
Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods

 , ,
, ,
Abstract
:1. Introduction
2. Proposed Method
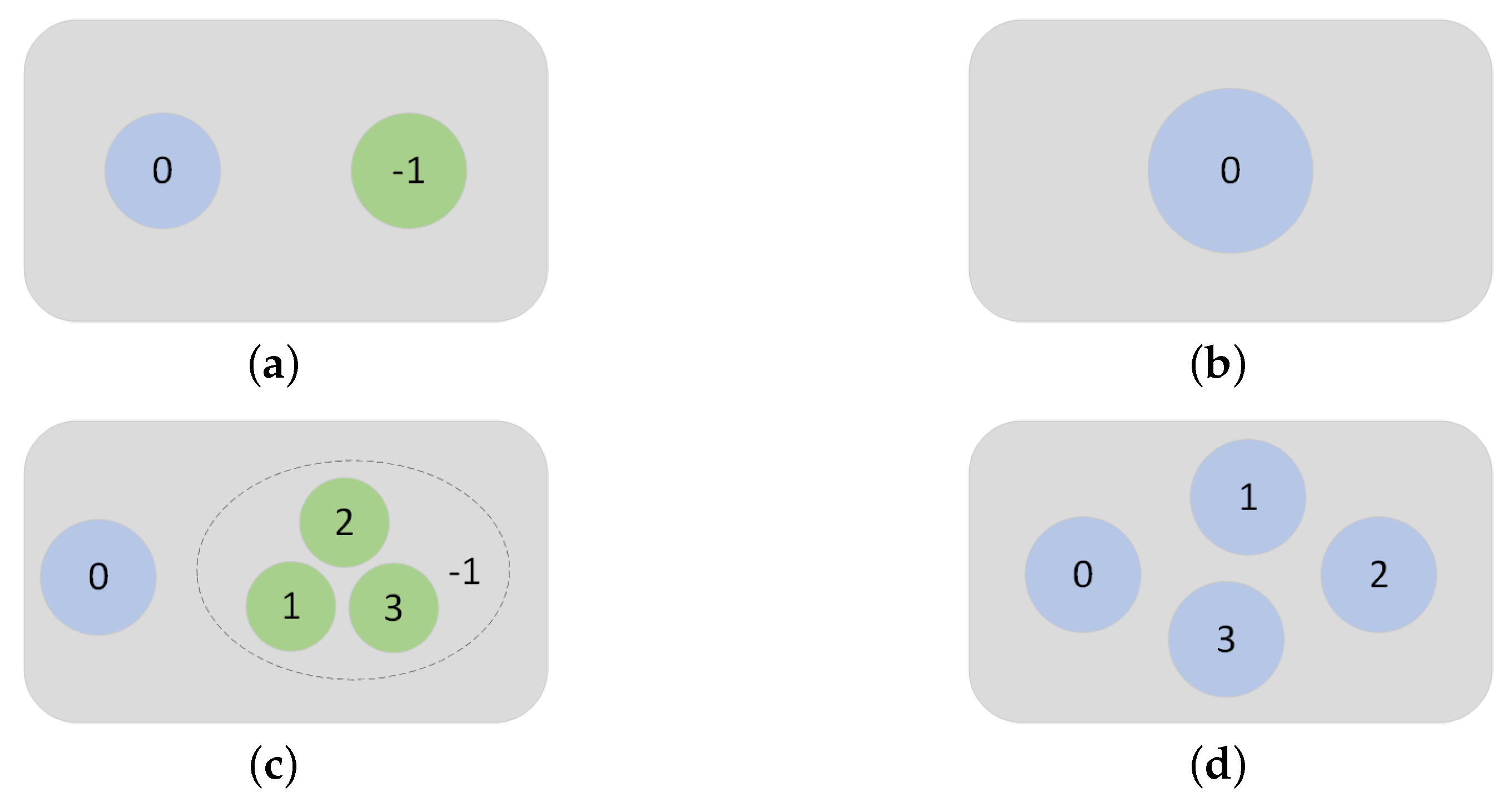
2.1. Outlier Classifier for Binary Classification
2.1.1. Attention-Based Audio Classification Network
2.1.2. Auxiliary Classifiers for Anomaly Detection
2.2. ID Classifier for Multiple Classification
2.2.1. MobileNet-Based Audio Classification Network
2.2.2. Anomaly Detection in Multiple Ways
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Audio Surveillance of Roads: A System for Detecting Anomalous Sounds. IEEE Trans. ITS 2016, 17, 279–288. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Probabilistic Novelty Detection for Acoustic Surveillance Under Real-World Conditions. IEEE Trans. Multimed. 2011, 13, 713–719. [Google Scholar] [CrossRef]
- Koizumi, Y.; Saito, S.; Uematsu, H.; Harada, N. Optimizing Acoustic Feature Extractor for Anomalous Sound Detection Based on NeymanPearson Lemma. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Zheng, X.; Zhang, C.; Chen, P.; Zhao, K.; Jia, W. A CRNN System for Sound Event Detection Based on Gastrointestinal Sound Dataset Collected by Wearable Auscultation Devices. IEEE Access 2020, 8, 157892–157905. [Google Scholar] [CrossRef]
- Ick, C.; Mcfee, B. Sound Event Detection in Urban Audio With Single and Multi-Rate PCEN. arXiv 2021, arXiv:2102.03468. [Google Scholar]
- Koizumi, Y.; Kawaguchi, Y.; Imoto, K.; Nakamura, T.; Nikaido, Y.; Tanabe, R.; Purohit, H.; Suefusa, K.; Endo, T.; Yasuda, M.; et al. Description and discussion on DCASE2020 challenge task2: Unsupervised anomalous sound detection for machine condition monitoring. arXiv 2020, arXiv:2006.05822. [Google Scholar]
- Koizumi, Y.; Saito, S.; Uematsu, H.; Harada, N.; Imoto, K. ToyADMOS: A dataset of miniature-machine operating sounds for anomalous sound detection. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 308–312. [Google Scholar]
- Purohit, H.; Tanabe, R.; Ichige, T.; Endo, T.; Nikaido, Y.; Suefusa, K.; Kawaguchi, Y. MIMII Dataset: Sound dataset for malfunctioning industrial machine investigation and inspection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), Tokyo, Japan, 20 September 2019; pp. 209–213. [Google Scholar]
- Hayashi, T.; Toshimura, T.; Adachi, Y. Conformer-Based ID-Aware Autoencoder for Unsupervised Anomalous Sound Detection; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Nagoya, Japan, 2020. [Google Scholar]
- Wilkinghoff, H. Anomalous Sound Detection with Look, Listen, and Learn Embeddings; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Munich, Germany, 2020. [Google Scholar]
- Durkota, K.; Linda, M.; Ludvik, M.; Tozicka, J. Euron-Net: Siamese Network for Anomaly Detection; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Prague, Czech Republic, 2020. [Google Scholar]
