
Machine Translation in Low-Resource Languages by an Adversarial Neural Network





Abstract
:1. Introduction
- A novel translation model, LAC, is designed. Compared to Seq2Seq, this model takes advantage of the adversary technique, reduces the required size of the corpus, and significantly enhances the experimental results on LRLs;
- The LAC model is designed to be end-to-end differentiable and transferable. A pretrained discriminator demonstrated a stronger ability for feature extraction and achieved a higher accuracy in terms of Bilingual Evaluation Understudy (BLEU) scores compared to a non-transferred LAC system;
- The effectiveness of the generator and discriminator in the LAC model is investigated. From the exploratory experiments, the results are analyzed in an interpretable manner.
2. Related Work
2.1. Adversarial Neural Networks
2.2. Low Resource Languages Machine Translation
3. Adversarial Model
3.1. GAN
3.1.1. Basic GAN
3.1.2. WGAN
3.1.3. WGAN-GP
3.2. LAC
4. LAC Configuration
4.1. Generator
4.2. Discriminator
5. Experiments
5.1. Dataset
- (1)
- The dataset only comprises limited bilingual sentence pairs.
- (2)
- The languages do not have a good pretrained model, or the relative studies are insufficient.
5.2. Parameters
5.3. Metrics
5.4. Baseline Models
6. Results
6.1. Main Results
6.1.1. Comparison of Baseline Models
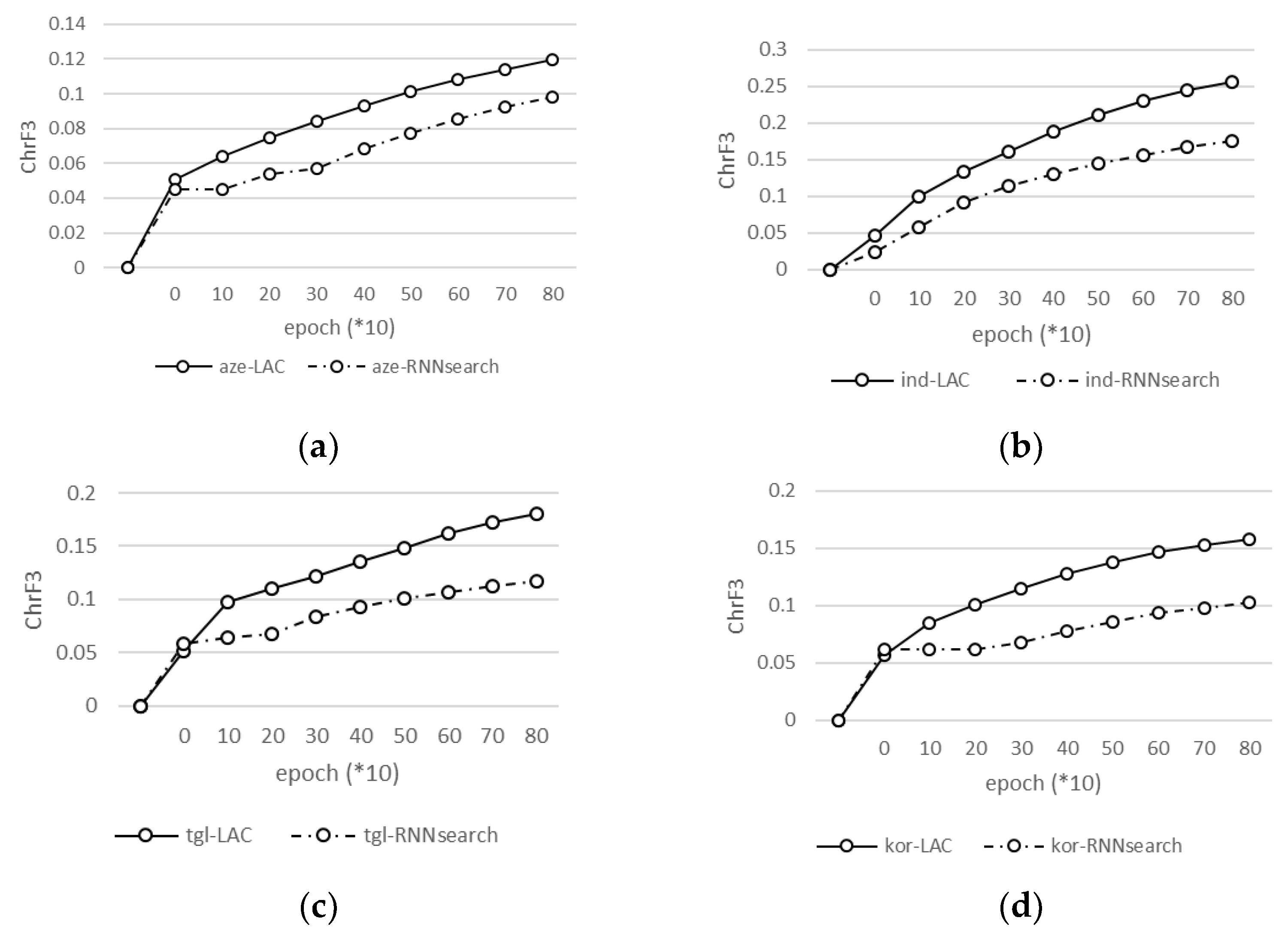
6.1.2. Comparison of Languages (aze/ind/tgl/kor/nob-eng)
6.2. Transfer Learning
6.3. Case Study
6.4. Ablation Study
6.5. Wasserstein Distance
6.6. Steps of Message Passing
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems Conference, Long Beach, CA, USA, 4 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2 June 2019. [Google Scholar]
- Ruder, S.; Vulić, I.; Søgaard, A. A survey of cross-lingual word embedding models. J. Artif. Intell. Res. 2019, 65, 569–631. [Google Scholar] [CrossRef] [Green Version]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1 November 2016. [Google Scholar] [CrossRef]
- Maimaiti, M.; Liu, Y.; Luan, H.; Sun, M. Multi-Round Transfer Learning for Low-Resource NMT Using Multiple High-Resource Languages. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2019, 18, 4. [Google Scholar] [CrossRef] [Green Version]
- Yong, C. Joint Training for Neural Machine Translation. Ph.D. Thesis, IIIS Department, Tsinghua University, Beijing, China, 2014. [Google Scholar]
- Ren, S.; Chen, W.; Liu, S.; Li, M.; Zhou, M.; Ma, S. Triangular architecture for rare language translation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15 July 2018. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Wu, L.; Xia, Y.; Tian, F.; Zhao, L.; Qin, T.; Lai, J.; Liu, T.Y. Adversarial neural machine translation. In Proceedings of the Asian Conference on Machine Learning (ACML 2018), Beijing, China, 14 November 2018; pp. 534–549. [Google Scholar]
- Cao, P.; Chen, Y.; Liu, K.; Zhao, J.; Liu, S. Adversarial transfer learning for Chinese named entity recognition with self-attention mechanism. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October 2018; pp. 182–192. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4 February 2017. [Google Scholar] [CrossRef]
