1. Introduction
Nowadays, user surveys are an important part of online services provided on the web. Service providers ask their customers about the interface usability, quality of service, and other issues. They try to customize their systems to ensure better user experience, also trying to model a consumer behavior, which is important for customer-oriented systems.
Usually, such feedback is requested in the form of a web survey, where the user is invited to spend a few minutes of their time and answer questions about the quality of services, or information about the person, such as age, gender, or place of residence. The same kind of surveys are used for research, which has become especially common during the coronavirus pandemic. Despite certain limitations (information is collected outside the “natural” situation; any information obtained during the survey is not devoid of subjectivity associated with the pressure of social approval; the survey provokes an answer, even if the respondent is not competent in one aspect or another), web surveys are widely used in research and practical tasks. At the same time, web surveys make it possible to obtain information directly from the event participants on a wide range of topics and allow for collecting information from any number of respondents. The problems associated with the use of questionnaires are widely discussed in a number of studies [
1,
2,
3], so we will not specifically dwell on the discussion of the advantages and limitations of this method. The same type of web survey is used in mass psychological research. Some surveys can take up to an hour or even more of a respondent’s time. In these circumstances, researchers need tools that allow them to know whether the respondent is tired, the interface is convenient, the participant is a random clicker, or the answer was filled by a bot (script).
One of the effective tools for solving the problems of the evaluation of user actions and their verification throughout the web survey is the evaluation of user reactions. Technically, user reaction time is the timespan from the start of the web survey screen representing a page with a number of questions to the time when the user clicked the desired answer option. In works [
4,
5,
6] on various experiments with large samples, it was shown that reaction time reflects personal skills of interaction with the user interface. Of course, various factors may influence the change in reaction time, but in general, reactions are maintained the same over the course of a few hours of experimentation.
In studies of web surveys, researchers quite often pay attention to the respondent’s reaction time. The main focus is on the fact that long reaction times indicate the difficulty of the question [
7]. Research in works [
8,
9,
10,
11] is dedicated to web questionnaire design and emphasize that the user reaction time should be noted. Works [
12,
13,
14] consider reaction time to predict that the respondent will abandon a web survey prior to completing it. It is logical to assume that there is a correlation between the time it takes to read a question and the reaction time; besides, a direct comparison of respondents’ reaction times is problematic, because each person has an individual speed [
15]. Individual characteristics of a person, according to studies, influence the reaction time quite strongly, which makes it possible to identify the respondent [
16,
17,
18,
19,
20,
21,
22].
During the preprocessing of experimental data, it is possible to identify random clickers, who run through web surveys without even reading given questions [
23,
24,
25]. Identifying random clickers and excluding them from the dataset is an important task [
26], and machine learning is used to solve this problem quite often [
27]. Machine learning techniques are used to solve many problems in online survey research [
28]. For example, [
29] the following methods are considered to describe various relationships between the result and the input data: logistic regression, advanced tree models (decision trees, random forest and boosting), support vector machine and neural network.
A significant problem, especially in a child survey, is the substitution of the user during the interview. For example, either a companion or an adult replaces the interviewee in the middle of the survey. Such data should be questioned.
Thus, the purpose of this study is to show the possibilities for evaluating data correctness in web surveys. There are three hypotheses:
While participating in a long web survey, respondents get tired, which leads to a slowing down of an individual’s reaction time.
There is a relationship between the response time and the question number, which allows for identification of random clickers and bots.
Change in reaction time is and individual’s characteristic when working with the web interface, which can be used to ensure the respondent’s authenticity.
The work is organized as follows:
Section 2 describes the experimental data;
Section 3 is focused on the research methods and results obtained;
Section 4 discusses the results obtained; finally,
Section 5 concludes the paper.
2. Research Materials
For the study, we used a dataset generated from a web survey that took around 45 min of an average respondent’s time. The survey involved 20,000 students to answer the web survey and generate the dataset.
There were two types of questions: standard survey questions and questions about attitudes toward various subjects and processes.
The research was carried out as follows: respondents were provided with a survey web-interface where data were collected on the local device to exclude the influence of networks [
30]. For fairness, we use the response time of the first question (interface element) on each page of the web survey. Obviously, open-ended questions require significantly more time to answer; therefore, such questions were excluded from the data.
