1. Introduction
Pattern recognition methods using deep learning techniques have shown good results in many applications [
1,
2,
3,
4,
5]. However, these results can only be obtained with a sufficiently large number of training data. Unlike the conventional deep learning models, humans can classify patterns with only a small number of samples. In order to realize this ability in a deep learning model, studies on few-shot learning have been attracting attention recently [
6,
7,
8].
In few-shot learning for classification tasks, a classifier is required to recognize classes that are unseen in the learning phase, with a very limited number of samples. To achieve this goal, there have been proposed a number of few-shot classification models which are composed of two modules: an embedding module and a classification module [
8,
9,
10,
11,
12]. The embedding module extracts appropriate features through mapping given input to an embedding space, and the classification module tries to classify newly given samples (query data) with only a few training samples (support data) by using the features from the embedding module. Since a new learning strategy, called episodic learning [
8], was proposed to obtain a good embedding function under the few-shot scenario in [
8], most of the subsequent works have mainly focused on designing a good embedding function model that can provide an efficient and general representation for recognizing unseen test classes [
13,
14,
15,
16,
17].
On the other hand, there has been relatively little interest in the classification module where linear classifiers or simple distance-based classifiers have been mainly adopted [
18,
19,
20]. This approach seems to be appropriate for the situation that the number of labeled samples for test classes is very limited because classifiers with high complexity can be easily overfitted to the few given samples. Although computational experiments have shown that a simple classifier combined with a well-generalized embedding module can achieve good performance [
21], there would be further room for improvement in the classification module [
22,
23,
24]. In this paper, we try to improve the performance of the few-shot classifiers by elaborating on the distance-based classification module.
It is well-known that the accuracy of a distance-based classifier can be improved by using a statistical measure such as Mahalanobis distance [
25] rather than simple geometric measures such as Euclidean distance. Under the situation of few-shot classification, however, it is difficult to utilize the statistical measure because the estimation of accurate distribution is hard due to the extremely limited number of samples. Inaccurate estimation on the class distributions lead to poor distance measure, resulting in low classification accuracy.
To overcome this limitation, we propose to combine the probabilistic similarity based on intra-class statistics [
26,
27,
28,
29] with the prototypical network [
9] that is a representative few-shot classification model. In [
26,
27], the probabilistic similarity between two samples is defined as a probability that they belong to the same class, and its probability density function is estimated under the assumption that a data point is generated from two factors: a class-specific factor and a class-independent factor. The class-specific factor can be represented by a prototype vector that is defined as the mean vector of support samples in the prototypical network [
9]. The class-independent factor can be considered as an environmental factor that is irrelevant to each class, and thus can be estimated through an episodic learning strategy developed for few-shot learning [
8,
9,
30].
Based on these considerations, we develop a method for applying the probabilistic similarity measure in the learning of embedding function as well as in the recognition of unseen classes. Moreover, by exploiting the similarity in learning of the embedding function as well, it is also expectable to obtain better feature representation, which is more suitable to the assumption on the data distribution for the prototype-based classifier. Additionally, since the distribution of the class-independent factor can be estimated more accurately as the number of classes increases even when each class has few samples, the proposed method is expected to be more effective in the case of a large number of classes. This can be an advantage of the proposed method, which cannot be expected from the conventional works using Euclidean distance.
The aim and main contributions of our work are summarized below:
In order to improve the performance of few-shot classification, we propose to combine the probabilistic similarity measure with deep embedding function networks.
We define an explicit function of probabilistic similarity based on the intra-class statistics and propose a modified episodic learning algorithm that simultaneously performs estimation of the similarity and optimization of the embedding function.
Whereas the conventional methods have been tested for a limited number of classes, we evaluate the change of performance as the number of classes increases, and confirm the apparent superiority of the proposed method, especially in the case of many classes.
Although we adopted the prototypical network for the experiments, the proposed method is not constrained by the embedding network model, and thus it can be extended to various forms using more sophisticated deep network models.
In
Section 2, we describe the few-shot classification problem and briefly review the previous works to solve it, focusing on the metric-based method. In
Section 3, we explain the probabilistic similarity measure used in our proposed method, and the overall process of the proposed method is described in
Section 4.
Section 5 presents experimental results on benchmark datasets comparing its performance with the existing methods. Our conclusion is made in
Section 6.
2. Few-Shot Classification Problem
The few-shot classification task is used to classify newly given samples by using an extremely limited number of training samples. The set of given training samples is called support set S, and the set of new samples to be classified is called query set Q. Usually, we consider the N-way K-shot problem, where the number of classes is N and the number of support samples per class is K. Since the value of K is very small, it is difficult to obtain a good classification model with only support samples. Therefore, in order to develop a deep learning model for few-shot classification, it is normal to use a separate dataset that is in the same domain but has completely distinct class labels. In this approach, the main goal of the learning is to find a deep learning model that can recognize query samples from the new test classes with only a few support samples.
