
Research on Alarm Reduction of Intrusion Detection System Based on Clustering and Whale Optimization Algorithm


Abstract
:1. Introduction
- To deal with the alarm reduction problem, we propose a coding and decoding scheme that applies WOA to hierarchical clustering and propose a new fitness function. We apply crossover and mutation operators to WOA to enhance the search capability of the algorithm.
- To solve the problems of premature convergence of clustering and the tendency of clustering algorithm to fall into the local optimum, we propose a local version of WOA applied to hierarchical clustering, namely WOAHC-L. On the basis of WOAHC-L, we further propose a global version of WOAHC to resolve the problem of the high overlap degree of the cluster center, namely WOAHC-G.
- We conducted experiments on UNSW-NB15 data set to explore the performance of WOAHC in the search of cluster centers, time consuming, clustering results, accuracy and other indicators. Compared with the alarm hierarchical clustering algorithm in the past, the proposed framework can obtain higher quality alarm clustering within the allowed time range and solves the problem of alarm redundancy well.
2. Literature Review
3. Theoretical Background
3.1. Alarm Reduction Algorithm Based on Hierarchical Clustering
3.1.1. Generalization Hierarchies
3.1.2. Distance Definition
3.1.3. Definition of the Clustering Problem
| Algorithm 1 Julisch’s alarm hierarchical clustering algorithm |
| Input: a set of events; a threshold T; a set of trees of all the attributes considerer; Output: an alarm/ /an abstract event 1: select an arbitrary alarm A, each member of which is a leaf in a tree 2: while the number of events A covers is less than T do 3: select an arbitrary member of A, and replace the member with its direct parent 4: end while |
3.2. Whale Optimization Algorithm
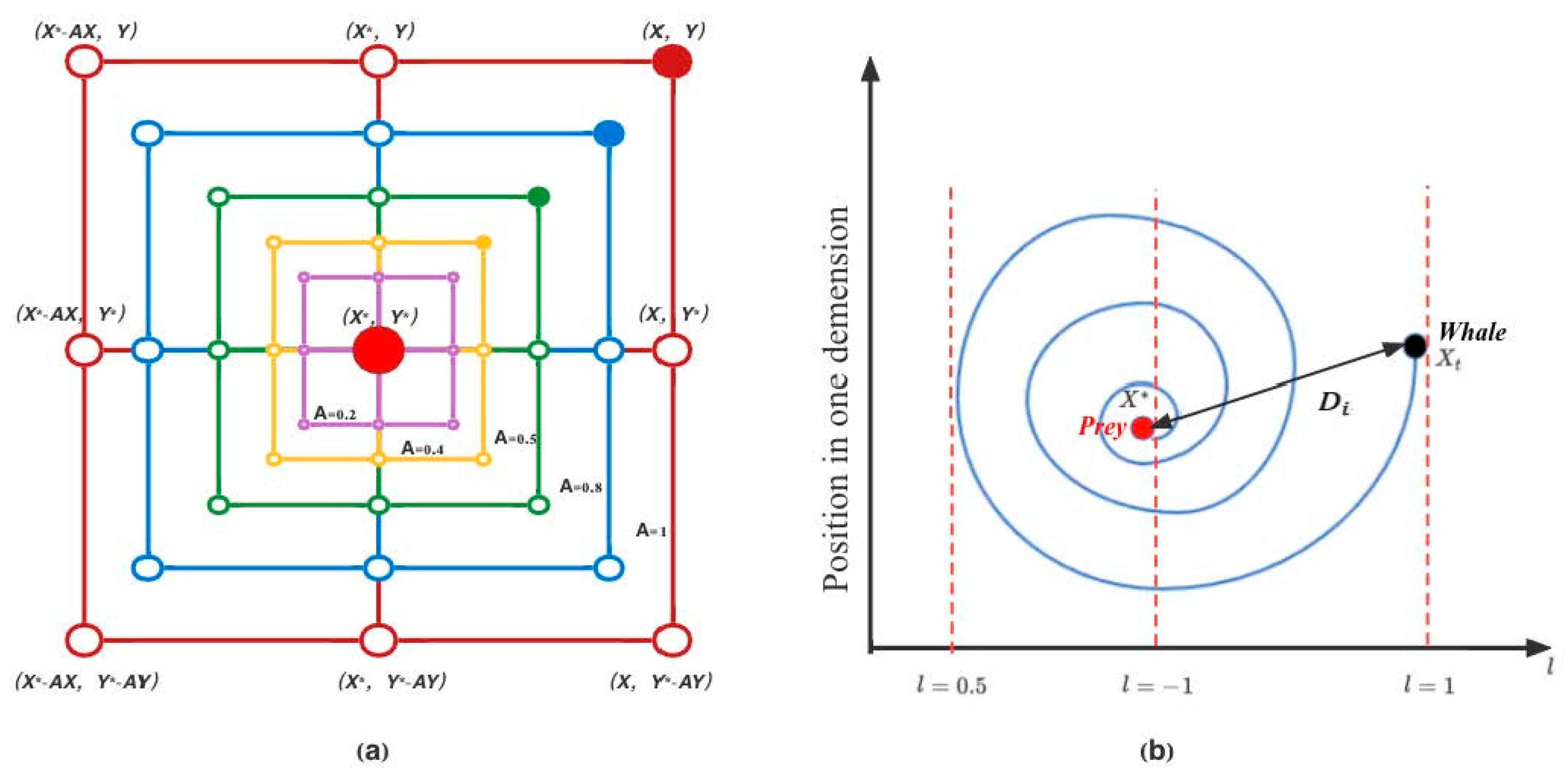
3.2.1. Exploitation Phase (Encircling Prey/Bubble-Net Attacking Method)
3.2.2. Exploration Phase (Search for Prey)
4. Proposed Method
4.1. Encoding and Decoding
4.2. Fitness Function
4.3. Crossover and Mutation Operator
4.4. WOA-Based Alarm Hierarchical Clustering Process
| Algorithm 2 WOA for alarm hierarchical clustering (local version) |
| Input: threshold, N, maxIteration, mutation rate, t = 0, k = 0 Output: alarm_center[], alarms after clustering 1: while the number of current alarms is bigger than threshold do 2: Randomly generate initial population Xi (i = 1, 2, …, N) 3: Calculate the fitness value of each solution 4: Get the best Xi that has the largest fitness value, mark it as X* 5: while t < MaxIterationr do 6: for population Xi(i = 1, 2, …, N) do 7: Use Equations (3)–(5) to update a,A,C 8: Generate values for random numbers 1 and P 9: if p < 0.5 then 10: if |A| < 1 then 11: Use Equations (1) and (2) to update the position of Xi 12: Apply mutation operation on X* (best solution) given mutation rate (r) to get Xmut 13: Perform crossover operation between Xmut and Xi 14: Set the new position of Xi to the output of crossover operation 15: else if |A| ≥ 1 then 16: Select a random search agent (Xrand) 17: Use Equations (8) and (9) to update the position of Xi 18: Apply mutation operation on Xrand given mutation rate(r) to get Xmut 19: Perform crossover operation between Xmut and Xrand 20: Set the new position of Xi to the output of crossover operation 21: end if 22: else if p ≥ 0.5 then 23: Use Equation (6) to update the position of the current solution Xi 24: Apply mutation operation on X* (best solution) given mutation rate (r) to get Xmut 25: Perform crossover operation between Xmut and Xi 26: Set the new Position of Xi to the output of crossover operation 27: end if 28: end for 29: Calculate the ftness value of each solution, check if any solution goes beyond the search space 30: If there is a better solution Xi update Xi as X* 31: t = t + 1 32: end while 33: Mark X* as cluster k 34: Put alarms which belong to the cluster k to the alarm_center[k] 35: Remove alarms from the original alarms set 36: k = k + 1 37: end while |
| Algorithm 3 WOA for alarm hierarchical clustering (global version) |
| Input: N, maxIteration, mutation rate, t = 0, k = 0 Output: alarm_center[], alarms after clustering 1: Randomly generate initial population Xi (i = 1, 2, …, N) 2: Calculate the fitness value of each solution 3: Get the best Xi that has the largest fitness value, mark it as X* 4: while t < MaxIteration do 5: for population Xi (i = 1, 2, …, N) do 6: Use Equations (3)–(5) to update a,A,C 7: Generate values for random numbers 1 and p 8: if p < 0.5 then 9: if |A| < 1 then 10: Use Equations (1) and (2) to update the position of Xi 11: Apply mutation operation on X* (best solution) given mutation rate (r) to get Xmut 12: Perform crossover operation between Xmut and Xi 13: Set the new position of Xi to the output of crossover operation 14: else if |A| ≥ 1 then 15: Select a random search agent (Xrand) 16: Use Equations (8) and (9) to update the position of Xi 17: Apply mutation operation on Xrand given mutation rate (r) to get Xmut 18: Perform crossover operation between Xmut and Xrand 19: Set the new position of Xi to the output of crossover operation 20: end if 21; else if p ≥ 0.5 then 22: Use Equation (6) to update the position of the current solution Xi 23: Apply mutation operation on X* (best solution) given mutation rate (r) to get Xmut 24: Perform crossover operation between Xmut and Xi 25: Set the new position of Xi to the output of crossover operation 26: end if 27: end for 28: Calculate the fitness of each solution, check if any solution goes beyond the search space 29: If there is a better solution Xi, update Xi as X* 30: t = t + 1 31 end while 32: return X* |
5. Experiments and Results
5.1. Experiment Data Set
5.2. Experimental Setup
5.3. Experimental Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, J.; Gu, L.; Chen, K. An Efficient Alert Aggregation Method Based on Conditional Rough Entropy and Knowledge Granularity. Entropy 2020, 22, 324. [Google Scholar] [CrossRef] [Green Version]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.K.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A taxonomy of network threats and the effect of current datasets on intrusion detection systems. IEEE Access 2020, 8, 104650–104675. [Google Scholar] [CrossRef]
- Masdari, M.; Khezri, H. A survey and taxonomy of the fuzzy signature-based Intrusion Detection Systems. Appl. Soft Comput. 2020, 92, 106301. [Google Scholar] [CrossRef]
- Aldweesh, A.; Derhab, A.; Emam, A. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowl.-Based Syst. 2019, 189, 105124. [Google Scholar] [CrossRef]
- Siddique, K.; Akhtar, Z.; Khan, F.A.; Kim, Y. KDD Cup 99 Data Sets: A Perspective on the Role of Data Sets in Network Intrusion Detection Research. Computer 2019, 52, 41–51. [Google Scholar] [CrossRef]