For Hypothesis #2, a bot program was developed. Data generation by the bot was performed using the same web platform as that used by real respondents. The program was developed and designed to mimic the actions of a real user when filling out the questionnaire in a web browser. Thus, the interaction of a person and the program with the web platform had no differences.
The following components were used to develop the program that simulates respondent behavior:
Node.js platform and JavaScript language as the basis for the script development.
Selenium WebDriver as the system for automating actions in the browser.
Chromedriver, which provides Selenium WebDriver interaction with the Google Chrome browser.
The program fills in the web survey questionnaire from beginning to end with random data, and there are delays between the actions taken.
Different researchers [
31,
32,
33,
34] defined and filtered random clickers and their thoughtless responses in different ways. In previous studies of web surveys [
4,
5,
30], we gained experience in detecting random clickers. In this study, we simulate the behavior of random clickers based on the analysis of data from previous surveys when working with the given web interface.
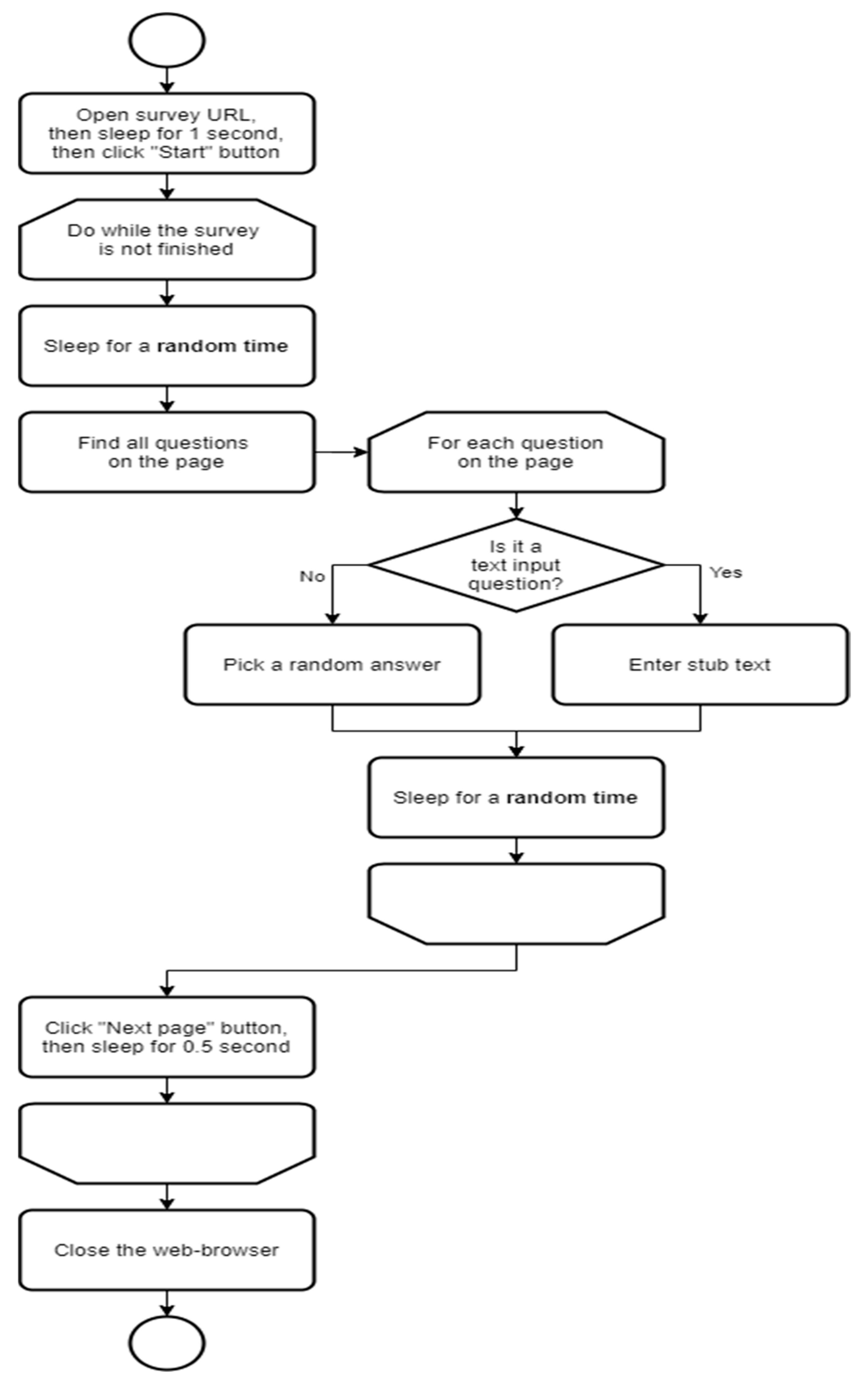
To create variability in the delays between actions in the browser, we used beta distributed pseudorandom numbers with the following parameters: alpha = 1.5; beta = 5. In the diagram shown in
Figure 1, the lag time between a number of actions is shown as “random time”. The following formula was used for our study:
where T is time in milliseconds.
