
Multi-Objective Design of Profit Volumes and Closeness Ratings Using MBHS Optimizing Based on the PrefixSpan Mining Approach (PSMA) for Product Layout in Supermarkets


Abstract
:1. Introduction
2. Related Work
3. Proposed Model
3.1. Sequential Pattern Mining
3.2. PrefixSpan Algorithm
| Algorithm 1. PrefixSpan |
| Input: Department of product (DT: A, B, C, …, S), and the minimum support threshold min_sup Output: The complete set of sequential product patterns (2-length sequential pattern) |
| Method: Call PrefixSpan Subroutine: PrefixSpan Parameters: α is a sequential pattern, l is the length of α, and is the α-projected database if α ≠ <>; otherwise, it represents the department transaction database DT. |
Procedure:
|
PrefixSpan for Finding Sequence Patterns
3.3. Adjacency Preferences
3.4. Multi-Objective Mutation-Based Harmony Search for Layout Design
3.4.1. Initialization Parameters and the Harmony Memory
3.4.2. Generating a New Harmony
3.4.3. Update the Harmony Memory
3.4.4. Terminate Criterion
4. Experiments and Results
4.1. Multi-Objective Evaluation
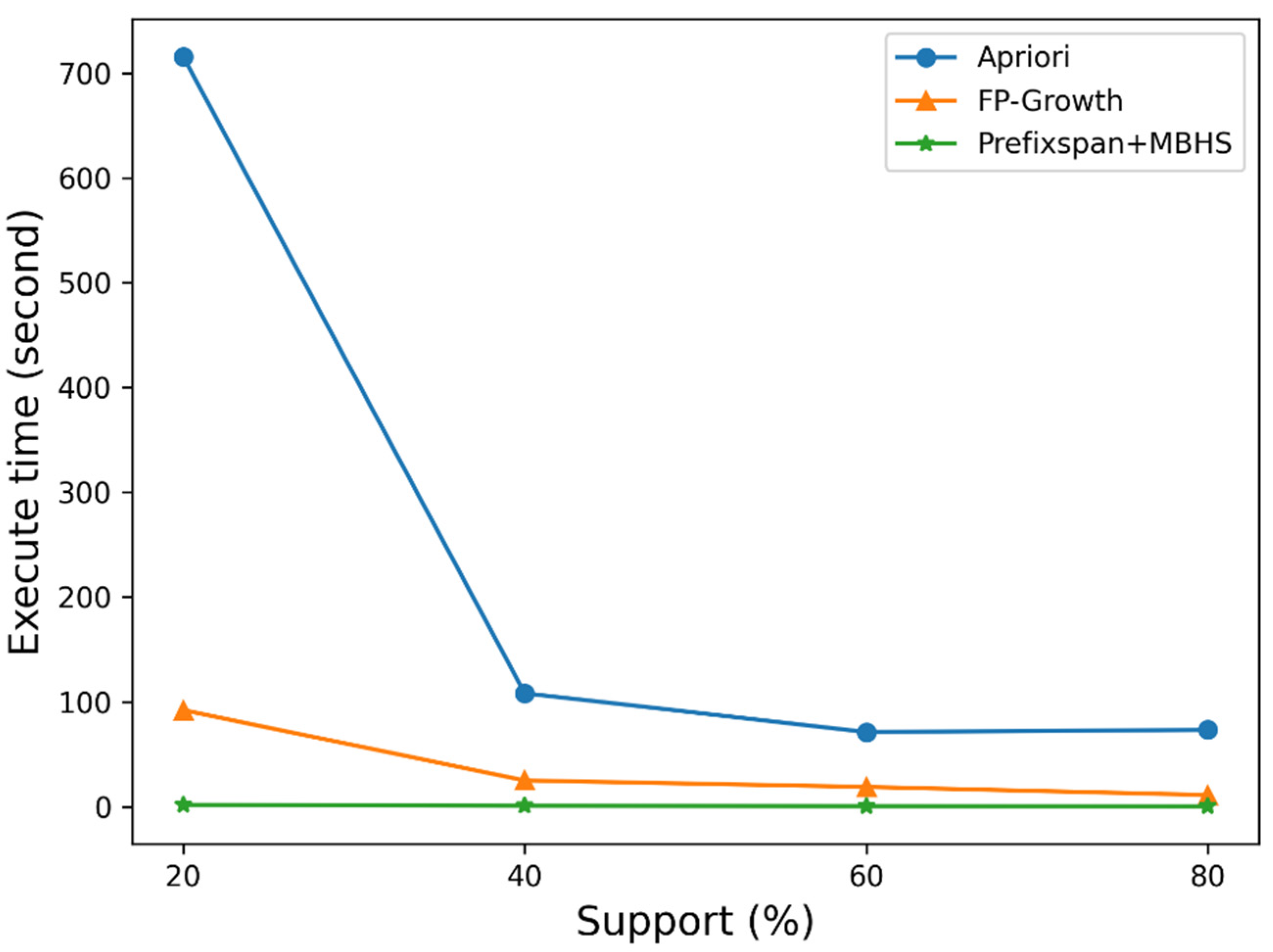
4.2. Comparison of Algorithms
4.3. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Agrawal, R.; Srikant, R. Mining Sequential Patterns. In Proceedings of the Eleventh International Conference on Data Engineering, Washington, DC, USA, 6–10 March 1995; pp. 3–14. [Google Scholar]
- Srikant, R.; Agrawal, R. Mining Sequential Patterns: Generalizations and Performance Improvements. In Advances in Database Technology, Proceedings of the International Conference on Extending Database Technology EDBT ’96, Munich, Germany, 26–31 March 2006; Apers, P., Bouzeghoub, M., Gardarin, G., Eds.; Springer: Berlin/Heidelberg, 1996; pp. 1–17. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Waltham, MA, USA, 2011. [Google Scholar]
- Tsai, C.; Wu, M. Applying a Two-Stage Simulated Annealing Algorithm for Shelf Space Allocation Problems. In Proceedings of the World Congress on Engineering, London, UK, 30 June–2 July 2010; Volume 30, pp. 2376–2380. [Google Scholar]
- Lu, Y.; Seo, H.-B. Developing Visibility Analysis for a Retail Store: A Pilot Study in a Bookstore. Environ. Plan. B Plan. Des. 2015, 42, 95–109. [Google Scholar] [CrossRef]
- Guidotti, R.; Rossetti, G.; Pappalardo, L.; Giannotti, F.; Pedreschi, D. Personalized Market Basket Prediction with Temporal Annotated Recurring Sequences. IEEE Trans. Knowl. Data Eng. 2019, 31, 2151–2163. [Google Scholar] [CrossRef]
- Kanavos, A.; Iakovou, S.A.; Sioutas, S.; Tampakas, V. Large Scale Product Recommendation of Supermarket Ware Based on Customer Behaviour Analysis. Big Data Cogn. Comput. 2018, 2, 11. [Google Scholar] [CrossRef] [Green Version]
- Seraphim, B.I.; Rao, L.S.; Joshi, S. Survey on Customer Centric Sales Analysis and Prediction. In Proceedings of the 2018 3rd International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 15–16 November 2018; pp. 495–500. [Google Scholar]
- Yuan, X.; Chang, W.; Zhou, S.; Cheng, Y. Sequential Pattern Mining Algorithm Based on Text Data: Taking the Fault Text Records as an Example. Sustainability 2018, 10, 4330. [Google Scholar] [CrossRef] [Green Version]
