
Automatic Ontology-Based Model Evolution for Learning Changes in Dynamic Environments


Abstract
:1. Introduction
2. Related Work
2.1. Ontology Learning Approaches
2.2. Comparison Criteria
- Input. Different inputs are used to learn ontologies. They are grouped as structured, semi-structured, and unstructured input data;
- Learning element. Learning elements are classified as follows: concept (C), taxonomic relation (TR), non-taxonomic relation (NTR), datatype property (D), individual (I), and axiom (A);
- Pivot model. This is a model that behaves as a unification of heterogeneous inputs by transforming them to an intermediate model during the process of ontology learning;
- Pivot model’s hierarchy. A pivot model can detect and maintain the underlying hierarchical structure in the input data;
- Ontology Refinement. This is achieved through improving learned ontologies, for example, by discovering and integrating new relations using different external resources;
- Ontology Alignment. This is achieved using a process of determining correspondences between terms in a preexisting ontology and a learned ontology;
- Ontology Merging. This is achieved by extending a preexisting ontology through the addition of new concepts, relations, properties, individuals, and axioms;
- Automation Degree. The acquisition of knowledge may be performed automatically or semi-automatically, where it is handled with the help of users or experts.
2.3. Comparison and Discussion
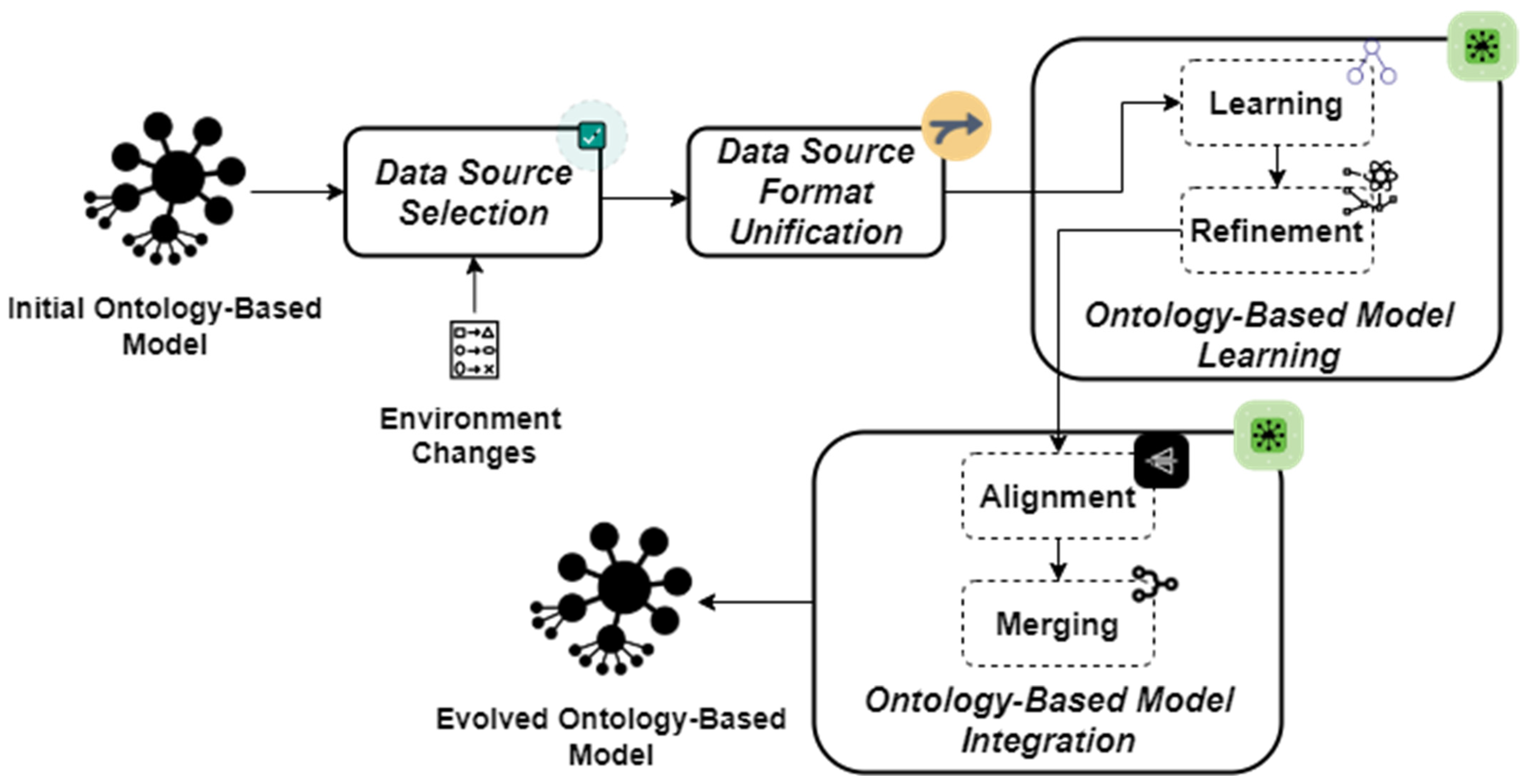
3. Ontology-Based Model Evolution Approach
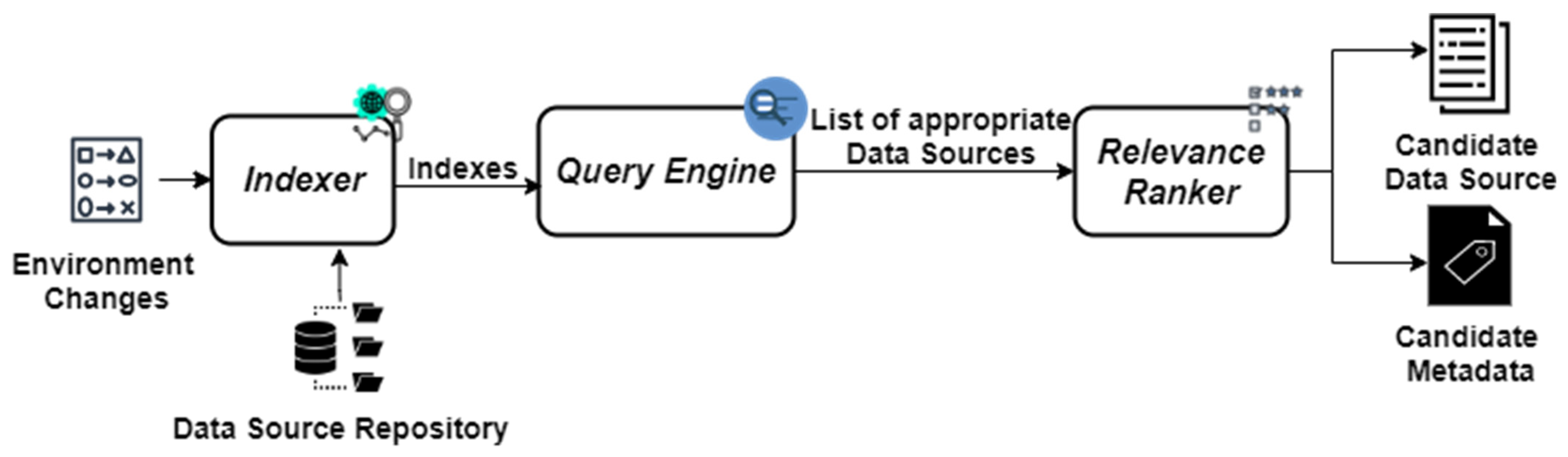
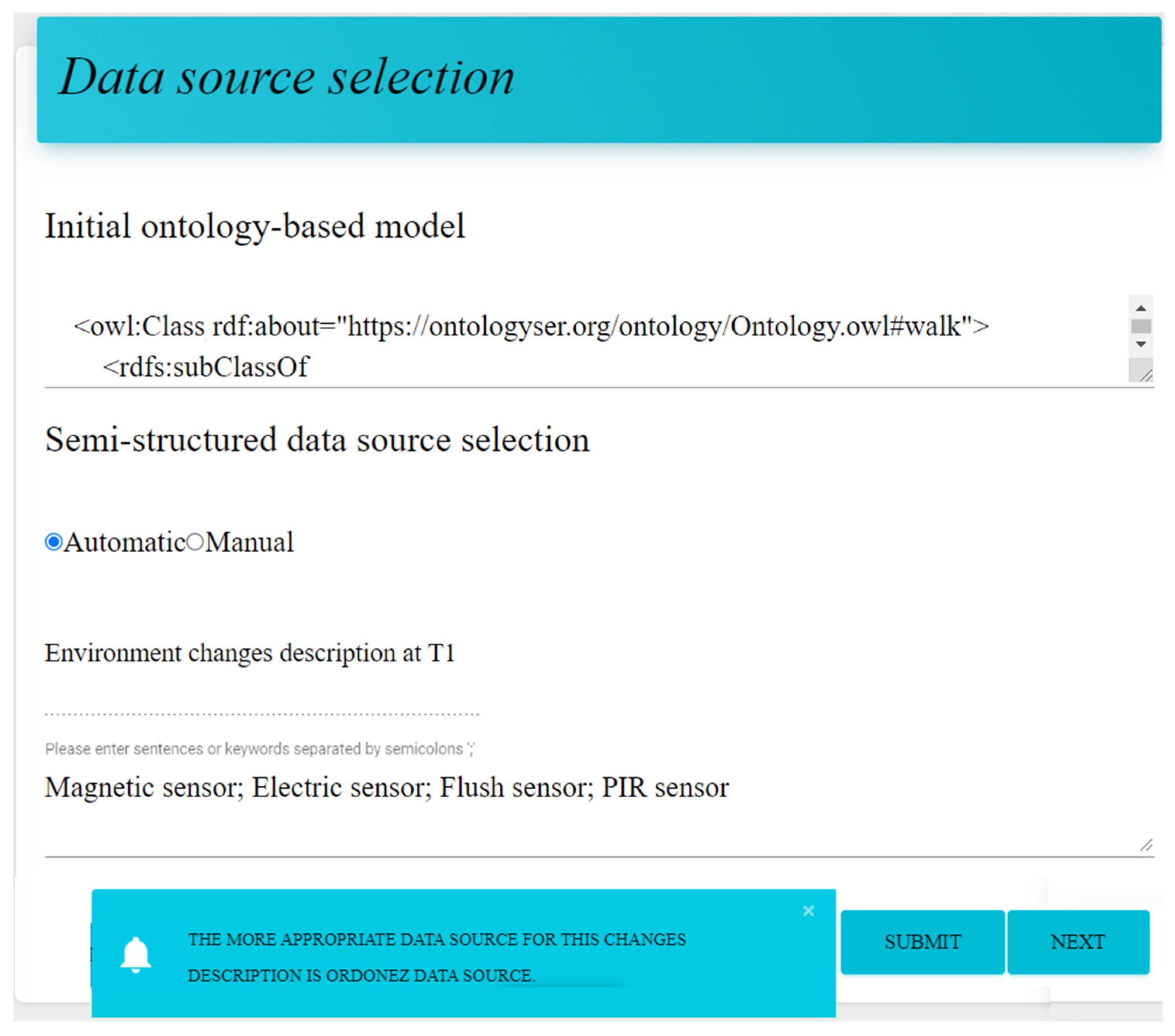
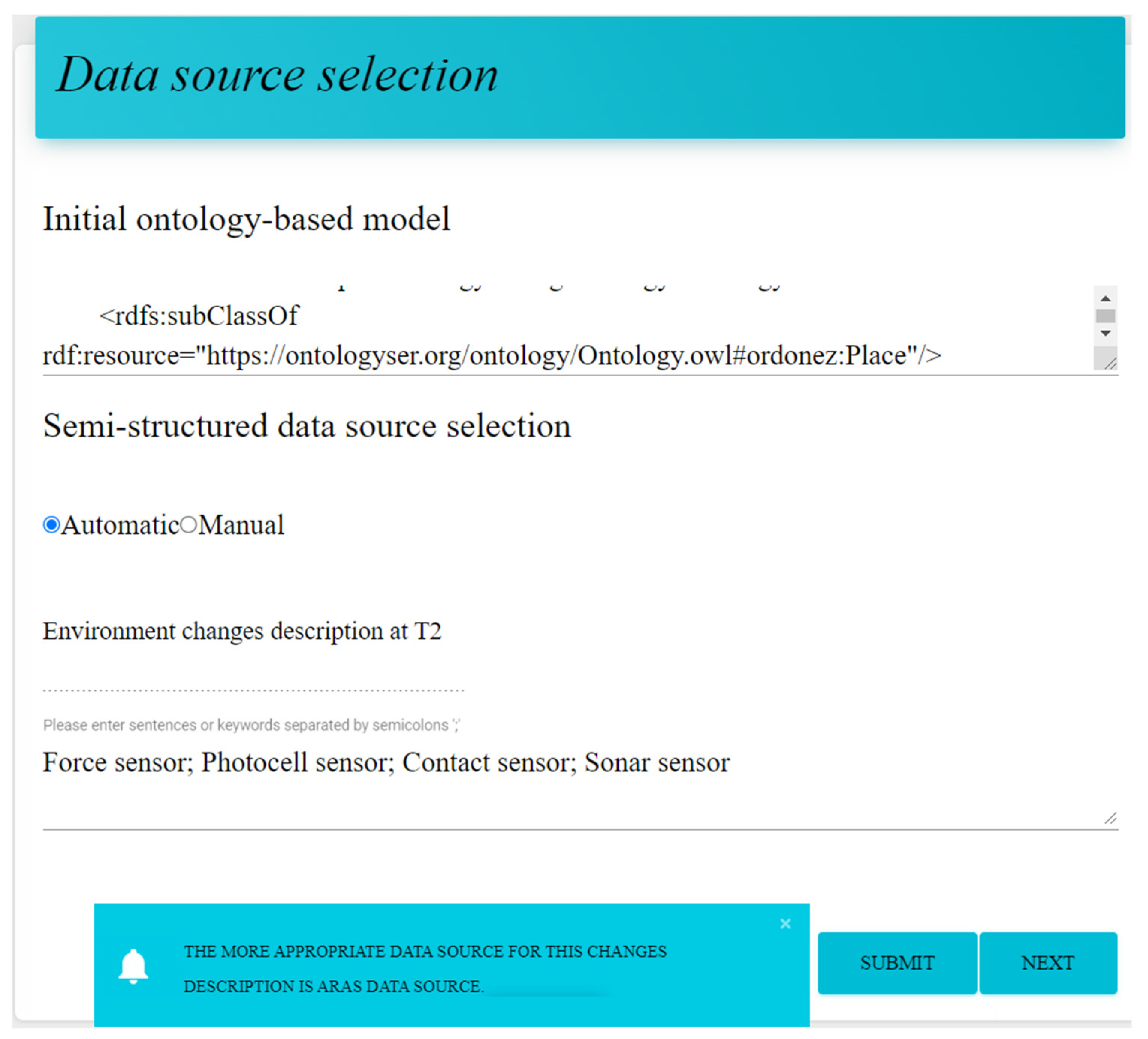
3.1. Data Source Selection Module
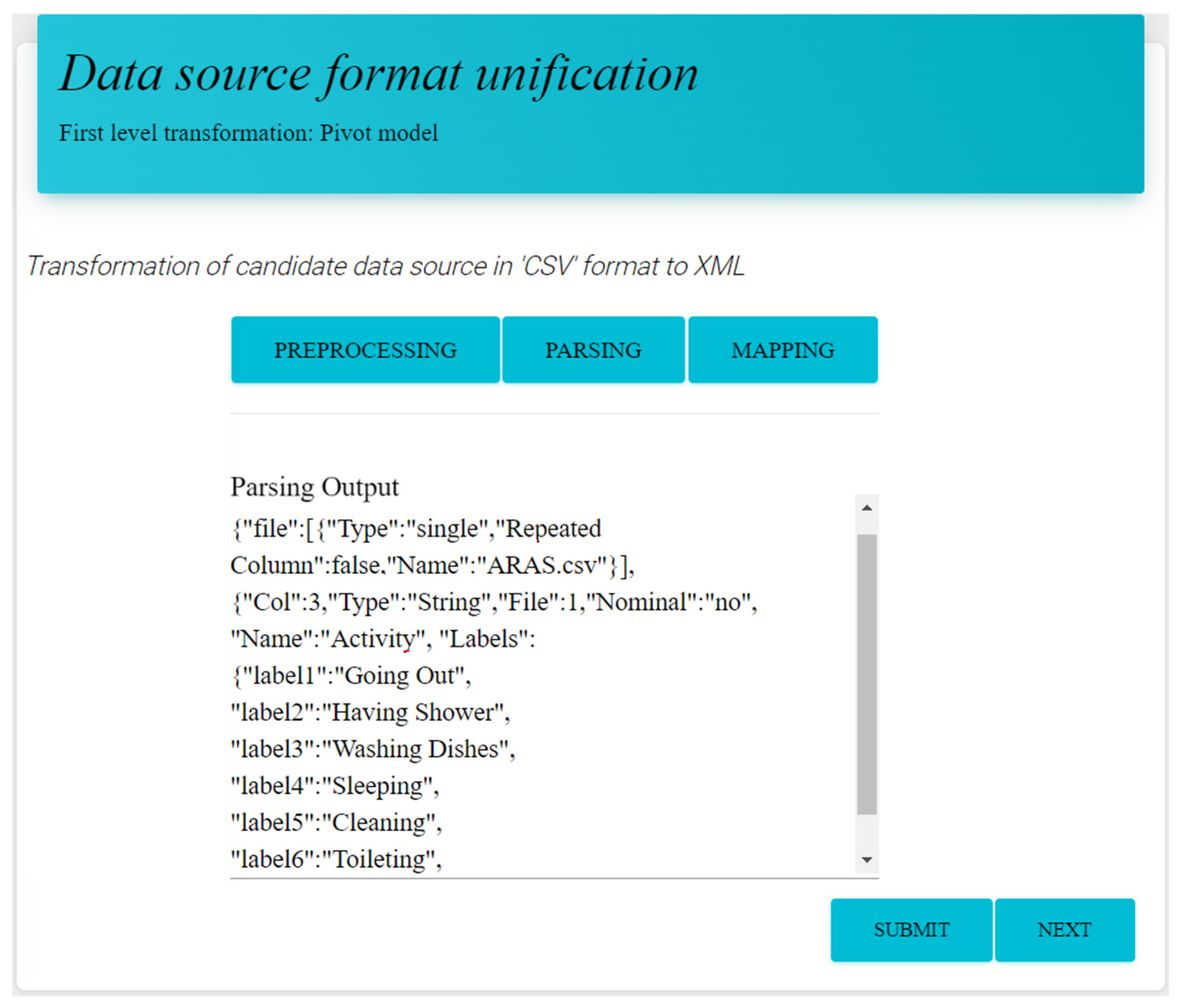