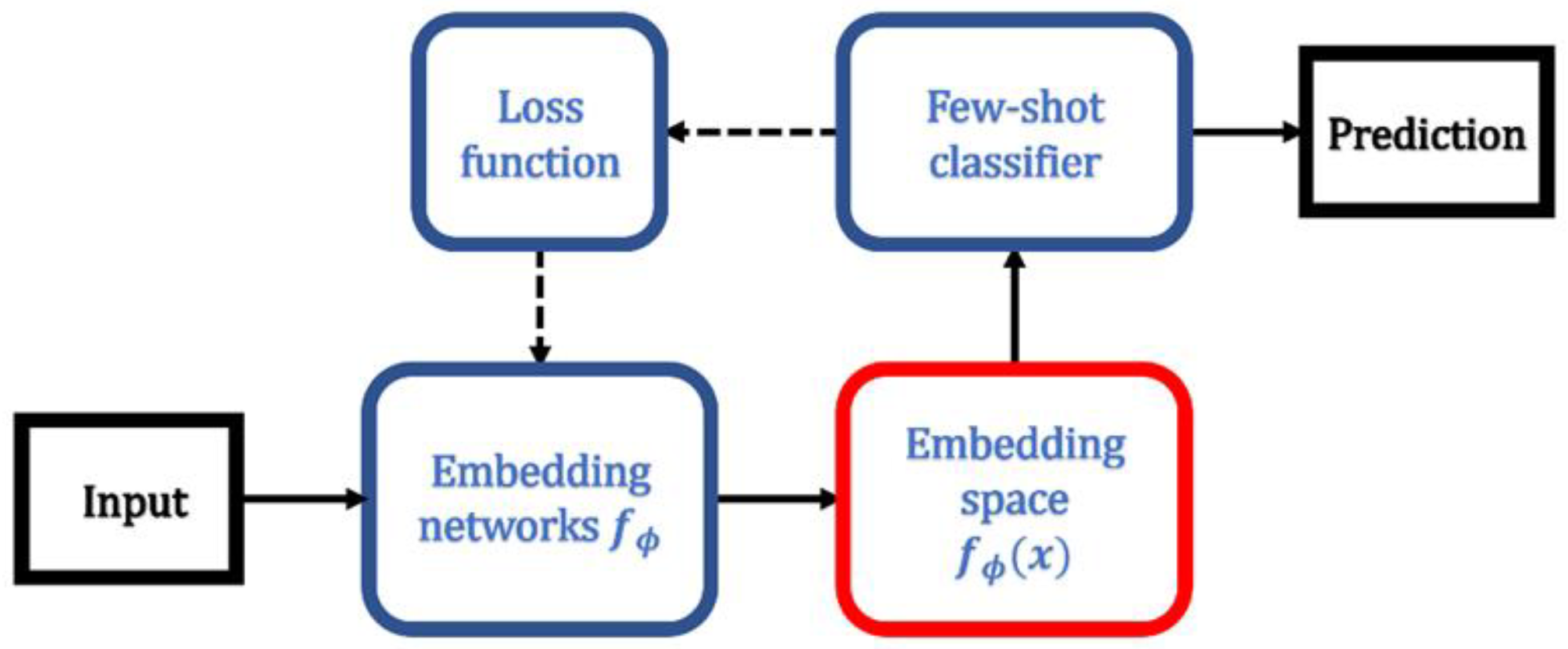
One of the representative methods for achieving this goal is the metric-based method which tries to find an appropriate metric for classification [
8,
9,
10,
12]. As shown in
Figure 1, the overall structure of the metric-based method is largely composed of two modules: the embedding network and the few-shot classifier. During the learning phase, a deep network model learns to find an embedding function that maps raw inputs to feature vectors on the embedding metric space. The few-shot classifier then predicts the class of query data based on their similarity to the support data, which is measured on the metric space. The loss from the classifier is then transmitted for learning of the embedding network.
Unlike the usual metric-learning problem, the few-shot learning task assumes that the classes in the test phase are unseen during the learning phase, and thus it is important to acquire a good embedding function that can generally apply to unseen test classes. To address this problem, the matching networks [
8] introduced the episodic learning strategy, which is one of the meta-learning techniques. In the episodic learning strategy, subsets in the form of an
N-way
K-shot classification are generated by random selections from the whole training data, which are called episodes. The neural network model updates the network parameters by learning one episode at a time. By proceeding through numerous episodes, the model learns a variety of cases composed of various classes and samples. In this way, the model is not limited to the given classes but can learn more generally about the domain of the classes. That is, information about unseen classes is obtained by the use of various combinations of classes that share some common factors of the domain.
Based on the episodic learning strategy, Snell et al. proposed the prototypical network [
9], which combines a nonlinear embedding function network and a simple distance-based classifier. Under the assumption that there exists an embedding space on which samples from each class are clustered around a single prototype, it tries to find a good embedding network through episodic learning. Once a good embedding space is found, the classification is conducted by simply finding the nearest class prototype defined as the mean of the support samples. The Euclidean distances between queries and the prototype on the embedding space are used for defining the loss function for learning of the embedding network as well, so as to create an embedding space where samples from each class are gathered near its prototype.
Since the prototypical network [
9] has shown better performance than more complicated few-shot learning models [
6,
7,
8], there have been a number of extensions based on the same structure shown in
Figure 1 [
10,
13,
14,
15]. Sung et al. [
10] added the relation module after the embedding module for more fine-grained classification. Li et al. [
13] proposed to use local features as additional information to image-level features in the embedding module. Based on the prototypical networks, Wertheimer et al. [
14] use a concatenation of foreground and background vector representations as feature vectors. Kim et al. [
15] introduced the variational autoencoder (VAE) structure [
31] into the embedding module for training the prototype images.