- Valle, M.A.; Ruz, G.A.; Morrás, R. Market Basket Analysis: Complementing Association Rules with Minimum Spanning Trees. Expert Syst. Appl. 2018, 97, 146–162. [Google Scholar] [CrossRef]
- Kanaan, M.; Cazabet, R.; Kheddouci, H. Temporal Pattern Mining for E-commerce Dataset. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XLVI; Hameurlain, A., Tjoa, A.M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 67–90. ISBN 978-3-662-62386-2. [Google Scholar]
- González, E.M.; Meyer, J.-H.; Paz Toldos, M. What Women Want? How Contextual Product Displays Influence Women’s Online Shopping Behavior. J. Bus. Res. 2021, 123, 625–641. [Google Scholar] [CrossRef]
- Wang, H.; Du, Y.; Yi, J.; Wang, N.; Liang, F. Mining Evolution Patterns from Complex Trajectory Structures—A Case Study of Mesoscale Eddies in the South China Sea. ISPRS Int. J. Geo-Inf. 2020, 9, 441. [Google Scholar] [CrossRef]
- Haritha, P.; Sreedevi, M.; Ravali, K.; ManojPruthvi, M. A Survey for Acquiring Frequent and Sequential Items in E-Commerce Sites. Int. J. Eng. Technol. 2017, 7, 273–277. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.-L.; Chen, J.-M.; Tung, C.-W. A Data Mining Approach for Retail Knowledge Discovery with Consideration of the Effect of Shelf-Space Adjacency on Sales. Decis. Support Syst. 2006, 42, 1503–1520. [Google Scholar] [CrossRef]
- Zhou, H.; Hirasawa, K. Evolving Temporal Association Rules in Recommender System. Neural Comput. Appl. 2019, 31, 2605–2619. [Google Scholar] [CrossRef] [Green Version]
- Kim, G.; Moon, I. Integrated Planning for Product Selection, Shelf-Space Allocation, and Replenishment Decision with Elasticity and Positioning Effects. J. Retail. Consum. Serv. 2021, 58, 102274. [Google Scholar] [CrossRef]
- Sowmyanarayanan, R.; Krishnaa, G.; Gupta, D. Beyond Kirana Stores: A Study on Consumer Purchase Intention for Buying Grocery Online. In ICTIS 2020: Information and Communication Technology for Intelligent Systems, Proceedings of the International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 15–16 May 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 599–606. [Google Scholar]
- Chen, Y.-L.; Tang, K.; Shen, R.-J.; Hu, Y.-H. Market Basket Analysis in a Multiple Store Environment. Decis. Support Syst. 2005, 40, 339–354. [Google Scholar] [CrossRef]
- Borgelt, C. Frequent Item Set Mining. WIREs Data Min. Knowl. Discov. 2012, 2, 437–456. [Google Scholar] [CrossRef]
- Finamore, A.C.; Jiménez, H.G.; Casanova, M.A.; Nunes, B.P.; Santos, A.M.; Pires, A.P. A Comparative Analysis of Two Computer Science Degree Offerings. J. Braz. Comput. Soc. 2020, 26, 1–23. [Google Scholar] [CrossRef]
- Mild, A.; Reutterer, T. An Improved Collaborative Filtering Approach for Predicting Cross-Category Purchases Based on Binary Market Basket Data. J. Retail. Consum. Serv. 2003, 10, 123–133. [Google Scholar] [CrossRef] [Green Version]
- Verma, N.; Malhotra, D.; Singh, J. Big Data Analytics for Retail Industry Using MapReduce-Apriori Framework. J. Manag. Anal. 2020, 7, 424–442. [Google Scholar] [CrossRef]
- Li, H.; Wu, Y.J.; Chen, Y. Time Is Money: Dynamic-Model-Based Time Series Data-Mining for Correlation Analysis of Commodity Sales. J. Comput. Appl. Math. 2020, 370, 112659. [Google Scholar] [CrossRef]
- Wang, F.; Wen, Y.; Guo, T.; Liu, J.; Cao, B. Collaborative Filtering and Association Rule Mining-Based Market Basket Recommendation on Spark. Concurr. Comput. Pract. Exp. 2020, 32, e5565. [Google Scholar] [CrossRef]