- Haunschmid, V.; Praher, P. Anomalous Sound Detection with Masked Autoregressive Flows and Machine Type Dependent Postprocessing; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events 2020: Linz, Austria, 2020. [Google Scholar]
- Giri, R.; Tenneti, S.V.; Cheng, F.; Helwani, K.; Isik, U.; Krishnaswamy, A. Unsupervised Anomalous sound Detection Using Self-Supervised Classification and Group Masked Autoencoder for Density Estimation; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Palo Alto, CA, USA, 2020. [Google Scholar]
- Daniluk, P.; Goździewski, M.; Kapka, S.; Kośmider, M. Ensemble of Auto-Encoder Based and WaveNet Like Systems for Unsupervised Anomaly Detection; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Warsaw, Poland, 2020. [Google Scholar]
- Primus, P. Reframing Unsupervised Machine Condition Monitoring as a Supervised Classification Task with Outlier Exposed Classifiers; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Linz, Austria, 2020. [Google Scholar]
- Inoue, T.; Vinayavekhin, P.; Morikuni, S.; Wang, S.; Trong, T.H.; Wood, D.; Tatsubori, M.; Tachibana, R. Detection of Anomalous Sounds for Machine Condition Monitoring Using Classification Confidence; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Tokyo, Japan, 2020. [Google Scholar]
- Zhou, Q. ArcFace Based Sound MobileNets for DCASE 2020 Task 2; Tech. Report in DCASE2020 Challenge Task 2; Detection and Classification of Acoustic Scenes and Events: Shanghai, China, 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for accurate realTime face verification on mobile devices. In Proceedings of the 13th Chinese Conference, CCBR 2018, Urumqi, China, 11–12 August 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the International Conference on Computer Vision 2019 (ICCV2019), Seoul, Koren, 27 October–2 November 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.W.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference, New York, NY, USA, 6–12 August 2015; pp. 18–25. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Koutini, K.; Eghbal-zadeh, H.; Widmer, G. Receptivefield-regularized CNN variants for acoustic scene classification. arXiv 2019, arXiv:1909.02859. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operator | Exp Size | #out | SE | NL | s |
|---|---|---|---|---|---|
| conv3 × 3 | - | 32 | - | HS | 2 |
| bneck3 × 3 | 64 | 32 | - | RE | 1 |
| bneck3 × 3 | 64 | 32 | - | RE | 2 |
| bneck3 × 3 | 64 | 32 | - | RE | 1 |
| bneck3 × 3 | 64 | 32 | ✓ | RE | 2 |
| bneck3 × 3 | 64 | 32 | ✓ | RE | 1 |
| bneck3 × 3 | 128 | 64 | ✓ | RE | 1 |
| bneck3 × 3 | 128 | 64 | - | HS | 2 |
| bneck3 × 3 | 128 | 64 | - | HS | 1 |
| bneck3 × 3 | 128 | 64 | - | HS | 1 |
| bneck3 × 3 | 128 | 64 | - | HS | 1 |
| bneck3 × 3 | 256 | 128 | ✓ | HS | 1 |
| bneck3 × 3 | 256 | 128 | ✓ | HS | 1 |
| bneck3 × 3 | 256 | 128 | ✓ | HS | 1 |
