1. Introduction
An increasing number of machine learning algorithms have recently moved from academia to commercial applications. When applied to business, the number of samples collected is often small due to the need for rapid decision-making. The small-sample problem occurs in actual cases, such as in manufacturing industries [
1,
2,
3,
4], disease diagnosis [
5,
6,
7,
8], and DNA analysis of cancer patients [
9]. Datasets with imbalanced classes can be regarded as another case of the small sample problem, in which learning models ignore the information from the minority, and may thus output biased results [
10,
11,
12]. Therefore, it is a very important issue to enable machine learning to undertake effective training with a small dataset.
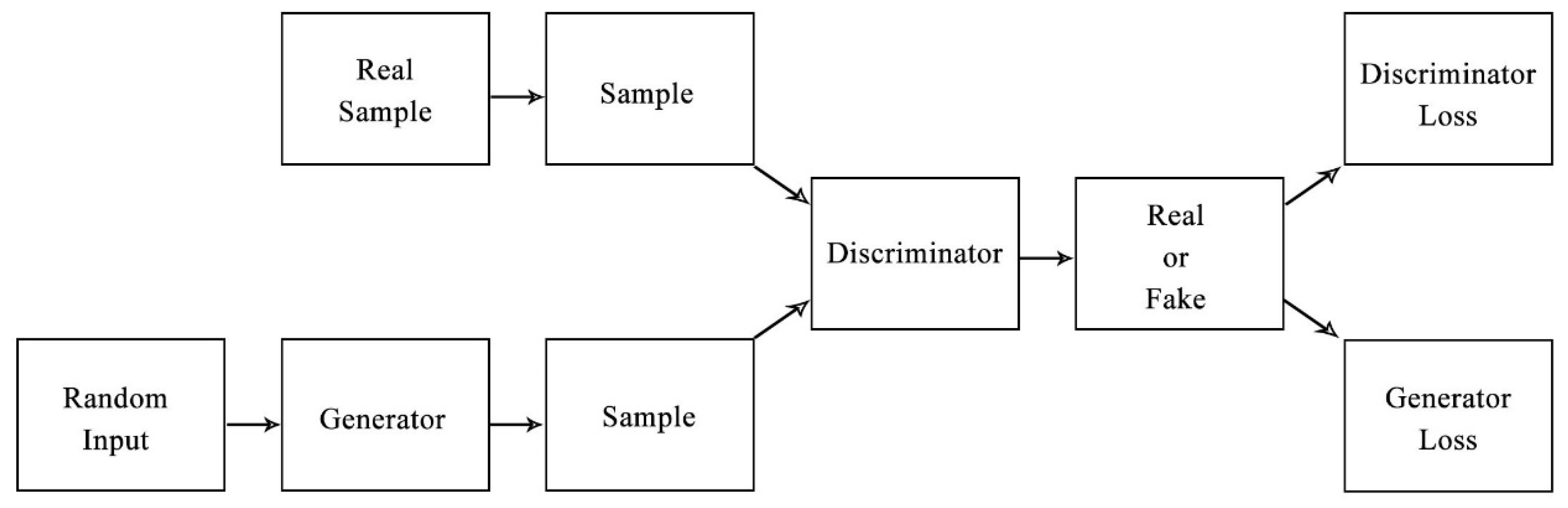
To address this issue, the main solution for the small sample problem is virtual sample generation (VSG). In recent studies, generative adversarial networks (GANs) which were proposed by Goodfellow et al. [
13], have been a popular method of VSG. This approach consists of two parts—a generator and a discriminator—as shown in
Figure 1. The generator is used to generate new data with a distribution similar to that of the original real data, so that the discriminator is unable to distinguish between the original and generated data, but attempts to distinguish between the two sets of data.
Typically, in statistics, a small sample can be referred to a data set with a sample size of less than 30. However, in real-world problems, the sample size should be determined according to the purpose of the survey. Because a small sample may be a tiny subset of the population, it is not possible to fully express the whole information of the population, which may lead to biased machine learning results and poor prediction performance. Furthermore, an incomplete data structure or imbalanced dataset is also a common problem in small-sample learning. It is believed that small samples still contain the underlying information. Thus, finding the clue hidden inside small samples, and inferring these samples’ corresponding population information, is meaningful for practical needs.
There are many acceptable methods for small-sample learning, of which virtual sample generation (VSG) is one of the main methods as used, for example, by Efron et al. [
14] with the bootstrap method. Niyogi et al. [
15], based on statistical inference mechanisms and using the principle of repeated sampling without replacement, investigated mathematical algorithms for converting limited 2D images into 3D images. Li et al. [
16] produced a functional virtual population through the trial-and-error method. According to Huang [
17], in order to solve the problem of incomplete information, the principle of information diffusion on display based on fuzzy theory has a more sufficient and long-term continuity and development. Huang and Moraga [
18] reasoned that the normal diffusion function infers that each sample point can spread on both sides of two derivative samples, increasing the possibility of improving the accuracy of the neurologic network for learning with a small sample; this approach is called a diffusion neural network. Like the approach of Li et al. [
19], based on the sample derivation formula of Huang and Moraga [
18], the mega-trend-diffusion (MTD) technique takes into account the overall information of all data, and is proposed to infer the value domain of the parent.