- Ünvan, Y.A. Market Basket Analysis with Association Rules. Commun. Stat. Theory Methods 2020, 50, 1615–1628. [Google Scholar] [CrossRef]
- Qu, J.-F.; Fournier-Viger, P.; Liu, M.; Hang, B.; Wang, F. Mining High Utility Itemsets Using Extended Chain Structure and Utility Machine. Knowl. Based Syst. 2020, 208, 106457. [Google Scholar] [CrossRef]
- Raeder, T.; Chawla, N.V. Market Basket Analysis with Networks. Soc. Netw. Anal. Min. 2011, 1, 97–113. [Google Scholar] [CrossRef]
- Reyes, P.M.; Frazier, G.V. Goal Programming Model for Grocery Shelf Space Allocation. Eur. J. Oper. Res. 2007, 181, 634–644. [Google Scholar] [CrossRef]
- Inglay, R.; Dhalla, R. Application of Systematic Layout Planning in Hypermarkets. In Proceedings of the 2010 International Conference on Industrial Engineering and Operations Management, Dhaka, Bangladesh, 9–10 January 2010; pp. 9–10. [Google Scholar]
- Brandtner, P.; Darbanian, F.; Falatouri, T.; Udokwu, C. Impact of COVID-19 on the Customer End of Retail Supply Chains: A Big Data Analysis of Consumer Satisfaction. Sustainability 2021, 13, 1464. [Google Scholar] [CrossRef]
- Jian, P.; Jiawei, H.; Mortazavi-Asl, B.; Pinto, H.; Qiming, C.; Dayal, U.; Mei-Chun, H. PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 215–224. [Google Scholar]
- Wang, J.; Han, J. BIDE: Efficient Mining of Frequent Closed Sequences. In Proceedings of the 20th International Conference on Data Engineering, Boston, MA, USA, 2nd April 2004; pp. 79–90. [Google Scholar]
- Gao, C.; Wang, J.; He, Y.; Zhou, L. Efficient Mining of Frequent Sequence Generators. In WWW’08: Proceedings of the 17th International Conference on World Wide Web, Beijing, China 21–25 April 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1051–1052. [Google Scholar]
- Çetin, O.; Mersereau, A.J.; Parlaktürk, A.K. Management and Effects of In-Store Promotional Displays. Manuf. Serv. Oper. Manag. 2019, 22, 481–494. [Google Scholar] [CrossRef]
- Chaudhary, P.; Mondal, A.; Reddy, P.K. An Improved Scheme for Determining Top-Revenue Itemsets for Placement in Retail Businesses. Int. J. Data Sci. Anal. 2020, 10, 359–375. [Google Scholar] [CrossRef]
- Wang, X.; Wang, F.; Yan, S.; Liu, Z. Application of Sequential Pattern Mining Algorithm in Commodity Management. J. Electron. Commer. Organ. 2018, 16, 94–106. [Google Scholar] [CrossRef] [Green Version]
- Timonina-Farkas, A.; Katsifou, A.; Seifert, R.W. Product Assortment and Space Allocation Strategies to Attract Loyal and Non-Loyal Customers. Eur. J. Oper. Res. 2020, 285, 1058–1076. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989; ISBN 0-201-15767-5. [Google Scholar]
- Bonyadi, M.R.; Michalewicz, Z. Particle Swarm Optimization for Single Objective Continuous Space Problems: A Review. Evol. Comput. 2017, 25, 1–54. [Google Scholar] [CrossRef]
- Kong, L.; Wang, J.; Zhao, P. Solving the Dynamic Weapon Target Assignment Problem by an Improved Multiobjective Particle Swarm Optimization Algorithm. Appl. Sci. 2021, 11, 9254. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Roeva, O.; Zoteva, D.; Lyubenova, V. Escherichia Coli Cultivation Process Modelling Using ABC-GA Hybrid Algorithm. Processes 2021, 9, 1418. [Google Scholar] [CrossRef]
