
Systematic Literature Review on Machine Learning and Student Performance Prediction: Critical Gaps and Possible Remedies



Abstract
:1. Introduction
2. Overview of Machine Learning Principles
2.1. Overview of Machine Learning Models
2.1.1. Decision Trees
2.1.2. Random Forest
2.1.3. Gradient Boosting
2.1.4. Extreme Gradient Boosting
2.1.5. Support Vector Machine and Support Vector Regression
2.1.6. Artificial Neural Networks and Deep Neural Networks
2.1.7. Logistic Regression
2.1.8. Linear Regression
2.1.9. Long Short-Term Memory Neural Network
2.2. Evaluation and Validation Strategies
2.2.1. Evaluation Metrics for Classification Tasks
2.2.2. Evaluation Metrics for Regression Tasks
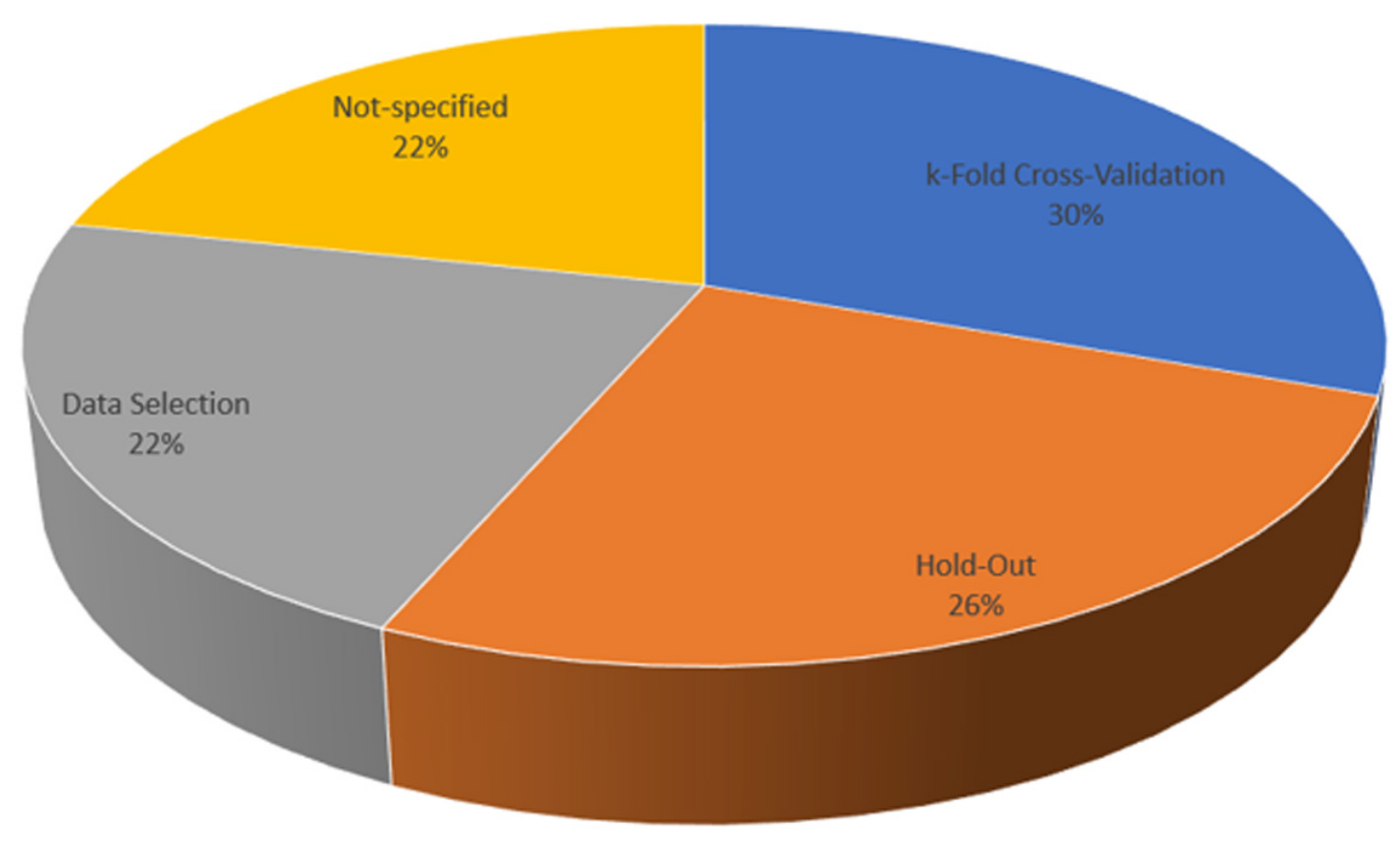
2.2.3. Validation Methods
3. Results of Systematic Literature Review
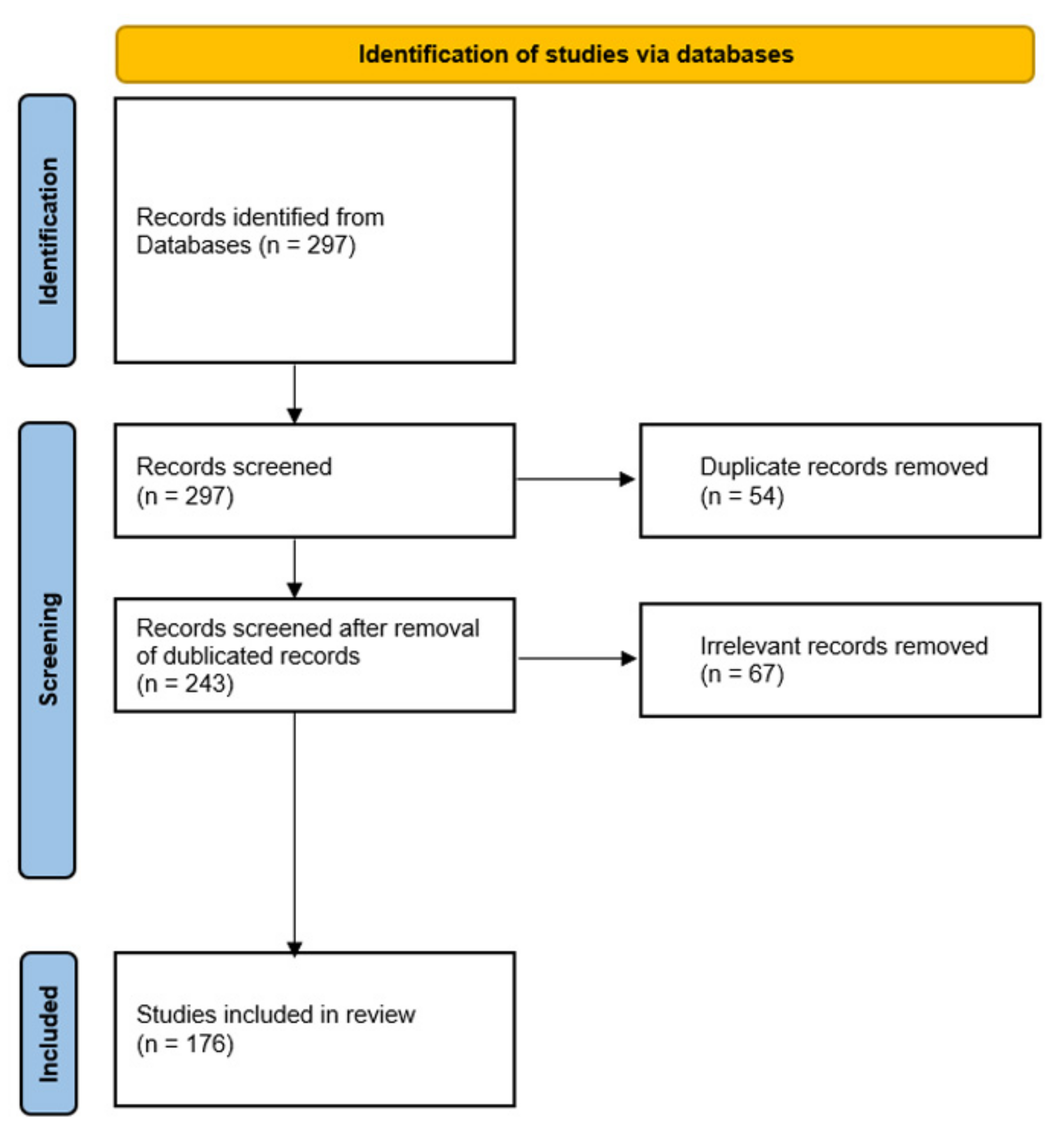
3.1. Methodology
3.1.1. Search Strategy
3.1.2. Inclusion and Exclusion Criteria
- Research papers (published in scientific peer-reviewed journals);
- Studies that implemented or proposed machine learning and/or deep learning models to predict student performance for all levels of education;
- The research was reported in English.