These works focused on obtaining a good embedding network and there has not been much interest in the classification module. This is primarily due to the limitations of the few-shot classification task. Even though it is known that other alternatives such as Mahalanobis distance [
25] can be adopted instead of the simple deterministic distance, it is difficult to apply the statistical distance, because it needs distribution information of samples which are not sufficiently given in the few-shot classification tasks.
As an attempt to overcome these difficulties, Fort [
22] tried confidence region estimation in the embedding space in the form of a Gaussian covariance matrix and used it to construct metrics. Liu et al. [
24] proposed to use of a new metric learning formula based on Mahalanobis distance [
25] to avoid the tendency to overfit the training class. However, these methods still have difficulty in estimating the covariance matrix of each class under the few-shot setting. Li et al. [
23] proposed a method relatively free from this problem by defining a local covariance that is obtained from local features in the embedding modules. Though this method shows the efficiency of the second-order statistics, it needs a more complex classifier with specially designed metrics.
In this paper, we try to find some possibility of improving the classifier by using a probabilistic similarity based on the intra-class statistics, which can be estimated robustly especially when the number of classes increases. Unlike [
20], our proposed method does not depend on the structure of the embedding module, and it can be combined with the original prototypical network as well as other sophisticated models.
3. Probabilistic Similarity Measure
In the probabilistic similarity measure [
26,
27,
28,
29], the similarity is defined as the probability that two data
and
belong to the same class
, which can be written as:
An explicit function of the probability can be obtained by defining a generation model of data
x with two components [
28]: class component
and environmental component
such as:
The environmental components originates from some environmental variations such as illuminations and is assumed to be independent of the class source. On the contrary, the class component is originated from a class-specific source determined differently for each class.
Additionally, Ref. [
28] further assumes that the class-specific component
for each class
can be regarded as a unique prototype, and the intra-class variations are caused by the environmental component
. The environmental component is also assumed to be independent of the class and be identical regardless of the class-label. Although these assumptions may be considered rather strict for application in real data, they are consistent with the assumption placed on the classifier of the prototypical network. More precisely, the simple classifier used in the prototypical network can be regarded as a particular case of the distance-based classifier using the probabilistic similarity used in [
26,
27,
28,
29].
In order to obtain an explicit form of the probabilistic similarity, let us consider a difference vector between two samples
and
belonging to a single class
, which can be written as:
By subtracting two vectors belonging to the same class, we can infer that the class-specific component disappears and only the environmental component remains in the intra-class difference vector. Then, the probability that the two data belong to the same class can be obtained by estimating the probability density function .
According to the assumption in [
28], all classes have the same environmental component
. Therefore, all of the difference vectors will follow a single distribution regardless of class-labels. We can specify the distribution using this set of difference vectors and the characteristics of the environmental component
. Noting that the environmental component
is caused by diverse sources, we can assume that
is subject to Gaussian distribution, and so does the difference vector
.
In order to estimate the mean and variance of Gaussian pdf
, we compose the set of intra-class difference vectors
using support samples, which can be defined as:
Then, the mean vector
and the covariance matrix
can be estimated from the set
, and the density function
that we want to know can be written as:
Noting that the higher value of
implies a higher likelihood that the two data making up
belong to the same class, the similarity measure
for two samples
and
is defined as the value proportional to
, such as:
The efficiency of the obtained similarity value has been confirmed in various application problems [
26,
27,
32]. In the prototypical network, its classifier uses Euclidean distance, which is the special case of the probabilistic similarity with
and unit covariance matrix. In this paper, we apply the general covariance matrix in the learning of embedding function as well as classification. It should also be remarked that this similarity is different from the conventional Mahalanobis distance [
25] that uses covariance of original samples
. By using intra-class difference vectors, the larger number of samples can be used to estimate the covariance matrix
, and can obtain more accurate estimation.
4. Proposed Method
4.1. Few-Shot Classification Using Probabilistic Similarity
The assumption for deriving the explicit form of Equation (6) is rather impractical to deal with diverse variations of real data, but it could be effectively applied to the data representation obtained from the well-trained embedding function. Based on this consideration, we propose to combine the probabilistic similarity with the metric-based few-shot classification model. Though the probabilistic similarity does not depend on the structure of the embedding network and can be combined with various few-shot learning models, we adopt the prototypical network, the primary and representative model, in order to focus on the effect of the similarity.
When the probabilistic similarity
of Equation (6) is applied to the few-shot classification model,
is a query data,
is a support data, and the average
of the difference vectors can be set to zero. Additionally, with the few-shot classification model, we have an embedding function
with parameter
, and the embedding vector representation
can be used instead of the raw data
. The similarity function is then written as:
With the nearest neighbor classifier, we assign query data
to the classes including the support data with maximum similarity values. For the case of prototype-based classifier, a prototype vector
for each class
is calculated first by taking the mean of embedding support vectors
in
, which is written as:
Then, the class-label of query data
is determined by the similarity between embedding query vector
and the prototype
for each class
;
According to the format of the distance-based classifier, the similarity function defined above is rewritten as a distance function and we finally obtain:
Here, the covariance matrix is a parameter to be estimated during learning of embedding network as well as classification. Note that this probabilistic similarity has an advantage in that the number of samples for estimating is relatively large even under the few-shot situation. Since the set of intra-class difference vectors is used for estimation, the number of samples in is finally in the case of the N-way K-shot problem.