The algorithm of the program shown in
Figure 1 consists of the following steps. The program starts the web-browser and goes to the specified page, then waits for 1 s before pressing the “Start” button. After that, the program presses the “Start” button and proceeds to fill out the questionnaire. The cycle checks the completion of the questionnaire and, if the questionnaire is not filled in completely, the program waits for a random time (as if the respondent has opened the questionnaire page and familiarized themselves with the arrangement of interface elements on the page). After that, the program identifies all the questions on the page and proceeds to their sequential completion. For each question, the following sequence is repeated: if it is a multiple-choice question, the program selects one random option, and if it is an open-ended question, the program enters a preset text, then the program waits for a random time (assuming the respondent needs some time to move to the next interface item). When all questions on the page have been answered, the program presses the “Next page” button and waits for 0.5 s. When the web survey questionnaire is completely filled out, the program closes the web-browser window.
To test Hypothesis #3 about the possibility of ensuring a user’s authenticity and the development of the user verification tool for assessing the possible replacement of the respondent during the course of the survey, another data sample was formed. This sample consists of the mixed data of real users. That is, a third of the user’s survey answers are taken and two-thirds of another, random user’s answers are added to it.
3. Research Methods and Results
3.1. Regression Analysis
To test Hypothesis #1, a diagram of the relationship between reaction time and question number was plotted. Questions with an open-ended answer are excluded from the diagram.
The median reaction time is shown in
Figure 2.
The figure demonstrates that Hypothesis #1 about the user’s reaction getting slow over time is not confirmed for the large sample. This is explained by the fact that the respondents get used to the web interface and do not spend time searching for interface elements. Moreover, the reaction time decrease may be due to the wish to finish the survey as soon as possible.
If we consider the individual trajectories presented in
Figure 3, there are tendencies for a decrease in reaction time. There are also cases when the respondent was distracted by external circumstances, which can be seen in
Figure 4 as noticeable outliers.
Let us add a regression line for the median values of reaction times. To make the data comparable, we will use only the reaction time related to the first question on each page, since the survey offers various number of questions per page. Open-ended questions are excluded from the dataset in order to keep an objective picture.
Thus, the built models show that the reaction time decreases on average.
3.2. Random Clicker and Bot Detection
To test Hypothesis #2, a neural network model was built.
Therefore, the real data of 16,350 of 20,000 entries (containing no null values) were labeled as Class 1 and the random clicker data of 688 entries were generated automatically and labeled as Class 2. A total of 17,038 entries were randomly split into the training set of 6815 entries and the test set of 10,223 entries. The multi-layer perceptron classifier (MLPClassifier) from scikit-learn 1.0 was then fitted on the training set with the following parameters: solver: ‘adam’, random_state: 1, max_iter = 3000, activation = ’relu’, alpha = 0.0001, learning_rate = ‘constant’.
We then searched for the optimal number of neurons in the hidden layer of the perceptron (
Figure 7 and
Figure 8) and identified 30 as the best parameter.
The classification report with a total of 30 neurons is given in
Table 1. The confusion matrix is given in
Figure 9.
Therefore, the MLPClassifier was able to distinguish excellently between the clickers and original data. However, there were 40 entries mistakenly labeled as random clickers (
Figure 9). Manual analysis of those records showed that they were abnormal in terms of the speed change of a user’s reaction from very fast (1–2 s) to more than a minute in consecutive questions during the survey. In a real practice, such a suspicious subset of records, identified by the classifier, could be analyzed by hand by the expert.
3.3. Verification of the Respondent’s Identity Authenticity
To test Hypothesis #3, a neural network model was built.