- Studies that focused on student performance but did not implement machine learning models;
- Review studies, abstracts, commentaries, book chapters, or editorials.
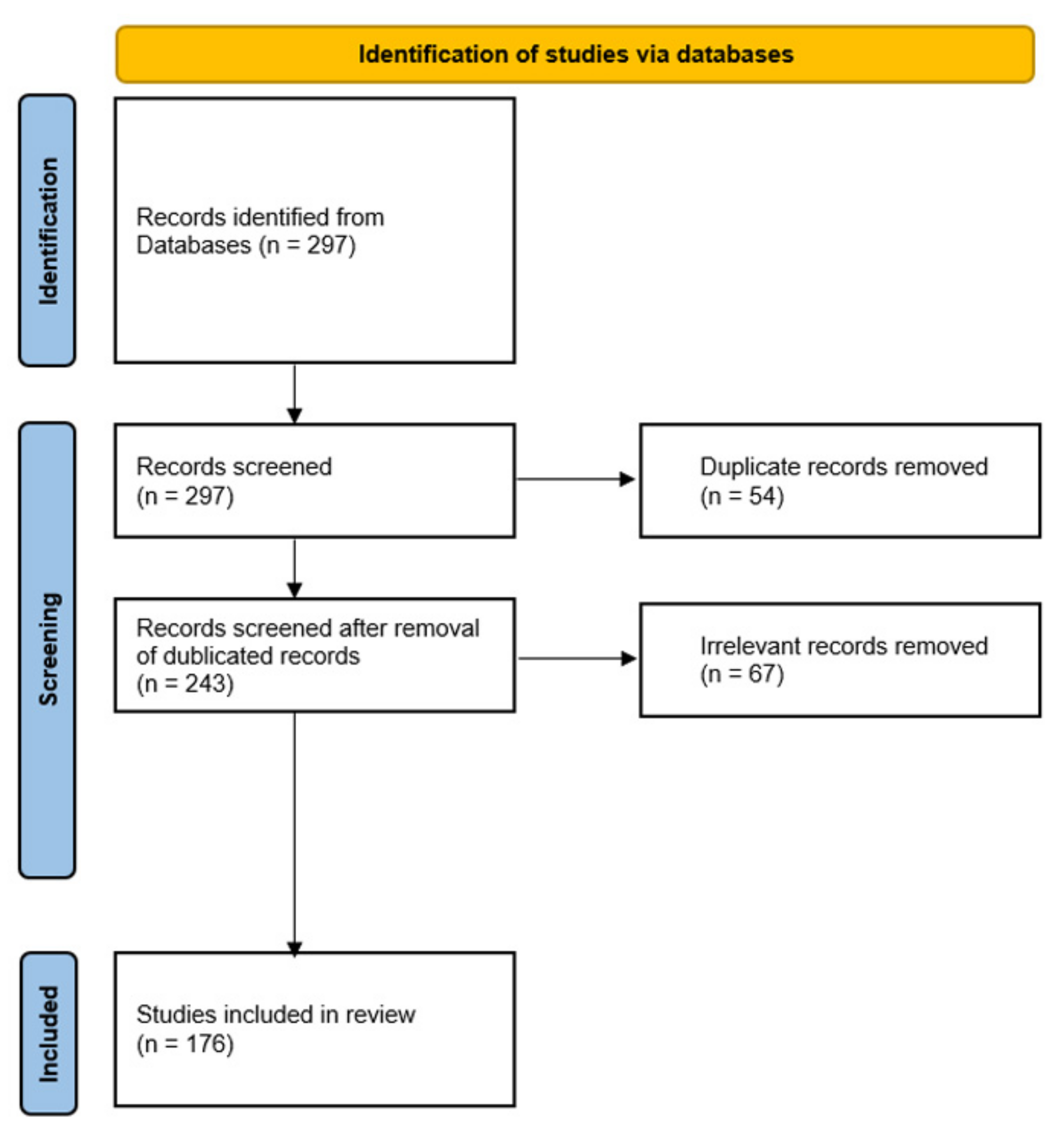