- Ingre, B.; Yadav, A. Performance analysis of NSL-KDD dataset using ANN. In Proceedings of the 2015 International Conference on Signal Processing and Communication Engineering Systems, Guntur, India, 2–3 January 2015; pp. 92–96. [Google Scholar]
- Alkasassbeh, M.; Al-Naymat, G.; Hassanat, A.B.; Almseidin, M. Detecting Distributed Denial of Service Attacks Using Data Mining Techniques. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 436–445. [Google Scholar] [CrossRef] [Green Version]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. A detailed analysis of the cicids2017 data set. In Proceedings of the International Conference on Information Systems Security and Privacy, Funchal-Madeira, Portuga, 22–24 January 2018; Springer: Cham, Switzerland, 2018; pp. 172–188. [Google Scholar]
- Damasevicius, R.; Venckauskas, A.; Grigaliunas, S.; Toldinas, J.; Morkevicius, N.; Aleliunas, T.; Smuikys, P. LITNET-2020: An Annotated Real-World Network Flow Dataset for Network Intrusion Detection. Electronics 2020, 9, 800. [Google Scholar] [CrossRef]
- Dinh, D.T.; Huynh, V.N.; Sriboonchitta, S. Clustering mixed numerical and categorical data with missing values. Inf. Sci. 2021, 571, 418–442. [Google Scholar] [CrossRef]
- Pattanodom, M.; Iam-On, N.; Boongoen, T. Clustering data with the presence of missing values by ensemble approach. In Proceedings of the 2016 Second Asian Conference on Defence Technology (acdt), Chiang Mai, Thailand, 21–23 January 2016; pp. 151–156. [Google Scholar]
- Boluki, S.; Dadaneh, S.Z.; Qian, X.; Dougherty, E.R. Optimal clustering with missing values. BMC Bioinform. 2019, 20, 321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmed, T.; Siraj, M.M.; Zainal, A.; Mat Din, M. A taxonomy on intrusion alert aggregation techniques. In Proceedings of the 2014 International Symposium on Biometrics and Security Technologies (ISBAST), Kuala Lumpur, Malaysia, 26–27 August 2014; pp. 244–249. [Google Scholar]
- Husák, M.; Čermák, M.; Laštovička, M.; Vykopal, J. Exchanging security events: Which and how many alerts can we aggregate? In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 604–607. [Google Scholar]
- Milan, H.S.; Singh, K. Reducing false alarms in intrusion detection systems—A survey. Int. Res. J. Eng. Technol. 2018, 5, 9–12. [Google Scholar]
- Tian, W.; Zhang, G.; Liang, H. Alarm clustering analysis and ACO based multi-variable alarms thresholds optimization in chemical processes. Process. Saf. Environ. Prot. 2018, 113, 132–140. [Google Scholar] [CrossRef]
- Hachmi, F.; Boujenfa, K.; Limam, M. Enhancing the Accuracy of Intrusion Detection Systems by Reducing the Rates of False Positives and False Negatives Through Multi-objective Optimization. J. Netw. Syst. Manag. 2018, 27, 93–120. [Google Scholar] [CrossRef]
- Liu, L.; Xu, B.; Zhang, X.; Wu, X. An intrusion detection method for internet of things based on suppressed fuzzy clustering. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 113. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Guo, T.; Liu, J. An IDS alerts aggregation algorithm based on rough set theory. IOP Conf. Ser. Mater. Sci. Eng. 2018, 322, 062009. [Google Scholar] [CrossRef]
- Li, W.; Meng, W.; Su, C.; Kwok, L.F. Towards False Alarm Reduction Using Fuzzy If-Then Rules for Medical Cyber Physical Systems. IEEE Access 2018, 6, 6530–6539. [Google Scholar] [CrossRef]
