1. Introduction
The emergence of a large number of online public opinions is the product of people expressing their own opinions in response to various events, and the resulting online public opinions are related to the development of things. Sina Weibo (referred to in this paper as ‘Weibo’), as one of the social platforms with the most users in China, carries a large amount of online public opinion. Users post their views on things in the form of short texts on the Weibo platform for other users to browse, comment on and forward. In addition, users can also search for related events by keywords. Through these methods, certain events that attract people’s attention can be spread quickly and widely, and then generate public opinion on the internet. Therefore, Weibo is regarded as a platform for the public to collect and publish information and learn about social knowledge to manage uncertainty and risk [
1], hence sentiment analysis of Weibo text is critical.
Text sentiment analysis refers to analyzing the emotional information contained in a text and classifying it into its category, and the classification results can be applied to some other downstream tasks. It plays a vital role in monitoring online public opinion. Analyzing the emotional tendency of short texts posted by Weibo users can not only aid understanding of users’ views on things and grasp user psychology, but also further control the trend of online public opinion and improve government credibility. It also can speed up the government’s response to online public opinion.
Recently, sentiment analysis has been a research hotspot in the field of data mining and natural language processing [
2]. Therefore, many methods for sentiment analysis were born. At present, commonly used text sentiment analysis methods are divided into early rule-based methods, machine learning methods, and the currently more popular deep learning methods. Rule-based methods include methods based on sentiment dictionary, and so forth. This method requires artificial construction of sentiment dictionary [
3]. However, due to the endless emergence of a large number of online new words and new ideas in the internet, the constructed sentiment dictionary can not meet the needs, so this method cannot achieve a high accuracy rate [
4]. Methods based on machine learning include support vector machine, decision tree, and so forth, which also require a certain labor cost, and the accuracy of classification depends on the results of feature extraction. However, due to the continuous emergence of massive information, it is difficult to fully extract text features, making the classification accuracy drop. Compared with the traditional machine learning methods, the deep learning technology that appeared later has achieved more successful results in the fields of computer vision [