3.1.3. Selection Procedure and Data Extraction
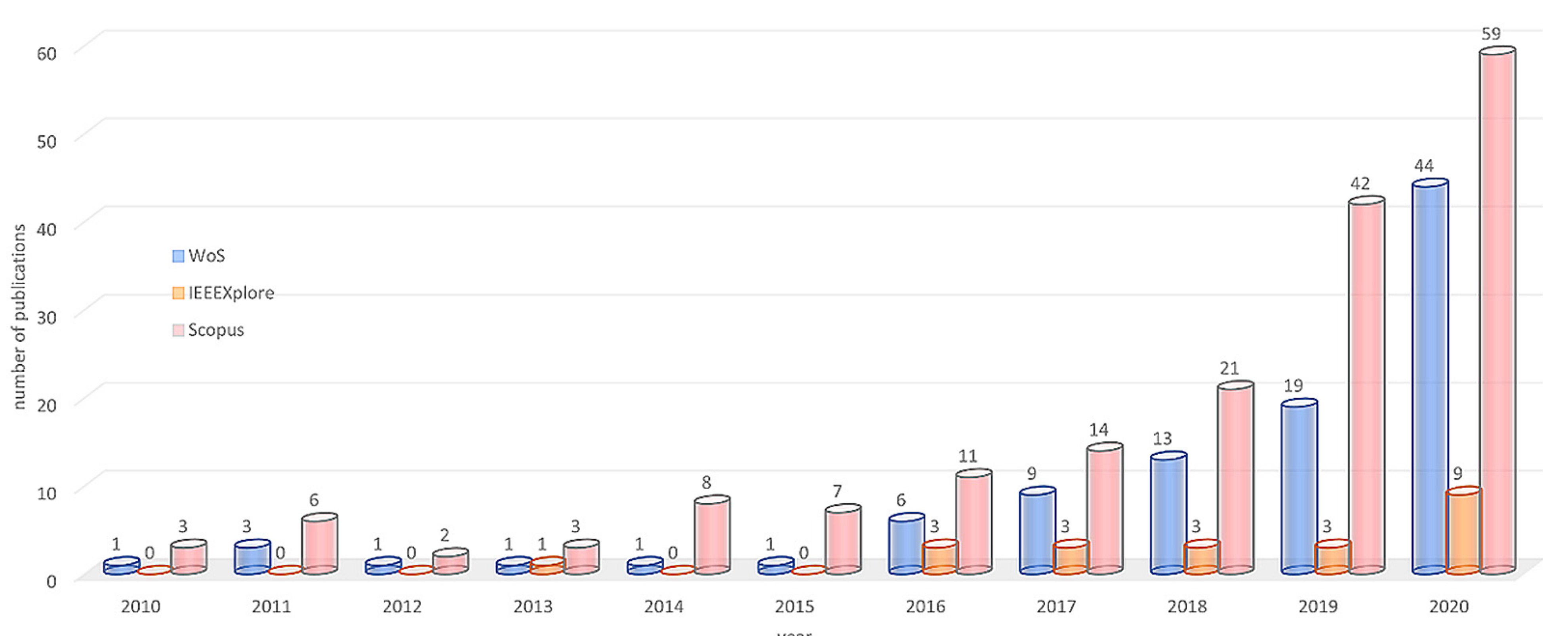
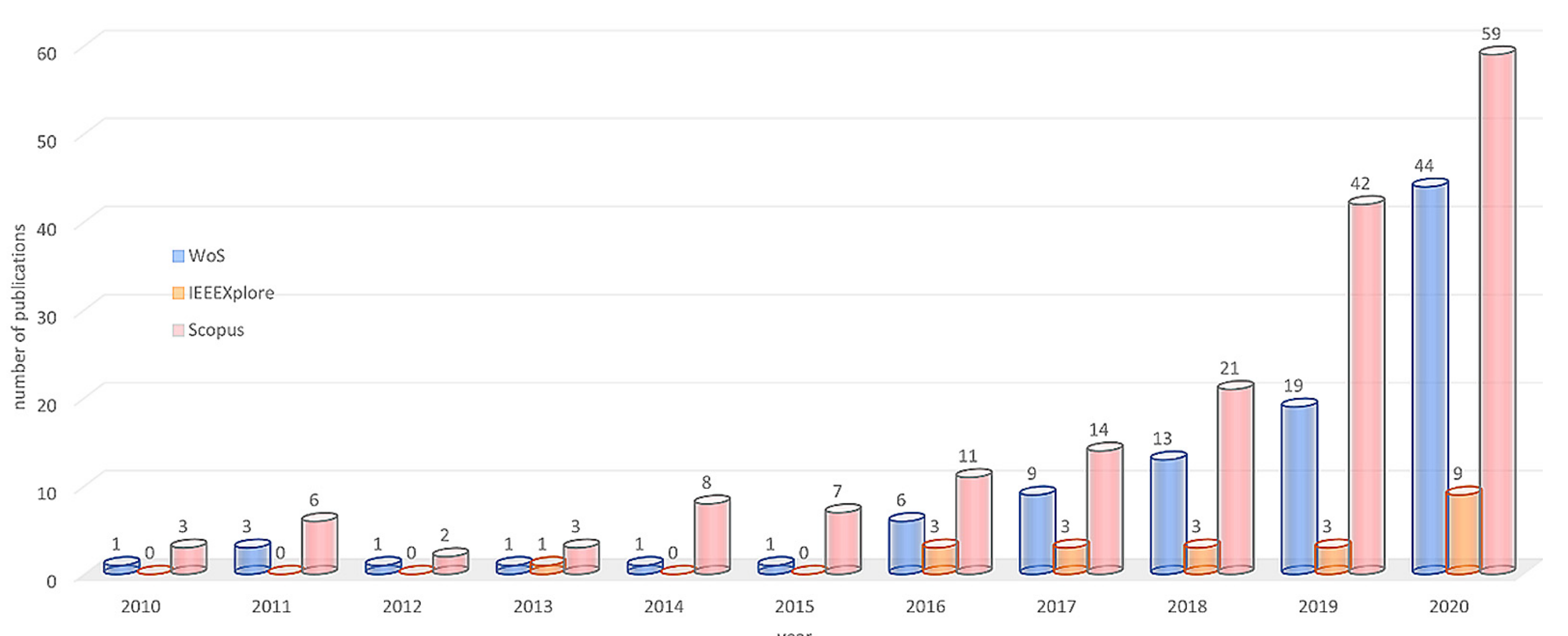
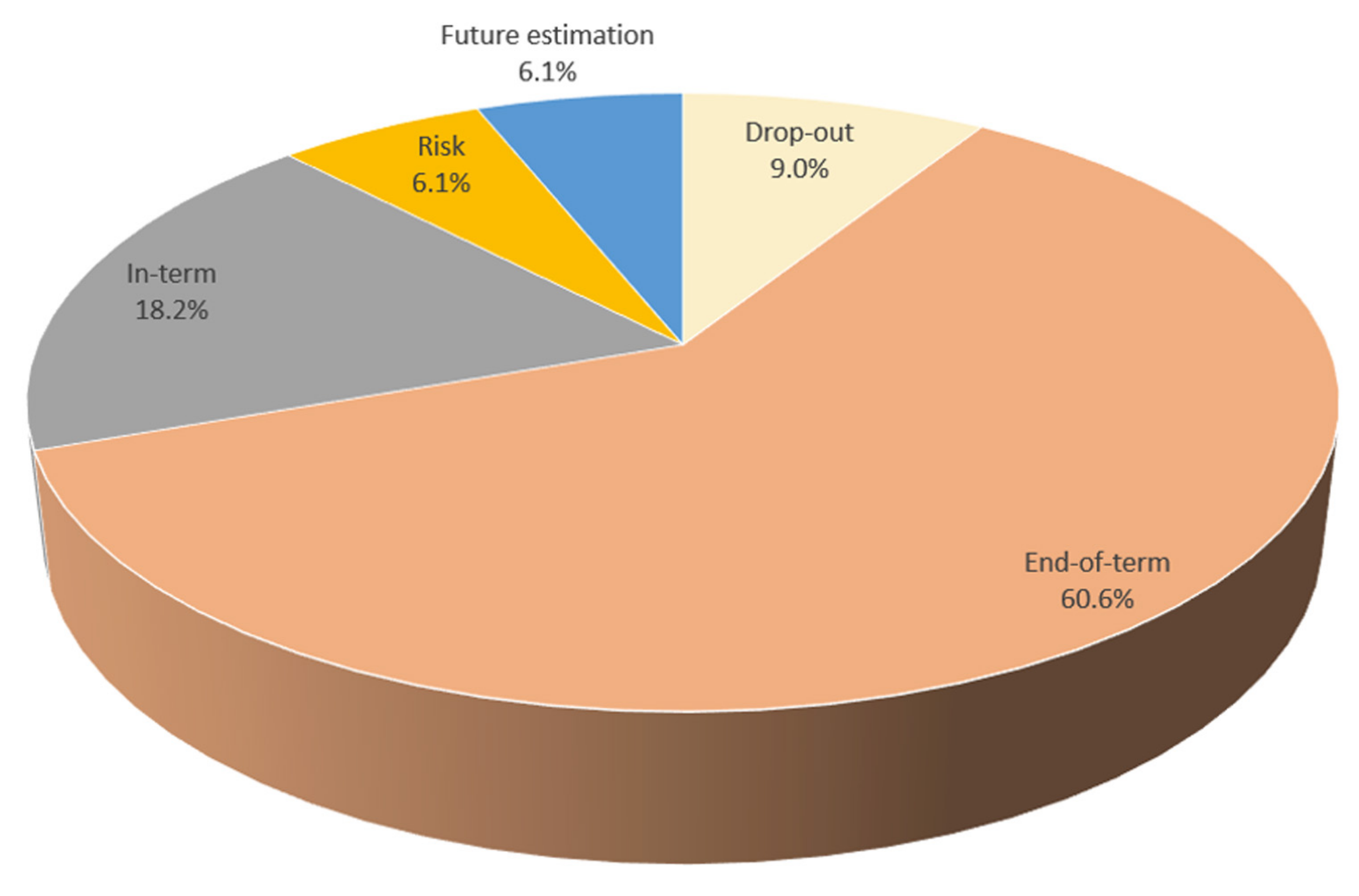
3.2. Publication Numbers and Aims
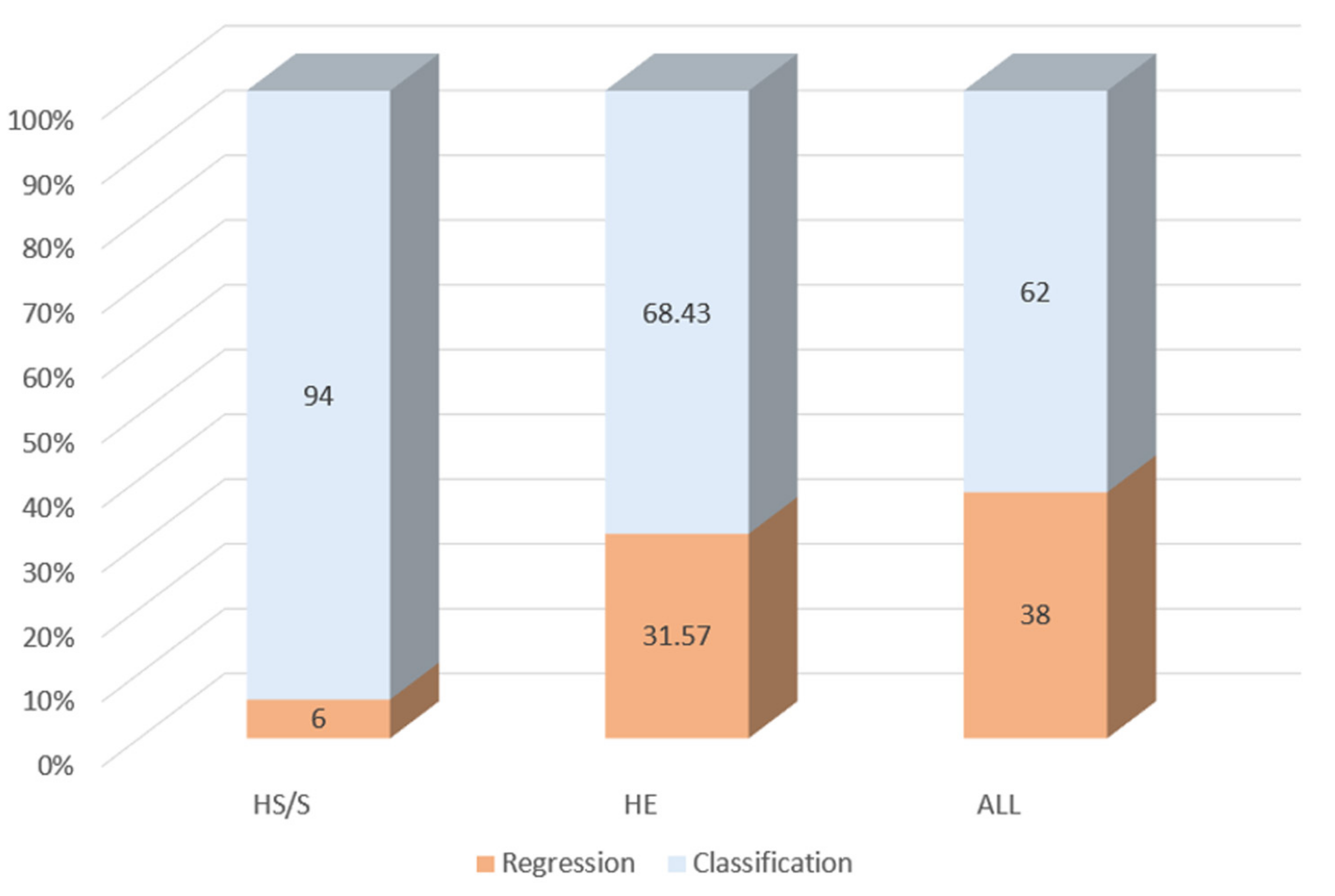