- Lee, H.; Yu, T. ICASSP 2018 tutorial: Generative adversarial network; Its applications to signal processing; Natural language processing. In Proceedings of the ICASSP 2018, Calgary, AB, Canada, 15 April 2018. [Google Scholar] [CrossRef]
- Zhang, Y.; Gan, Z.; Fan, K.; Chen, Z.; Henao, R.; Shen, D.; Carin, L. Adversarial feature matching for text generation. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6 August 2017; Volume 70, pp. 4006–4015. [Google Scholar]
- Nie, W.; Narodytska, N.; Patel, A. Relgan: Relational generative adversarial networks for text generation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April 2018. [Google Scholar]
- Press, O.; Bar, A.; Bogin, B.; Berant, J.; Wolf, L. Language generation with recurrent generative adversarial networks without pre-training. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6 August 2017. [Google Scholar]
- Ash, J.T.; Adams, R.P. On the difficulty of warm-starting neural network training. arXiv 2019, arXiv:1910.08475. [Google Scholar]
- Yi, J.; Tao, J.; Wen, Z.; Bai, Y. Language-Adversarial Transfer Learning for Low-Resource Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Proc. 2019, 27, 621–630. [Google Scholar] [CrossRef]
- Dai, G.; Xie, J.; Fang, Y. Metric-based generative adversarial network. In Proceedings of the 25th ACM International Conference on Multimedia (MM ‘17), Mountain View, CA, USA, 23–27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 672–680. [Google Scholar] [CrossRef]
- Dong, X.; Zhu, Y.; Zhang, Y.; Fu, Z.; Xu, D.; Yang, S.; de Melo, G. Leveraging adversarial training in self-learning for cross-lingual text classification. In Proceedings of the 43rd International ACM SIGIR Conference on Research, Development in Information Retrieval, Virtual Conference, China, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1541–1544. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Luo, S.; Sarwar, M.U.; Shabbir, S.; Li, J.; Khushi, M. An investigation of credit card default prediction in the imbalanced datasets. IEEE Access 2020, 8, 201173–201198. [Google Scholar] [CrossRef]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A Comparative Performance Analysis of Data Resampling Methods on Imbalance Medical Data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Mahboob, H.; Sarwar, M.U.; Iqbal, F.; Nasir, A.; Hameed, I.A.; Luo, S. A Machine Learning Approach for Identification of Malignant Mesothelioma Etiological Factors in an Imbalanced Dataset. Comput. J. 2021, bxab015. [Google Scholar] [CrossRef]
- Latif, M.Z.; Shaukat, K.; Luo, S.; Hameed, I.A.; Iqbal, F.; Alam, T.M. Risk factors identification of malignant mesothelioma: A data mining based approach. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–6. [Google Scholar]
- Yang, X.; Khushi, M.; Shaukat, K. Biomarker CA125 Feature engineering and class imbalance learning improves ovarian cancer prediction. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 16–18 December 2020; pp. 1–6. [Google Scholar]