5], machine translation [
6], and text classification [
7]. Methods based on deep learning algorithms such as CNN and LSTM do not require manual intervention, and the classification accuracy is high but it needs to use a large scale dataset to train the model, and it is difficult to construct a large scale and high-quality training dataset. At present, many researchers combine rule-based methods with machine learning or deep learning techniques. They have achieved satisfactory results in terms of accuracy, but there are often problems such as excessively complex models [
8].
In view of the shortcomings of the above methods, in order to increase the accuracy of the text sentiment analysis model, based on the BERT and related deep learning techniques, this paper proposes a new sentiment analysis model. Experimental results show that this model has significantly improved accuracy compared with other similar models.
4. Proposed Method
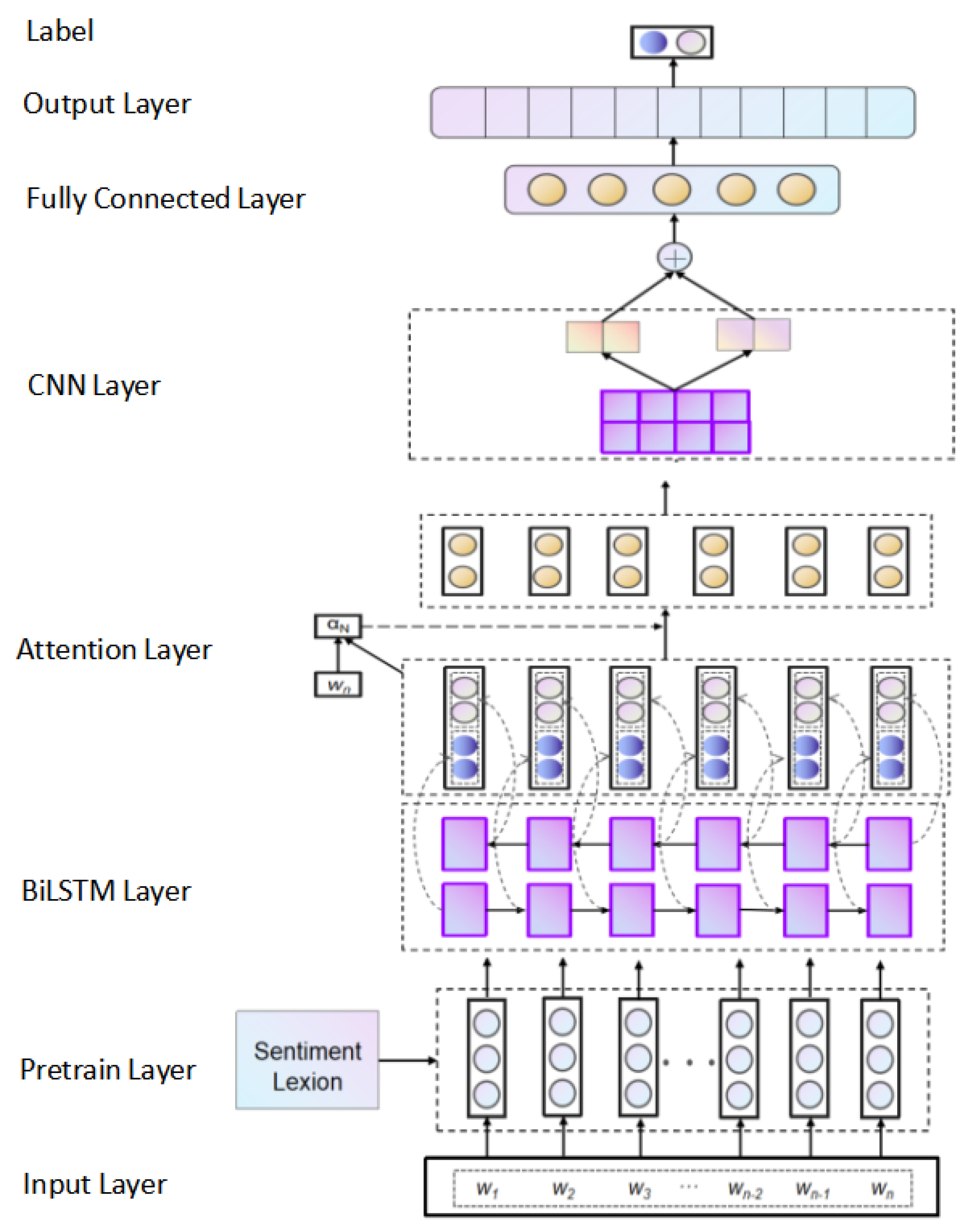
Aiming at the shortcomings of most existing sentiment classification models, this paper proposes a new model. The model consists of five parts: Pre-train layer, BiLSTM layer, Attention layer, CNN layer and Full Connected layer. The structure is shown in
Figure 4:
Suppose the input text sentence is , where represents the i-th word in the sentence S. The task of the model is to assume a given text sentence S, input S into the model, and the model outputs the sentiment polarity P of the sentence.
We first need to build a sentiment dictionary
, which consists of two parts, the first part is the sentiment words, and the second part is the sentiment weight
corresponding to each sentiment word. The function of the sentiment dictionary is to assign a sentiment weight
to words that belong to
in
S, and to assign a sentiment weight one to words that do not belong to
in
S. The sentiment dictionary used in this article is based on the open source sentiment dictionary provided by Dalian University of Technology [
30]. We only retain the positive and negative words in the original dictionary, and removes the words that represent neutral or both genders. The sentiment strength of the word in the original sentiment dictionary is used as the sentiment weight
of the constructed sentiment dictionary. It is worth mentioning that, for negative words, the sentiment weight should be the sentiment strength multiplied by
. The expression of sentiment weight is as follows:
In Formula (
10),
represents the
i-th word in
S,
represents the sentiment weight of the word
in the constructed sentiment dictionary, and
is the constructed sentiment dictionary.