- Hu, Q.; Lv, S.; Shi, Z.; Sun, L.; Xiao, L. Defense against advanced persistent threats with expert system for internet of things. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications; Guilin, China, 19–21 June 2017; Springer: Cham, Switzerland, 2017; pp. 326–337. [Google Scholar]
- Zaeri-Amirani, M.; Afghah, F.; Mousavi, S. A feature selection method based on shapley value to false alarm reduction in icus a genetic-algorithm approach. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 319–323. [Google Scholar]
- Sabino, S.; Grilo, A. Routing for Efficient Alarm Aggregation in Smart Grids: A Genetic Algorithm Approach. Procedia Comput. Sci. 2018, 130, 164–171. [Google Scholar] [CrossRef]
- Mannani, Z.; Izadi, I.; Ghadiri, N. Preprocessing of Alarm Data for Data Mining. Ind. Eng. Chem. Res. 2019, 58, 11261–11274. [Google Scholar] [CrossRef]
- Hashim, S.H. Intrusion detection system based on data mining techniques to reduce false alarm rate. Eng. Technol. J. 2018, 36 Pt B, 110–119. [Google Scholar]
- Mavrovouniotis, M.; Li, C.; Yang, S. A survey of swarm intelligence for dynamic optimization: Algorithms and applications. Swarm Evol. Comput. 2017, 33, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Gholizadeh, H. A comprehensive survey: WOA and its applications. Swarm Evol. Comput. 2019, 48, 1–24. [Google Scholar] [CrossRef]
- Wang, Y.; Meng, W.; Li, W.; Liu, Z.; Liu, Y.; Xue, H. Adaptive machine learning based alarm reduction via edge computing for distributed intrusion detection systems. Concurr. Comput. Pract. Exp. 2019, 31, e5101. [Google Scholar] [CrossRef]
- Toldinas, J.; Venčkauskas, A.; Damaševičius, R.; Grigaliūnas, Š.; Morkevičius, N.; Baranauskas, E. A Novel Approach for Network Intrusion Detection Using Multistage Deep Learning Image Recognition. Electronics 2021, 10, 1854. [Google Scholar] [CrossRef]
- Weiß, I.; Kinghorst, J.; Kröger, T.; Pirehgalin, M.F.; Vogel-Heuser, B. Alarm flood analysis by hierarchical clustering of the probabilistic dependency between alarms. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; pp. 227–232. [Google Scholar]
- Fahimipirehgalin, M.; Weiss, I.; Vogel-Heuser, B. Causal inference in industrial alarm data by timely clustered alarms and transfer entropy. In Proceedings of the 2020 European Control Conference (ECC), St. Petersburg, Russia, 12–15 May 2020; pp. 2056–2061. [Google Scholar]
- Alharbi, A.; Alosaimi, W.; Alyami, H.; Rauf, H.; Damaševičius, R. Botnet Attack Detection Using Local Global Best Bat Algorithm for Industrial Internet of Things. Electronics 2021, 10, 1341. [Google Scholar] [CrossRef]
- Abu Khurma, R.; Almomani, I.; Aljarah, I. IoT Botnet Detection Using Salp Swarm and Ant Lion Hybrid Optimization Model. Symmetry 2021, 13, 1377. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, B.; Li, J. Research on IDS Alert Aggregation Based on Improved Quantum-behaved Particle Swarm Optimization. In Proceedings of the Computer Science and Technology(CST2016), Shenzhen, China, 8–10 January 2016; pp. 293–299. [Google Scholar]
- Lin, H.C.; Wang, P.; Lin, W.H.; Chao, K.M.; Yang, Z.Y. Identifying the Attack Sources of Botnets for a Renewable Energy Management System by Using a Revised Locust Swarm Optimisation Scheme. Symmetry 2021, 13, 1295. [Google Scholar] [CrossRef]