Generative adversarial networks (GANs) have become one of the commonly used models for producing virtual samples. The GAN structure is a sample generation method developed by Goodfellow et al. [
13] that uses the confrontation between the generative network (the Generator), and the discriminative network (the Discriminator) as the main core to ensure the generated virtual samples are closer to the training samples. Since the GAN method was published in 2014, it has been regarded as an important method for virtual sample generation of image data. It has also been extensively applied, and many extensions to and improvements of GANs have been made. According to the GAN Zoo website, there are more than 70 types of GAN. Mirza and Osindero [
20] improved the GAN and proposed conditional generative adversarial nets (cGAN), adding additional conditions to the generative and discriminative networks, so that the model can be generated and determined with additional conditions. The improvement also transformed the GAN structure from an unsupervised learning model to a supervised model. Arjovsky et al. [
21] proposed the Wasserstein GAN (WGAN) to improve the problem of gradient vanishing, by replacing the sigmoid function for the discriminative network, introducing the concept of Wasserstein Distance, and adding the 1-Lipschitz continuous function. As a result, the output of the discriminative network [0, 1] was changed to the degree of similarity to the training sample.
The VSG method provides a good solution for learning with small datasets; however, it cannot verify the quality of the virtual sample it generates. If the generated virtual sample is biased, it leads to biased results of subsequent modelling. Although the GAN and its extension improvement methods enhance the similarity between the generated virtual sample and the real sample, the cost in terms of the time required to train the sample is very large, and the GAN mostly uses vast graphic data sets as its input rather than small sets of numeric data. In addition, the GAN (e.g., its discriminative network) is based on the convolutional neural network (CNN), which is a deep neural network (DNN) and does not apply to data learning scenarios with a sparse sample [
22]. The development of a process suitable for small-sample learning under the framework of a GAN, to effectively improve the sample quality generated by the VSG method and thus improve the learning efficiency of small samples, is a topic worth exploring.
This study proposed a GAN architecture that can generate effective virtual samples with only a small dataset. Based on the original architecture of GANs, the graphical generation part of the generative network was modified to numerical generation, the MTD virtual sample generation method was modified, and the tanh function was adopted as the activation function of the output layer in the generative network (of the GAN). It aims to facilitate the match between the two so that the random numbers generated by the GAN through Latent Space could be limited by the MTD method and finally restored to a value close to that of the original.
In this study, we proposed a new method based on the Wasserstein GAN (WGAN) architecture and modified mega-trend-diffusion (MTD) as a limitation of the GAN generative network to reverse the back-propagation network (BPN) to actually generate and identify the networks of the GAN. Thus, this study used this improved GAN architecture, called WGAN_MTD, so that small-sample data can also be used to generate virtual samples that are similar to real samples through the GAN. We verified the model with two public data sets from the UC Irvine Machine Learning Repository and compared the performance, in terms of accuracy, standard deviation, and p-value, with other methods of supporting classification models, such as support vector machines (SVM), decision tree (DT), and Naïve Bayes. The results showed a better classification performance than those models without generating virtual samples.
The following section is dedicated to a review of the related research. Our approach to improve the generating network ability of GANs in the context of the numerical small-sample classifier, based on MTD, is presented in
Section 3. The proposed approach was validated based on experiments with two public datasets, as presented in
Section 4. Finally,
Section 5 concludes the paper.
4. Experimental Study
This section details the experiments and the results of the proposed approach with the experiment data. We verified the model with two public data sets from the UC Irvine Machine Learning Repository and compared the performance in terms of accuracy, standard deviation, and p-value, with other supporting classification models such as SVM, DT, and Naïve Bayes.
4.1. Evaluation Criterion
This study evaluated the model performance based on accuracy, standard deviation, and the p-value. Accuracy can measure how the virtual samples perform in different prediction models compared to those only predicted by small-sample datasets. Standard deviation and the p-value can measure the stability of the experiment. The smaller the standard deviation, the greater the stability between each experiment with the same method. The smaller the p-value, the more consistent the accuracy between each experiment without virtual samples and with virtual samples added. If the p-value is above 0.05, there may be no difference between the accuracies of those experiments with or without virtual samples added.
4.2. Experiment Environment and Datasets
The experiment was conducted under the Python integrated development environment (IDE), Anaconda, which includes the packages Pandas, NumPy, Scikit-learn, and TensorFlow. This research used the SVM, DT, and Naïve Bayes classifiers to verify the results. Two types of kernel function were used by SVM: the polynomial function and the radial basis function (RBF).
To verify the accuracy of the proposed WGAN_MTD method, three experimental datasets from the UC Irvine Machine Learning Repository (
https://archive.ics.uci.edu/, accessed on 15 June 2021) were employed.
Table 1 shows the three datasets used in this study, namely, Wine, Seeds, and Cervical Cancer.