In the pre-train layer, through the fine-tuned BERT model, the input word
is converted into a word vector
, and then the sentiment weight in
is used to weight
, as shown in Formula (
11):
The weighted word vector carries a stronger emotional color, and we use it as the input of the BiLSTM layer. At this time, the text sentence starts to classify. In the text data, the current word will be affected by adjacent words, and the LSTM network can only extract information in one direction, so this paper chooses to use the BiLSTM network. The BiLSTM network can process a long text sequence and apply it after the pre-train layer which function is to extract the dependencies of the text in the forward and backward directions. It can combine the historical information at the previous moment and the input at the current moment to determine the output information at the current moment, so it can extract contextual features in the sequence data. For the input
at time
t, the hidden state representation
and
obtained by the forward LSTM and the reverse LSTM, as shown in Formulas (
12) and (
13):
For each word, we can connect its forward and backward context information, and then obtain the annotation of the word. Combining
and
is the output
of the state at time
t, as shown in Formula (
14):
In the task of text sentiment analysis, some words have a strong emotional color, and some words have no emotional color or only a small amount of emotional color. Different words have different effects on judging the sentiment polarity of the entire text. Therefore, the model introduces an attention mechanism to assign different sentiment weights to different words. Word with stronger emotion is given a higher attention, that is, a higher weight is assigned. For the hidden state output
of BiLSTM, the attention weight is allocated as follows:
In the above formula, is the hidden state representation, is the contextual content vector of the article, is randomly initialized at the beginning of training and is continuously optimized during the training process.
The similarity between and is used to judge the importance of the word. We standardize to get the attention weight, and the calculated attention weight is finally weighted with and aggregated into . represents the entire input text vector, which contains the sentiment information of all words in the text.
After obtaining the comment vector containing all word information, convolution is performed on the comment vector. Convolution is to extract the most influential local feature information in the input text information through a filter, which can reduce the data dimension and the model can get the position invariant. The convolutional operation is performed according to Formula (
1).
After the convolutional operation is over, we perform the pooling operation. The role of the pooling layer is to further compress the convolutional feature vector, which can reduce the vector dimension and reduce the computational complexity. Traditional pooling methods include max pooling and average pooling. If max pooling is used, while retaining the most important features, other important features may be omitted. Therefore, this article uses both max pooling and average pooling in parallel. In this way, the two pooled feature vectors are connected together as the final feature vector and sent to the fully connected layer, which can improve the robustness of the feature vector while retaining important features as much as possible. The max pooling and average pooling operations are independently applied to the feature vector after the convolution operation, and then the results of the two are connected to obtain the text vector .
After obtaining the pooled
vector, this paper uses batch normalization to speed up network training and reduce overfitting [
31]. In order to predict the emotional polarity of the review, the fully connected layer is used to convert the text vector
into the final emotional representation
, and finally the emotional representation
is sent to the output layer to perform the binary classification task using the sigmoid function.
In the output layer, the sigmoid function is used to convert the sentiment representation
into the approximate probability value
of each emotional polarity category. This function can map the input information to the
interval.
close to 0 indicates that the sentiment category is close to negative,
close to 1 means that the sentiment category is close to positive, and then the emotional label of the input text is obtained, that is, the positive and negative two-category sentiment analysis task is completed.
where
is the high-level emotional representation obtained through the fully connected layer, and
and
are the parameter matrix and bias items that are continuously learned during the training process.
5. Experiment and Analysis
In this section, we evaluate our model for sentiment analysis task.
5.1. Experimental Setup
5.1.1. Dataset
The dataset used in this article is a public dataset of Weibo text collected during the COVID-19 epidemic. The dataset is based on the subject keywords related to ‘COVID-19’ for data collection, and captured from 1 January 2020 to 20 February 2020, a total of more than 1,000,000 Weibo data were labelled. The labelled results were divided into two categories: P (representing positive text) and N(representing negative text). We select more than 100,000 pieces of data as our dataset which contains 102,830 comments, of which 50,830 are positive comments and 52,000 are negative comments. Examples of emotional tags are shown in
Table 1:
5.1.2. Evaluation Criteria
The experiment uses four evaluation criteria: Accuracy (Acc), Precision (P), Recall (R) and F1-measure (F1), which are widely used in text classification and sentiment analysis tasks.