- Li, Y.; Jiang, J.; Yangji, J.; Ma, N. Finding better subwords for Tibetan neural machine translation. In Proceedings of the Transactions on Asian and Low-Resource Language Information Processing, Gold Coast, Australia, 16–18 December 2021; Volume 20, pp. 1–11. [Google Scholar]
- Tran, P.; Dinh, D.; Nguyen, L.H. Word re-segmentation in Chinese-Vietnamese machine translation. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2016, 16, 1–22. [Google Scholar] [CrossRef]
- Choi, Y.-S.; Park, Y.-H.; Yun, S.; Kim, S.-H.; Lee, K.-J. Factors Behind the Effectiveness of an Unsupervised Neural Machine Translation System between Korean and Japanese. Appl. Sci. 2021, 11, 7662. [Google Scholar] [CrossRef]
- Nguyen, T.Q.; Chiang, D. Zero-shot reading comprehension by cross-lingual transfer learning with multi-lingual language representation model. In Proceedings of the EMNLP, Hong Kong, China, 3 November 2019. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of Wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems Conference, Long Beach, CA, USA, 4 December 2017; pp. 5767–5777. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 5 December 2013. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by Exponential Linear Units (ELUs). In Proceedings of the International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2 May 2016. [Google Scholar]
- Kim, J.; Won, M.; Serra, X.; Liem, C.C. Transfer learning of artist group factors to musical genre classification. In Proceedings of the Web Conference 2018 (WWW ‘18), Lyon, France, 23 April 2018; pp. 1929–1934. [Google Scholar] [CrossRef] [Green Version]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5 December 2016; pp. 550–558. [Google Scholar]
- Balduzzi, D.; Frean, M.; Leary, L.; Lewis, J.P.; Ma, K.W.D.; McWilliams, B. The shattered gradients problem: If resnets are the answer, then what is the question? In Proceedings of the 34th International Conference on Machine Learning (ICML’17), Sydney, Australia, 6 August 2017; Volume 70, pp. 342–350. [Google Scholar]
- Fu, Z.; Xian, Y.; Geng, S.; Ge, Y.; Wang, Y.; Dong, X.; Wang, G.; de Melo, G. ABSent: Cross-lingual sentence representation mapping with bidirectional GANs. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA, 7 February 2017. [Google Scholar] [CrossRef]
- Tran, C.; Tang, Y.; Li, X.; Gu, J. Cross-lingual retrieval for iterative self-supervised training. In Proceedings of the Advances in Neural Information Processing Systems Conference (NIPS 2020), Virtual Conference, 6 December 2020. [Google Scholar]
- Mathur, N.; Baldwin, T.; Cohn, T. Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), Virtual Conference, 5 July 2020. [Google Scholar] [CrossRef]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation (EMNLP 2015 Workshop), Lisbon, Portugal, 17 September 2015; pp. 392–395. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Xu, M. A Survey on Machine Learning Techniques for Cyber Security in the Last Decade. IEEE Access 2020, 8, 222310–222354. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Jean, S.; Cho, K.; Memisevic, R.; Bengio, Y. On using very large target vocabulary for neural machine translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015), Beijing, China, 26 July 2015. [Google Scholar] [CrossRef]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.Y. Incorporating BERT into neural machine translation. In Proceedings of the International Conference on Learning Representations (ICLR 2020), Virtual Conference, 30 April 2020. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A lite BERT for self-supervised learning of language representations. In Proceedings of the International Conference on Learning Representations (ICLR 2020), Virtual Conference, 30 April 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language Codes | Full Names | Avg Sentence Length | Train | Val | Test |
|---|---|---|---|---|---|
| tur-eng | Turkish-English | 8.05 | 7.0 k | 2.0 k | 2.0 k |
| aze-eng | Azerbaijani-English | 7.01 | 2.2 k | 0.4 k | 0.4 k |
| ind-eng | Indonesian-English | 8.36 | 2.2 k | 0.4 k | 0.4 k |
| tgl-eng | Tagalog-English | 8.34 | 2.2 k | 0.4 k | 0.4 k |
| dan-eng | Danish-English | 8.94 | 7.0 k | 2.0 k | 2.0 k |
| nob-eng | Norwegian-English | 9.14 | 2.2 k | 0.4 k | 0.4 k |
| kor-eng | Korean-English | 7.27 | 2.2 k | 0.4 k | 0.4 k |
| Language Codes | Before | After | ||
|---|---|---|---|---|
| Source | Target | Source | Target | |
| tur-eng | Tom şirketin %30’unun sahibi. | Tom owns 30% of the company. | <start> tom şirketin 30 unun sahibi . <end> | <start> tom owns 30 of the company . <end> |
| aze-eng | Ağzınızı açın! | Open your mouth! | <start> ağzınızı açın ! <end> | <start> open your mouth ! <end> |
| ind-eng | Aku membayar $200 untuk pajak. | I paid $200 in taxes. | <start> aku membayar 200 untuk pajak . <end> | <start> i paid 200 in taxes . <end> |
| tgl-eng | “Terima kasih.” “Sama-sama.” | “Thank you.” “You’re welcome.” | <start> terima kasih. sama sama . <end> | <start> thank you. You re welcome . <end> |
| dan-eng | Vores lærer sagde at vand koger ved 100 °C. | Our teacher said that water boils at 100 °C. | <start> vores lærer sagde at vand koger ved 100 °C . <end> | <start> our teacher said that water boils at 100 °C . <end> |
| nob-eng | Du hater virkelig ekskona di, gjør du ikke? | You really do hate your ex-wife, don’t you? | <start> du hater virkelig ekskona di, gjør du ikke ? <end> | <start> you really do hate your ex wife, don t you ? <end> |
| kor-eng | 게임은2:30에 시작해. | The game starts 2:30. | <start> 게임은2 30 에 시작해 . <end> | <start> the game starts 2 30 . <end> |
| First Proposed | Details | BLEU |
|---|---|---|
| RNNsearch. 2015 [1] | GRU_encoder + Att. + GRU_decoder | 33.6 |
| RNNsearch + UNK Replace. 2015 [45] | RNNsearch + UNK Replace | 32.8 |
| BERT. 2019. [3] 2020. [46] | BERT_encoder + RNNsearch | 34.7 |
| ALBERT. 2020 [47] | ALBERT_encoder + RNNsearch | 35.8 |
| LAC-RNNsearch | Adversary (RNNsearch, D) | 37.9 |
| Language Codes | RNNsearch | LAC-RNNsearch |
|---|---|---|
| aze-eng | 20.4 | 20.7 |
| ind-eng | 17.7 | 19.3 |
| tgl-eng | 22.0 | 22.8 |
| kor-eng | 17.6 | 17.7 |
| nob-eng | 14.4 | 15.3 |
| aze–eng | BLEU | ChrF3 |
|---|---|---|