- Villegas, J.M.; Caraveo, C.; Mejía, D.A.; Rodríguez, J.L.; Vega, Y.; Cervantes, L.; Medina-Santiago, A. Intelligent Search of Values for a Controller Using the Artificial Bee Colony Algorithm to Control the Velocity of Displacement of a Robot. Algorithms 2021, 14, 273. [Google Scholar] [CrossRef]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A New Heuristic Optimization Algorithm: Harmony Search. SIMULATION 2001, 76, 60–68. [Google Scholar] [CrossRef]
- Peraza, C.; Valdez, F.; Castillo, O. A harmony search algorithm comparison with genetic algorithms. In Fuzzy Logic Augmentation of Nature-Inspired Optimization Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2015; pp. 105–123. [Google Scholar]
- Lee, K.S.; Geem, Z.W. A New Structural Optimization Method Based on the Harmony Search Algorithm. Comput. Struct. 2004, 82, 781–798. [Google Scholar] [CrossRef]
- Lee, K.S.; Geem, Z.W. A New Meta-Heuristic Algorithm for Continuous Engineering Optimization: Harmony Search Theory and Practice. Comput. Methods Appl. Mech. Eng. 2005, 194, 3902–3933. [Google Scholar] [CrossRef]
- Mahdavi, M.; Fesanghary, M.; Damangir, E. An Improved Harmony Search Algorithm for Solving Optimization Problems. Appl. Math. Comput. 2007, 188, 1567–1579. [Google Scholar] [CrossRef]
- Szwarc, K.; Boryczka, U. The Pheromone-Based Harmony Search Algorithm for the Asymmetric Traveling Salesman Problem. Appl. Sci. 2020, 10, 6422. [Google Scholar] [CrossRef]
- Al-harkan, I.M.; Qamhan, A.A.; Badwelan, A.; Alsamhan, A.; Hidri, L. Modified Harmony Search Algorithm for Resource-Constrained Parallel Machine Scheduling Problem with Release Dates and Sequence-Dependent Setup Times. Processes 2021, 9, 654. [Google Scholar] [CrossRef]
- Çarbaş, S.; Saka, M.P. Optimum Topology Design of Various Geometrically Nonlinear Latticed Domes Using Improved Harmony Search Method. Struct. Multidisc. Optim. 2012, 45, 377–399. [Google Scholar] [CrossRef]
- Wang, W.; Tian, J.; Lv, F.; Xin, G.; Ma, Y.; Wang, B. Mining Frequent Pyramid Patterns from Time Series Transaction Data with Custom Constraints. Comput. Secur. 2021, 100, 102088. [Google Scholar] [CrossRef]
- Anwar, T.; Uma, V. CD-SPM: Cross-Domain Book Recommendation Using Sequential Pattern Mining and Rule Mining. J. King Saud Univ. Comput. Inf. Sci. in press. 2019. [Google Scholar] [CrossRef]
- Hung, C.W. Using Cloud Services to Develop Marketing Information System Applications. J. Internet Technol. 2019, 20, 157–166. [Google Scholar] [CrossRef]
- Tandon, N.; Varde, A.S.; de Melo, G. Commonsense Knowledge in Machine Intelligence. SIGMOD Rec. 2018, 46, 49–52. [Google Scholar] [CrossRef]
- Pires, M.; Camanho, A.; Amorim, P. Solving the Grocery Backroom Sizing Problem. Int. J. Prod. Res. 2020, 58, 5707–5720. [Google Scholar] [CrossRef]
- Rosales-Salas, J.; Maldonado, S.; Seret, A. Mining Sequences in Activities for Time Use Analysis. Intell. Data Anal. 2020, 24, 339–362. [Google Scholar] [CrossRef]
- Epstein, L.D.; Flores, A.A.; Goodstein, R.C.; Milberg, S.J. A New Approach to Measuring Retail Promotion Effectiveness: A Case of Store Traffic. J. Bus. Res. 2016, 69, 4394–4402. [Google Scholar] [CrossRef]
- Vu, H.Q.; Li, G.; Law, R.; Zhang, Y. Travel Diaries Analysis by Sequential Rule Mining. J. Travel Res. 2018, 57, 399–413. [Google Scholar] [CrossRef]