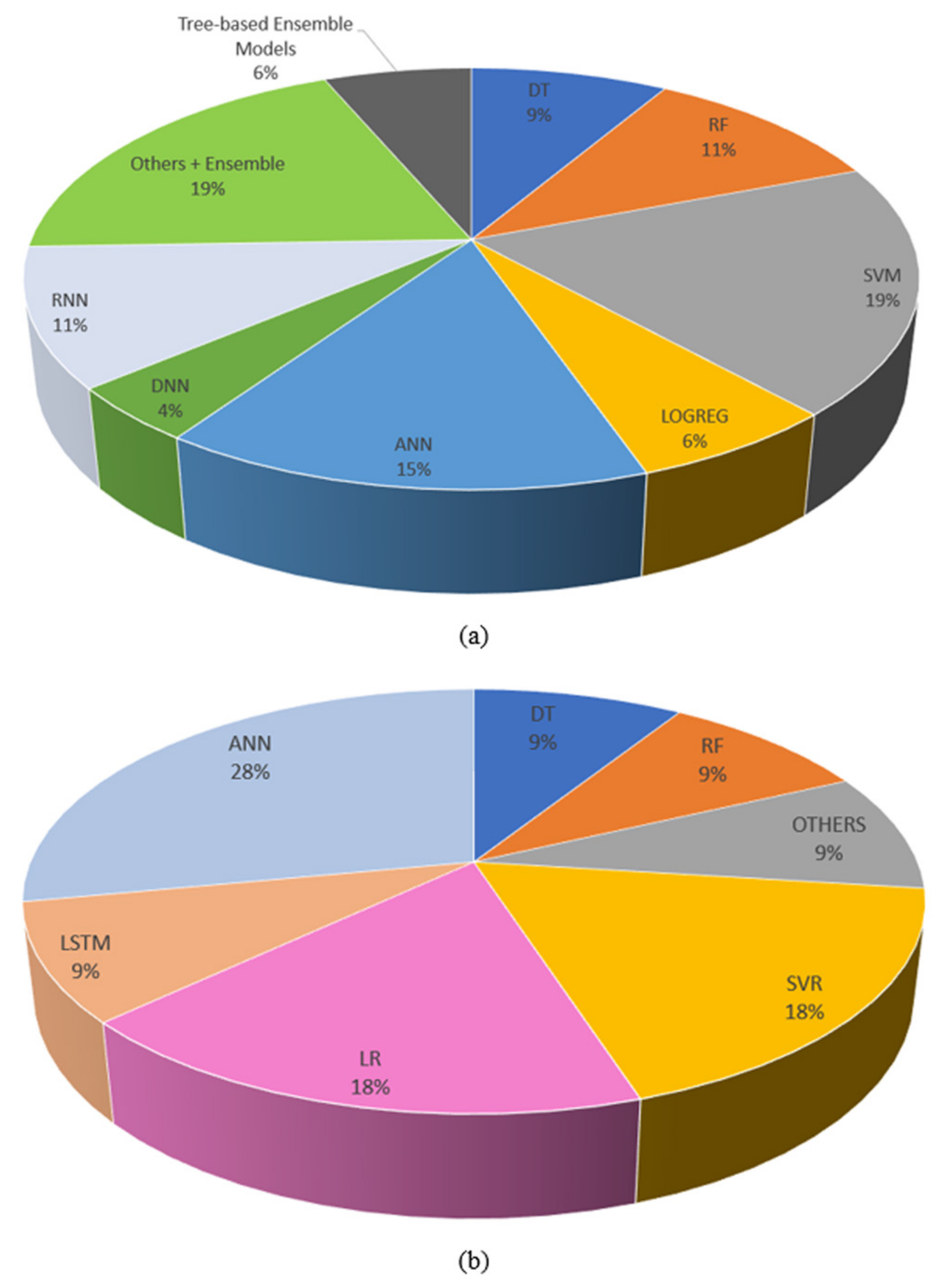
3.3. Model Selection in Studies
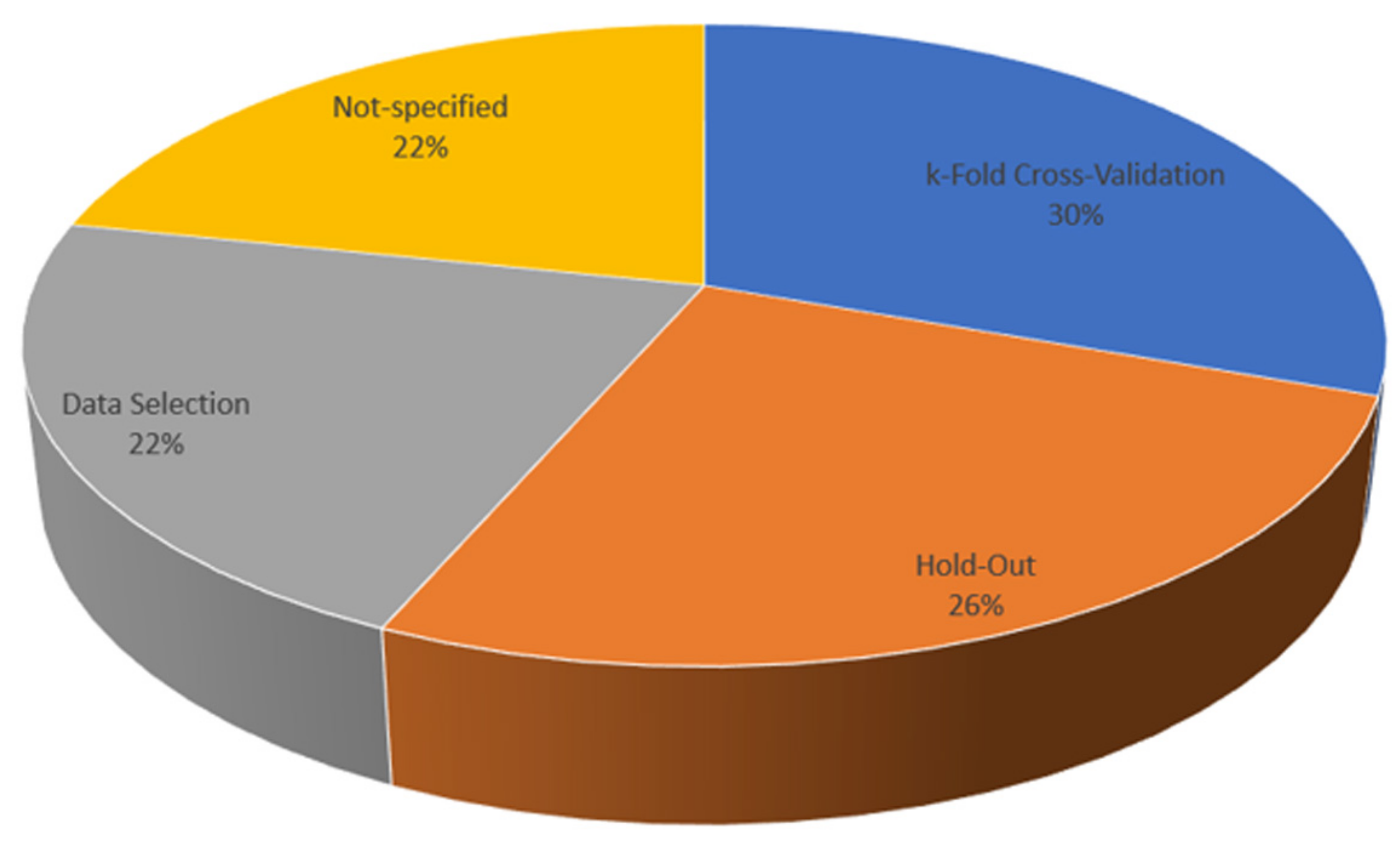
3.4. Evaluation and Validation Metrics in Studies
3.5. Datasets
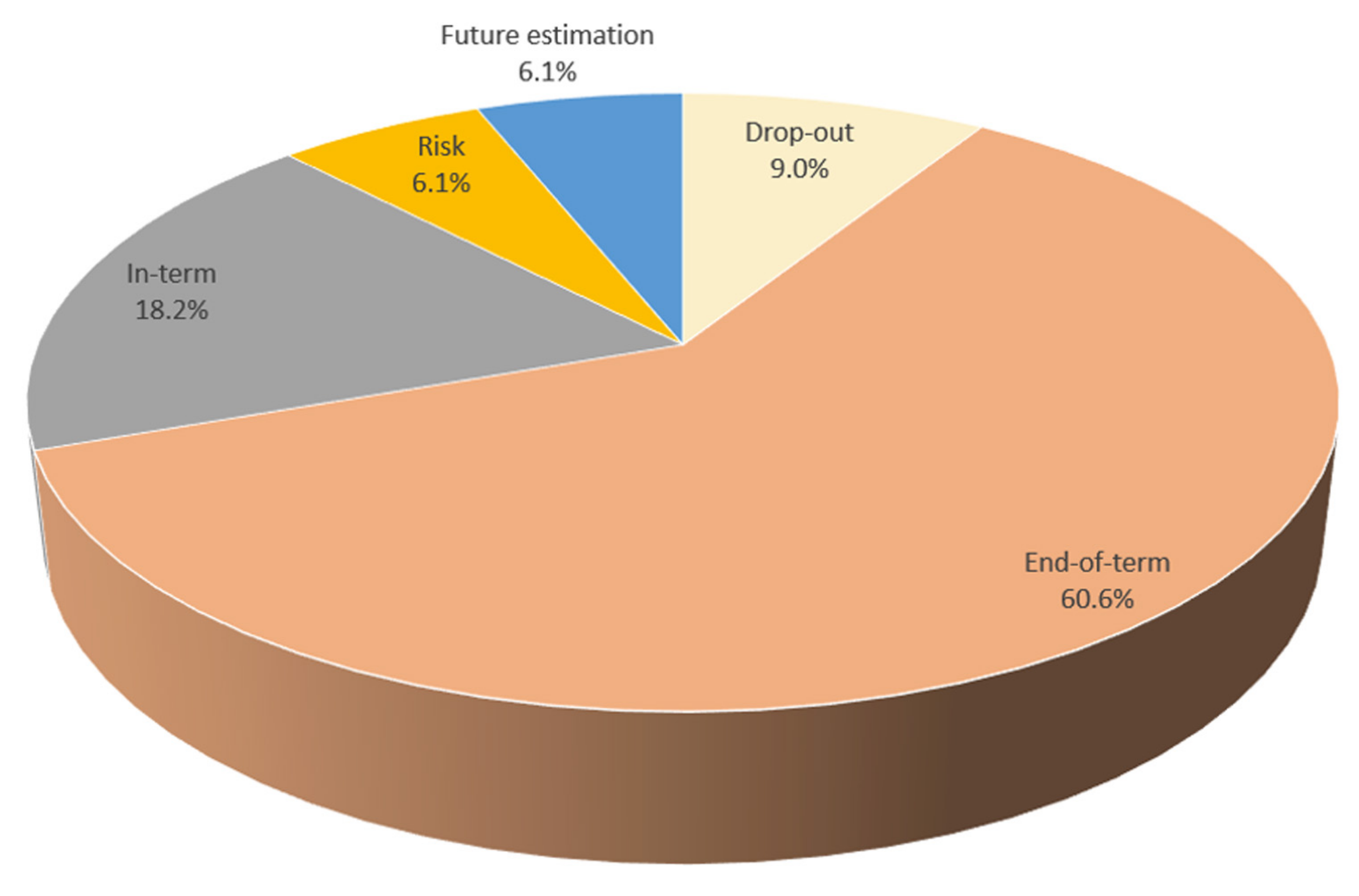
4. Results and Discussion
- Do drop-out predictions contribute significantly to the student and their success levels?
- When does the prediction of end-of-term success contribute to students’ self-development and their education?
