006, Graz, Austria, 7–13 May 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Lect. Notes Comput. Sci. 2016, 9905, 21–37. [Google Scholar] [CrossRef] [Green Version]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Computer Vision—ECCV 2016 Workshops; Hua, G., Jégou, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Shadeed, O.; Hasanzade, M.; Koyuncu, E. Deep Reinforcement Learning based Aggressive Flight Trajectory Tracker. In Proceedings of the AIAA Scitech 2021 Forum, Online, 11–15 January 2021. [Google Scholar]
- Siddiquee, M.; Junell, J.; Van Kampen, E.J. Flight test of Quadcopter Guidance with Vision-Based Reinforcement Learning. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019. [Google Scholar]
- Polvara, R.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R. Autonomous Vehicular Landings on the Deck of an Unmanned Surface Vehicle using Deep Reinforcement Learning. Robotica 2019, 37, 1867–1882. [Google Scholar] [CrossRef] [Green Version]
- Luo, W.; Sun, P.; Zhong, F.; Liu, W.; Zhang, T.; Wang, Y. End-to-End Active Object Tracking and Its Real-World Deployment via Reinforcement Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1317–1332. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, S.; Liu, T.; Zhang, C.; Yeung, D.Y.; Shen, S. Learning Unmanned Aerial Vehicle Control for Autonomous Target Following. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4936–4942. [Google Scholar]
- Rohmer, E.; Singh, S.P.N.; Freese, M. V-REP: A versatile and scalable robot simulation framework. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1321–1326. [Google Scholar] [CrossRef]
- James, S.; Freese, M.; Davison, A. PyRep: Bringing V-REP to Deep Robot Learning. arXiv 2019, arXiv:1906.11176. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Amiranashvili, A.; Dosovitskiy, A.; Koltun, V.; Brox, T. Motion perception in reinforcement learning with dynamic objects. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 156–168. [Google Scholar]
- Shang, W.; Wang, X.; Srinivas, A.; Rajeswaran, A.; Gao, Y.; Abbeel, P.; Laskin, M. Reinforcement Learning with Latent Flow. arXiv 2021, arXiv:2101.01857. [Google Scholar]
- Yang, G.; Ramanan, D. Upgrading Optical Flow to 3D Scene Flow Through Optical Expansion. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1331–1340. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; pp. 8024–8035. [Google Scholar]












| Hyperparameter | Value |
|---|---|
| Number of actors N | 2 |
| Horizon T | 2048 |
| Adam stepsize | |
| Num. epochs | 2 |
| Minibatch size | 640 |
| Discount | 0.99 |
| GAE parameter | 0.98 |
| Clipping | 0.2 |
| Auxiliary loss coefficient | 1.0 |
| Auxiliary loss coefficient | 0.05 |
| Reward coefficient | 0.5 |
| Reward coefficient | 0.5 |
| Reward coefficient | 0.5 |
| Reward coefficient | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Meng, Z.; Wang, K.; Zhang, J.; Lu, S. Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning. Appl. Sci. 2021, 11, 10595. https://doi.org/10.3390/app112210595
Zhao W, Meng Z, Wang K, Zhang J, Lu S. Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning. Applied Sciences. 2021; 11(22):10595. https://doi.org/10.3390/app112210595
Chicago/Turabian StyleZhao, Wenlong, Zhijun Meng, Kaipeng Wang, Jiahui Zhang, and Shaoze Lu. 2021. "Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning" Applied Sciences 11, no. 22: 10595. https://doi.org/10.3390/app112210595
APA StyleZhao, W., Meng, Z., Wang, K., Zhang, J., & Lu, S. (2021). Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning. Applied Sciences, 11(22), 10595. https://doi.org/10.3390/app112210595