- Lourenco, J.; Varde, A.S. Item-Based Collaborative Filtering and Association Rules for a Baseline Recommender in E-Commerce. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 4636–4645. [Google Scholar]
- Kim, H.-J.; Baek, J.-W.; Chung, K. Optimization of Associative Knowledge Graph Using TF-IDF Based Ranking Score. Appl. Sci. 2020, 10, 4590. [Google Scholar] [CrossRef]
- Su, J.-H.; Liao, Y.-W.; Chen, L.-N. An Intelligent Course Decision Assistant by Mining and Filtering Learners’ Personality Patterns. Appl. Sci. 2019, 9, 4665. [Google Scholar] [CrossRef] [Green Version]
- Aloysius, G.; Binu, D. An Approach to Products Placement in Supermarkets Using PrefixSpan Algorithm. J. King Saud Univ. Comput. Inf. Sci. 2013, 25, 77–87. [Google Scholar] [CrossRef] [Green Version]
- Degertekin, S.O.; Minooei, M.; Santoro, L.; Trentadue, B.; Lamberti, L. Large-Scale Truss-Sizing Optimization with Enhanced Hybrid HS Algorithm. Appl. Sci. 2021, 11, 3270. [Google Scholar] [CrossRef]
- Kang, J.; Kwon, S.; Ryu, D.; Baik, J. HASPO: Harmony Search-Based Parameter Optimization for Just-in-Time Software Defect Prediction in Maritime Software. Appl. Sci. 2021, 11, 2002. [Google Scholar] [CrossRef]
- Molina-Pérez, D.; Portilla-Flores, E.A.; Vega-Alvarado, E.; Calva-Yañez, M.B.; Sepúlveda-Cervantes, G. A Novel Multi-Objective Harmony Search Algorithm with Pitch Adjustment by Genotype. Appl. Sci. 2021, 11, 8931. [Google Scholar] [CrossRef]
- Mahalingam, S.K.; Nagarajan, L.; Salunkhe, S.; Nasr, E.A.; Davim, J.P.; Hussein, H.M.A. Harmony Search Algorithm for Minimizing Assembly Variation in Non-Linear Assembly. Appl. Sci. 2021, 11, 9213. [Google Scholar] [CrossRef]
- Pei, J.; Han, J.; Mortazavi-Asl, B.; Wang, J.; Pinto, H.; Chen, Q.; Dayal, U.; Hsu, M.-C. Mining Sequential Patterns by Pattern-Growth: The PrefixSpan Approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1424–1440. [Google Scholar] [CrossRef] [Green Version]
- Chaudhari, M.; Mehta, C. Extension of Prefix Span Approach with GRC Constraints for Sequential Pattern Mining. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 2496–2498. [Google Scholar]
- Varghese, C.; Pathak, D.; Varde, A.S. SeVa: A Food Donation App for Smart Living. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Virtual Conference, 27–30 January 2021; pp. 408–413. [Google Scholar]
- Ma, X.; Ye, L. Career Goal-Based e-Learning Recommendation Using Enhanced Collaborative Filtering and Prefixspan. Int. J. Mob. Blended Learn. 2018, 10, 23–37. [Google Scholar] [CrossRef]
- Kang, J.-S.; Baek, J.-W.; Chung, K. PrefixSpan Based Pattern Mining Using Time Sliding Weight From Streaming Data. IEEE Access 2020, 8, 124833–124844. [Google Scholar] [CrossRef]
- Niyazmand, T.; Izadi, I. Pattern Mining in Alarm Flood Sequences Using a Modified PrefixSpan Algorithm. ISA Trans. 2019, 90, 287–293. [Google Scholar] [CrossRef] [PubMed]
- Heragu, S. Facilities Design, 4th ed.; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Tompkins, J.; White, J.; Bozer, Y.; Tanchoco, J. Facilities Planning, 4th ed.; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Related Works | Methods | Domains |
|---|---|---|---|
| 2004 | J. Pei et al. [69] | PrefixSpan | Sequential pattern mining |