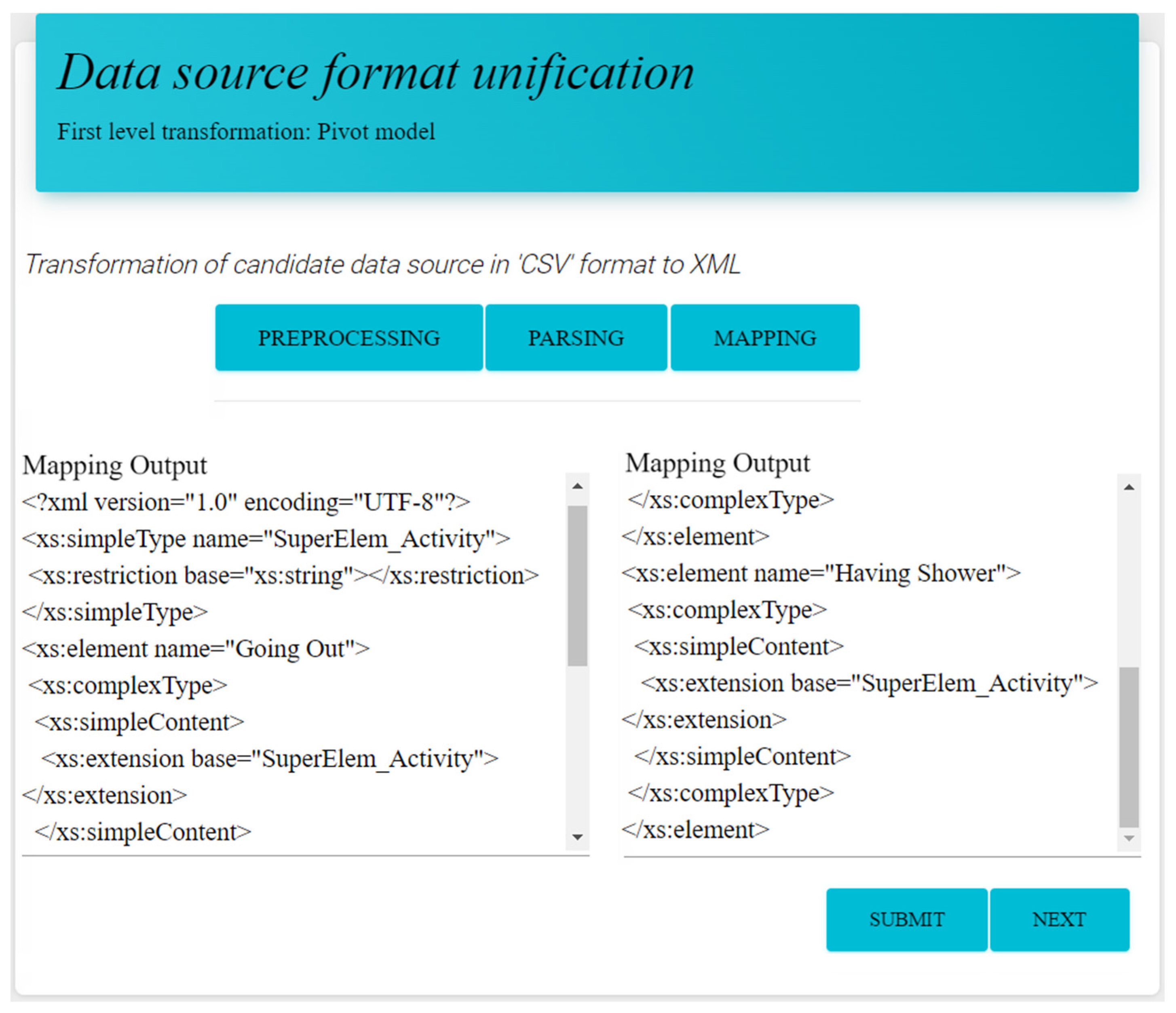
3.2. Data Source Format Unification Module
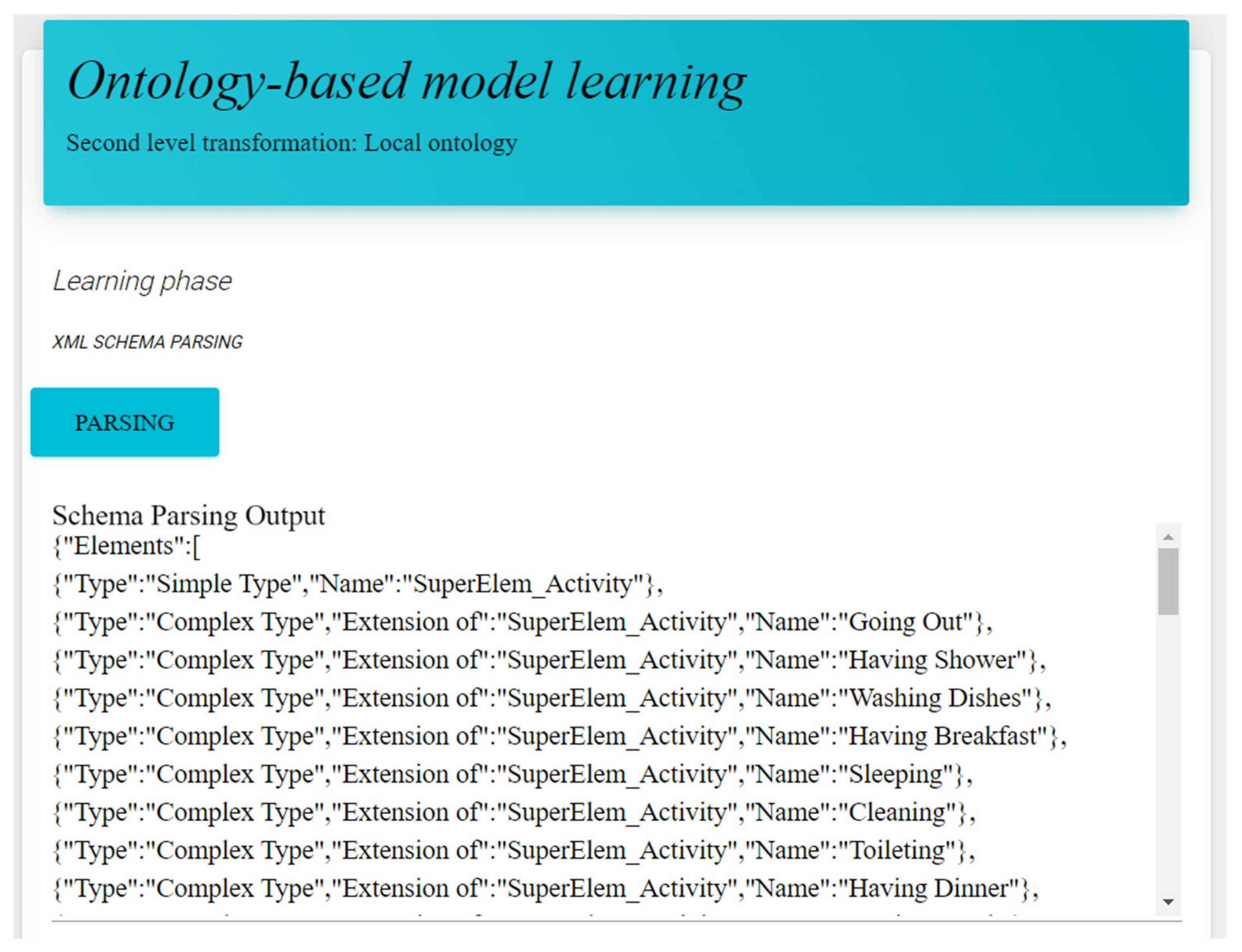
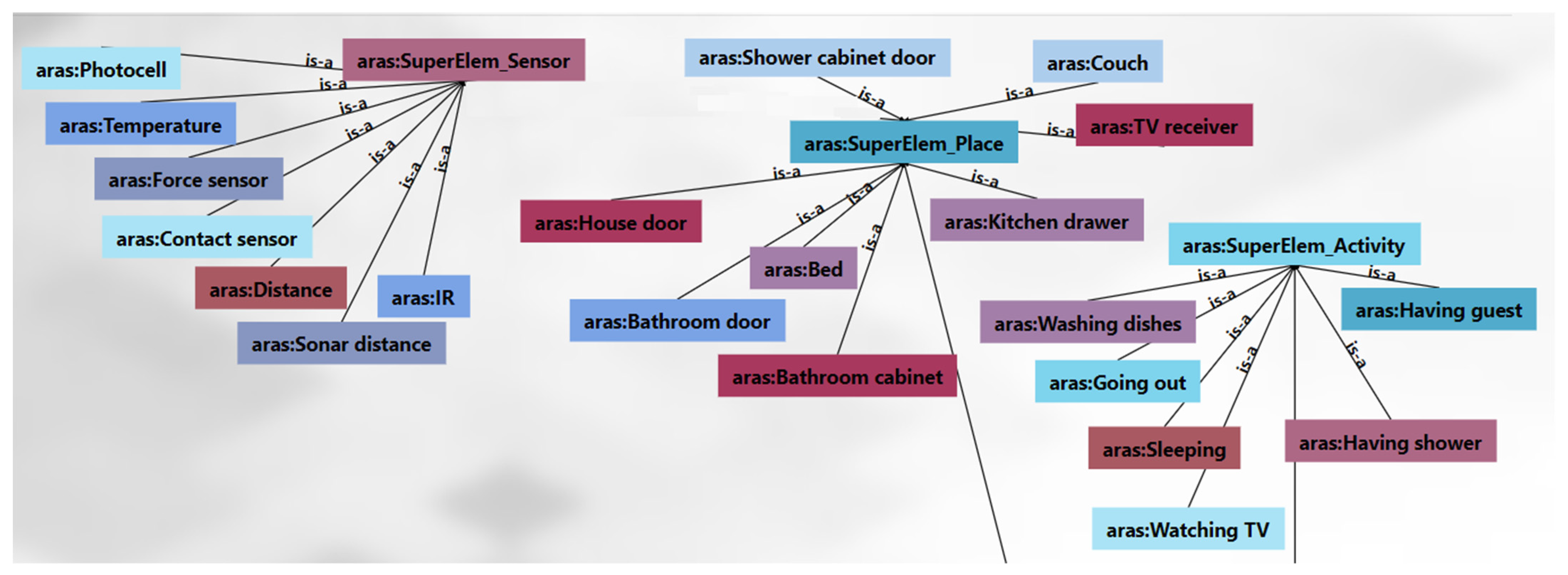
3.3. Ontology-Based Model’s Learning Module
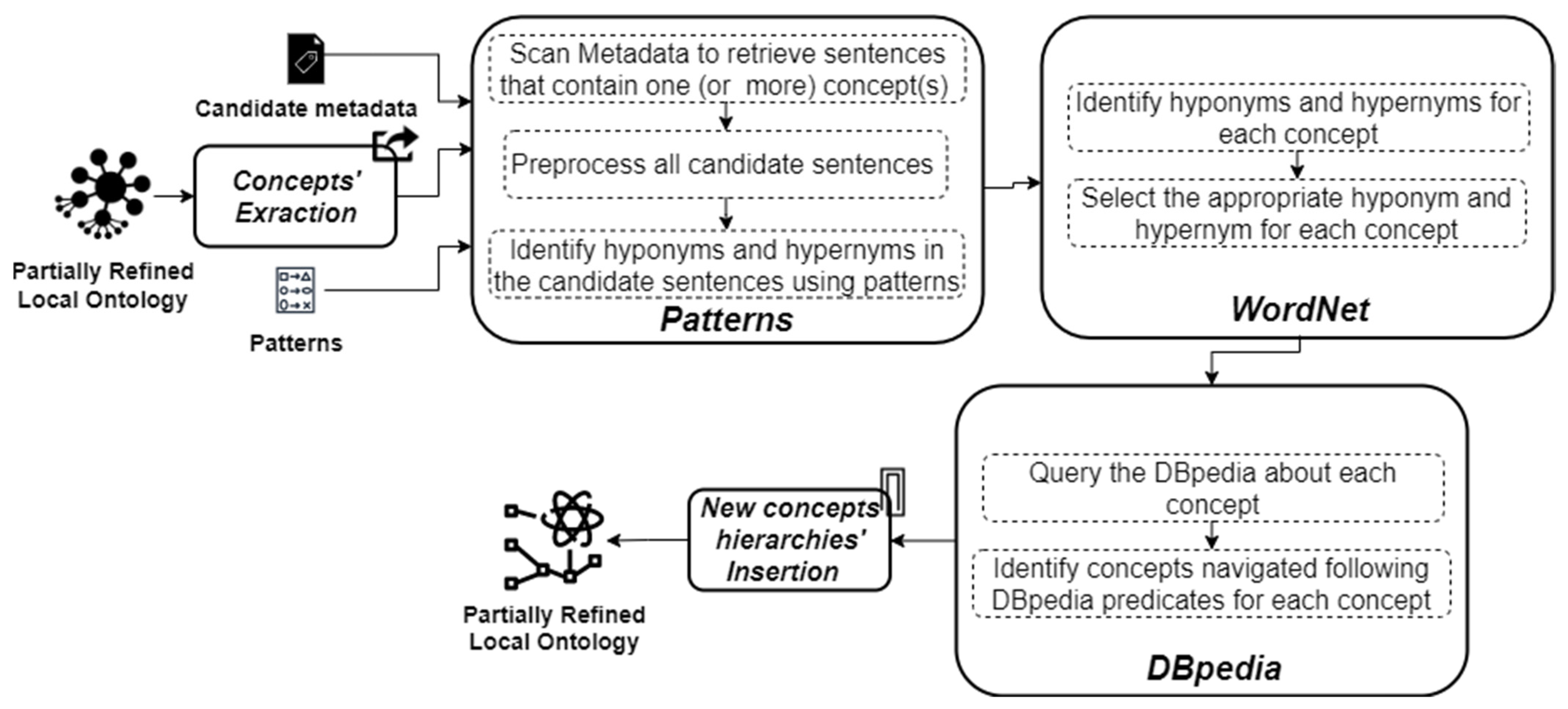
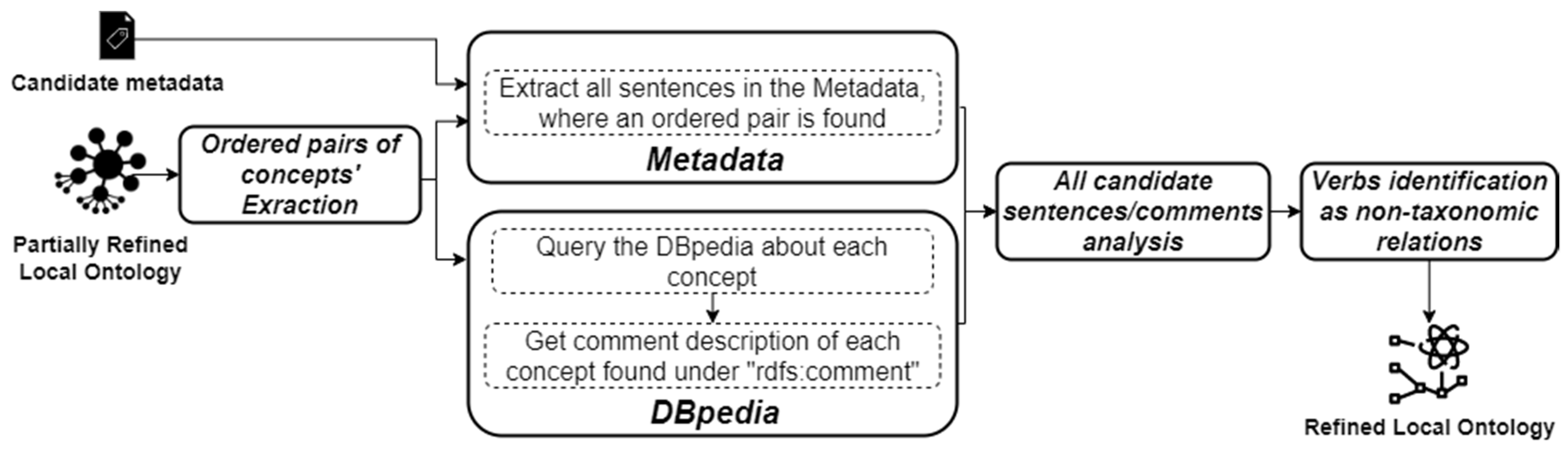
3.3.1. Learning Phase
3.3.2. Refinement Phase
| Algorithm 1. The Proposed Missing Concepts Refinement Algorithm |
| Input: LocalOntology, Metadata, LSPs |
| Output: PartiallyRefined_LocalOntology |
| 1. DataTypePropertiesSet = GetAllDatatypeProperties (LocalOntology) |
| 2. For each DatatypeProperty ∈ DataTypePropertiesSet do |
| 3. Domain = GetDomain (DatatypeProperty) |
| 4. SentencesSet = FindSentences (DatatypeProperty, Metadata) |
| 5. For each Sentence ∈ SentencesSet do |
| 6. Sentence = PartsOfSpeechTagging(Sentence, POS) |
| 7. NewDomain = matches (Sentence, LSPs) |
| 8. If NewDomain ≠ ∅ then |