- Ibrahim, N.M.; Zainal, A. A Feature Selection Technique for Cloud IDS Using Ant Colony Optimization and Decision Tree. Adv. Sci. Lett. 2017, 23, 9163–9169. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.-K.R.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 130. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Du, X.; Wang, W. An Alert Aggregation Algorithm Based on K-means and Genetic Algorithm. IOP Conf. Ser. Mater. Sci. Eng. 2018, 435, 012031. [Google Scholar] [CrossRef]
- Yang, X.S.; Gandomi, A.H. Bat algorithm: A novel approach for global engineering optimization. Eng. Comput. 2012, 29, 464–483. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Yapici, H.; Cetinkaya, N. A new meta-heuristic optimizer: Pathfinder algorithm. Appl. Soft Comput. 2019, 78, 545–568. [Google Scholar] [CrossRef]
- Julisch, K. Clustering intrusion detection alarms to support root cause analysis. ACM Trans. Inf. Syst. Secur. 2003, 6, 443–471. [Google Scholar] [CrossRef]
- Julisch, K. Using Root Cause Analysis to Handle Intrusion Detection Alarms. Ph.D. Thesis, University of Dortmund, North Rhine-Westphalia, Germany, 2003. [Google Scholar]
- Wang, J.; Wang, H.; Zhao, G. A GA-based Solution to an NP-hard Problem of Clustering Security Events. In Proceedings of the 2006 International Conference on Communications, Circuits and Systems, Guilin, China, 25–28 June 2006; pp. 2093–2097. [Google Scholar]
- Wang, J.; Xia, Y.; Wang, H. Minining Intrusion Detection Alarms with an SA-based Clustering Approach. In Proceedings of the 2007 International Conference on Communications, Circuits and Systems, Kokura, Japan, 11–13 July 2007; pp. 905–909. [Google Scholar]
- Mafarja, M.; Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. 2018, 62, 441–453. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.; Trigg, L.; Holmes, G.; Witten, I. Data mining in bioinformatics using Weka. Bioinformatics 2004, 20, 2479–2481. [Google Scholar] [CrossRef] [PubMed] [Green Version]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| node of a hierarchical tree | |
| alarm in an alarm set | |
| The distance between alarm and alarm in an alarm set | |
| alarm cluster center | |
| In WOA, the current solution at iteration t | |
| In WOA, the best solution at iteration t | |
| In WOA, a random solution in the current solution space | |
| In WOA, the distance between and | |
| In WOA, the number of search agents to search solution simultaneously | |
| In WOA, a predetermined maximum number of iterations | |
| Random numbers used in WOA to control logical judgment | |
| Fitness value of alarm number for cluster center k | |
| Fitness value of alarm distance for cluster center k | |
| The degree of overlap between cluster center and cluster center | |
| Fitness value of the coincidence degree of all cluster centers in the cluster | |
| Number of normal network traffic clustering to normal cluster | |
| Number of network attack clustering to attack cluster | |
| Number of network attack alarms incorrectly clustering to normal cluster | |
| Number of normal network traffic incorrectly clustering to attack cluster |
| Category | No | Name | Data Type | Category | No | Name | Data Type |
|---|---|---|---|---|---|---|---|
| Flow | 1 | srcip | Nominal | Content | 25 | trans_depth | Integer |
| 2 | sport | Integer | 26 | res_bdy_len | Integer | ||
| 3 | dstip | Nominal | Time | 27 | Sjit | Float | |