5.1.3. Data Preprocessing
First, the text data need to be segmented. This article uses Jieba tokenizer to segment the comments. Before segmentation, all words in the constructed sentiment dictionary should be added to the Jieba tokenizer to prevent sentiment words from being divided into two words, which will affect the result of sentiment analysis. After the word segmentation is over, illegal characters and stop words should be removed from the word segmentation results, which can improve the performance of the model.
5.2. Baselines
In order to verify the effectiveness of the proposed model in analyzing the sentiment of Weibo text comments collected during the epidemic, we designed the following comparative experiment.
CNN [
32]: The most basic convolutional neural network for sentiment analysis.
CNN+Att [
33]: After the convolutional neural network extracts the main features, it uses the attention mechanism to give different degrees of attention to the extracted features, and then classifies the feature vectors with different attention weights.
BiLSTM [
8]: Using two LSTM networks, it can process information in both forward and backward directions, effectively fusing text contextual content.
BiLSTM+Att [
34]: The attention mechanism is introduced into the BiLSTM network to assign different weights to different words, which can better reflect the importance of different words.
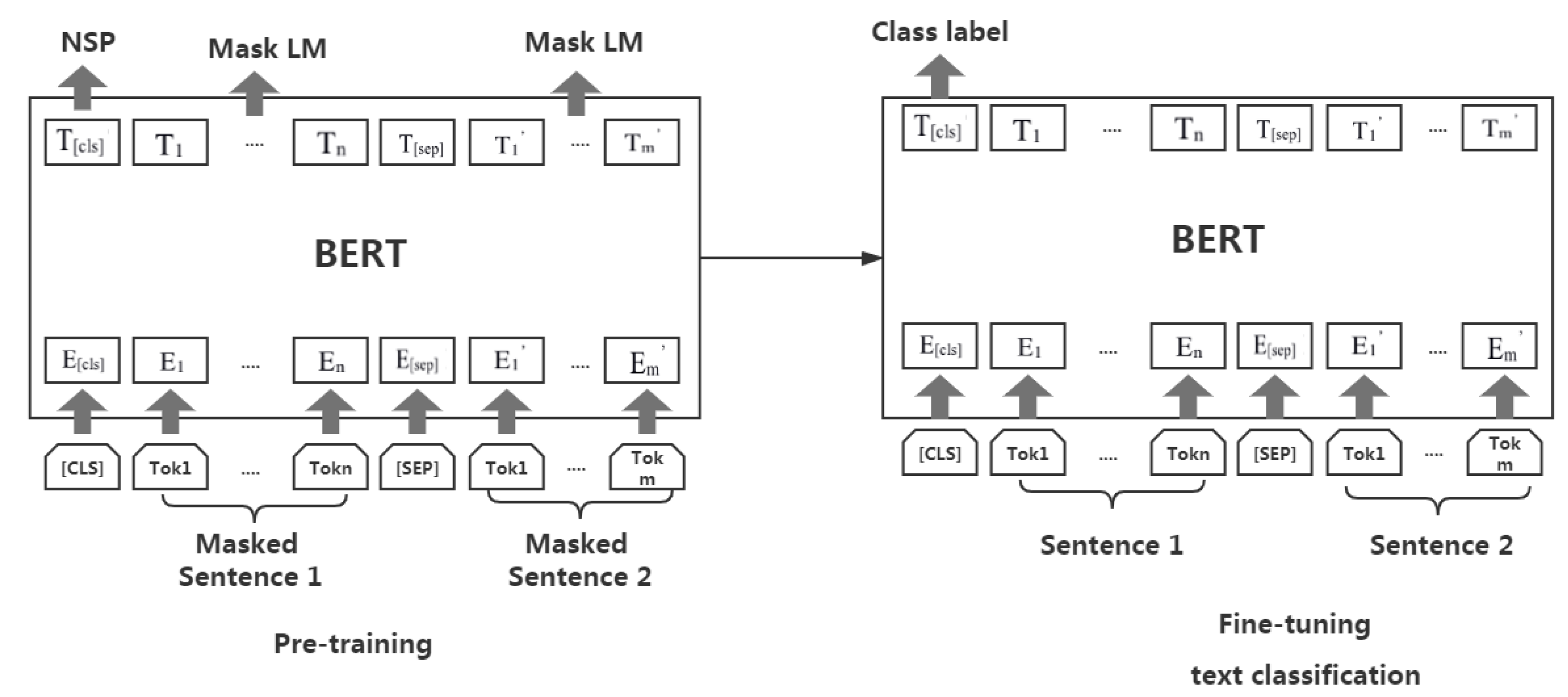
BERT [
24]: A powerful and open source text pre-training model based on the transformer structure.