- Do the in-term performance predictions provide sufficient time to contribute to the students?
- How early can risk predictions related to courses taken by students contribute to them?
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khashman, A.; Carstea, C. Oil price prediction using a supervised neural network. Int. J. Oil Gas Coal Technol. 2019, 20, 360. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Tuncal, K. Prediction of cancer incidence rates for the European continent using machine learning models. Health Inform. J. 2021, 27, 1460458220983878. [Google Scholar] [CrossRef] [PubMed]
- Ozcil, I.; Esenyel, I.; Ilhan, A. A Fuzzy Approach Analysis of Halloumi Cheese in N. Cyprus. Food Anal. Methods 2021. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Perrotta, C.; Selwyn, N. Deep learning goes to school: Toward a relational understanding of AI in education. Learn. Media Technol. 2019, 45, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Guan, C.; Mou, J.; Jiang, Z. Artificial intelligence innovation in education: A twenty-year data-driven historical analysis. Int. J. Innov. Stud. 2020, 4, 134–147. [Google Scholar] [CrossRef]
- Somasundaram, M.; Junaid, K.; Mangadu, S. Artificial Intelligence (AI) Enabled Intelligent Quality Management System (IQMS) For Personalized Learning Path. Procedia Comput. Sci. 2020, 172, 438–442. [Google Scholar] [CrossRef]
- Liu, J.; Loh, L.; Ng, E.; Chen, Y.; Wood, K.; Lim, K. Self-Evolving Adaptive Learning for Personalized Education; Association for Computing Machinery: New York, NY, USA, 2020; pp. 317–321. [Google Scholar] [CrossRef]
- Tilahun, L.; Sekeroglu, B. An intelligent and personalized course advising model for higher educational institutes. SN Appl. Sci. 2020, 2, 1635. [Google Scholar] [CrossRef]
- Wu, Z.; He, T.; Mao, C.; Huang, C. Exam Paper Generation Based on Performance Prediction of Student Group. Inf. Sci. 2020, 532, 72–90. [Google Scholar] [CrossRef]
- Yilmaz, N.; Sekeroglu, B. Student Performance Classification Using Artificial Intelligence Techniques. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2020; Volume 1095. [Google Scholar] [CrossRef]
- Zaffar, M.; Hashmani, M.; Savita, K.; Sajjad, S.; Rehman, M. Role of FCBF Feature Selection in Educational Data Mining. Mehran Univ. Res. J. Eng. Technol. 2020, 39, 772–778. [Google Scholar] [CrossRef]
- Jiang, P.; Wang, X. Preference Cognitive Diagnosis for Student Performance Prediction. IEEE Access 2020, 8, 219775–219787. [Google Scholar] [CrossRef]
- Gitinabard, N.; Xu, Y.; Heckman, S.; Barnes, T.; Lynch, C. How Widely Can Prediction Models Be Generalized? Performance Prediction in Blended Courses. IEEE Trans. Learn. Technol. 2019, 12, 184–197. [Google Scholar] [CrossRef] [Green Version]
- Gamulin, J.; Gamulin, O.; Kermek, D. Using Fourier coefficients in time series analysis for student performance prediction in blended learning environments. Expert Syst. 2015, 33. [Google Scholar] [CrossRef]
- Aydogdu, S. Predicting student final performance using artificial neural networks in online learning environments. Educ. Inf. Technol. 2020, 25, 1913–1927. [Google Scholar] [CrossRef]
- Zhao, L.; Chen, K.; Song, J.; Zhu, X.; Sun, J.; Caulfield, B.; Namee, B. Academic Performance Prediction Based on Multisource, Multifeature Behavioral Data. IEEE Access 2021, 9, 5453–5465. [Google Scholar] [CrossRef]
- He, Y.; Chen, R.; Li, X.; Hao, C.; Liu, S.; Zhang, G.; Jiang, B. Online At-Risk Student Identification using RNN-GRU Joint Neural Networks. Information 2020, 11, 474. [Google Scholar] [CrossRef]
- Mengash, H. Using Data Mining Techniques to Predict Student Performance to Support Decision Making in University Admission Systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Yang, J.; Devore, S.; Hewagallage, D.; Miller, P.; Ryan, Q.; Stewart, J. Using machine learning to identify the most at-risk students in physics classes. Phys. Rev. Phys. Educ. Res. 2020, 16, 020130. [Google Scholar] [CrossRef]
- Figueroa-Cañas, J.; Sancho-Vinuesa, T. Early Prediction of Dropout and Final Exam Performance in an Online Statistics Course. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2020, 15, 86–94. [Google Scholar] [CrossRef]
- Xing, W.; Du, D. Dropout Prediction in MOOCs: Using Deep Learning for Personalized Intervention. J. Educ. Comput. Res. 2018, 57, 073563311875701. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.; Shami, A. Multi-split optimized bagging ensemble model selection for multiclass educational data mining. Appl. Intell. 2020, 50, 4506–4528. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. BMJ 2009, 339, e1000097. [Google Scholar] [CrossRef] [Green Version]
- Shanthini, A.; Vinodhini, G.; Chandrasekaran, R. Predicting Students’ Academic Performance in the University Using Meta Decision Tree Classifiers. J. Comput. Sci. 2018, 14, 654–662. [Google Scholar] [CrossRef] [Green Version]
- Yan, L.; Liu, Y. An Ensemble Prediction Model for Potential Student Recommendation Using Machine Learning. Symmetry 2020, 12, 728. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Dimililer, K.; Tuncal, K. Artificial intelligence in education: Application in student performance evaluation. Dilemas Contemp. Educ. Política Y Valores 2019, 7, 1–21. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; Taylor and Francis: Boca Raton, FL, USA, 1984. [Google Scholar]
- Oytun, M.; Tinazci, C.; Sekeroglu, B.; Acikada, C.; Yavuz, H. Performance Prediction and Evaluation in Female Handball Players Using Machine Learning Models. IEEE Access 2020, 8, 116321–116335. [Google Scholar] [CrossRef]
- Dougherty, G. Pattern Recognition and Classification; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pahlavan-Rad, M.; Dahmardeh, K.; Hadizadeh, M.; Keykha, G.; Mohammadnia, N.; Keikha, M.G.M.; Davatgar, N.; Brungard, C. Prediction of soil water infiltration using multiple linear regression and random forest in a dry flood plain, eastern Iran. CATENA 2020, 194, 104715. [Google Scholar] [CrossRef]
- Yang, L.; Wu, H.; Jin, X.; Zheng, P.; Hu, S.; Xu, X.; Yu, W.; Yan, J. Study of cardiovascular disease prediction model based on random forest in eastern China. Sci. Rep. 2020, 10, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. arXiv 2016, arXiv:1603.02754. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Smola, A.; Scholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199. [Google Scholar] [CrossRef] [Green Version]
- Sekeroglu, B.; Dimililer, K. Review and analysis of hidden neuron number effect of shallow backpropagation neural networks. Neural Netw. World 2020, 30, 97–112. [Google Scholar] [CrossRef]
- Mason, C.; Twomey, J.; Wright, D.; Whitman, L. Predicting Engineering Student Attrition Risk Using a Probabilistic Neural Network and Comparing Results with a Backpropagation Neural Network and Logistic Regression. Res. High. Educ. 2018, 59, 382–400. [Google Scholar] [CrossRef]