In the few-shot classification, it is important to catch common distributional property shared by different classes at the learning phase and use them to classify the newly given classes in the test phase. Since the probabilistic similarity measure is derived from the distribution of environmental components shared by all classes, it can be estimated iteratively through episodic learning.
At
t-th iteration of episodic learning, with the set of difference vectors
, the covariance
is estimated as:
where
is a user-defined parameter to control the proportion of the previously obtained estimation at
-th episode. In the test phase, we have the set of difference vectors
composed of support samples in test classes, and the covariance
is estimated as:
where
is the covariance estimated by using the whole train set after learning is finished, and it is added to the covariance of the set of
with a user-defined coefficient
. We should note that the estimated covariance can be near singular under the few-shot settings, especially when the dimension of the embedding vector is larger than a number of samples in
. In that case, we need to add a regularization term (e.g., identity matrix) to prevent a singular condition of its inverse matrix.
4.2. Overall Process
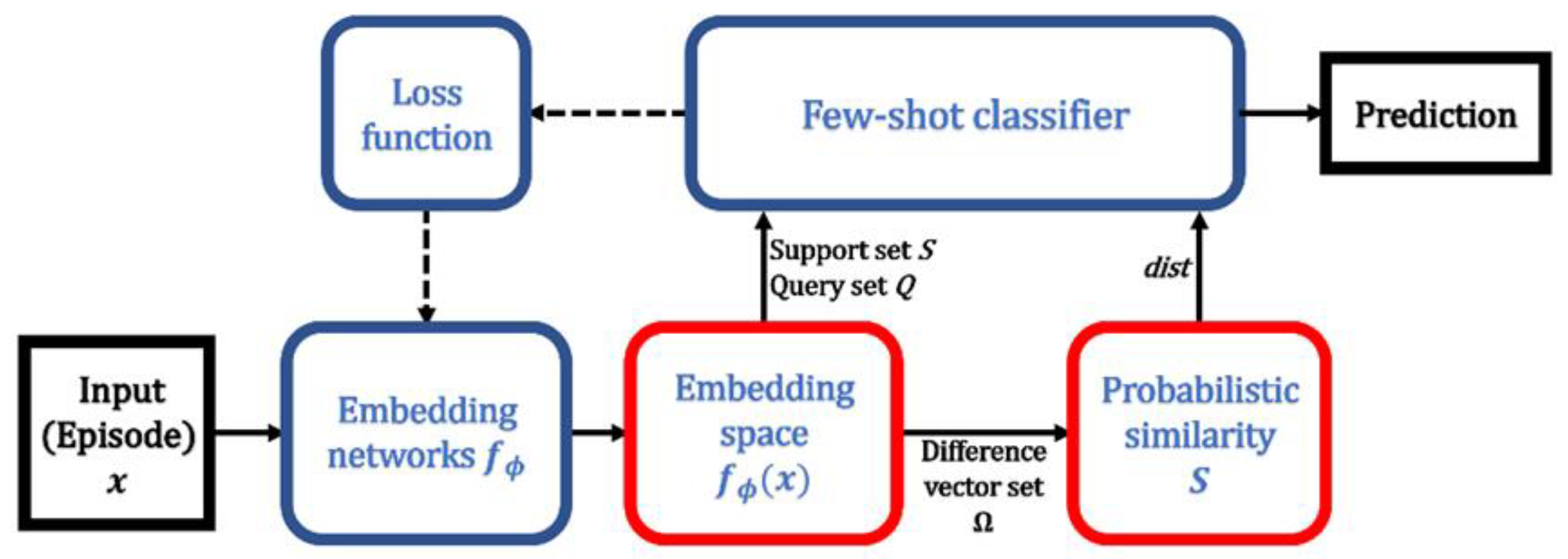
Figure 2 shows the overall structure of the proposed few-shot classification model using probabilistic similarity. The overall process follows the conventional metric-based few-shot classifier illustrated in
Figure 1, but there is an additional module for obtaining probabilistic similarity.
Under the
N-way
K-shot classification scenario, a subset for an episode contains examples from
N different classes, each of which is decomposed as the support set
with
K samples and the query set
with the remaining samples (
). Using the support set
, the prototype vector for each class is calculated and the set of intra-class difference vectors is also composed. The samples in the query set
are given to a few-shot classifier for conducting classification and evaluating loss value. The loss
L for the training episode is defined by using softmax over distances between queries and prototypes, which can be written as:
The proposed episodic learning process is summarized in Algorithm 1.