| Non-transfer | 20.7 | 19.4 |
| Transfer G | 18.5 | 16.6 |
| Transfer D | 21.2 | 23.9 |
| Transfer G and D | 18.8 | 17.1 |
| nob–eng | BLEU | ChrF3 |
|---|---|---|
| None-Transfer | 15.3 | 26.9 |
| Transfer G | 15.6 | 24.7 |
| Transfer D | 15.8 | 29.2 |
| Transfer G and D | 15.5 | 25.5 |
| Epoch | 100 | 200 | 300 | 700 |
| Source | Sizin mənə nə edəcəyimi deməyə haqqınız yoxdur. | |||
| Ground Truth | You have no right to tell me what to do. | |||
| RNNsearch | . | i . | i think i think i think i think | i think that what do you know tom |
| LAC | i m the know i m the know | i m a good to go to go | i don t know you re not your | you have three children are you want to |
| LAC #G | door tom | door tom | is have you ? | is have you ? |
| LAC #D #G | door tom | door tom | is have you the . | is have you ? |
| LAC #D | i m a m a m a m | you re you re you re you re | you have to be your problem to do | you have no right to tell me what |
| Source | Sən Avstriyanın harasında böyümüsən? | |||
| Ground Truth | Where in Austria did you grow up? | |||
| RNNsearch | . | i . | tom is the dog . | tom is monday . |
| LAC | i m a know the know the know | i m not a good to go to | you can t want you have a good | where in austria ? |
| LAC #G | do you house the tom | do you . | do you re ? | do my to tom |
| LAC #D #G | do you like tom | do you very the tom | do you re ? | do my to tom |
| LAC #D | i m a m a m a m | you ? | where are you in japan ? | where in austria did you grow up ? |
| Source | Mən maşında idim. | |||
| Ground Truth | I was in the car. | |||
| RNNsearch | . | i . | i have a good . | i ate the library . |
| LAC | i m a m a m a m | i m a good . | tom has a good . | i think of the cat . |
| LAC #G | is briefly . | i happy is . | i m s t . | i m s t . |
| LAC #D #G | is briefly . | i happy is . | i m s t . | i m s t . |
| LAC #D | i m a was . | i m a i m a i m | i was in the driver . | i was in the car . |
| Source | Əminəm ki, Tom sənə nifrət etmir. | |||
| Ground Truth | I’m sure Tom doesn’t hate you. | |||
| RNNsearch | . | i . | i m not a good . | i m sure tom will you like it |
| LAC | i m the know i m the know | i m a good to go to go | i don t know you re not your | i m sure tom doesn t hate you |
| LAC #G | i will the he | i will the you very the he | i m s the you her you re | i m s the to be you her |
| LAC #D #G | i will the he | i will the the the the the the | i m s the you her the you | i m s the you the to be |
| LAC #D | i m a m a m a m | i m a tom s a tom is | i m here . | i m sure tom doesn t hate you |
| Epoch | 100 (10) | 200 (20) | 300 (30) | 700 (70) |
| Source | Jeg betraktet Tom som en venn. | |||
| Ground Truth | I regarded Tom as a friend. | |||
| RNNsearch | i . | i . | i ve been a lot of the truth | i ve been to be a friend . |
| LAC | i m a lot of a lot of | i m a lot of the tom is | i m sure tom is a friend in | i wonder tom will have a friend . |
| LAC #G | i if tom to tom | i was into . . | i was tom . | i m and tom a lot it tom |
| LAC #D #G | i that | i ve tom . . | i was t to to . | i m tom a friend . |