| 2013 | G. Aloysius and D. Binu [64] | PrefixSpan | Sequential pattern mining for supermarkets |
| 2016 | M. Chaudhari et al. [70] | PrefixSpan with GRC constraints | Constraints in pattern mining |
| 2016 | L. Epstein et al. [59] | Auto regressive Poisson regression | Recommender system |
| 2017 | N. Tandon et al. [56] | CSK | Machine-learning and smart cities |
| 2018 | X. Wang et al. [37] | SPM Map-Reduce | Sequential pattern mining for commodity management |
| 2018 | H. Vu et al. [60] | Top-K SRM | Sequential pattern mining |
| 2019 | T. Anwar and V. Uma [54] | CD-SPM | Recommender system |
| 2019 | C. Hung [55] | CSIS | E-commerce services |
| 2020 | M. Pires et al. [57] | DEA | Optimum retail space |
| 2020 | J. Lourenco et al. [61] | Item-based collaborative filtering with Apriori | E-commerce services |
| 2021 | Varghese et al. [71] | Mobile app development | Smart cities |
| 2021 | W. Wang et al. [53] | TVI-PrefixSpan | Sequential pattern mining for pyramid scheme patterns |
| Order ID | Product ID |
|---|---|
| 1 | 8, 317, 4264, 3008, 289 |
| 2 | 12, 150, 11432, 4055 |
| Department | Department Name | Product ID |
|---|---|---|
| A | Frozen | 4, 8, 12, 18, 46, 1176, 1268, 49636 |
| B | Bakery | 58, 245, 317, 346, 15369, 28129, 46065 |
| C | Produce | 89, 380, 4264, 7805, 11432, 23429, 48825 |
| D | Alcohol | 150, 3008, 5810, 10532, 32445 |
| E | International | 425, 1414, 4055, 6372, 9942, 42023 |
| F | Beverages | 197, 289, 16514, 25743, 35027 |
| G | Pets | 8445, 11558, 23337, 32748, 44480 |
| H | Dry Goods and Pasta | 173, 27675, 28301, 37469, 41224 |
| I | Bulk Food | 1000, 12699,19628, 22827, 32232, 42091 |
| J | Personal Care | 113, 280, 11929, 12172, 30689, 36905 |
| K | Meat Seafood | 5770, 7519, 18975, 20518 |
| L | Pantry | 4401, 4682, 11503, 26163, 34720, 41660 |
| M | Breakfast | 510, 1087, 15477, 23456 |
| N | Canned goods | 626, 1251, 10173 |
| O | Dairy Eggs | 432, 505, 894, 953, 1006 |
| P | Household | 14, 105, 328, 415, 500 |
| Q | Babies | 219, 309, 426, 873, 1202 |
| R | Snacks | 1, 16, 145, 164, 212, 213 |
| S | Deli | 49, 109, 138, 403, 886 |
| Department | Department Name | Profit |
|---|---|---|
| A | Frozen | 500,111 |
| B | Bakery | 165,168 |
| C | Produce | 87,917 |
| D | Alcohol | 213,612 |
| E | International | 339,047 |
| F | Beverages | 240,790 |
| G | Pets | 58,603 |
| H | Dry Goods and Pasta | 32,417 |
| I | Bulk Food | 5669 |
| J | Personal Care | 396,602 |
| K | Meat Seafood | 181,856 |
| L | Pantry | 161,281 |
| M | Breakfast | 16,846 |
| N | Canned Goods | 73,052 |
| O | Dairy Eggs | 51,724 |
| P | Household | 462,062 |
| Q | Babies | 110,228 |
| R | Snacks | 188,293 |
| S | Deli | 66,213 |
| Order ID | Department |
|---|---|
| 1 | A, B, C, D, F |
| 2 | A, D, C, E |
| 3 | E, F, A, B, D, C |
| 4 | E, A, F, C, B |
| Prefix | Projected Postfix Database |
|---|---|
| A | <_, B, C, D, F>, <_, D, C, E>, < _, B, D, C>, <_ F, C, B> |
| B | <A, C, D, F>, <_, D, C> |
| C | <_, D, F>, <_, E>, <_, B> |
| D | <_F>, <_, C, E>, <_, C> |
| E | < _, F, A, B, D, C>, <_, A, F, C, B> |
| Prefix | Projected Postfix Database | Sequential Patterns |
|---|---|---|
| A | <_, B, C, D, F>, <_, D, C, E>, < _, B, D, C>, <_ F, C, B> | <A, B>, <A, C>, <A, D>, <A, F>, <A, E> |