| Algorithm 1. A training algorithm for embedding network in N-way K-shot problem. N is the number of classes per episode, K is the number of support samples per class, Ncls is the total number of classes in the training set. |
| Input: Training set , where denotes the subset of composed of all samples with class label |
| Output: Trained embedding networks |
| for each episode t do |
| Compose a subset V by randomly selecting N values from |
| Set |
| for each class label k in V do |
| Compose a support set Sk by randomly selecting K examples from |
| Compose a query set Qk by subtracting Sk from |
| Calculate class prototype |
| Compose set of difference vectors |
| end for k |
| Calculate covariance matrix using |
| Update covariance matrix |
| Set loss |
| for each class k in V do |
| for each x in Qk do |
| |
| end for x |
| end for k |
| Update network parameters ϕ using a gradient descent optimizer with loss L |
| end fort |
In the test phase, samples from new classes that are not seen during learning are given. Each test class is also decomposed as support data and query data. After calculating the prototype vector and similarity function by using the optimized embedding function through the learning phase, query samples are assigned to the class of the closest prototype. In this case, the covariance matrix used for distance calculation is obtained by using Equation (12).
5. Experimental Results
In order to verify the performance of our proposed method, we conducted experiments using three datasets: Omniglot [
33], Multi-PIE [
32], and GTSRB [
34]. Since the purpose of the experiments is to see the effect of the probabilistic similarity measure, we mainly compare its performance with the conventional model with Euclidean distance. Each dataset was divided into training data and test data. With the training set, the embedding network was trained using the Adam optimizer. The learning rate started at
and halved every 5000 episodes. The training continued until convergence of loss value, which took at least 50,000 episodes. For the performance evaluation, the classification accuracies for 600 test episodes were calculated and averaged various
N-way
K-shot settings. Since the proposed method needs at least two samples to compose the difference vector set
, we set
, which is a common setting in the conventional works. Instead, we investigated the performance change according to the increase in the number of ways
N, which is practically more important but is not addressed in the previous works.
5.1. Omniglot Character Recognition
Figure 3 shows some examples of Omniglot data [
34] which are a handwritten dataset for various characters. It consists of 1623 characters collected from 50 alphabets, and each character has 20 samples drawn by different individuals. We follow the procedure of Vinyals et al. [
8] for data preparation and augmentation. The original
data are resized to
and rotated by multiples of 90 degrees. By rotating the existing image, we obtained four times as many classes as the original one. The embedding network with four convolutional blocks transforms an image into a 64-dimensional feature.
Since the embedding vector is 64 dimensions, the covariance matrix is , and thus we have 4096 parameters to be estimated, which is much larger than the number of data given in the few-shot task. This is prone to cause a singularity in the inversion of the covariance matrix during distance calculation. To avoid this, we added an identity matrix as a regularization term for estimating covariance, as shown in Equation (11). In the test phase, we also added the covariance obtained from training data as shown in Equation (12).