| LAC #D | i m to i m to i m | i m a lot of the tom s | i tom tom a friend . | i assumed tom was a friend . |
| Source | Er det noe du ikke forteller oss? | |||
| Ground Truth | Is there something you’re not telling us? | |||
| RNNsearch | i . | i . | i ve been to be a lot of | what is it s someone know that you |
| LAC | i m a lot of a lot of | are you have a lot of this is | is there is you re not his life | is there something you re not telling me |
| LAC #G | i do about you the . | are s you you the . | are s you t you the . | are s you t you that ? |
| LAC #D #G | i do people you the . | are s you the . | are s you the . | are s you that you you that you |
| LAC #D | tom is a lot . | are you have to do you are you | is there s something to do not to | is there something you re not telling me |
| Source | Jeg skulle ønske det var mer jeg kunne ha gjort. | |||
| Ground Truth | I wish there was more I could’ve done. | |||
| RNNsearch | i . | i . | i wish i wish i wish i wish | i wish i wish i wish i wish |
| LAC | i ve | i m not to be a lot of | i wish there s more than i was | i wish there was more than i was |
| LAC #G | do wish the . | i wish . . | i wish i do i could the . | i wish there do i could the . |
| LAC #D #G | i wish the . | i wish . . | i wish i had the . | i wish there will more do more more |
| LAC #D | i m i m i m i m | i m a lot of i ve been | i wish it was more than i was | i wish there were more than i could |
| Source | Tom skal gjøre det i morgen. | |||
| Ground Truth | Tom will be doing that tomorrow. | |||
| RNNsearch | i . | i . | i m a lot of the lot of | you re supposed to be happy to be |
| LAC | tom s a lot of a lot of | tom is a lot . | tom will be happy to be the truth | tom will do that . |
| LAC #G | he t with really | tom your with i that with i that | tom a lot know find | tom will really tomorrow . |
| LAC #D #G | he t with he t | tom . . | tom a lot know a lot it , | tom will it tomorrow |
| LAC #D | tom is the lot . | tom s a lot of the room . | tom is do that . | tom will do that tomorrow . |
| Model | BLEU |
|---|---|
| LAC | 37.9 |
| G_RNN | 35.5 |
| G_No Attention | 35.0 |
| D_ReLu Nonlinearity | 36.5 |
| D_ res block × 1 | 35.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, M.; Wang, H.; Pasquine, M.; A. Hameed, I. Machine Translation in Low-Resource Languages by an Adversarial Neural Network. Appl. Sci. 2021, 11, 10860. https://doi.org/10.3390/app112210860
Sun M, Wang H, Pasquine M, A. Hameed I. Machine Translation in Low-Resource Languages by an Adversarial Neural Network. Applied Sciences. 2021; 11(22):10860. https://doi.org/10.3390/app112210860
Chicago/Turabian StyleSun, Mengtao, Hao Wang, Mark Pasquine, and Ibrahim A. Hameed. 2021. "Machine Translation in Low-Resource Languages by an Adversarial Neural Network" Applied Sciences 11, no. 22: 10860. https://doi.org/10.3390/app112210860
APA StyleSun, M., Wang, H., Pasquine, M., & A. Hameed, I. (2021). Machine Translation in Low-Resource Languages by an Adversarial Neural Network. Applied Sciences, 11(22), 10860. https://doi.org/10.3390/app112210860