| 9. PartiallyRefined_LocalOntology = UpdateMissingConcept (DatatypeProperty,Domain,NewDomain) |
| 10. End If |
| 11. End For |
| 12. End For |
| 13. End. |
3.4. Ontology-Based Model Integration Module
3.4.1. Alignment Phase
3.4.2. Merging Phase
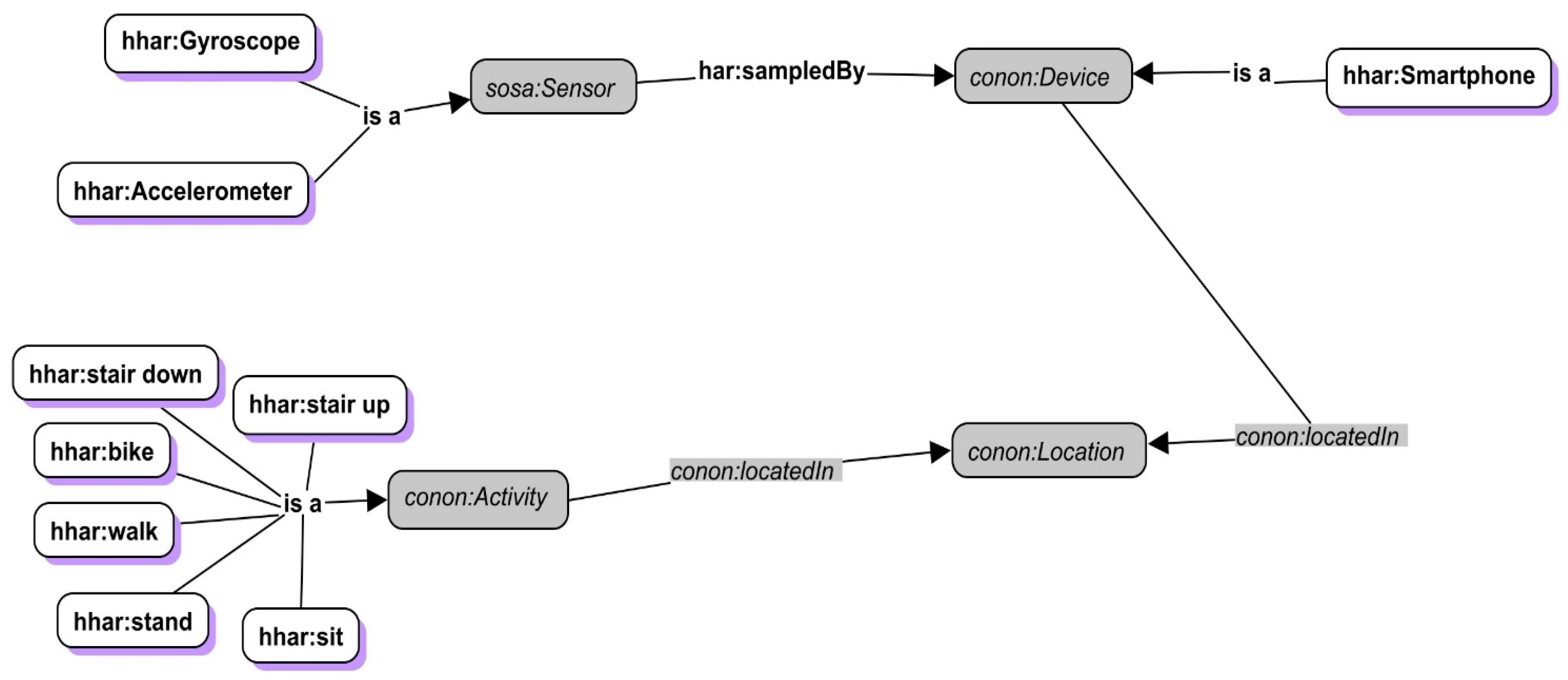
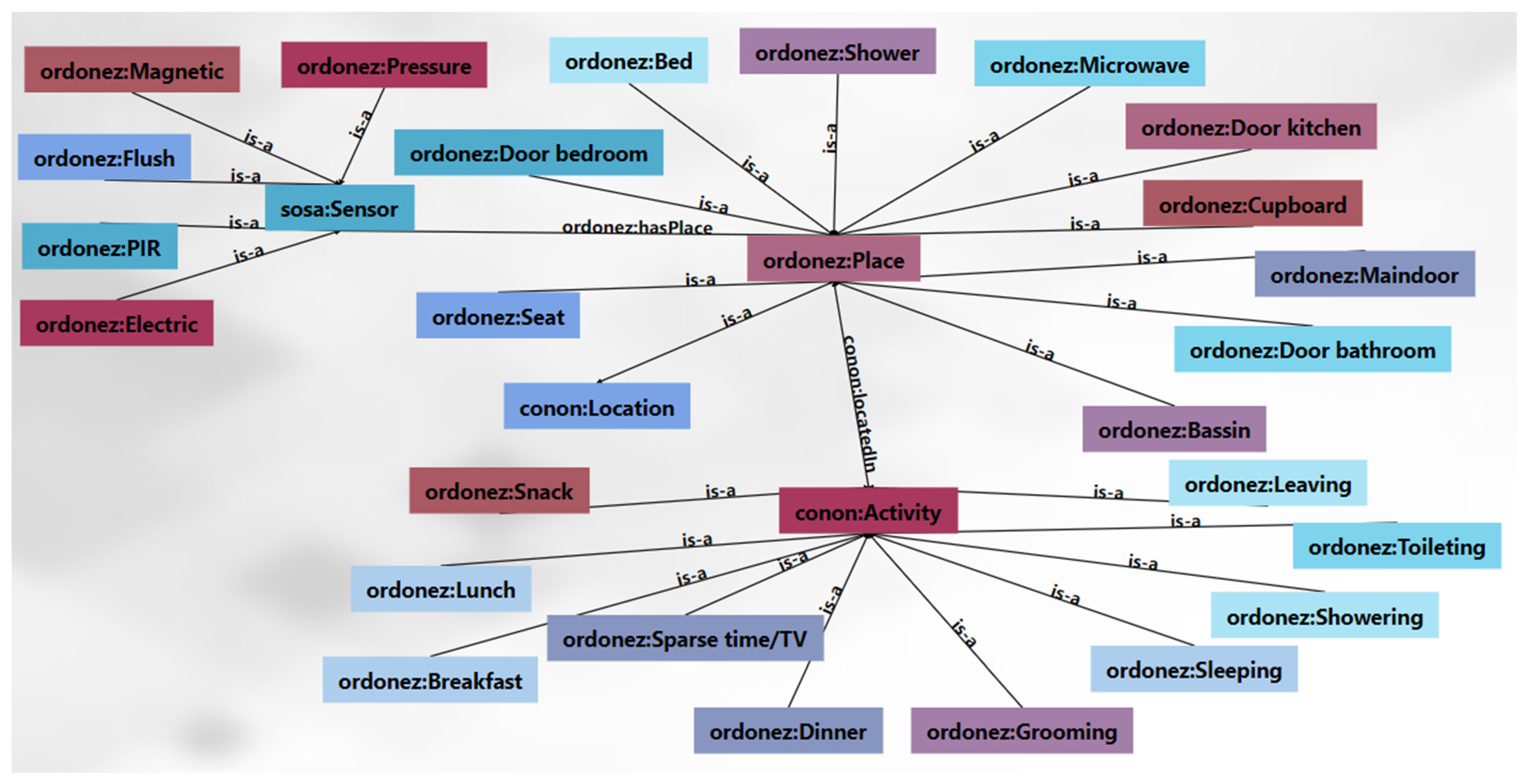
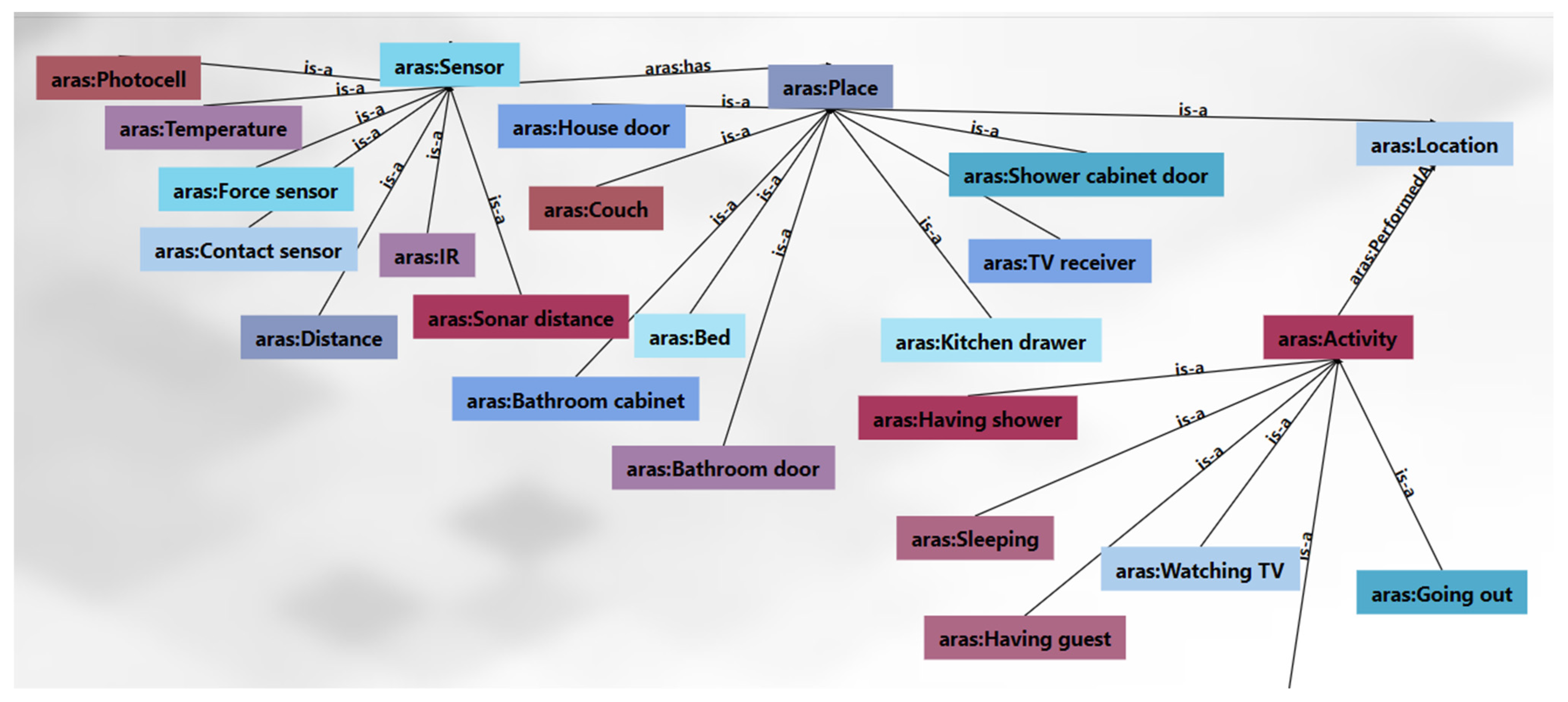
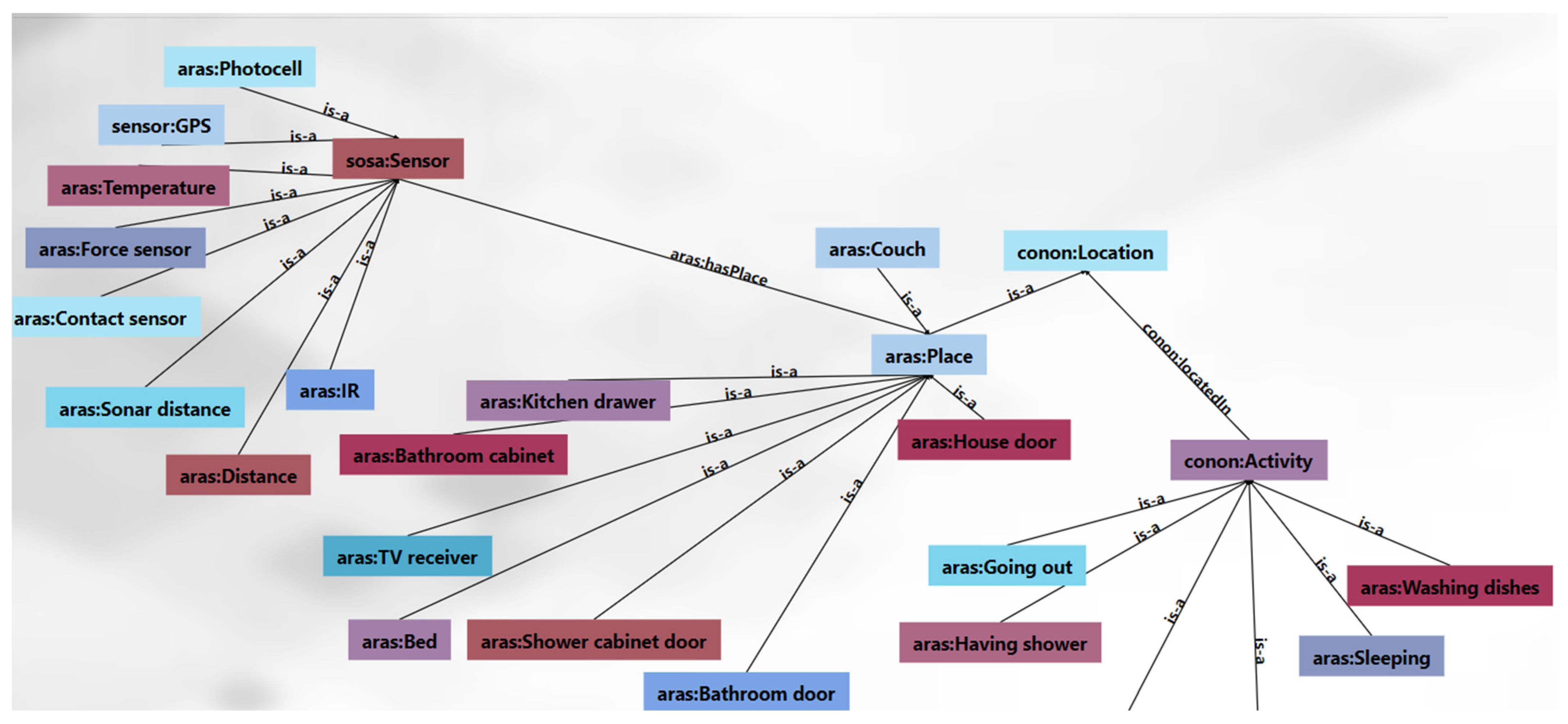
4. Proof of Concept and Case Study
4.1. Proof of Concept
4.2. Case Study
- Scenario 1: Moving from an ordinary apartment to a smart apartment.
- Scenario 2: Moving from a smart apartment to a smart home.
5. Evaluation
5.1. Feature-Based Evaluation
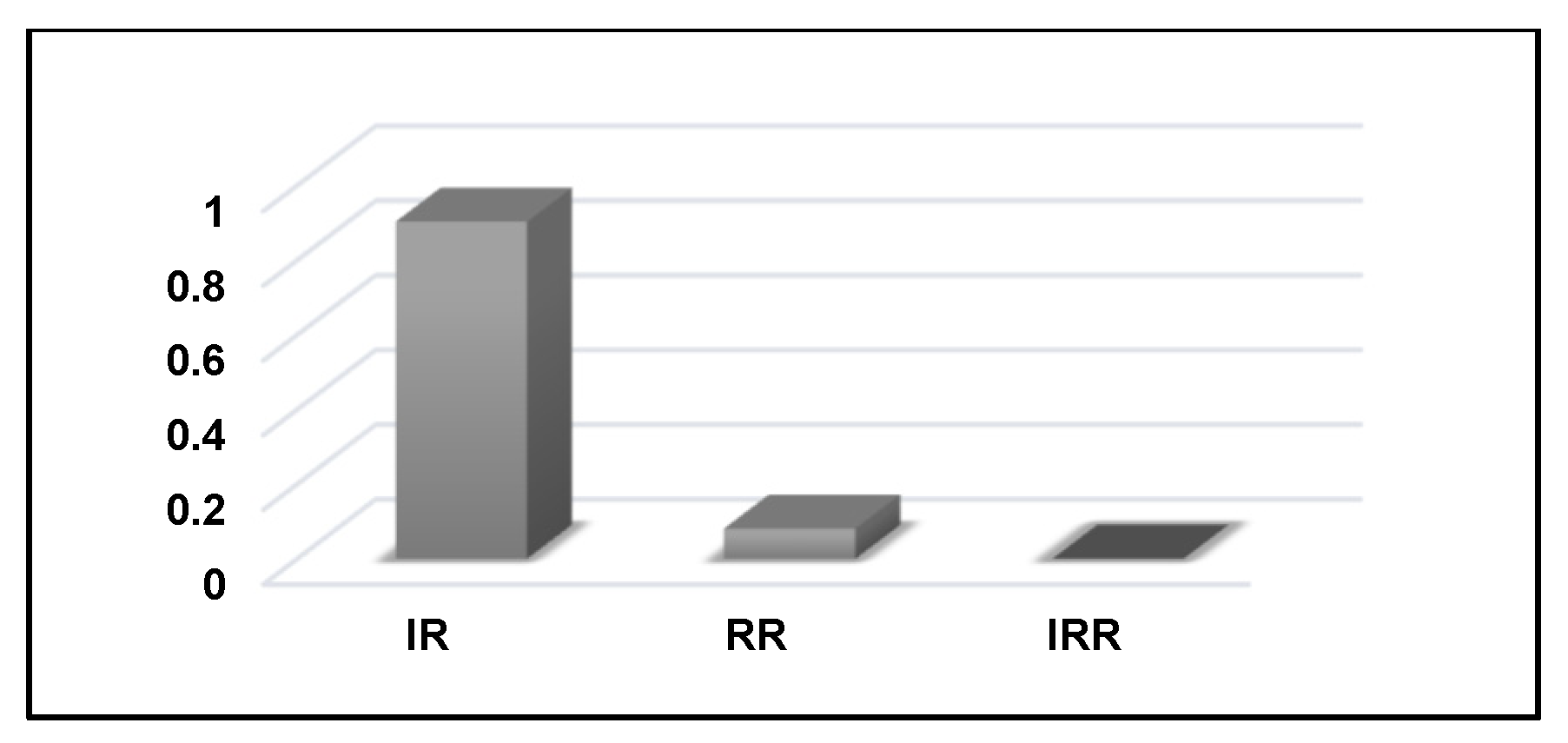
- The schema metrics assess the design of ontologies by calculating and comparing statistics about the concepts, inheritance levels, relation types, properties, and other