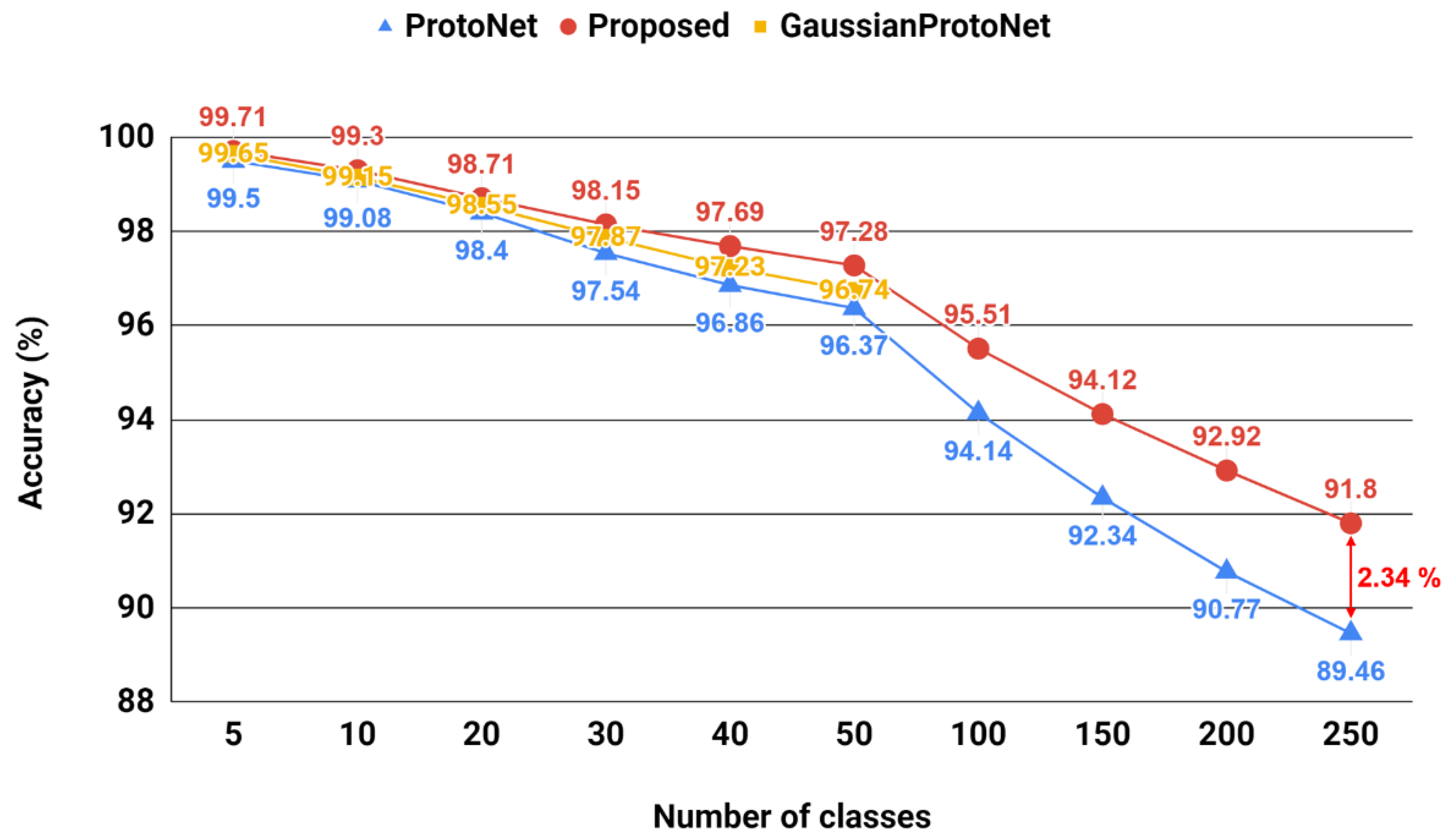
Table 1 compares the classification accuracy of the proposed method with the conventional methods, under the 5-shot settings. The Omniglot data are one of the representative benchmark sets for few-shot classification, but it is relatively simple. Thus, as shown in
Table 1, all the methods show good results while the proposed one achieves the best results. In
Figure 4, we compared the performance changes according to the number of test classes. In order to see the effectiveness of the proposed method, we compare the performance with the original prototypical network [
9] as well as the Gaussian prototypical network [
22] that uses class-wise covariance information. As shown in the graph, the performance degradation of the proposed method is gentler than the original prototypical network. Though the Gaussian prototypical network shows better performance than the original one, it can be seen that the proposed intra-class covariance gives a more effective distance measure than the class-wise covariance used in [
19]. Since the proposed probabilistic similarity is estimated by using intra-class difference vectors which increase in proportion to the number of classes, it is possible to estimate the covariance matrix
more accurately as
N increases. This may act as a strength of the proposed method, showing better performance in the case of large
N. In particular, when compared with the gaussian prototypical network using statistical characteristics, it can be seen that the performance gap increases as N increases.
5.2. Multi-PIE Face Recognition
Figure 5 shows some examples of the Multi-PIE dataset that has been created as a benchmark for facial recognition. A total of 337 subjects participated in data collection, and shooting was conducted in four-time sessions. In the shooting, 20 patterns of lighting effects, 15 poses, and 6 types of emotional expression were mobilized, and over 2000 images were collected per subject in a one-time session. We transform the original data to suit the intention of the experiment according to the previous work [
32]. The whole image is cropped so that only the face appears as shown in
Figure 6. It is then converted to a black and white image and then resized to
pixels. The Multi-PIE data have rather simple variations compared to the recent benchmark for face verification. However, considering that this experiment is conducted with the simple convolutional network with the purpose of verifying the effect of the probabilistic similarity, Multi-PIE data are appropriate in the sense that it assorted environmental variations such as illumination, poses, expression, and time sessions.
The modified dataset consists of a total of 184 classes, and we divide them into 122 training classes and 62 test classes for a few-shot classification problem. The training set contains 600 samples per class, and the test set contains 370 samples per class. For each training episode, 45 queries per class are used. We also should note that each class of Multi-PIE data has much more samples with diverse variations than Omniglot data while only five samples per class are used for support. This may cause some difficulties in estimating the covariance of difference vectors.