| B | < _, C, D, F>, <_, D, C>, | <B, C>, <B, D>, <B, F> |
| C | <_, D, F>, <_, E>, <_, B> | <C, D>, <C, F>, <C, E>, <C, B> |
| D | <_F>, <_, C, E>, <_, C> | <D, F>, <D, C>, <D, E> |
| E | < _, F, A, B, D, C>, <_, A, F, C, B> | <E, F>, <E, A>, <E, B>, <E, D>, <E, C> |
| No. | Department Pair | Support | Confidence |
|---|---|---|---|
| 1 | Meat Seafood–Produce | 16.19% | 87% |
| 2 | International–Produce | 6.46% | 87% |
| 3 | Dry goods and Pasta–Dairy eggs | 16.38% | 83% |
| 4 | Breakfast–Dairy eggs | 13.87% | 82% |
| 5 | Frozen–Produce | 31.49% | 80% |
| 6 | Snacks–Produce | 33.78% | 77% |
| 7 | Frozen–Dairy eggs | 30.05% | 77% |
| 8 | Pets–Dairy eggs | 1.44% | 69% |
| 9 | Household–Produce | 11.14% | 57% |
| 10 | Breakfast–Snacks | 10.28% | 61% |
| 11 | Pets–Beverages | 1.25% | 60% |
| 12 | International–Pantry | 4.20% | 56% |
| 13 | Dry goods and Pasta–Frozen | 10.99% | 55% |
| 14 | Bakery–Snacks | 15.25% | 55% |
| 15 | Babies–Frozen | 2.57% | 52% |
| 16 | Deli–Beverages | 12.93% | 52% |
| 17 | Meat Seafood–Pantry | 8.97% | 48% |
| 18 | International–Canned goods | 3.17% | 42% |
| 19 | Deli–Bakery | 10.02% | 40% |
| 20 | Dry goods and Pasta–Canned goods | 7.95% | 40% |
| Rating | Definition | Assigned Score |
|---|---|---|
| A | Absolutely necessary | 125 |
| E | Especially important | 25 |
| I | Important | 5 |
| O | Ordinary closeness | 0 |
| U | Unimportant | −25 |
| X | Undesirable | −125 |
| Department | Frozen | Bakery | Produce | Alcohol | International | Beverages | Pets | Dry Goods | Bulk Food | Personal Care | Meat Seafood | Pantry | Breakfast | Canned Goods | Dairy Eggs | Household | Babies | Snacks | Deli |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Frozen | 0 | 5 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 5 | 125 | 0 | −25 | 25 | 5 |
| Bakery | 25 | 0 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 5 | 125 | 0 | −25 | 25 | 5 |
| Produce | 25 | 5 | 0 | −25 | −25 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 0 | 5 | 125 | 0 | −25 | 25 | 5 |
| Alcohol | 5 | 5 | 25 | 0 | −25 | 25 | −25 | 0 | −125 | 0 | 0 | 5 | 0 | 0 | 25 | 5 | −25 | 5 | 0 |
| International | 25 | 5 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 25 | 125 | 0 | −25 | 25 | 5 |
| Beverages | 25 | 5 | 125 | −25 | −25 | 0 | −25 | 5 | −25 | 0 | 0 | 5 | 0 | 5 | 125 | 5 | −25 | 25 | 5 |
| Pets | 25 | 5 | 125 | −25 | −25 | 125 | 0 | 5 | −125 | 5 | 5 | 25 | 5 | 5 | 125 | 5 | −25 | 25 | 5 |
| Dry goods | 25 | 25 | 125 | −25 | 0 | 25 | −25 | 0 | −25 | 0 | 5 | 25 | 5 | 25 | 125 | 0 | −25 | 25 | 5 |
| Bulk food | 25 | 5 | 125 | −125 | −25 | 25 | −125 | 5 | 0 | −25 | 5 | 25 | 5 | 5 | 125 | 0 | −25 | 25 | 5 |
| Personal care | 25 | 5 | 125 | −25 | −25 | 25 | −25 | 5 | −125 | 0 | 0 | 25 | 5 | 5 | 125 | 5 | −25 | 25 | 5 |
| Meat Seafood | 25 | 5 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 0 | 25 | 5 | 5 | 125 | 0 | −25 | 25 | 5 |
| Pantry | 25 | 5 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 5 | 0 | 5 | 5 | 125 | 0 | −25 | 25 | 5 |
| Breakfast | 25 | 25 | 125 | −25 | −25 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 0 | 5 | 125 | 5 | −25 | 125 | 5 |
| Canned goods | 25 | 5 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 0 | 125 | 0 | −25 | 25 | 5 |