BERT+BiLSTM+Att [
27]: The words are dynamically converted into word vectors through BERT, so that the converted word vectors are closer to the context. The generated word vectors are used to extract the sentiment features through the BiLSTM network, and the extracted feature vectors are given different attention weights through the attention mechanism.
AC-BiLSTM [
17]: A new framework for sentiment analysis that combines bidirectional LSTM (BiLSTM) and asymmetric CNN (ACNN) with high classification accuracy.
ABCDM [
18]: The model introduces a parallel mechanism so that BiLSTM and BiGRU can work at the same time. The addition of the attention mechanism allows the model to allocate weights more reasonably, and finally extract features through CNN.
5.3. Experimental Results
In order to evaluate the performance of our proposed model, we randomly divide the dataset into ten parts, using nine of them as the training set and validation set, the remaining one part as the test set, taking the results as the evaluation result of our model.
As we all know, the performance of the model is affected by the number of iterations. Therefore, the optimal number of iterations suitable for the model is explored here through experiments. The experimental results are shown in
Figure 5 and
Table 2. It can be seen that, when the number of iterations is eight, the performance of the model is optimal. When the number of times is greater than eight, the performance of the model begins to decline, which is caused by the phenomenon of overfitting. When the number of times is less than eight, the performance of the model is also not optimal due to the insufficient ability of learning features.
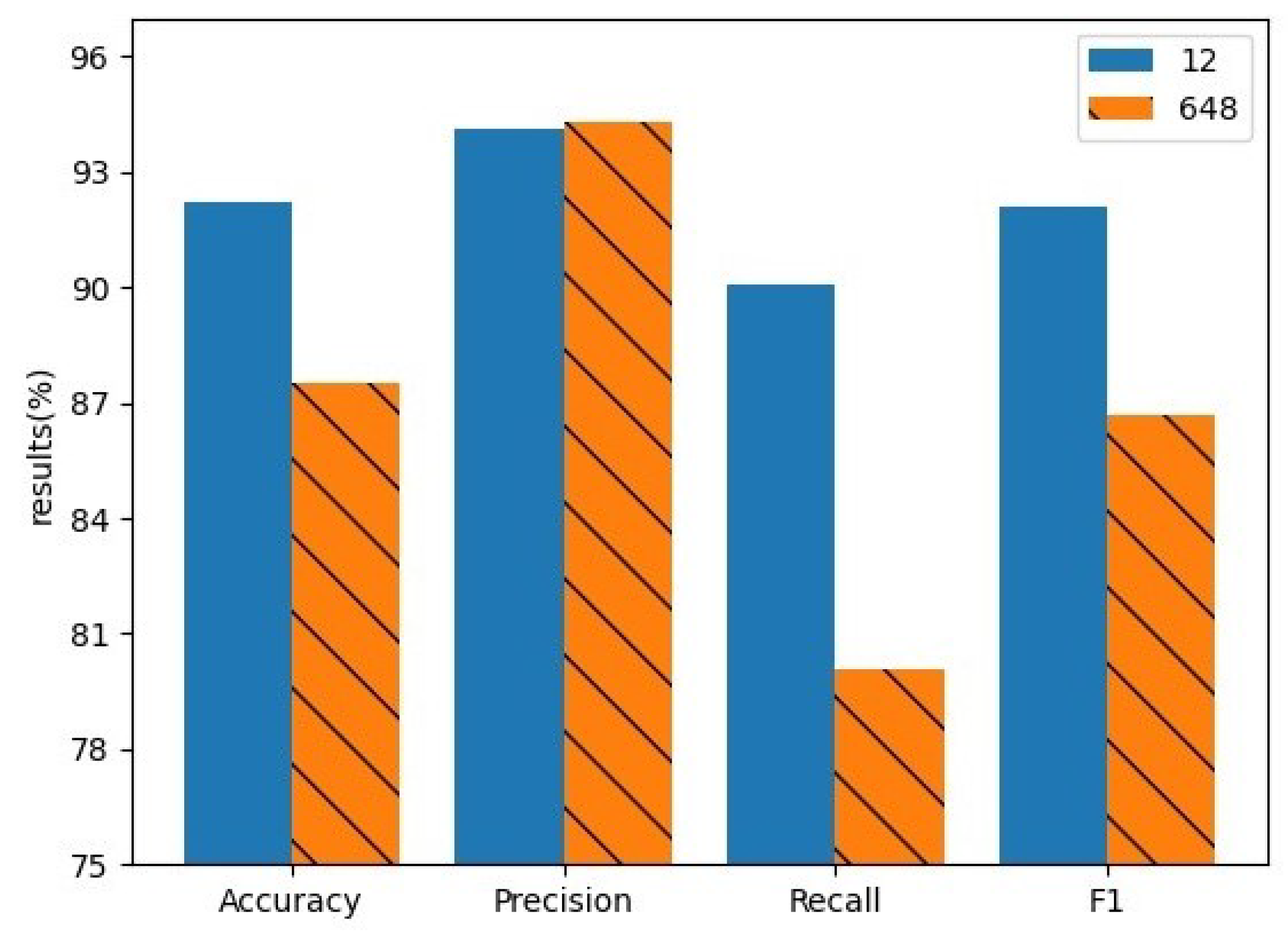
The input length of the text also affects the performance of the model. Therefore, choosing an appropriate input text length is very important. If the review length is larger than the selected length, it is intercepted, and if the review length is smaller than the selected length, 0 will be added. We chose the maximum text length of 648 and the average text length of 12 in the dataset for the experiment. The experimental results are shown in
Table 3 and