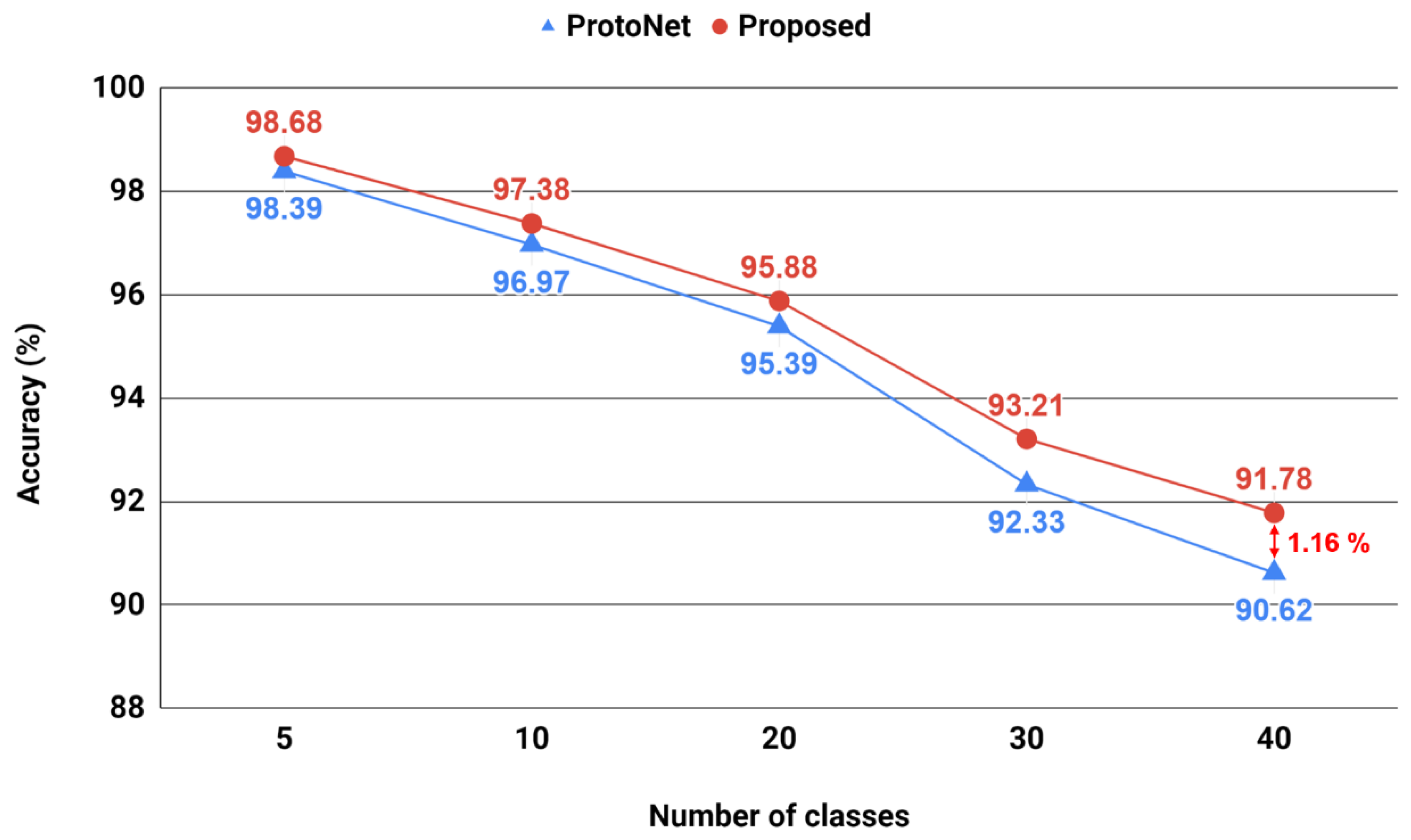
Figure 7 compares the performance of the proposed method using prototypical networks. From the graph, we can see that the proposed method can improve the accuracy by using probabilistic similarity, and the effect of performance improvement appears more clearly as the number of ways increases. This result is consistent with our argument that, as the number of ways increases, the accuracy of the estimation increases and thus more sophisticated classification becomes possible. Recognition performance could be further improved by using a more complex backbone network, but this is somewhat out of the scope of this study. In this experiment, we focused on confirming the effect of probabilistic similarity.
5.3. GTSRB Traffic Sign Recognition
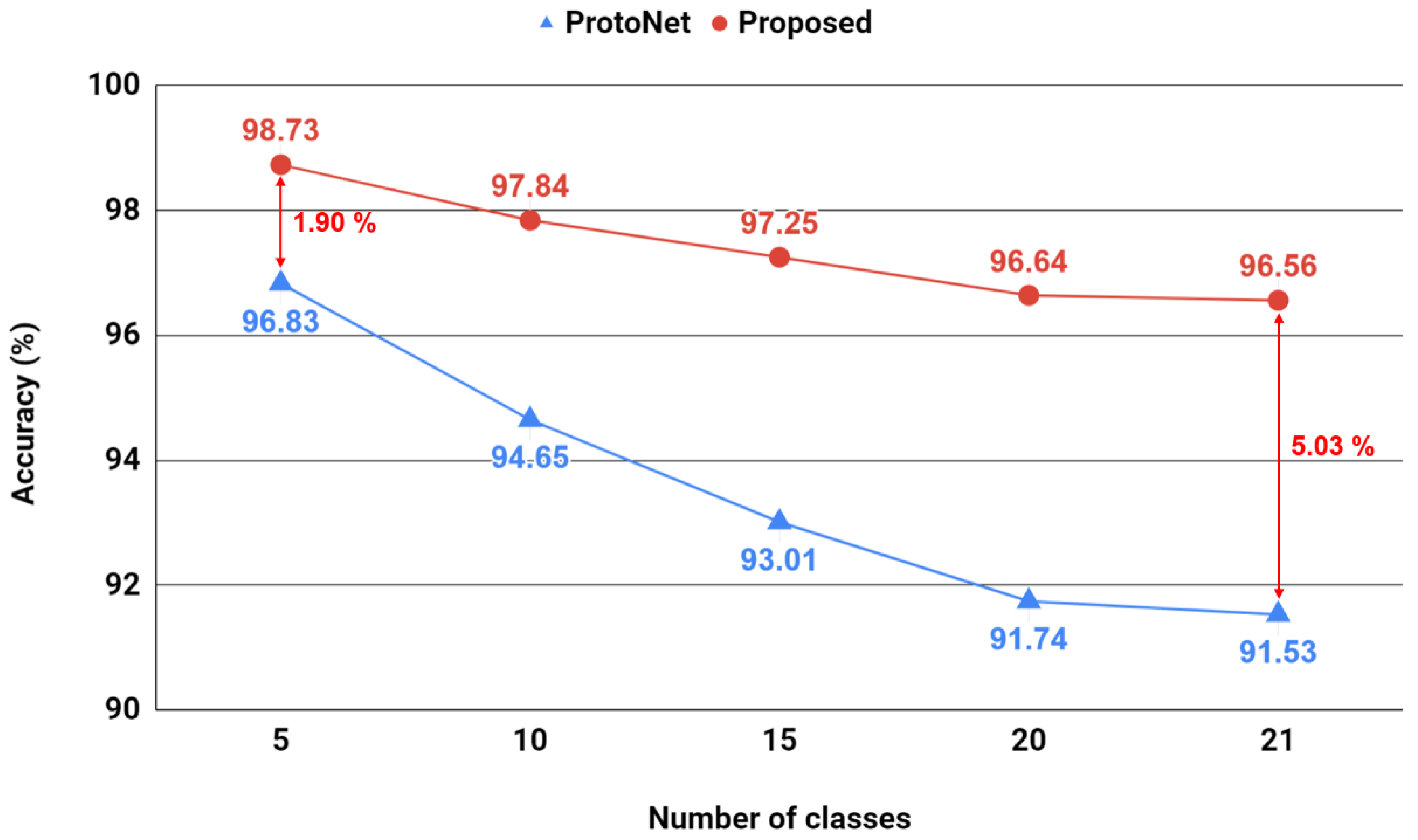
As the third dataset, we chose a more practical one that is likely to be observed in real applications. GTSRB dataset [
34] consists of various types of sign images as shown in
Figure 8. There are 43 types of signs and total 51,839 images, which are color images taken from various angles and lighting conditions with various resolutions. We resize all the images to
pixel size. A total of 43 classes are divided into 22 and 21 classes used for training and testing, respectively. In order to maximize the generality of the embedding network through learning, data augmentation for the training set was performed according to the previous work [
13]. Similar to the case of Omniglot, the number of training classes was increased by rotating the training images. Since it is a color image, the raw data format becomes
and is converted into a 1600-dimensional feature vector through the embedding network. In the learning phase, the embedding network is trained through episodes in the form of 20-way 5-shot. In the test phase, we start at 5-way 5-shot classification, and increase the ways by 5, finally reaching up to 21-way.
Figure 9 shows the change of accuracy according to the number of classes for the proposed method and prototypical network. In these practical data, the effect of probabilistic similarity is observed more clearly. Especially, the superiority of the proposed method becomes clearer as the number of ways increases. The results are consistent with the assumptions about the correlation between the number of ways and the accuracy. In order to verify the efficiency of the proposed method compared with state-of-the-art methods, we also conducted experiments for 1-shot classification according to [
34]. Since the proposed method cannot obtain difference vectors set
with a single support sample, episodic training was carried out with five support samples during the learning phase, and the covariance obtained from the train dataset was used for testing. From
Table 2, we can see that the performance of the proposed method was higher than most conventional models except the VPE model with data augmentation, which is well-designed for the specific GTSRB data.