In order to model the situation “Bob started filling out the questionnaire then Carol continued and completed it”, we randomly divided the normalized dataset of user’s reaction times into two equal parts: Part A and B. Therefore, Part A contained 8175 original entries of users’ reaction times to 26 consecutive questions from the questionnaire. Meanwhile, Part B’s dataframe of another 8175 original entries was split horizontally, leaving reaction times to the first 10 questions in the left part and the reaction times to the last 16 questions in the right part. Then, the rows of the right part of the dataframe were randomly permutated and joined again with the left part of Part B. Then, we assigned Class 1 (“good”) for all of the entries of Part A and Class 2 (“bad”) for all of the entries of modified Part B. So, Class 1 (“good”) corresponded to the situation when Bob started and completed the survey himself, and Class 2 (“bad”) corresponded to the situation when Carol intervened after Question 10 and finished the survey.
We joined Part A and Part B dataframes vertically and split the resulting dataframe randomly into the training and test set. The training set contained 6540 entries and the test set contained 9810 entries. MLPClassifier was then fitted on the training set with the following parameters: solver: ‘adam’, random_state: 1, max_iter = 3000, activation = ’relu’, alpha = 0.0001, learning_rate = ’constant’. To measure the performance of the classifier on the test set, we applied the accuracy measure, as there was an equal number of Class 1 and Class 2 representatives in the dataset and the accuracy measure was meaningful.
We then searched for the optimal number of neurons in the hidden layer of the perceptron (
Figure 10 and
Figure 11) and identified 60 as the best parameter.
The classification report with a total of 60 neurons is given in
Table 2. The confusion matrix is given in
Figure 12.
Therefore, the MLPClassifier was able to distinguish between the original and permutated data quite accurately (0.73), providing the opportunity to identify the situation when the survey was completed by another person.
As the cardinality of parametric set of MLPClassifier extends 1000 and the training process takes some significant time with each tuple of parameters, different strategies can be applied to reduce the brute force search. The evolutionary algorithms could be applied as a promising solution for the directed search of parameters.
4. Discussion
The web survey was conducted in the Russian Federation as a part of psychological study. The dataset was generated from the responses of 20,000 students to simple survey questions. For this study, the data were preprocessed as follows. Empty records and questions that took an abnormally long time to answer were excluded. To preserve comparability, only the response time of the first question on each page was taken for further analysis.
Hypothesis #1 was not confirmed. Contrary to the expectations, in the long survey, respondents accelerated over time. This is likely the respondents getting accustomed to the web interface and them stopping spending time searching for interface elements. Another possible explanation is that the reaction time decrease may be due to the wish to finish the survey as soon as possible.
For Hypothesis #2 an additional dataset representing the random clickers was generated. It consists of 688 survey results filled in by an automation script. To identify random clickers, MLPClassifier was trained, and it was able to do so with high accuracy (0.99). There were 40 entries mistakenly labeled as random clickers. These records appeared to be abnormal in terms of the speed change of a user’s reaction from very fast (1–2 s) to more than a minute in consecutive questions during the survey. It can be suggested that the approach is suitable for identification of random clickers and bots.
For Hypothesis #3, the initial dataset was split into two dataframes (Part A contained 8175 original entries of users’ reactions to 26 consecutive questions from the questionnaire; meanwhile, Part B’s dataframe of another 8175 entries was partly mixed with another respondent’s answers). To find records with violated authenticity, MLPClassifier was trained, and it was able to distinguish between the original and permutated data quite accurately (0.73).
5. Conclusions
We have obtained new data that can be widely used to verify the results of web surveys.
The research was conducted using a dataset of 20,000 records containing responses to a web survey, which took an average of 45 min to complete. Respondents with different devices and different operating systems participated in the survey; however, the technology used to collect the reaction times on client devices made it possible to compensate for the difference in gadgets.
It is shown that it is sufficient to consider the reaction time for user verification during the entire web survey. For the reliability of the experiment, we considered the reaction time obtained only while answering the first question on each web survey page. For the present study, the reaction time is the sum of the time in which the respondent read the question and choose the answer option from the suggested ones. We have excluded open-ended questions from consideration. The data from a long web survey on a large sample gave interesting results: respondents do not get tired; rather, they begin to react faster, that is, they get used to the interface elements and try to finish the survey faster. This trend is observed for both individual users and for the median model.