| 4 | dsport | Integer | 28 | Djit | Float | ||
| 5 | proto | Nominal | 29 | Stime | Timestamp | ||
| Basic | 6 | state | Nominal | 30 | Ltime | Timestamp | |
| 7 | dur | Float | 31 | Sintpkt | Float | ||
| 8 | sbytes | Integer | 32 | Dintpkt | Float | ||
| 9 | dbytes | Integer | 33 | Tcprtt | Float | ||
| 10 | sttl | Integer | 34 | Synacj | Float | ||
| 11 | dttl | Integer | 35 | Ackdat | Float | ||
| 12 | sloss | Integer | General | 36 | Is_sm_ips_ports | Binary | |
| 13 | dloss | Integer | Purpose | 37 | Ct_state_ttl | Integer | |
| 14 | service | Nominal | 38 | Ct_flw_http_mthd | Integer | ||
| 15 | Sload | Float | 39 | Is_ftp_login | Binary | ||
| 16 | Dload | Float | 40 | Ct_ftp_cmd | Integer | ||
| 17 | Spkts | Integer | Connection | 41 | Ct_srv_src | Integer | |
| 18 | Dpkts | Integer | 42 | Ct_srv_dst | Integer | ||
| Content | 19 | swin | Integer | 43 | Ct_dst_ltm | Integer | |
| 20 | dwin | Integer | 44 | Ct_src_ltm | Integer | ||
| 21 | stcpb | Integer | 45 | Ct_src_dport_ltm | Integer | ||
| 22 | dtcpb | Integer | 46 | Ct_dst_sport_ltm | Integer | ||
| 23 | smeansz | Integer | 47 | Ct_dst_src_ltm | Integer | ||
| 24 | dmeansz | Integer | 48 | Attack_cat | Nominal | ||
| 49 | Class | Binary |
| Attack_Catgory | Number | Attack_Catgory | Number | ||
|---|---|---|---|---|---|
| 1 | Null | 44,387 | 6 | Reconnaissance | 289 |
| 2 | Generic | 4257 | 7 | Backdoor | 53 |
| 3 | Exploits | 913 | 8 | Analysis | 52 |
| 4 | Fizzers | 463 | 9 | Shellcode | 29 |
| 5 | DoS | 355 | 10 | Worms | 3 |
| Source_IP | Number | Destination_IP | Number |
|---|---|---|---|
| 59.166.0.X | 38,817 | 149.171.126 | 46,051 |
| 175.45.176.X | 7234 | 175.45.176 | 4284 |
| 149.171.126.X | 4338 | 10.40.X.X | 298 |
| 10.40.X.X | 412 | 224.0.0.X | 108 |
| 59.166.0.X | 55 | ||
| 192.168.241 | 5 |
| Time Rounds | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Time Consuming |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 18,433 | 14,870 | 3219 | 6553 | 4170 | 745 | 421 | 921 | 31 | 29 | 51 | 66.3 s |
| 2 | 38,923 | 4331 | 3490 | 993 | 671 | 210 | 78 | 32 | 52.0 s | |||
| 3 | 36,544 | 4370 | 4921 | 2008 | 719 | 198 | 43 | 23 | 104 | 97 | 56.5 s | |
| 4 | 24,003 | 18,995 | 4109 | 529 | 899 | 32 | 390 | 241 | 45 | 122 | 55.3 s | |
| 5 | 15,023 | 30,901 | 2104 | 2233 | 920 | 320 | 429 | 290 | 102 | 63.4 s |
| Cluster Numbers | Time Consuming | Remaining Alarms | Accuracy | Precision | Recall | |
| Julisch’s method | 16 | 43.2 | 831.4 | 91.8% | 97.6% | 92.9% |
| GA-based | 10 | 31.5 | 432.4 | 93.5% | 97.1% | 95.4% |
| SA-based | 13 | 25.5 | 913.0 | 91.7% | 96.7% | 93.7% |
| WOAHC-L | 10 | 68.3 | 322.5 | 95.2% | 98.4% | 96.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Gu, L.; Tang, Y. Research on Alarm Reduction of Intrusion Detection System Based on Clustering and Whale Optimization Algorithm. Appl. Sci. 2021, 11, 11200. https://doi.org/10.3390/app112311200
Wang L, Gu L, Tang Y. Research on Alarm Reduction of Intrusion Detection System Based on Clustering and Whale Optimization Algorithm. Applied Sciences. 2021; 11(23):11200. https://doi.org/10.3390/app112311200
Chicago/Turabian StyleWang, Leiting, Lize Gu, and Yifan Tang. 2021. "Research on Alarm Reduction of Intrusion Detection System Based on Clustering and Whale Optimization Algorithm" Applied Sciences 11, no. 23: 11200. https://doi.org/10.3390/app112311200