To summarize the results of the three experiments, when the size of the way is low, the difference in performance from the existing models does not appear much. However, from
Figure 4,
Figure 7 and
Figure 9, we can see a noticeable difference from the original model for the task with a larger number of ways, which has not been investigated in previous works. The larger the way, the more samples can be used to estimate the environmental distribution represented as the covariance matrix. Thanks to this advantage of the proposed method based on intra-class statistics, the performance degradation according to the increase in ways is gentler than that of the conventional model. Although the classification task for a large number of classes has great practical importance, it has rarely been dealt with in conventional works on few-shot classification. This paper has significance in that it presents a method to solve the many-class few-shot classification problem.
6. Conclusions
For the conventional metric-based few-shot classification methods, the main focus is to find a good metric space on which the intra-class variations of unseen classes are minimized. Under the premise that this can be successfully achieved by using a deep embedding network and episodic learning strategy, the classification is performed by a simple distance-based classifier using standard distance such as cosine and Euclidean. In this paper, we suggest a way of improving the distance-based classifier by using a probabilistic similarity, which is derived from a class-independent environmental factor estimated by using intra-class difference vectors. Taking the intra-class difference vector, we can exclude the class-specific components that are hard to estimate with a limited number of samples per class.
Although the probabilistic similarity based on intra-class statistics has already been used in classical pattern recognition studies, the conventional works suggest a premise that a good feature representation for the input data is provided in advance. In the proposed method, however, the feature extraction module (embedding network) is also trained by using loss signals from the classifier with probability similarity. Essentially, the probabilistic similarity assumes that all the classes in a domain have the same intra-class variations, and this is consistent with the prototypical network model, which assumes that it is possible to find a good embedding space where each class has a single prototype and its variations are very limited. Owing to this consistency, the proposed method achieves improved performance in the experiments. However, it is noteworthy that the proposed algorithm has no constraint on the embedding network model and better performance can be expected by using a more complex embedding network. Finally, since the good performance for problems with many classes and the simplicity of implementation can be practical strengths of the proposed method, its practical applications in various fields can also be an interesting follow-up.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}