| Dairy eggs | 25 | 5 | 125 | −25 | −25 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 5 | 0 | 0 | −25 | 25 | 5 |
| Household | 25 | 5 | 125 | −25 | −25 | 25 | −25 | 5 | −125 | 5 | 5 | 25 | 5 | 5 | 125 | 0 | −25 | 25 | 5 |
| Babies | 25 | 5 | 125 | −25 | −25 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 5 | 125 | 5 | 0 | 25 | 5 |
| Snacks | 25 | 5 | 125 | −25 | −25 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 5 | 125 | 0 | −25 | 0 | 5 |
| Deli | 25 | 25 | 125 | −25 | 0 | 25 | −25 | 5 | −25 | 0 | 5 | 25 | 5 | 5 | 125 | 0 | −25 | 25 | 0 |
| Iteration | PrefixSpan and MBHS(Proposed Algorithm) | GA | SA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Profit | TCR | Time(s) | Profit | TCR | Time(s) | Profit | TCR | Time(s) | |
| 1 | 311,235.91 | 105 | 0.03 | 255,865.51 | −5 | 3.82 | 249,138.03 | 225 | 0.008 |
| 25 | 390,576.34 | 205 | 0.46 | 367,919.9 | 10 | 9.62 | 307,112.12 | 285 | 0.026 |
| 50 | 396,787.27 | 180 | 0.84 | 372,192.96 | 35 | 13.38 | 324,907.14 | 160 | 0.031 |
| 75 | 416,880.68 | 205 | 1.32 | 390,894.29 | 100 | 17.23 | 321,803.74 | 305 | 0.036 |
| 100 | 433,363.4 | 210 | 1.69 | 390,894.29 | 100 | 20.37 | 341,573.87 | 275 | 0.042 |
| 150 | 441,331.74 | 345 | 2.80 | 392,172.53 | 150 | 26.68 | 341,573.87 | 275 | 0.052 |
| 180 | 441,477.71 | 350 | 3.12 | 392,172.53 | 150 | 30.05 | 341,573.87 | 275 | 0.058 |
| 190 | 441,477.71 | 350 | 3.21 | 392,172.53 | 150 | 31.17 | 341,573.87 | 275 | 0.060 |
| 200 | 441,477.71 | 350 | 3.55 | 392,172.53 | 150 | 32.29 | 341,573.87 | 275 | 0.062 |
| Profit Volume (THB) | Total Closeness Rating | |
|---|---|---|
| Original layout | 228,139.50 | 205 |
| Proposed layout | 441,477.71 | 350 |
| Algorithms | Execute Times (Second) |
|---|---|
| Apriori | 715.51 |
| FP-Growth | 92.18 |
| Prefixspan | 0.29 |
| Algorithm | Parameter | Selected Values |
|---|---|---|
| PrefixSpan and MBHS | HMS | 25 |
| HMCR | 0.9 | |
| PAR | 0.1 | |
| SA | Initial temperature | 100 |
| Cooling rate | 0.99 | |
| Complete temperature | 0.01 | |
| GA | Population size | 2000 |
| Probability of crossover: Pc | 0.2 | |
| Probability of mutation: Pm | 0.08 | |
| Iteration | 200 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaewyotha, J.; Songpan, W. Multi-Objective Design of Profit Volumes and Closeness Ratings Using MBHS Optimizing Based on the PrefixSpan Mining Approach (PSMA) for Product Layout in Supermarkets. Appl. Sci. 2021, 11, 10683. https://doi.org/10.3390/app112210683
Kaewyotha J, Songpan W. Multi-Objective Design of Profit Volumes and Closeness Ratings Using MBHS Optimizing Based on the PrefixSpan Mining Approach (PSMA) for Product Layout in Supermarkets. Applied Sciences. 2021; 11(22):10683. https://doi.org/10.3390/app112210683
Chicago/Turabian StyleKaewyotha, Jakkrit, and Wararat Songpan. 2021. "Multi-Objective Design of Profit Volumes and Closeness Ratings Using MBHS Optimizing Based on the PrefixSpan Mining Approach (PSMA) for Product Layout in Supermarkets" Applied Sciences 11, no. 22: 10683. https://doi.org/10.3390/app112210683
APA StyleKaewyotha, J., & Songpan, W. (2021). Multi-Objective Design of Profit Volumes and Closeness Ratings Using MBHS Optimizing Based on the PrefixSpan Mining Approach (PSMA) for Product Layout in Supermarkets. Applied Sciences, 11(22), 10683. https://doi.org/10.3390/app112210683