Based on the data, we built a neural network model that determines the records in which the respondent was changed and a neural network model that identifies if the respondent acted as a random clicker. As a possible direction for future work, we consider an evaluation of different probability distributions and parameters, which can lead to more accurate random clicker detection.
The amount of data allows us to conclude that the identified dependencies are widely applicable to verify the user during the participation in the web surveys.
Author Contributions
Conceptualization, E.N. and S.M.; methodology, E.N.; software, D.I. and A.G.; validation, N.G., A.G. and S.M.; formal analysis, A.G.; data curation, E.N., A.G., D.I. and N.G.; writing—original draft preparation, E.N., A.G., D.I. and N.G.; writing—review and editing, S.M.; visualization, D.I. and A.G.; supervision, E.N.; project administration, S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Russian Science Foundation, grant number 17-78-30028.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Not Applicable, the study does not report any data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Saris, W.E.; Gallhofer, I.N. Design, Evaluation and Analysis of Questionnaires for Survey Research, 2nd ed.; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]
- Taherdoost, H. How to Design and Create an Effective Survey/Questionnaire; A Step by Step Guide. IJARM 2016, 5, 37–41. [Google Scholar]
- Mirri, S.; Roccetti, M.; Salomoni, P. Collaborative design of software applications: The role of users. Hum. Cent. Comput. Inf. Sci. 2018, 8, 6. [Google Scholar] [CrossRef] [Green Version]
- Magomedov, S.; Gusev, A.; Ilin, D.; Nikulchev, E. Users’ Reaction Time for Improvement of Security and Access Control in Web Services. Appl. Sci. 2021, 11, 2561. [Google Scholar] [CrossRef]
- Magomedov, S.; Ilin, D.; Silaeva, A.; Nikulchev, E. Dataset of user reactions when filling out web questionnaires. Data 2020, 5, 108. [Google Scholar] [CrossRef]
- Magomedov, S.G.; Kolyasnikov, P.V.; Nikulchev, E.V. Development of technology for controlling access to digital portals and platforms based on estimates of user reaction time built into the interface. Russ. Technol. J. 2020, 8, 34–46. [Google Scholar] [CrossRef]
- Liu, M.; Wronski, L. Trap questions in online surveys: Results from three web survey experiments. Int. J. Mark. Res. 2018, 60, 32–49. [Google Scholar] [CrossRef] [Green Version]
- Montabon, F.; Daugherty, P.J.; Chen, H. Setting standards for single respondent survey design. J. Supply Chain. Manag. 2018, 54, 35–41. [Google Scholar] [CrossRef]
- Krosnick, J.A. Questionnaire design. In The Palgrave Handbook of Survey Research; Palgrave Macmillan: Cham, Switzerland, 2018; pp. 439–455. [Google Scholar]
- Tangmanee, C.; Niruttinanon, P. Web survey’s completion rates: Effects of forced responses, question display styles, and subjects’ attitude. Int. J. Res. Bus. Soc. Sci. 2019, 8, 20–29. [Google Scholar] [CrossRef] [Green Version]
- Basok, B.M.; Rozhanskaya, A.N.; Frenkel, S.L. On web-applications usability testing. Russ. Technol. J. 2019, 7, 9–24. [Google Scholar] [CrossRef]
- Mittereder, F.; West, B.T. A dynamic survival modeling approach to the prediction of web survey breakoff. J. Surv. Stat. Methodol. 2021, smab015. [Google Scholar] [CrossRef]
- Mittereder, F.K. Predicting and Preventing Breakoff in Web Surveys. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2019. [Google Scholar]
- Cheng, A.; Zamarro, G.; Orriens, B. Personality as a predictor of unit nonresponse in an internet panel. Sociol. Methods Res. 2020, 49, 672–698. [Google Scholar] [CrossRef]
- Schmidt, K.; Gummer, T.; Roßmann, J. Effects of respondent and survey characteristics on the response quality of an open-ended attitude question in Web surveys. Methods Data Anal. 2020, 14, 32. [Google Scholar]
- Mastrotto, A.; Nelson, A.; Sharma, D.; Muca, E.; Liapchin, K.; Losada, L.; Bansal, M. User Activity Anomaly Detection by Mouse Movements in Web Surveys. 2020. Available online: http://ceur-ws.org/Vol-2790/paper07.pdf (accessed on 3 November 2021).