4.3. Experiment Results
Table 2 shows the results of generating virtual samples by WGAN_MTD with training dataset having a size of 10 (denoted by 10 TD) from the Wine dataset. The table includes the accuracy of the experiment conducted 30 times, the average accuracy (denoted by average), standard deviation (denoted by stddev), and the
p-value between only small dataset samples (denoted by SDS) and WGAN_MTD (proposed method denoted by PM), in different prediction models (denoted by SVM_poly, SVM_rbf, Decision_Tree, and Naïve Bayes).
p-value < 0.05 is denoted by *,
p-value < 0.01 is denoted by **,
p-value < 0.001 is denoted by *** and
p-value > 0.05 means the state is not stable, and is denoted by ns.
The experiment shows that our method works better in every prediction model as indicated by the better average accuracy and significant p-value (under 0.01) for 10 TD in the Wine dataset with 100 virtual samples.
Table 3 shows the results of generating virtual samples by WGAN_MTD with a different number of training datasets (10, 15, and 20) in the Wine dataset, omitting the detailed results of the 30 replications of the experiment. With 15 training datasets, as shown in
Table 3, the experiment shows that our method works better in the SVM polynomial and decision tree, as indicated by better average accuracy and significant
p-value (under 0.05) when using the Wine training dataset with 100 virtual samples.
As reported in
Table 3, the experiment also shows that our method works better in both the SVM and decision tree, as indicated by the better average accuracy and significant
p-value (under 0.05) when using 20 training datasets in the Wine dataset with 100 virtual samples.
Table 4 shows the results of generating virtual samples by WGAN_MTD with different numbers of training datasets (10, 15, and 20) in the Seeds datasets when omitting the detailed results of 30 replications of the experiment. When the 10 training datasets are used in the Seeds dataset with 100 virtual samples, the experiment shows that our method works better in the SVM with the polynomial kernel and Naïve Bayes, as indicated by the better average accuracy and significant
p-value (under 0.05). The experiment results show that our method only works better in the SVM with the polynomial kernel, as indicated by the better average accuracy and significant
p-value (under 0.01), when the training dataset size increases to 15 and 20 in the Seeds dataset with 100 virtual samples. In
Table 5, the experiment results show a similar pattern to that of
Table 4; that is, our method only works better in the SVM with the polynomial kernel, as indicated by the better average accuracy and significant
p-value (under 0.01), when the training dataset size increases to 15 and 20 in the Cervical Cancer dataset with 100 virtual samples.
The results shown in
Table 3,
Table 4,
Table 5 and
Table 6 indicate that the process of adopting WGAN_MTD can improve the learning accuracy when facing small datasets. We also compared the performance of WGAN_MTD with that of MTD and WGAN. As mentioned, MTD can output the generated virtual samples while WGAN produces a dataset similar to that of the input. By applying them to small datasets, as the input, MTD generates virtual data and produces the augmented dataset, including generated data and original data. In addition, WGAN produced a dataset that is more analogous to the original small dataset. We conducted the comparison based on the learning accuracy of the SVM whose inputs came from MTD, WGAN, and WGAN_MTD. For MTD and WGAN_MTD, we considered the case of 20 original data and 100 virtual data.
Table 6 shows that WGAN_MTD can perform well in both of three datasets because it not only generates virtual samples, in the same manner are MTD, but also ensures the generated data are more similar to the original data.
5. Conclusions
In small-sample learning, WGAN_MTD can produce virtual samples generated by the generative adversarial network through MTD, and generate effective virtual samples with numerical small datasets. The screening mechanism included in the process monitors the samples generated by MTD range estimation. As shown in
Table 2,
Table 3 and
Table 4, the virtual sample generated with the small dataset can improve the performance by increasing the learning accuracy. Under the prediction of the decision tree, although the prediction accuracy is likely to be lower than that of a small sample, adding more virtual samples provides decision-makers with more diversified decision-making directions and has certain value.
According to the experimental results, it was found that, in most cases, the larger the number of small samples, the more likely it is that the p-value will be greater than the verification level of 0.05. The reason for this is that the greater the number of real samples, the better the reflection of the distribution of the real data. In addition, the accuracy in the case of small samples also increases. Therefore, when the number of small samples increases, the added virtual samples are easily regarded as samples containing noise, which makes the prediction results unstable, and results in p-values greater than the verification level of 0.05.
In the process of the experiment, we also found that if the number of iterations of WGAN_MTD is increased, it is easy to cause overfitting of the discrimination network, and the virtual samples generated by the generation network do not pass the discrimination network. Moreover, GAN training is relatively dependent on the initial randomly generated virtual samples. Thus, if the virtual samples generated at the beginning are very similar to the real samples, the time for GAN to complete the training is shortened; if the virtual samples generated at the beginning are judged to be significantly different from the real samples, the training time of GAN is lengthened. The training in this situation is relatively unstable. Thus, in our experiment, it was difficult to decide on the number of iterations required for training. Therefore, follow-up research can develop a means to improve the stability of the generation of small samples against the network, so as to control the number of training iterations and the speed, in addition to helping virtual samples pass the discrimination network.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}