- Stanton, J. Galton, Pearson, and the Peas: A brief history of linear regression for statistics instructors. J. Stat. Educ. 2001, 9. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Yuan, J. Student Performance Prediction Model Based on Discriminative Feature Selection. Int. J. Emerg. Technol. Learn. (IJET) 2018, 13, 55. [Google Scholar] [CrossRef]
- Wakelam, E.; Jefferies, A.; Davey, N.; Sun, Y. The potential for student performance prediction in small cohorts with minimal available attributes. Br. J. Educ. Technol. 2019, 51, 347–370. [Google Scholar] [CrossRef] [Green Version]
- Luque, A.; Carrasco, A.; Martin, A.; de Las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 6829. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Ever, Y.; Dimililer, K.; Sekeroglu, B. Comparison of Machine Learning Techniques for Prediction Problems. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2019; Volume 927. [Google Scholar] [CrossRef]
- Ozsahin, I.; Sekeroglu, B.; Musa, M.; Mustapha, M.; Ozsahin, D. Review on Diagnosis of COVID-19 from Chest CT Images Using Artificial Intelligence. Comput. Math. Methods Med. 2020, 2020, 9756518. [Google Scholar] [CrossRef]
- Azcona, D.; Hsiao, I.; Smeaton, A. Detecting students-at-risk in computer programming classes with learning analytics from students’ digital footprints. User Model. User-Adapt. Interact. 2019, 29, 759–788. [Google Scholar] [CrossRef]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, S.; Ali, S. Using machine learning to predict student difficulties from learning session data. Artif. Intell. Rev. 2019, 52, 381–407. [Google Scholar] [CrossRef]
- Imran, M.; Latif, S.; Mehmood, D.; Shah, M. Student Academic Performance Prediction using Supervised Learning Techniques. Int. J. Emerg. Technol. Learn. 2019, 14, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Waheed, H.; Ul Hassan, S.; Aljohani, N.; Hardman, J.; Alelyani, S.; Nawaz, R. Predicting academic performance of students from VLE big data using deep learning models. Comput. Hum. Behav. 2020, 104, 106189. [Google Scholar] [CrossRef] [Green Version]
- Yousafzai, B.; Hayat, M.; Afzal, S. Application of machine learning and data mining in predicting the performance of intermediate and secondary education level student. Educ. Inf. Technol. 2020, 25, 4677–4697. [Google Scholar] [CrossRef]
- Naicker, N.; Adeliyi, T.; Wing, J. Linear Support Vector Machines for Prediction of Student Performance in School-Based Education. Math. Probl. Eng. 2020, 2020, 1–7. [Google Scholar] [CrossRef]
- Elbadrawy, A.; Polyzou, A.; Ren, Z.; Sweeney, M.; Karypis, G.; Rangwala, H. Predicting Student Performance Using Personalized Analytics. Computer 2016, 49, 61–69. [Google Scholar] [CrossRef]
- Deo, R.; Yaseen, Z.; Al-Ansari, N.; Nguyen-Huy, T.; Langlands, T.; Galligan, L. Modern Artificial Intelligence Model Development for Undergraduate Student Performance Prediction: An Investigation on Engineering Mathematics Courses. IEEE Access 2020, 8, 136697–136724. [Google Scholar] [CrossRef]
- Turabieh, H.; Azwari, S.; Rokaya, M.; Alosaimi, W.; Alhakami, A.A.W.; Alnfiai, W. Enhanced Harris Hawks optimization as a feature selection for the prediction of student performance. Computing 2021, 103, 1417–1438. [Google Scholar] [CrossRef]
- Wang, X.; Yu, X.; Guo, L.; Liu, F.; Xu, L. Student Performance Prediction with Short-Term Sequential Campus Behaviors. Information 2020, 11, 201. [Google Scholar] [CrossRef] [Green Version]
- Adejo, O.; Connolly, T. Predicting student academic performance using multi-model heterogeneous ensemble approach. J. Appl. Res. High. Educ. 2017, 10, 61–75. [Google Scholar] [CrossRef]
- Tran, O.; Dang, H.; Thuong, D.; Truong, T.; Vuong, T.; Phan, X. Performance Prediction for Students: A Multi-Strategy Approach. Cybern. Inf. Technol. 2017, 17, 164–182. [Google Scholar] [CrossRef] [Green Version]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Transfer Learning from Deep Neural Networks for Predicting Student Performance. Appl. Sci. 2020, 10, 2145. [Google Scholar] [CrossRef] [Green Version]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open University Learning Analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortez, P.; Silva, A. Using Data Mining to Predict Secondary School Student Performance. In Proceedings of the 5th FUture BUsiness TEChnology Conference (FUBUTEC 2008), Porto, Portugal, 9–11 April 2008; pp. 5–12, ISBN 978-9077381-39-7. [Google Scholar]
- Sood, S.; Saini, M. Hybridization of Cluster-Based LDA and ANN for Student Performance Prediction and Comments Evaluation. Educ. Inf. Technol. 2021, 26, 2863–2878. [Google Scholar] [CrossRef]
- Balci, S.; Ayhan, B. Internet usage patterns among university students. J. Selcuk Commun. 2007, 5, 174–197. [Google Scholar]
- Bodovski, K.; Jeon, H.; Byun, S. Cultural capital and academic achievement in post-socialist Eastern Europe. Br. J. Sociol. Educ. 2017, 38, 887–907. [Google Scholar] [CrossRef]
- Richardson, M.; Abraham, C.; Bond, R. Psychological correlates of university students’ academic performance: A systematic review and meta-analysis. Psychol. Bull. 2012, 138, 353–387. [Google Scholar] [CrossRef] [Green Version]
- Boz, Y.; Boz, N. Prospective chemistry and mathematics teachers’ reasons for choosing teaching as a profession. Kastamonu Educ. J. 2008, 16, 137–144. [Google Scholar]
- Kayalar, F.; Kayalar, F. The effects of Auditory Learning Strategy on Learning Skills of Language Learners (Students’ Views). IOSR J. Humanit. Soc. Sci. (IOSR-JHSS) 2017, 22, 4–10. [Google Scholar] [CrossRef]
- Memduhoğlu, H.; Tanhan, F. Study of organizational factors scale’s validity and reliability affecting university students’ academic achievements. YYU J. Educ. Fac. 2013, X, 106–124. [Google Scholar]
- Franzoni, V.; Pallottelli, S.; Milani, A. Reshaping Higher Education with e-Studium, a 10-Years Capstone in Academic Computing. Lect. Notes Comput. Sci. 2020, 12250, 293–303. [Google Scholar] [CrossRef]
- Franzoni, V.; Tasso, S.; Pallottelli, S.; Perri, S. Sharing Linkable Learning Objects with the Use of Metadata and a Taxonomy Assistant for Categorization. Lect. Notes Comput. Sci. 2019, 11620, 336–348. [Google Scholar] [CrossRef]
- Schneider, M.; Preckel, F. Variables Associated With Achievement in Higher Education: A Systematic Review of Meta-Analyses. Psychol. Bull. 2017, 143, 565–600. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Task |
|---|---|
| Artificial Neural Networks | Classification and Regression |
| Deep Neural Networks | Classification and Regression |
| Long Short-Term Memory NN | Classification and Regression |
| Decision Tree | Classification and Regression |
| Random Forest | Classification and Regression |
| Ectreme Gradient Boosting | Classification and Regression |
| Gradient Boosting | Classification and Regression |
| Logistic Regression | Classification |
| Linear Regression | Regression |