- Mastrotto, A.; Nelson, A.; Sharma, D.; Muca, E.; Liapchin, K.; Losada, L.; Bansal, M.; Samarev, R.S. Validating psychometric survey responses. arXiv 2020, arXiv:2006.14054. [Google Scholar]
- Nagatomo, M.; Kita, Y.; Aburada, K.; Okazaki, N.; Park, M. Implementation and user testing of personal authentication having shoulder surfing resistance with mouse operations. IEICE Commun. Express 2018, 2017XBL0170. [Google Scholar] [CrossRef] [Green Version]
- Traore, I.; Alshahrani, M.; Obaidat, M.S. State of the art and perspectives on traditional and emerging biometrics: A survey. Secur. Priv. 2018, 1, e44. [Google Scholar] [CrossRef] [Green Version]
- Horwitz, R.; Brockhaus, S.; Henninger, F.; Kieslich, P.J.; Schierholz, M.; Keusch, F.; Kreuter, F. Learning from mouse movements: Improving questionnaires and respondents’ user experience through passive data collection. In Advances in Questionnaire Design, Development, Evaluation and Testing; Wiley: Hoboken, NJ, USA, 2020; pp. 403–425. [Google Scholar] [CrossRef]
- Shi, Y.; Feng, J.; Luo, X. Improving surveys with paradata: Analytic uses of response time. China Popul. Dev. Stud. 2018, 2, 204–223. [Google Scholar] [CrossRef] [Green Version]
- Bridger, D. Response latency measures in questionnaires: A brief overview. Appl. Mark. Anal. 2020, 6, 111–118. [Google Scholar]
- Varol, O.; Ferrara, E.; Davis, C.; Menczer, F.; Flammini, A. Online human-bot interactions: Detection, estimation, and characterization. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11. [Google Scholar]
- Yang, K.C.; Varol, O.; Hui, P.M.; Menczer, F. Scalable and generalizable social bot detection through data selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1096–1103. [Google Scholar]
- Efthimion, P.G.; Payne, S.; Proferes, N. Supervised machine learning bot detection techniques to identify social twitter bots. SMU Data Sci. Rev. 2018, 1, 5. [Google Scholar]
- Kayalvizhi, R.; Khattar, K.; Mishra, P. A Survey on online click fraud execution and analysis. Int. J. Appl. Eng. Res. 2018, 13, 13812–13816. [Google Scholar]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef] [Green Version]
- Kern, C.; Klausch, T.; Kreuter, F. Tree-based machine learning methods for survey research. Surv Res Methods 2019, 13, 73–93. [Google Scholar] [PubMed]
- Fernández-Fontelo, A.; Kieslich, P.J.; Henninger, F.; Kreuter, F.; Greven, S. Predicting respondent difficulty in web surveys: A machine-learning approach based on mouse movement features. arXiv 2020, arXiv:2011.06916. [Google Scholar]
- Nikulchev, E.; Ilin, D.; Silaeva, A.; Kolyasnikov, P.; Belov, V.; Runtov, A.; Pushkin, P.; Laptev, N.; Alexeenko, A.; Magomedov, S.; et al. Digital Psychological Platform for Mass Web-Surveys. Data 2020, 5, 95. [Google Scholar] [CrossRef]
- Kim, S.-H.; Yun, H.; Yi, J.S. How to filter out random clickers in a crowdsourcing-based study? In Proceedings of the 2012 BELIV Workshop: Beyond Time and Errors—Novel Evaluation Methods for Visualization, BELIV ’12, Seattle, WA, USA, 14–15 October 2012; ACM: New York, NY, USA, 2012; pp. 1–7. [Google Scholar]
- Sun, P.; Stolee, K.T. Exploring crowd consistency in a mechanical turk survey. In Proceedings of the 3rd International Workshop on CrowdSourcing in Software Engineering, Austin, TX, USA, 16 May 2016; ACM: New York, NY, USA, 2016; pp. 8–14. [Google Scholar]
- Kwon, B.C.; Lee, B. A comparative evaluation on online learning approaches using parallel coordinate visualization. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; ACM: New York, NY, USA, 2016; pp. 993–997. [Google Scholar]
- Kim, S.H. Understanding the Role of Visualizations on Decision Making: A Study on Working Memory. Informatics 2020, 7, 53. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}