| bneck3 × 3 | 256 | 128 | ✓ | HS | 2 |
| bneck3 × 3 | 256 | 128 | ✓ | HS | 1 |
| conv1 × 1 | - | 512 | - | HS | 1 |
| GDConv32 × 1 | - | 512 | - | - | 1 |
| conv1 × 1 | - | 128 | - | - | 1 |
| Fan | Pump | Slider | Valve | Toy-Car | Toy-Conveyor | Average | |
|---|---|---|---|---|---|---|---|
| AUC(pAUC) | AUC(pAUC) | AUC(pAUC) | AUC(pAUC) | AUC(pAUC) | AUC(pAUC) | AUC(pAUC) | |
| Baseline [6] | 82.80(65.80) | 82.37(64.11) | 79.41(58.87) | 57.37(50.79) | 80.14(66.17) | 85.36(66.95) | 77.91(62.12) |
| Hayashi [9] | 92.72(80.52) | 90.63(73.61) | 95.68(81.48) | 97.43(89.69) | 91.75(83.97) | 92.10(76.76) | 93.39(81.01) |
| Wilkinghoff [10] | 93.75(80.68) | 93.19(81.10) | 95.71(79.45) | 94.87(83.58) | 94.06(86.80) | 84.22(69.12) | 92.63(80.12) |
| Durkota [11] | 90.74(83.38) | 88.70(75.97) | 96.18(87.49) | 97.48(92.46) | 94.32(89.01) | 64.38(53.79) | 88.63(80.35) |
| Haunschmid [12] | 91.48(74.32) | 92.30(72.14) | 89.74(76.43) | 81.99(69.82) | 81.50(67.00) | 88.01(70.52) | 87.50(71.71) |
| Giri [13] | 94.54(84.30) | 93.65(81.73) | 97.63(89.73) | 96.13(90.89) | 94.34(89.73) | 91.19(73.34) | 94.58(84.95) |
| Daniluk [14] | 99.13(96.40) | 95.07(90.23) | 98.18(91.98) | 90.97(77.41) | 93.52(83.87) | 90.51(77.56) | 94.56(86.24) |
| Primus [15] | 96.84(95.24) | 97.76(92.24) | 97.29(88.74) | 90.15(86.65) | 86.37(83.83) | 88.28(79.15) | 92.78(87.64) |
| Inoue [16] | 98.84(94.89) | 94.37(88.27) | 95.68(83.09) | 97.82(94.93) | 93.16(87.69) | 87.41(72.03) | 94.55(86.82) |
| Zhou [17] | 99.79(98.92) | 95.79(92.60) | 99.84(99.17) | 91.83(84.74) | 95.60(91.30) | 73.61(64.06) | 92.74(88.47) |
| Outlier classifier | 97.53(95.64) | 97.34(91.54) | 99.04(95.14) | 92.00(89.05) | 88.11(86.53) | 89.80(80.61) | 93.97(89.75) |
| ID classifier | 99.94(99.80) | 95.01(90.89) | 99.09(95.91) | 95.82(93.58) | 91.33(86.57) | 71.32(60.09) | 92.09(87.81) |
| ensemble | 99.96(99.84) | 97.35(91.58) | 99.97(99.83) | 95.82(93.58) | 92.02(88.50) | 89.80(80.61) | 95.82(92.32) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zheng, Y.; Zhang, Y.; Xie, Y.; Xu, S.; Hu, Y.; He, L. Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods. Appl. Sci. 2021, 11, 11128. https://doi.org/10.3390/app112311128
Wang Y, Zheng Y, Zhang Y, Xie Y, Xu S, Hu Y, He L. Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods. Applied Sciences. 2021; 11(23):11128. https://doi.org/10.3390/app112311128
Chicago/Turabian StyleWang, Yaoguang, Yaohao Zheng, Yunxiang Zhang, Yongsheng Xie, Sen Xu, Ying Hu, and Liang He. 2021. "Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods" Applied Sciences 11, no. 23: 11128. https://doi.org/10.3390/app112311128
APA StyleWang, Y., Zheng, Y., Zhang, Y., Xie, Y., Xu, S., Hu, Y., & He, L. (2021). Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods. Applied Sciences, 11(23), 11128. https://doi.org/10.3390/app112311128