| Support Vector Machine | Classification |
| Support Vector Regression | Regression |
| Author/Publication Year | Objective | Type | Target Level | Primary ML Method | Primary Evaluation Metric (s) | Validation Technique |
|---|---|---|---|---|---|---|
| Zaffar et al., 2020 [12] | End-of-term | C | HS+HE | FCBF + SVM | Accuracy, Precision Recall, F1 Score | 10-fold cross-validation |
| Jiang and Wang, 2020 [13] | In-term | R | HS | PreferenceCD | RMSE and MAE | 5-fold cross-validation |
| Gitinabard et al., 2019 [14] | Early prediction | C | HE | SVM, RF, Logistic Regression | F1 Score | 5-fold cross-validation |
| Gamulin et al., 2015 [15] | End-of-term | C | HE | DFT + (nB/kNN/ANN/SVM) | Accuracy | Hold-out |
| Aydogdu, 2020 [16] | End-of-term | C | HE | ANN | Accuracy | Hold-out |
| He et al., 2020 [18] | At-risk identification | C | HE | RNN-GRU Joint Neural Networks | Accuracy | Hold-out |
| Mengash, 2020 [19] | End-of-term | C | HE | ANN | Accuracy, Recall, Precision, and F1 Score | 10-fold cross-validation |
| Yang et al., 2020 [20] | End-of-term, at-risk | C | HE | RF | Accuracy, ROC AUC, Recall, Specificity, Precision | Hold-out |
| Figueroa-Cañas and Sancho-Vinue, 2020 [21] | Dropout and Final Exam Performance | C | HE | Conditional Tree | Recall | 5-fold cross-validation |
| Xing and Du, 2018 [22] | Drop out | C | HE | DNN | ROC AUC | 10-fold cross-validation |
| Injadat et al., 2020 [23] | In-term | C | HE | Ensemble Model | Accuracy, Precision, Recall, F1 Score, FPR | Hold-out |
| Shantini et al., 2018 [25] | End-of-term | C | HE | AdaBoost | Precision, Recall, and F1 Score | Hold-out |
| Yan and Liu, 2020 [26] | Predict student performance in academic competition | C | HE | Ensemble Model (SVM/RF/AdaBoost) | Precision, Recall, F1 Score, ROC AUC | 10-fold cross-validation |
| Sekeroglu et al., 2019 [27] | End-of-term | C | HS | ANN + DT | Accuracy | Hold-out |
| Lu and Yuan, 2017 [42] | End-of-term | C | HS | integrated Optimized Ensemble Feature Selection Algorithm by Density Peaks + SVM | Accuracy | 10-fold cross-validation |
| Wakelam et al., 2019 [43] | In-term, end-of-term, at-risk | R | HE | DT, KNN and RF | MSE | - |
| Azcona et al., 2019 [48] | At-risk prediction | C | HE | kNN, RF, DT, Logistic Regression, Linear and Gaussian SVM | F1 Score, Precision, Recall | - |
| Hussain et al., 2019 [49] | In-term | C | HE | ANN, SVM | Accuracy, F1 Score, Precision, Recall | 5-fold cross-validation |
| Imran et al., 2019 [50] | End-of-term | C | HS | J48 DT | Accuracy (for comparisons) | 5-fold cross-validation |
| Waheed et al., 2020 [51] | End-of-term, early prediction | C | HE | DNN | Recall, Precision, Accuracy | Hold-out |
| Yousafzai et al., 2020 [52] | End-of-term | R + C | PE+HS | GA-based DT | Accuracy, RMSE | 10-fold cross-validation |
| Naicker et al., 2020 [53] | End-of-term | C | HS | Linear SVM | Accuracy, ROC AUC | 5-fold cross-validation |
| Elbadrawy et al., 2016 [54] | Next-term grade prediction, In-class assessment prediction | R | HE | RF, FM, PLMR, Course-specific regression | RMSE, MAE | - |
| Deo et al., 2020 [55] | End-of-term | R | HE | ELM | MAE, MAPE, root MSE, RRMSE | Hold-out |
| Yan and Liu, 2020 [26] | Predict student performance in academic competition | C | HE | Ensemble Model (SVM/RF/AdaBoost) | Precision, Recall, F1 Score, ROC AUC | 10-fold cross-validation |
| Sekeroglu et al., 2019 [27] | End-of-term | C | HS | ANN + DT | Accuracy | Hold-out |
| Lu and Yuan, 2017 [42] | End-of-term | C | HS | Integrated Optimized Ensemble Feature Selection Algorithm by Density Peaks + SVM | Accuracy | 10-fold cross-validation |
| Wakelam et al., 2019 [43] | In-term, end-of-term, at-risk | R | HE | DT, KNN and RF | MSE | - |
| Azcona et al., 2019 [48] | At-risk prediction | C | HE | kNN, RF, DT, Logistic Regression, Linear and Gaussian SVM | F1 Score, Precision, Recall | - |
| Hussain et al., 2019 [49] | In-term | C | HE | ANN, SVM | Accuracy, F1 Score, Precision, Recall | 5-fold cross-validation |
| Imran et al., 2019 [50] | End-of-term | C | HS | J48 DT | Accuracy (for comparisons) | 5-fold cross-validation |
| Waheed et al., 2020 [51] | End-of-term, Early prediction | C | HE | DNN | Recall, Precision, Accuracy | Hold-out |
| Yousafzai et al., 2020 [52] | End-of-term | R + C | PE+HS | GA-based DT | Accuracy, RMSE | 10-fold cross-validation |
| Naicker et al., 2020 [53] | End-of-term | C | HS | Linear SVM | Accuracy, ROC AUC | 5-fold cross-validation |
| Elbadrawy et al., 2016 [54] | Next-term grade prediction, In-class assessment prediction | R | HE | RF, FM, PLMR, Course-specific regression | RMSE, MAE | - |
| Deo et al., 2020 [55] | End-of-term | R | HE | ELM | MAE, MAPE, root MSE, RRMSE | Hold-out |
| Turabieh et al., 2020 [56] | End-of-term | C | HS | HHO + Layered RNN | Accuracy | Hold-out |
| Wang et al., 2020 [57] | In-term, end-of-term | C | HE | Attention-based Hybrid RNN + SVM | Accuracy, Recall | Hold-out |
| Adejo and Connolly, 2017 [58] | Early identification At risk of dropping out | C | HE | Ensemble Hybrid model | Accuracy, Precision, Recall, F1 Score, Error | 10-fold cross-validation |
| Tran et al., 2017 [59] | End-of-term | R | HE | Hybrid Model | RMSE | 10-fold cross-validation |
| Tsiakmaki et al., 2020 [60] | Students at risk | C | HE | DNN and Transfer Learning | Accuracy | 10-fold cross-validation |
| Dataset | Level | Type | Courses/Modules | # of Students |
|---|---|---|---|---|
| SPD | SE | Questionnaire | 2 | 649 and 395 |
| Kaggle MOOC | HE | Online | 247 | >155,000 |
| WorldUC Dataset | HE | Online | 10 | 10,523 |
| Liru Dataset | HE | Online | 18 | 1046 |
| Junyi Dataset | HE | Online | 18 | 2063 |
| OULAD | HE | Online | 22 | 32,593 |
| Real-world dataset smart card | HE | C. Behaviors | - | 9207 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sekeroglu, B.; Abiyev, R.; Ilhan, A.; Arslan, M.; Idoko, J.B. Systematic Literature Review on Machine Learning and Student Performance Prediction: Critical Gaps and Possible Remedies. Appl. Sci. 2021, 11, 10907. https://doi.org/10.3390/app112210907
Sekeroglu B, Abiyev R, Ilhan A, Arslan M, Idoko JB. Systematic Literature Review on Machine Learning and Student Performance Prediction: Critical Gaps and Possible Remedies. Applied Sciences. 2021; 11(22):10907. https://doi.org/10.3390/app112210907
Chicago/Turabian StyleSekeroglu, Boran, Rahib Abiyev, Ahmet Ilhan, Murat Arslan, and John Bush Idoko. 2021. "Systematic Literature Review on Machine Learning and Student Performance Prediction: Critical Gaps and Possible Remedies" Applied Sciences 11, no. 22: 10907. https://doi.org/10.3390/app112210907
APA StyleSekeroglu, B., Abiyev, R., Ilhan, A., Arslan, M., & Idoko, J. B. (2021). Systematic Literature Review on Machine Learning and Student Performance Prediction: Critical Gaps and Possible Remedies. Applied Sciences, 11(22), 10907. https://doi.org/10.3390/app112210907