elements. They stand for searching for schema-related errors such as recursive definitions, unconnected concepts, missing domains or ranges, and missing inverse relations. The most essential and significant metrics of the schema category are the following: the Inheritance Richness (IR), Relationship Richness (RR) and Inverse Relations Ratio (IRR).
- ○
- The IR is a way to measure the overall levels of the distribution of concepts of the ontology’s inheritance tree. It is known as the average number of sub-concepts per concept to describe how the concepts are distributed across the different levels of the ontology and thus distinguish shallow from deep ontologies. A relatively low IR result would correspond to a deep or vertical ontology that covers its targeted environment in a very detailed way, while a high result, by contrast, would reflect a shallow or horizontal ontology that tends to represent a wide range of general concepts with fewer levels.
- ○
- The RR examines the existing relations within an ontology to reflect the diversity of relationships. It is calculated as the fraction of the number of non-taxonomic relations, specifically the object properties, and the total number of sub-concepts and non-taxonomic relations in the ontology. The RR result is a number between 0 and 1, where a high value closer to 1 indicates that the ontology is rich and contains a variety of non-taxonomic relations, while a small RR value closer to 0 indicates that the ontology mostly consists of subsumption relations.
- ○
- The IRR illustrates the ratio between the inverse non-taxonomic relations and all non-taxonomic relations. Lower values for this metric indicate a deficiency in the definition of inverse non-taxonomic relations in the ontology.