Figure 6. Through experiments, it can be seen that when the selected input text length is the average text length, the performance of the model is better. This is because the Weibo data is mostly short text. If a longer text length is selected, most texts need to be filled with a lot of zeros. Filling reduces the accuracy while increasing the time loss, thereby reducing the performance of the model.
We introduced the dropout value in the model to increase the generalization ability of the model, prevent the model from overfitting, and the performance of the neural network has been further improved. We set up different dropout values for comparison experiments, and learned through experiments that when the dropout value is equal to 0.6, the experimental result is the best. The dropout value at this time can effectively prevent the occurrence of model overfitting. The experimental results are shown in
Table 4 and
Figure 7.
Through the above experiments, the best parameters of the model are obtained. The parameter settings of the model are shown in
Table 5:
The experiment was conducted on the collected Weibo text dataset related to the COVID-19 epidemic. The experimental results of the proposed model and other competitive models are shown in
Table 6. We can divide the competition model into three parts. The first part is the traditional deep learning model, including CNN and BiLSTM, the second part is based on transformer models, such as BERT, and the last part is the combined model.
As shown in the table, although traditional deep learning models do not need to manually label features, their performance is not satisfactory. It is worth mentioning that the same is a deep learning related model, the accuracy of the BiLSTM network is noticeably higher than CNN. This is because BiLSTM considers the context information of text from two directions and solves the related dependencies of long text. In addition, the attention mechanism can also increase the accuracy by giving different degrees of attention to different words. After introducing the BERT language model, the accuracy of classification has been significantly increased. This is because BERT is a powerful pre-training language model. Unlike traditional language models such as Glove and Word2vec, BERT can dynamically, based on context, generate word vectors and use them for downstream tasks.