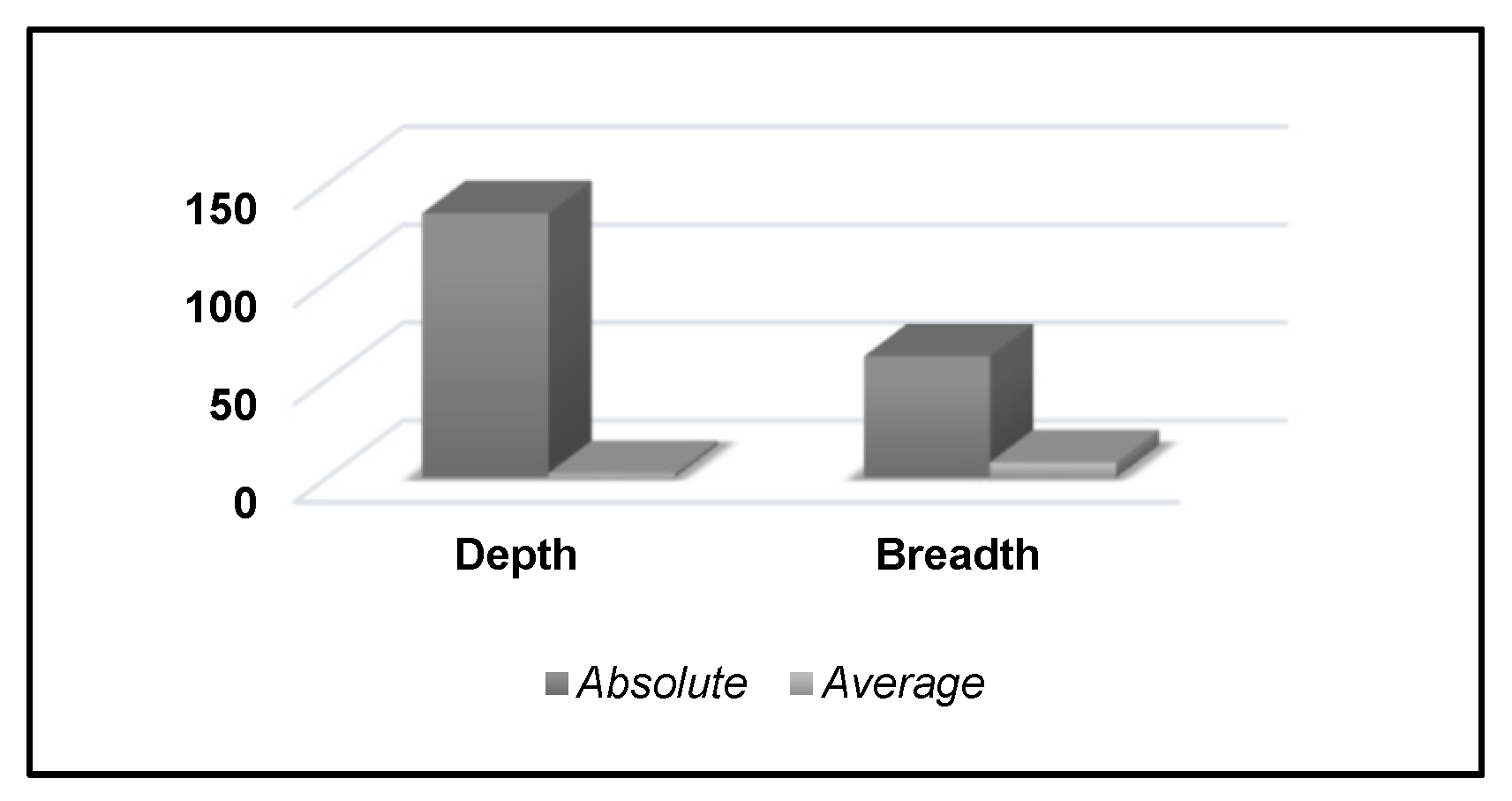
- Graph metrics are also known as structural metrics, where the taxonomy of ontologies is analyzed. These metrics calculate the cardinality and depth of the ontology structure in terms of the absolute and average depth, breadth, and so on. The depth metric that consists of an absolute and average is associated with the cardinality of the paths. The breadth metric, which is represented by the absolute and average, expresses the cardinality of the levels. The value of these different parameters in the graph metrics depicts the effectiveness of an ontology structure.
5.2. Criteria-Based Evaluation
5.3. Expert-Based Evaluation
6. Results
6.1. Evolved Ontology-Based Models’ Overview
6.2. Feature-Based Evaluation Results
6.3. Criteria-Based Evaluation Results
6.4. Expert-Based Evaluation Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Echarte, F.; Astrain, J.J.; Córdoba, A.; Villadangos, J.E. Ontology of Folksonomy: A New Modelling Method. SAAKM 2007, 289, 36. [Google Scholar]
- Rani, M.; Dhar, A.K.; Vyas, O. Semi-automatic terminology ontology learning based on topic modeling. Eng. Appl. Artif. Intell. 2017, 63, 108–125. [Google Scholar] [CrossRef] [Green Version]
- Krataithong, P.; Buranarach, M.; Hongwarittorrn, N.; Supnithi, T. Semi-automatic framework for gener-ating RDF dataset from open data. In International Symposium on Natural Language Processing; Springer: Cham, Switzerland, 2016; pp. 3–14. [Google Scholar]
- Yao, Y.; Liu, H.; Yi, J.; Chen, H.; Zhao, X.; Ma, X. An automatic semantic extraction method for web data interchange. In Proceedings of the 2014 6th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 26–27 March 2014; IEEE: Washington, DC, USA, 2014; pp. 148–152. [Google Scholar]
- Booshehri, M.; Luksch, P. An Ontology Enrichment Approach by Using DBpedia. In Proceedings of the 5th International Conference on Web Intelligence, Mining and Semantics, Larnaca, Cyprus, 13–15 July; ACM Press: New York, NY, USA, 2015; pp. 1–11. [Google Scholar]
- Gómez-Pérez, A.; Manzano-Macho, D. A survey of ontology learning methods and techniques. OntoWeb Deliv. D 2003, 1. [Google Scholar]
- Asim, M.N.; Wasim, M.; Khan, M.U.G.; Mahmood, W.; Abbasi, H.M. A survey of ontology learning techniques and applications. Database 2018, 24, 2018. [Google Scholar] [CrossRef] [PubMed]
- Lehmann, J.; Voelker, J. An introduction to ontology learning. Perspect. Ontol. Learn. 2014, 18, 7–14. [Google Scholar]
- Ma, C.; Molnár, B. Use of Ontology Learning in Information System Integration: A Literature Survey. In Machine Learning and Knowledge Discovery in Databases; Springer: Vienna, Austria, 2020; pp. 342–353. [Google Scholar]
- Jablonski, S.; Lay, R.; Meiler, C.; Muller, S.; Hümmer, W. Data logistics as a means of integration in healthcare applications. In Proceedings of the 2005 ACM symposium on Applied computing—SAC’ 05, Santa Fe, NM, USA, 13–17 March 2005; ACM Press: New York, NY, USA, 2005; p. 236. [Google Scholar]
- Völker, J.; Niepert, M. Statistical Schema Induction. In Proceedings of the 8th Extended Semantic Web Conference, Heraklion, Crete, Greece, 29 May–2 June 2011; Springer: London, UK, 2011; pp. 124–138. [Google Scholar]
- Bohring, H.; Auer, S. Mapping XML to OWL ontologies. In Marktplatz Internet: Von e-Learning bis e-Payment, Leipziger Informatik-Tage (LIT 2005); Gesellschaft für Informatik e. V.: Berlin, Germany, 2015. [Google Scholar]
- Lakzaei, B.; Shmasfard, M. Ontology learning from relational databases. Inf. Sci. 2021, 577, 280–297. [Google Scholar] [CrossRef]
- Sbai, S.; Chabih, O.; Louhdi, M.R.C.; Behja, H.; Zemmouri, E.M.; Trousse, B. Using decision trees to learn ontology taxonomies from relational databases. In Proceedings of the 2020 6th IEEE Congress on Information Science and Technology (CiSt), Agadir-Essaouira, Morocco, 5–12 June 2021; IEEE: Washington, DC, USA, 2020; pp. 54–58. [Google Scholar]
- Aggoune, A. Automatic ontology learning from heterogeneous relational databases: Application in alimenta-tion risks field. In Proceedings of the IFIP International Conference on Computational Intelligence and Its Applications, Oran, Algeria, 8–10 May 2018; Springer: Cham, Switzerland, 2018; pp. 199–210. [Google Scholar]
- Sbissi, S.; Mahfoudh, M.; Gattoufi, S. A medical decision support system for cardiovacsular disease based on ontology learning. In Proceedings of the 2020 International Multi-Conference on: “Organization of Knowledge and Advanced Technologies” (OCTA), Tunis, Tunisia, 6–8 February 2020; IEEE: Washington, DC, USA, 2020; pp. 1–9. [Google Scholar]
- Shamsfard, M.; Barforoush, A.A. The state of the art in ontology learning: A framework for comparison. Knowl. Eng. Rev. 2003, 18, 293–316. [Google Scholar] [CrossRef] [Green Version]
- Khadir, A.C.; Aliane, H.; Guessoum, A. Ontology learning: Grand tour and challenges. Comput. Sci. Rev. 2021, 39, 100339. [Google Scholar] [CrossRef]
- de Cea, G.A.; Gomez-Perez, A.; Montiel-Ponsoda, E.; Suárez-Figueroa, M.C. Natural Language-Based Approach for Helping in the Reuse of Ontology Design Patterns. In Proceedings of the Computer Vision, Acitrezza, Catania, Italy, 29 September–3 October; Springer: New York, NY, USA, 2008; pp. 32–47. [Google Scholar]
- Almuhareb, A. Attributes in Lexical Acquisition. Ph.D. Thesis, University of Essex, Essex, UK, 2006. [Google Scholar]
- Sowa, J.F. Knowledge Representation: Logical, Philosophical and Computational Foundations; Brooks/Cole Publish-ing Co.: Pacific Grove, CA, USA, 1999. [Google Scholar]
- Hearst, M.A. Automatic acquisition of hyponyms from large text corpora. In Proceedings of the 14th Conference on Computational Linguistics, Nantes, France, 23–28 August 1992; Volume 2, pp. 539–545. [Google Scholar]
- Hearst, M. WordNet: An Electronic Lexical Database and Some of Its Applications. Automated Discovery of WordNet Relations. 1998. Available online: https://direct.mit.edu/books/book/1928/WordNetAn-Electronic-Lexical-Database (accessed on 9 November 2021).
- Cederberg, S.; Widdows, D. Using lsa and noun coordination information to improve the recall and precision of automatic hyponymy extraction. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Stroudsburg, PA, USA, 31 May 2003; pp. 111–118. [Google Scholar]
- Apache Lucene Core. Available online: https://lucene.apache.org/core (accessed on 2 October 2021).
- Ordóñez, F.J.; De Toledo, P.; Sanchis, A. Activity Recognition Using Hybrid Generative/Discriminative Models on Home Environments Using Binary Sensors. Sensors 2013, 13, 5460–5477. [Google Scholar] [CrossRef] [PubMed]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; IEEE: Washington, DC, USA, 2013; pp. 232–235. [Google Scholar]
- Lantow, B. OntoMetrics: Putting Metrics into Use for Ontology Evaluation. In Proceedings of the 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Porto, Portugal, 9–11 November 2016; SCITEPRESS-Science and Technology Publications: Setubal, Portugal, 2016; pp. 186–191. [Google Scholar]
- Gómez-Pérez, A. From Knowledge Based Systems to Knowledge Sharing Technology: Evaluation and Assessment; Knowledge Systems Lab., Stanford University: Stanford, CA, USA, 1994. [Google Scholar]
- Guarino, N.; Welty, C. Evaluating ontological decisions with OntoClean. Commun. ACM 2002, 45, 61–65. [Google Scholar] [CrossRef]
- Poveda-Villalón, M.; Gómez-Pérez, A.; Suárez-Figueroa, M.C. Oops! (ontology pitfall scanner!): An on-line tool for ontology evaluation. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2014, 10, 7–34. [Google Scholar] [CrossRef] [Green Version]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Jensen, M.M. Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition. In Proceedings of the 13th ACM conference on embedded networked sensor systems, Seoul, Korea, 1–4 November 2015; pp. 127–140. [Google Scholar]
- Morgner, P.; Müller, C.; Ring, M.; Eskofier, B.; Riess, C.; Armknecht, F.; Benenson, Z. Privacy implica-tions of room climate data. In European Symposium on Research in Computer Security; Springer: Cham, Switzerland, 2017; pp. 324–343. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing Detailed Human Context In-the-Wild from Smartphones and Smart-watches. arXiv 2017, arXiv:1609.06354. [Google Scholar]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Learning Element | Pivot Model | Pivot Model’s Hierarchy | Ontology Refinement | Ontology Alignment | Ontology Merging | Automation Degree | |
|---|---|---|---|---|---|---|---|---|
| Jablonski et al. [10] | Semi-Structured: CSV | I | XML data | x | x | x | x | Automatic |
| Völker and Niepert [11] | Strucured: DBpedia | C + NTR + I | x | x | x | x | x | Automatic |
| Bohring and Auer [12] | Semi-Structured: XML | C + NTR + D + I + A | x | x | x | x | x | Automatic |
| Krataithong et al. [3] | Semi-Structured: CSV or XSL | C + NTR + D | RDB schema | x | x | x | x | Semi-Automatic |
| Lakzaei and Shmasfard [13] | Structured: RBD | C + TR + NTR + D + I + A | x | x | x | x | x | Automatic |
| Sbai et al. [14] | Structured: RBD | C + TR | x | x | x | x | x | Semi-Automatic |
| Yao et al. [4] | Semi-Structured: JSON | C + NTR + D + I | x | x | Predefined Rules | √ | √ | Semi-Automatic |
| Booshehri and Luksch [5] | Unstructured: Text | NTR | x | x | LOD with DBpedia | x | √ | Semi-Automatic |
| Aggoune [15] | Structured: RBD | C + NTR + D + I | x | x | x | x | √ | Automatic |
| Sbissi et al. [16] | Unstructured: Text | C + TR + NTR + D+I + A | x | x | x | x | √ | Automatic |
| Our approach | Semi-Structured: CSV, JSON or XML | C + TR + NTR + D + I + A | XML schema+ data | √ | LOD with DBpedia + WordNet + Metadata | √ | √ | Automatic |
| CSV | XML Schema |
|---|---|
| Table name (group of CSV files) | Complex type |
| Column (non-nominal datatype) | Attribute with column datatype as type |
| Column (nominal datatype) | Element inside an anonymous complex type |
| Column (group of CSV files) | Element inside an anonymous complex type |
| Label column | Complex type uses extension |
| XML Schema | OWL Ontology |
|---|---|
| xsd:complexType: xsd:element, containing other elements or having at least one attribute | owl:Class, coupled with owl:ObjectProperty |
| xsd:attribute | owl:DataProperty with a range depending on the attribute type |
| xsd:element, inside an anonymous complex type | owl:ObjectProperty |
| xsd:complexType, which uses extensions | owl:Class as an owl:subClassOf “base type” |
| LSP | Example | Relation |
|---|---|---|
| Property|ies | characteristic|s | attribute|s of NP<class> be [PARA] [(NP<property>,) * and] NP<property> | Attributes of an accelerometer are X, Y, and Z | Datatype properties: X, Y, Z Class or domain: accelerometer |
| NP<class> be [(AP<property>,) *] and AP<property> | Metals are lustrous, malleable, and good conductors of heat and electricity | Datatype property: lustrous Class or domain: metal |
| NP<class> have NP<class> | A car has a color | Datatype property: color Class or domain: car |
| NN with|without DT? RB? JJ? ATTR | A pizza with some cheese. | Datatype property: cheese Class or domain: pizza |
| DT ATTR of DT? RB? JJ? NN | The color of the car | Datatype property: color Class or domain: car |
| Pattern Group | Pattern |
|---|---|
| Hearst’s patterns | NP {,} such as {NP,} * {and|or} NP |
| NP {,} including {NP,} * {and|or} NP | |
| NP {,} especially {NP,} * {and|or} NP | |
| Cea’s patterns | [(NP<subclass>,) * and] NP<subclass> be [CN] NP<superclass> |
| [(NP<subclass>,) * and] NP<subclass> (classify as) | (group in|into|as) | (fall into) | (belong to) [CN] NP<superclass> | |
| There are CD | QUAN [CN] NP<superclass> PARA [(NP<subclass>,) * and] NP<subclass> |
| Criteria | Description | Related OOPS! Pitfalls |
|---|---|---|
| Consistency | To ensure that the evolved ontology-based models do not contain any inconsistencies (e.g., contradictory or conflicting output results). | P05: Define incorrect inverse relationship. P06: Involve cycles in hierarchy. P07: Merging dissimilar concepts in the same concept. P19: Swapping intersection and union. P24: Using recursive definition. |
| Completeness | To ensure that all output results that are supposed to be in the evolved ontology-based models are explicitly presented. | P04: Creating unconnected ontology elements. P11: Missing domain or range in properties. P12: Missing equivalent properties. P13: Inverse relationships not explicitly declared. |
| Conciseness | To ensure that the evolved ontology-based models do not include redundancies (e.g., irrelevant or redundant output results). | P02: Creating class synonyms. P03: Creating “is” relationship place of “rdfs:subClassOf”, “rdf:type”, or “owl:sameAs”. P21: Using a miscellaneous concept. |
| #Concepts | #Relations | Candidate Dataset | ||||
|---|---|---|---|---|---|---|
| Name | Setting | #Dataset Size | #Dataset Observation | |||
| Evolved ontology-based model 1 | 68 | 80 | ARAS [27] | Smart home | 47 | 5,184,000 |
| Evolved ontology-based model 2 | 37 | 54 | Ordonez [26] | Smart apartment | 24 | 20,358 |
| Evolved ontology-based model 3 | 26 | 38 | HHAR [32] | Ordinary apartment | 16 | 43,930,250 |
| Evolved ontology-based model 4 | 22 | 31 | RCD [33] | Smart room | 14 | 250,000 |
| Evolved ontology-based model 5 | 139 | 167 | ExtraSensory [34] | Outdoor or indoor | 127 | 300,000 |
| Criteria | Detected Pitfall | Affects to | OOPS! Importance Level | Satisfaction |
|---|---|---|---|---|
| Consistency | - | - | Normal | Yes, no contradictory or conflicting output results can be inferred by reasoners since OOPS! shows no errors for all evolved models. |
| Completeness | P13: Inverse relationship not explicitly stated | Non-taxonomic relations | Minor | No, the evolved models are not completed well since inverse relationships were not explicitly defined as determined by OOPS! |
| Conciseness | - | - | Normal | Yes, no unnecessary or redundant output results were contained in the evolved models according to OOPS! |
| Precision | Recall | F-Measure | |
|---|---|---|---|
| Initial ontology-based model | 0.69 | 0.48 | 0.57 |
| Evolved ontology-based model | 0.80 | 0.65 | 0.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jabla, R.; Khemaja, M.; Buendia, F.; Faiz, S. Automatic Ontology-Based Model Evolution for Learning Changes in Dynamic Environments. Appl. Sci. 2021, 11, 10770. https://doi.org/10.3390/app112210770
Jabla R, Khemaja M, Buendia F, Faiz S. Automatic Ontology-Based Model Evolution for Learning Changes in Dynamic Environments. Applied Sciences. 2021; 11(22):10770. https://doi.org/10.3390/app112210770
Chicago/Turabian StyleJabla, Roua, Maha Khemaja, Félix Buendia, and Sami Faiz. 2021. "Automatic Ontology-Based Model Evolution for Learning Changes in Dynamic Environments" Applied Sciences 11, no. 22: 10770. https://doi.org/10.3390/app112210770
APA StyleJabla, R., Khemaja, M., Buendia, F., & Faiz, S. (2021). Automatic Ontology-Based Model Evolution for Learning Changes in Dynamic Environments. Applied Sciences, 11(22), 10770. https://doi.org/10.3390/app112210770