The proposed model defeats most competitive models in the accuracy of classification, and reflects its superiority. The advantages are mainly reflected in the following points: First, the model combines the advantages of BiLSTM, the CNN network, and the attention mechanism. Secondly, the model uses the more advanced BERT language model to mine the deep semantics of words and dynamically generate high-quality word vectors. Finally, the model introduces an external sentiment dictionary when constructing the word vector, and strengthens the sentiment intensity of the word vector through the sentiment dictionary.
The experimental results show that the accuracy and other performance indicators of the proposed model in this article are lower than those of the ABCDM model. This is because BiLSTM and BiGRU are used in parallel in ABCDM, which give the model the ability to process long text and short text at the same time, so its performance is slightly better than the model proposed in this paper. This has inspired us, and our model is also going to consider parallel mechanisms in the next step.
Besides, in order to study the impact of the introduction of sentiment dictionary and CNN on proposed model, we established four controlled experiments to conduct ablation studies based on the model proposed in this article:
−CNN − Lexion: We remove the emotional dictionary and convolutional neural network from our model, so that the remaining model is equivalent to the BERT + BiLSTM + Attention model. BERT dynamically converts words into word vectors, and then converts the word vectors It is sent to the BiLSTM network to extract context information, and then different word vectors are given different degrees of attention through the attention mechanism, and are finally sent to the output layer for classification.
−CNN + Lexion: We remove the convolutional and pooling operations. The pooling operation here refers to the parallelization of max pooling and average pooling, and then connect the pooled results (the same below), and retain external sentiment dictionary. Through this experiment, the influence of sentiment dictionary on the model can be explored.
+CNN − Lexion: We retain the convolutional and pooling operations, but do not introduce the external sentiment dictionary, through this experiment to learn about the effect of the CNN on the model.
+CNN + Lexion: All components of the model are retained.
The experimental results are shown in
Table 7 and
Figure 8. Compared with removing the CNN and the sentiment dictionary in the meantime, the accuracy of the experiment is increased by 2.7% when all components are retained. After adding the CNN, the accuracy is improved by 1.3%. This is because the CNN can extract local features and reduce the dimension of the feature vector. In addition, the average pooling result is added to the max pooling result to retain important features as much as possible and increase its robustness. It can also observe that the introduction of a sentiment dictionary can strengthen the performance of the model, and the accuracy of the experiment is increased by 1.6%. This is because some emotional words with strong emotional color play a significant role in judging the sentiment tendency of the entire text; we weight the word vectors through the introduced sentiment dictionary to improve the sentiment strength of the word vector, thereby improving the accuracy of classification.
6. Conclusions
At present, deep learning models are popular in the field of sentiment analysis, but the existing traditional models can be further increased in accuracy. This paper proposes a new model based on BERT and deep learning algorithms for sentiment analysis. The model uses the BERT to convert the words in the text into corresponding word vectors, and also introduces a sentiment dictionary to enhance the sentiment intensity of the word vector, and then uses a BiLSTM network to extract the forward and reverse contextual information. In order to more or less emphasize different words in the text, the attention mechanism is added to the output of the BiLSTM network. Through convolutional and pooling operations, the main features are extracted, which reduces the dimensionality of the feature vector and increases the robustness of the model. Therefore, the long-distance dependence between texts and local features are effectively processed.
We conducted experiments on the collected COVID-19 Weibo text dataset. Compared with the comparison model, the proposed model achieves the best experimental results. We also set up ablation experiments to explore the effects of CNN and the sentiment dictionary on the proposed model.
The research in this article points out two directions for our future work. One direction is that the BERT model consumes huge hardware resources and requires a huge corpus for training. How to train a high-quality and light weight BERT model and apply the trained BERT model to downstream tasks is our future research direction. On the other hand, we noticed that the accuracy of the experiment could be further improved by introducing an external sentiment dictionary. Therefore, our next goal is to introduce more external knowledge, such as part-of-speech information.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}